
Mein Name ist Yuri Nevinitsin und ich beschäftige mich mit dem System der internen Statistik in OK. Ich möchte darüber sprechen, wie wir ein 50-Terabyte-Analysesystem in Echtzeit, in dem täglich Milliarden von Ereignissen protokolliert werden, von Microsoft SQL auf eine Spaltenbasis namens Druid übertragen haben. Gleichzeitig lernen Sie einige Rezepte für die Verwendung von
Druiden .
Warum brauchen wir Statistiken?
Wir möchten alles über unsere Site wissen und protokollieren daher nicht nur das Verhalten von Festplatten, Prozessoren usw., sondern auch jede Benutzeraktion, jede Interaktion zwischen Subsystemen und allen internen Prozessen fast aller unserer Systeme. Das Statistiksystem ist eng in den Entwicklungsprozess eingebunden.
Basierend auf den Daten aus dem Statistiksystem legen unsere Manager Ziele für die Teams fest, verfolgen deren Leistung und Schlüsselindikatoren. Administratoren und Entwickler überwachen den Betrieb aller Systeme, untersuchen Vorfälle und Anomalien. Die automatische Überwachung überwacht ständig und erkennt frühzeitig Probleme und prognostiziert Grenzüberschreitungen. Außerdem werden ständig Funktionen und Experimente gestartet, Aktualisierungen und Änderungen vorgenommen. Und wir überwachen die Auswirkungen all dieser Aktionen über das Statistiksystem. Wenn sie sich weigert, können wir keine Änderungen an der Website vornehmen.
Unsere Statistiken werden hauptsächlich in Form von Grafiken dargestellt. In der Regel wird das Diagramm mehrere Tage gleichzeitig angezeigt, damit die Dynamik klar ist. Hier ist ein Beispiel meiner Experimente mit Druiden. Hier ist ein Diagramm des Datenladens (Linien / 5 min).
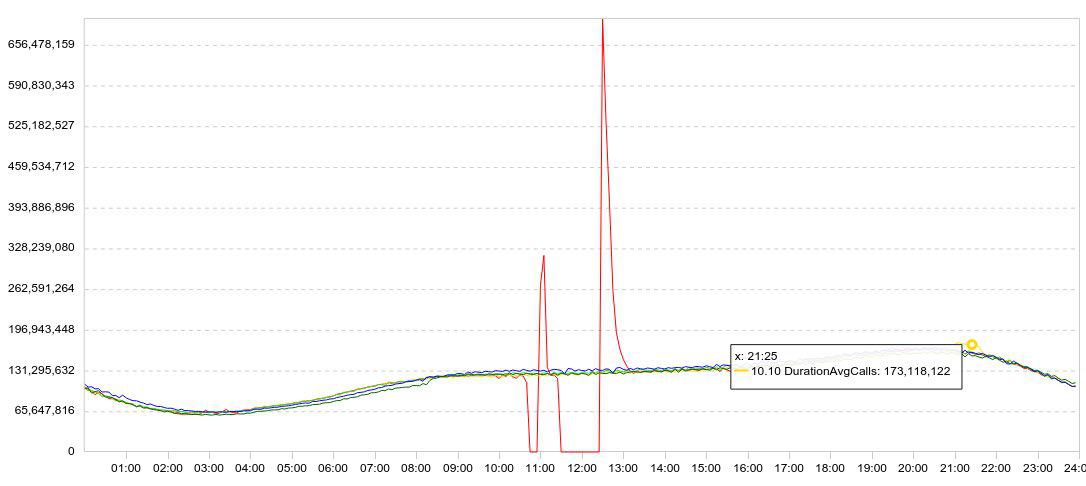
Ich verlangsamte den Download (das rote Diagramm stürzt auf Null ab), wartete eine Weile, startete den Download neu und beobachtete, wie schnell Druid die gesammelten Daten laden konnte (Spitzen nach Fehlern).
Jeder Zeitplan kann um einen beliebigen Parameter erweitert werden, z. B. nach Host, Tabelle, Operation usw. Wir haben auch Langzeit-Charts mit jährlicher Dynamik. Im Folgenden sehen Sie beispielsweise ein Diagramm der täglichen Zunahme der Anzahl der Einträge in Druid.
