Im Fall der Microservice-Organisation der Anwendung beruht ein erheblicher Arbeitsaufwand auf den Mechanismen der Integrationsverbindung von Microservices. Darüber hinaus sollte diese Integration fehlertolerant sein und einen hohen Grad an Verfügbarkeit aufweisen.
In unseren Lösungen verwenden wir die Integration mit Kafka, gRPC und RabbitMQ.
In diesem Artikel werden wir unsere Erfahrungen mit dem Clustering von RabbitMQ teilen, dessen Knoten auf Kubernetes gehostet werden.

Vor RabbitMQ Version 3.7 war das Clustering in K8S keine sehr triviale Aufgabe, mit vielen Hacks und nicht sehr schönen Lösungen. In Version 3.6 wurde ein Autocluster-Plugin von RabbitMQ Community verwendet. Und in 3.7 erschien das Kubernetes Peer Discovery Backend. Es ist durch das Plug-In in der Basisauslieferung von RabbitMQ integriert und erfordert keine separate Montage und Installation.
Wir werden die endgültige Konfiguration als Ganzes beschreiben und kommentieren, was passiert.
In der Theorie
Das Plugin verfügt über ein
Repository auf dem Github , in dem es
ein Beispiel für die grundlegende Verwendung gibt .
Dieses Beispiel ist nicht für die Produktion gedacht, was in seiner Beschreibung klar angegeben ist, und außerdem sind einige der darin enthaltenen Einstellungen entgegen der Verwendungslogik im Produkt festgelegt. In diesem Beispiel wird die Persistenz des Speichers überhaupt nicht erwähnt, sodass sich unser Cluster in jeder Notsituation in einen Zilch verwandelt.
In der Praxis
Jetzt erfahren Sie, was Sie selbst gesehen haben und wie Sie RabbitMQ installieren und konfigurieren.
Beschreiben wir die Konfigurationen aller Teile von RabbitMQ als Service in K8s. Wir werden sofort klarstellen, dass wir RabbitMQ in K8s als StatefulSet installiert haben. Auf jedem Knoten des K8s-Clusters funktioniert immer eine Instanz von RabbitMQ (ein Knoten in der klassischen Clusterkonfiguration). Wir werden auch das RabbitMQ-Control Panel in K8s installieren und Zugriff auf dieses Panel außerhalb des Clusters gewähren.
Rechte und Rollen:
rabbitmq_rbac.yaml--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-reader
Die Zugriffsrechte für RabbitMQ stammen vollständig aus dem Beispiel, es sind keine Änderungen erforderlich. Wir erstellen ein ServiceAccount für unseren Cluster und erteilen ihm Endberechtigungen für Endpoints K8s.
Dauerhafte Speicherung:
rabbitmq_pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"
Hier haben wir den einfachsten Fall als persistenten Speicher genommen - hostPath (ein regulärer Ordner auf jedem K8s-Knoten), aber Sie können jeden der vielen Arten von persistenten Volumes verwenden, die von K8s unterstützt werden.
rabbitmq_pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10Gi
Volume erstellen Anspruch auf das im vorherigen Schritt erstellte Volume. Dieser Anspruch wird dann in StatefulSet als persistenter Datenspeicher verwendet.
Dienstleistungen:
rabbitmq_service.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmq
Wir erstellen einen internen Headless-Service, über den das Peer Discovery-Plugin funktioniert.
rabbitmq_service_ext.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmq
Damit Anwendungen in K8s mit unserem Cluster funktionieren, erstellen wir einen Balancer-Service.
Da wir außerhalb von K8s Zugriff auf den RabbitMQ-Cluster benötigen, rollen wir über NodePort. RabbitMQ ist verfügbar, wenn auf einen beliebigen Knoten des K8s-Clusters an den Ports 31673 und 30673 zugegriffen wird. In der Praxis besteht hierfür kein großer Bedarf. Die Frage nach der Benutzerfreundlichkeit des RabbitMQ-Admin-Panels.
