Vor einiger Zeit erschien in meinem Facebook-Feed ein Link zu Andrew Ngs Buch über maschinelles Lernen, das als Leidenschaft für maschinelles Lernen oder Durst für maschinelles Lernen übersetzt werden kann.

Menschen, die sich für maschinelles Lernen interessieren oder in diesem Bereich arbeiten, müssen Andrew nicht vorstellen. Für den Uneingeweihten ist es genug zu sagen, dass er ein Weltklasse-Star auf dem Gebiet der künstlichen Intelligenz ist. Wissenschaftler, Ingenieur, Unternehmer, einer der Gründer von Coursera . Er ist Autor einer hervorragenden Einführung in das maschinelle Lernen und die Kurse, aus denen sich die Spezialisierung Deep Learning zusammensetzt .
Ich habe großen Respekt vor Andrew, ich habe an seinen Kursen teilgenommen und mich sofort entschlossen, das veröffentlichte Buch zu lesen. Es stellte sich heraus, dass das Buch noch nicht geschrieben wurde und in Teilen veröffentlicht wird, wie es vom Autor geschrieben wurde. Im Allgemeinen ist dies nicht einmal ein Buch, sondern ein Entwurf eines zukünftigen Buches (ob es in Papierform veröffentlicht wird, ist unbekannt). Dann kam die Idee, die veröffentlichten Kapitel zu übersetzen. Derzeit übersetzte 14 Kapitel (dies ist der erste veröffentlichte Auszug des Buches). Ich plane, diese Arbeit fortzusetzen und das gesamte Buch zu übersetzen. Ich werde übersetzte Kapitel in meinem Blog über Habré veröffentlichen.
Zum Zeitpunkt des Schreibens dieser Zeilen hat der Autor 52 von 56 Kapiteln veröffentlicht (eine Benachrichtigung über die Bereitschaft von 52 Kapiteln ging am 4. Juli an meine Mail). Alle derzeit verfügbaren Kapitel können hier heruntergeladen oder selbst im Internet gefunden werden.
Bevor ich meine Übersetzung veröffentlichte, suchte ich nach anderen Übersetzungen. Ich fand diese, die ebenfalls auf Habré veröffentlicht wurde. Es stimmt, nur die ersten 7 Kapitel wurden übersetzt. Ich kann nicht beurteilen, wessen Übersetzung besser ist. Weder ich noch IliaSafonov (wie ich beim Lesen finde) sind professionelle Übersetzer. Ich mag einige Teile mehr, Ilya einige. Im Vorwort von Ilya können Sie interessante Details über das Buch lesen, die ich weglasse.
Ich veröffentliche meine Übersetzung ohne Korrekturlesen, "aus dem Ofen", ich plane, an einige Orte zurückzukehren und sie zu korrigieren (dies gilt insbesondere für Verwechslungen mit Zug- / Entwicklungs- / Testdatensätzen). Ich wäre dankbar, wenn Kommentare zu Stil, Fehlern usw. sowie Informationen zum Text des Autors gegeben würden.
Alle Bilder sind original (von Andrew Eun), ohne sie wäre das Buch langweiliger.
Also zum Buch:
Kapitel 1. Warum brauchen wir eine Strategie für maschinelles Lernen?
Maschinelles Lernen steht im Mittelpunkt zahlreicher wichtiger Anwendungen, darunter Websuche, E-Mail-Antispam, Spracherkennung, Produktempfehlungen und andere. Ich gehe davon aus, dass Sie oder Ihr Team an Anwendungen für maschinelles Lernen arbeiten. Und dass Sie Ihren Fortschritt in dieser Arbeit beschleunigen möchten. Dieses Buch wird Ihnen dabei helfen.
Beispiel: Erstellen eines Starts zur Erkennung von Katzenbildern
Angenommen, Sie arbeiten in einem Startup, das einen endlosen Strom von Katzenfotos für Katzenliebhaber verarbeitet.

Sie verwenden ein neuronales Netzwerk, um ein Computer-Vision-System zum Erkennen von Katzen auf Fotos aufzubauen.
Leider ist die Qualität Ihres Lernalgorithmus immer noch nicht gut genug und der enorme Druck auf Sie besteht darin, Ihren Katzendetektor zu verbessern.
Was zu tun ist?
Ihr Team hat viele Ideen, wie zum Beispiel:
- Holen Sie sich mehr Daten: Sammeln Sie mehr Fotos von Katzen.
- Sammeln Sie einen heterogeneren Datensatz. Zum Beispiel Fotos von Katzen in ungewöhnlichen Positionen; Fotos von Katzen mit ungewöhnlicher Färbung; Bilder mit verschiedenen Kameraeinstellungen; ...
- Trainieren Sie den Algorithmus länger, indem Sie die Anzahl der Iterationen des Gradientenabfalls erhöhen
- Versuchen Sie, das neuronale Netzwerk mit vielen Schichten / versteckten Neuronen / Parametern zu vergrößern.
- Versuchen Sie, das neuronale Netzwerk zu reduzieren.
- Versuchen Sie, eine Regularisierung hinzuzufügen (z. B. L2-Regularisierung).
- Ändern Sie die Architektur des neuronalen Netzwerks (Aktivierungsfunktion, Anzahl der versteckten Neuronen usw.)
- ...
Wenn Sie erfolgreich zwischen diesen möglichen Richtungen wählen, bauen Sie eine führende Plattform für die Bildverarbeitung von Katzen auf und führen Ihr Unternehmen zum Erfolg. Wenn Ihre Wahl nicht erfolgreich ist, können Sie Monate der Arbeit vergeblich verlieren.
