
Die Entwicklung hochwertiger Software ist heute ohne
statische Code-Analysemethoden kaum vorstellbar. Die statische Analyse des Programmcodes kann in die Entwicklungsumgebung integriert werden (mit Standardmethoden oder mithilfe von Plug-Ins). Sie kann von einer speziellen Software durchgeführt werden, bevor der Code kommerziell in Betrieb genommen wird, oder „manuell“ von einem regulären oder externen Experten.
Es wird oft argumentiert, dass
dynamische Code-Analyse oder
Penetrationstests die statische Analyse ersetzen können, da diese Überprüfungsmethoden echte Probleme aufdecken und es keine falsch positiven Ergebnisse gibt. Dies ist jedoch ein strittiger Punkt, da bei der dynamischen Analyse im Gegensatz zur statischen Analyse nicht der gesamte Code überprüft wird, sondern nur der Widerstand der Software gegen eine Reihe von Angriffen, die die Aktionen eines Angreifers nachahmen. Ein Angreifer kann erfinderischer sein als der Prüfer, unabhängig davon, wer die Prüfung durchführt: eine Person oder eine Maschine.
Die dynamische Analyse ist nur dann abgeschlossen, wenn sie mit einer vollständigen Testabdeckung durchgeführt wird, was bei Anwendung auf reale Anwendungen eine schwierige Aufgabe ist. Der Nachweis der Vollständigkeit der Testabdeckung ist ein algorithmisch unlösbares Problem.
Die obligatorische statische Analyse des Programmcodes ist einer der notwendigen Schritte bei der Inbetriebnahme von Software mit erhöhten Anforderungen an die Informationssicherheit.
Im Moment gibt es viele verschiedene statische Code-Analysatoren auf dem Markt, und es erscheinen immer mehr neue. In der Praxis gibt es Fälle, in denen mehrere statische Analysegeräte zusammen verwendet werden, um die Qualität der Überprüfung zu verbessern, da unterschiedliche Analysegeräte nach unterschiedlichen Fehlern suchen.
Warum gibt es keinen universellen statischen Analysator, der Code vollständig überprüft und alle darin enthaltenen Fehler ohne Fehlalarme findet und gleichzeitig schnell arbeitet und nicht viele Ressourcen (CPU-Zeit und Speicher) benötigt?
Ein bisschen über die Architektur statischer Analysatoren
