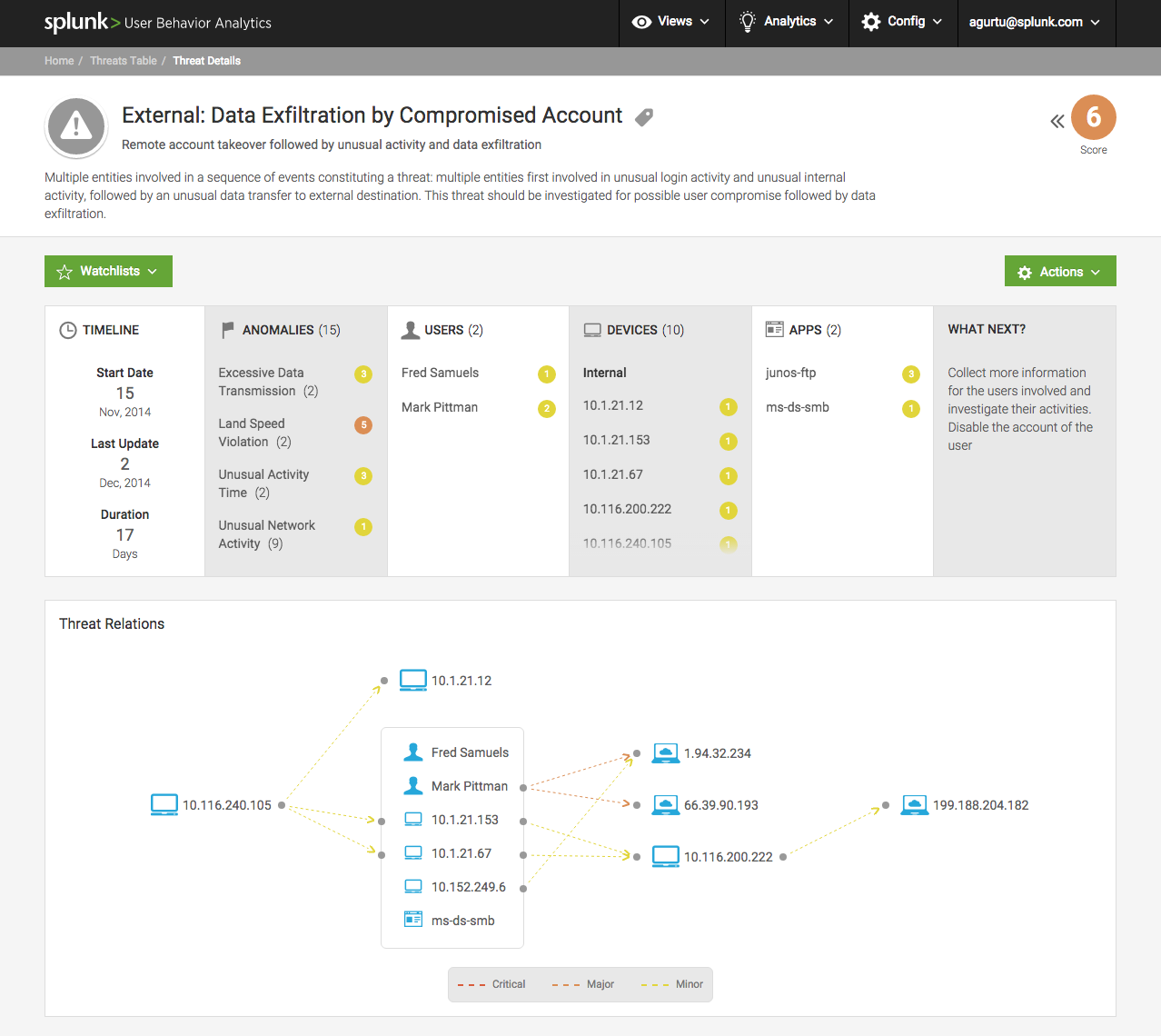
Screenshot der gesammelten Daten:
 Moderne Sicherheitssysteme sind sehr ressourcenschonend.