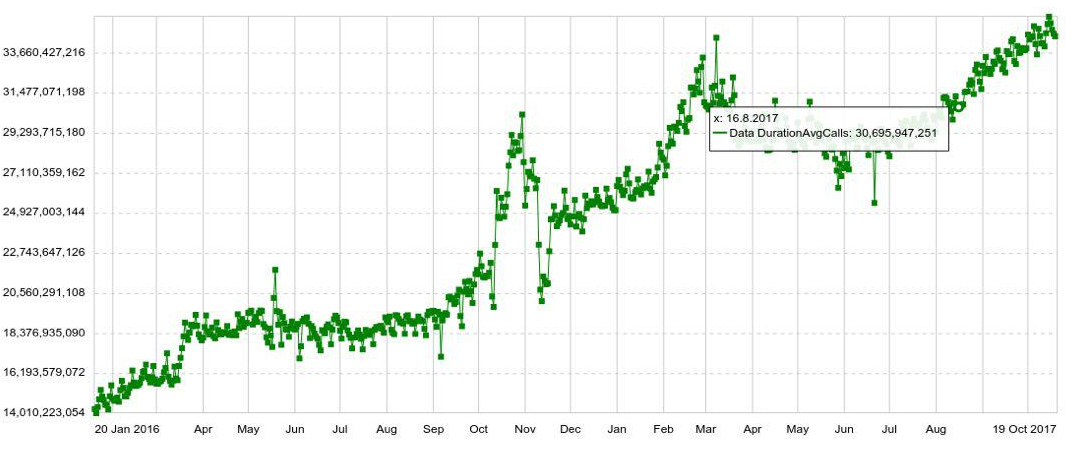
Wir können auch mehrere Diagramme in separaten Bedienfeldern (Dashboards) kombinieren, was sich als sehr praktisch herausstellte. Und selbst wenn der Benutzer nur ein paar Hundert Diagramme sehen muss, öffnet er sie nicht einzeln, sondern im Bedienfeld, was die Belastung des Systems erhöht.
Das Problem
Obwohl das Datenvolumen gering war, haben wir SQL recht gut gemeistert. Mit zunehmendem Datenvolumen verlangsamte sich jedoch die Diagrammausgabe. Am Ende verzögerte sich die Statistik zur Hauptverkehrszeit um eine halbe Stunde, und die durchschnittliche Antwortzeit eines Diagramms erreichte 6 Sekunden. Das heißt, jemand erhielt den Zeitplan in 2 Sekunden, jemand in 10-20 und jemand in einer Minute. (Informationen zur Entwicklung des Systems in SQL finden Sie
hier )
Wenn Sie eine Anomalie oder einen Vorfall untersuchen, müssen Sie normalerweise ein Dutzend Diagramme öffnen und anzeigen, von denen jedes aus dem vorherigen folgt. Sie können nicht gleichzeitig geöffnet werden. Ich musste 10 mal 10-20 Sekunden warten. Es war sehr nervig.
Die Migration
Sie könnten immer noch etwas aus dem System herausdrücken, Server hinzufügen ... Aber ungefähr zur gleichen Zeit änderte Microsoft seine Lizenzierungsrichtlinie. Wenn wir weiterhin SQL Server verwenden würden, müssten wir Millionen von Dollar verschenken. Daher beschlossen sie, zu migrieren.
Die Anforderungen waren wie folgt:
- Statistiken sollten nicht verzögert werden (mehr als 2 Minuten).
- Das Diagramm sollte sich in nicht mehr als 2 Sekunden öffnen.
- Das gesamte Bedienfeld sollte sich in nicht mehr als 10 Sekunden öffnen.
- Das System muss fehlertolerant sein und den Verlust eines Rechenzentrums überstehen können.
- Das System muss leicht skalierbar sein.
- Das System sollte leicht zu modifizieren sein, daher wollten wir, dass es in Java ist.
All dies wurde uns nur von Druiden angeboten. Es verfügt auch über eine vorläufige Aggregation, mit der Sie etwas mehr Volumen sparen und während des Einfügens von Daten indizieren können. Druid unterstützt alle Arten von Abfragen, die für unsere Statistiken benötigt werden. Daher schien es, dass wir SQL Server leicht durch Druid ersetzen konnten.
Natürlich haben wir nicht nur Druiden als Kandidaten für den Umzug in Betracht gezogen. Mein erster Gedanke war, Microsoft SQL Server durch PostgreSQL zu ersetzen. Dies würde jedoch nur das Problem der finanziellen Kosten lösen, aber nicht zur Erreichbarkeit und Skalierung beitragen.
Wir haben auch Influx analysiert, aber es stellte sich heraus, dass der Teil, der für hohe Verfügbarkeit und Skalierbarkeit verantwortlich ist, geschlossen ist. Prometheus ist bei allem Respekt vor seiner Leistung besser auf die Überwachung abgestimmt und kann sich weder einer hohen Verfügbarkeit noch einer einfachen Skalierbarkeit rühmen. OpenTSDB eignet sich auch besser zur Überwachung, es verfügt nicht über Indizes für alle Felder. Click House haben wir nicht in Betracht gezogen, da es zu diesem Zeitpunkt noch nicht da war.
