
Wir haben begonnen, die Überwachung für PgBouncer in unserem Service zu aktualisieren, und beschlossen, alles ein wenig zu kämmen. Um alles fit zu machen, haben wir die bekanntesten Methoden zur Leistungsüberwachung verwendet: USE (Utilization, Saturation, Errors) von Brendan Gregg und RED (Requests, Errors, Durations) von Tom Wilkie.
Unter der Zwischensequenz finden Sie eine Geschichte mit Grafiken darüber, wie pgbouncer funktioniert, welche Konfigurationshandles es hat und wie USE / RED verwendet wird, um die richtigen Metriken für die Überwachung auszuwählen.
Zunächst zu den Methoden selbst
Obwohl diese Methoden ziemlich bekannt sind (über sie war es bereits bei Habré, wenn auch nicht sehr detailliert ), ist es nicht so, dass sie in der Praxis weit verbreitet sind.
VERWENDUNG
Behalten Sie für jede Ressource die Entsorgung, Sättigung und Fehler im Auge.
Brendan Gregg
Hier ist eine Ressource eine separate physische Komponente - eine CPU, eine Festplatte, ein Bus usw. Aber nicht nur - die Leistung einiger Softwareressourcen kann mit dieser Methode auch berücksichtigt werden, insbesondere virtuelle Ressourcen, wie z. B. Container / Gruppen mit Einschränkungen, es ist auch zweckmäßig, dies zu berücksichtigen.
U - Entsorgung : entweder ein Prozentsatz der Zeit (ab dem Beobachtungsintervall), in der die Ressource mit nützlicher Arbeit beschäftigt war. Da beispielsweise das Laden der CPU- oder Festplattenauslastung zu 90% bedeutet, dass 90% der Zeit von etwas Nützlichem beansprucht wurde) oder für Ressourcen wie Speicher der Prozentsatz des verwendeten Speichers.
In jedem Fall bedeutet 100% Recycling, dass die Ressource nicht mehr als jetzt genutzt werden kann. Und entweder bleibt die Arbeit hängen und wartet auf die Veröffentlichung / geht in die Warteschlange, oder es gibt Fehler. Diese beiden Szenarien werden durch die entsprechenden zwei verbleibenden USE-Metriken abgedeckt:
S - Sättigung , es ist auch Sättigung: ein Maß für die Menge der "zurückgestellten" / in die Warteschlange gestellten Arbeit.
E - Fehler : Wir zählen einfach die Anzahl der Fehler. Fehler / Ausfälle beeinträchtigen die Leistung, sind jedoch möglicherweise nicht sofort erkennbar, da gespiegelte Vorgänge oder Fehlertoleranzmechanismen mit Sicherungsgeräten usw. abgerufen werden.
Rot
Tom Wilkie (der jetzt bei Grafana Labs arbeitet) war frustriert über die USE-Methodik oder vielmehr über die in einigen Fällen schlechte Anwendbarkeit und die Inkonsistenz mit der Praxis. Wie kann man zum Beispiel die Sättigung des Gedächtnisses messen? Oder wie man Systembusfehler in der Praxis misst?
Es stellt sich heraus, dass Linux wirklich Fehlerzahlen meldet.
T. Wilkie
Kurz gesagt, um die Leistung und das Verhalten von Mikrodiensten zu überwachen, schlug er eine andere geeignete Methode vor: erneut drei Indikatoren zu messen:
R - Rate : Die Anzahl der Anfragen pro Sekunde.
E - Fehler : Wie viele Anfragen haben einen Fehler zurückgegeben.
D - Dauer : Zeitaufwand für die Bearbeitung der Anfrage. Es ist Latenz, "Latenz" (© Sveta Smirnova :), Reaktionszeit usw.
Im Allgemeinen eignet sich USE besser zur Überwachung von Ressourcen und RED für Dienste und deren Arbeitslast / Nutzlast.
Pgbouncer
Als Dienstleistung hat sie gleichzeitig alle möglichen internen Grenzen und Ressourcen. Gleiches gilt für Postgres, auf das Clients über diesen PgBouncer zugreifen. Für eine vollständige Überwachung in dieser Situation sind daher beide Methoden erforderlich.
Um zu verstehen, wie diese Methoden auf einen Türsteher angewendet werden, müssen Sie die Details seines Geräts verstehen. Es reicht nicht aus, es als Black-Box zu überwachen - "lebt der pgbouncer-Prozess" oder "ist der Port offen", weil Im Falle von Problemen gibt dies kein Verständnis dafür, was genau und wie es kaputt gegangen ist und was zu tun ist.
Was macht PgBouncer im Allgemeinen aus Sicht des Kunden?
