
In letzter Zeit war Phishing für Cyberkriminelle die einfachste und beliebteste Möglichkeit, Geld oder Informationen zu stehlen. Zum Beispiel müssen Sie nicht weit gehen. Im vergangenen Jahr waren führende russische Unternehmen einem beispiellosen Angriff ausgesetzt - Angreifer registrierten massiv gefälschte Ressourcen, exakte Kopien der Standorte von Düngemittel- und Petrochemieherstellern, um in ihrem Namen Verträge abzuschließen. Der durchschnittliche Schaden durch einen solchen Angriff beträgt 1,5 Millionen Rubel, ganz zu schweigen von dem Reputationsschaden, den das Unternehmen erleidet. In diesem Artikel wird erläutert, wie Phishing-Sites mithilfe von Ressourcenanalysen (CSS, JS-Bilder usw.) anstelle von HTML effektiv erkannt werden und wie ein Data Science-Spezialist diese Probleme lösen kann.
Pavel Slipenchuk, Architekt für maschinelle Lernsysteme, Gruppe-IB
Die Phishing-Epidemie
Laut Group-IB werden allein in Russland täglich mehr als 900 Kunden verschiedener Banken Opfer von Finanz-Phishing - dies ist das Dreifache der täglichen Zahl von Malware-Opfern. Der Schaden durch einen Phishing-Angriff auf einen Benutzer variiert zwischen 2.000 und 50.000 Rubel. Betrüger kopieren nicht nur die Website eines Unternehmens oder einer Bank, ihre Logos und Firmenfarben, Inhalte, Kontaktdaten, registrieren einen ähnlichen Domainnamen, sondern bewerben ihre Ressourcen weiterhin aktiv in sozialen Netzwerken und Suchmaschinen. Zum Beispiel versuchen sie, Links zu ihren Phishing-Sites an die Spitze der Suchergebnisse für die Anfrage "Geld auf eine Karte überweisen" zu bringen. In den meisten Fällen werden gefälschte Websites genau erstellt, um Geld bei der Übertragung von Karte zu Karte oder bei sofortiger Bezahlung für die Dienste von Mobilfunkbetreibern zu stehlen.
Phishing (dt. Phishing, vom Fischen - Fischen, Fischen) ist eine Form des Internetbetrugs, mit dem das Opfer dazu gebracht werden soll, dem Betrüger vertrauliche Informationen zur Verfügung zu stellen. Meistens stehlen sie Zugangskennwörter für Bankkonten, um Geld weiter zu stehlen, Social-Media-Konten (um Geld zu erpressen oder Spam im Namen des Opfers zu senden), sich für kostenpflichtige Dienste anzumelden, Mailinglisten zu erstellen oder einen Computer zu infizieren, wodurch er zu einem Link im Botnetz wird.
Bei Angriffsmethoden gibt es zwei Arten von Phishing, die sich an Benutzer und Unternehmen richten:
- Phishing-Sites, die die ursprüngliche Ressource des Opfers kopieren (Banken, Fluggesellschaften, Online-Shops, Unternehmen, Regierungsbehörden usw.).
- Phishing-Mailings, E-Mails, SMS, Nachrichten in sozialen Netzwerken usw.
Einzelpersonen werden häufig von Benutzern angegriffen, und die Schwelle für den Eintritt in dieses Segment des kriminellen Geschäfts ist so niedrig, dass minimale „Investitionen“ und Grundkenntnisse ausreichen, um es umzusetzen. Die Verbreitung dieser Art von Betrug wird auch durch Phishing-Kits erleichtert, Phishing-Site-Builder-Programme, die in Darknet in Hacker-Foren kostenlos gekauft werden können.
Angriffe auf Unternehmen oder Banken sind unterschiedlich. Sie werden von technisch versierteren Angreifern ausgeführt. In der Regel werden große Industrieunternehmen, Online-Shops, Fluggesellschaften und meist Banken als Opfer ausgewählt. In den meisten Fällen kommt es beim Phishing darauf an, eine E-Mail mit einer infizierten Datei im Anhang zu senden. Damit ein solcher Angriff erfolgreich ist, benötigen die „Mitarbeiter“ der Gruppe Spezialisten für das Schreiben von Schadcode und Programmierer, um ihre Aktivitäten zu automatisieren, sowie Personen, die primäre Informationen über das Opfer liefern und Schwachstellen in ihr finden können.
In Russland gibt es nach unseren Schätzungen 15 kriminelle Gruppen, die sich mit Phishing für Finanzinstitute befassen. Die Höhe des Schadens ist immer gering (zehnmal weniger als bei Bank-Trojanern), aber die Anzahl der Opfer, die sie an ihre Standorte locken, wird auf Tausende pro Tag geschätzt. Etwa 10-15% der Besucher von Finanz-Phishing-Websites geben ihre Daten selbst ein.
