In Fortsetzung des „
Debriefings “ mit HighLoad ++ 2017 haben wir einen kurzen Überblick über die fünf besten (laut Konferenzteilnehmern) englischsprachigen Berichte erstellt.
Themen im Zusammenhang mit der Verwendung von ProxySQL (in TOP 5 gab es zwei Berichte zu diesem Tool), Anwendungstests in der öffentlichen Cloud von Amazon sowie den Grundsätzen der Protokollierung auf einer Skala, wenn dies zu einem Problem wird, und der Überwachung von Apache Kafka wurden mit Bestnoten bewertet.
Wir haben gerade Videos aller Berichte von HighLoad ++ 2017 für den freien Zugriff veröffentlicht. Eine vollständige Liste von 150 Berichten auf unserem YouTube-Kanal in dieser Wiedergabeliste .
Zusätzlich zu dieser Wiedergabeliste enthält der Kanal mehrere hundert Videos zu Datenbanken, Architekturen, Skalierung, Warteschlangen, maschinellem Lernen und anderen Highload-Informationen :)
Messung der Leistungsvariabilität von EC2
Henrik Ingo (MongoDB Solution Architect und jetzt Lead Productivity Engineer bei Mongo DB).Der erste von den Teilnehmern festgestellte Bericht argumentiert, dass die öffentliche Cloud tatsächlich zum Testen ihrer eigenen Produkte verwendet werden kann, einschließlich Lasttests. In diesem Fall war das MongoDB-DBMS, das mit der Amazon-Cloud getestet wird, das „Experiment“. Insgesamt werden pro Monat etwa 400.000 Stunden für diese Aufgabe aufgewendet, etwa 5% dieser Zeit sind nur Leistungstests, deren Hauptaufgabe nicht einmal darin besteht, Optimierungen bereitzustellen und aufgrund einiger Verbesserungen kein „Absinken“ zuzulassen.