- Client verbindet
- [Kunde stellt eine Anfrage - erhält eine Antwort] x wie oft er benötigt
Hier habe ich ein Diagramm der entsprechenden Client-Zustände aus Sicht von PgBoucer gezeichnet:

Während des Anmeldevorgangs kann die Autorisierung sowohl lokal (Dateien, Zertifikate und sogar PAM und hba aus neuen Versionen) als auch remote erfolgen - d. H. in der Datenbank selbst, zu der die Verbindung versucht wird. Somit hat der Anmeldestatus einen zusätzlichen Unterzustand. Nennen wir es Executing um anzuzeigen, dass auth_query zu diesem Zeitpunkt in der Datenbank ausgeführt wird:
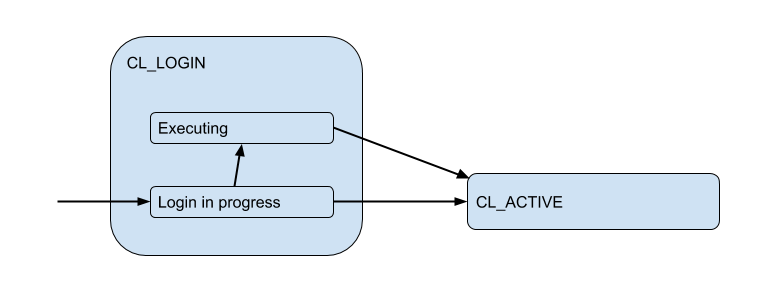
Diese Clientverbindungen stimmen jedoch tatsächlich mit den Backend- / Upstream-Verbindungen überein, die PgBouncer innerhalb des Pools öffnet und eine begrenzte Anzahl enthält. Und sie stellen eine solche Verbindung zum Client nur für die Zeit her - für die Dauer der Sitzung, Transaktion oder Anforderung, abhängig von der Art des Poolings (bestimmt durch die Einstellung pool_mode ). In den meisten Fällen wird das Transaktionspooling verwendet (wir werden es hauptsächlich später besprechen) - wenn die Verbindung für eine Transaktion an den Client ausgegeben wird und der Client für den Rest der Zeit tatsächlich nicht mit dem Server verbunden ist. Der "aktive" Zustand des Clients sagt also wenig aus, und wir werden ihn in Substrate unterteilen:
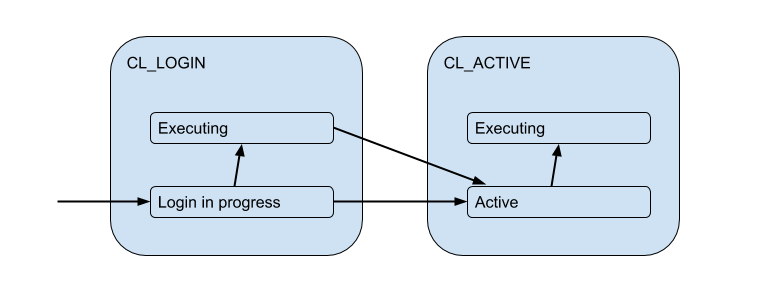
Jeder dieser Clients fällt in seinen eigenen Verbindungspool, der für die tatsächliche Verbindung zu Postgres ausgegeben wird. Dies ist die Hauptaufgabe von PgBouncer - die Anzahl der Verbindungen zu Postgres zu begrenzen.
Aufgrund der eingeschränkten Serververbindungen kann es vorkommen, dass der Client die Anforderung direkt erfüllen muss, aber derzeit keine freie Verbindung besteht. Dann wird der Client in die Warteschlange gestellt und seine Verbindung wird in den CL_WAITING . Daher muss das Zustandsdiagramm ergänzt werden:
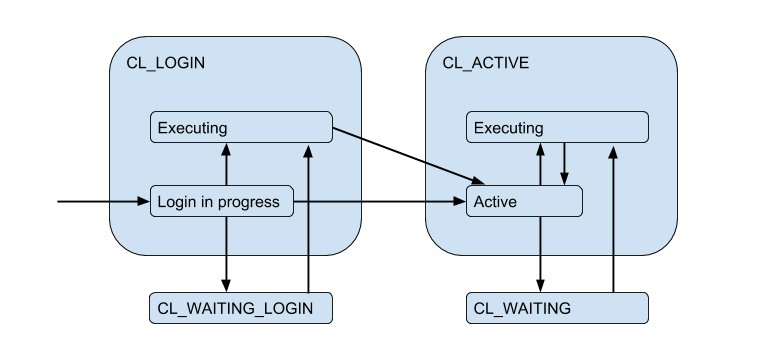
Da dies passieren kann, wenn sich der Client nur anmeldet und eine Autorisierungsanforderung ausführen muss, wird auch der CL_WAITING_LOGIN .
Wenn Sie jetzt von der Rückseite - von der Seite der Serververbindungen - SV_LOGIN , befinden sie sich dementsprechend in solchen Zuständen: Wenn die Autorisierung unmittelbar nach der Verbindung erfolgt - SV_LOGIN , ausgestellt und (möglicherweise) vom Client verwendet - SV_ACTIVE oder frei - SV_IDLE .