Setzen Sie Druide. Terabyte Daten wurden migriert. Unmittelbar nach dem Wechsel von SQL Server zu Druid wurde die Anzahl der Diagrammansichten um das Fünffache erhöht. Dann fingen sie an, "schwere" Statistiken zu erstellen, für die sie Angst hatten, früher zu führen, weil SQL würde kaum damit umgehen.
Jetzt nimmt Druide von 12 Knoten (40 Kerne, 196 GB RAM) 500.000 Ereignisse pro Sekunde pro Hauptverkehrszeit auf, während es einen großen Sicherheitsspielraum gibt (MAX-Spalte: fast das Fünffache des CPU-Spielraums).
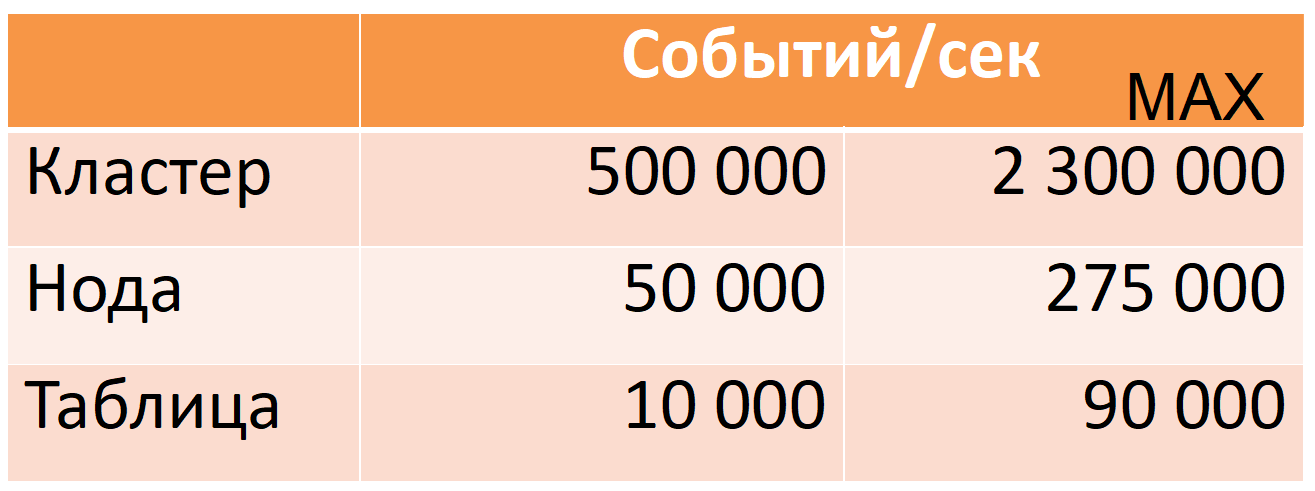
Diese Zahlen basieren auf Produktionsdaten. Ich werde Ihnen sagen, wie wir dies erreicht haben, aber zuerst werde ich Druiden genauer beschreiben.
Druide
Dies ist ein verteiltes Spalten-Zeitreihen-OLAP-System. Die Dokumentation enthält nicht die üblichen Konzepte der SQL-Welt für eine Tabelle (stattdessen Datenquelle) oder eine Zeichenfolge (stattdessen Ereignis), aber ich werde sie zur einfacheren Beschreibung verwenden.
Druide basieren auf mehreren Datenannahmen (Einschränkungen):
- Jede Datenzeile hat einen Zeitstempel, der monoton wächst (standardmäßig innerhalb eines Fensters von 10 Minuten).
- Daten ändern sich nicht, nur Einfügen (Aktualisierungsvorgang nicht).
Auf diese Weise können Sie Daten in sogenannte Zeitsegmente schneiden. Ein Segment ist eine minimale unteilbare und unveränderliche "Partition" einer Tabelle für einen bestimmten Zeitraum. Alle Datenoperationen, alle Abfragen werden segmentweise ausgeführt.
Jedes Segment ist autark: Neben der in Spaltenform geschriebenen Haupttabelle enthält es auch Verzeichnisse und Indizes, die für die Ausführung von Abfragen erforderlich sind. Wir können sagen, dass ein Segment eine schreibgeschützte Datenbank mit kleinen Spalten ist (eine detailliertere Beschreibung des Segmentgeräts wird unten gegeben).
Dies führt wiederum zu einer „Verteilung“: Die Fähigkeit, eine große Datenmenge in kleine Segmente zu unterteilen, um Berechnungen parallel durchzuführen (sowohl auf einer Maschine als auch auf vielen gleichzeitig).