Die zentrale Frage der Präsentation ist, wie reproduzierbare Testergebnisse in der öffentlichen Cloud erzielt werden können.
Der Bericht basiert auf dem Prinzip der Hypothesenanalyse. Zunächst geht Henrik Ingo davon aus, welche Faktoren den Pegel des „Rauschens“ in Tests beeinflussen sollten (das Konzept des „Rauschens“ im Bericht hat eine sehr spezifische Definition). Das Testteam schlug beispielsweise vor, dass bei „schweren“ Tests das Hauptrauschen von der Festplatte ausgeht oder dass Sie in der Cloud beim Verteilen von Ressourcen auf gute (vollständig zugewiesene) oder schlechte (gemeinsam mit) stoßen können von jemandem) Instanzen, die die Testergebnisse beeinflussen.
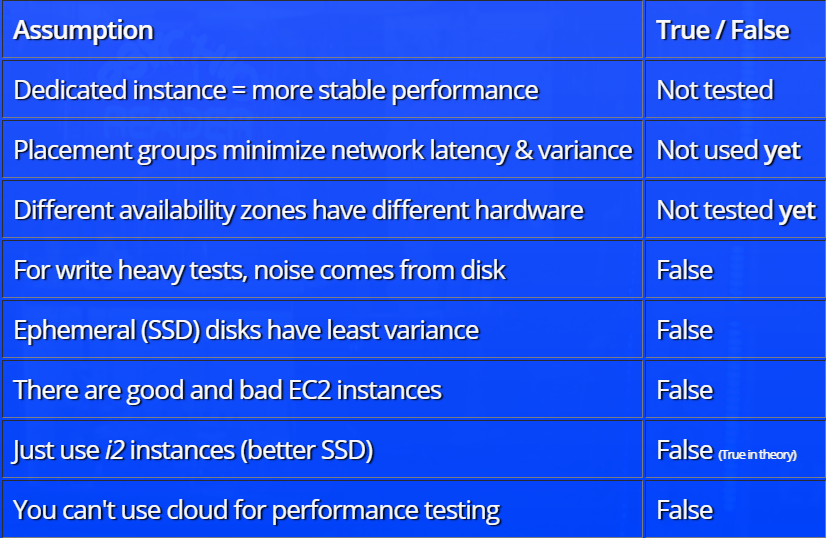
Danach werden die Ergebnisse des Testens jeder der Theorien mit einer Demonstration einiger interessanter Abhängigkeiten analysiert. Hier ist beispielsweise ein Diagramm der Abhängigkeit des Rauschpegels (in der Terminologie des Berichts) von der ausgewählten Instanzkonfiguration:
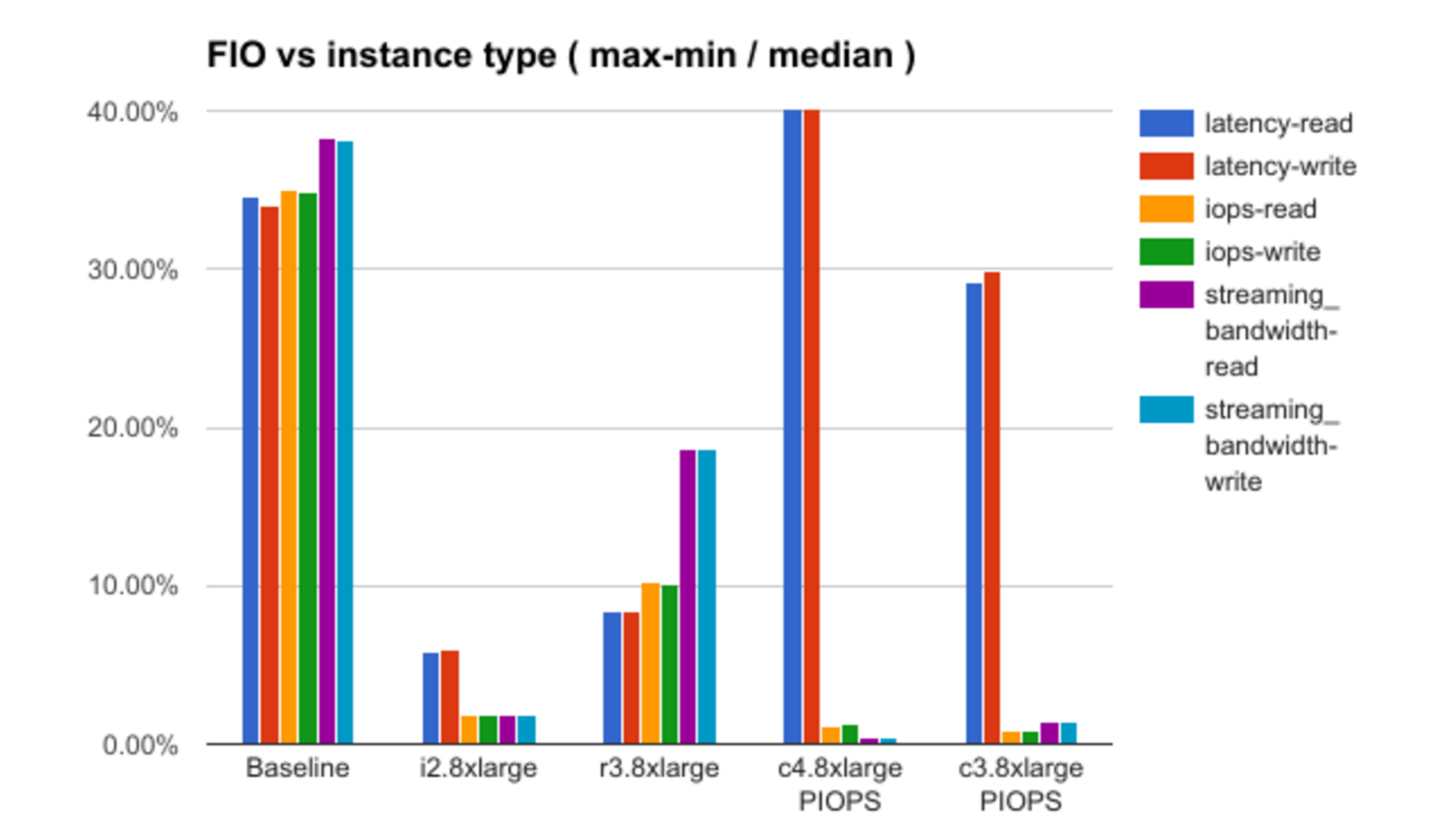
In Ermangelung von Informationen zu den Details der Amazon-Infrastruktur beantwortet der Bericht nicht alle Fragen, in einigen Fällen werden nur Annahmen getroffen, aber es gibt etwas zu überlegen.