Was tun?
In diesem Buch erfahren Sie, wie.
Die meisten Aufgaben des maschinellen Lernens enthalten Hinweise, die Ihnen Aufschluss darüber geben, was nützlich wäre und was es sinnlos ist, es zu versuchen. Wenn Sie lernen, diese Tipps zu lesen, können Sie Monate und Jahre der Entwicklung sparen.
2. Wie Sie dieses Buch verwenden, um Ihrem Team bei der Arbeit zu helfen
Nachdem Sie dieses Buch gelesen haben, haben Sie ein tiefes Verständnis dafür, wie Sie die technische Richtung für das maschinelle Lernprojekt auswählen.
Aber Ihren Teamkollegen ist möglicherweise nicht klar, warum Sie eine bestimmte Richtung empfehlen. Vielleicht möchten Sie, dass Ihr Team bei der Beurteilung der Qualität des Algorithmus eine Ein-Parameter-Metrik verwendet, aber die Kollegen sind sich nicht sicher, ob dies eine gute Idee ist. Wie überzeugen Sie sie?
Deshalb habe ich die Kapitel kurz gemacht: Damit Sie sie ausdrucken und Ihren Kollegen ein oder zwei Seiten mit Material geben können, mit dem Sie das Team vertraut machen müssen.
Kleine Änderungen in der Priorisierung können einen großen Einfluss auf die Produktivität Ihres Teams haben. Ich hoffe, dass Sie bei diesen kleinen Änderungen zum Superhelden Ihres Teams werden können!

3. Hintergrund und Bemerkungen
Wenn Sie einen maschinellen Lernkurs wie meinen MOOC-Kurs für maschinelles Lernen bei Coursera abgeschlossen haben oder Erfahrung im Unterrichten von Algorithmen mit einem Lehrer haben, wird es für Sie nicht schwierig sein, diesen Text zu verstehen.
Ich gehe davon aus, dass Sie mit der „Lehrerausbildung“ vertraut sind: Lernen einer Funktion, die x mit y verknüpft, anhand von gekennzeichneten Schulungsbeispielen (x, y). Zu den Lernalgorithmen mit einem Lehrer gehören lineare Regression, logistische Regression, neuronale Netze und andere. Heutzutage gibt es viele Formen und Ansätze für maschinelles Lernen, aber die meisten Ansätze von praktischer Bedeutung leiten sich aus den Algorithmen der Klasse "Lernen mit einem Lehrer" ab.
Ich werde mich oft auf neuronale Netze beziehen (auf "tiefes Lernen"). Sie benötigen nur grundlegende Ideen darüber, was sie sind, um diesen Text zu verstehen.
Wenn Sie mit den hier genannten Konzepten nicht vertraut sind, sehen Sie sich das Video der ersten drei Wochen des Kurses für maschinelles Lernen unter Coursera an: http://ml-class.org/
4. Der Fortschrittsbalken beim maschinellen Lernen
Viele Ideen für tiefes Lernen (neuronale Netze) existieren seit Jahrzehnten. Warum sind diese Ideen gerade heute in die Höhe geschossen?
Die beiden größten Treiber der jüngsten Fortschritte sind:
- Datenverfügbarkeit Heutzutage verbringen Menschen viel Zeit mit Computergeräten (Laptops, Mobilgeräten). Ihre digitale Aktivität generiert riesige Datenmengen, die wir unseren Lernalgorithmen zuführen können.
- Rechenleistung Noch vor wenigen Jahren war es möglich, ausreichend große neuronale Netze zu trainieren, sodass Sie die Vorteile der Verwendung der riesigen Datenmengen nutzen können, die wir hatten.
Ich werde klarstellen, dass selbst wenn Sie viele Daten sammeln, die Wachstumskurve der Genauigkeit alter Lernalgorithmen wie der logistischen Regression normalerweise "flach" ist. Dies bedeutet, dass die Lernkurve „abgeflacht“ ist und die Qualität der Vorhersage des Algorithmus nicht mehr wächst, obwohl Sie ihm mehr Daten für das Training geben.
