Eines der Haupthindernisse für die Einführung des maschinellen Lernens in Unternehmen ist heute die Inkompatibilität von ML-Metriken und -Indikatoren, mit denen das Top-Management arbeitet. Analyst prognostiziert Gewinnsteigerung? Sie müssen jedoch verstehen, in welchen Fällen maschinelles Lernen die Ursache für den Anstieg sein wird und in welchen anderen Faktoren. Leider führt die Verbesserung der ML-Kennzahlen häufig nicht zu einem Gewinnwachstum. Darüber hinaus ist die Komplexität der Daten manchmal so hoch, dass selbst erfahrene Entwickler falsche Metriken auswählen können, die nicht ausgerichtet werden können.
Schauen wir uns an, was ML-Metriken sind und wann sie verwendet werden können. Wir werden häufige Fehler analysieren und darüber sprechen, welche Optionen zur Behebung des Problems für maschinelles Lernen und Unternehmen geeignet sind.
ML-Metriken: Warum gibt es so viele?
Die Metriken für maschinelles Lernen sind sehr spezifisch und oft irreführend und zeigen ein
gutes Gesicht bei einem schlechten Spiel, ein gutes Ergebnis für schlechte Modelle. Um Modelle zu testen und zu verbessern, müssen Sie eine Metrik auswählen, die die Qualität des Modells und dessen Messung angemessen widerspiegelt. Normalerweise wird ein separater Testdatensatz verwendet, um die Qualität des Modells zu bewerten. Und wie Sie wissen, ist die Auswahl der richtigen Metrik eine schwierige Aufgabe.
Welche Aufgaben werden am häufigsten mit Hilfe des maschinellen Lernens gelöst? Dies ist vor allem Regression, Klassifizierung und Clustering. Die ersten beiden sind das sogenannte Training mit dem Lehrer: Es gibt eine Reihe von beschrifteten Daten, basierend auf einigen Erfahrungen müssen Sie den eingestellten Wert vorhersagen. Regression ist eine Vorhersage von einem gewissen Wert: Zum Beispiel, wie viel der Kunde kaufen wird, wie hoch die Verschleißfestigkeit des Materials ist, wie viele Kilometer das Auto vor der ersten Panne fahren wird.
Clustering ist die Definition einer Datenstruktur durch Hervorheben von Clustern (z. B. Kundenkategorien), und wir haben keine Annahmen über diese Cluster. Wir werden diese Art von Problem nicht berücksichtigen.
Algorithmen für maschinelles Lernen optimieren (durch Berechnung der Verlustfunktion) die mathematische Metrik - die Differenz zwischen der Modellvorhersage und dem wahren Wert. Wenn die Metrik jedoch die Summe der Abweichungen ist, ist diese Summe bei gleicher Anzahl von Abweichungen in beide Richtungen Null, und wir wissen einfach nicht, ob ein Fehler vorliegt. Daher verwenden sie normalerweise das mittlere Absolut (die Summe der absoluten Werte der Abweichungen) oder den mittleren quadratischen Fehler (die Summe der Quadrate der Abweichungen vom wahren Wert). Manchmal ist die Formel kompliziert: Nehmen Sie den Logarithmus oder extrahieren Sie die Quadratwurzel dieser Summen. Dank dieser Metriken können Sie die Dynamik der Qualität der Modellberechnungen bewerten. Dazu müssen Sie jedoch das Ergebnis mit etwas vergleichen.
Dies wird nicht schwierig sein, wenn es bereits ein Modell gibt, mit dem die Ergebnisse verglichen werden können. Aber was ist, wenn Sie zum ersten Mal ein Modell erstellt haben? In diesem Fall wird häufig der Bestimmungskoeffizient R2 verwendet. Der Bestimmungskoeffizient wird ausgedrückt als:
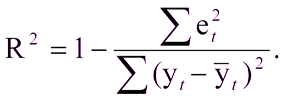
Wo:
R ^ 2 - Bestimmungskoeffizient,
e
t ^ 2 ist der mittlere quadratische Fehler,
y
t ist der richtige Wert,
y
t mit einer Abdeckung ist der Durchschnittswert.
