Entgegen der landläufigen Meinung ist maschinelles Lernen keine Erfindung des 21. Jahrhunderts. In den letzten zwanzig Jahren sind nur ausreichend produktive Hardwareplattformen erschienen, so dass es ratsam ist, neuronale Netze und andere Modelle des maschinellen Lernens zu verwenden, um alltägliche Probleme zu lösen. Die Software-Implementierungen von Algorithmen und Modellen wurden ebenfalls verschärft.
Die Versuchung, Maschinen selbst für unsere Sicherheit zu sorgen und Menschen zu schützen (eher faul, aber klug), ist zu groß geworden. Laut
CB Insights versuchen fast 90 Startups (2 davon mit einer Schätzung von mehr als einer Milliarde US-Dollar), zumindest einen Teil der routinemäßigen und monotonen Aufgaben zu automatisieren. Mit unterschiedlichem Erfolg.

Das Hauptproblem der
künstlichen Intelligenz in der Sicherheit ist derzeit zu viel Hype und offener Marketing-Bullshit. Der Ausdruck "Künstliche Intelligenz" zieht Investoren an. Es kommen Leute in die Branche, die bereit sind, KI als einfachste Korrelation von Ereignissen zu bezeichnen. Käufer von Lösungen für ihr eigenes Geld bekommen nicht das, was sie sich erhofft hatten (auch wenn diese Erwartungen anfangs zu hoch waren).

Wie aus der CB Insights-Karte hervorgeht, gibt es Dutzende von Gebieten, in denen MO verwendet wird. Maschinelles Lernen ist jedoch aufgrund mehrerer schwerwiegender Einschränkungen noch nicht zur „magischen Pille“ der Cybersicherheit geworden.
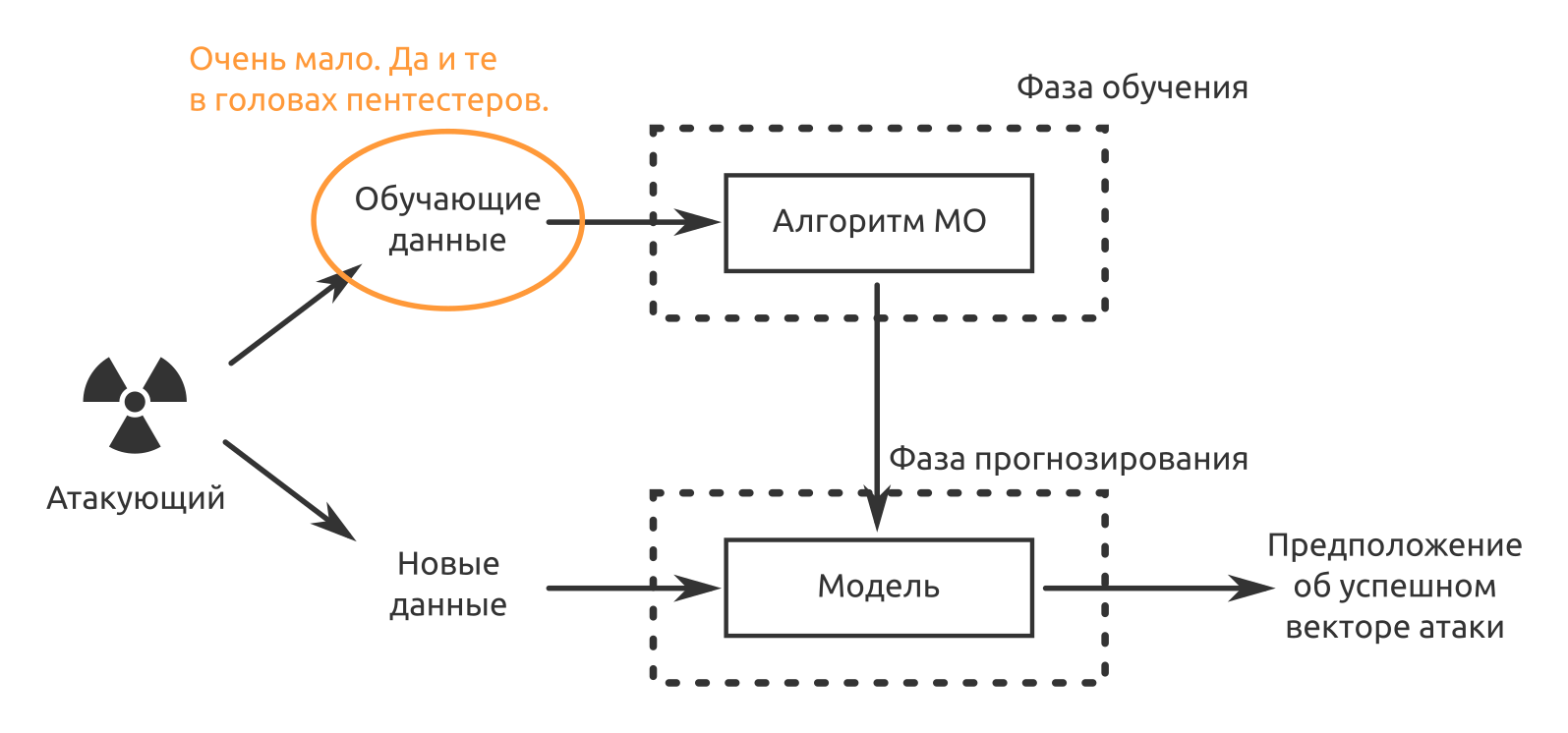
Die erste Einschränkung ist die enge Anwendbarkeit der Funktionalität jedes einzelnen Modells. Ein neuronales Netzwerk kann eines gut. Wenn Bilder gut erkannt werden, kann dasselbe Netzwerk Audio nicht erkennen. Dasselbe gilt für die Informationssicherheit: Wenn das Modell darauf trainiert wurde, Ereignisse von Netzwerksensoren zu klassifizieren und Computerangriffe auf Netzwerkgeräte zu erkennen, kann es beispielsweise nicht mit mobilen Geräten arbeiten. Wenn der Kunde ein KI-Fan ist, wird er kaufen, kaufen und kaufen.
Die zweite Einschränkung ist das Fehlen von Trainingsdaten. Die Lösungen sind vorab geschult, jedoch nicht für Ihre Daten. Wenn die Situation „Wer in den ersten zwei Betriebswochen als falsch positiv eingestuft wird“ weiterhin akzeptiert werden kann, wird das „Sicherheitspersonal“ in Zukunft leicht verwirrt sein, da es eine Lösung gekauft hat, damit die Maschine die Routine übernimmt und nicht umgekehrt.

