Softwareentwicklung wird als schlecht messbarer Prozess angesehen, und es scheint, dass Sie ein besonderes Flair benötigen, um ihn effektiv zu verwalten. Und wenn die Intuition mit emotionaler Intelligenz nicht sehr entwickelt ist, ändern sich zwangsläufig die Bedingungen, die Qualität des Produkts sinkt und die Liefergeschwindigkeit sinkt.
 Sergei Semenov
Sergei Semenov glaubt, dass dies hauptsächlich aus zwei Gründen geschieht.
- Es gibt keine Werkzeuge und Standards zur Bewertung der Arbeit von Programmierern. Manager müssen auf subjektive Bewertungen zurückgreifen, was wiederum zu Fehlern führt.
- Es werden keine Mittel zur automatischen Steuerung der Prozesse im Team verwendet. Ohne angemessene Kontrolle erfüllen die Prozesse in den Entwicklungsteams ihre Funktionen nicht mehr, da sie teilweise ausgeführt oder einfach ignoriert werden.
Und es bietet einen Ansatz zur Bewertung und Kontrolle von Prozessen auf der Grundlage objektiver Daten.
Unten finden Sie eine Video- und Textversion von Sergeys Bericht, der nach den Ergebnissen der Publikumsabstimmung bei
Saint TeamLead Conf den zweiten Platz
belegte .
Über den Redner: Sergey Semenov ( sss0791 ) arbeitet seit 9 Jahren in der IT, war Entwickler, Teamleiter, Produktmanager und jetzt CEO von GitLean. GitLean ist ein Analyseprodukt für Manager, technische Direktoren und Teamleiter, mit dem objektive Managemententscheidungen getroffen werden sollen. Die meisten Beispiele in dieser Geschichte basieren nicht nur auf persönlichen Erfahrungen, sondern auch auf den Erfahrungen von Kundenunternehmen mit Entwicklungsmitarbeitern von 6 bis 200 Personen.Bereits mit meinem Kollegen Alexander Kiselev haben wir im Februar bei der vorherigen TeamLead Conf über die
Evaluierung von Entwicklern gesprochen. Ich werde nicht im Detail darauf eingehen, sondern auf einen Artikel über einige Metriken verweisen. Heute werden wir über Prozesse sprechen und wie man sie steuert und misst.
Datenquellen
Wenn es sich um Messungen handelt, wäre es schön zu verstehen, woher die Daten stammen. Zunächst haben wir:
- Git mit Code-Informationen;
- Jira oder ein anderer Task-Tracker mit Informationen zu Aufgaben;
- GitHub , Bitbucket, Gitlab mit Informationen zur Codeüberprüfung.
Darüber hinaus gibt es einen so coolen Mechanismus wie das Sammeln verschiedener subjektiver Bewertungen. Ich werde reservieren, dass es systematisch verwendet werden muss, wenn wir uns auf diese Daten verlassen wollen.

Natürlich erwarten Sie Schmutz und Schmerz in den Daten - Sie können nichts dagegen tun, aber das ist nicht so beängstigend. Das Unangenehmste ist, dass in diesen Quellen möglicherweise einfach keine Daten zur Arbeit Ihrer Prozesse vorhanden sind. Dies kann daran liegen, dass die Prozesse so erstellt wurden, dass keine Artefakte in den Daten zurückbleiben.
Die erste Regel , die wir beim Entwerfen und Erstellen von Prozessen empfehlen, besteht darin, sie so zu gestalten, dass sie Artefakte in den Daten hinterlassen. Sie müssen nicht nur Agile erstellen, sondern es auch messbar
agil machen .
Ich erzähle Ihnen die Horrorgeschichte, die wir mit einem der Kunden getroffen haben, die zu uns kamen, um die Qualität des Produkts zu verbessern. Damit Sie die Größenordnung verstehen, flogen pro Woche etwa 30 bis 40 Fehler aus der Produktion an ein Team von 15 Entwicklern. Sie begannen die Gründe zu verstehen und stellten fest, dass 30% der Aufgaben nicht in den Status „Testen“ fielen. Zuerst dachten wir, es sei nur ein Datenfehler, oder die Tester haben den Status der Aufgabe nicht aktualisiert. Es stellte sich jedoch heraus, dass wirklich 30% der Aufgaben einfach nicht getestet werden. Einmal gab es ein Problem in der Infrastruktur, aufgrund dessen 1-2 Aufgaben in der Iteration nicht in den Test fielen. Dann vergaßen alle dieses Problem, die Tester hörten auf, darüber zu reden, und im Laufe der Zeit wuchs es auf 30%. Dies führte zu mehr globalen Problemen.
Daher ist die erste wichtige Metrik für jeden Prozess, dass er Daten hinterlässt. Befolgen Sie diese Anweisungen unbedingt.