Moderne Sicherheitssysteme sind sehr ressourcenschonend. Warum? Weil sie mehr zählen als viele Produktionsserver und Business Intelligence-Systeme.
Was denken sie? Ich werde es jetzt erklären. Beginnen wir mit einem einfachen: Konventionell war die erste Generation von Schutzvorrichtungen sehr einfach - auf der Ebene von „Start“ und „Nicht-Start“. Beispielsweise erlaubte eine Firewall Datenverkehr nach bestimmten Regeln und nicht nach anderen Regeln. Eine spezielle Rechenleistung wird hierfür natürlich nicht benötigt.
Die nächste Generation hat komplexere Regeln erworben. Es gab also Reputationssysteme, die ihnen abhängig von seltsamen Benutzeraktionen und Änderungen in Geschäftsprozessen eine Zuverlässigkeitsbewertung gemäß vordefinierten Vorlagen zuweisen und manuell Schwellenwerte für den Betrieb festlegen.
Jetzt analysieren UBA-Systeme (User Behaviour Analytics) das Benutzerverhalten, vergleichen es mit anderen Mitarbeitern des Unternehmens und bewerten die Konsistenz und Richtigkeit der Aktionen jedes Mitarbeiters. Dies geschieht aufgrund von Data Lake-Methoden und einer recht ressourcenintensiven, aber automatisierten Verarbeitung durch Algorithmen für maschinelles Lernen - vor allem, weil es mehrere tausend Manntage dauert, alle möglichen Szenarien mit Ihren Händen zu schreiben.
Klassisches SIEM
Bis etwa 2016 wurde der Ansatz als fortschrittlich angesehen, wenn alle Ereignisse von allen Netzwerkknoten an einem Ort gesammelt wurden, an dem sich der Analyseserver befindet. Der Analyseserver kann Ereignisse erfassen, filtern und Korrelationsregeln zuordnen. Wenn beispielsweise auf einer Workstation eine massive Dateiaufzeichnung gestartet wird, kann dies ein Zeichen für einen Verschlüsselungsvirus sein oder auch nicht. Für alle Fälle sendet das System eine Benachrichtigung an den Administrator. Wenn mehrere Stationen vorhanden sind, steigt die Wahrscheinlichkeit der Bereitstellung der Malware. Wir müssen Alarm schlagen.
Wenn ein Benutzer auf eine seltsame Domain geklopft hat, die vor ein paar Wochen registriert wurde, und nach ein paar Minuten all diese Farbmusik verschwunden ist, ist dies mit ziemlicher Sicherheit ein Verschlüsselungsvirus. Es ist erforderlich, die Workstation zu löschen und das Netzwerksegment zu isolieren, während Administratoren benachrichtigt werden.
SIEM verglich Daten von DLP, Firewall, Antispam usw. und dies ermöglichte es, sehr gut auf verschiedene Bedrohungen zu reagieren. Der Schwachpunkt waren diese Muster und Auslöser - was als gefährliche Situation zu betrachten ist und was nicht. Wie bei Viren und verschiedenen kniffligen DDoS begannen auch die Spezialisten des SOC-Zentrums, ihre Basis für Angriffszeichen zu bilden. Für jede Art von Angriff wurde ein Szenario betrachtet, Symptome wurden hervorgehoben und ihnen wurden zusätzliche Aktionen zugewiesen. All dies erforderte eine kontinuierliche Verbesserung und Anpassung des Systems im 24-mal-7-Modus.
Es funktioniert - fass es nicht an, aber alles funktioniert gut!