Wenn Sie mindestens eine Zeile „aktualisieren“ müssen, müssen Sie das gesamte Segment erneut laden. Es ist möglich und alles ist dafür bereit. Jedes Segment hat eine Version, und ein Segment mit einer neueren Version ersetzt automatisch das Segment mit der alten Version (wenn jedoch regelmäßig Updates erforderlich sind, sollte neu bewertet werden, ob Druid für diesen Anwendungsfall geeignet ist).
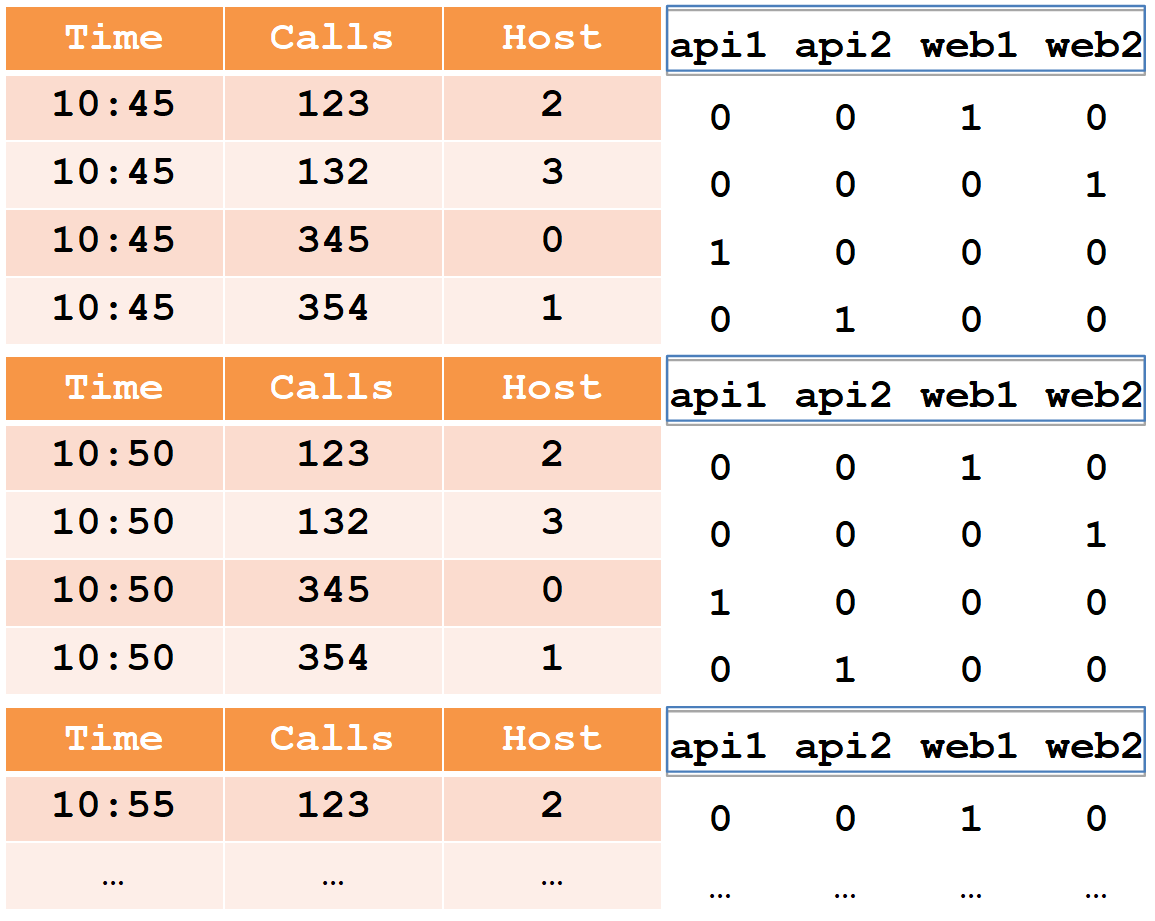
Zur Beschreibung des Gerätesegments betrachten wir ein einfaches Beispiel in der üblichen tabellarischen Form:
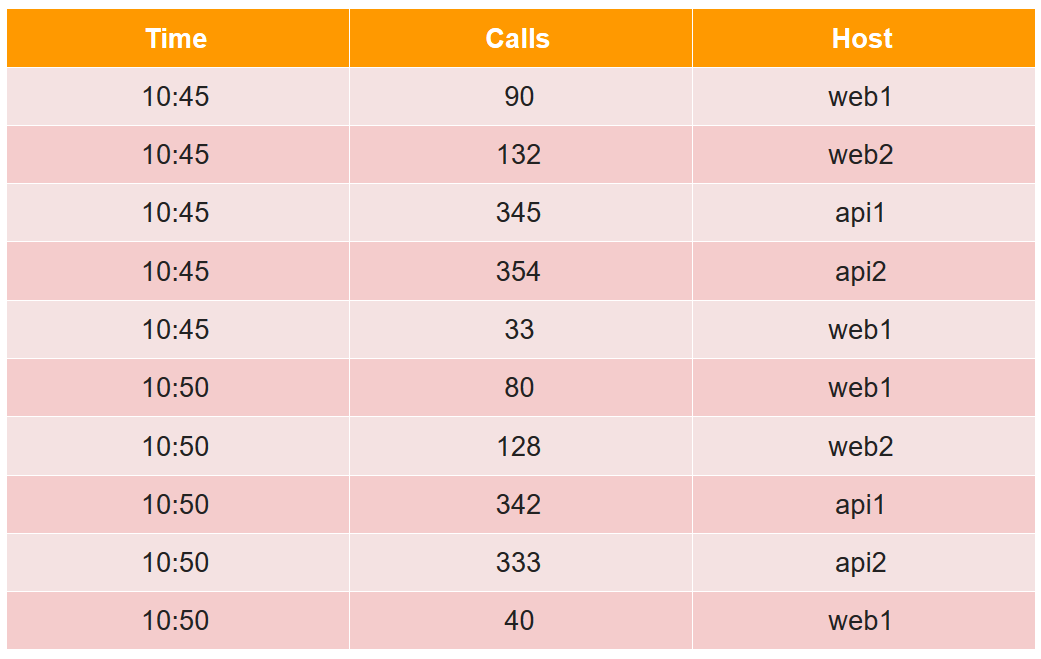
In dieser Tabelle ist die Anzahl der Anrufe in zwei fünf Minuten von vier Hosts angegeben (beachten Sie, dass für den web1-Host in jedem Fünf-Minuten-Zeitraum zwei Leitungen vorhanden sind).
Alle Datenzellen aus Sicht des Druiden sind in drei Typen unterteilt:
- Zeitstempel - UTC-Zeitstempel in ms (im Beispiel ist es Zeit).
- Metriken müssen berechnet werden (Summe, Min, Max, Anzahl, ...), und Sie müssen sie für jede Tabelle im Voraus kennen (im Beispiel ist dies Aufrufe, und wir berechnen die Summe).
- Dimensionen - Dies können Sie gruppieren und filtern (Sie müssen sie nicht im Voraus kennen und können im laufenden Betrieb geändert werden) (im Beispiel ist dies Host).
Beim Einfügen werden alle Zeilen nach dem vollständigen Satz von Dimensionen + Zeitstempel gruppiert. Wenn sie mit jeder der Metriken übereinstimmen, wird die Aggregationsfunktion "ihre" angewendet (daher gibt es keine Zeilen mit demselben Satz von Dimensionen + Zeitstempel). So sieht unser Beispiel nach dem Einfügen in den Druiden folgendermaßen aus:

Der Zeitstempel und alle Metriken (in unserem Fall Time and Calls) werden als Arrays mit Zahlen vom Typ long geschrieben (float und double werden ebenfalls unterstützt). Für jede der Dimensionen (in unserem Fall Host) wird ein Wörterbuch erstellt - ein sortierter Satz von Zeichenfolgen (mit Hostnamen). Die Hostspalte selbst wird als int-Array geschrieben und gibt die Zahlen im Wörterbuch an.
Bitte beachten Sie, dass nach dem Einfügen in den Druiden Zeilenpaare für den web1-Host mit demselben Zeitstempel aggregiert wurden und der Gesamtbetrag in Anrufen aufgezeichnet wurde (es ist unmöglich, die Anfangsdaten aus dem Druiden zu extrahieren).
Für eine schnelle Datenfilterung sind Indizes erforderlich, da Millionen von Zeilen und Tausende von Hosts vorhanden sein können. Indizes sind Bitmaps, eine für jede Zeile im Wörterbuch.

Einheiten geben Zeilennummern an, an denen dieser Host teilnimmt. Um zwei Hosts zu filtern, müssen Sie zwei Bitmaps nehmen, sie durch ODER kombinieren und die Zeilennummern in Einheiten der resultierenden Bitmap auswählen.
Ein Druide besteht aus vielen Komponenten.
Erstens hat es mehrere externe Abhängigkeiten.

- Lagerung Dort speichert Druid die Segmente einfach in komprimierter Form. Es kann ein lokales Verzeichnis sein, HDFS, Amazon S3. Hier wird nur Platz verwendet, es werden keine Berechnungen durchgeführt.
- Meta: Eine Datenbank für Meta-Informationen. Diese Datenbank speichert die vollständige Datenkarte: Welche Segmente sind relevant, welche sind veraltet, welcher Pfad ist gespeichert.