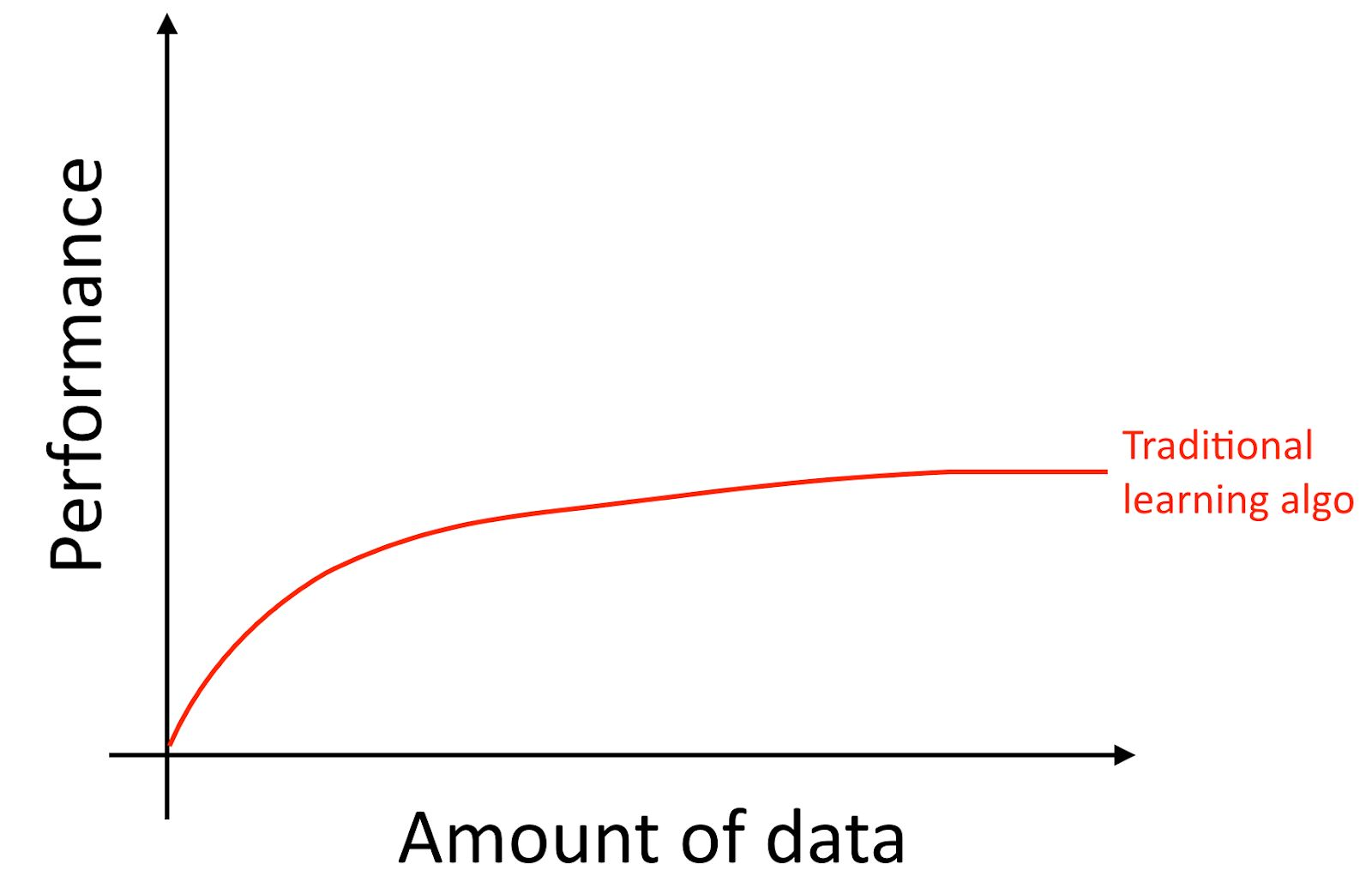
Es sieht so aus, als ob die alten Algorithmen nicht wissen, was sie mit all diesen Daten anfangen sollen, die uns jetzt zur Verfügung stehen.
Wenn Sie ein kleines neuronales Netzwerk (NN) für dieselbe Aufgabe „Lernen mit einem Lehrer“ trainieren, erhalten Sie möglicherweise ein etwas besseres Ergebnis als die „alten Algorithmen“.
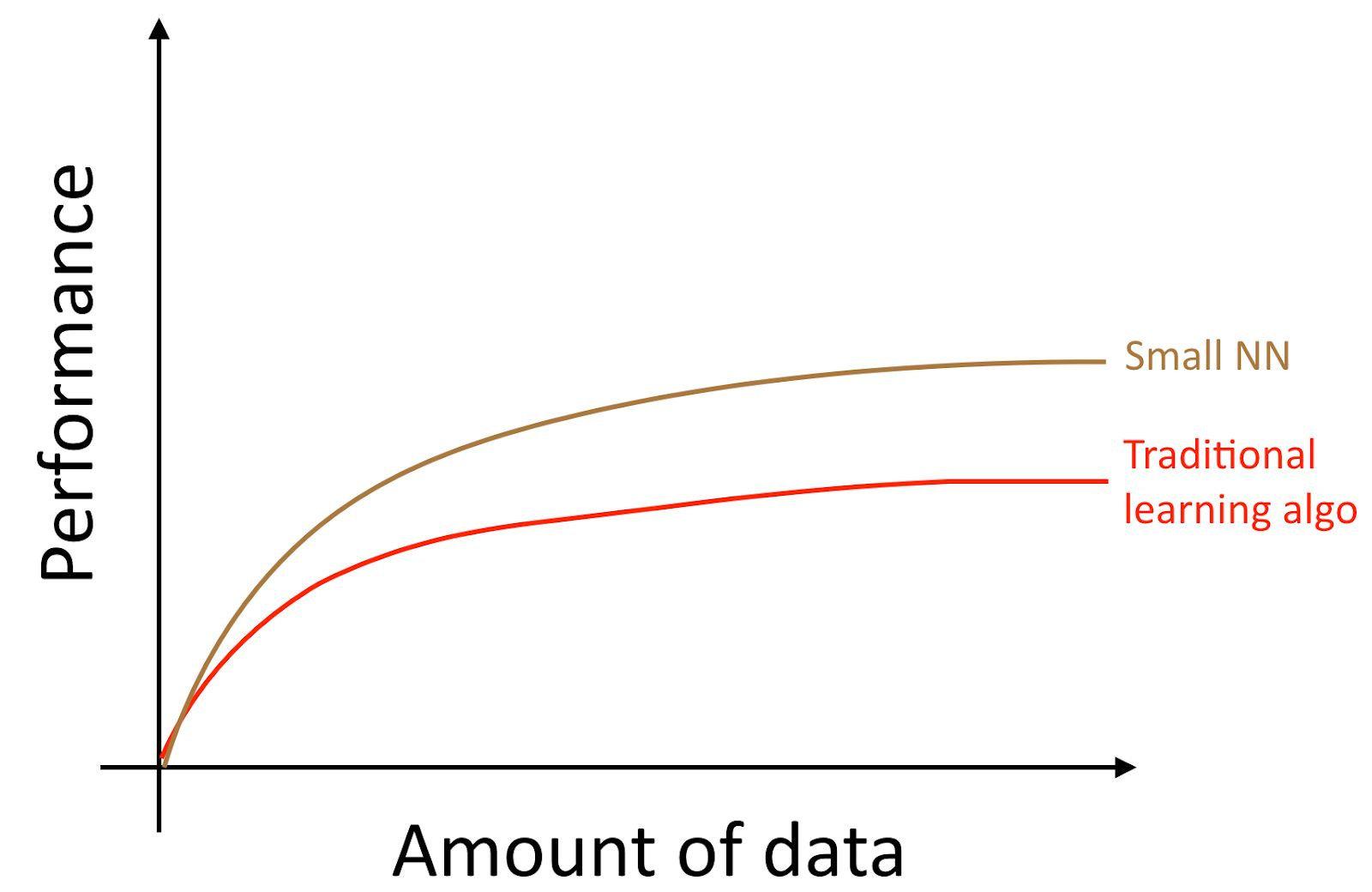
Mit "Small NN" meinen wir hier ein neuronales Netzwerk mit einer kleinen Anzahl versteckter Neuronen / Schichten / Parameter. Wenn Sie schließlich anfangen, immer größere neuronale Netze zu trainieren, können Sie eine immer höhere Qualität erzielen.
Anmerkung des Autors : Dieses Diagramm zeigt, dass neuronale Netze im Modus für kleine Datenmengen eine bessere Leistung erbringen. Dieser Effekt ist weniger stabil als der Effekt neuronaler Netze, die im Modus mit großen Datenmengen gut funktionieren. Im Small-Data-Modus können herkömmliche Algorithmen je nach Verarbeitung der Features (abhängig von der Qualität der Entwicklung der Features) sowohl besser als auch schlechter funktionieren als neuronale Netze. Wenn Sie beispielsweise 20 Trainingsbeispiele haben, spielt es keine Rolle, ob Sie eine logistische Regression oder ein neuronales Netzwerk verwenden. Die Merkmalsvorbereitung hat einen größeren Effekt als die Wahl des Algorithmus. Wenn Sie jedoch 1 Million Trainingsbeispiele haben, würde ich ein neuronales Netzwerk bevorzugen.

Auf diese Weise erhalten Sie die beste Qualität des Algorithmus, wenn Sie (i) ein sehr großes neuronales Netzwerk trainieren. In diesem Fall befinden Sie sich auf der grünen Kurve im obigen Bild. (ii) Sie verfügen über eine große Datenmenge.
Viele andere Details, wie die Architektur neuronaler Netze, sind ebenfalls wichtig, und in diesem Bereich wurden viele innovative Lösungen entwickelt. Der zuverlässigste Weg, um die Qualität des Algorithmus heute zu verbessern, besteht jedoch immer noch darin, (i) das trainierte neuronale Netzwerk zu vergrößern (ii) mehr Daten für das Training zu erhalten.