Die Antwort auf diese Frage liegt in der Architektur statischer Analysatoren. Fast alle statischen Analysatoren basieren irgendwie auf dem Prinzip der Compiler, dh in ihrer Arbeit gibt es Stufen der Quellcode-Konvertierung - die gleichen wie die vom Compiler durchgeführten.
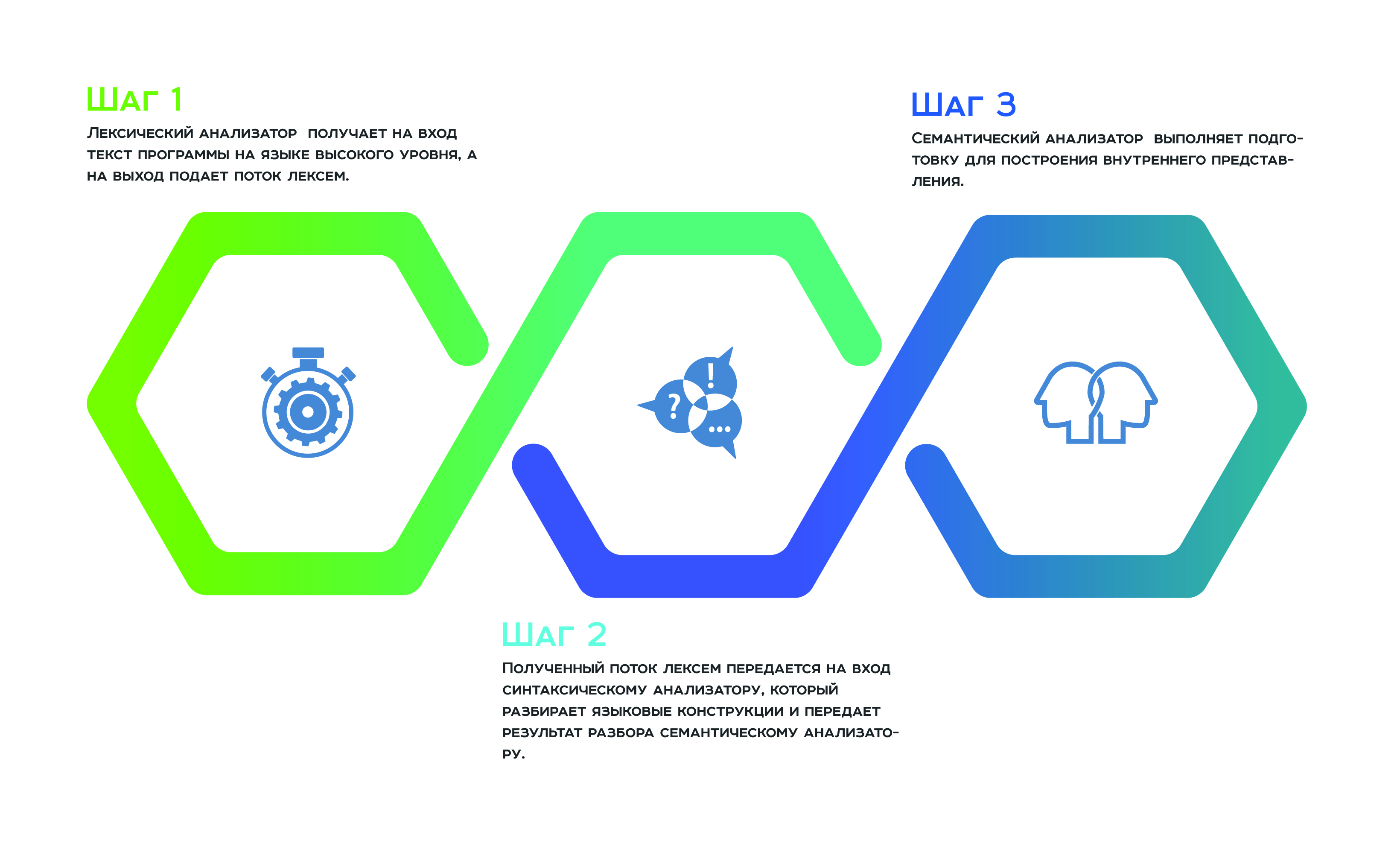
Alles beginnt mit einer
lexikalischen Analyse , die den Text des Programms in einer höheren Sprache als Eingabe und einen Strom von Token zur Ausgabe empfängt. Als nächstes wird der empfangene Token-Stream an die Eingabe
an den Parser übertragen , der die Sprachkonstrukte analysiert und das Ergebnis der Analyse an den
semantischen Analysator weiterleitet , der sich aufgrund seiner Arbeit darauf vorbereitet, die interne Darstellung zu erstellen. Diese interne Darstellung ist ein Merkmal jedes statischen Analysators. Die Effizienz des Analysators hängt davon ab, wie erfolgreich er ist.
Viele Hersteller von statischen Analysatoren behaupten, für alle vom Analysator unterstützten Programmiersprachen eine universelle interne Darstellung zu verwenden. Auf diese Weise können sie den Programmcode analysieren, der in mehreren Sprachen als Ganzes und nicht als separate Komponenten entwickelt wurde. Ein „ganzheitlicher Ansatz“ für die Analyse ermöglicht es, das Auslassen von Fehlern zu vermeiden, die an der Schnittstelle zwischen den einzelnen Komponenten eines Softwareprodukts auftreten.
Theoretisch ist dies richtig, aber in der Praxis ist eine universelle interne Darstellung für alle Programmiersprachen schwierig und ineffizient. Jede Programmiersprache ist etwas Besonderes. Eine interne Ansicht ist normalerweise ein Baum, dessen Scheitelpunkte Attribute speichern. Durch Überqueren eines solchen Baums sammelt und konvertiert der Analysator Informationen. Daher muss jeder Scheitelpunkt des Baums einen einheitlichen Satz von Attributen enthalten. Da jede Sprache einzigartig ist, kann die Einheitlichkeit von Attributen nur durch Redundanz von Komponenten unterstützt werden. Je heterogener Programmiersprachen sind, desto heterogener sind die Komponenten in den Merkmalen jedes Scheitelpunkts, und daher ist die interne Darstellung aus dem Speicher ineffizient. Eine große Anzahl heterogener Merkmale wirkt sich auch auf die Komplexität der Baumläufer aus, was zu Ineffizienzen bei der Leistung führt.