Protokollieren und schimpfen
Vytis Valentinavičius (Lamoda, Betriebsleiter)Der nächste interessante Bericht sind die Gedanken eines Spezialisten in einem großen Lamoda-Online-Shop über die Protokollierung und wie es sein sollte, damit Entwickler einerseits die erforderlichen Daten vollständig erhalten und andererseits nicht in Gigabyte eingehender Informationen ertrinken. Und der Sprecher weiß, wovon er spricht. Das Problem, mit dem die Arbeit mit Protokollen in Lamoda erstellt wurde, ist der Verlust von 5% der von Benutzern über UDP gesendeten Berichte (in einigen Fällen erreichte dieser Anteil 100%). Dies verzerrte ernsthaft alle Metriken, die auf ihrer Basis erstellt werden konnten.
Der Bericht erklärt, wie man eine solche Situation nicht enträtselt, sondern im Prinzip verhindert, da viele offensichtliche Lösungen ihre Tücken haben.
Vytis Valentinavičius konzentriert sich auf die Tatsache, dass das Protokoll eine Struktur haben sollte. Gleichzeitig kann es aber nicht aufgeblasen werden. Es muss einen Zweck für das Sammeln und Speichern jedes Feldes geben, da alle gesammelten Daten Geld sind. Ein Beispiel für Lamoda sind 25.000 Debug-Protokollnachrichten pro Sekunde (32 TB Informationen pro Woche, für die allein der Speicher 12.000 US-Dollar kostet).
Darüber hinaus ist es wichtig, Ereignisse und nicht bestimmte Fehler zu verfolgen. Sie müssen aggregiert, Metriken identifiziert und auf ihrer Analyse basieren, um komplexere Ereignisse für die zukünftige Aggregation zu erstellen.
Zusätzlich zu theoretischen Überlegungen beschreibt der Bericht einige der Tricks, die Lamoda in der Produktion verwendet hat, um mit Protokollen zu arbeiten.
Metriken sind nicht genug: Überwachung von Apache Kafka
Gwen Shapira (Confluent, Produktmanager)Im nächsten Bericht geht es um die Überwachung von Apache Kafka bzw. darum, welche Metriken aus der Fülle der für die Analyse verfügbaren Parameter ausgewählt werden sollten, um den Status des Nachrichtenbrokers jederzeit zu verstehen.
Die Sprecherin begann ihre Geschichte mit einem Witz, in dem, wie sie sagen, nur ein Bruchteil des Witzes enthalten ist: "Auch wenn Sie sich nicht an den Inhalt des gesamten Berichts erinnern können, denken Sie an eines: Wenn Kafka in der Produktion verwendet wird, muss es überwacht werden" (gut, die entsprechende API wird dafür bereitgestellt )
Ist es notwendig, alles zu überwachen? Kommt auf die Aufgabe an. Von ihnen stößt Gwen Shapira ab und analysiert die empfohlenen Metriken. Der Redner beschreibt Standardbetriebsfälle und empfiehlt Parameter, die dem Dashboard hinzugefügt werden müssen, um auf das zu reagieren, was pünktlich geschieht, und um die Situation nicht zu verschlimmern. Insbesondere wird erneut darauf hingewiesen, dass es nicht erforderlich ist, den Broker bei der ersten Änderung der Metriken neu zu starten, da Dies nimmt viel Zeit in Anspruch und kann manchmal (aufgrund bekannter Fehler) zu schwerwiegenderen Konsequenzen führen. Letztendlich sind Metriken nur Anfangsdaten. Und um Entscheidungen treffen zu können, muss man Hypothesen haben, die auf diesen Daten basieren.

Dank der langjährigen Erfahrung von Gwen Shapira als Berater wird die gesamte Präsentation von lebendigen Beispielen aus dem Leben begleitet.
ProxySQL-Anwendungsfallszenarien
Alkin Tezuysal (Percona, globales DBA-Team)Zwei sofortige Berichte, die sich nach Schätzungen der Teilnehmer in TOP 5 befanden, beziehen sich auf ProxySQL, ein Mittel zum Proxying von SQL-Abfragen an MySQL (und in jüngerer Zeit an ClickHouse).
Der erste Bericht befasst sich im Allgemeinen mit Szenarien für die Verwendung dieses Tools.
ProxySQL ist eine Open-Source-Lösung, auf die wir bisher noch nicht gestoßen sind. Ja, viele Unternehmen laden diese Lösung herunter, aber selbst der Hersteller selbst versteht nicht immer, wer sie in welchem Umfang verwenden wird. Die in diesem Bericht gesammelten Szenarien wurden als Ergebnis der Kommunikation mit ProxySQL-Benutzern und der Analyse ihrer Fälle identifiziert.