Beim Erstellen eines Dienstes mit dem NodePort-Typ in K8s wird implizit auch ein Dienst mit dem ClusterIP-Typ erstellt, um ihn bereitzustellen. Daher können Anwendungen in K8s, die mit unserem RabbitMQ arbeiten müssen, unter
amqp: // rabbitmq: 5672 auf den Cluster
zugreifenKonfiguration:
rabbitmq_configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Wir erstellen RabbitMQ-Konfigurationsdateien. Die Hauptmagie.
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s].
Fügen Sie die erforderlichen Plugins zu den zum Herunterladen zugelassenen hinzu. Jetzt können wir die automatische Peer Discovery im K8S verwenden.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
Wir stellen das erforderliche Plugin als Backend für die Peer-Erkennung zur Verfügung.
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443
Geben Sie die Adresse und den Port an, über die Sie kubernetes apiserver erreichen können. Hier können Sie die IP-Adresse direkt angeben, aber es ist schöner, dies zu tun.
In der Standardeinstellung für Namespaces wird normalerweise ein Dienst mit dem Namen kubernetes erstellt, der zu k8-apiserver führt. In verschiedenen K8S-Installationsoptionen können Namespace, Dienstname und Port unterschiedlich sein. Wenn etwas in einer bestimmten Installation anders ist, müssen Sie es entsprechend beheben.
Zum Beispiel sind wir mit der Tatsache konfrontiert, dass sich der Dienst in einigen Clustern auf Port 443 und in einigen auf 6443 befindet. Es ist möglich zu verstehen, dass in den RabbitMQ-Startprotokollen etwas nicht stimmt. Die Verbindungszeit zu der hier angegebenen Adresse ist dort deutlich hervorgehoben.
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname
Standardmäßig wurde im Beispiel der Adresstyp des RabbitMQ-Clusterknotens nach IP-Adresse angegeben. Wenn Sie den Pod jedoch neu starten, erhält er jedes Mal eine neue IP. Überraschung! Der Cluster stirbt vor Qual.
Ändern Sie die Adressierung in Hostname. StatefulSet garantiert uns die Unveränderlichkeit des Hostnamens innerhalb des Lebenszyklus des gesamten StatefulSet, was vollständig zu uns passt.
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true
Wenn wir davon ausgehen, dass einer der Knoten früher oder später wiederhergestellt wird, deaktivieren wir die Selbstlöschung durch einen Cluster unzugänglicher Knoten. In diesem Fall tritt der Knoten, sobald er online ist, in den Cluster ein, ohne seinen vorherigen Status zu verlieren.
cluster_partition_handling = autoheal
Dieser Parameter bestimmt die Aktionen des Clusters bei Verlust des Quorums. Hier müssen Sie nur die
Dokumentation zu diesem Thema lesen und selbst verstehen, was einem bestimmten Anwendungsfall näher kommt.
queue_master_locator=min-masters
Bestimmen Sie die Assistentenauswahl für neue Warteschlangen. Mit dieser Einstellung wählt der Assistent den Knoten mit der geringsten Anzahl von Warteschlangen aus, sodass die Warteschlangen gleichmäßig auf die Clusterknoten verteilt werden.
cluster_formation.k8s.service_name = rabbitmq-internal
Wir nennen den kopflosen K8-Dienst (von uns zuvor erstellt), über den die RabbitMQ-Knoten miteinander kommunizieren.
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Eine wichtige Sache für die Adressierung in einem Cluster ist der Hostname. Der FQDN des K8-Herdes wird als Kurzname (rabbitmq-0, rabbitmq-1) + Suffix (Domänenteil) gebildet. Hier geben wir dieses Suffix an. In K8S sieht es so aus
: <Dienstname>. <Namespace-Name> .svc.cluster.localkube-dns löst Namen der Form rabbitmq-0.rabbitmq-internal.our-namespace.svc.cluster.local ohne zusätzliche Konfiguration in die IP-Adresse eines bestimmten Pods auf, wodurch die Magie des Clustering nach Hostnamen möglich wird.
StatefulSet RabbitMQ-Konfiguration:
rabbitmq_statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Eigentlich StatefulSet selbst. Wir stellen interessante Punkte fest.
serviceName: rabbitmq-internal
Wir schreiben den Namen des kopflosen Dienstes, über den Pods in StatefulSet kommunizieren.
replicas: 3
Legen Sie die Anzahl der Replikate im Cluster fest. In unserem Land entspricht dies der Anzahl der K8-Arbeitsknoten.
