
Zu unserer großen Überraschung gab es kein einziges Material über das wunderbare Open Source-Tool zur Datensicherung -
Borg (nicht zu verwechseln mit dem gleichnamigen Vorfahren Kubernetes!) . Da wir es seit mehr als einem Jahr in der Produktion verwenden, werde ich in diesem Artikel die „Eindrücke“ teilen, die wir über Borg gewonnen haben.
Hintergrund: Erfahrung mit Bacula und Bareos
Im Jahr 2017 hatten wir die Bacula und Bareos satt, die wir von Beginn unserer Tätigkeit an verwendet haben (d. H. Ungefähr 9 Jahre in der Produktion zu diesem Zeitpunkt). Warum? Während des Betriebs haben wir viel Unzufriedenheit angehäuft:
- SD (Storage Daemon) friert ein. Wenn Sie Parallelität konfiguriert haben, wird die SD-Wartung komplizierter, und das Einfrieren blockiert weitere planmäßige Sicherungen und die Möglichkeit der Wiederherstellung.
- Es ist notwendig, Konfigurationen sowohl für den Kunden als auch für den Direktor zu generieren. Selbst wenn wir dies automatisieren (in unserem Fall wurden Chef, Ansible und unsere eigene Entwicklung zu unterschiedlichen Zeiten verwendet), müssen wir überwachen, dass der Director nach seinem Neuladen die Konfiguration tatsächlich übernommen hat. Dies wird nur in der Ausgabe des Befehls reload und im Aufruf von Nachrichten nachverfolgt (um den Fehlertext selbst zu erhalten).
- Planen Sie Backups. Die Entwickler von Bacula haben beschlossen, ihren eigenen Weg zu gehen und ein eigenes Zeitplanformat zu schreiben, das Sie nicht einfach analysieren oder in ein anderes konvertieren können. Hier sind Beispiele für Standard-Sicherungspläne in unseren alten Installationen:
- Täglich vollständige Sicherung mittwochs und schrittweise an anderen Tagen:
Run = Level=Full Pool="Foobar-low7" wed at 18:00
Run = Level=Incremental Pool="Foobar-low7" at 18:00 - Vollständige Sicherung der Wal-Dateien zweimal im Monat und stündliche Erhöhung:
Run = Level=Full FullPool=CustomerWALPool 1st fri at 01:45
Run = Level=Full FullPool=CustomerWALPool 3rd fri at 01:45
Run = Level=Incremental FullPool=CustomerWALPool IncrementalPool=CustomerWALPool on hourly - Der generierte
schedule für alle Gelegenheiten (an verschiedenen Wochentagen alle 2 Stunden) ergab ungefähr 1665 ... aufgrund dessen, was Bacula / Bareos regelmäßig verrückt machte.
- Bacula-fd (und bareos-fd) haben Verzeichnisse mit vielen Daten (z. B. 40 TB, von denen 35 TB große Dateien [100+ MB] und die restlichen 5 TB kleine Dateien [1 KB bis 100 MB] enthalten ]) Es beginnt ein langsamer Speicherverlust, was bei der Produktion eine sehr unangenehme Situation darstellt.
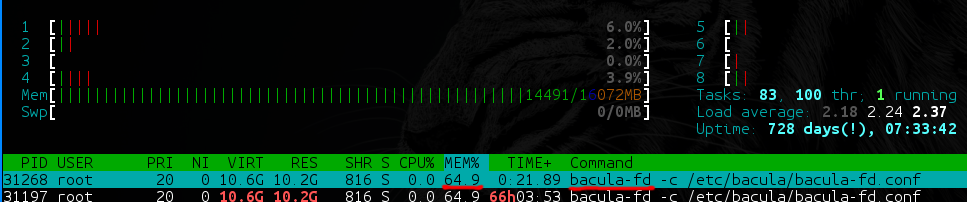
- Bei Sicherungen mit einer großen Anzahl von Dateien hängen Bacula und Bareos stark von der Leistung des verwendeten DBMS ab. Welche Laufwerke hat es? Wie geschickt wissen Sie, wie Sie sie auf diese spezifischen Bedürfnisse abstimmen können? Übrigens wird in der Datenbank eine (!) Nicht partitionierbare Tabelle mit einer Liste aller Dateien in allen Sicherungen und die zweite mit einer Liste aller Pfade in allen Sicherungen erstellt. Wenn Sie nicht bereit sind, mindestens 8 GB RAM für die Basis + 40 GB SSD für Ihren Backup-Server zuzuweisen, machen Sie sich sofort für die Bremsen bereit.