Manchmal muss man aus Gründen der Messbarkeit einen Teil der Prinzipien von Agile opfern und zum Beispiel irgendwo die schriftliche Kommunikation der mündlichen vorziehen.
Die Fälligkeitspraxis, die wir in mehreren Teams implementiert haben, um die Vorhersagbarkeit zu verbessern, hat sich als sehr gut erwiesen. Das Wesentliche ist wie folgt: Wenn der Entwickler die Aufgabe übernimmt und sie auf "In Bearbeitung" zieht, muss er das Fälligkeitsdatum festlegen, an dem die Aufgabe entweder freigegeben oder zur Veröffentlichung bereit ist. Diese Praxis lehrt den Entwickler, ein bedingter Mikroprojektmanager seiner eigenen Aufgaben zu sein, dh externe Abhängigkeiten zu berücksichtigen und zu verstehen, dass die Aufgabe nur dann bereit ist, wenn der Client das Ergebnis verwenden kann.
Damit die Schulung nach dem Fälligkeitsdatum stattfinden kann, muss der Entwickler zu Jira gehen und ein neues Fälligkeitsdatum festlegen und Kommentare in einer speziell angegebenen Form hinterlassen, warum dies passiert ist. Es scheint, warum eine solche Bürokratie benötigt wird. Tatsächlich laden wir nach zwei Wochen dieser Übung alle derartigen Kommentare von Jira mit einem einfachen Skript ab und führen eine Retrospektive mit dieser Textur durch. Es gibt viele Erkenntnisse darüber, warum die Fristen nicht eingehalten werden. Es funktioniert sehr cool, ich empfehle es zu verwenden.
Problemansatz
Bei der Messung von Prozessen bekennen wir uns zu folgendem Ansatz: Wir müssen von Problemen ausgehen. Wir stellen uns einige ideale Praktiken und Prozesse vor und sind dann kreativ, wie sie möglicherweise nicht funktionieren.
Es ist notwendig, die Verletzung von Prozessen zu überwachen und nicht, wie wir einige Praktiken befolgen. Prozesse funktionieren oft nicht, nicht weil Leute sie böswillig verletzen, sondern weil Entwickler und Manager nicht genug Kontrolle und Speicher haben, um ihnen allen zu folgen. Wenn wir Verstöße gegen Vorschriften verfolgen, können wir die Leute automatisch daran erinnern, was zu tun ist, und wir erhalten automatische Kontrollen.
Um zu verstehen, welche Prozesse und Praktiken Sie implementieren müssen, müssen Sie verstehen, warum dies im Entwicklungsteam zu tun ist und was das Unternehmen von der Entwicklung benötigt. Jeder versteht, dass nicht so viel benötigt wird:
- dass das Produkt für einen angemessenen Prognosezeitraum geliefert wird;
- dass das Produkt von angemessener Qualität war, nicht unbedingt perfekt;
- damit das alles schnell genug ist.
Das heißt,
Vorhersehbarkeit, Qualität und Geschwindigkeit sind wichtig. Daher werden wir alle Probleme und Metriken genau untersuchen und berücksichtigen, wie sie sich auf die Vorhersagbarkeit und Qualität auswirken. Wir werden kaum über Geschwindigkeit sprechen, da aufgrund der fast 50 Teams, mit denen wir auf die eine oder andere Weise gearbeitet haben, nur zwei mit Geschwindigkeit arbeiten konnten. Um die Geschwindigkeit zu erhöhen, müssen Sie in der Lage sein, sie zu messen, damit sie zumindest ein wenig vorhersehbar ist, und dies ist Vorhersehbarkeit und Qualität.
Neben Vorhersehbarkeit und Qualität führen wir eine Richtung wie
Disziplin ein . Wir werden Disziplin alles nennen, was das grundlegende Funktionieren von Prozessen und die Erfassung von Daten sicherstellt, auf deren Grundlage eine Analyse von Problemen mit Vorhersehbarkeit und Qualität durchgeführt wird.
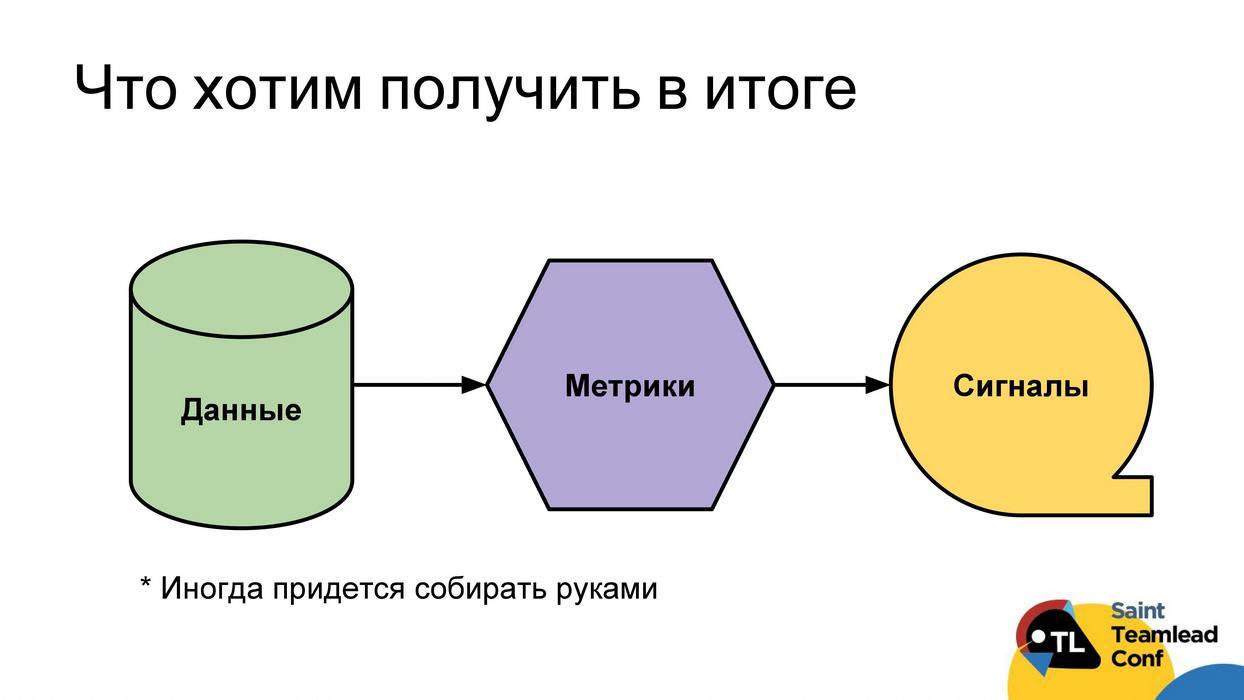
Im Idealfall möchten wir das folgende Arbeitsschema erstellen: Damit wir eine automatische Datenerfassung haben; Aus diesen Daten konnten wir Metriken erstellen. Verwenden von Metriken zum Auffinden von Problemen Melden Sie Probleme direkt dem Entwickler, Teamleiter oder Team. Dann kann jeder rechtzeitig auf sie reagieren und die festgestellten Probleme bewältigen. Ich muss sofort sagen, dass es nicht immer möglich ist, zu verständlichen Signalen zu gelangen. Manchmal bleiben Metriken nur Metriken, die analysiert werden müssen, um Werte, Trends usw. zu betrachten. Selbst bei Daten tritt manchmal ein Problem auf, manchmal können sie nicht automatisch erfasst werden, und Sie müssen dies von Hand tun (ich werde solche Fälle separat klären).
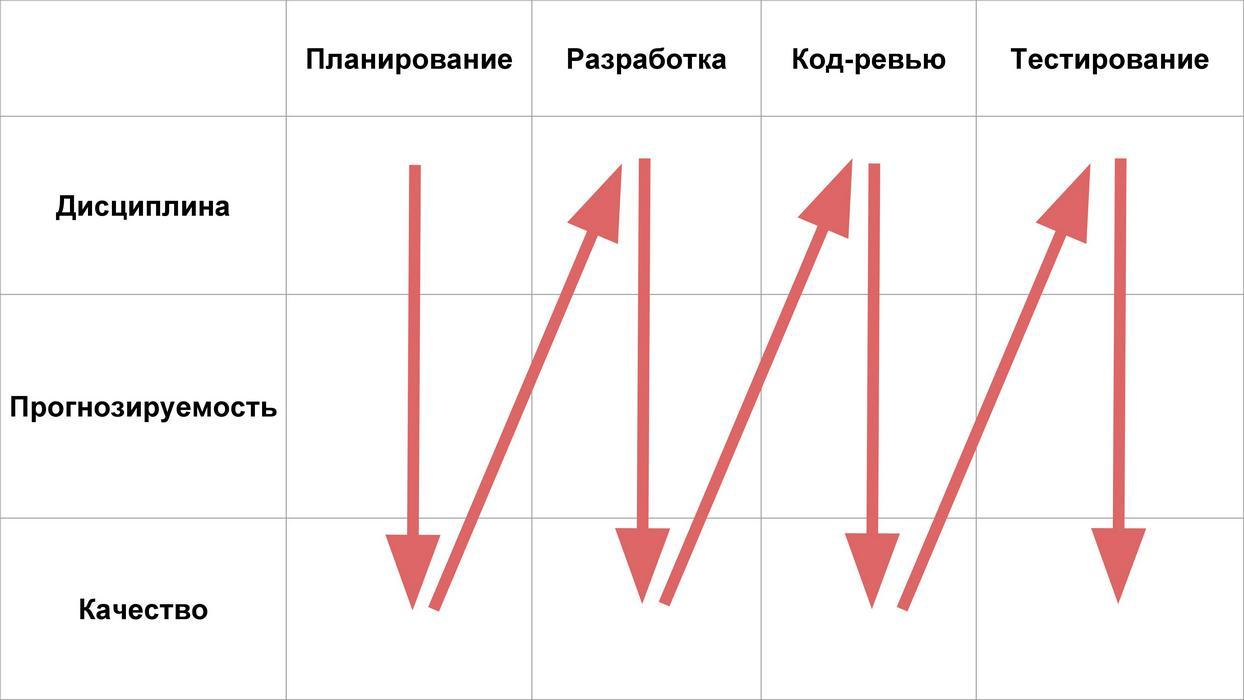
Als nächstes betrachten wir 4 Phasen des Lebens der Merkmale:
Und wir werden analysieren, welche Probleme in Bezug auf Disziplin, Vorhersehbarkeit und Qualität in jeder dieser Phasen auftreten können.
Probleme mit der Disziplin in der Planungsphase
Es gibt viele Informationen, aber ich achte auf die grundlegendsten Punkte. Sie mögen recht einfach erscheinen, aber sie stehen vor einer sehr großen Anzahl von Teams.