Das dritte und wahrscheinlich wichtigste ist, dass MO-Produkte nicht für ihre Entscheidungen verantwortlich gemacht werden können. Selbst der Entwickler eines „einzigartigen Schutzmittels mit künstlicher Intelligenz“ kann solche Behauptungen beantworten: „Nun, was wollten Sie? Ein neuronales Netzwerk ist eine Black Box! Warum hat sie sich so entschieden, niemand außer ihr weiß es. “ Daher bestätigen Personen jetzt Vorfälle mit Informationssicherheit. Maschinen helfen, aber die Leute sind immer noch verantwortlich.
Es gibt Probleme mit dem Schutz von Informationen. Sie werden früher oder später gelöst. Aber was ist mit dem Angriff? Können MO und AI zur „Silberkugel“ von Cyberangriffen werden?
Optionen für die Verwendung von maschinellem Lernen, um die Wahrscheinlichkeit eines Pentest-Erfolgs oder einer Sicherheitsanalyse zu erhöhen
Wahrscheinlich ist es jetzt am rentabelsten, MO zu verwenden, wo:
- Sie müssen etwas Ähnliches erstellen, auf das das neuronale Netzwerk bereits gestoßen ist.
- Es ist notwendig, Muster zu identifizieren, die für den Menschen nicht offensichtlich sind.
Das MO macht diese Aufgaben bereits sehr gut. Abgesehen davon können einige Aufgaben beschleunigt werden. Zum Beispiel haben meine Kollegen bereits über
Angriffsautomatisierung mit Python und Metasploit geschrieben .
Ich versuche zu täuschen
Oder überprüfen Sie das Bewusstsein der Mitarbeiter für Informationssicherheitsprobleme. Wie unsere Penetrationstestpraxis zeigt, funktioniert Social Engineering - in fast allen Projekten, in denen ein solcher Angriff durchgeführt wurde, waren wir erfolgreich.
Angenommen, wir haben bereits mit herkömmlichen Methoden (Unternehmenswebsite, soziale Netzwerke, Jobwebsites, Veröffentlichungen usw.) wiederhergestellt:
- Organisationsstruktur;
- Liste der wichtigsten Mitarbeiter;
- E-Mail-Adressmuster oder echte Adressen
- telefoniert, vorgetäuscht, ein potenzieller Kunde zu sein, fand den Namen des Verkäufers, Managers, Sekretärs heraus.
Als nächstes müssen wir Daten erhalten, um ein neuronales Netzwerk zu trainieren, das die Stimme einer bestimmten Person nachahmt. In unserem Fall jemand aus dem Management des getesteten Unternehmens. In diesem
Artikel heißt es, dass eine Minute Stimme ausreicht, um authentisch vorzutäuschen.
