Um den
Artikel über die Gefahren einer übermäßigen Diversifizierung fortzusetzen, werden wir nützliche Tools zur Aktienauswahl erstellen. Danach werden wir eine einfache Neuausrichtung vornehmen und die einzigartigen Bedingungen für technische Indikatoren hinzufügen, die in populären Diensten so oft fehlen. Vergleichen Sie dann die Renditen einzelner Vermögenswerte und verschiedener Portfolios.
Bei all dem verwenden wir Pandas und minimieren die Anzahl der Zyklen. Gruppieren Sie die Zeitreihen und zeichnen Sie die Grafiken. Machen wir uns mit Multi-Indizes und deren Verhalten vertraut. Und das alles in Jupyter in Python 3.6.
Wenn Sie etwas gut machen wollen, machen Sie es selbst.
Ferdinand Porsche
Mit dem beschriebenen Tool können Sie die optimalen Assets für das Portfolio auswählen und die von Beratern auferlegten Tools ausschließen. Aber wir werden nur das große Ganze sehen - ohne Berücksichtigung der Liquidität, der Zeit für die Rekrutierung von Positionen, der Maklerprovisionen und der Kosten für eine Aktie. Im Allgemeinen sind bei einer monatlichen oder jährlichen Neuausrichtung großer Broker die Kosten unbedeutend. Vor der Anwendung sollte die gewählte Strategie jedoch noch im ereignisgesteuerten Backtester, z. B. Quantopian (QP), überprüft werden, um mögliche Fehler zu beseitigen.
Warum nicht sofort in QP? Zeit. Dort dauert der einfachste Test ca. 5 Minuten. Mit der aktuellen Lösung können Sie in einer Minute Hunderte verschiedener Strategien mit einzigartigen Bedingungen überprüfen.
Laden von Rohdaten
Verwenden Sie zum Laden der Daten die in diesem
Artikel beschriebene Methode. Ich verwende PostgreSQL, um Tagespreise zu speichern, aber jetzt ist es voll von kostenlosen Quellen, aus denen Sie den erforderlichen DataFrame erstellen können.
Der Code zum Herunterladen des Preisverlaufs aus der Datenbank ist im Repository verfügbar. Der Link befindet sich am Ende des Artikels.
DataFrame-Struktur
Wenn Sie mit der Preishistorie arbeiten, können Sie für eine bequeme Gruppierung und den Zugriff auf alle Daten am besten einen Multi-Index (MultiIndex) mit Datum und Tickern verwenden.
df = df.set_index(['dt', 'symbol'], drop=False).sort_index() df.tail(len(df.index.levels[1]) * 2)
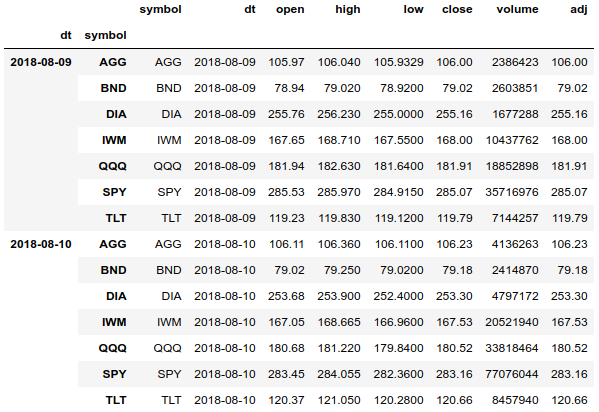
Mithilfe eines Multi-Index können wir problemlos auf die gesamte Preishistorie für alle Assets zugreifen und das Array getrennt nach Datum und Asset gruppieren. Wir können auch die Preishistorie für einen Vermögenswert abrufen.
Hier ist ein Beispiel dafür, wie Sie den Verlauf einfach nach Woche, Monat und Jahr gruppieren können. Und um all dies auf Grafiken der Pandas zu zeigen:
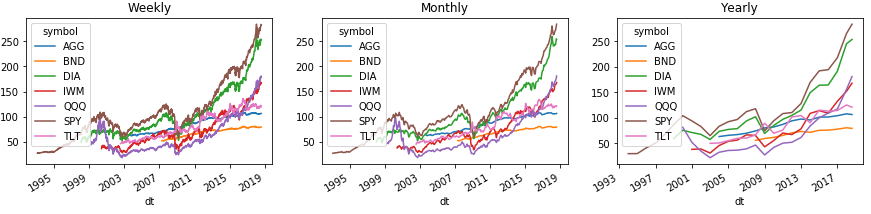
Um den Bereich mit der Diagrammlegende korrekt anzuzeigen, übertragen wir die Indexebene mit Tickern mit dem Befehl Series (). Unstack (1) auf die zweite Ebene über den Spalten. Mit DataFrame () funktioniert eine solche Nummer nicht, aber die Lösung ist unten.