Das erste Problem, das häufig während der Planung auftritt, ist ein banales
organisatorisches Problem - nicht jeder, der dort sein sollte, ist beim Planungstreffen anwesend.
Beispiel: Ein Team beschwert sich, dass ein Tester etwas falsch testet. Es stellt sich heraus, dass Tester in diesem Team überhaupt nicht zur Planung gehen. Oder anstatt zu sitzen und etwas zu planen, sucht das Team verzweifelt nach einem Platz zum Sitzen, weil es vergessen hat, einen Besprechungsraum zu buchen.
Metriken und Signale müssen nicht konfiguriert werden. Stellen Sie nur sicher, dass diese Probleme nicht auftreten. Das Treffen wurde auf dem Kalender vermerkt, alle wurden dazu eingeladen, der Veranstaltungsort wurde besetzt. Egal wie lustig es auch klingen mag, dies ist in verschiedenen Teams anzutreffen.
Jetzt werden wir Situationen diskutieren, in denen Signale und Metriken benötigt werden. In der Planungsphase sollten die meisten Signale, über die ich sprechen werde, etwa eine Stunde nach dem Ende des Planungsmeetings an das Team gesendet werden, um das Team nicht abzulenken, aber dennoch den Fokus zu behalten.
Das erste disziplinarische Problem besteht darin,
dass Aufgaben nicht oder nur unzureichend beschrieben werden. Dies wird elementar gesteuert. Es gibt ein Format, dem die Aufgaben entsprechen sollen - wir prüfen, ob dies der Fall ist. Zum Beispiel folgen wir, dass Akzeptanzkriterien festgelegt sind, oder für Front-End-Aufgaben gibt es einen Link zum Layout. Sie müssen auch die platzierten Komponenten im Auge behalten, da das Beschreibungsformat häufig an die Komponente gebunden ist. Für eine Backend-Aufgabe ist eine Beschreibung relevant, für eine Frontend-Aufgabe eine andere.

