Im Unternehmen wird unser Team zur Abwehr von DDoS-Angriffen als "Packet Dropper" bezeichnet. Während alle anderen Teams coole Dinge mit dem Verkehr tun, der durch unser Netzwerk fließt, haben wir Spaß daran, neue Wege zu finden, um ihn loszuwerden.
 Foto: Brian Evans , CC BY-SA 2.0
Foto: Brian Evans , CC BY-SA 2.0Die Fähigkeit, Pakete schnell zu verwerfen, ist sehr wichtig, um DDoS-Angriffen entgegenzuwirken.
Drop-Pakete, die unsere Server erreichen, können auf mehreren Ebenen ausgeführt werden. Jede Methode hat ihre Vor- und Nachteile. Unter dem Schnitt schauen wir uns alles an, was wir getestet haben.
Anmerkung des Übersetzers: In der Ausgabe einiger der vorgestellten Befehle wurden zusätzliche Leerzeichen entfernt, um die Lesbarkeit zu gewährleisten.
Teststelle
Um den Vergleich der Methoden zu vereinfachen, stellen wir Ihnen einige Zahlen zur Verfügung. Nehmen Sie diese jedoch aufgrund der Künstlichkeit der Tests nicht zu wörtlich. Wir werden eine unserer Intel 10Gb / s-Netzwerkkarten verwenden. Die verbleibenden Servereigenschaften sind nicht so wichtig, da wir uns auf die Einschränkungen des Betriebssystems konzentrieren möchten, nicht auf die Hardware.
Unsere Tests werden wie folgt aussehen:
- Wir erstellen eine große Anzahl kleiner UDP-Pakete, die einen Wert von 14 Millionen Paketen pro Sekunde erreichen.
- Der gesamte Datenverkehr wird an einen Prozessorkern des ausgewählten Servers geleitet.
- Wir messen die Anzahl der vom Kernel verarbeiteten Pakete auf einem einzelnen Prozessorkern.
Künstlicher Verkehr wird so erzeugt, dass eine maximale Last entsteht: Zufällige IP-Adresse und Absenderport werden verwendet. So sieht es in tcpdump aus:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
Auf dem ausgewählten Server befinden sich alle Pakete in einer Empfangswarteschlange und werden daher von einem Kern verarbeitet. Dies erreichen wir mit der Hardware-Flusskontrolle:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Leistungstests sind ein komplexer Prozess. Bei der Vorbereitung der Tests haben wir festgestellt, dass das Vorhandensein aktiver Raw-Sockets die Leistung negativ beeinflusst. Bevor Sie die Tests ausführen, müssen Sie sicherstellen, dass kein
tcpdump wird. Es gibt eine einfache Möglichkeit, nach schlechten Prozessen zu suchen:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
Und schließlich schalten wir Intel Turbo Boost auf unserem Server aus:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Trotz der Tatsache, dass Turbo Boost eine großartige Sache ist und den Durchsatz um mindestens 20% erhöht, wird die Standardabweichung in unseren Tests erheblich beeinträchtigt. Bei eingeschaltetem Turbo erreicht die Abweichung ± 1,5%, ohne sie nur 0,25%.