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }
Wenn einer der K8s-Knoten ausfällt, versucht das Statefulset, die Anzahl der Instanzen in der Menge beizubehalten. Daher werden mehrere Herde auf demselben K8s-Knoten erstellt. Dieses Verhalten ist völlig unerwünscht und grundsätzlich sinnlos. Daher schreiben wir eine Anti-Affinitätsregel für Herd-Sets von Statefulset vor. Wir machen die Regel hart (Erforderlich), damit der Kube-Scheduler sie bei der Planung von Pods nicht brechen kann.
Das Wesentliche ist einfach: Es ist dem Scheduler untersagt, (innerhalb des Namespace) mehr als einen Pod mit dem
Tag app: rabbitmq auf jedem Knoten zu platzieren. Wir unterscheiden die
Knoten durch den Wert der Bezeichnung
kubernetes.io/hostname . Wenn nun aus irgendeinem Grund die Anzahl der funktionierenden K8S-Knoten geringer ist als die erforderliche Anzahl von Replikaten in StatefulSet, werden neue Replikate erst erstellt, wenn wieder ein freier Knoten angezeigt wird.
serviceAccountName: rabbitmq
Wir registrieren ServiceAccount, unter dem unsere Pods arbeiten.
image: rabbitmq:3.7
Das Image von RabbitMQ ist vollständig Standard und stammt aus dem Docker-Hub. Es erfordert keine Neuerstellung und Dateirevision.
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia
Persistente Daten von RabbitMQ werden in / var / lib / rabbitmq / mnesia gespeichert. Hier stellen wir unseren Persistent Volume Claim in diesen Ordner, damit beim Neustart der Herde / Knoten oder sogar des gesamten StatefulSet die Daten (sowohl der Dienst, einschließlich des zusammengestellten Clusters, als auch die Benutzerdaten) sicher und zuverlässig sind. Es gibt einige Beispiele, bei denen der gesamte Ordner / var / lib / rabbitmq / persistent gemacht wird. Wir kamen zu dem Schluss, dass dies nicht die beste Idee ist, da gleichzeitig alle von den Kaninchenkonfigurationen gesetzten Informationen in Erinnerung bleiben. Das heißt, um etwas in der Konfigurationsdatei zu ändern, müssen Sie den persistenten Speicher bereinigen, was im Betrieb sehr unpraktisch ist.
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local"
Mit diesem Satz von Umgebungsvariablen weisen wir RabbitMQ zunächst an, den FQDN-Namen als Kennung für die Clustermitglieder zu verwenden, und zweitens legen wir das Format dieses Namens fest. Das Format wurde bereits beim Parsen der Konfiguration beschrieben.
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"
Der Name des kopflosen Dienstes für die Kommunikation zwischen Clustermitgliedern.
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"
Der Inhalt des Erlang-Cookies sollte auf allen Knoten des Clusters gleich sein. Sie müssen Ihren eigenen Wert registrieren. Ein Knoten mit einem anderen Cookie kann den Cluster nicht betreten.
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Definieren Sie das zugeordnete Volume aus dem zuvor erstellten Persistent Volume Claim.
Hier sind wir mit dem Setup in den K8 fertig. Das Ergebnis ist ein RabbitMQ-Cluster, der die Warteschlangen gleichmäßig auf die Knoten verteilt und gegen Probleme in der Laufzeitumgebung resistent ist.