Das nächste häufige Problem besteht darin, dass
Prioritäten mündlich oder gar nicht gesprochen werden und sich nicht in den Daten widerspiegeln . Am Ende der Iteration stellt sich heraus, dass die wichtigsten Aufgaben nicht erledigt wurden. Es muss sichergestellt werden, dass das Team Prioritäten verwendet und diese angemessen verwendet. Wenn in einem Team 90% der Aufgaben in der Iteration eine hohe Priorität haben, entspricht dies keinerlei Prioritäten.
Wir versuchen, zu einer solchen Verteilung zu gelangen: 20% Aufgaben mit hoher Priorität (Sie können nicht anders, als zu entladen); 60% - mittlere Priorität; 20% - niedrige Priorität (es ist nicht beängstigend, wenn wir es nicht veröffentlichen). Wir hängen Signale an all das.

Das letzte Problem mit der Disziplin, das in der Planungsphase auftritt -
es gibt
nicht genügend Daten , auch für nachfolgende Metriken. Grundlegende: Aufgaben haben keine Bewertungen (es sollte ein Signal gegeben werden) oder Arten von Aufgaben sind unzureichend. Das heißt, Fehler werden als Aufgaben gestartet, und die Aufgaben der technischen Verschuldung können überhaupt nicht zurückverfolgt werden. Leider ist es nicht möglich, die zweite Art von Problemen automatisch zu steuern. Wir empfehlen Ihnen nur einmal alle paar Monate, insbesondere wenn Sie CTO sind und mehrere Teams haben, den Rückstand zu durchsuchen und sicherzustellen, dass die Leute Fehler wie Fehler, Geschichten wie Geschichten, technische Schuldenaufgaben wie technische Schulden starten.
Vorhersagbarkeitsprobleme in der Planungsphase
Wir wenden uns Problemen mit der Vorhersehbarkeit zu.

Das Grundproblem besteht darin,
dass wir die Fristen und Schätzungen nicht einhalten. Leider ist es unmöglich, ein magisches Signal oder eine Metrik zu finden, die dieses Problem lösen. Die einzige Möglichkeit besteht darin, das Team zu ermutigen, besser zu lernen und die Fehlerursachen mit der einen oder anderen Bewertung anhand von Beispielen zu analysieren. Und dieser Lernprozess kann durch automatische Mittel erleichtert werden.
Das erste, was getan werden kann, ist, offensichtlich problematische Aufgaben mit einer hohen Schätzung der Ausführungszeit zu lösen. Wir hängen SLA auf und kontrollieren, dass alle Aufgaben gut genug zerlegt sind. Wir empfehlen zunächst maximal zwei Tage für die Ausführung. Anschließend können Sie mit einem Tag fortfahren.
Der nächste Absatz kann die Sammlung von Artefakten erleichtern, anhand derer mit dem Team Schulungen durchgeführt und analysiert werden können, warum bei der Bewertung ein Fehler aufgetreten ist. Wir empfehlen hierfür die Fälligkeitspraxis. Sie hat sich hier als sehr cool erwiesen.
Eine andere Möglichkeit ist eine Metrik namens Churn-Code als Teil der Aufgabe. Das Wesentliche ist, dass wir uns ansehen, wie viel Prozent des Codes im Rahmen der Aufgabe geschrieben wurden, aber der Veröffentlichung nicht gerecht wurden (mehr im letzten
Bericht ). Diese Metrik zeigt, wie gut durchdachte Aufgaben sind. Dementsprechend wäre es schön, auf Probleme mit Churn-Sprüngen zu achten und sie zu verstehen, was wir nicht berücksichtigt haben und warum wir bei der Bewertung einen Fehler gemacht haben.