Im Allgemeinen können Sie mit ProxySQL eine Vielzahl von Aufgaben lösen, von Lastausgleichs- und Umschreibeabfragen (die im nächsten Bericht aus unserer Liste erläutert werden) bis hin zur Abfragewarteschlange und dem Erwärmen des Caches, der nicht in MySQL enthalten ist. Jede der Optionen, die Alkin Tezuysal ausführlich analysiert, nennt die Vor- und Nachteile der Lösung sowie spezielle Fälle, in denen sie nützlich sein kann.
Hier erwähnen wir nur zwei Beispiele zur Optimierung der Datenbank.
Beispiel 1 - Verwenden von ProxySQL, um die Anzahl der Anforderungen zum Herstellen einer Anwendungsverbindung zur Datenbank zu verringern. Die Idee spiegelt sich grafisch in der im Bericht angegebenen Grafik wider:
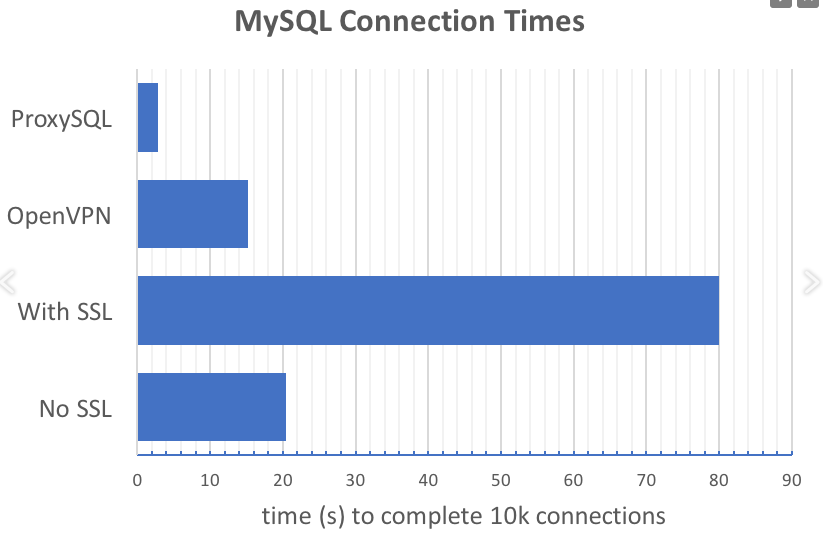
ProxySQL reduziert die Anzahl der Verbindungsanforderungen drastisch, insbesondere bei Verwendung von SSL.
Beispiel 2 - Filtern nutzloser Abfragen (wie SELECT 1, die sich in großen Anwendungen manifestieren), die die Datenbank verlangsamen. Hier lässt sich das Ergebnis auch am besten grafisch auswerten:

Preiswertes Datamasking für MySQL mit ProxySQL - Datenanonymisierung für Entwickler
Rene Cannao (Gründer und Produktbesitzer ProxySQL)Der zweite englischsprachige Bericht über ProxySQL, der in den TOP-5 aufgenommen wurde, befasst sich mit der Lösung eines ganz bestimmten Problems - der Datenmaskierung.
Nach einer kurzen Einführung in ProxySQL für diejenigen, die den ersten Bericht noch nicht gesehen haben, taucht der Sprecher in die Funktionen des Tools ein, um ein bestimmtes Problem zu lösen - indem er einen Teil des Namens versteckt (durch Sternchen ersetzt) oder den tatsächlichen Einkommensbetrag durch einen gefälschten ersetzt.
Wie der Redner feststellt, kann dieses Problem mit Ihren eigenen Mitteln mit denselben MySQL- oder Drittanbieterprodukten gelöst werden. Unter Drittanbietern ist ProxySQL bei weitem nicht das einzige Tool. Es gibt zwar keine ideale Lösung auf dem Markt, und ProxySQL ist nicht schlechter als viele andere, sodass Entwickler gültige Daten für Tests erhalten können, die keine echten persönlichen Informationen enthalten. Darüber hinaus hat es Open Source Code.
Wenn die erste Geschichte über ProxySQL theoretischer war, dann ist hier eine kontinuierliche Praxis. Sogar Regeln, die mit regulären Ausdrücken konfiguriert wurden, werden aufgelistet.