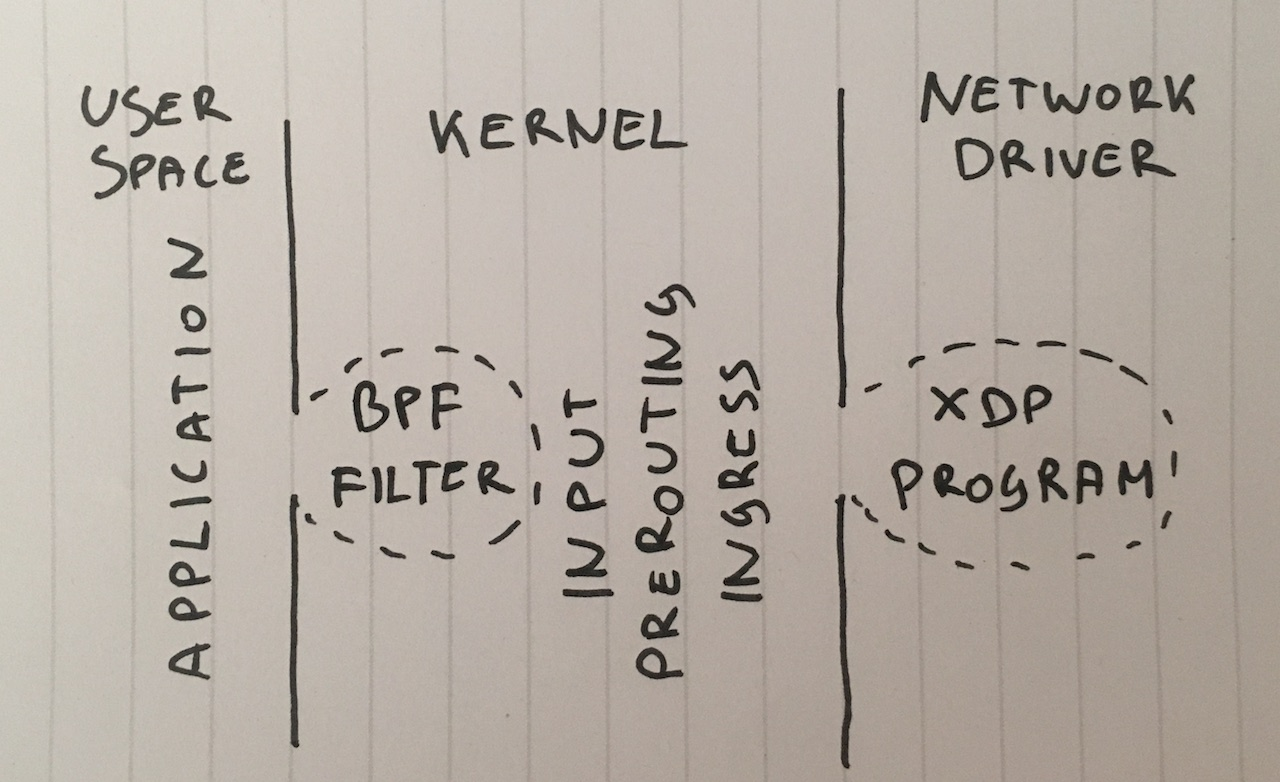
Schritt 1. Verwerfen Sie Pakete in der Anwendung
Beginnen wir mit der Idee, alle Pakete an die Anwendung zu liefern und dort zu ignorieren. Stellen Sie zur Ehrlichkeit des Experiments sicher, dass iptables die Leistung in keiner Weise beeinträchtigt:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
Die Anwendung ist ein einfacher Zyklus, in dem die empfangenen Daten sofort verworfen werden:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
Wir haben den
Code bereits vorbereitet, führen Sie aus:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
Diese Lösung ermöglicht es dem Kernel, nur
ethtool Pakete aus der Hardware-Warteschlange zu entnehmen, wie vom
ethtool und
unseren mmwatch gemessen wurde:
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
Technisch gesehen kommen 14 Millionen Pakete pro Sekunde auf dem Server an, jedoch kann ein Prozessorkern ein solches Volumen nicht bewältigen.
mpstat bestätigt dies:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Wie wir sehen können, ist die Anwendung kein Engpass: CPU # 1 wird mit 27,17% + 2,17% verwendet, während die Interrupt-Behandlung 100% auf CPU # 2 beansprucht.