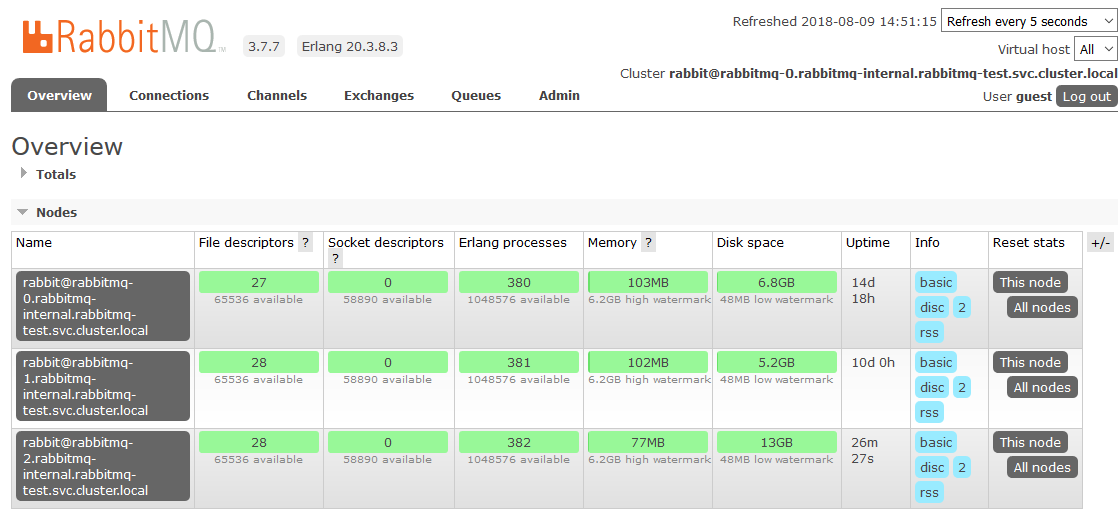
Wenn einer der Clusterknoten nicht verfügbar ist, ist der Zugriff auf die darin enthaltenen Warteschlangen nicht mehr möglich, alles andere funktioniert weiterhin. Sobald der Knoten wieder in Betrieb ist, kehrt er zum Cluster zurück, und die Warteschlangen, für die er ein Master war, werden wieder betriebsbereit, wobei alle darin enthaltenen Daten erhalten bleiben (wenn der persistente Speicher natürlich nicht beschädigt wurde). Alle diese Prozesse sind vollautomatisch und erfordern kein Eingreifen.
Bonus: HA anpassen
Eines der Projekte war eine Nuance. Die Anforderungen ergaben eine vollständige Spiegelung aller im Cluster enthaltenen Daten. Dies ist erforderlich, damit in einer Situation, in der mindestens ein Clusterknoten betriebsbereit ist, aus Sicht der Anwendung weiterhin alles funktioniert. Dieser Moment hat nichts mit K8s zu tun, wir beschreiben ihn einfach als Mini-How-to.
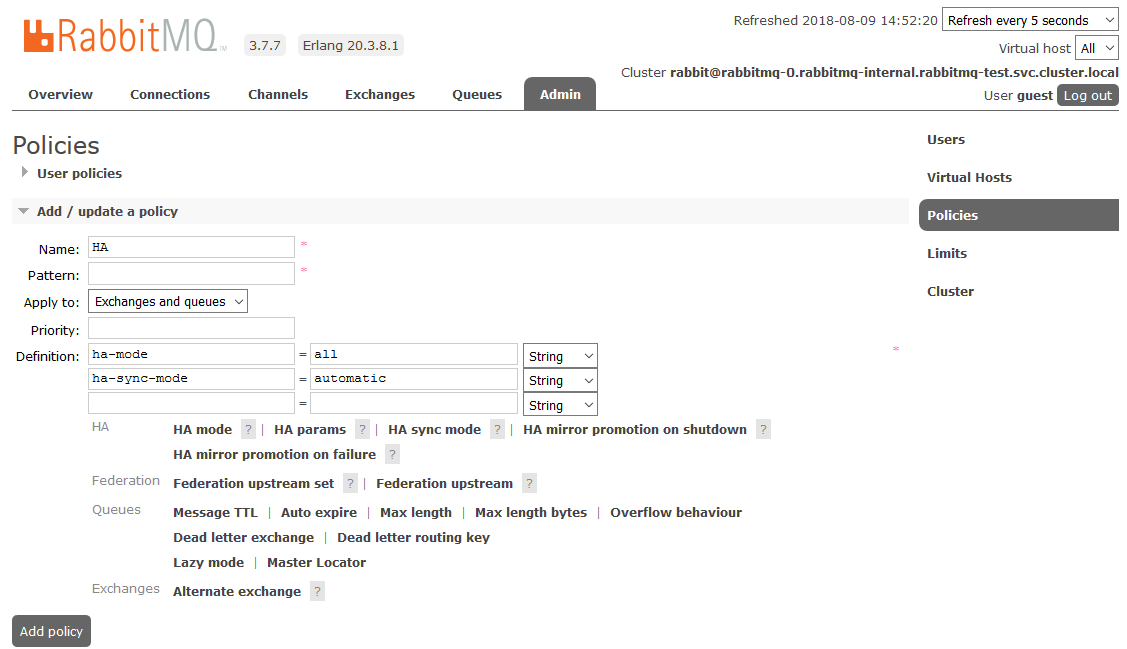
Um die vollständige HA zu aktivieren, müssen Sie im RabbitMQ-Dashboard auf der Registerkarte
Admin -> Richtlinien eine Richtlinie erstellen. Der Name ist beliebig, das Muster ist leer (alle Warteschlangen), in den Definitionen werden zwei Parameter hinzugefügt:
ha-Modus: alle ,
ha-Sync-Modus: automatisch .