- Die Datenbankabhängigkeit verdient einen weiteren Punkt. Bacula / Bareos fragt den Regisseur für jede Datei, ob es bereits eine solche Datei gibt. Der Director kriecht natürlich in die Datenbank, in diese sehr großen Tabellen ... Es stellt sich heraus, dass die Sicherung einfach dadurch blockiert werden kann, dass mehrere schwere Sicherungen gleichzeitig gestartet wurden - selbst wenn der Unterschied dort mehrere Megabyte beträgt.
Es wäre unfair zu sagen, dass überhaupt keine Probleme gelöst wurden, aber wir kamen zu einem Punkt, an dem wir verschiedene Problemumgehungen wirklich satt hatten und "hier und jetzt" eine zuverlässige Lösung wollten.
Bacula / Bareos arbeiten hervorragend mit einer kleinen Anzahl (10-30) einheitlicher Jobs. Ist einmal in der Woche etwas kaputt gegangen? Es ist in Ordnung: Sie haben die Aufgabe dem diensthabenden Beamten (oder einem anderen Ingenieur) gegeben - sie haben sie repariert. Wir haben jedoch Projekte, bei denen die Anzahl der Jobs Hunderte und die Anzahl der Dateien Hunderttausende beträgt. Infolgedessen begannen sich 5 Minuten pro Woche, um das Backup zu reparieren (ohne mehrere Stunden Einstellungen zuvor zu zählen), zu vermehren. All dies führte dazu, dass 2 Stunden am Tag Backups in allen Projekten repariert werden mussten, da buchstäblich überall etwas unbedeutend oder ernsthaft kaputt ging.
Dann könnte jemand denken, dass ein dedizierter Ingenieur, der sich diesem Thema widmet, Backups durchführen sollte. Sicherlich wird er so bärtig und streng wie möglich sein, und von seinem Aussehen her werden Backups sofort repariert, während er ruhig an Kaffee nippt. Und diese Idee mag irgendwie wahr sein ... Aber es gibt immer ein Aber. Nicht jeder kann es sich leisten, Backups rund um die Uhr zu reparieren und zu überwachen, und noch mehr - ein Ingenieur, der für diese Zwecke eingesetzt wird. Wir sind uns nur sicher, dass es besser ist, diese 2 Stunden am Tag für etwas Produktiveres und Nützlicheres zu verwenden. Aus diesem Grund haben wir uns auf die Suche nach alternativen Lösungen gemacht, die „einfach funktionieren“.
Borg als neuer Weg
Die Suche nach anderen Open Source-Optionen war über die Zeit verteilt, daher ist es schwierig, die Gesamtkosten abzuschätzen. An einem Punkt (letztes Jahr) richtete sich unsere Aufmerksamkeit jedoch auf den „
Helden des Anlasses“ -
BorgBackup (oder einfach Borg). Zum Teil wurde dies durch die tatsächliche Erfahrung mit der Verwendung durch einen unserer Ingenieure (am vorherigen Arbeitsplatz) erleichtert.
Borg ist in Python geschrieben (Version> = 3.4.0 ist erforderlich) und leistungsintensiver Code (Komprimierung, Verschlüsselung usw.) ist in C / Cython implementiert. Vertrieb unter einer kostenlosen BSD-Lizenz (3-Klausel). Es unterstützt viele Plattformen, einschließlich Linux, * BSD, macOS sowie auf experimenteller Ebene Cygwin und Linux Subsystem von Windows 10. Zur Installation von BorgBackup stehen Pakete für gängige Linux-Distributionen und andere Betriebssysteme sowie Quellcodes zur Verfügung, die auch über pip installiert werden können. - Nähere Informationen hierzu finden Sie in der
Projektdokumentation .