Wenn eine Phishing-Seite angezeigt wird, gilt die Rechnung für Stunden und manchmal sogar Minuten, da den Benutzern ernsthafte finanzielle und im Falle von Unternehmen auch Reputationsschäden entstehen. Zum Beispiel waren einige erfolgreiche Phishing-Seiten für weniger als einen Tag verfügbar, konnten jedoch Mengen von 1.000.000 Rubel Schaden zufügen.
In diesem Artikel werden wir uns mit der ersten Art von Phishing befassen: Phishing-Sites. Die Ressourcen, bei denen der Verdacht auf Phishing besteht, können mit verschiedenen technischen Mitteln leicht erkannt werden: Honeypots, Crawler usw. Es ist jedoch problematisch, sicherzustellen, dass es sich tatsächlich um Phishing handelt, und die angegriffene Marke zu identifizieren. Lassen Sie uns herausfinden, wie Sie dieses Problem lösen können.
Angeln
Wenn eine Marke ihren Ruf nicht überwacht, wird sie zu einem einfachen Ziel. Es ist notwendig, die Initiative von Kriminellen sofort nach der Registrierung ihrer gefälschten Websites zu ergreifen. In der Praxis ist die Suche nach einer Phishing-Seite in vier Phasen unterteilt:
- Bildung vieler verdächtiger Adressen (URLs) für Phishing-Scans (Crawler, Honeypots usw.).
- Die Bildung vieler Phishing-Adressen.
- Klassifizierung bereits erkannter Phishing-Adressen nach Tätigkeitsbereich und angegriffener Technologie, z. B. „RBS :: Sberbank Online“ oder „RBS :: Alfa-Bank“.
- Suchen Sie nach einer Spenderseite.
Die Umsetzung der Absätze 2 und 3 fällt auf die Schultern von Spezialisten für Data Science.
Danach können Sie bereits aktive Schritte unternehmen, um die Phishing-Seite zu blockieren. Insbesondere:
- die Group-IB-Produkte und Produkte unserer Partner auf die schwarze Liste setzen;
- Senden Sie automatisch oder manuell Briefe an den Eigentümer der Domain-Zone mit der Aufforderung, die Phishing-URL zu entfernen.
- Briefe an den Sicherheitsdienst der angegriffenen Marke senden;
- usw.

HTML-Analysemethoden
Die klassische Lösung für die Aufgabe, verdächtige Phishing-Adressen zu überprüfen und eine betroffene Marke automatisch zu erkennen, sind verschiedene Methoden zum Parsen von HTML-Quellseiten. Am einfachsten ist es, reguläre Ausdrücke zu schreiben. Es ist lustig, aber dieser Trick funktioniert immer noch. Und heute kopieren die meisten Anfänger einfach Inhalte von der ursprünglichen Website.
Außerdem können von Phishing-Kit-Forschern sehr effektive Anti-Phishing-Systeme entwickelt werden. In diesem Fall müssen Sie jedoch die HTML-Seite untersuchen. Darüber hinaus sind diese Lösungen nicht universell - ihre Entwicklung erfordert eine Basis der „Wale“ selbst. Einige Phishing-Kits sind dem Forscher möglicherweise nicht bekannt. Und natürlich ist die Analyse jedes neuen „Wals“ ein ziemlich mühsamer und teurer Prozess.
Alle auf der HTML-Seitenanalyse basierenden Phishing-Erkennungssysteme funktionieren nach der HTML-Verschleierung nicht mehr. In vielen Fällen reicht es aus, nur den Rahmen der HTML-Seite zu ändern.
Laut Group-IB gibt es derzeit nicht mehr als 10% solcher Phishing-Sites, aber selbst das Fehlen einer solchen kann das Opfer viel kosten.
Damit ein Fischer die Sperre umgehen kann, reicht es aus, das HTML-Framework seltener zu ändern, um die HTML-Seite zu verschleiern (das Markup zu verwirren und / oder den Inhalt über JS zu laden).
Erklärung des Problems. Ressourcenbasierte Methode
Methoden, die auf der Analyse der verwendeten Ressourcen basieren, sind viel effektiver und universeller für die Erkennung von Phishing-Seiten. Eine Ressource ist eine Datei, die beim Rendern einer Webseite hochgeladen wird (alle Bilder, Cascading Style Sheets (CSS), JS-Dateien, Schriftarten usw.).
In diesem Fall können Sie ein zweigeteiltes Diagramm erstellen, in dem einige Scheitelpunkte Adressen sind, die Phishing verdächtig sind, während andere Ressourcen sind, die ihnen zugeordnet sind.