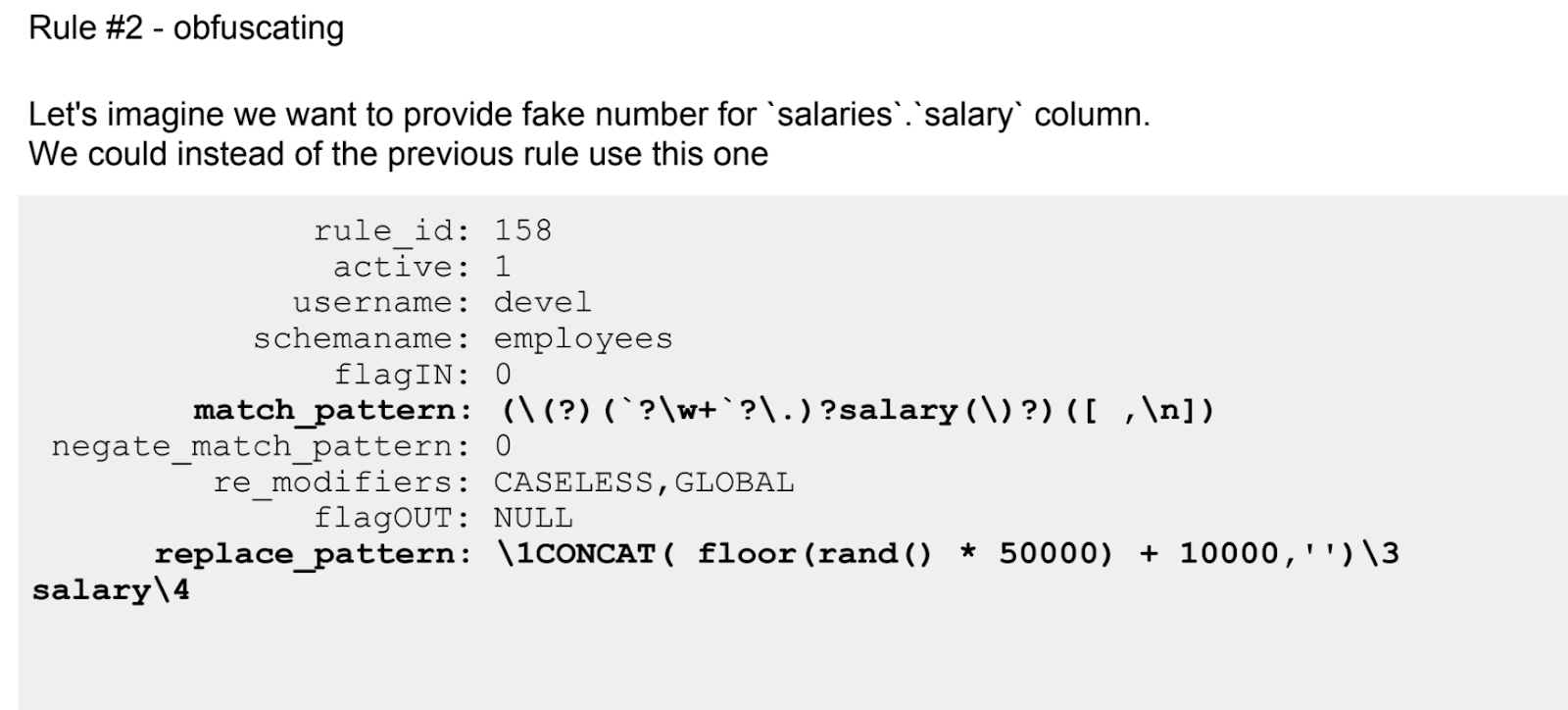
Wie jedes ProxySQL-Tool hat es seine Grenzen. Dies wird ebenfalls diskutiert. Insbesondere ist dies nicht der beste Ansatz für komplexe Transformationen.
Der Bericht endete mit einem umfassenden Abschnitt mit Fragen und Antworten, aus dem Sie auch viele nützliche und interessante Dinge lernen können.
Natürlich ist diese englischsprachige Fünf nur die Spitze des Eisbergs, der bei HighLoad ++ 2017 war. Daher erinnern wir uns, dass wir gerade Videos aller Konferenzberichte gepostet haben, die in
dieser Wiedergabeliste zu finden sind .
HighLoad ++ 2018 findet am 8. und 9. November in Moskau in Skolkovo statt. Die Arbeiten an dem Programm sind bereits im Gange, der Bericht kann jedoch vor dem 1. September eingereicht werden .