Die folgende Geschichte ist Standard: Das Team plante etwas, der Sprint füllte sich, aber am Ende
tat es überhaupt nicht, was es geplant hatte . Sie können Signale zum Füllen und Ändern von Prioritäten konfigurieren, aber für die meisten Teams, mit denen wir dies getan haben, waren sie irrelevant. Oft handelt es sich dabei um rechtliche Schritte des Produktmanagers, um etwas in den Sprint zu werfen und die Priorität zu ändern, sodass es viele Fehlalarme gibt.
Was kann man hier machen? Berechnen Sie ziemlich standardmäßige Grundmetriken: Schließen des ersten Sprint-Scouts, Anzahl der Würfe in den Sprint, Schließen der Würfe selbst, Prioritätsänderungen, siehe Struktur der Würfe. Bewerten Sie anschließend, wie viele Aufgaben und Fehler Sie normalerweise in die Iteration werfen. Verwenden Sie außerdem ein Signal, um zu steuern, dass Sie
dieses Kontingent in der Planungsphase festlegen .
Qualitätsprobleme in der Planungsphase
Das erste Problem: Das
Team denkt nicht über die Funktionalität der veröffentlichten Funktionen nach . Ich werde allgemein über Qualität sprechen - ein Qualitätsproblem ist, wenn der Kunde sagt, dass es existiert. Es kann eine Art Lebensmittelfehler sein, oder es können technische Dinge sein.
In Bezug auf Lebensmittelfehler
funktioniert eine Metrik wie
3-Wochen-Abwanderung gut , was zeigt, dass 3 Wochen nach der Freigabe der Abwanderungsaufgabe über dem Normalwert liegt. Das Wesentliche ist einfach: Die Aufgabe wurde nicht freigegeben, und innerhalb von drei Wochen wurde ein ausreichend hoher Prozentsatz des Codes gelöscht. Anscheinend war die Aufgabe nicht sehr gut umgesetzt. Wir erfassen und analysieren solche Fälle mit dem Team.

Die zweite Metrik wird für Teams benötigt, die Probleme mit Fehlern, Abstürzen und Qualität haben. Wir schlagen vor, ein
Diagramm des Gleichgewichts von Fehlern und Abstürzen zu erstellen
: Wie viele Fehler gibt es gerade, wie viele sind gestern angekommen, wie viele sind gestern aufgetreten. Sie können einen solchen
Echtzeitmonitor direkt vor das Team hängen, damit sie ihn jeden Tag sieht. Dies konzentriert das Team auf Qualitätsprobleme. Die beiden Teams und ich haben das gemacht und sie haben wirklich angefangen, Aufgaben besser zu durchdenken.

Das nächste Standardproblem ist,
dass das Team keine Zeit für technische Schulden hat . Diese Geschichte kann leicht überwacht werden, wenn Sie die Arbeit mit Typen verfolgen, dh technische Schuldenaufgaben werden bewertet und in Jira als technische Schuldenaufgaben gestartet. Wir können berechnen, welche Zeitzuweisungsquote dem technischen Schulden-Team während des Quartals gegeben wurde. Wenn wir dem Geschäft zustimmen, dass es 20% waren und nur 10% ausgaben, kann dies berücksichtigt werden und im nächsten Quartal mehr Zeit für technische Schulden aufgewendet werden.
Probleme mit der Disziplin in der Entwicklung
Fahren wir nun mit der Entwicklungsphase fort. Was sind die Probleme mit der Disziplin?
Leider kommt es vor, dass
Entwickler nichts tun oder wir nicht verstehen können, ob sie etwas tun. Es ist leicht, dies anhand von zwei banalen Zeichen zu verfolgen:
- Häufigkeit der Commits - mindestens einmal am Tag;
- mindestens eine aktive Aufgabe in Jira.
Wenn dies nicht der Fall ist, ist es keine Tatsache, dass Sie die Hände des Entwicklers schlagen müssen, aber Sie müssen darüber Bescheid wissen.
Das zweite Problem, das selbst die mächtigsten Leute und das Gehirn selbst eines sehr coolen Entwicklers umwerfen kann, ist die
ständige Verarbeitung . Es wäre schön, wenn Sie als Teamleiter wüssten, dass eine Person verarbeitet: schreibt einen Code oder führt nach Stunden eine Codeüberprüfung durch.
Es können auch
verschiedene Git-Regeln verletzt werden . Das erste, was wir allen Befehlen dringend empfehlen, ist die Angabe von Aufgabenpräfixen aus dem Tracker in Festschreibungsnachrichten, da nur in diesem Fall die Aufgabe und der Code damit verknüpft werden können. Hier ist es besser, nicht einmal Signale zu erstellen, sondern den Git-Hook direkt zu konfigurieren. Für zusätzliche Git-Regeln, die Sie beispielsweise nicht im Master festschreiben können, konfigurieren wir auch Git-Hooks.
Gleiches gilt für vereinbarte Praktiken. In der Entwicklungsphase gibt es viele Praktiken, denen ein Entwickler folgen muss. Im Fall des Fälligkeitsdatums gibt es beispielsweise drei Signale:
- Aufgaben, für die kein Fälligkeitsdatum festgelegt ist;
- Aufgaben, deren Fälligkeitsdatum abgelaufen ist;
- Aufgaben, für die das Fälligkeitsdatum geändert wurde, aber kein Kommentar.
Die Signale sind darauf abgestimmt. Ähnliche Dinge können auch für jede andere Praxis eingerichtet werden.
Vorhersagbarkeitsprobleme in der Entwicklungsphase
Bei Prognosen in der Entwicklungsphase kann vieles schief gehen.
Eine Aufgabe kann nur lange in der Entwicklung hängen bleiben. Wir haben bereits in der Planungsphase versucht, dieses Problem zu lösen - die Aufgaben ganz fein zu zerlegen. Leider hilft dies nicht immer und
es gibt Aufgaben, die einfrieren . Für den Anfang empfehlen wir, die SLA einfach auf "in Bearbeitung" zu setzen, damit ein Signal angezeigt wird, dass diese SLA verletzt wird. Auf diese Weise können Sie Aufgaben jetzt nicht schneller freigeben, aber Sie können erneut Rechnungen sammeln, darauf reagieren und mit dem Team besprechen, was passiert ist und warum die Aufgabe lange Zeit hängt.
Die Vorhersagbarkeit kann leiden, wenn
ein Entwickler zu viele Aufgaben hat . Es ist ratsam, die Anzahl der parallelen Aufgaben, die der Entwickler ausführt, anhand des Codes und nicht anhand von Jira zu überprüfen, da Jira nicht immer relevante Informationen widerspiegelt. Wir sind alle Menschen, und wenn wir viele parallele Aufgaben erledigen, steigt das Risiko, dass irgendwo etwas schief geht.