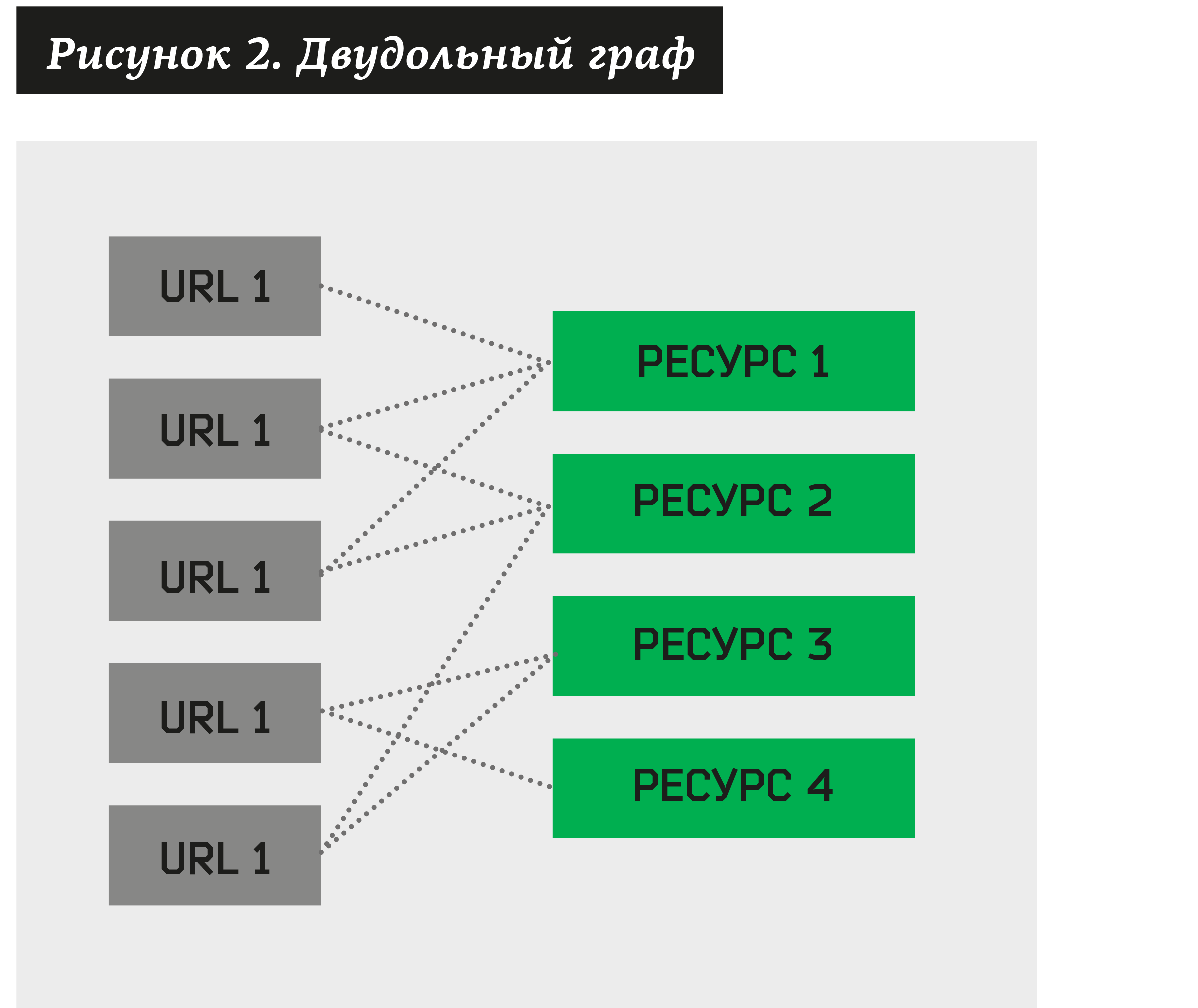
Die Aufgabe des Clustering besteht darin, eine Sammlung solcher Ressourcen zu finden, die eine relativ große Anzahl unterschiedlicher URLs besitzen. Durch die Konstruktion eines solchen Algorithmus können wir jeden zweigeteilten Graphen in Cluster zerlegen.