Der Prozess der gemeinsamen Erfüllung der Bedingungen (i) und (ii) in der Praxis ist überraschend komplex. In diesem Buch werden die Details ausführlich erläutert. Wir beginnen mit allgemeinen Strategien, die sowohl für traditionelle Algorithmen als auch für neuronale Netze gleichermaßen nützlich sind, und untersuchen dann die modernsten Strategien, die beim Entwurf und der Entwicklung von Deep-Learning-Systemen verwendet werden.
5. Erstellen von Beispielen für Trainings- und Testalgorithmen
Kehren wir zu unserem obigen Katzenfoto-Beispiel zurück: Sie haben eine mobile Anwendung gestartet und Benutzer laden eine große Anzahl verschiedener Fotos in Ihre Anwendung hoch. Sie möchten automatisch Fotos von Katzen finden.
Ihr Team erhält ein umfangreiches Trainingsset, indem es Fotos von Katzen (positive Beispiele) und Fotos, auf denen es keine Katzen gibt (negative Beispiele), von verschiedenen Websites herunterlädt. Sie teilten den Datensatz in Training und Test im Verhältnis von 70% zu 30% auf. Mit diesen Daten erstellten sie einen Algorithmus, der Katzen findet, die sowohl für Trainings- als auch für Testdaten gut geeignet sind.
Als Sie diesen Klassifikator jedoch in eine mobile Anwendung einführten, stellten Sie fest, dass seine Qualität sehr schlecht ist!

Was ist passiert?
Sie stellen plötzlich fest, dass die Fotos, die Benutzer in Ihre mobile Anwendung hochladen, ein völlig anderes Aussehen haben als die Fotos von den Websites, aus denen Ihr Trainingsdatensatz besteht: Benutzer laden Fotos hoch, die normalerweise mit Handykameras aufgenommen wurden niedrigere Auflösung, weniger scharf und bei schlechten Lichtverhältnissen gemacht. Nach dem Training Ihrer Trainings- / Testmuster, die von Fotos von Websites gesammelt wurden, konnte Ihr Algorithmus die Ergebnisse qualitativ nicht auf die tatsächliche Verteilung der für Ihre Anwendung relevanten Daten (mit Handykameras aufgenommene Fotos) verallgemeinern.