Die Verwendung von
recvmessagge(2) spielt eine wichtige Rolle. Nachdem die Spectre-Sicherheitsanfälligkeit entdeckt wurde, wurden Systemaufrufe aufgrund des im Kernel verwendeten
KPTI und der
Retpoline noch teurer
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
Schritt 2. Conntrack töten
Wir haben eine solche Last speziell mit unterschiedlichen IP- und Absenderports erstellt, um so viel wie möglich Conntrack zu laden. Die Anzahl der Einträge in conntrack während des Tests ist maximal und wir können dies überprüfen:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
Darüber hinaus können Sie in
dmesg auch Conntrack-Schreie sehen:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
Schalten wir es also aus:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Und starten Sie die Tests neu:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
Dadurch konnten wir die Marke von 333.000 Paketen pro Sekunde erreichen. Hurra!
PS Mit SO_BUSY_POLL können wir bis zu 470.000 pro Sekunde erreichen. Dies ist jedoch ein Thema für einen separaten Beitrag.
Schritt 3. Berkeley Batch Filter
Lass uns weitermachen. Warum müssen wir Pakete an die Anwendung liefern? Obwohl dies keine übliche Lösung ist, können wir den klassischen Berkeley-Paketfilter an den Socket binden, indem
setsockopt(SO_ATTACH_FILTER) und den Filter so konfigurieren, dass Pakete zurück in den Kernel fallen.
Bereiten Sie den
Code vor und führen Sie Folgendes aus:
$ ./bpf-drop packets=0 bytes=0
Mit einem Paketfilter (klassische und erweiterte Berkeley-Filter bieten eine ungefähr ähnliche Leistung) erreichen wir ungefähr 512.000 Pakete pro Sekunde. Darüber hinaus befreit das Verwerfen eines Pakets während eines Interrupts den Prozessor davon, die Anwendung aufwecken zu müssen.
Schritt 4. iptables DROP nach dem Routing
Jetzt können wir Pakete verwerfen, indem wir iptables in der INPUT-Kette die folgende Regel hinzufügen:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Ich möchte Sie daran erinnern, dass wir conntrack bereits mit der
-j NOTRACK Regel
-j NOTRACK . Diese beiden Regeln geben uns 608.000 Pakete pro Sekunde.
Schauen wir uns die Zahlen in iptables an:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Nicht schlecht, aber wir können es besser machen.
Schritt 5. iptabes DROP in PREROUTING
Eine schnellere Methode besteht darin, Pakete vor dem Routing mit dieser Regel zu verwerfen:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Dies ermöglicht es uns, beträchtliche 1,688 Millionen Pakete pro Sekunde zu verwerfen.
In der Tat ist dies ein etwas überraschender Leistungssprung. Ich verstehe die Gründe immer noch nicht, vielleicht ist unser Routing kompliziert oder nur ein Fehler in der Serverkonfiguration.
In jedem Fall sind rohe Iptables viel schneller.
Schritt 6. nftables DROP
Das Dienstprogramm iptables ist jetzt etwas alt. Sie wurde durch Nftables ersetzt. Schauen Sie sich
diese Video-Erklärung an, warum nftables top ist. Nftables verspricht aus verschiedenen Gründen schneller zu sein als grau werdende Iptables, einschließlich Gerüchten, dass Retpolinen Iptables stark verlangsamen.
In unserem Artikel geht es jedoch immer noch nicht um den Vergleich von iptables und nftables. Versuchen wir also einfach das schnellste, was ich tun kann:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Zähler können so gesehen werden:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
Der nftables-Eingabehaken zeigte Werte von ungefähr 1,53 Millionen Paketen. Dies ist etwas weniger als die PREROUTING-Kette in iptables. Dies ist jedoch ein Rätsel: Theoretisch geht der nftables-Hook früher als PREROUTING iptables und sollte daher schneller verarbeitet werden.
In unserem Test ist nftables etwas langsamer als iptables, aber nftables sind trotzdem cooler. : P.