Einheit abzüglich des Verhältnisses des mittleren quadratischen Fehlers des Modells zum mittleren quadratischen Fehler des Durchschnittswerts der Testprobe.Das heißt, der Bestimmungskoeffizient ermöglicht es uns, die Verbesserung der Vorhersage durch das Modell zu bewerten.
Manchmal kommt es vor, dass ein Fehler in einer Richtung nicht einem Fehler in der anderen entspricht. Wenn ein Modell beispielsweise eine Bestellung von Waren im Lager eines Lagers vorhersagt, ist es durchaus möglich, einen Fehler zu machen und etwas mehr zu bestellen. Die Waren warten im Lager auf ihre Zeit. Und wenn das Modell einen Fehler in die andere Richtung macht und weniger bestellt, können Sie Kunden verlieren. In solchen Fällen wird ein Quantilfehler verwendet: Positive und negative Abweichungen vom wahren Wert werden mit unterschiedlichen Gewichten berücksichtigt.
Bei dem Klassifizierungsproblem verteilt das Modell des maschinellen Lernens Objekte in zwei Klassen: Der Benutzer verlässt die Site oder verlässt sie nicht, das Teil ist defekt oder nicht usw. Die Vorhersagegenauigkeit wird häufig als Verhältnis der Anzahl korrekt definierter Klassen zur Gesamtzahl der Vorhersagen geschätzt. Diese Eigenschaft kann jedoch selten als adäquater Parameter angesehen werden.
 Abb. 1. Fehlermatrix für das Problem der Vorhersage der KundenrückgabeBeispiel
Abb. 1. Fehlermatrix für das Problem der Vorhersage der KundenrückgabeBeispiel : Wenn 7 von 100 Versicherten eine Entschädigung beantragen, hat das Modell, das das Fehlen eines versicherten Ereignisses vorhersagt, eine Genauigkeit von 93% ohne Vorhersagekraft.
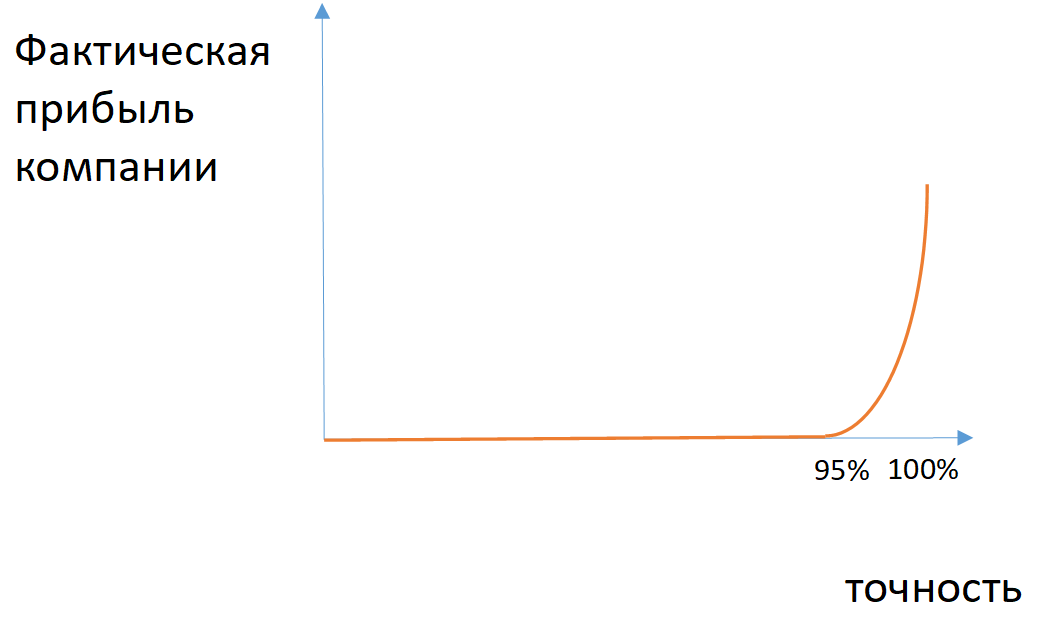 Abb. 2. Ein Beispiel für die Abhängigkeit des tatsächlichen Gewinns des Unternehmens von der Genauigkeit des Modells bei unausgeglichenen Klassen
Abb. 2. Ein Beispiel für die Abhängigkeit des tatsächlichen Gewinns des Unternehmens von der Genauigkeit des Modells bei unausgeglichenen KlassenFür einige Aufgaben können Sie die Metriken der Vollständigkeit (die Anzahl der korrekt definierten Objekte der Klasse unter allen Objekten dieser Klasse) und der Genauigkeit (die Anzahl der korrekt definierten Objekte der Klasse unter allen Objekten, die das Modell dieser Klasse zugewiesen hat) anwenden. Wenn sowohl die Vollständigkeit als auch die Genauigkeit berücksichtigt werden müssen, wenden Sie das harmonische Mittel zwischen diesen Werten an (F1-Maß).