Deshalb ist es unmöglich, auf UBA zu verzichten? Das erste Problem ist, dass es unmöglich ist, mit Ihren Händen zu verschreiben. Weil sich verschiedene Dienste unterschiedlich verhalten - und auch unterschiedliche Benutzer. Wenn Sie Ereignisse für den durchschnittlichen Benutzer innerhalb des Unternehmens registrieren, werden Support, Buchhaltung, Ausschreibungsabteilung und Administratoren sehr unterschieden. Der Administrator ist aus Sicht eines solchen Systems eindeutig ein böswilliger Benutzer, da er viel tut und aktiv in dieses System kriecht. Support ist böswillig, da er eine Verbindung zu allen Personen herstellt. Die Buchhaltung überträgt Daten über verschlüsselte Tunnel. Und die Ausschreibungsabteilung führt bei der Veröffentlichung der Dokumentation ständig Unternehmensdaten zusammen.
Schlussfolgerung - Für jedes Szenario müssen Ressourcennutzungsszenarien festgelegt werden. Dann tiefer. Dann noch tiefer. Dann ändert sich etwas in den Prozessen (und das passiert jeden Tag) und muss erneut verschrieben werden.
Es wäre logisch, so etwas wie einen „gleitenden Durchschnitt“ zu verwenden, wenn die Norm für den Benutzer automatisch bestimmt wird. Wir werden darauf zurückkommen.
Das zweite Problem war, dass die Angreifer viel genauer wurden. Bisher war das Entleeren von Daten, selbst wenn Sie den Moment des Hackens verpasst hatten, recht einfach zu erfassen. Beispielsweise konnten Hacker eine Datei von Interesse per E-Mail oder Datei-Hosting auf sich selbst hochladen und bestenfalls in einem Archiv verschlüsseln, um eine Erkennung durch das DLP-System zu vermeiden.
Jetzt ist alles interessanter. Dies haben wir im vergangenen Jahr in unseren SOC-Zentren gesehen.
- Steganographie durch Senden von Fotos an Facebook. Die Malware hat sich bei FB registriert und die Gruppe abonniert. Jedes in der Gruppe veröffentlichte Foto war mit einem integrierten Datenblock ausgestattet, der Anweisungen für die Malware enthielt. Unter Berücksichtigung der Verluste während der JPEG-Komprimierung stellte sich heraus, dass etwa 100 Bytes pro Bild übertragen wurden. Außerdem hat die Malware selbst 2-3 Fotos pro Tag im sozialen Netzwerk gepostet, was ausreichte, um über mimikatz zusammengeführte Logins / Passwörter zu übertragen.
- Ausfüllen von Formularen auf Websites. Die Malware führte einen Benutzeraktionssimulator aus, ging zu bestimmten Websites, fand dort „Feedback“ -Formulare und sendete Daten über diese, wobei Binärdaten in BASE64 codiert wurden. Dies haben wir bereits bei einem System der neuen Generation festgestellt. Auf dem klassischen SIEM würden sie, wenn sie nicht über eine solche Sendemethode Bescheid wissen, höchstwahrscheinlich gar nichts bemerken.
- Auf standardmäßige Weise - leider auf standardmäßige Weise - mischten sie Daten in den DNS-Verkehr. Es gibt viele Technologien für die Steganografie in DNS und im Allgemeinen für den Bau von Tunneln über DNS. Hier lag der Schwerpunkt nicht auf der Abfrage bestimmter Domänen, sondern auf Anfragetypen. Das System hat einen kleinen Alarm über das Wachstum des DNS-Verkehrs für den Benutzer ausgelöst. Die Daten wurden langsam und in unterschiedlichen Intervallen gesendet, um die Analyse mit Sicherheitsfunktionen zu erschweren.
Für die Penetration verwenden sie normalerweise streng benutzerdefinierte Viren, die direkt unter den Benutzern des Zielunternehmens erstellt wurden. Darüber hinaus werden Angriffe häufig über eine Zwischenverbindung abgewickelt. Zum Beispiel wird zuerst der Auftragnehmer kompromittiert, und dann wird die Malware dadurch in das Hauptunternehmen eingegeben.