- Mit ZooKeeper führt das System eine Ermittlung durch und gibt bekannt, auf welchen Druidenknoten welche Segmente zur Abfrage verfügbar sind.
- Der Cache der ausgeführten Anforderungen kann zwischengespeichert oder ein lokaler Cache im Java-Heap sein.
Zweitens besteht Druide selbst aus mehreren Arten von Komponenten.
- Echtzeitknoten laden den Strom frischer Daten in der Reihenfolge ihres Empfangs und bedienen Anforderungen dafür.
- Historische Knoten enthalten die gesamte Datenmasse und bedienen Anforderungen dafür. Wenn wir sagen, dass wir einen 300-TB-Cluster haben, meinen wir historische Knoten.
- Der Broker ist für die Verteilung der Berechnungen zwischen historischen und Echtzeitknoten verantwortlich.
- Der Koordinator ist für die Zuordnung von Segmenten zu historischen Knoten und für die Replikation verantwortlich.
- Indizierungsdienst, mit dem Sie Daten in Stapeln (erneut) laden können, um beispielsweise einen Teil der Daten zu "aktualisieren".
Datenstrom
 Fettgedruckte Pfeile zeigen einen Datenstrom an, dünne Pfeile zeigen einen Metadatenstrom an.
Fettgedruckte Pfeile zeigen einen Datenstrom an, dünne Pfeile zeigen einen Metadatenstrom an.Ein Echtzeitknoten nimmt Daten, Indizes und schneidet nach Zeit, z. B. nach Tag, in Segmente.
Jedes neue Segment eines Echtzeitknotens schreibt in den Speicher und hinterlässt eine Kopie, um Anforderungen dafür zu bearbeiten. Dann zeichnet es Metadaten auf, dass ein neues Segment entlang eines solchen und eines solchen Pfades im Repository angezeigt wurde.
Diese Informationen werden vom Koordinator empfangen und die Metadatenbasis regelmäßig erneut gelesen. Wenn er ein neues Segment findet, befiehlt er (über ZooKeeper) mehreren historischen Knoten, dieses Segment herunterzuladen. Sie laden herunter und geben (über ZooKeeper) bekannt, dass sie ein neues Segment haben. Wenn ein Echtzeitknoten diese Nachricht empfängt (über ZooKeeper), löscht er seine Kopie, um Platz für neue Daten zu schaffen.
Anfrage bearbeiten

Drei Arten von Knoten nehmen an der Anforderungsverarbeitung teil: Broker, Echtzeit und Verlauf. Die Anfrage geht an den Broker, der weiß, auf welchen Knoten sich welche Segmente befinden. Es verteilt die Anforderung nach historischen (und Echtzeit-) Knoten, die die gewünschten Segmente speichern. Historische Knoten parallelisieren die Berechnungen so weit wie möglich, senden die Ergebnisse an den Broker und er gibt sie an den Kunden weiter. Durch die Kombination dieses Schemas mit der Speicherung von Spaltendaten kann Druid sehr schnell große Informationsmengen verarbeiten.
Hohe Verfügbarkeit
Wie Sie sich erinnern, hat Druid in der Liste der Abhängigkeiten eine Basis für Metadaten, die MySQL oder PostgreSQL sein können. Apache Derby wird ebenfalls erwähnt, aber dieses Produkt kann nicht für die Produktion verwendet werden, sondern nur für die Entwicklung (so wie ich es verstehe, wird Derby in einer eingebetteten Form verwendet, um mysql / pgsql in einer jungfräulichen Umgebung nicht zu erhöhen).
Was passiert, wenn diese Basis ausfällt (und / oder Speicher und / oder der Koordinator)? Ein Echtzeitknoten kann keine Metadaten (und / oder Segmente) schreiben. Dann kann der Koordinator sie nicht erneut lesen und findet kein neues Segment. Der historische Knoten lädt ihn nicht herunter und der Echtzeitknoten löscht seine Kopie nicht, lädt jedoch weiterhin die neuesten Daten herunter. Infolgedessen beginnen sich Daten in Echtzeitknoten anzusammeln. Dies kann nicht auf unbestimmte Zeit so weitergehen. Es ist jedoch bekannt, welche Ressourcen auf Echtzeitknoten verfügbar sind und welche Art von Datenfluss wir haben. Daher haben wir eine vorhersehbare Zeitspanne, für die wir die ausgefallene Basis (und / oder Speicher und / oder Koordinator) reparieren können.
Da die unterstützten mysql / pgsql keine sofortige Hochverfügbarkeit garantieren, haben wir uns entschlossen, auf Nummer sicher zu gehen, und unsere eigene (vorgefertigte) Lösung auf Basis von Cassandra verwendet, da sie sofort eine hohe Verfügbarkeit bietet (mehr dazu
hier ).