Vor dem Aufkommen der modernen Ära von Big Data bestand die allgemeine Regel des maschinellen Lernens darin, die Daten im Verhältnis von 70% zu 30% in Bildungs- und Testdaten aufzuteilen. Trotz der Tatsache, dass dieser Ansatz immer noch funktioniert, wird es eine schlechte Idee sein, ihn in immer mehr Anwendungen zu verwenden, in denen sich die Verteilung des Trainingsbeispiels (Fotos von Websites im oben diskutierten Beispiel) von der Verteilung der Daten unterscheidet, die im Kampf verwendet werden Modus Ihrer Anwendung (Fotos von der Kamera von Mobiltelefonen).
Die folgenden Definitionen werden häufig verwendet:
- Trainingssatz - eine Stichprobe von Daten, die zum Trainieren des Algorithmus verwendet werden
- Validierungs-Sampling (Dev (Development) -Set) - Ein Daten-Sampling, mit dem Parameter ausgewählt, Merkmale ausgewählt und andere Entscheidungen bezüglich des Trainings des Algorithmus getroffen werden. Es wird manchmal auch als Hold-Out-Kreuzvalidierungssatz bezeichnet.
- Testbeispiel - Ein Beispiel, das zur Beurteilung der Qualität des Algorithmus verwendet wird, während es nicht zum Unterrichten des Algorithmus oder der in diesem Training verwendeten Parameter verwendet wird.
Anmerkung des Übersetzers: Andrew Eun verwendet das Konzept des Entwicklungssatzes oder des Entwicklungssatzes, in russischer Sprache und in der russischsprachigen Terminologie des maschinellen Lernens kommt ein solcher Begriff nicht vor. "Design Sample" oder "Design Sample" (direkte Übersetzung von englischen Wörtern) klingt umständlich. Daher werde ich weiterhin den Ausdruck "Validierungsauswahl" als Übersetzung des Entwicklungssatzes verwenden.
Anmerkung von Übersetzer 2: DArtN schlug vor, das Dev-Set als „Debugging-Sampling“ zu übersetzen. Ich denke, dies ist eine sehr gute Idee, aber ich habe den Begriff „Validation-Sampling“ bereits für eine große Textmenge verwendet und es ist jetzt mühsam, ihn zu ersetzen. Fairerweise stelle ich fest, dass der Begriff „Validierungsstichprobe“ einen Vorteil hat: Diese Stichprobe wird verwendet, um die Qualität des Algorithmus zu bewerten (um die Qualität des in der Trainingsstichprobe trainierten Algorithmus zu bewerten), daher ist es in gewissem Sinne „Test“, der Begriff „Validierung“ in schließt diesen Aspekt ein. Das Adjektiv "Debugging" konzentriert sich auf die Optimierung von Parametern. Aber insgesamt ist dies ein sehr guter Begriff (insbesondere aus Sicht der russischen Sprache), und wenn ich früher daran denken würde, würde ich ihn anstelle des Begriffs "Validierungsstichprobe" verwenden.
Wählen Sie Validierungs- und Testmuster so aus, dass sie (mit Ausnahme der Auswahl (Anpassung) von Parametern) die Daten widerspiegeln, die Sie in Zukunft erwarten, und dass Ihr Algorithmus gut darauf funktioniert.
Mit anderen Worten, Ihre Testprobe sollte nicht nur 30% der verfügbaren Daten ausmachen, insbesondere wenn Sie erwarten, dass die in Zukunft kommenden Daten (Fotos von Mobiltelefonen) von Ihrem Trainingsset abweichen (Fotos aus dem Internet) Websites).
Wenn Sie Ihre mobile Anwendung noch nicht gestartet haben, haben Sie möglicherweise keine Benutzer. Daher sind möglicherweise keine Daten verfügbar, die die Kampfdaten widerspiegeln, die Ihr Algorithmus verarbeiten sollte. Sie können jedoch versuchen, sie zu approximieren. Bitten Sie beispielsweise Ihre Freunde, mit Mobiltelefonen Fotos von Katzen zu machen und diese an Sie zu senden. Nach dem Start Ihrer Anwendung können Sie Ihre Validierungs- und Testmuster anhand der aktuellen Benutzerdaten aktualisieren.
Wenn Sie keine Daten erhalten können, die ungefähr den Daten entsprechen, die Benutzer hochladen, können Sie wahrscheinlich versuchen, Fotos von Websites zu verwenden. Sie müssen sich jedoch bewusst sein, dass dies das Risiko birgt, dass das System mit Kampfdaten nicht gut funktioniert (seine Generalisierungsfähigkeit wird für sie nicht ausreichen).
Die Entwicklung von Validierungs- und Testmustern erfordert einen ernsthaften Ansatz und gründliche Überlegungen. Postulieren Sie zunächst nicht, dass die Verteilung Ihres Trainingssatzes genau mit der Verteilung des Testsatzes übereinstimmen sollte. Versuchen Sie, Testfälle so auszuwählen, dass sie die Verteilung der Daten widerspiegeln, für die Ihr Algorithmus am Ende gut funktionieren soll, und nicht die Daten, die Ihnen beim Erstellen des Trainingsmusters zur Verfügung standen.