Bei der Gruppierung nach Standardperioden verwendet Pandas das neueste Kalenderdatum der Gruppe im Index, das häufig von den tatsächlichen Daten abweicht. Um dies zu beheben, aktualisieren Sie den Index.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \ .set_index(['dt', 'symbol'], drop=False)
Ein Beispiel für die Ermittlung des Preisverlaufs eines bestimmten Vermögenswerts (wir nehmen alle Daten, den QQQ-Ticker und alle Spalten):
monthly.loc[(slice(None), ['QQQ']), :]
Monatliche Volatilität der Vermögenswerte
Jetzt können wir uns in einigen Zeilen des Diagramms die Änderung des Preises jedes Vermögenswerts für den für uns interessanten Zeitraum ansehen. Zu diesem Zweck erhalten wir den Prozentsatz der Preisänderungen, indem wir den Datenrahmen mit einem Asset-Ticker nach Multi-Index-Ebene gruppieren.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg( agg_rules).set_index(['dt', 'symbol'], drop=False)
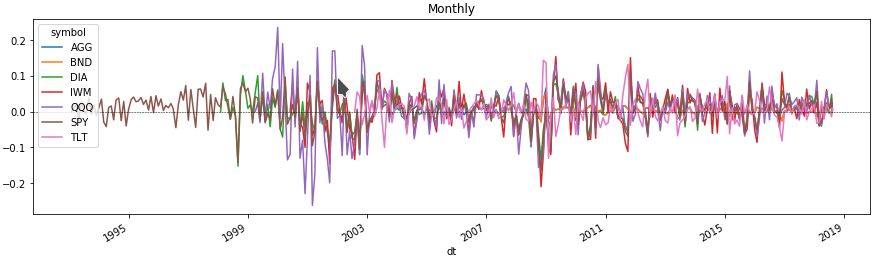
Vergleichen Sie die Anlagenrenditen
Jetzt verwenden wir die Fenstermethode Series (). Rolling () und zeigen die Kapitalrendite für einen bestimmten Zeitraum an:
Python-Code rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod)
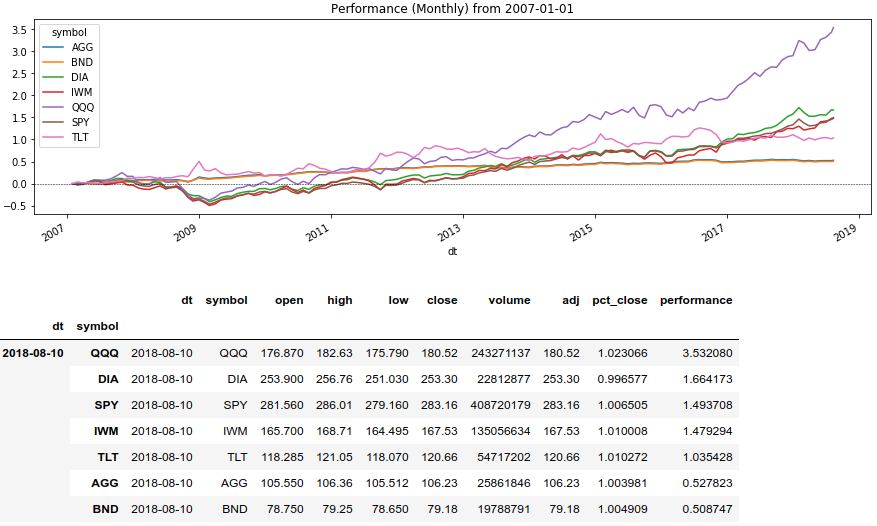
Methoden zur Neuausrichtung des Portfolios
Also kamen wir zum leckersten. In den Beispielen werden wir die Ergebnisse des Portfolios bei der Aufteilung des Kapitals auf vorgegebene Aktien zwischen mehreren Vermögenswerten betrachten. Fügen Sie außerdem einzigartige Bedingungen hinzu, unter denen wir einige Vermögenswerte zum Zeitpunkt der Kapitalverteilung aufgeben werden. Wenn keine geeigneten Vermögenswerte vorhanden sind, gehen wir davon aus, dass der Broker das Kapital im Cache hat.
Um Pandas-Methoden für die Neuverteilung zu verwenden, müssen die Verteilungsfreigaben und die Neuausgleichsbedingungen in einem DataFrame mit gruppierten Daten gespeichert werden. Betrachten Sie nun die Neuausgleichsfunktionen, die wir an DataFrame () übergeben. Apply () -Methode:
In der Reihenfolge:
- rebalance_simple ist die einfachste Funktion, mit der die Rentabilität jedes Vermögenswerts in Aktien verteilt wird.
- rebalance_sma ist eine Funktion, die Kapital auf Vermögenswerte verteilt, deren gleitender Durchschnitt zum Zeitpunkt des Ausgleichs 50 Tage höher als 200 Tage ist.