Die Hypothese ist, dass basierend auf realen Daten mit einer ziemlich hohen Wahrscheinlichkeit gesagt werden kann, dass der Cluster eine Sammlung von URLs enthält, die zur gleichen Marke gehören und von einem Phishing-Kit generiert werden. Um diese Hypothese zu testen, kann jeder dieser Cluster zur manuellen Überprüfung an das CERT (Information Security Incident Response Center) gesendet werden. Der Analyst würde wiederum den Clusterstatus angeben: +1 („genehmigt“) oder –1 (abgelehnt). Ein Analyst würde auch allen genehmigten Clustern eine angegriffene Marke zuweisen. Diese „manuelle Arbeit“ endet - der Rest des Prozesses ist automatisiert. Im Durchschnitt entfallen auf eine genehmigte Gruppe 152 Phishing-Adressen (Daten Stand Juni 2018), und manchmal werden sogar Cluster mit 500 bis 1000 Adressen gefunden! Der Analyst benötigt ca. 1 Minute, um den Cluster zu genehmigen oder zu widerlegen.
Dann werden alle abgelehnten Cluster aus dem System entfernt und nach einer Weile werden alle ihre Adressen und Ressourcen wieder der Eingabe des Clustering-Algorithmus zugeführt. Als Ergebnis erhalten wir neue Cluster. Und wieder senden wir sie zur Überprüfung usw.
Daher muss das System für jede neu empfangene Adresse Folgendes tun:
- Extrahieren Sie viele der Ressourcen für die Site.
- Suchen Sie nach mindestens einem zuvor genehmigten Cluster.
- Wenn die URL zu einem Cluster gehört, extrahieren Sie automatisch den Markennamen und führen Sie eine Aktion dafür aus (benachrichtigen Sie den Kunden, löschen Sie die Ressource usw.).
- Wenn Ressourcen kein Cluster zugewiesen werden kann, fügen Sie die Adresse und die Ressourcen zum zweiteiligen Diagramm hinzu. Diese URL und Ressourcen werden in Zukunft an der Bildung neuer Cluster beteiligt sein.
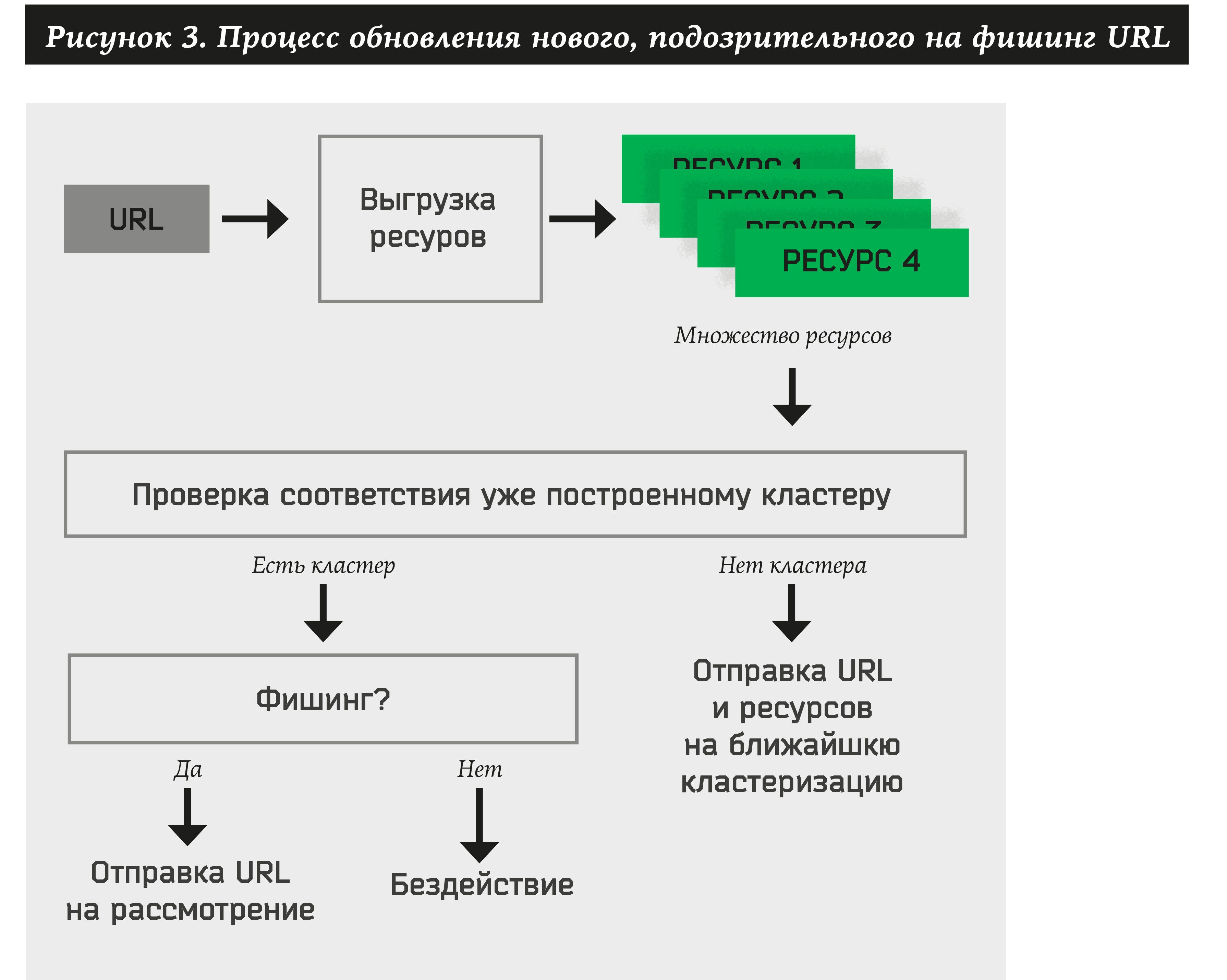
Einfacher Algorithmus für das Clustering von Ressourcen