Optimierungskonvertierungen für statische Analysatoren
Damit ein statischer Analysator effizient im Speicher und in der Zeit arbeitet, benötigen Sie eine kompakte universelle interne Darstellung. Dies kann durch die Tatsache erreicht werden, dass die interne Darstellung in mehrere Bäume unterteilt ist, von denen jeder für verwandte Programmiersprachen ausgelegt ist.
Die Optimierungsarbeit beschränkt sich nicht nur auf die Aufteilung der internen Darstellung in verwandte Programmiersprachen. Darüber hinaus verwenden Hersteller verschiedene Optimierungstransformationen - genau wie bei Compilertechnologien, insbesondere
Optimierungstransformationen von Zyklen . Tatsache ist, dass das Ziel der statischen Analyse im Idealfall darin besteht, eine Datenförderung im Programm durchzuführen, um deren Transformation während der Programmausführung zu bewerten. Daher müssen die Daten in jeder Umdrehung des Zyklus „vorgerückt“ werden. Wenn Sie also genau diese Umdrehungen sparen und sie viel kleiner machen, erhalten Sie erhebliche Vorteile sowohl im Speicher als auch in der Leistung. Zu diesem Zweck werden solche Transformationen aktiv verwendet, die mit einiger Wahrscheinlichkeit eine Extrapolation der Datentransformation auf alle Windungen des Zyklus mit der minimalen Anzahl von Durchläufen durchführen.
Sie können auch Zweige einsparen, indem Sie die Wahrscheinlichkeit berechnen, dass das Programm auf den einen oder anderen Zweig geht. Wenn die Wahrscheinlichkeit eines Durchgangs entlang eines Zweigs geringer ist, wird dieser Programmzweig nicht berücksichtigt.
Natürlich "verliert" jede dieser Transformationen die Fehler, die der Analysator erkennen sollte, aber dies ist eine "Gebühr" für die Speichereffizienz und -leistung.
Was sucht ein statischer Code-Analysator?
Bedingt können Mängel, die irgendwie an Eindringlingen und damit an Wirtschaftsprüfern interessiert sind, in folgende Gruppen eingeteilt werden:
- Validierungsfehler
- Informationsleckfehler,
- Authentifizierungsfehler.
Validierungsfehler treten auf, weil die Eingabedaten nicht ausreichend auf Richtigkeit überprüft werden. Ein Angreifer kann als Eingabe verrutschen, was das Programm nicht erwartet, und dadurch unbefugten Zugriff auf das Steuerelement erhalten. Die häufigsten Datenüberprüfungsfehler sind Injektionen und
XSS . Anstelle gültiger Daten übermittelt der Angreifer dem Programm speziell vorbereitete Daten, die ein kleines Programm enthalten. Dieses Programm wird gerade ausgeführt. Das Ergebnis seiner Implementierung kann die Übertragung der Kontrolle auf ein anderes Programm, Datenkorruption und vieles mehr sein. Aufgrund von Validierungsfehlern kann auch die Site ersetzt werden, mit der der Benutzer arbeitet. Validierungsfehler können durch statische Code-Analysemethoden qualitativ erkannt werden.
Informationsleckfehler sind Fehler, die darauf zurückzuführen sind, dass vertrauliche Informationen des Benutzers infolge der Verarbeitung abgefangen und an den Angreifer übertragen wurden. Dies kann auch umgekehrt sein: Im System gespeicherte vertrauliche Informationen werden abgefangen und an den Angreifer übertragen, wenn dieser sich an den Benutzer bewegt.
Solche Schwachstellen sind genauso schwer zu erkennen wie Validierungsfehler. Die Erkennung dieser Art von Fehler erfordert die Verfolgung des Fortschritts und der Konvertierung von Daten im gesamten Programmcode in der Statistik. Dies erfordert die Implementierung von Methoden wie
Taint-Analyse und
Interprocedural-Datenanalyse . Die Genauigkeit der Analyse hängt weitgehend davon ab, wie gut diese Methoden entwickelt sind, nämlich die Minimierung von Fehlalarmen und fehlenden Fehlern.