Der Entwickler hat möglicherweise einige Probleme, über die er nicht spricht, die jedoch anhand der Daten leicht zu identifizieren sind. Zum Beispiel hatte der Entwickler gestern wenig Code-Aktivität. Dies bedeutet nicht unbedingt, dass es ein Problem gibt, aber Sie als Teamleiter können es herausfinden. Er mag stecken bleiben und Hilfe brauchen, aber es ist ihm peinlich, sie zu fragen.
Ein anderes Beispiel: Der Entwickler hat im Gegenteil eine große Aufgabe, die im Code immer weiter wächst. Dies kann auch erkannt und möglicherweise zerlegt werden, so dass am Ende keine Probleme bei der Codeüberprüfung oder beim Testen auftreten.
, . , , . .
. , , .
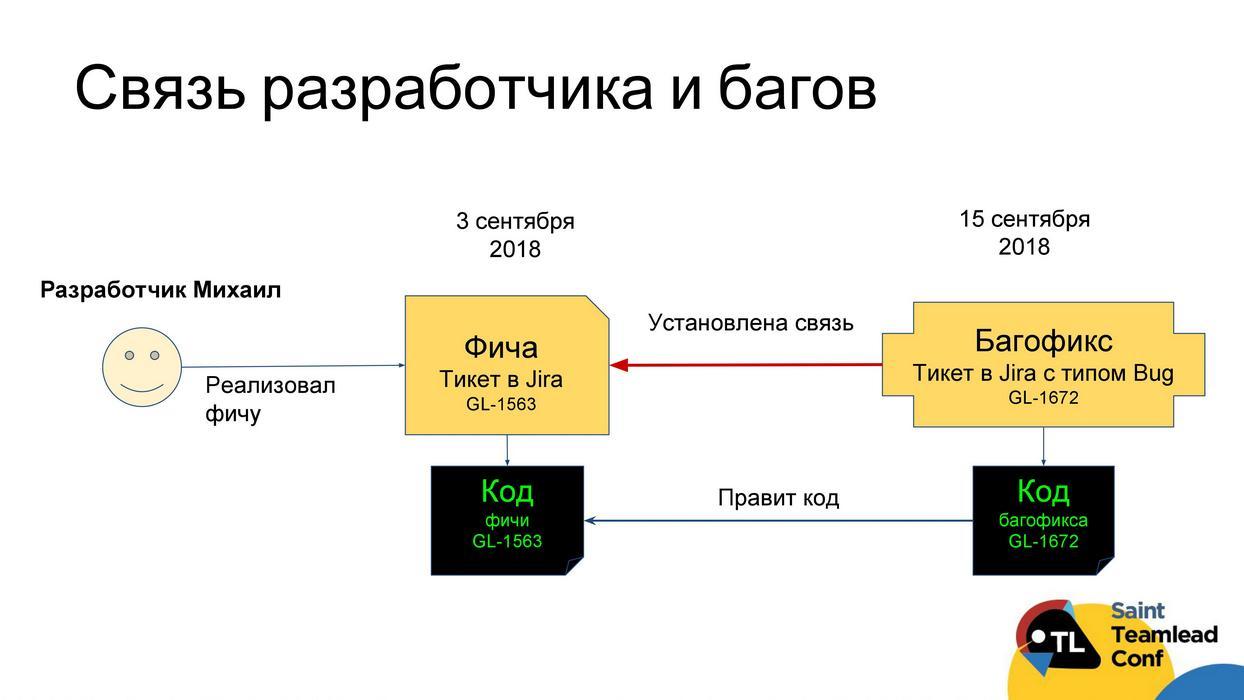
.
«» : , ; «»; «»; , bug fix. , , , , , — « ».
, , , , . , - , .
, , ,
, «» . , . ,
Legacy Refactoring , , , .
, —
SLA high-priority- . , . , , : high-priority critical .
, —
. -, . -, , . , .
-
Code review. ? , , — pull requests. -, pull request, . , , «in review», , Jira. , . , 2-3 , .