Viren der letzten Jahre sitzen fast immer streng im RAM und werden auf Anhieb gelöscht - Betonung auf das Fehlen von Spuren. Forensik unter solchen Bedingungen ist sehr schwierig.
Gesamtergebnis - SIEM leistet schlechte Arbeit. Vieles, was außer Sicht gerät. So etwas erschien ein leerer Platz auf dem Markt: Damit das System nicht auf die Art des Angriffs abgestimmt werden musste, verstand sie selbst, was los war.
Wie hat sie sich "verstanden"?
Die ersten Reputationssicherheitssysteme waren Betrugsbekämpfungsmodule zum Schutz vor Geldwäsche in Banken. Für die Bank besteht die Hauptsache darin, alle betrügerischen Transaktionen zu identifizieren. Das heißt, es ist nicht schade, ein bisschen zu wiederholen. Hauptsache, der menschliche Bediener versteht, worauf er zuerst achten muss. Und er wurde nicht von sehr kleinen Alarmen überwältigt.
Die Systeme funktionieren folgendermaßen:
- Sie erstellen ein Benutzerprofil basierend auf vielen Parametern. Zum Beispiel, wie er normalerweise Geld ausgibt: was er kauft, wie er kauft, wie schnell er einen Bestätigungscode eingibt, von welchen Geräten er es tut usw.
- Die Logikschicht prüft, ob es möglich ist, vom Zeitpunkt der Zahlung bis zu einem anderen Punkt im Transport für den Zeitraum zwischen den Transaktionen rechtzeitig zu gelangen. Wenn sich der Kauf in einer anderen Stadt befindet, wird geprüft, ob der Benutzer häufig in andere Städte reist, wenn er sich in einem anderen Land befindet - ob der Benutzer häufig andere Länder besucht, und ein kürzlich gekauftes Flugticket erhöht die Wahrscheinlichkeit, dass der Alarm nicht benötigt wird.
- Reputationsmodul - Wenn der Benutzer alles im Rahmen seines normalen Verhaltens tut, werden für seine Handlungen positive Punkte vergeben (sehr langsam) und wenn im Rahmen von atypisch - negativ.
Lassen Sie uns näher auf Letzteres eingehen.
Beispiel 1. Ihr ganzes Leben lang haben Sie sich freitags bei McDonald's einen Kuchen und Cola gekauft und am Dienstagmorgen plötzlich 500 Rubel gekauft. Minus 2 Punkte für eine nicht standardmäßige Zeit, minus 3 Punkte für einen nicht standardmäßigen Kauf. Die Alarmschwelle für Sie ist auf –20 eingestellt. Es passiert nichts.
Bei etwa 5 bis 6 solcher Einkäufe ziehen Sie diese Punkte auf Null zurück, da sich das System daran erinnert, dass es normal ist, dass Sie am Dienstagmorgen zu McDonald's gehen. Natürlich vereinfache ich stark, aber die Logik der Arbeit ist ungefähr dieselbe.
Beispiel 2. Ihr ganzes Leben lang haben Sie sich als normaler Benutzer verschiedene kleine Dinge gekauft. Sie zahlen im Lebensmittelgeschäft (das System „weiß“ bereits, wie viel Sie normalerweise essen und wo Sie am häufigsten kaufen, oder besser gesagt, es weiß es nicht, sondern schreibt einfach in Ihr Profil), kaufen dann ein Ticket für die U-Bahn für einen Monat oder bestellen etwas Kleines über den Online-Shop. Und jetzt kaufen Sie in Hongkong ein Klavier für 8 Tausend Dollar. Könnte? Könnte. Schauen wir uns die Punkte an: –15 für einen Standardbetrug, –10 für einen nicht standardmäßigen Betrag, –5 für einen nicht standardmäßigen Ort und eine nicht standardmäßige Zeit, –5 für ein anderes Land ohne Ticketkauf, –7 für die Tatsache, dass Sie zuvor nichts benutzt haben Sie gingen ins Ausland, +5 für ihr Standardgerät, +5 für das, was andere Benutzer der Bank dort gekauft hatten.