Schritt 7. tc DROP
Etwas unerwartet tritt der tc-Haken (Traffic Control) früher auf als iptables PREROUTING. Mit tc können wir Pakete nach einfachen Kriterien auswählen und natürlich verwerfen. Die Syntax ist etwas ungewöhnlich, daher empfehlen wir,
dieses Skript für die Konfiguration zu verwenden. Und wir brauchen eine ziemlich komplizierte Regel, die so aussieht:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Und wir können es in Aktion überprüfen:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
Mit dem TC-Hook konnten wir bis zu 1,8 Millionen Pakete pro Sekunde auf einem einzigen Kern ablegen. Das ist großartig!
Aber wir können es noch schneller machen ...
Schritt 8. XDP_DROP
Und schließlich unsere stärkste Waffe: XDP -
eXpress Data Path . Mit XDP können wir den erweiterten eBPF-Code (Berkley Packet Filter) direkt im Kontext des Netzwerktreibers und vor allem noch vor der Zuweisung von Speicher für
skbuff , was uns eine Erhöhung der Geschwindigkeit verspricht.
In der Regel besteht ein XDP-Projekt aus zwei Teilen:
- Herunterladbarer eBPF-Code
- Bootloader, der Code in die richtige Netzwerkschnittstelle einfügt
Das Schreiben Ihres Bootloaders ist eine schwierige Aufgabe. Verwenden Sie einfach den
