Hallo Habr. Ich möchte über einen der Ansätze zur Lösung des Problems der Sprecherdiarisierung sprechen und zeigen, wie diese Methode in Python implementiert werden kann. Um den Leser nicht abzuschrecken, werde ich keine komplexen mathematischen Formeln angeben (auch weil ich selbst „kein echter Schweißer“ bin), aber ich werde versuchen, alles in einfacher Sprache zu erklären und alles so zu erzählen, dass ein Entwickler, der noch nie auf maschinelles Lernen gestoßen ist, es verstanden hat.
Bei der Vorbereitung dieses Artikels habe ich zwischen zwei Optionen gewählt: für diejenigen, die bereits mit Data Science vertraut sind, und für diejenigen, die einfach gut programmieren. Am Ende entschied ich mich für die zweite Option und entschied, dass dies eine gute Demonstration der Fähigkeiten von DS sein würde.
Erklärung des Problems
Wie Wikipedia uns
sagt , ist Diarisierung der Prozess des Aufteilens eines eingehenden Audiostreams in homogene Segmente, je nachdem, ob der Audiostream dem einen oder anderen Sprecher gehört. Mit anderen Worten, die Aufzeichnung muss in Teile geteilt und nummeriert werden: Eine Person spricht an diesen Orten und eine andere an diesen Orten. Aus Sicht des maschinellen Lernens gehören Aufgaben dieser Art zur Klasse des Lernens ohne Lehrer und werden als Clustering bezeichnet. Sie können
hier oder
hier beispielsweise lesen, welche Clustering-Methoden existieren, aber ich werde nur diejenigen diskutieren, die für uns nützlich sind - dies ist ein Gaußsches Mischungsmodell und spektrales Clustering. Aber etwas später über sie.
Beginnen wir von vorne.
Umweltvorbereitung
SpoilerIch war mir nicht sicher, ob ich diesen Abschnitt verlassen sollte - ich wollte den Artikel nicht in ein Tutorial verwandeln. Aber am Ende habe ich es verlassen. Wer es nicht benötigt, überspringt es und für diejenigen, die alles von Grund auf neu machen, erleichtert dieser Schritt den Start.
Im Allgemeinen ist Python neben R die Hauptsprache für die Lösung von Data Science-Problemen. Wenn Sie noch nicht versucht haben, darauf zu programmieren, empfehle ich dies dringend, da Sie mit Python viele Dinge elegant und buchstäblich in wenigen Zeilen ausführen können (übrigens gibt es solche) sogar so ein Mem).
Es gibt zwei sich separat entwickelnde Zweige von Python - Version 2 und 3. In meinen Beispielen habe ich Version 3.6 verwendet, aber auf Wunsch können sie problemlos auf Version 2.7 portiert werden. Es ist praktisch, einen dieser Zweige zusammen mit dem
Anaconda- Installationsprogramm bereitzustellen. Durch die Installation erhalten Sie sofort eine interaktive Shell für die Entwicklung - IPython.
Zusätzlich zur Entwicklungsumgebung selbst werden zusätzliche Bibliotheken benötigt: librosa (zum Arbeiten mit Audio und zum Extrahieren von Attributen), webrtcvad (zum Segmentieren) und pickle (zum Schreiben trainierter Modelle in eine Datei). Alle von ihnen werden durch einen einfachen Befehl in Anaconda Prompt installiert.
pip install [library]
Merkmalsextraktion
Beginnen wir mit der Extraktion von Features - Daten, mit denen Modelle für maschinelles Lernen arbeiten. Im Prinzip besteht das Tonsignal selbst bereits aus Daten, nämlich einer geordneten Anordnung von Schallamplitudenwerten, zu denen ein Header hinzugefügt wird, der die Anzahl der Kanäle, die Abtastfrequenz und andere Informationen enthält. Wir können diese Daten jedoch nicht direkt analysieren, da sie solche Dinge nicht enthalten. Unser Modell kann sagen: Ja, diese Teile gehören derselben Person.
Bei Sprachverarbeitungsaufgaben gibt es verschiedene Ansätze zum Extrahieren von Merkmalen. Eine davon ist das Erhalten von Mel-Frequenz-Cepstral-Koeffizienten. Sie wurden hier
bereits geschrieben , daher werde ich Sie nur geringfügig daran erinnern.