VERWENDUNG für PgBouncer
So kommen wir zur (naiven Version) Nutzung eines bestimmten Pools:
Pool utiliz = /
PgBouncer verfügt über eine spezielle pgbouncer-Dienstprogrammdatenbank, in der sich ein SHOW POOLS , der den aktuellen Status der Verbindungen jedes Pools anzeigt:

Es sind 4 Clientverbindungen offen und alle sind cl_active . Von 5 Serververbindungen - 4 sv_active und eine im neuen Status sv_used .
Was ist sv_used wirklich an den verschiedenen Einstellungen von pgbouncer, die nichts mit der Überwachung zu tun haben?sv_used bedeutet also nicht "Verbindung wird verwendet", wie Sie vielleicht denken, sondern "Verbindung wurde einmal verwendet und wurde lange nicht mehr verwendet". Tatsache ist, dass PgBouncer standardmäßig Serververbindungen im LIFO-Modus verwendet - d. H. Zuerst werden neu freigegebene Verbindungen verwendet, dann kürzlich verwendete usw. allmählich zu lang verwendeten Verbindungen übergehen. Dementsprechend können Serververbindungen von der Unterseite eines solchen Stapels "schlecht werden". Und sie sollten vor der Verwendung auf Lebendigkeit überprüft werden, was mit server_check_query erfolgt. Während sie überprüft werden, wird der Status sv_tested .
Die Dokumentation besagt, dass LIFO standardmäßig als aktiviert ist dann "bekommt eine kleine Anzahl von Verbindungen die meiste Arbeitslast. Und dies bietet die beste Leistung, wenn es einen Server gibt, der die Datenbank hinter pgbouncer bedient", d.h. wie im typischsten Fall. Ich glaube, dass der potenzielle Leistungsschub auf die Einsparungen bei der Switching-Leistung zwischen mehreren Backend-Prozessen zurückzuführen ist. Aber es hat nicht zuverlässig geklappt, weil Dieses Implementierungsdetail besteht seit> 12 Jahren und geht über die Commit-Historie für Github und die Tiefe meines Interesses hinaus =)
Es schien also seltsam und server_check_delay mit den aktuellen Realitäten, dass der Standardwert der Einstellung server_check_delay , die feststellt, dass der Server nicht zu lange verwendet wurde und überprüft werden sollte, bevor er an den Client übergeben wird, 30 Sekunden beträgt. Dies trotz der Tatsache, dass standardmäßig tcp_keepalive gleichzeitig mit den Standardeinstellungen aktiviert ist. Beginnen Sie 2 Stunden nach dem Leerlauf mit der Überprüfung der Keep-Alive-Verbindung mit Samples.
Es stellt sich heraus, dass in einer Burst / Surge-Situation von Clientverbindungen, die etwas auf dem Server tun möchten, eine zusätzliche Verzögerung für server_check_query eingeführt server_check_query , die, obwohl " SELECT 1; immer noch ~ 100 Mikrosekunden dauern kann, und wenn server_check_query = ';' dann können Sie ~ 30 Mikrosekunden sparen =)
Aber die Annahme, dass die Arbeit in nur wenigen Verbindungen = an mehreren "Haupt" -Back-End-Postgres-Prozessen effizienter ist, scheint mir zweifelhaft. Der Postgres-Worker-Prozess speichert (Meta-) Informationen zu jeder Tabelle, auf die in diesem Zusammenhang zugegriffen wurde. Wenn Sie eine große Anzahl von Tabellen haben, kann dieser Relcache sehr stark wachsen und viel Speicher beanspruchen, bis die Seiten des 0_o-Prozesses ausgetauscht werden. Um dies zu server_lifetime , verwenden Sie die Einstellung server_lifetime (Standard ist 1 Stunde), mit der die Serververbindung für die Rotation geschlossen wird. Andererseits gibt es eine Einstellung für server_round_robin , mit der der Modus für die Verwendung von Verbindungen von LIFO zu FIFO server_round_robin wodurch Clientanforderungen auf Serververbindungen gleichmäßiger verteilt werden.
SHOW POOLS wir SHOW POOLS Metriken von SHOW POOLS (von einem Prometheus-Exporteur) übernehmen, können wir diese Zustände darstellen:
Um zur Verfügung zu stehen, müssen Sie jedoch einige Fragen beantworten:
- Wie groß ist der Pool?
- Wie wird gezählt, wie viele Verbindungen verwendet werden? In Witzen oder in der Zeit, im Durchschnitt oder in der Spitze?
Poolgröße
Hier ist alles kompliziert, wie im Leben. Insgesamt gibt es im pbbouncer bereits fünf Einstellungslimits!
pool_size kann für jede Datenbank festgelegt werden. Für jedes DB / Benutzer-Paar wird ein separater Pool erstellt, d. H. Von jedem zusätzlichen Benutzer aus können Sie weitere pool_size Backends / Postgres-Worker erstellen. Weil Wenn pool_size nicht festgelegt ist, fällt es in default_pool_size , das standardmäßig 20 ist. Es stellt sich heraus, dass jeder Benutzer, der das Recht hat, eine Verbindung zur Datenbank herzustellen (und über pgbouncer arbeitet), möglicherweise 20 Postgres-Prozesse erstellen kann, was nicht viel zu sein scheint. Wenn Sie jedoch viele verschiedene Benutzer der Datenbanken oder der Datenbanken selbst haben und die Pools nicht bei einem festen Benutzer registriert sind, d. H. wird im autodb_idle_timeout erstellt (und dann von autodb_idle_timeout gelöscht), dann kann dies gefährlich sein =)
Es könnte sich lohnen, default_pool_size klein zu lassen, nur für jeden Feuerwehrmann.
max_db_connections - wird nur benötigt, um die Gesamtzahl der Verbindungen zu einer Datenbank zu begrenzen, weil Andernfalls können sich schlecht verhaltende Clients zu vielen Backend- / Postgres-Prozessen führen. Und standardmäßig hier - unbegrenzt ¯_ (ツ) _ / ¯
Vielleicht sollten Sie die Standardeinstellungen für max_db_connections ändern. Sie können sich beispielsweise auf die max_connections Ihrer Postgres konzentrieren (standardmäßig 100). Aber wenn Sie viele PgBouncer haben ...
reserve_pool_size - Wenn nur pool_size verwendet wird, kann PgBouncer mehrere weitere Verbindungen zur Basis herstellen. So wie ich es verstehe, wird dies getan, um mit einem Lastanstieg fertig zu werden. Wir werden darauf zurückkommen.max_user_connections - Dies ist im Gegenteil die Grenze der Verbindungen von einem Benutzer zu allen Datenbanken, d. h. relevant, wenn Sie mehrere Datenbanken haben und diese unter denselben Benutzern liegen.max_client_conn - Wie viele Clientverbindungen akzeptiert PgBouncer insgesamt? Standard hat wie üblich eine sehr seltsame Bedeutung - 100. Das heißt, Es wird davon ausgegangen, dass mehr als 100 Clients, die plötzlich abstürzen, nur stillschweigend auf TCP-Ebene reset und reset (nun, in den Protokollen muss ich zugeben, dass dies "keine Verbindungen mehr zulässig (max_client_conn)" ist).
Es könnte sich lohnen, max_client_conn >> SUM ( pool_size' ) beispielsweise zehnmal mehr zu machen.
Zusätzlich zu SHOW POOLS Dienst pseudo-base pgbouncer auch den SHOW DATABASES , der die tatsächlich auf einen bestimmten Pool angewendeten Grenzwerte anzeigt:

Serververbindungen
Noch einmal - wie kann man messen, wie viele Verbindungen verwendet werden?
In Witzen im Durchschnitt / in Spitzenzeiten / in der Zeit?
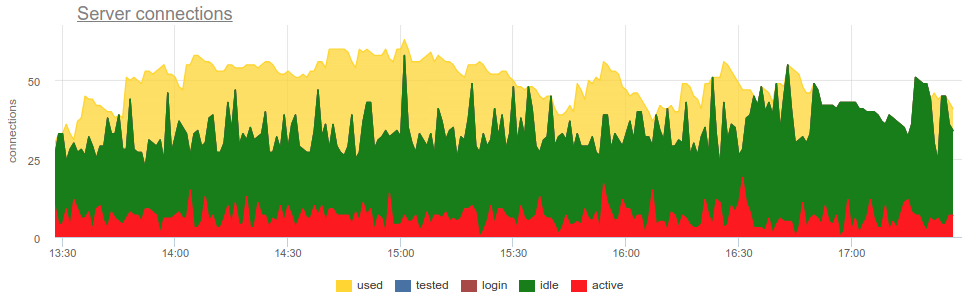
In der Praxis ist es ziemlich problematisch, die Verwendung von Pools durch den Türsteher mit weit verbreiteten Werkzeugen zu überwachen, wie z pgbouncer selbst liefert nur ein kurzes Bild, und da häufig keine Umfrage durchgeführt wird, besteht immer noch die Möglichkeit eines falschen Bildes aufgrund von Stichproben. Hier ist ein reales Beispiel, bei dem sich das Bild sowohl offener als auch verwendeter Verbindungen grundlegend ändert, je nachdem, wann der Exporteur zu Beginn oder am Ende der Minute gearbeitet hat:
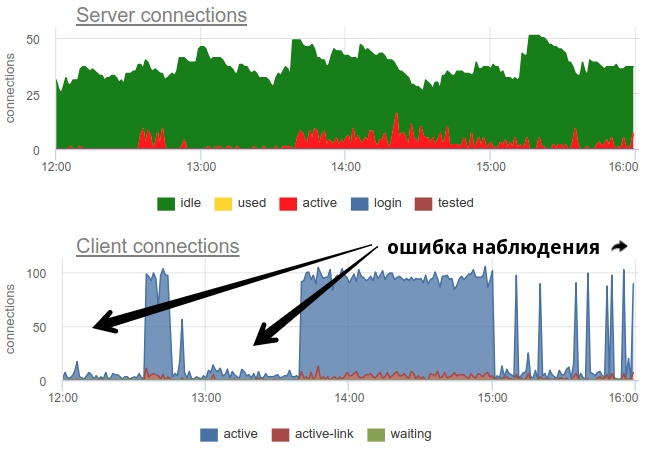
Hier sind alle Änderungen beim Laden / Verwenden der Verbindungen nur eine Fiktion, ein Artefakt der Neustarts des Statistiksammlers. Hier sehen Sie die Verbindungsdiagramme in Postgres während dieser Zeit und die Dateideskriptoren des Bouncers und des PG - keine Änderungen:
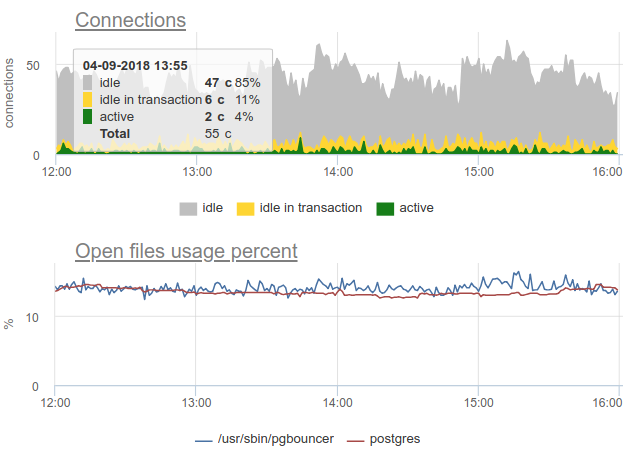
Zurück zum Thema Entsorgung. Wir haben uns für einen kombinierten Ansatz in unserem Service entschieden - wir SHOW POOLS einmal pro Sekunde und rendern einmal pro Minute sowohl die durchschnittliche als auch die maximale Anzahl von Verbindungen in jeder Klasse:
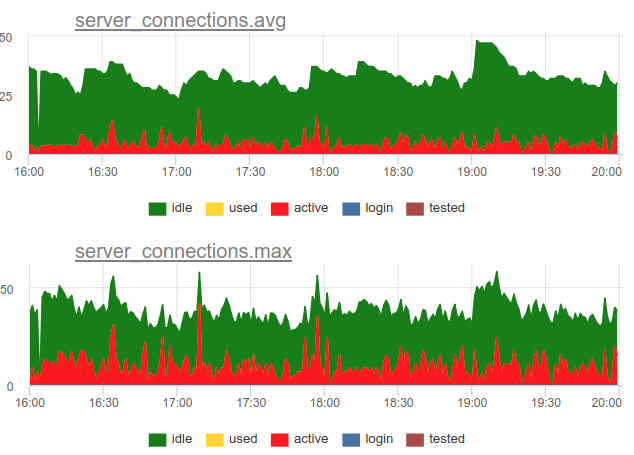
Wenn wir die Anzahl dieser aktiven Statusverbindungen durch die Größe des Pools dividieren, erhalten wir die durchschnittliche und maximale Auslastung dieses Pools und können benachrichtigen, wenn er nahe bei 100% liegt.
Darüber hinaus verfügt PgBouncer über einen Befehl SHOW STATS dem Nutzungsstatistiken für jede Proxy-Datenbank angezeigt werden:

Wir interessieren uns am meisten für die Spalte total_query_time - die Zeit, die alle Verbindungen für die Ausführung von Abfragen in Postgres benötigen. Und ab Version 1.8 gibt es auch die Metrik total_xact_time - die Zeit, die für Transaktionen aufgewendet wird. Basierend auf diesen Metriken können wir die Auslastung der Serververbindungszeit aufbauen, da dieser Indikator im Gegensatz zu den aus Verbindungszuständen berechneten nicht Stichprobenproblemen unterliegt, weil Diese total_..._time sind kumulativ und bestehen nichts:

Vergleichen
Es ist ersichtlich, dass die Stichprobe nicht alle Momente mit einer hohen Auslastung von ~ 100% zeigt, und query_time zeigt.
Sättigung und PgBouncer
Warum müssen Sie die Sättigung überwachen, da aufgrund der hohen Auslastung bereits klar ist, dass alles schlecht ist?
Das Problem ist, dass unabhängig davon, wie Sie die Auslastung messen, selbst akkumulierte Zähler keine lokale 100% ige Ressourcennutzung anzeigen können, wenn sie nur in sehr kurzen Intervallen auftritt. Sie haben beispielsweise alle Kronen oder andere synchrone Prozesse, die gleichzeitig mit dem Befehl Abfragen an die Datenbank durchführen können. Wenn diese Anforderungen kurz sind, kann die Auslastung, gemessen auf der Skala von Minuten und sogar Sekunden, gering sein, aber gleichzeitig mussten diese Anforderungen irgendwann in der Schlange auf die Ausführung warten. Ähnlich verhält es sich mit einer Situation, in der die CPU nicht zu 100% ausgelastet ist und die durchschnittliche Last hoch ist - wie die Prozessorzeit immer noch vorhanden ist, aber dennoch warten viele Prozesse in der Schlange auf die Ausführung.
Wie kann diese Situation überwacht werden cl_waiting , wir können einfach die Anzahl der Clients im cl_waiting gemäß SHOW POOLS . In einer normalen Situation gibt es Null und mehr als Null bedeutet einen Überlauf dieses Pools:
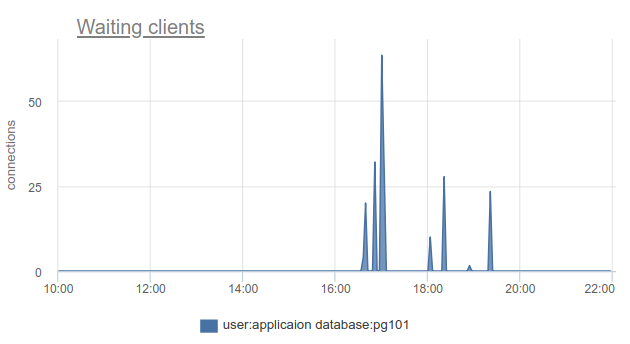
Es bleibt das Problem, dass SHOW POOLS nur abgetastet werden können, und in einer Situation mit synchronen Kronen oder Ähnlichem können wir solche wartenden Clients einfach überspringen und nicht sehen.
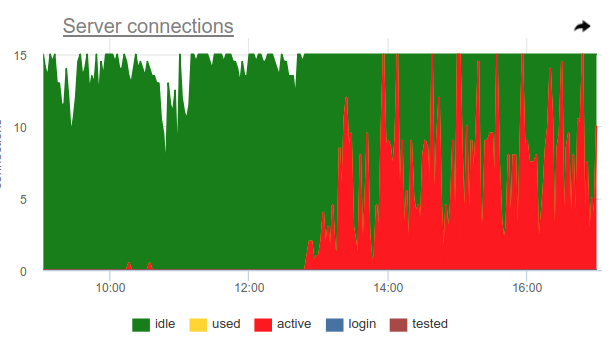
Sie können diesen Trick anwenden. Pgbouncer selbst kann die 100% ige Nutzung des Pools erkennen und den Sicherungspool öffnen. Dafür sind zwei Einstellungen verantwortlich: reserve_pool_size - wie gesagt für seine Größe und reserve_pool_timeout - wie viele Sekunden ein Client waiting sollte, bevor er den Sicherungspool verwendet. Wenn wir also in der Grafik der Serververbindungen sehen, dass die Anzahl der für Postgres geöffneten Verbindungen größer als pool_size ist, gab es eine Sättigung des Pools wie folgt:

Offensichtlich macht so etwas wie Kronen einmal pro Stunde viele Anfragen und belegt den Pool vollständig. Und obwohl wir nicht den Moment sehen, in dem active Verbindungen das Limit pool_size überschreiten, war pgbouncer dennoch gezwungen, zusätzliche Verbindungen zu öffnen.
Auch in diesem Diagramm sind die Einstellungen für server_idle_timeout deutlich sichtbar - nach dem server_idle_timeout zu dem das Halten und Schließen nicht verwendeter Verbindungen gestoppt werden muss. Standardmäßig sind dies 10 Minuten, die wir in der Tabelle sehen - nach den active Spitzen genau um 5:00 Uhr, um 6:00 Uhr usw. (gemäß cron 0 * * * * ) hängen die Verbindungen im idle + used weitere 10 Minuten verwendet und schließen.
Wenn Sie an der Spitze des Fortschritts stehen und PgBouncer in den letzten 9 Monaten aktualisiert haben, finden Sie in der Spalte SHOW STATS total_wait_time die beste Sättigung, weil berücksichtigt kumulativ die Zeit, die Kunden in einem waiting verbringen. Zum Beispiel hier - waiting erschien um 16:30:
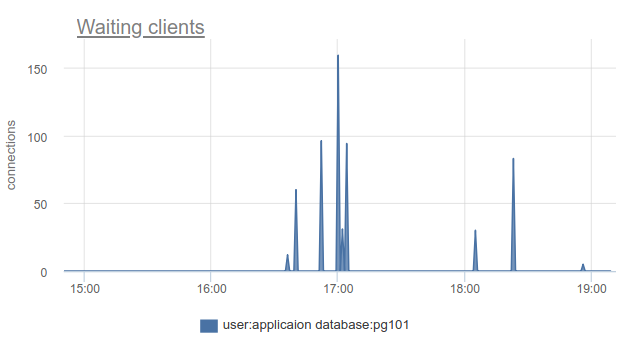
Und wait_time , die vergleichbar ist und sich eindeutig auf die average query time wait_time auswirkt, kann von 15:15 bis fast 19 Uhr wait_time :

Trotzdem ist die Überwachung des Status von Clientverbindungen immer noch sehr nützlich, weil Auf diese Weise können Sie nicht nur feststellen, dass alle Verbindungen zu einer solchen Datenbank hergestellt wurden und die Clients warten müssen, sondern auch, dass SHOW POOLS von Benutzern in separate Pools unterteilt wird und SHOW STATS dies nicht. SHOW STATS können Sie herausfinden, welche Clients alle Verbindungen verwendet haben auf die angegebene Basis - gemäß der Spalte sv_active des entsprechenden Pools. Oder nach Metrik
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
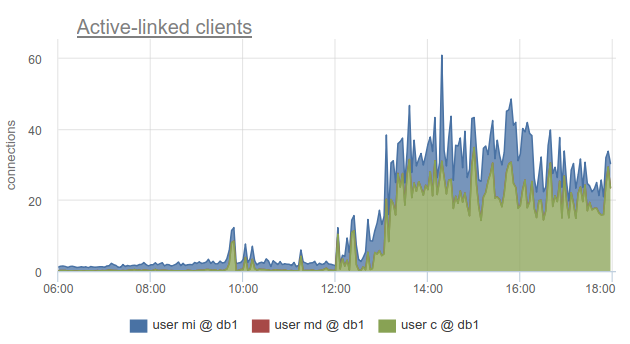
Wir bei okmeter sind noch weiter gegangen und haben eine Aufschlüsselung der Verbindungen hinzugefügt, die von den IP-Adressen der Clients verwendet werden, die sie geöffnet und verwendet haben. Auf diese Weise können Sie genau verstehen, welche Anwendungsinstanzen sich unterschiedlich verhalten:

Hier sehen wir IPs bestimmter Kubernetes von Herden, mit denen wir uns befassen müssen.
Fehler
Hier gibt es nichts besonders Kniffliges: pgbouncer schreibt Protokolle, in denen Fehler gemeldet werden, wenn das Limit der Clientverbindungen erreicht ist, das Zeitlimit für die Verbindung zum Server usw. Wir haben die pgbouncer-Protokolle selbst noch nicht erreicht :(
ROT für PgBouncer
Während sich die NUTZUNG mehr auf die Leistung konzentriert, geht es bei RED im Sinne von Engpässen meiner Meinung nach mehr um die Merkmale des eingehenden und ausgehenden Verkehrs im Allgemeinen und nicht um Engpässe. Das heißt, RED beantwortet die Frage: Funktioniert alles einwandfrei? Wenn nicht, hilft USE, das Problem zu verstehen.
Anforderungen
Es scheint, dass für die SQL-Datenbank und für den Proxy- / Verbindungsabzieher in einer solchen Datenbank alles recht einfach ist - Clients führen SQL-Anweisungen aus, bei denen es sich um Anforderungen handelt. Aus SHOW STATS nehmen wir total_requests und zeichnen seine Zeitableitung
rate(metric(name="pgbouncer.total_requests", database: "*"))

Tatsächlich gibt es jedoch verschiedene Arten des Ziehens, und die häufigsten sind Transaktionen. Die Arbeitseinheit für diesen Modus ist eine Transaktion, keine Abfrage. Dementsprechend bietet Pgbouner ab Version 1.8 bereits zwei weitere Statistiken an: total_query_count anstelle von total_requests und total_xact_count - die Anzahl der abgeschlossenen Transaktionen.
Jetzt kann die Arbeitslast nicht nur anhand der Anzahl der abgeschlossenen Anforderungen / Transaktionen charakterisiert werden, sondern Sie können beispielsweise die durchschnittliche Anzahl der Anforderungen pro Transaktion in verschiedenen Datenbanken anzeigen und in eine andere aufteilen
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

Hier sehen wir offensichtliche Änderungen im Lastprofil, die der Grund für die Änderung der Leistung sein können. Und wenn Sie nur die Rate der Transaktionen oder Anfragen betrachten, sehen Sie dies möglicherweise nicht.