neuen iproute2-Chip und laden Sie den Code mit einem einfachen Befehl:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Ta Dam!
Den Quellcode für das
herunterladbare eBPF-Programm finden Sie hier . Das Programm untersucht Eigenschaften von IP-Paketen wie das UDP-Protokoll, das Absendersubnetz und den Zielport:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
Das XDP-Programm muss mit modernem Clang erstellt werden, der BPF-Bytecode generieren kann. Danach können wir die Funktionalität des BFP-Programms herunterladen und testen:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
Und dann sehen Sie sich die Statistiken in
ethtool :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
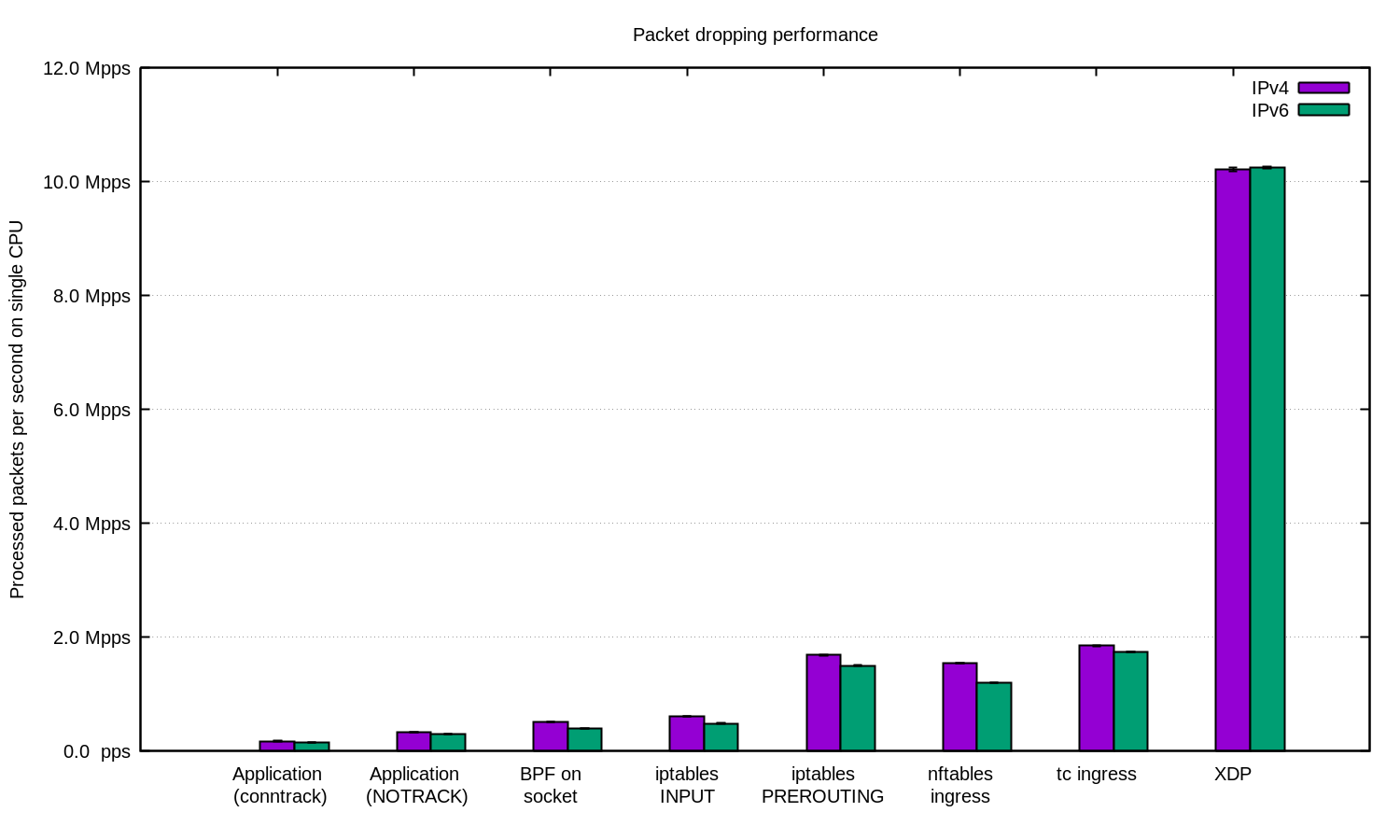
Yoo hoo! Mit XDP können wir bis zu 10 Millionen Pakete pro Sekunde verwerfen!
 Foto: Andrew Filer , CC BY-SA 2.0
Foto: Andrew Filer , CC BY-SA 2.0Schlussfolgerungen
Wir haben das Experiment für IPv4 und IPv6 wiederholt und dieses Diagramm erstellt:
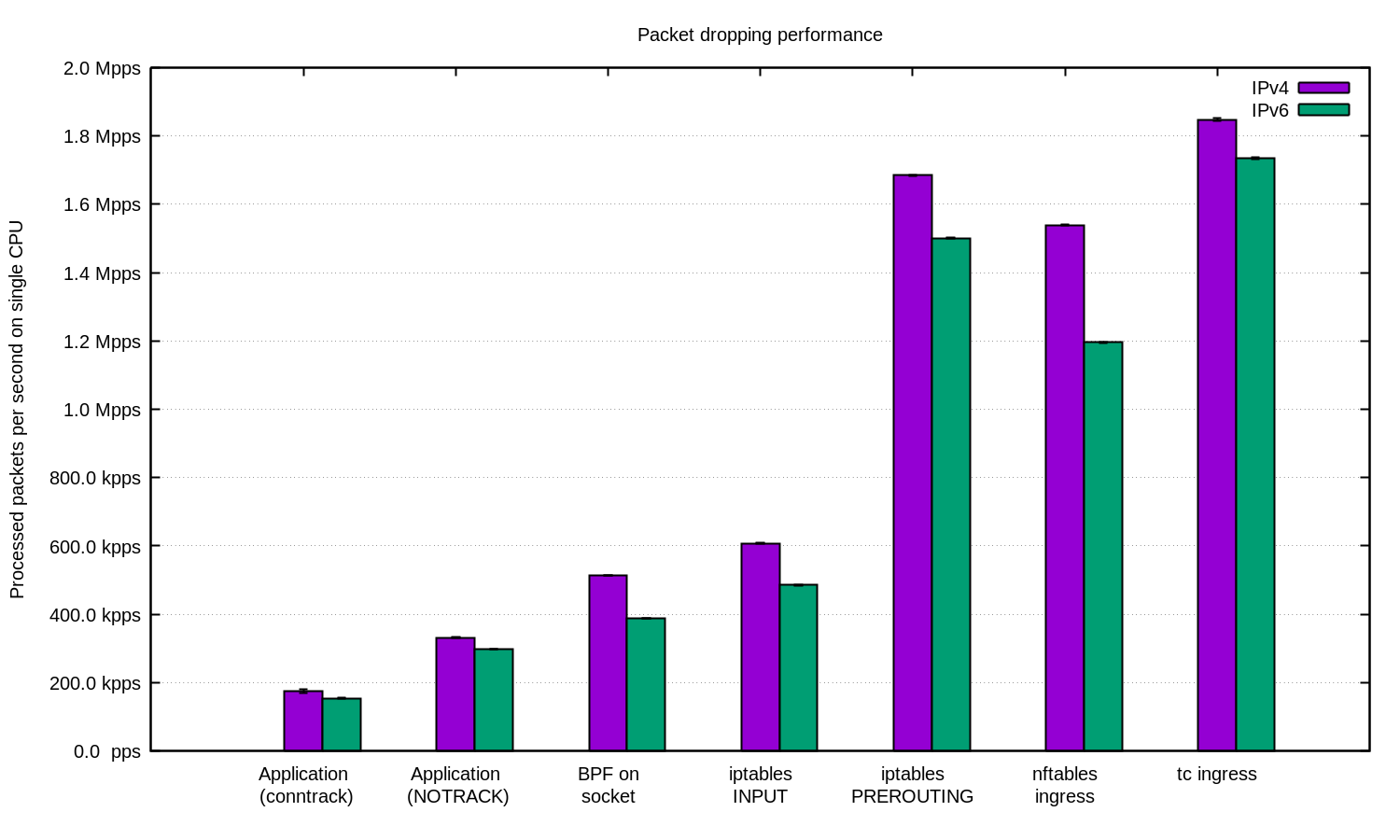
Im Allgemeinen kann argumentiert werden, dass unser Setup für IPv6 etwas langsamer ist. Da IPv6-Pakete jedoch etwas größer sind, wird ein Geschwindigkeitsunterschied erwartet.
Linux hat viele Möglichkeiten, Pakete zu filtern, jedes mit seiner eigenen Geschwindigkeit und Komplexität.