6. Validierungs- und Testproben sollten die gleiche Verteilung haben

Angenommen, die Daten Ihrer Katzenfoto-App sind in vier Regionen unterteilt, die Ihren größten Märkten entsprechen: (i) USA, (ii) China, (iii) Indien, (iv) Andere.
Angenommen, wir haben eine Validierungsstichprobe aus Daten aus dem amerikanischen und indischen Markt und eine Teststichprobe aus chinesischen und anderen Daten erstellt. Mit anderen Worten, wir können zwei Segmente zufällig zuweisen, um eine Validierungsprobe zu erhalten, und zwei andere, um eine Testprobe zu erhalten. Richtig?
Nachdem Sie die Validierungs- und Testmuster ermittelt haben, konzentriert sich Ihr Team auf die Verbesserung der Funktionsweise des Algorithmus für das Validierungsmuster. Daher sollte die Validierungsstichprobe die Aufgaben widerspiegeln, die am wichtigsten sind, um gelöst zu werden. Der Algorithmus sollte in allen vier geografischen Segmenten und nicht nur in zwei gut funktionieren.
Das zweite Problem, das sich aus den unterschiedlichen Verteilungen der Validierungs- und Testmuster ergibt, besteht darin, dass Ihr Team wahrscheinlich etwas entwickelt, das für das Validierungsmuster gut funktioniert, nur um herauszufinden, dass es im Testmuster eine schlechte Qualität erzeugt. Ich habe viele Enttäuschungen und verschwendete Anstrengungen gesehen. Vermeiden Sie dies.
Angenommen, Ihr Team hat ein System entwickelt, das bei einer validierten Stichprobe gut funktioniert, bei einer Testprobe jedoch nicht. Wenn Ihre Validierungs- und Testproben aus derselben Verteilung stammen, können Sie [eine sehr klare Diagnose davon erhalten] leicht diagnostizieren, was schief gelaufen ist: Ihr Algorithmus hat die Validierungsprobe umgeschult. Die offensichtliche Lösung für dieses Problem besteht darin, mehr Daten für die Validierungsstichprobe zu verwenden.
, .
- , . , .
- , , . . .
. , — . , , , .
, , , ( ). , , , . — , . , , , , . .
7. ?
, . , 90.0% 90.1%, , , 100 , 0.1%.
: . ( ), .
— , , -, , , 0.01% , . , 10000, , .
? . 30% . , , 100 10000 . , , , , , . / , , .
8.
: ( ), , , . , 97% , 90%, .
(precision) (recall), . . . :
, .
: (precision) () , , . (recall) () , , . , .
, , , , . . , (accuracy) , .
, , . , . F1 , , .
: F1 , . https://en.wikipedia.org/wiki/F1_score , « » , 2/((1/Precision)+(1/Recall)).
, . .
, , : (i) , (ii) , (iii) (iv) . . , . .
9.
.
, . :
, , [] — 0.5*[] , .
: -, , «». , 100 . , . (satisficing) — , , 100 . .
N , ( - , ), , , N-1 . . . , . (N-) , . , , , .
, , « », ( , ). , Amazon Echo «Alexa»; Apple Siri «Hey Siri»; Android «Okay, Google»; Baidu «Hello Baidu». false-positive — , , false-negative — . false-negative ( ) false positive 24 ( ).
.
10
, . - . , :
- ,
- ( )
- , . ( !) , .
. , . : , , .
, , . , - , , . ! , 95.0% 95.1%, 0.1% () . 0.1%- . , , ( ) , , .
11 (dev/test sets)
, , .
, . - , . , . , . , .
, dev/test , , . , + A , B, , , , dev/test .
, - :
1. , , dev/test
, dev/test . , , , . dev/test , , . dev/test , .

2. (dev set)
Durch den Prozess der mehrfachen Entwicklung von Ideen auf einem Validierungssatz (Dev-Set) wird Ihr Algorithmus schrittweise darauf umgeschult. Wenn Sie die Entwicklung abgeschlossen haben, bewerten Sie die Qualität Ihres Systems anhand eines Testmusters. Wenn Sie feststellen, dass die Qualität Ihres Algorithmus im Validierungssatz (Entwicklungssatz) viel besser ist als im Testsatz (Testsatz), bedeutet dies, dass Sie die Validierungsprobe umgeschult haben. In diesem Fall benötigen Sie ein neues Validierungsmuster.
Wenn Sie den Fortschritt Ihres Teams verfolgen müssen, können Sie auch regelmäßig die Qualität Ihres Systems bewerten, z. B. wöchentlich oder monatlich, indem Sie die Qualität des Algorithmus an einem Testmuster bewerten. Verwenden Sie den Testsatz jedoch nicht, um Entscheidungen bezüglich des Algorithmus zu treffen, einschließlich der Frage, ob zur vorherigen Version des Systems zurückgekehrt werden soll, die letzte Woche getestet wurde. Wenn Sie das Testmuster zum Ändern des Algorithmus verwenden, werden Sie das Testmuster erneut trainieren und können sich nicht mehr darauf verlassen, um eine objektive Bewertung der Qualität Ihres Algorithmus zu erhalten (die Sie benötigen, wenn Sie Forschungsartikel veröffentlichen oder diese Metriken verwenden für wichtige Geschäftsentscheidungen).