Die Regelbibliothek zur Erkennung von Fehlern, insbesondere das Format zur Beschreibung dieser Regeln, spielt ebenfalls eine wichtige Rolle für die Genauigkeit des statischen Analysators. All dies ist ein Wettbewerbsvorteil jedes Analysators und wird sorgfältig vor Wettbewerbern geschützt.
Authentifizierungsfehler sind die interessantesten Fehler für einen Angreifer, da sie schwer zu erkennen sind, da sie an der Verbindungsstelle von Komponenten auftreten und schwer zu formalisieren sind. Angreifer nutzen diese Art von Fehler, um Zugriffsrechte zu eskalieren. Authentifizierungsfehler werden nicht automatisch erkannt, da nicht klar ist, wonach gesucht werden soll. Dies sind Fehler in der Logik zum Erstellen des Programms.
Speicherfehler
Sie sind schwer zu erkennen, da für eine genaue Identifizierung ein umständliches Gleichungssystem gelöst werden muss, das sowohl im Speicher als auch in der Leistung teuer ist. Daher wird das Gleichungssystem reduziert, was bedeutet, dass die Genauigkeit verloren geht.
Typische Speicherfehler sind "
Use-After-Free" , "
Double-Free" , "
Null-Zeiger-Dereferenzierung" und deren Varianten, z. B. "
Out-of-Bound-Read" und "
Out-of-Bound-Write" .
Wenn der nächste Analysator einen Speicherverlust nicht erkennen konnte, können Sie hören, dass solche Fehler schwer auszunutzen sind. Ein Angreifer muss hochqualifiziert sein und viel Geschick einsetzen, um zum einen das Vorhandensein eines solchen Fehlers im Code herauszufinden und zum anderen einen Exploit durchzuführen. Nun, und weiter lautet das Argument: "Sind Sie sicher, dass Ihr Softwareprodukt für einen Guru dieser Stufe interessant ist?" ... Die Geschichte kennt jedoch Fälle, in denen Speicherfehler erfolgreich ausgenutzt wurden und erheblichen Schaden verursachten. Als Beispiele können Sie bekannte Situationen anführen wie:
- CVE-2014-0160 - ein Fehler in der openssl-Bibliothek - Ein möglicher Kompromiss zwischen privaten Schlüsseln erforderte die Neuausstellung aller Zertifikate und die Neuerstellung des Kennworts.
- CVE-2015-2712 - Fehler in der Implementierung von js in Mozilla Firefox - Überprüfung der Grenzen.
- CVE-2010-1117 - nach kostenlos im Internet Explorer verwenden - remote ausnutzbar.
- CVE-2018-4913 - Verwendung nach der kostenlosen Verwendung in Acrobat Reader - Codeausführung.
Außerdem nutzen Angreifer gerne Fehler aus, die mit einer nicht ordnungsgemäßen Synchronisierung von Threads oder Prozessen verbunden sind. Solche Fehler sind in der Statik schwer zu identifizieren, da die Simulation des Zustands einer Maschine ohne das Konzept der „Zeit“ keine leichte Aufgabe ist. Dies bezieht sich auf Fehler wie
Rennbedingungen . Und heute wird Parallelität überall verwendet, auch in sehr kleinen Anwendungen.
Zusammenfassend sollte angemerkt werden, dass ein statischer Analysator im Entwicklungsprozess nützlich ist, wenn er richtig verwendet wird. Während des Betriebs muss verstanden werden, was von ihm zu erwarten ist und was mit den Fehlern zu tun ist, die der statische Analysator im Prinzip nicht identifizieren kann. Wenn sie sagen, dass während des Entwicklungsprozesses kein statischer Analysator benötigt wird, bedeutet dies, dass sie einfach nicht wissen, wie sie ihn bedienen sollen.
Lesen Sie in unserem Blog weiter, wie Sie den statischen Analysator richtig bedienen, um mit den darin enthaltenen Informationen richtig und effizient zu arbeiten.