Mit diesen Metriken können Sie die durchgeführten Klassifizierungen auswerten. Viele Modelle sagen jedoch die Wahrscheinlichkeit der Beziehung eines Modells zu einer bestimmten Klasse voraus. Unter diesem Gesichtspunkt ist es möglich, den Wahrscheinlichkeitsschwellenwert zu ändern, in Bezug auf den die Elemente der einen oder anderen Klasse zugeordnet werden (wenn der Client beispielsweise mit einer Wahrscheinlichkeit von 60% abreist, kann dies als verbleibend betrachtet werden). Wenn kein bestimmter Schwellenwert festgelegt ist, kann zur Bewertung der Wirksamkeit des Modells ein Diagramm der Abhängigkeit von Metriken von verschiedenen Schwellenwerten (
ROC-Kurve oder PR-Kurve ) erstellt werden, wobei die Fläche unter der ausgewählten Kurve als Metrik verwendet wird.
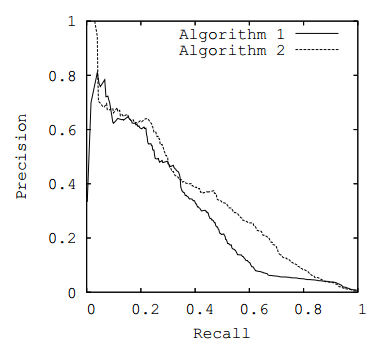 Abb. 3. PR-Kurve
Abb. 3. PR-KurveGeschäftsmetriken
Allegorisch gesehen sind Geschäftsmetriken Elefanten: Sie können nicht übersehen werden, und in einen solchen „Elefanten“ kann eine große Anzahl maschinell lernender „Papageien“ passen. Die Antwort auf die Frage, welche ML-Metriken den Gewinn steigern, hängt von der Verbesserung ab. Tatsächlich sind Geschäftsmetriken irgendwie mit steigenden Gewinnen verbunden, aber wir schaffen es fast nie, Gewinne direkt mit ihnen zu verknüpfen. Zwischenmetriken werden häufig verwendet, zum Beispiel:
- die Dauer der Waren auf Lager und die Anzahl der Anfragen nach Waren, wenn diese nicht verfügbar sind;
- den Geldbetrag, den Kunden im Begriff sind zu verlassen;
- die Menge an Material, die im Herstellungsprozess eingespart wird.
Wenn es darum geht, ein Unternehmen mithilfe von maschinellem Lernen zu optimieren, müssen immer zwei Modelle erstellt werden: Vorhersage und Optimierung.
Der erste ist komplizierter, der zweite nutzt seine Ergebnisse. Fehler im Vorhersagemodell zwingen uns, einen größeren Spielraum im Optimierungsmodell zu legen, sodass der optimierte Betrag reduziert wird.
Beispiel :
Je geringer die Genauigkeit der Vorhersage des Kundenverhaltens oder die Wahrscheinlichkeit von Industriemängeln ist, desto weniger Kunden können behalten und desto weniger Material wird eingespart.
Die allgemein anerkannten Kennzahlen für den Geschäftserfolg (EBITDA usw.) werden beim Festlegen von ML-Aufgaben selten ermittelt. Normalerweise müssen Sie die Besonderheiten gründlich studieren und die in dem Bereich, in dem wir maschinelles Lernen einführen, akzeptierten Metriken anwenden (durchschnittliche Überprüfung, Teilnahme usw.).