Zum Schutz vor DDoS ist es durchaus sinnvoll, der Anwendung Pakete zu geben und diese dort zu verarbeiten. Eine gut abgestimmte Anwendung kann gute Ergebnisse zeigen.
Bei DDoS-Angriffen mit zufälliger oder gefälschter IP kann es nützlich sein, conntrack zu deaktivieren, um die Geschwindigkeit geringfügig zu erhöhen. Seien Sie jedoch vorsichtig: Es gibt Angriffe, gegen die conntrack sehr nützlich ist.
In anderen Fällen ist es sinnvoll, die Linux-Firewall hinzuzufügen, um den DDoS-Angriff abzuschwächen. In einigen Fällen ist es besser, die Tabelle "-t raw PREROUTING" zu verwenden, da sie viel schneller als die Filtertabelle ist.
In den fortgeschrittensten Fällen verwenden wir immer XDP. Und ja, das ist eine sehr mächtige Sache. Hier ist eine Grafik wie oben, nur mit XDP:
Wenn Sie das Experiment wiederholen möchten, finden Sie hier die
README-Datei, in der wir alles dokumentiert haben .
Wir bei CloudFlare verwenden ... fast alle diese Techniken. Einige Tricks im Benutzerbereich sind in unsere Anwendungen integriert. Die iptables-Technik finden Sie in unserem
Gatebot . Schließlich ersetzen wir unsere eigene Kernlösung durch XDP.
Vielen Dank an
Jesper Dangaard Brouer für ihre Hilfe.