, , , pull request, . — , pull request ticket Jira .

, , , . pull requests, . , , : «, , - ». , . pull requests , , Jira.
pull request, , — , , - , - , , . .
, , — , , , , . : , « , ». , .

, , linter. , , - linter, - - , .
-
, SLA , , . , , .
SLA , "
- " — . , -. pull request .

,
- , . , CTO , , , . -. - , 6 50% - . , , 50%, CTO . , CTO - , 100%.
, — , - . :
, -.
-
, -. , .
100 . - 10 , - 1-2 . , .
— , , . , , , .

, , , , .
—
, - , . — churn -, .. pull request , .
,
- , , , . , commit, , -.

, - ( pull request ), - . , commit, . , .
. , — Jira. Jira. , «testing». task-tracker. , , - .

SLA . SLA , .
-, , , — . . , , ,
.

pipeline test- — , , , . build' , , — , . , 1-2 , , . , .
— . , . , , «» , , , , , .
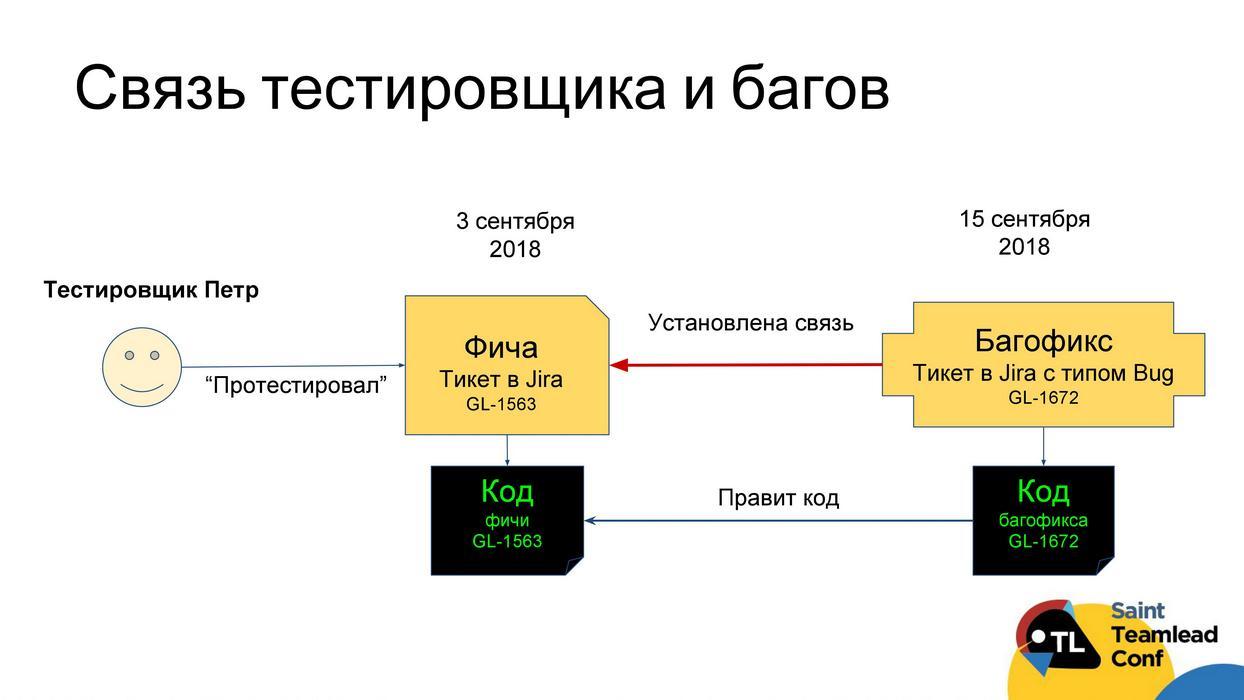
, , ,
. . , , , , . , , , . : , , , .

, «» , , . , , , .

, —
- . , , . , , .
Wir haben über Metriken gesprochen, und jetzt lautet die Frage: Wie soll man damit umgehen? Ich erzählte nur die grundlegendsten Dinge, aber auch viele davon. Was tun mit all dem und wie benutzt man es?
Wir empfehlen, dass Sie diesen Prozess maximal automatisieren und alle Signale über einen Bot in Instant Messenger an das Team senden. Wir haben verschiedene Kommunikationskanäle ausprobiert: sowohl E-Mail als auch Dashboard - es funktioniert nicht sehr gut. Der Bot hat sich am besten bewährt. Sie können selbst einen Bot schreiben, Sie können OpenSource von jemandem nehmen, Sie können bei uns kaufen.
Der Punkt hier ist sehr einfach: Das Team reagiert viel ruhiger auf Signale vom Bot als auf den Manager, der auf Probleme hinweist. Wenn möglich, senden Sie die meisten Signale zuerst direkt an den Entwickler und dann an das Team, wenn der Entwickler beispielsweise nicht innerhalb von ein bis zwei Tagen antwortet.