Warum hat Borg uns so bestochen? Hier sind die Hauptvorteile:
Der Übergang zu Borg begann langsam bei kleinen Projekten. Anfangs waren dies einfache Cron-Skripte, die jeden Tag ihre Arbeit erledigten. Dies dauerte etwa sechs Monate. Während dieser Zeit mussten wir viele Male Backups bekommen ... und es stellte sich heraus, dass Borg überhaupt nicht buchstäblich repariert werden musste! Warum? Denn hier funktioniert das einfache Prinzip: "Je einfacher der Mechanismus ist, desto weniger Stellen brechen ihn."
Übung: Wie kann man mit Borg sichern?
Betrachten Sie ein einfaches Beispiel für die Erstellung eines Backups:
- Laden Sie die neueste Binärversion auf den Sicherungsserver und den Computer herunter, den wir aus dem offiziellen Repository sichern möchten :
sudo wget https://github.com/borgbackup/borg/releases/download/1.1.6/borg-linux64 -O /usr/local/bin/borg sudo chmod +x /usr/local/bin/borg
Hinweis : Wenn Sie einen lokalen Computer für den Test sowohl als Quelle als auch als Empfänger verwenden, liegt der gesamte Unterschied nur in der URI, die wir weitergeben. Wir denken jedoch daran, dass die Sicherung separat und nicht auf demselben Computer gespeichert werden muss. - Erstellen Sie auf dem Sicherungsserver den
borg Benutzer:
sudo useradd -m borg
Einfach: ohne Gruppen und mit einer Standard-Shell, aber immer mit einem Home-Verzeichnis. - Auf dem Client wird ein SSH-Schlüssel generiert:
ssh-keygen
- Fügen Sie auf dem Server den generierten Schlüssel zum
borg Benutzer hinzu:
mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh local / bin / borg dienen" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf / XmSVWfF7PfjGlbKW00MJ63zal / E / mxm + vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU / JNU0jITLx + vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk / QmteOOclzx684t9d6BhMvFE9w9r + c76aVBIdbEyrkloiYd + vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44 / Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam + 9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y + IQM7fbDR'> ~ borg / .ssh mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh
- Wir initialisieren das Borg-Repo auf dem Server vom Client aus:
ssh borg@172.17.0.3 hostname
Mit dem Schalter -e wird die Verschlüsselungsmethode für das Repository ausgewählt (ja, Sie können jedes Repository zusätzlich mit Ihrem Passwort verschlüsseln!). In diesem Fall, weil Dies ist ein Beispiel, wir verwenden keine Verschlüsselung. MyBorgRepo ist der Name des Verzeichnisses, in dem sich das Borg-Repo befindet (Sie müssen es nicht im Voraus erstellen - Borg MyBorgRepo alles selbst). - Starten Sie das erste Backup mit Borg:
borg create --stats --list borg@172.17.0.3:MyBorgRepo::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" /etc /root
Über die Schlüssel:
--stats und --list geben uns Statistiken über Backups und Dateien, die darauf --list .borg@172.17.0.3:MyBorgRepo - hier ist alles klar, dies ist unser Server und Verzeichnis. Und was kommt als nächstes für Magie?::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" ist der Name des Archivs im Repository. Es ist willkürlich, aber wir halten uns an das Format _-timestamp (Zeitstempel im Python-Format).
Was weiter? Sehen Sie natürlich, was in unser Backup gelangt ist! Liste der Archive im Repository:
borg@b3e51b9ed2c2:~$ borg list MyBorgRepo/ Warning: Attempting to access a previously unknown unencrypted repository! Do you want to continue? [yN] y MyFirstBackup-2018-08-04_16:55:53 Sat, 2018-08-04 16:55:54 [89f7b5bccfb1ed2d72c8b84b1baf477a8220955c72e7fcf0ecc6cd5a9943d78d]
Wir sehen ein Backup mit einem Zeitstempel und wie Borg uns fragt, ob wir wirklich auf ein unverschlüsseltes Repository zugreifen möchten, in dem wir noch nie waren.
Wir sehen uns die Liste der Dateien an:
borg list MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53
Wir erhalten die Datei aus dem Backup (Sie können auch das gesamte Verzeichnis):
borg@b3e51b9ed2c2:~$ borg extract MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53 etc/hostname borg@b3e51b9ed2c2:~$ ll etc/hostname -rw-r--r-- 1 borg borg 13 Aug 4 16:27 etc/hostname
Herzlichen Glückwunsch, Ihr erstes Borg-Backup ist fertig!