Darüber hinaus haben wir die Echtzeitknoten so finalisiert, dass bei übermäßiger Akkumulation die ältesten Daten gelöscht werden und Speicherplatz für neue frei wird. Dies ist für uns sehr wichtig, da die Situation, in der wir die ausgefallene Basis (und / oder Speicher und / oder den Koordinator) nicht über einen längeren Zeitraum erhöhen können und sich viele Daten ansammeln, höchstwahrscheinlich eine Folge eines großen Unfalls ist. Und in diesem Moment sind die neuesten Daten am wichtigsten.
Druide und ZooKeeper
Mit ZooKeeper ist alles besser und schlechter. Besser, da ZooKeeper selbst fehlertolerant ist, ist die Replikation sofort einsatzbereit. Es scheint, dass das passieren könnte?
Im Allgemeinen ist dieses Kapitel nicht mehr relevant. Und dies ist keine Erfolgsgeschichte, dies ist ein Schmerz, den (sowohl wir als auch der frische Druide) beschlossen haben, fast alle Daten von ZooKeeper radikal zu entfernen, und jetzt fordern die Druiden-Knoten sie direkt über HTTP voneinander an.
ZooKeeper hat zwei Arten von Zeitüberschreitungen. Das Verbindungszeitlimit ist ein einfaches Netzwerkzeitlimit, nach dem der Client erneut eine Verbindung zu ZooKeeper herstellt und versucht, seine Sitzung wiederherzustellen. Das Sitzungszeitlimit, nach dem die Sitzung gelöscht und alle in dieser Sitzung erstellten
kurzlebigen Daten gelöscht werden (von ZooKeeper selbst), wird allen anderen ZooKeeper-Clients mitgeteilt.
Auf dieser Grundlage funktioniert die Erkennung im Druiden: Beim Start erstellt jeder Knoten eine neue Sitzung in ZooKeeper und zeichnet
kurzlebige Daten über sich selbst auf: Host: Port, Knotentyp (Broker / Echtzeit / Historisch / ...), Verbindungszeitstempel usw. ... Andere Druidenknoten erhalten Benachrichtigungen von ZooKeeper und lesen diese Daten, damit sie erfahren, dass ein neuer Druidenknoten gestiegen ist und um welche Art von Knoten es sich handelt. Wenn ein Druidenknoten nach dem Timeout seiner Sitzung ausfällt, werden die Daten darüber von ZooKeeper gelöscht, und die anderen Druidenknoten wissen davon. Damit sie schneller davon erfahren, bevorzugen wir eine kleine Sitzungszeitüberschreitung.
Wenn ein Echtzeit- oder historischer Knoten ansteigt, schreibt er neben Daten über sich selbst auch eine Liste der Segmente in ZooKeeper (dies sind auch
kurzlebige Daten). Weiter auf dem Weg werden Segmente auf Echtzeit- und historischen Knoten erstellt, neue und alte werden gelöscht, und jeder Knoten spiegelt dies in seiner Liste in ZooKeeper wider. Diese Liste kann groß sein, daher wird sie in Teile aufgeteilt, sodass nicht die gesamte Liste, sondern nur der geänderte Teil überschrieben wird.
Wenn der Broker wiederum einen neuen Echtzeit- oder historischen Knoten sieht, subtrahiert er auch seine Liste der Segmente von ZooKeeper, um Anforderungen an diesen Knoten zu verteilen. Echtzeitknoten lesen diese Liste, um ihre Kopie des Segments zu entfernen, das auf dem historischen Knoten angezeigt wurde. Da die Liste in Teile unterteilt und in Teile überschrieben ist, teilt Ihnen ZooKeeper mit, welcher Teil geändert wurde, nur dass er erneut gelesen wird.
Wie gesagt, diese Liste kann lang sein. Wenn in ZooKeeper viele Daten vorhanden sind, stellt sich heraus, dass diese nicht mehr so stabil sind. In unserem Fall begannen offensichtliche Probleme, als die Anzahl der Segmente etwa 7 Millionen erreichte. Der ZooKeeper-Snapshot belegte dann 6 GB.
Was passiert, wenn ein Druidenknoten den Kontakt zu ZooKeeper verliert?
Druid arbeitet mit ZooKeeper so zusammen, dass im Falle eines Sitzungszeitlimits jeder Knoten eine neue Sitzung erstellt und alle seine Daten dort schreibt und die Daten anderer Knoten erneut liest. Da es viele Daten gibt, nimmt der Verkehr auf ZooKeeper ab. Dies kann zu einer Zeitüberschreitung auf anderen Knoten des Druiden führen, dann beginnen auch diese neu zu schreiben und neu zu lesen. Somit wächst der Datenverkehr wie eine Lawine bis zu dem Punkt, an dem ZooKeeper die Synchronisation zwischen seinen Instanzen verliert und Snapshots hin und her treibt.