Sie müssen nicht versuchen, alle Signale gleichzeitig zu erstellen. Die meisten von ihnen funktionieren einfach nicht, weil Sie aufgrund trivialer Disziplinprobleme keine Daten haben. Deshalb legen wir zuerst Disziplin fest und setzen Signale für disziplinarische Praktiken. Nach den Erfahrungen der Teams, mit denen wir gesprochen haben, dauerte es anderthalb Jahre, um ohne Automatisierung einfach Disziplin im Entwicklungsteam aufzubauen. Mit der Automatisierung beginnt das Team mit Hilfe konstanter Signale irgendwo nach ein paar Monaten, dh viel schneller, diszipliniert normal zu arbeiten.
Alle Signale, die Sie veröffentlichen oder direkt an den Entwickler richten, können Sie in keinem Fall einfach abholen und einschalten. Zuerst müssen Sie dies mit dem Entwickler abstimmen, mit ihm und dem Team sprechen. Es ist ratsam, alle Schwellenwerte schriftlich in eine Teamvereinbarung einzutragen, die Gründe, warum Sie dies tun, die nächsten Schritte und so weiter.

Es sollte berücksichtigt werden, dass alle Prozesse Ausnahmen haben, und dies in der Entwurfsphase berücksichtigen.
Wir bauen kein Konzentrationslager für Entwickler, in dem es unmöglich ist, einen Schritt nach rechts und einen Schritt nach links zu machen. Alle Prozesse haben eine Ausnahme, wir wollen sie nur kennen. Wenn der Bot ständig auf eine Aufgabe schwört, die wirklich nicht zerlegt werden kann und deren Bearbeitung 5 Tage dauert, müssen Sie ein "No-Tracking" -Markieren setzen, damit der Bot dies berücksichtigt. Als Manager können Sie die Anzahl solcher "No-Tracking" -Aufgaben separat überwachen und so verstehen, wie gut sowohl diese Prozesse als auch die von Ihnen erstellten Signale sind. Wenn die Anzahl der Aufgaben mit der Bezeichnung "No-Tracking" stetig zunimmt, bedeutet dies leider, dass die von Ihnen erfundenen Signale und Prozesse für das Team schwierig sind, ihnen nicht folgen können und es einfacher ist, sie zu umgehen.
 Die manuelle Steuerung bleibt weiterhin bestehen
Die manuelle Steuerung bleibt weiterhin bestehen . Es wird nicht funktionieren, den Bot einzuschalten und irgendwo auf Bali zu bleiben - Sie müssen sich immer noch mit jeder Situation auseinandersetzen. Sie haben ein Signal erhalten, die Person hat nicht darauf reagiert - Sie müssen in ein oder zwei Tagen den Grund herausfinden, das Problem besprechen und eine Lösung finden.
Um diesen Prozess zu optimieren, empfehlen wir die Einführung einer Praxis, z. B. eines
Prozessbegleiters . Dies ist eine Übergangsposition einer Person (einmal pro Woche), die die Probleme versteht, die der Bot signalisiert. Und Sie als Teamleiter helfen dem Mitarbeiter, diese Probleme zu lösen, dh ihn zu beaufsichtigen. Somit erhöht der Entwickler die Motivation, mit diesem Produkt zu arbeiten. Er versteht seine Vorteile, weil er sieht, wie diese Probleme gelöst werden können und wie er darauf reagieren kann. Auf diese Weise reduzieren Sie Ihre Einzigartigkeit gegenüber dem Team und
bringen den Moment näher, in dem das Team autonom wird , und Sie können trotzdem nach Bali gehen.
SchlussfolgerungenDaten sammeln. Erstellen Sie Prozesse so, dass Sie Daten sammeln können. Auch wenn Sie jetzt keine Metriken und Signale erstellen möchten, können Sie in Zukunft eine coole, retrospektive Analyse durchführen, wenn Sie jetzt mit der Erfassung beginnen.
Prozesse automatisch steuern. Denken Sie beim Entwerfen von Prozessen immer daran, wie Sie sie hacken und wie Sie solche Hacks anhand der Daten erkennen können.
Wenn die Signale für einige Wochen wenige sind - gut gemacht! Wir waren mit der Tatsache konfrontiert, dass, wenn das Team sieht, dass es weniger Signale gibt und es scheint, dass sich die Situation verbessert, es beginnt, einige andere Praktiken zu entwickeln, etwas zu implementieren, um diese Signalpakete wieder zu sehen. Dies ist nicht immer notwendig, vielleicht wenn weniger Signale vorhanden sind - bei Ihnen ist alles in Ordnung, das Team hat von Anfang an so gearbeitet, wie Sie es wollten, und Sie sind fertig :)
Teilen Sie Ihre Timlid-Fundstücke auf TeamLead Conf . Die Februar-Konferenz findet in Moskau statt und Call for Papers ist bereits geöffnet .
Möchten Sie die Erfahrung anderer Menschen erleben? Melden Sie sich für unseren Management- Newsletter an, um Neuigkeiten über das Programm zu erhalten, und verpassen Sie nicht die Zeit, um Konferenztickets zu verhandeln.