Eine der wichtigsten Nuancen, die ein Data Science-Spezialist für Informationssicherheit berücksichtigen sollte, ist die Tatsache, dass eine Person sein Gegner ist. Aus diesem Grund ändern sich die Bedingungen und Daten für die Analyse sehr schnell! Eine Lösung, die das Problem nach 2-3 Monaten bemerkenswert behebt, funktioniert möglicherweise im Prinzip nicht mehr. Daher ist es wichtig, wenn möglich entweder universelle (ungeschickte) Mechanismen oder die flexibelsten Systeme zu schaffen, die schnell entwickelt werden können. Der Data Science-Spezialist für Informationssicherheit kann das Problem nicht ein für alle Mal lösen.
Standard-Clustering-Methoden funktionieren aufgrund der großen Anzahl von Funktionen nicht. Jede Ressource kann als boolesches Attribut dargestellt werden. In der Praxis erhalten wir jedoch täglich 5.000 Website-Adressen, von denen jede durchschnittlich 17,2 Ressourcen enthält (Daten für Juni 2018). Der Fluch der Dimensionalität erlaubt nicht einmal das Laden von Daten in den Speicher, geschweige denn das Erstellen von Clustering-Algorithmen.
Eine andere Idee besteht darin, zu versuchen, mithilfe verschiedener kollaborativer Filteralgorithmen Cluster zu bilden. In diesem Fall musste ein weiteres Feature erstellt werden - das zu einer bestimmten Marke gehört. Die Aufgabe wird auf die Tatsache reduziert, dass das System das Vorhandensein oder Fehlen dieses Zeichens für die verbleibenden URLs vorhersagen sollte. Die Methode ergab positive Ergebnisse, hatte jedoch zwei Nachteile:
- Für jede Marke musste ein eigenes Merkmal für die kollaborative Filterung erstellt werden.
- brauchte ein Trainingsmuster.
In letzter Zeit wollen immer mehr Unternehmen ihre Marke im Internet schützen und fordern die Automatisierung der Erkennung von Phishing-Sites. Jede neue Marke, die unter Schutz gestellt wird, würde ein neues Attribut hinzufügen. Das Erstellen eines Schulungsmusters für jede neue Marke ist eine zusätzliche manuelle Arbeit und Zeit.
Wir suchten nach einer Lösung für dieses Problem. Und sie haben einen sehr einfachen und effektiven Weg gefunden.
Zu Beginn erstellen wir Ressourcenpaare mit dem folgenden Algorithmus:
- Nehmen Sie alle Arten von Ressourcen (wir bezeichnen sie als a), für die es mindestens N1-Adressen gibt. Wir bezeichnen diese Beziehung als # (a) ≥ N1.
- Wir konstruieren alle Arten von Ressourcenpaaren (a1, a2) und wählen nur diejenigen aus, für die es mindestens N2 Adressen gibt, d. H. # (a1, a2) ≥ N2.