Die Alarmschwelle für Sie ist auf –20 eingestellt. Die Transaktion wird "ausgesetzt", ein Mitarbeiter der IB der Bank beginnt die Situation zu verstehen. Dies ist ein sehr einfacher Fall. Höchstwahrscheinlich wird er Sie nach 5 Minuten anrufen und sagen: "Haben Sie sich wirklich entschieden, um 8 Uhr morgens etwas in einem Musikgeschäft in Hongkong für 8 Tausend Dollar zu kaufen?" Wenn Sie mit Ja antworten, wird die Transaktion übersprungen. Die Daten fallen als abgeschlossene Aktion in das Profil. Bei ähnlichen Aktionen werden weniger negative Punkte vergeben, bis sie überhaupt zur Norm werden.
Wie gesagt, ich vereinfache es wirklich sehr. Banken investieren seit Jahren in Reputationssysteme und verbessern diese seit Jahren. Andernfalls würde ein Haufen Maultiere sehr schnell Geld abheben.
Wie wird dies auf die Unternehmensinformationssicherheit übertragen?
Basierend auf den Algorithmen zur Betrugsbekämpfung und Geldwäsche erscheinen Verhaltensanalysesysteme. Ein vollständiges Benutzerprofil wird erfasst: wie schnell es druckt, auf welche Ressourcen es zugreift, mit wem es interagiert, welche Software es startet - im Allgemeinen alles, was der Benutzer jeden Tag tut.
Ein Beispiel. Der Benutzer interagiert häufig mit 1C und gibt dort häufig Daten ein. Dann beginnt er plötzlich, die gesamte Datenbank in Dutzenden kleiner Berichte zu entladen. Sein Verhalten geht über das Standardverhalten eines solchen Benutzers hinaus, aber er kann mit dem Verhalten ähnlicher Profile nach Typ verglichen werden (höchstwahrscheinlich handelt es sich dabei um andere Buchhalter) - es ist klar, dass zu bestimmten Zeiten eine Woche lang Berichte eingehen und alle dies tun. Die Zahlen sind gleich, es gibt keine weiteren Unterschiede, der Alarm wird nicht ausgelöst.
Ein weiteres Beispiel. Ein Benutzer hat sein ganzes Leben lang mit einem Dateiball gearbeitet und täglich ein paar Dutzend Dokumente aufgezeichnet, und dann begann er plötzlich, Hunderte und Tausende von Dateien daraus zu entnehmen. Und ein anderer DLP sagt, dass er etwas Wichtiges aussendet. Vielleicht hat die Ausschreibungsabteilung mit den Vorbereitungen für den Wettbewerb begonnen, vielleicht gibt die „Ratte“ Daten an Wettbewerber weiter. Das System weiß das natürlich nicht, sondern beschreibt einfach sein Verhalten und alarmiert die Sicherheitskräfte. Grundsätzlich kann sich das Verhalten eines neuen Mitarbeiters, technischen Supports oder CEOs kaum vom Verhalten des „misshandelten Kosaken“ unterscheiden, und die Aufgabe des Sicherheitspersonals besteht darin, dem System mitzuteilen, dass dies ein normales Verhalten ist. Das Profil wird trotzdem folgen, und wenn das Konto des Generaldirektors kompromittiert wird und der Ruf auf Punkte sinkt, wird der Alarm ausgelöst.