- rebalance_rsi - eine Funktion, die Kapital auf Vermögenswerte verteilt, für die der Wert des RSI-Indikators für 100 Tage über 50 liegt.
- rebalance_custom ist die langsamste und universellste Funktion, bei der wir die Indikatorwerte aus der täglichen Vermögenspreishistorie zum Zeitpunkt des Neuausgleichs berechnen. Hier können Sie beliebige Bedingungen und Daten verwenden. Sogar jedes Mal von externen Quellen herunterladen. Auf einen Zyklus kann man aber nicht verzichten.
- Drawdown - Hilfsfunktion, die den maximalen Drawdown im Portfolio anzeigt.
In den Neuausgleichsfunktionen benötigen wir ein Array aller Daten für das Datum, aufgeschlüsselt nach Assets. Die DataFrame (). Apply () -Methode, mit der wir die Portfolioergebnisse berechnen, übergibt ein Array an unsere Funktion, wobei die Spalten zum Zeilenindex werden. Und wenn wir einen Multi-Index erstellen, bei dem die Ticker den Nullpegel bilden, kommt ein Multi-Index zu uns. Wir können diesen Multi-Index zu einem zweidimensionalen Array erweitern und die Daten des entsprechenden Assets in jeder Zeile abrufen.

Neuausrichtung des Portfolios
Jetzt reicht es aus, die erforderlichen Bedingungen vorzubereiten und für jedes Portfolio im Zyklus eine Berechnung durchzuführen. Zunächst berechnen wir die Indikatoren für die tägliche Preisentwicklung:
Jetzt werden wir die Geschichte für die gewünschte Ausgleichsperiode unter Verwendung der oben beschriebenen Methoden gruppieren. Gleichzeitig werden wir zu Beginn des Berichtszeitraums die Werte der Indikatoren heranziehen, um einen Blick in die Zukunft auszuschließen.
Wir beschreiben die Struktur der Portfolios und geben die gewünschte Neuausrichtung an. Wir werden die Portfolios in einem Zyklus berechnen, da wir eindeutige Aktien und Bedingungen angeben müssen:
Dieses Mal müssen wir einen Trick mit Spalten- und Zeilenindizes ausführen, um den gewünschten Multi-Index in der Neuausgleichsfunktion zu erhalten. Dies erreichen wir, indem wir die Methoden DataFrame (). Stack (). Unstack ([1, 2]) nacheinander aufrufen. Dieser Code überträgt die Spalten in einen Multi-Index in Kleinbuchstaben und gibt dann den Multi-Index mit Tickern und Spalten in der gewünschten Reihenfolge zurück.
Vorgefertigte Aktentaschen für Diagramme
Jetzt bleibt alles zu zeichnen. Führen Sie dazu den Portfolio-Zyklus erneut aus, in dem die Daten in den Diagrammen angezeigt werden. Am Ende werden wir SPY als Vergleichsmaßstab ziehen.
Python-Code fig = plt.figure(figsize=(15, 4), facecolor='white') ax_perf = fig.add_subplot(121) ax_dd = fig.add_subplot(122) for p in portfolios: p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance') p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
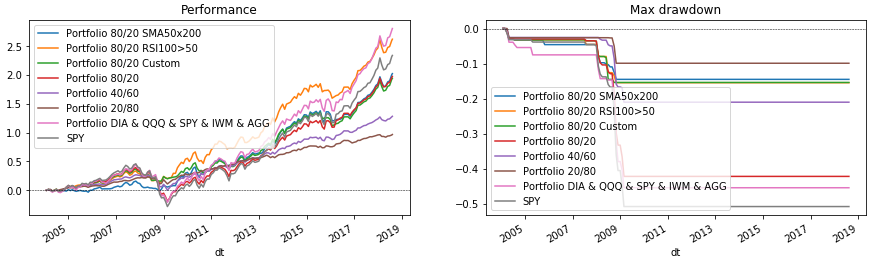
Fazit
Mit dem betrachteten Code können Sie verschiedene Portfoliostrukturen und Ausgleichsbedingungen auswählen. Mit seiner Hilfe können Sie schnell prüfen, ob es sich beispielsweise lohnt, Gold (GLD) oder Emerging Markets (EEM) in einem Portfolio zu halten. Probieren Sie es aus, fügen Sie Ihre eigenen Bedingungen für Indikatoren hinzu oder wählen Sie die bereits beschriebenen Parameter aus. (Denken Sie jedoch daran, dass der Fehler des Überlebenden und die Anpassung an frühere Daten in Zukunft möglicherweise nicht den Erwartungen entsprechen.) Und entscheiden Sie dann, wem Sie Ihr Portfolio anvertrauen - Python oder Finanzberater?
Repository:
rebalance.portfolio