Wir suchen nach Aufzeichnungen von Reden auf Konferenzen, wir gehen selbst zu ihnen und zeichnen sie auf, wir versuchen, mit der Person zu sprechen, die wir brauchen. Wenn es uns gelingt, eine Stimme zu imitieren, können wir selbst eine stressige Situation für ein bestimmtes Opfer des Angriffs schaffen.
- Hallo?
- Verkäufer Preseylovich, hallo. Dies ist Direktor Nachalnikovich. Ihr Mobiltelefon reagiert nicht. Dort erhalten Sie nun einen Brief von Vector-Fake LLC, siehe. Das ist dringend!
"Ja, aber ..."
- Das war's, ich kann nicht mehr reden. Ich bin in einer Besprechung. Vor der Kommunikation. Antworte ihnen!
Wer wird nicht antworten? Wer wird den Anhang nicht sehen? Jeder wird sehen. Und Sie können alles in diesen Brief laden. Gleichzeitig ist es nicht erforderlich, die Telefonnummer des Direktors oder die persönliche Telefonnummer des Verkäufers zu kennen. Es ist nicht erforderlich, eine E-Mail-Adresse auf einer internen Unternehmensadresse zu fälschen, von der eine böswillige E-Mail stammt.
Die Angriffsvorbereitung (Datenerfassung und -analyse) kann übrigens auch teilweise automatisiert werden. Wir suchen gerade einen
Entwickler in einem Team, das ein solches Problem löst und ein Softwarepaket erstellt, das einem Analysten das Leben im Bereich Wettbewerbsinformationen und wirtschaftliche Sicherheit eines Unternehmens erleichtert.
Wir greifen die Implementierung von Kryptosystemen an
Angenommen, wir können den verschlüsselten Datenverkehr der angegriffenen Organisation abhören. Aber wir möchten wissen, was genau in diesem Verkehr ist. Diese Untersuchung der Cisco-Mitarbeiter „
Erkennen von Schadcode in verschlüsseltem TLS-Verkehr (ohne Entschlüsselung) “ kam auf die Idee. Wenn wir das Vorhandensein bösartiger Objekte anhand von Daten aus NetFlow-, TLS- und DNS-Dienstdaten feststellen können, was hindert uns dann daran, dieselben Daten zur Identifizierung der Kommunikation zwischen Mitarbeitern der angegriffenen Organisation sowie zwischen Mitarbeitern und Unternehmens-IT-Diensten zu verwenden?
Eine Krypta auf der Stirn anzugreifen ist teurer. Daher versuchen wir anhand von Daten zu den Adressen und Ports der Quelle und des Ziels, der Anzahl der übertragenen Pakete und ihrer Größe sowie der Zeitparameter, den verschlüsselten Verkehr zu bestimmen.
Nachdem wir bei der P2P-Kommunikation Krypto-Gateways oder Endknoten ermittelt haben, beginnen wir mit deren Fertigstellung und zwingen die Benutzer, zu weniger sicheren Kommunikationsmethoden zu wechseln, die leichter anzugreifen sind.
Der Reiz der Methode besteht aus zwei Vorteilen:
- Die Maschine kann zu Hause auf virtualochki trainiert werden. Es gibt viele kostenlose und sogar Open-Source-Produkte für die Erstellung sicherer Kommunikation. „Maschine, das ist so und so ein Protokoll, es hat so und so viele Paketgrößen, so und so Entropie. Verstehst du es Erinnerst du dich? " Wiederholen Sie dies so oft wie möglich für verschiedene Arten offener Daten.
- Sie müssen nicht den gesamten Datenverkehr "fahren" und das Modell durchlaufen, nur Metadaten reichen aus.
Nachteil - MitM muss noch empfangen werden.
Auf der Suche nach Softwarefehlern und Schwachstellen
Der wohl bekannteste Versuch, die Suche, Ausnutzung und Korrektur von Schwachstellen zu automatisieren, ist die DARPA Cyber Grand Challenge. Im Jahr 2016 kamen sieben vollautomatische Systeme, die von verschiedenen Teams entwickelt wurden, im letzten CTF-ähnlichen Kampf zusammen. Natürlich wurde das Ziel der Entwicklung als ausschließlich gut erklärt - Schutz von Infrastrukturen, iot, Anwendungen in Echtzeit und mit minimaler Beteiligung von Menschen. Sie können die Ergebnisse jedoch aus einem anderen Blickwinkel betrachten.
Die erste Richtung, in die sich das MO in dieser Angelegenheit entwickelt, ist die Fuzzing-Automatisierung. Dieselben CGC-Mitglieder nutzten den amerikanischen Fuzzy-Lop ausgiebig. Je nach Einstellung erzeugen Fuzzers während des Betriebs mehr oder weniger Leistung. Wo es viele strukturierte und schwach strukturierte Daten gibt, suchen MO-Modelle perfekt nach Mustern. Wenn der Versuch, die Anwendung zu "löschen", mit einer Eingabe funktioniert hat, besteht die Möglichkeit, dass dieser Ansatz an einer anderen Stelle funktioniert.