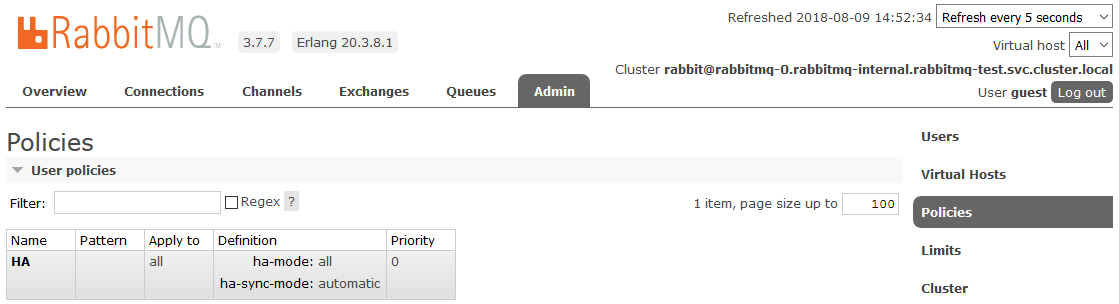
Danach befinden sich alle im Cluster erstellten Warteschlangen im Hochverfügbarkeitsmodus: Wenn der Masterknoten nicht verfügbar ist, wird einer der Slaves vom neuen Assistenten automatisch ausgewählt. Die in die Warteschlange eingehenden Daten werden auf alle Knoten des Clusters gespiegelt. Was in der Tat erforderlich war, um zu erhalten.
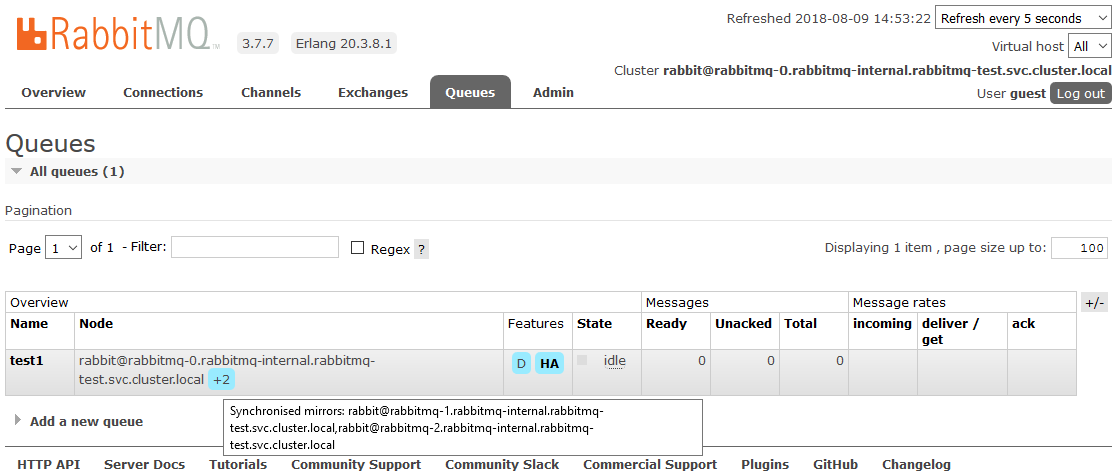
Lesen Sie hier mehr über HA in RabbitMQ
Nützliche Literatur:
Viel Glück!