Benutzerprofile führen zu Regeln für das UBA-System. Genauer gesagt, Tausende von Heuristiken, die sich regelmäßig ändern. Jede Benutzergruppe hat ihre eigenen Prinzipien. Beispielsweise senden Benutzer dieses Typs 100 MB pro Tag, Benutzer des anderen Typs 1 GB pro Tag, wenn es kein Wochenende ist. Usw. Wenn der erste 5 GB sendet, ist dies verdächtig. Und wenn das zweite - dann gibt es negative Punkte, aber sie werden die Alarmschwelle nicht überschreiten. Aber wenn er in der Nähe DNS für verdächtige neue Domains aktiviert hat, gibt es noch ein paar negative Punkte und der Alarm wird bereits ausgelöst.
Der Ansatz ist, dass dies nicht die Regel "Wenn es seltsame DNS-Abfragen gab und dann der Verkehr sprang, dann ..." und die Regel "Wenn die Reputation –20, dann ..." ist - jede einzelne Quelle von Punkten für die Reputation des Benutzers oder Prozesses ist unabhängig und bestimmt ausschließlich die Norm seines Verhaltens. Automatisch.
Gleichzeitig hilft die Informationssicherheitsabteilung zunächst dabei, das System zu schulen und festzustellen, was die Norm ist und was nicht. Anschließend passt sich das System an und schult sich in realen Verkehrs- und Benutzeraktivitätsprotokollen um.
Was wir setzen
Als Systemintegrator bieten wir unseren Kunden einen Service für das operative Management der Informationssicherheit (Managed
SOC CROC Service). Eine Schlüsselkomponente neben Systemen wie Asset Management, Vulnerability Management, Sicherheitstests und Threat Intelligence, die in unserer Cloud-Infrastruktur verfügbar sind, ist die Verbindung zwischen klassischem SIEM und proaktivem UBA. Gleichzeitig können wir für UBA je nach Kundenwunsch sowohl industrielle Lösungen großer Anbieter als auch unser eigenes Analysesystem verwenden, das auf dem Hadoop + Hive + Redis + Splunk Analytics für Hadoop (Hunk) -Paket basiert.
Die folgenden Lösungen stehen für die Verhaltensanalyse in unserem Cloud-SOC-CROC oder nach dem On-Premise-Modell zur Verfügung:
- Exabeam: Vielleicht das benutzerfreundlichste UBA-System, mit dem Sie einen Vorfall mithilfe der User Tracking-Technologie schnell untersuchen können, die Aktivitäten in der IT-Infrastruktur (z. B. lokale Datenbankanmeldung unter SA-Konto) mit einem echten Benutzer verbindet. Enthält ungefähr 400 Risikobewertungsmodelle, die für jede seltsame oder verdächtige Aktion Benutzer-Strafpunkte hinzufügen.
- Securonix: ein sehr ressourcenhungriges, aber äußerst effektives Verhaltensanalysesystem. Das System wird auf die Big Data-Plattform gestellt, fast 1000 Modelle sind sofort verfügbar. Die meisten von ihnen verwenden proprietäre Clustering-Technologie für Benutzeraktivitäten. Die Engine ist sehr flexibel. Sie können jedes Feld des CEF-Formats verfolgen und gruppieren, beginnend mit der Abweichung von der durchschnittlichen Anzahl von Anforderungen pro Tag durch die Webserverprotokolle und endend mit der Identifizierung neuer Netzwerkinteraktionen für den Benutzerverkehr.
- Splunk UBA: Eine gute Ergänzung zu Splunk ES. Die sofort einsatzbereite Regelbasis ist klein, bezieht sich jedoch auf die Kill Chain, sodass Sie sich nicht von kleineren Vorfällen ablenken lassen und sich auf einen echten Hacker konzentrieren können. Selbstverständlich verfügen wir über die gesamte Leistungsfähigkeit der statistischen Datenverarbeitung mit dem Splunk Machine Learning Toolkit und einer retrospektiven Analyse des gesamten akkumulierten Datenvolumens.