Übung: Automatisieren Sie dies [mit GitLab]!
Nachdem wir all dies in Skripte verpackt haben, haben wir Backups auf ähnliche Weise auf ungefähr 40 Hosts manuell konfiguriert. Als sie erkannten, dass Borg wirklich funktioniert, begannen sie, mehr und größere Projekte darauf zu übertragen ...
Und hier stehen wir vor dem, was in Bareos ist, aber nicht in Borg! Nämlich: WebUI oder eine Art zentraler Ort zum Konfigurieren von Backups. Und wir hoffen wirklich, dass dies ein vorübergehendes Phänomen ist, aber bisher mussten wir etwas lösen. Nachdem wir die fertigen Werkzeuge gegoogelt und uns in einer Videokonferenz versammelt hatten, machten wir uns an die Arbeit. Es war eine großartige Idee, Borg wie zuvor bei Bacula in unsere internen Services zu integrieren (Bacula selbst hat die Liste der Jobs von unserer zentralisierten API entfernt, in die wir unsere eigene Schnittstelle in andere Projekteinstellungen integriert hatten). Wir haben darüber nachgedacht, wie es geht, haben einen Plan entworfen, wie und wo es gebaut werden soll, aber ... Jetzt sind normale Backups erforderlich, aber es gibt keine Orte, an denen man großartige Zeitpläne erstellen kann. Was zu tun ist?
Fragen und Anforderungen waren ungefähr wie folgt:
- Was ist als zentrales Backup-Management zu verwenden?
- Was kann ein Linux-Administrator tun?
- Was kann selbst ein Manager, der Kunden einen Sicherungsplan anzeigt, verstehen und konfigurieren?
- Was macht eine geplante Aufgabe jeden Tag auf Ihrem System?
- Was wird nicht schwer zu konfigurieren sein und wird nicht kaputt gehen?
Die Antwort lag auf der Hand: Dies ist der gute alte Crond, der jeden Tag seine Pflicht heldenhaft erfüllt. Einfach. Es friert nicht ein. Sogar der Manager, der von Unix zu "Ihnen" wechselt, kann das Problem beheben.
Also Crontab, aber wo bewahrst du das alles auf? Gehen Sie jedes Mal zur Projektmaschine und bearbeiten Sie die Datei mit Ihren Händen? Natürlich nicht. Wir können unseren Zeitplan in das Git-Repository stellen und GitLab Runner konfigurieren, der ihn durch Festschreiben auf dem Host aktualisiert.
Hinweis : Es wurde GitLab als Automatisierungstool ausgewählt, da es für die Aufgabe praktisch ist und in unserem Fall fast überall. Aber ich muss sagen, dass er keineswegs eine Notwendigkeit ist.Sie können crontab für Backups mit einem vertrauten Automatisierungstool oder allgemein manuell (bei kleinen Projekten oder Heiminstallationen) erweitern.
Folgendes benötigen Sie für eine einfache Automatisierung:
1.
GitLab und ein Repository , in dem sich zunächst zwei Dateien befinden:
schedule - Sicherungszeitplanborg_backup_files.sh - ein einfaches Skript zum Sichern von Dateien (wie im obigen Beispiel).
Beispiel für einen
schedule :
CI-Variablen werden verwendet, um zu überprüfen, ob das Crontab-Update erfolgreich war, und
CI_PROJECT_DIR ist das Verzeichnis, in dem sich das Repository nach dem Klonen des
CI_PROJECT_DIR befindet. Die letzte Zeile zeigt an, dass die Sicherung jeden Tag um Mitternacht durchgeführt wird.
Beispiel
borg_backup_files.sh :
Das erste Argument ist hier der Name der Sicherung und das
zweite die Liste der Verzeichnisse für die Sicherung, die durch Kommas getrennt sind. Genau genommen kann eine Liste auch aus mehreren separaten Dateien bestehen.
2.
GitLab Runner , der auf dem Computer ausgeführt wird, der gesichert werden muss, und nur für die Jobs dieses Repositorys blockiert wird.
3.