Gleiches gilt für die statische Code-Analyse und die dynamische Analyse ausführbarer Dateien, wenn der Quellcode der Anwendung nicht verfügbar ist. Neuronale Netze können nicht nur nach Codeteilen mit Schwachstellen suchen, sondern auch nach Code, der verwundbar aussieht. Glücklicherweise gibt es viel Code mit bestätigten (und behobenen) Schwachstellen. Der Forscher muss diesen Verdacht überprüfen. Mit jedem neuen Fehler wird ein solcher NS immer „schlauer“. Dank dieses Ansatzes können Sie nicht nur vorab geschriebene Signaturen verwenden.
Wenn ein neuronales Netzwerk in der dynamischen Analyse die Beziehung zwischen Eingabedaten (einschließlich Benutzerdaten), Ausführungsreihenfolge, Systemaufrufen, Speicherzuweisung und bestätigten Schwachstellen „verstehen“ kann, kann es schließlich nach neuen suchen.
Betrieb automatisieren
Jetzt mit rein automatischem Betrieb gibt es ein Problem -
Isao Takaesu und die anderen Mitwirkenden, die Deep Exploit, das „vollautomatische Penetrationstest-Tool mit maschinellem Lernen“, entwickeln, versuchen, es zu lösen. Details über ihn sind
hier und
hier geschrieben .
Diese Lösung kann in zwei Modi arbeiten - Datenerfassungsmodus und Brute-Force-Modus.
Im ersten Modus identifiziert DE alle offenen Ports auf dem angegriffenen Host und startet Exploits, die zuvor für eine solche Kombination funktioniert haben.
Im zweiten Modus gibt der Angreifer den Produktnamen und die Portnummer an, und DE trifft nach Bereich, wobei alle verfügbaren Kombinationen aus Exploit, Nutzlast und Ziel verwendet werden.
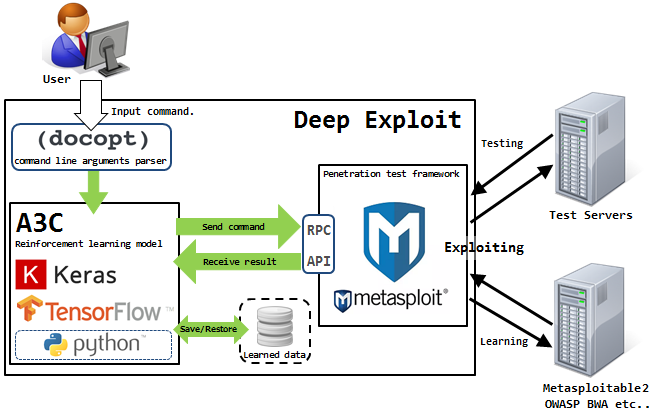
Deep Exploit kann mithilfe eines verstärkten Trainings unabhängig voneinander Betriebsmethoden erlernen (dank des Feedbacks, das DE von dem angegriffenen System erhält).
Kann AI jetzt das Pentester-Team ersetzen?
Wahrscheinlich
noch nicht.
Maschinen haben Probleme beim Aufbau logischer Ketten zur Ausnutzung identifizierter Schwachstellen. Genau dies wirkt sich jedoch häufig direkt auf die Erreichung des Ziels der Penetrationstests aus. Eine Maschine kann eine Sicherheitsanfälligkeit finden, sie kann sogar selbst einen Exploit erstellen, aber sie kann den Grad der Auswirkung dieser Sicherheitsanfälligkeit auf ein bestimmtes Informationssystem, Informationsressourcen oder Geschäftsprozesse des gesamten Unternehmens nicht bewerten.
Der Betrieb automatisierter Systeme erzeugt auf dem angegriffenen System eine Menge Geräusche, die von der Schutzausrüstung leicht wahrgenommen werden. Autos arbeiten ungeschickt. Es ist möglich, dieses Rauschen zu reduzieren und sich mithilfe von Social Engineering ein Bild vom System zu machen, und damit sind die Maschinen auch nicht sehr gut.
Und die Autos haben keinen Einfallsreichtum und keinen Sinn. Wir hatten kürzlich ein Projekt, bei dem die kostengünstigste Möglichkeit zur Durchführung von Tests die Verwendung eines funkgesteuerten Modells ist. Ich kann mir nicht vorstellen, wie ein Nicht-Mensch an so etwas denken könnte.
Welche Ideen für die Automatisierung könnten Sie anbieten?