Und für kritische Segmente, ob es sich um ein automatisiertes Prozessleitsystem oder eine wichtige Geschäftsanwendung handelt, platzieren wir zusätzliche Sensoren, um fortschrittliche Forensik und Hanitope zu sammeln und die Aufmerksamkeit des Hackers von produktiven Systemen abzulenken.
Warum ein Meer von Ressourcen?
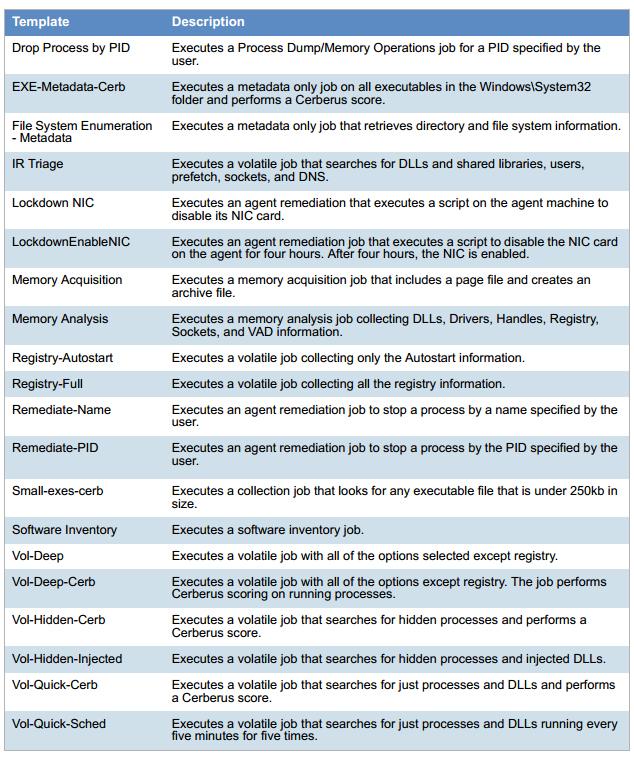
Weil alle Ereignisse geschrieben sind. Dies ist wie bei Google Analytics nur auf der lokalen Workstation. Im lokalen Netzwerk werden Ereignisse über die Internet-Metadaten zu Statistiken und Schlüsselereignissen an Data Lake gesendet. Wenn der SOC-Betreiber den Vorfall jedoch untersuchen möchte, wird auch ein vollständiges Protokoll aufgezeichnet. Alles wird gesammelt: temporäre Dateien, Registrierungsschlüssel, alle laufenden Prozesse und deren Prüfsummen, die beim Start geschrieben werden, Aktionen, Screencast - was auch immer. Unten finden Sie ein Beispiel für die gesammelten Daten.
Liste der Parameter von der Workstation:


Systeme in Bezug auf Speicher und RAM werden viel komplizierter. Das klassische SIEM startet mit 64 GB RAM, einigen Prozessoren und einem halben Terabyte Speicher. UBA ist von einem Terabyte RAM und höher. Unsere letzte Implementierung war beispielsweise auf 33 physischen Servern (28 Rechenknoten für die Datenverarbeitung + 5 Steuerknoten für den Lastausgleich), 150 TB Seen (600 TB in der Hardware, einschließlich schnellem Cache auf Instanzen) und jeweils 384 GB RAM.
Wer braucht das?
Zuallererst sind Banken, Finanzinstitute, der Öl- und Gassektor, der große Einzelhandel und viele andere diejenigen, die sich in der „Risikozone“ befinden und ständig angegriffen werden.
Für solche Unternehmen können sich die Kosten für Datenlecks oder -verluste auf zehn oder sogar Hunderte Millionen Dollar belaufen. Die Installation eines UBA-Systems kostet jedoch viel weniger. Und natürlich staatseigene Unternehmen und Telekommunikationsunternehmen, denn niemand möchte, dass irgendwann die Daten von Millionen von Patienten oder die Korrespondenz von zig Millionen Menschen im Open Access veröffentlicht werden.
Referenzen