Übersetzungsschwierigkeiten
Ironischerweise ist es am bequemsten, Modelle mithilfe von Metriken zu optimieren, die für Unternehmensvertreter schwer zu verstehen sind. In welcher Beziehung steht die Fläche unter der ROC-Kurve im Kommentar-Tonalitätsmodell zu einer bestimmten Umsatzgröße? Unter diesem Gesichtspunkt steht das Unternehmen vor zwei Aufgaben: Wie kann gemessen und wie kann der Effekt der Einführung von maschinellem Lernen maximiert werden?
Die erste Aufgabe ist einfacher zu lösen, wenn Sie retrospektive Daten haben und gleichzeitig andere Faktoren eingeebnet oder gemessen werden können. Dann hindert Sie nichts daran, die erhaltenen Werte mit ähnlichen retrospektiven Daten zu vergleichen. Es gibt jedoch eine Komplikation: Die Stichprobe muss repräsentativ und gleichzeitig derjenigen ähnlich sein, mit der wir das Modell testen.
Beispiel : Sie müssen die ähnlichsten Kunden finden, um herauszufinden, ob sich ihr durchschnittlicher Scheck erhöht hat. Gleichzeitig sollte die Stichprobe der Kunden groß genug sein, um Spannungsspitzen aufgrund ungewöhnlichen Verhaltens zu vermeiden. Dieses Problem kann gelöst werden, indem zunächst eine ausreichend große Auswahl ähnlicher Kunden erstellt und das Ergebnis ihrer Bemühungen überprüft wird.
Möglicherweise fragen Sie sich jedoch: Wie übersetzt man die ausgewählte Metrik in eine Verlustfunktion (die das Modell minimiert) für maschinelles Lernen? Diese Aufgabe kann nicht sofort gelöst werden: Die Entwickler des Modells müssen sich eingehend mit Geschäftsprozessen befassen. Wenn Sie jedoch beim Trainieren des Modells eine vom Unternehmen abhängige Metrik verwenden, steigt die Qualität der Modelle sofort. Wenn das Modell vorhersagt, welche Kunden das Unternehmen verlassen werden, können Sie in der Rolle einer Geschäftsmetrik ein Diagramm verwenden, in dem die Anzahl der Kunden, die das Modell verlassen, auf einer Achse und der Gesamtbetrag der Mittel für diese Kunden auf der anderen Achse dargestellt wird. Mit Hilfe eines solchen Zeitplans kann ein Geschäftskunde einen für ihn geeigneten Punkt auswählen und damit arbeiten. Wenn wir den Graphen mithilfe linearer Transformationen auf eine PR-Kurve reduzieren (Genauigkeit auf einer Achse, zweite Vollständigkeit), können wir den Bereich unter dieser Kurve gleichzeitig mit der Geschäftsmetrik optimieren.
 Abb. 4. Geldeffektkurve
Abb. 4. GeldeffektkurveFazit
Bevor Sie die Aufgabe für maschinelles Lernen festlegen und ein Modell erstellen, müssen Sie eine angemessene Metrik auswählen. Wenn Sie das Modell optimieren möchten, können Sie eine der Standardmetriken als Fehlerfunktion verwenden. Stellen Sie sicher, dass Sie die ausgewählte Metrik, ihre Gewichte und andere Parameter mit dem Kunden koordinieren und Geschäftsmetriken in ML-Modelle konvertieren. In Bezug auf die Dauer kann dies mit der Entwicklung des Modells selbst verglichen werden, aber ohne dies macht es keinen Sinn, mit der Arbeit zu beginnen. Wenn Sie Mathematiker in das Studium von Geschäftsprozessen einbeziehen, können Sie die Wahrscheinlichkeit von Fehlern in den Metriken erheblich verringern. Eine effektive Optimierung des Modells ist ohne ein Verständnis des Themenbereichs und eine gemeinsame Erklärung des Problems auf der Ebene von Wirtschaft und Statistik nicht möglich. Und nach all den Berechnungen können Sie den Gewinn (oder die Einsparungen) abhängig von jeder Verbesserung des Modells bewerten.
Nikolay Knyazev ( iRumata ), Leiter der Gruppe für maschinelles Lernen, Jet Infosystems