Dann betrachten wir in ähnlicher Weise Paare, die aus Paaren bestehen, die im vorherigen Absatz erhalten wurden. Als Ergebnis erhalten wir vier: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). Wenn außerdem mindestens ein Element in einem der Paare vorhanden ist, erhalten wir anstelle von vier Tripeln: (a1, a2) + (a2, a3) → (a1, a2, a3). Von der resultierenden Menge belassen wir nur die vier und drei, die mindestens N3-Adressen entsprechen. Usw…
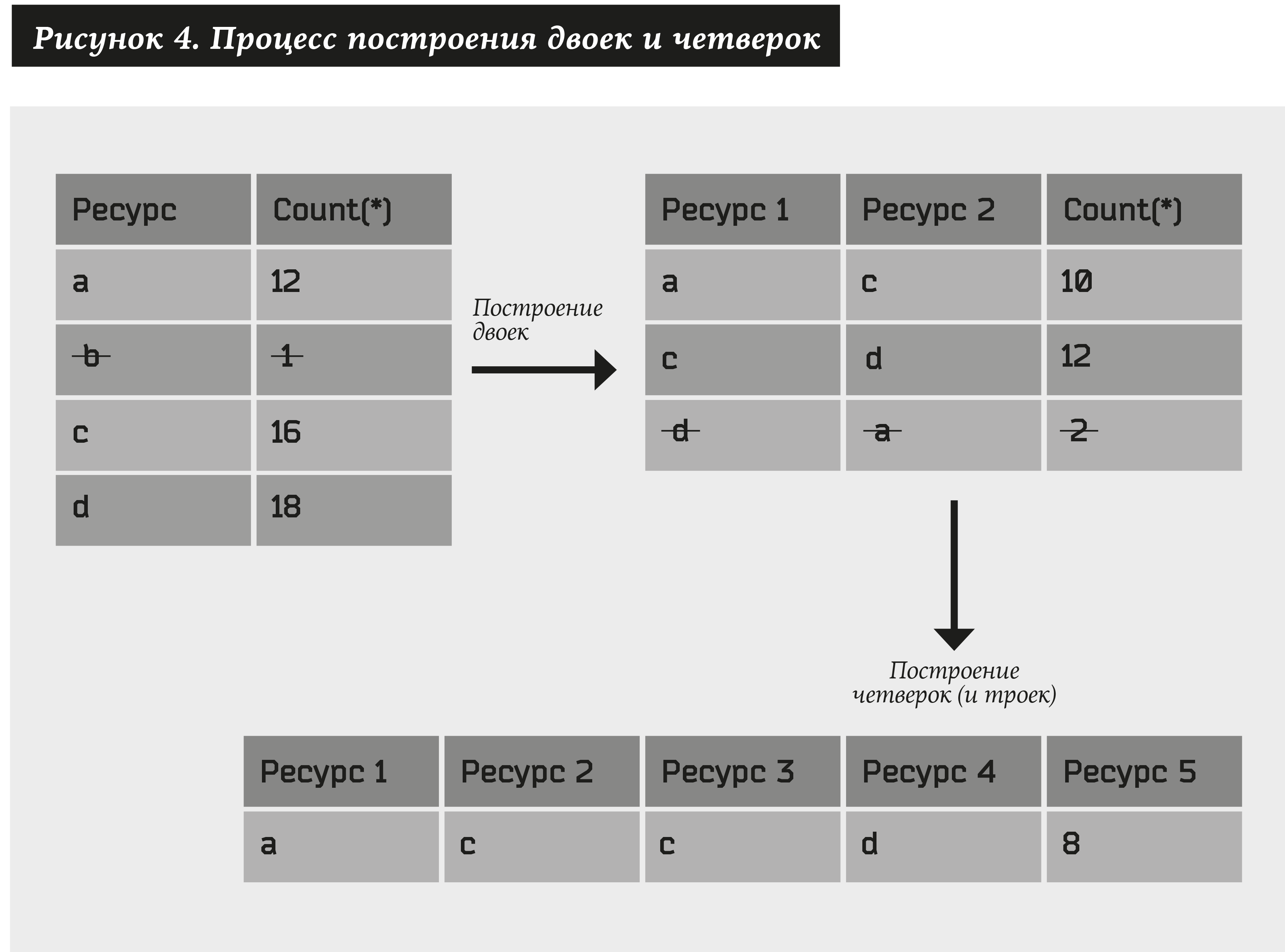
Sie können mehrere Ressourcen beliebiger Länge erhalten. Begrenzen Sie die Anzahl der Schritte auf U. Dann sind N1, N2 ... NU die Systemparameter.
Die Werte N1, N2 ... NU sind die Parameter des Algorithmus, sie werden manuell eingestellt. Im allgemeinen Fall haben wir verschiedene CL2-Paare, wobei L die Anzahl der Ressourcen ist, d.h. Die Schwierigkeit, Paare zu bilden, ist O (L2). Dann wird aus jedem Paar ein Quad erstellt. Und theoretisch erhalten wir wahrscheinlich O (L4). In der Praxis sind solche Paare jedoch viel kleiner, und mit einer großen Anzahl von Adressen wurde die O (L2log L) -Abhängigkeit empirisch erhalten. Darüber hinaus sind die nachfolgenden Schritte (zwei in vier, vier in acht usw. verwandeln) vernachlässigbar.
Es ist zu beachten, dass L die Anzahl der nicht gruppierten URLs ist. Alle URLs, die bereits einem zuvor genehmigten Cluster zugeordnet werden können, fallen nicht in die Auswahl für das Clustering.
Am Ausgang können Sie viele Cluster erstellen, die aus den größtmöglichen Ressourcensätzen bestehen. Wenn zum Beispiel (a1, a2, a3, a4, a5) existiert, die die Grenzen von Ni erfüllen, sollte man aus der Menge der Cluster (a1, a2, a3) und (a4, a5) entfernen.
Anschließend wird jeder empfangene Cluster zur manuellen Überprüfung gesendet, wobei der CERT-Analyst ihm den Status +1 ("genehmigt") oder –1 ("abgelehnt") zuweist. Außerdem wird angegeben, ob es sich bei den in den Cluster fallenden URLs um Phishing- oder legitime Websites handelt.
Wenn Sie eine neue Ressource hinzufügen, kann die Anzahl der URLs abnehmen, gleich bleiben, aber niemals zunehmen. Daher gilt für alle Ressourcen a1 ... aN die Beziehung:
# (a1) ≥ # (a1, a2) ≥ # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN).
Daher ist es ratsam, Parameter einzustellen:
N1 ≥ N2 ≥ N3 ≥ ... ≥ NU.
Am Ausgang geben wir alle Arten von Gruppen zur Überprüfung aus. In Abb. 1 ganz am Anfang des Artikels zeigt reale Cluster, für die alle Ressourcen Bilder sind.
Verwendung des Algorithmus in der Praxis
Beachten Sie, dass Sie jetzt keine Phishing-Kits mehr erforschen müssen! Das System gruppiert automatisch und findet die erforderliche Phishing-Seite.
Täglich empfängt das System 5.000 Phishing-Seiten und erstellt insgesamt 3 bis 25 neue Cluster pro Tag. Für jeden Cluster wird eine Liste mit Ressourcen hochgeladen und viele Screenshots erstellt. Dieser Cluster wird zur Bestätigung oder Ablehnung an CERT Analytics gesendet.
Beim Start war die Genauigkeit des Algorithmus gering - nur 5%. Nach 3 Monaten hielt das System die Genauigkeit jedoch von 50 bis 85%. In der Tat spielt Genauigkeit keine Rolle! Die Hauptsache ist, dass Analysten Zeit haben, die Cluster anzuzeigen. Wenn das System beispielsweise etwa 10.000 Cluster pro Tag generiert und Sie nur einen Analysten haben, müssen Sie die Systemparameter ändern. Wenn nicht mehr als 200 pro Tag, ist dies eine Aufgabe, die für eine Person möglich ist. Wie die Praxis zeigt, dauert die visuelle Analyse im Durchschnitt etwa 1 Minute.
Die Vollständigkeit des Systems beträgt ca. 82%. Die verbleibenden 18% sind entweder Einzelfälle von Phishing (daher können sie nicht gruppiert werden) oder Phishing mit einer geringen Menge an Ressourcen (es gibt nichts, nach dem gruppiert werden kann) oder Phishing-Seiten, die über die Grenzen der Parameter N1, N2 ... NU hinausgehen.
Ein wichtiger Punkt: Wie oft muss ein neues Clustering für frische, nicht zugestellte URLs gestartet werden? Wir machen das alle 15 Minuten. Darüber hinaus dauert die Clustering-Zeit selbst je nach Datenmenge 10 bis 15 Minuten. Dies bedeutet, dass nach dem Erscheinen der Phishing-URL eine Zeitverzögerung von 30 Minuten auftritt.
Unten finden Sie 2 Screenshots des GUI-Systems: Signaturen zur Erkennung von Phishing in den sozialen Netzwerken von VKontakte und Bank Of America.
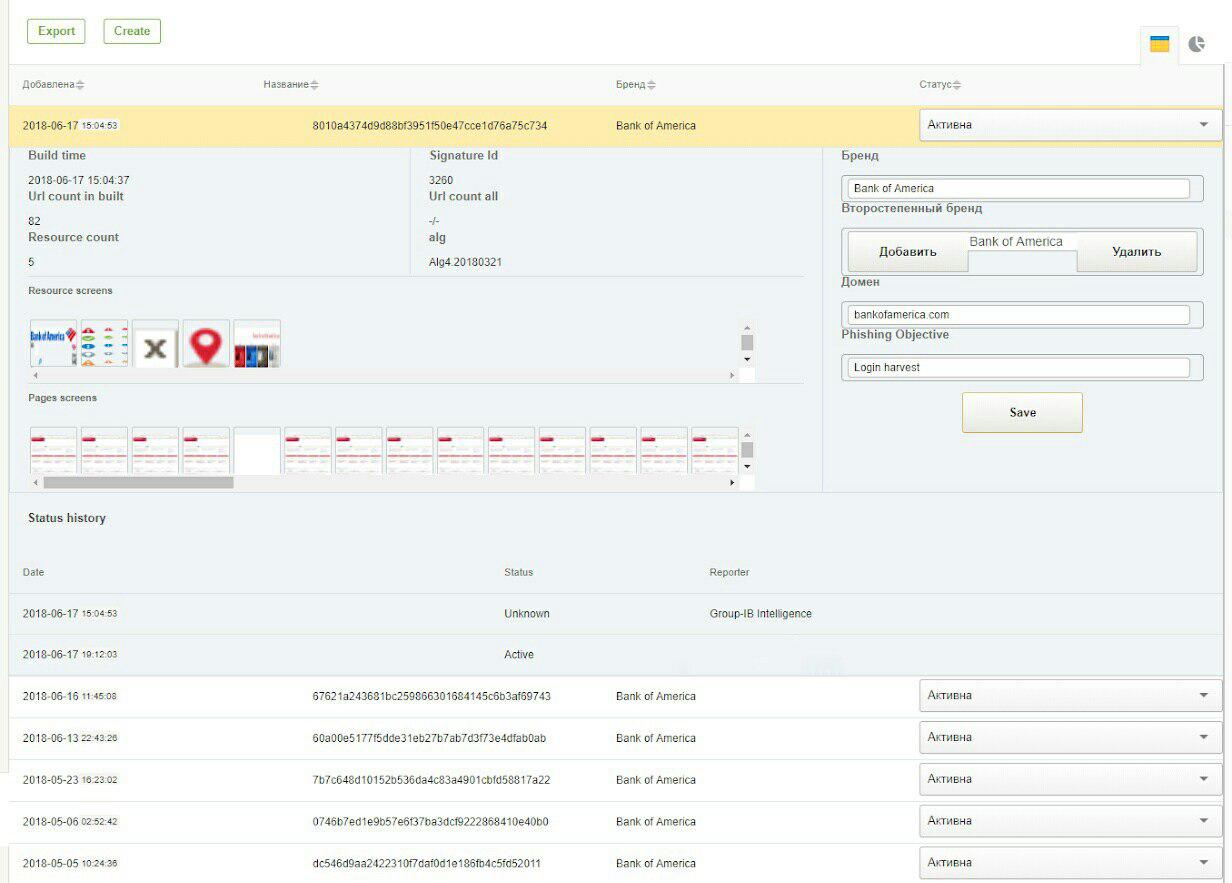
Wenn der Algorithmus nicht funktioniert
Wie oben erwähnt, funktioniert der Algorithmus im Prinzip nicht, wenn die durch die Parameter N1, N2, N3 ... NU angegebenen Grenzen nicht erreicht werden oder wenn die Anzahl der Ressourcen zu klein ist, um den erforderlichen Cluster zu bilden.
Ein Phisher kann den Algorithmus umgehen, indem er für jede Phishing-Site eindeutige Ressourcen erstellt. Beispielsweise können Sie in jedem Bild ein Pixel ändern und für geladene JS- und CSS-Bibliotheken die Verschleierung verwenden. In diesem Fall muss für jeden Typ geladener Dokumente ein vergleichbarer Hash-Algorithmus (Perceptual Hash) entwickelt werden. Diese Probleme gehen jedoch über den Rahmen dieses Artikels hinaus.
Alles zusammenfügen
Wir verbinden unser Modul mit den klassischen HTML-Stammgästen, den Daten von Threat Intelligence (Cyber Intelligence System), und erhalten eine Fülle von 99,4%. Dies ist natürlich die Vollständigkeit von Daten, die bereits zuvor von Threat Intelligence als Phishing-verdächtig eingestuft wurden.
Niemand kennt die Vollständigkeit aller möglichen Daten, da es im Prinzip unmöglich ist, das gesamte Darknet abzudecken. Laut Berichten von Gartner, IDC und Forrester ist Group-IB jedoch einer der führenden internationalen Anbieter von Threat Intelligence-Lösungen.
Was ist mit nicht klassifizierten Phishing-Seiten? Etwa 25-50 von ihnen pro Tag. Sie können manuell überprüft werden. Insgesamt gibt es bei jeder Aufgabe, die für Data Sciense im Bereich der Informationssicherheit recht schwierig ist, immer Handarbeit, und alle Vorwürfe einer 100-prozentigen Automatisierung sind eine Marketing-Fiktion. Die Aufgabe eines Data Sciense-Spezialisten besteht darin, die manuelle Arbeit um 2 bis 3 Größenordnungen zu reduzieren, um die Arbeit des Analytikers so effizient wie möglich zu gestalten.
Artikel auf
JETINFO veröffentlicht