Das CI-Skript selbst , das von der
.gitlab-ci.yml implementiert wird:
stages: - deploy Deploy: stage: deploy script: - export TIMESTAMP=$(date '+%Y.%m.%d %H:%M:%S') - cat schedule | envsubst | crontab - tags: - borg-backup
4. Der
SSH-Schlüssel für den
gitlab-runner Benutzer mit Zugriff auf den
gitlab-runner (im Beispiel 10.100.1.1). Standardmäßig sollte es sich im
.ssh/id_rsa (
gitlab-runner ) befinden.
5.
Der borg Benutzer auf demselben 10.100.1.1 mit nur Zugriff auf den Befehl
borg serve :
$ cat .ssh/authorized_keys command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAA...
Wenn Sie sich jetzt für das Runner-Repository festlegen, wird der Inhalt von crontab gefüllt. Und wenn die Antwortzeit des Cron kommt, wird eine Sicherung der Verzeichnisse
/etc und
/opt durchgeführt, die sich auf dem Sicherungsserver im
MyHostname-SYSTEM von Server 10.100.1.1 befindet.

Anstelle einer Schlussfolgerung: Was können Sie noch tun?
Die Verwendung von Borg endet hier natürlich nicht. Hier sind einige Ideen für die weitere Implementierung, von denen einige bereits zu Hause implementiert wurden:
- Fügen Sie universelle Skripte für verschiedene Sicherungen hinzu, die am Ende der Ausführung
borg_backup_files.sh und auf das Verzeichnis mit dem Ergebnis ihrer Arbeit abzielen. Sie können beispielsweise PostgreSQL (pg_basebackup), MySQL (innobackupex) und GitLab (integrierter Rake-Job, Erstellen eines Archivs) sichern. - Zentraler Host mit Zeitplan für die Sicherung . Nicht auf jedem Host GitLab Runner konfigurieren? Lassen Sie es auf dem Sicherungsserver allein, und crontab überträgt beim Start das Sicherungsskript auf den Computer und führt es dort aus. Dazu benötigen Sie natürlich den
borg Benutzer auf dem Client-Computer und den ssh-agent , um den Schlüssel für den Sicherungsserver nicht auf jedem Computer auszulegen. - Überwachung Wo ohne ihn! Warnungen über eine falsch abgeschlossene Sicherung müssen sein.
- Borg-Repository aus alten Archiven löschen. Trotz guter Deduplizierung müssen alte Backups noch bereinigt werden. Dazu können Sie am Ende des Sicherungsskripts einen Anruf bei
borg prune tätigen. - Webschnittstelle zum Zeitplan. Dies ist praktisch, wenn die Bearbeitung von crontab von Hand oder über das Webinterface für Sie nicht solide / unangenehm erscheint.
- Kreisdiagramme . Einige Diagramme zur visuellen Darstellung des Prozentsatzes erfolgreich abgeschlossener Sicherungen, ihrer Ausführungszeit und der Breite des "verzehrten" Kanals. Kein Wunder, dass ich geschrieben habe, dass es nicht genug WebUI gibt, wie in Bareos ...
- Einfache Aktionen , die ich per Knopfdruck erhalten möchte: Starten eines Backups bei Bedarf, Wiederherstellen auf einem Computer usw.
Und am Ende möchte ich ein Beispiel für die Effektivität der Deduplizierung bei einer wirklich funktionierenden Sicherung von PostgreSQL WAL-Dateien in einer Produktionsumgebung hinzufügen:
borg@backup ~ $ borg info PROJECT-PG-WAL Repository ID: 177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Location: /mnt/borg/PROJECT-PG-WAL Encrypted: No Cache: /mnt/borg/.cache/borg/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Security dir: /mnt/borg/.config/borg/security/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 ------------------------------------------------------------------------------ Original size Compressed size Deduplicated size All archives: 6.68 TB 6.70 TB 19.74 GB Unique chunks Total chunks Chunk index: 11708 3230099
Dies sind 65 Tage Backup von WAL-Dateien, die jede Stunde durchgeführt werden. Bei Verwendung von Bacula / Bareos, d.h. Ohne Deduplizierung würden wir 6,7 TB Daten erhalten. Denken Sie nur: Wir können es uns leisten, fast 7 Terabyte Daten zu speichern, die über PostgreSQL übertragen werden, nur 20 GB tatsächlich belegten Speicherplatz.
PS
Lesen Sie auch in unserem Blog: