Alle Organisationen, die früher oder später zumindest etwas mit Daten zu tun haben, stehen vor dem Problem, relationale und unstrukturierte Datenbanken zu speichern. Es ist nicht einfach, gleichzeitig einen bequemen, effektiven und kostengünstigen Ansatz für dieses Problem zu finden. Und um sicherzustellen, dass Datenwissenschaftler erfolgreich mit Modellen für maschinelles Lernen arbeiten können. Wir haben es geschafft - und obwohl ich daran basteln musste, war der endgültige Gewinn sogar höher als erwartet. Wir werden alle Details unten besprechen.

Im Laufe der Zeit sammeln sich in jeder Bank unglaubliche Mengen an Unternehmensdaten an. Ein vergleichbarer Betrag wird nur in Internetunternehmen und Telekommunikationsunternehmen gespeichert. Dies geschah aufgrund der hohen regulatorischen Anforderungen. Diese Daten liegen nicht im Leerlauf - die Leiter von Finanzinstituten haben lange herausgefunden, wie sie davon profitieren können.
Wir haben alle mit Management und Finanzberichterstattung begonnen. Basierend auf diesen Daten haben wir gelernt, wie man Geschäftsentscheidungen trifft. Oft mussten Daten aus mehreren Informationssystemen der Bank abgerufen werden, für die wir konsolidierte Datenbanken und Berichtssysteme erstellt haben. Daraus bildete sich nach und nach ein sogenanntes Data Warehouse. Auf der Grundlage dieses Speichers begannen bald unsere anderen Systeme zu funktionieren:
- analytisches CRM, das es dem Kunden ermöglicht, bequemere Produkte für ihn anzubieten;
- Kreditförderer, die Ihnen helfen, schnell und genau eine Kreditentscheidung zu treffen;
- Treue-Systeme, die Cashback- oder Bonuspunkte nach Mechanismen unterschiedlicher Komplexität berechnen.
All diese Aufgaben werden durch analytische Anwendungen gelöst, die Modelle für maschinelles Lernen verwenden. Je mehr Informationsmodelle aus dem Repository entnommen werden können, desto genauer funktionieren sie. Ihr Datenbedarf wächst exponentiell.
Über diese Situation kamen wir vor zwei oder drei Jahren. Zu diesem Zeitpunkt hatten wir einen Speicher, der auf dem MPP Teradata DBMS mit dem SAS Data Integration Studio ELT-Tool basierte. Wir haben dieses Lagerhaus seit 2011 zusammen mit Glowbyte Consulting gebaut. Es wurden mehr als 15 große Bankensysteme integriert, und gleichzeitig wurden genügend Daten für die Implementierung und Entwicklung analytischer Anwendungen gesammelt. Übrigens begann gerade zu diesem Zeitpunkt die Datenmenge in den Hauptschichten des Geschäfts aufgrund vieler verschiedener Aufgaben nicht linear zu wachsen, und fortschrittliche Kundenanalysen wurden zu einer der Hauptrichtungen der Bankentwicklung. Ja, und unsere Datenwissenschaftler wollten sie unbedingt unterstützen. Um die Datenforschungsplattform aufzubauen, bildeten sich die Sterne im Allgemeinen so, wie sie sollten.
Eine Lösung planen
Hier muss erklärt werden: Industrielle Software und Server sind selbst für eine große Bank ein teures Vergnügen. Nicht jedes Unternehmen kann es sich leisten, eine große Datenmenge im Top-MPP-DBMS zu speichern. Sie müssen immer zwischen Preis und Geschwindigkeit, Zuverlässigkeit und Volumen wählen.
Um die verfügbaren Möglichkeiten optimal zu nutzen, haben wir uns dazu entschlossen:
- Die ELT-Last und der am häufigsten angeforderte Teil der historischen Daten der CD sollten im Teradata-DBMS verbleiben.
- Senden Sie die ganze Geschichte an Hadoop, wodurch Sie Informationen viel billiger speichern können.
Zu dieser Zeit wurde das Hadoop-Ökosystem nicht nur modisch, sondern auch ausreichend zuverlässig und praktisch für den Einsatz in Unternehmen. Es war notwendig, ein Verteilungskit zu wählen. Sie können Ihre eigenen erstellen oder den offenen Apache Hadoop verwenden. Unter den auf Hadoop basierenden Unternehmenslösungen haben sich vorgefertigte Distributionen anderer Anbieter - Cloudera und Hortonworks - jedoch mehr bewährt. Aus diesem Grund haben wir uns auch für eine fertige Distribution entschieden.
Da unsere Hauptaufgabe immer noch darin bestand, strukturierte Big Data zu speichern, waren wir im Hadoop-Stack an Lösungen interessiert, die den klassischen SQL-DBMS so nahe wie möglich kommen. Die Führer hier sind Impala und Hive. Cloudera entwickelt und integriert Impala, Hortonworks - Hive-Lösungen.
Für eine eingehende Studie haben wir Lasttests für beide DBMS unter Berücksichtigung der Profillast für uns organisiert. Ich muss sagen, dass sich die Datenverarbeitungs-Engines in Impala und Hive erheblich unterscheiden - Hive bietet im Allgemeinen verschiedene Optionen. Die Wahl fiel jedoch auf Impala - und dementsprechend auf die Verteilung von Cloudera.
Was mir an Impala gefallen hat
- Hohe Ausführungsgeschwindigkeit von analytischen Abfragen aufgrund eines alternativen Ansatzes in Bezug auf MapReduce. Zwischenergebnisse von Berechnungen werden in HDFS nicht gefaltet, was die Datenverarbeitung erheblich beschleunigt.
- Effiziente Arbeit mit der Speicherung von Parkettdaten in Parkett . Für analytische Aufgaben werden häufig die sogenannten breiten Tabellen mit vielen Spalten verwendet. Alle Spalten werden selten verwendet. Wenn Sie nur die für die Arbeit erforderlichen Spalten aus HDFS abrufen können, können Sie RAM sparen und die Anforderung erheblich beschleunigen.
- Eine elegante Lösung mit Laufzeitfiltern mit Bloom-Filterung. Sowohl Hive als auch Impala sind aufgrund der Art des HDFS-Dateispeichersystems in ihrer Verwendung von Indizes, die klassischen DBMS gemeinsam sind, erheblich eingeschränkt. Um die Ausführung der SQL-Abfrage zu optimieren, sollte die DBMS-Engine daher die verfügbare Partitionierung effektiv verwenden, auch wenn sie in den Abfragebedingungen nicht explizit angegeben ist. Außerdem muss er versuchen, vorherzusagen, welche Mindestdatenmenge von HDFS für eine garantierte Verarbeitung aller Zeilen erhöht werden muss. In Impala funktioniert das sehr gut.
- Impala verwendet LLVM , einen Compiler für virtuelle Maschinen mit RISC-ähnlichen Anweisungen, um den optimalen SQL-Abfrageausführungscode zu generieren.
- ODBC- und JDBC-Schnittstellen werden unterstützt. Auf diese Weise können Sie Impala-Daten fast sofort in Analysetools und -anwendungen integrieren.
- Es ist möglich, Kudu zu verwenden, um einige der Einschränkungen von HDFS zu umgehen und insbesondere UPDATE- und DELETE-Konstrukte in SQL-Abfragen zu schreiben.
Sqoop und der Rest der Architektur
Das nächstwichtigste Tool auf dem Hadoop-Stack war für uns Sqoop. Sie können damit Daten zwischen relationalem DBMS (wir waren natürlich an Teradata interessiert) und HDFS in einem Hadoop-Cluster in verschiedenen Formaten, einschließlich Parkett, übertragen. In Tests zeigte Sqoop eine hohe Flexibilität und Leistung, daher haben wir uns für die Verwendung entschieden - anstatt eigene Tools zum Erfassen von Daten über ODBC / JDBC und zum Speichern in HDFS zu entwickeln.
Für Trainingsmodelle und verwandte Aufgaben von Data Science, die bequemer direkt auf dem Hadoop-Cluster ausgeführt werden können, haben wir Apache
Spark verwendet . Auf seinem Gebiet ist es zu einer Standardlösung geworden - und es gibt einen Grund:
- Spark ML-Bibliotheken für maschinelles Lernen
- Unterstützung für vier Programmiersprachen (Scala, Java, Python, R);
- Integration mit Analysewerkzeugen;
- Die speicherinterne Datenverarbeitung bietet eine hervorragende Leistung.
Der Oracle Big Data Appliance-Server wurde als Hardwareplattform gekauft. Wir haben mit sechs Knoten in einer produktiven Schaltung mit einer 2x24-Kern-CPU und jeweils 256 GB Speicher begonnen. Die aktuelle Konfiguration enthält 18 gleiche Knoten mit bis zu 512 GB Speicher.
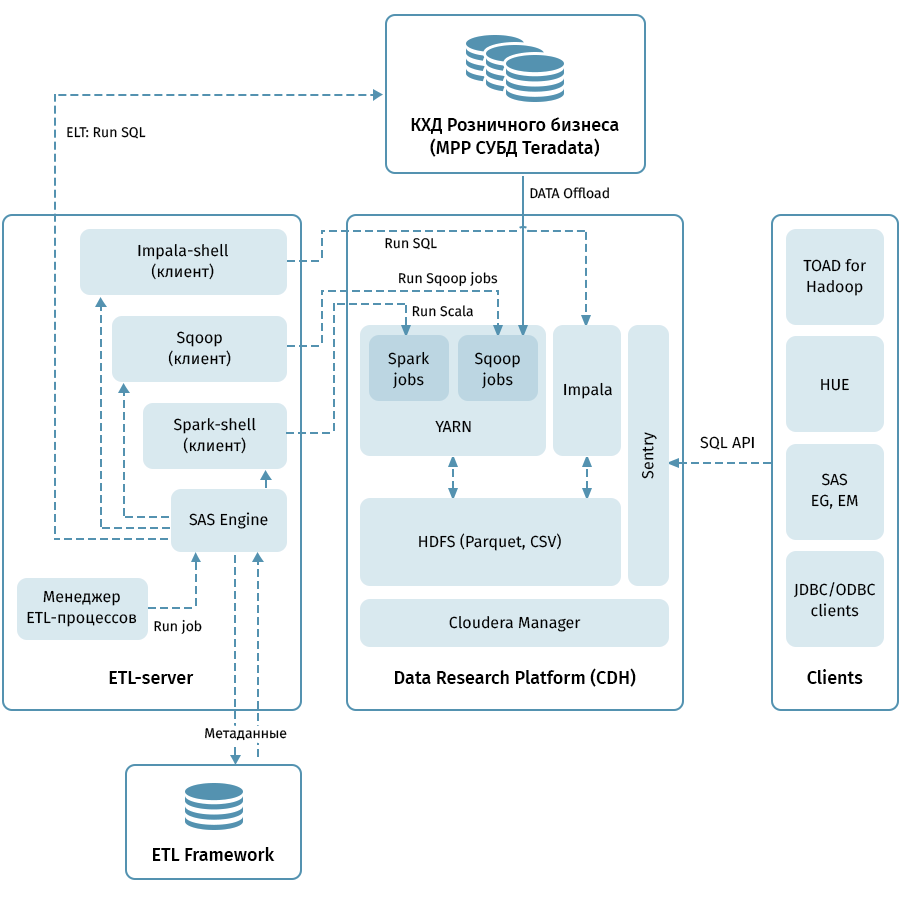
Das Diagramm zeigt die Architektur der obersten Ebene der Datenforschungsplattform und verwandter Systeme. Die zentrale Verbindung ist der Hadoop-Cluster, der auf der Cloudera (CDH) -Distribution basiert. Es wird sowohl zum Empfangen mit Sqoop als auch zum Speichern von QCD-Daten in HDFS verwendet - im Parkettformat, wodurch Codecs für die Komprimierung verwendet werden können, z. B. Snappy. Der Cluster verarbeitet auch Daten: Impala wird für ELT-ähnliche Transformationen verwendet, Spark - für Data Science-Aufgaben. Sentry wird verwendet, um den Datenzugriff gemeinsam zu nutzen.
Impala verfügt über Schnittstellen für fast alle modernen Unternehmensanalysetools. Darüber hinaus können beliebige Tools, die ODBC / JDBC-Schnittstellen unterstützen, als Clients verbunden werden. Für die Arbeit mit SQL betrachten wir Hue und TOAD für Hadoop als Hauptclients.
Ein ETL-Subsystem, das aus SAS-Tools (Metadata Server, Data Integration Studio) und einem ETL-Framework besteht, das auf der Basis von SAS- und Shell-Skripten unter Verwendung einer Datenbank zum Speichern von Metadaten von ETL-Prozessen geschrieben wurde, wird zum Verwalten aller durch Pfeile im Diagramm angegebenen Flüsse verwendet. . Anhand der in den Metadaten angegebenen Regeln startet das ETL-Subsystem Datenverarbeitungsprozesse sowohl auf QCD als auch auf der Data Research Platform. Infolgedessen verfügen wir über ein End-to-End-System zur Überwachung und Verwaltung des Datenflusses unabhängig von der verwendeten Umgebung (Teradata, Impala, Spark usw., falls erforderlich).
Durch den Rechen zu den Sternen
Das Entladen von QCD scheint einfach zu sein. Bei der Ein- und Ausgabe von relationalem DBMS werden Daten über Sqoop übertragen. Nach der obigen Beschreibung zu urteilen, verlief bei uns alles reibungslos, aber natürlich war es nicht ohne Abenteuer, und dies ist vielleicht der interessanteste Teil des gesamten Projekts.

Mit unserem Volumen konnten wir nicht hoffen, alle Daten jeden Tag vollständig zu übertragen. Dementsprechend musste von jedem Speicher gelernt werden, wie ein zuverlässiges Inkrement unterschieden werden kann, was nicht immer einfach ist, wenn sich Daten für historische Geschäftstermine in der Tabelle ändern können. Um dieses Problem zu lösen, haben wir Objekte in Abhängigkeit von den Methoden zum Laden und Verwalten des Verlaufs systematisiert. Dann wurden für jeden Typ das richtige Prädikat für Sqoop und die Methode zum Laden in den Empfänger bestimmt. Und schließlich schrieben sie Anweisungen für Entwickler neuer Objekte.
Sqoop ist ein sehr hochwertiges Werkzeug, aber nicht in allen Fällen und Systemkombinationen funktioniert es absolut zuverlässig. Auf unseren Volumes funktionierte der Konnektor zu Teradata nicht optimal. Wir haben den Open Source Code von Sqoop genutzt und Änderungen an den Connector-Bibliotheken vorgenommen. Die Stabilität der Verbindung beim Verschieben von Daten hat zugenommen.
Wenn Sqoop Teradata aufruft, werden Prädikate aus irgendeinem Grund nicht ganz korrekt in WHERE-Bedingungen konvertiert. Aus diesem Grund versucht Sqoop manchmal, einen riesigen Tisch herauszuziehen und später zu filtern. Wir konnten den Connector hier nicht patchen, haben aber einen anderen Weg gefunden: Erstellen Sie zwangsweise eine temporäre Tabelle mit einem auferlegten Prädikat für jedes entladene Objekt und bitten Sie Sqoop, es zu überfüllen.
Alle MPP und insbesondere Teradata verfügen über eine Funktion zur parallelen Datenspeicherung und Befehlsausführung. Wenn diese Funktion nicht berücksichtigt wird, kann sich herausstellen, dass die gesamte Arbeit von einem logischen Knoten des Clusters übernommen wird, wodurch die Ausführung der Abfrage einmal in 100-200 erheblich verlangsamt wird. Dies konnten wir natürlich nicht zulassen. Deshalb haben wir eine spezielle Engine geschrieben, die ETL-Metadaten von QCD-Tabellen verwendet und den optimalen Parallelisierungsgrad für Sqoop-Aufgaben auswählt.
Die historische Speicherkapazität ist eine heikle Angelegenheit, insbesondere wenn Sie
SCD2 verwenden , während Impala UPDATE und DELETE nicht unterstützt. Natürlich möchten wir, dass die historischen Tabellen in der Data Research Platform genauso aussehen wie in Teradata. Dies kann erreicht werden, indem das Empfangsinkrement über Sqoop kombiniert, aktualisierte Geschäftsschlüssel hervorgehoben und Partitionen in Impala gelöscht werden. Damit diese ausgefeilte Logik nicht von jedem Entwickler geschrieben werden muss, haben wir sie in eine spezielle Bibliothek gepackt (auf unserem ETL-Slang „Loader“).
Endlich - eine Frage mit Datentypen. Impala kann kostenlos konvertiert werden, daher sind einige Probleme nur bei den Typen TIMESTAMP und CHAR / VARCHAR aufgetreten. Für Datum und Uhrzeit haben wir beschlossen, Daten in Impala im Textformat (STRING) zu speichern. JJJJ-MM-TT HH: MM: SS. Wie sich herausstellte, ermöglicht dieser Ansatz die Verwendung der Funktionen zur Transformation von Datum und Uhrzeit. Bei Zeichenfolgendaten einer bestimmten Länge stellte sich heraus, dass das Speichern im STRING-Format in Impala diesen nicht unterlegen ist. Daher haben wir es auch verwendet.
Für die Organisation von Data Lake kopieren sie normalerweise Quelldaten in halbstrukturierten Formaten in einen speziellen Phasenbereich in Hadoop. Anschließend richten Hive oder Impala ein Deserialisierungsschema für diese Daten zur Verwendung in SQL-Abfragen ein. Wir sind den gleichen Weg gegangen. Es ist wichtig zu beachten, dass nicht alles und es nicht immer sinnvoll ist, das Data Warehouse zu ziehen, da die Entwicklung von Dateikopierprozessen und die Installation des Schemas viel billiger ist als das Laden von Geschäftsattributen in das QCD-Modell mithilfe von ETL-Prozessen. Wenn immer noch nicht klar ist, wie viel, wie lange und mit welcher Häufigkeit die Quelldaten benötigt werden, ist Data Lake im beschriebenen Ansatz eine einfache und kostengünstige Lösung. Jetzt laden wir regelmäßig hauptsächlich Quellen auf Data Lake hoch, die Benutzerereignisse generieren: Anwendungsanalysedaten, Protokolle und Übergangsszenarien für Avaya Auto Dialer und Anrufbeantworter, Kartentransaktionen.
Analyst Toolkit
Wir haben ein weiteres Ziel des gesamten Projekts nicht vergessen - Analysten die Möglichkeit zu geben, all diesen Reichtum zu nutzen. Hier sind die Grundprinzipien, die uns hierher geführt haben:
- Bequemlichkeit des Tools in Gebrauch und Support
- Anwendbarkeit in Data Science-Aufgaben
- Die maximale Möglichkeit, die Computerressourcen des Hadoop-Clusters anstelle von Anwendungsservern oder dem Computer des Forschers zu verwenden
Und hier ist, wo wir angehalten haben:
- Python + Anaconda. Die verwendete Umgebung ist iPython / Jupyter
- R + Shiny. Der Forscher arbeitet in der Desktop- oder Webversion von R Studio. Shiny wird verwendet, um Webanwendungen zu entwickeln, die durch die Verwendung von in R entwickelten Algorithmen geschärft werden.
- Funke Für die Arbeit mit Daten werden die Schnittstellen für Python (pyspark) und R verwendet, die in den in den vorherigen Absätzen angegebenen Entwicklungsumgebungen konfiguriert sind. Mit beiden Schnittstellen können Sie die Spark ML-Bibliothek verwenden, mit der Sie ML-Modelle im Hadoop / Spark-Cluster trainieren können.
- Auf Impala-Daten kann über Hue, Spark und aus Entwicklungsumgebungen über die Standard-ODBC-Schnittstelle und spezielle Bibliotheken wie implyr zugegriffen werden
Derzeit enthält Data Lake etwa 100 TB Daten aus dem Einzelhandelsspeicher sowie etwa 50 TB Daten aus einer Reihe von OLTP-Quellen. Der See wird täglich schrittweise aktualisiert. In Zukunft werden wir den Benutzerkomfort erhöhen, eine ELT-Belastung für Impala einführen, die Anzahl der auf Data Lake hochgeladenen Quellen erhöhen und die Möglichkeiten für erweiterte Analysen erweitern.
Abschließend möchte ich Kollegen, die gerade ihre Reise mit der Erstellung großer Repositories beginnen, einige allgemeine Ratschläge geben:
- Verwenden Sie Best Practices. Wenn wir kein ETL-Subsystem, keine Metadaten, keinen versionierten Speicher und keine verständliche Architektur hätten, hätten wir diese Aufgabe nicht gemeistert. Best Practices machen sich bezahlt, wenn auch nicht sofort.
- Merken Sie sich die Datenmenge. Big Data kann an sehr unerwarteten Orten zu technischen Schwierigkeiten führen.
- Seien Sie gespannt auf neue Technologien. Neue Lösungen erscheinen oft, nicht alle sind nützlich, aber manchmal werden echte Juwelen gefunden.
- Experimentieren Sie mehr. Vertrauen Sie nicht nur den Marketingbeschreibungen der Lösungen - probieren Sie es selbst aus.
Übrigens können Sie in einem separaten Beitrag nachlesen, wie unsere Analysten maschinelles Lernen und Bankdaten verwendet haben, um mit Kreditrisiken umzugehen.