ROTE Fehler
Es ist klar, dass sich RED und USE bei der Fehlerüberwachung überschneiden, aber es scheint mir, dass Fehler in der USE hauptsächlich Fehler bei der Anforderungsverarbeitung aufgrund einer 100% igen Auslastung betreffen, d. H. wenn der Dienst sich weigert, mehr Arbeit anzunehmen. Und Fehler für RED wären besser, um Fehler aus Sicht des Kunden und der Kundenanforderungen genau zu messen. Das heißt, nicht nur in einer Situation, in der der Pool im PgBouncer voll ist oder ein anderes Limit funktioniert hat, sondern auch, wenn Anforderungszeitlimits wie "Abbruch der Anweisung aufgrund eines Anweisungszeitlimits", Stornierungen und Rollbacks von Transaktionen durch den Client usw. funktioniert haben. e. übergeordnete, näher an der Geschäftslogik liegende Fehlertypen.
Dauer
Auch hier helfen uns SHOW STATS mit kumulativen Zählern total_xact_time , total_query_time und total_wait_time , indem wir sie durch die Anzahl der Anfragen bzw. Transaktionen dividieren. Wir erhalten die durchschnittliche Anforderungszeit, die durchschnittliche Transaktionszeit und die durchschnittliche Wartezeit pro Transaktion. Ich habe bereits eine Grafik über die erste und dritte gezeigt:
Was kannst du sonst noch cool bekommen? Das bekannte Antimuster bei der Arbeit mit der Datenbank und Postgres, insbesondere wenn die Anwendung eine Transaktion öffnet, eine Anfrage stellt, dann (für eine lange Zeit) beginnt, ihre Ergebnisse zu verarbeiten, oder noch schlimmer - geht zu einem anderen Dienst / einer anderen Datenbank und stellt dort Anfragen. Während dieser ganzen Zeit "hängt" die Transaktion in den geöffneten Postgres, der Dienst kehrt dann zurück und stellt weitere Anforderungen, Aktualisierungen in der Datenbank und schließt die Transaktion erst dann. Für Postgres ist dies besonders unangenehm, weil pg Arbeiter sind teuer. So können wir überwachen, wann eine solche Anwendung idle in transaction im Postgres selbst inaktiv ist - gemäß der pg_stat_activity in pg_stat_activity , aber es gibt immer noch die gleichen beschriebenen Probleme mit der Stichprobe, weil pg_stat_activity gibt nur das aktuelle Bild an. In PgBouncer können wir die Zeit, die Clients in total_query_time Anforderungen total_query_time , von der Zeit subtrahieren, die in Transaktionen total_xact_time verbracht wird - dies ist die Zeit eines solchen Leerlaufs. Wenn das Ergebnis immer noch durch total_xact_time geteilt wird, wird es normalisiert: Ein Wert von 1 entspricht einer Situation, in der Clients zu 100% idle in transaction total_xact_time sind. Und mit einer solchen Normalisierung ist es leicht zu verstehen, wie schlimm alles ist:
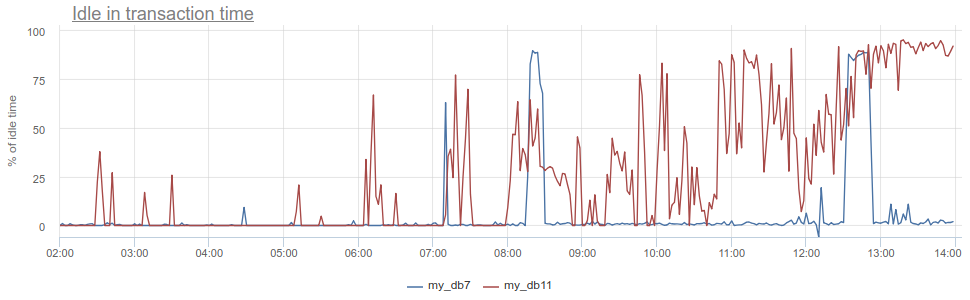
total_xact_time - total_query_time zu Duration zurückkehren, kann die Metrik total_xact_time - total_query_time durch die Anzahl der Transaktionen geteilt werden, um zu sehen, wie hoch die durchschnittliche Leerlaufanwendung pro Transaktion ist.
Meiner Meinung nach sind USE / RED-Methoden am nützlichsten, um zu strukturieren, welche Metriken Sie aufnehmen und warum. Da wir uns mit der Vollzeitüberwachung beschäftigen und verschiedene Infrastrukturkomponenten überwachen müssen, helfen uns diese Methoden, die richtigen Metriken zu ermitteln, die richtigen Zeitpläne und Auslöser für unsere Kunden zu erstellen.
Eine gute Überwachung kann nicht sofort durchgeführt werden, sondern ist ein iterativer Prozess. In okmeter.io haben wir nur eine kontinuierliche Überwachung (es gibt viele Dinge, aber morgen wird es besser und detaillierter sein :)