3. Metric bewertet etwas anderes als das, was für Projektzwecke optimiert werden muss
Angenommen, für Ihre Katzen-App ist Ihre Metrik die Klassifizierungsgenauigkeit. Diese Metrik stuft Klassifikator A derzeit als überlegenen Klassifikator B ein. Angenommen, Sie haben beide Algorithmen ausprobiert und festgestellt, dass zufällige pornografische Bilder durch Klassifikator A gleiten. Obwohl Klassifikator A genauer ist, macht der schlechte Eindruck, den zufällige pornografische Bilder hinterlassen, seine Qualität unbefriedigend. Was hast du falsch gemacht?
In diesem Fall kann die Metrik, die die Qualität der Algorithmen bewertet, nicht bestimmen, dass Algorithmus B tatsächlich besser ist als Algorithmus A für Ihr Produkt. Daher können Sie der Metrik nicht mehr vertrauen, um den besten Algorithmus auszuwählen. Es ist an der Zeit, die Qualitätsbewertungsmetrik zu ändern. Sie können beispielsweise die Metrik ändern, indem Sie den Algorithmus zum Überspringen eines pornografischen Bildes stark beeinträchtigen. Ich empfehle dringend, eine neue Metrik auszuwählen und diese neue Metrik zu verwenden, um explizit ein neues Ziel für das Team festzulegen, anstatt zu lange mit einer nicht vertrauenswürdigen Metrik weiterzuarbeiten und jedes Mal zur manuellen Auswahl zwischen Klassifizierern zurückzukehren.
Dies sind ziemlich allgemeine Ansätze zum Ändern von Entwicklungs- / Testmustern oder zum Ändern der Qualitätsbewertungsmetrik während der Arbeit an einem Projekt. Mit den Originalentwicklungs- / Testbeispielen und -metriken können Sie schnell mit der Iteration Ihres Projekts beginnen. Wenn Sie sogar feststellen, dass die ausgewählten Entwickler- / Testauswahlen oder Metriken Ihr Team nicht mehr in die richtige Richtung lenken, spielt das keine Rolle! Ändern Sie sie einfach und stellen Sie sicher, dass Ihr Team eine neue Richtung kennt.
12 Empfehlungen: Wir bereiten Validierungs- (Entwicklungs-) und Testmuster vor
- Wählen Sie Entwickler aus und testen Sie Beispiele aus einer Distribution, die die Daten widerspiegelt, die Sie in Zukunft erwarten und auf denen Ihr Algorithmus gut funktionieren soll. Diese Beispiele stimmen möglicherweise nicht mit der Verteilung Ihres Trainingsdatensatzes überein.
- Wählen Sie nach Möglichkeit Entwicklertestsätze aus derselben Distribution aus
- Wählen Sie eine Ein-Parameter-Metrik zur Bewertung der Qualität von Algorithmen zur Optimierung für Ihr Team. Wenn Sie mehrere Ziele gleichzeitig erreichen möchten, sollten Sie diese in einer Formel kombinieren (z. B. die Metrik des gemittelten Multiparameterfehlers) oder restriktive und Optimierungsmetriken definieren.
- Maschinelles Lernen ist ein sehr iterativer Prozess: Sie können viele Ideen ausprobieren, bevor Sie eine finden, die Sie zufriedenstellt.
- Das Vorhandensein von Entwicklungs- / Testbeispielen und einer Ein-Parameter-Qualitätsbewertungsmetrik hilft Ihnen dabei, Algorithmen schnell zu bewerten und somit schneller zu durchlaufen.
- Wenn die Entwicklung einer neuen Anwendung beginnt, versuchen Sie, die Entwicklungs- / Testbeispiele schnell zu installieren, und verbringen Sie beispielsweise nicht mehr als eine Woche damit. Bei ausgereiften Anwendungen ist es normal, wenn dieser Vorgang erheblich länger dauert.
- Die gute alte Heuristik, die Trainings- und Testmuster in 70% bis 30% zu unterteilen, gilt nicht für Probleme, bei denen eine große Datenmenge vorhanden ist. Entwicklungs- / Testproben können deutlich weniger als 30% aller verfügbaren Daten ausmachen.
- Wenn Ihr Entwicklungsbeispiel und Ihre Metrik Ihrem Team nicht mehr die richtige Richtung mitteilen, ändern Sie diese schnell: (i) Wenn Ihr Algorithmus für den Validierungssatz (Entwicklungssatz) umgeschult wird, fügen Sie ihm weitere Daten hinzu (in Ihrem Entwicklungssatz). (ii) Wenn sich die Verteilung realer Daten, die Qualität des Algorithmus, den Sie verbessern müssen, von der Verteilung der Daten bei Validierungs- und (oder) Testproben (dev / test sets) unterscheidet, erstellen Sie neue Proben für Test und Entwicklung (dev / test sets). mit anderen Daten. (iii) Wenn Ihre Qualitätsbewertungsmetrik nicht mehr misst, was für Ihr Projekt am wichtigsten ist, ändern Sie diese Metrik.
13 Erstellen Sie Ihr erstes System schnell und aktualisieren Sie es anschließend iterativ
Sie möchten ein neues Anti-Spam-System für E-Mails erstellen. Ihr Team hat mehrere Ideen:
- Sammeln Sie eine riesige Schulungsprobe, die aus Spam-E-Mails besteht. Richten Sie beispielsweise einen Lockvogel ein: Senden Sie absichtlich gefälschte E-Mail-Adressen an bekannte Spammer, damit Sie automatisch Spam-E-Mails sammeln können, die an diese Adressen gesendet werden
- Entwickeln Sie Zeichen, um den Textinhalt des Briefes zu verstehen
- Um Zeichen für das Verständnis der Hülle des Briefes / der Überschrift zu entwickeln, zeigen Zeichen an, über welche Internet-Server der Brief geleitet wurde
- usw
Obwohl ich hart an Anti-Spam-Anwendungen gearbeitet habe, wird es mir immer noch schwer fallen, einen dieser Bereiche auszuwählen. Es wird noch schwieriger, wenn Sie kein Experte auf dem Gebiet sind, für das die Anwendung entwickelt wird.