Was sieht der Benutzer gerade?
Wenn ein Broker den Kontakt zu ZooKeeper verliert (und ein Sitzungszeitlimit auftritt), weiß er nicht mehr, welche Segmente auf welchen historischen Knoten liegen. Und gibt leere Antworten. Das heißt, wenn ZooKeeper nicht verfügbar ist, funktioniert Druid nicht. Es ist völlig unmöglich, es zu „heilen“, aber es ist an einigen Stellen möglich, Strohhalme zu verbreiten.
Erstens können Sie Daten aus ZooKeeper löschen. Es ist in Ordnung, wenn sie sich verlaufen: Druide werden sie einfach überschreiben. Wenn das Problem mit ZooKeeper bereits begonnen hat, wird für die schnellste Lösung empfohlen, ZooKeeper zu deaktivieren, die Daten zu löschen und leer zu lassen und nicht darauf zu warten, dass sie sich selbst beheben.
Jetzt erhöhen wir das Sitzungszeitlimit. Was passiert in diesem Fall?
Angenommen, der historische Knoten wurde nicht korrekt neu gestartet und die alte Sitzung nicht aus ZooKeeper gelöscht, während eine neue Sitzung erstellt und dort eine Reihe von Daten geschrieben wurden. Während die alte Sitzung noch aktiv ist und das Zeitlimit nicht abgelaufen ist, werden zwei Kopien der Daten in ZooKeeper gespeichert. Wenn viele solcher Knoten sofort neu gestartet werden, werden viele Daten dupliziert. Daher müssen Sie Speicher für ZooKeeper bereitstellen, damit dieser nicht ausgeht und ZooKeeper nicht nicht mehr funktioniert. Warum konnten die Daten der alten Sitzung nicht gelöscht werden?
Aus dem gleichen Grund ist es notwendig, den Betrieb historischer Knoten korrekt abzuschließen, da sie zu diesem Zeitpunkt ihre Daten aus ZooKeeper löschen und dies für eine lange Zeit tun können. Die Fertigstellung historischer Knoten dauert etwa eine halbe Stunde.
Historische Knoten haben eine weitere Funktion. Wenn sie beginnen, sehen sie sich an, welche Segmente auf ihnen gespeichert sind, und dann werden Informationen dazu in ZooKeeper geschrieben. Und da die Daten mehr oder weniger gleichmäßig über historische Knoten verteilt sind, werden sie ungefähr zur gleichen Zeit in ZooKeeper geschrieben, wenn Sie sie gleichzeitig ausführen. Dies erhöht wiederum die Wahrscheinlichkeit eines wellenartigen Verkehrswachstums und von Zeitüberschreitungen. Daher müssen Sie historische Knoten nacheinander ausführen, um die Aufzeichnungssitzungen in ZooKeeper rechtzeitig zu verteilen.
Wir haben auch zwei weitere Optimierungen vorgenommen:
- Wir haben die Arbeit mit ZooKeeper etwas neu programmiert, sodass nur die Knoten, die sie benötigen, von Druid gelesen werden. realtime, , . , . , .
- , ZooKeeper, , . ZooKeeper 6 2 ( ).
8 ; .
Druid
realtime , . - ( , , ). , MMAP ( ). . .
-, realtime- , JVM , .

. : 1) 2) . , . , , . , , , . ( , , ).
, realtime- , , .. , , , ( ).
, . , , .
, Druid . , , , .
, . , (web%, api%).
- Druid — . .
- , .
- Druid , , : , , , .
- Druid , , calls.
, 5 % , 95 % — .
, , realtime- .
, ( 10:45) . - , -. , ( 10:50) , -. Usw. , , «calls», «time» «host» .
-. , «» . , , . ( 95% ) , : , . 100 , 1000.
? , . , realtime , . (.. historical realtime-), .
, : . , , . 100 . , . .
. 80% , , , . . . , selector, . , .
, , , . , . , 8 . Druid. , , Druid, . , . :

, , . . , , . . 27 . , 27 , 27 .
, . 27 , 9, 9 , .
.

— : , , . — : , , . — : , , . — , . , . , 27. 9, . ( 95% ) 9 . 27 .
14 . . , 14 . 14 . . , , 10 , . .
, 2 . 11 , 74 . , . 74 ? , .
Druid . , , , . , , . , , . , , .
, Druid . , ( ) , . 5 : , . . ( java), . Druid , .
Zusammenfassung
, , SQL Server, Microsoft.
, / .
, , .
20 , , 18 .
one-cloud (
https://habr.com/company/odnoklassniki/blog/346868/ ), .