Versuchen Sie daher nicht, von Anfang an ein ideales System aufzubauen. Bauen und trainieren Sie stattdessen ein einfaches System so schnell wie möglich, möglicherweise in wenigen Tagen.
Anmerkung des Autors: Dieser Tipp richtet sich an Leser, die KI-Anwendungen entwickeln möchten, und nicht an Leser, deren Ziel es ist, wissenschaftliche Artikel zu veröffentlichen. Später werde ich auf das Thema Forschung zurückkommen.
Auch wenn ein einfaches System weit von einem „idealen“ System entfernt ist, das Sie erstellen können, ist es hilfreich zu untersuchen, wie dieses einfache System funktioniert: Sie finden schnell Tipps, die Ihnen die vielversprechendsten Bereiche zeigen, in die Sie Ihre Zeit investieren sollten. In den nächsten Kapiteln erfahren Sie, wie Sie diese Tipps lesen.
14 Fehleranalyse: Schauen Sie sich Beispiele für Entwickler-Set-Ideen an.

Als Sie mit Ihrer Katzenanwendung spielten, bemerkten Sie mehrere Beispiele, in denen die Anwendung Hunde mit Katzen verwechselte. Einige Hunde sehen aus wie Katzen!
Eines der Teammitglieder schlug vor, Software von Drittanbietern einzuführen, die die Leistung des Systems bei Hundefotos verbessern würde. Die Umsetzung der Änderungen wird einen Monat dauern, das Mitglied des Teams, das sie vorgeschlagen hat, ist begeistert. Welche Entscheidung sollten Sie treffen?
Bevor Sie einen Monat in die Lösung dieses Problems investieren, empfehlen wir Ihnen, zunächst zu bewerten, wie die Lösung die Systemqualität verbessert. Dann können Sie rationaler entscheiden, ob es sich lohnt, einen Monat Entwicklungszeit zu verbessern, oder ob es besser ist, diese Zeit zur Lösung anderer Probleme zu nutzen.
Was kann in diesem Fall konkret getan werden:
- Sammeln Sie eine Stichprobe von 100 Beispielen aus dem Entwickler-Set, die Ihr System falsch klassifiziert hat. Das sind Beispiele, bei denen Ihr System einen Fehler gemacht hat.
- Studieren Sie diese Beispiele und berechnen Sie, wie viel vom Bild des Hundes ist.
Der Prozess der Untersuchung von Beispielen, bei denen der Klassifikator einen Fehler gemacht hat, wird als "Fehleranalyse" bezeichnet. Angenommen, Sie stellen in diesem Beispiel fest, dass nur 5% der falsch klassifizierten Bilder Hunde sind. Unabhängig davon, wie stark Sie die Leistung Ihres Algorithmus für Hundebilder verbessern, können Sie keine bessere Qualität als 5% Ihrer Fehlerrate erzielen . Mit anderen Worten, 5% ist die „Obergrenze“ (impliziert die höchstmögliche Anzahl), soweit die erwartete Verbesserung helfen kann. Wenn Ihr Gesamtsystem derzeit eine Genauigkeit von 90% (10% Fehler) aufweist, ist diese Verbesserung möglich. Im besten Fall wird das Ergebnis auf 90,5% Genauigkeit verbessert (oder die Fehlerrate beträgt 9,5%, was 5% weniger als das Original ist 10% der Fehler)
Wenn Sie im Gegenteil feststellen, dass 50% der Fehler Hunde sind, können Sie sicherer sein, dass das vorgeschlagene Projekt zur Verbesserung des Systems große Auswirkungen hat. Es könnte die Genauigkeit von 90% auf 95% erhöhen (50% relative Fehlerreduzierung von 10% auf 5%)
Mit diesem einfachen Bewertungsverfahren für die Fehleranalyse können Sie die möglichen Vorteile der Implementierung einer Software zur Klassifizierung von Hundebildern von Drittanbietern schnell bewerten. Es bietet eine quantitative Bewertung für die Entscheidung, ob es ratsam ist, Zeit in die Umsetzung zu investieren.
Eine Fehleranalyse kann oft helfen zu verstehen, wie vielversprechend die verschiedenen Richtungen für die zukünftige Arbeit sind. Ich habe festgestellt, dass viele Ingenieure nur ungern Fehler analysieren. Es scheint oft aufregender, sich einfach auf eine Idee einzulassen, als herauszufinden, ob die Idee die Zeit wert ist, die sie in Anspruch nehmen wird. Dies ist ein häufiger Fehler: Dies kann dazu führen, dass Ihr Team einen Monat damit verbringt, zu verstehen, dass das Ergebnis eine vernachlässigbare Verbesserung darstellt.
Die manuelle Überprüfung von 100 Beispielen aus der Stichprobe dauert nicht lange. Selbst wenn Sie eine Minute mit dem Bild verbringen, dauert die gesamte Überprüfung weniger als 2 Stunden. Diese zwei Stunden können Ihnen einen Monat unnötiger Mühe ersparen.
Fortsetzung