Das ursprüngliche Signal wird in Frames mit einer Länge von 16-40 ms geschnitten. Wenn sie dann ein
Hamming- Fenster auf den Rahmen anwenden, führen sie eine schnelle Fourier-Transformation durch und erhalten die spektrale Leistungsdichte. Dann wird mit einem speziellen „Kamm“ von Filtern, die gleichmäßig auf der Kreideskala angeordnet sind, ein Kreidespektrogramm erstellt, auf das eine diskrete Kosinustransformation (DCT) angewendet wird - ein weit verbreiteter Datenkomprimierungsalgorithmus. Die so erhaltenen Koeffizienten sind eine Art komprimierte Charakteristik des Rahmens, und da sich die von uns verwendeten Filter in der
Kreideskala befanden, tragen die Koeffizienten mehr Informationen im Wahrnehmungsbereich des menschlichen Ohrs. Typischerweise werden 13 bis 25 MFCC pro Frame verwendet. Da neben dem Spektrum selbst die Persönlichkeit der Stimme durch Geschwindigkeit und Beschleunigung gebildet wird, wird MFCC mit der ersten und zweiten Ableitung kombiniert.
Im Allgemeinen ist MFCC die häufigste Option für die Arbeit mit Sprache. Zusätzlich zu diesen gibt es jedoch andere Zeichen - LPC (Linear Predictive Coding) und PLP (Perceptual Linear Prediction). Manchmal wird auch LFCC verwendet, bei dem anstelle der Kreideskala linear verwendet wird.
Mal sehen, wie man MFCC in Python extrahiert.
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
Wie Sie sehen können, geschieht dies wirklich in nur wenigen Zeilen. Fahren wir nun mit dem ersten Clustering-Algorithmus fort.
Gaußsches Mischungsmodell
Ein Modell einer Mischung von Gaußschen Verteilungen legt nahe, dass unsere Daten eine Mischung aus mehrdimensionalen Gaußschen Verteilungen mit bestimmten Parametern sind.
Wenn Sie möchten, finden Sie leicht eine detaillierte Beschreibung des Modells und der Funktionsweise des
EM-Algorithmus , mit dem dieses Modell trainiert wird. Ich habe jedoch versprochen, mich nicht mit komplexen Formeln zu ärgern, und werde daher schöne Beispiele aus
diesem Artikel zeigen.
Wir werden vier Cluster generieren und sie zeichnen.
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
Wir werden ein Modell erstellen, unsere Daten trainieren und die Punkte erneut zeichnen, wobei wir jedoch das vorhergesagte Modell der Clustermitgliedschaft berücksichtigen.
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
Das Modell kam mit künstlichen Daten gut zurecht. Im Prinzip können durch Regulierung der Anzahl der Mischungskomponenten und der Art der Kovarianzmatrix (der Anzahl der Freiheitsgrade der Gaußschen) ziemlich komplizierte Daten beschrieben werden.

Wir wissen also, wie man Datenparametrisierung durchführt, und können ein Modell einer Mischung von Gaußschen Verteilungen trainieren. Jetzt könnte man versuchen, Clustering auf der Stirn durchzuführen - GMM auf dem MFCC zu trainieren, das aus dem Dialog extrahiert wurde. Und wahrscheinlich werden wir in einem idealen sphärischen Vakuumdialog, in dem jeder Sprecher in sein Gaußsches passt, ein gutes Ergebnis erzielen. Es ist klar, dass dies in Wirklichkeit niemals passieren wird. Tatsächlich modellieren sie mit Hilfe von GMM keinen Dialog, sondern jede Person in einem Dialog - das heißt, sie stellen sich vor, dass die Stimme jedes Sprechers in den extrahierten Zeichen durch eine eigene Gruppe von Gaußschen beschrieben wird.
Zusammenfassend kommen wir langsam zum Hauptthema.
Segmentierung
Traditionell besteht der Diarisierungsprozess aus drei aufeinander folgenden Blöcken - Spracherkennung (Voice Activity Detection), Segmentierung und Clustering (es gibt Modelle, in denen die letzten beiden Schritte kombiniert werden, siehe
LIA E-HMM ).
Im ersten Schritt wird die Sprache von verschiedenen Arten von Rauschen getrennt. Der VAD-Algorithmus bestimmt, ob es sich bei dem an ihn gesendeten Teil der Audiodatei um eine Rede handelt oder ob beispielsweise eine Sirene ertönt oder jemand niest. Es ist klar, dass eine Ausbildung mit einem Lehrer erforderlich ist, damit ein solcher Algorithmus von hoher Qualität ist. Dies bedeutet wiederum, dass Sie die Daten markieren müssen - mit anderen Worten, erstellen Sie eine Datenbank mit Sprachaufzeichnungen und allen Arten von Rauschen. Wir werden es faul machen - nehmen Sie ein fertiges
VAD , das nicht perfekt funktioniert, aber für den Anfang haben wir genug.
Der zweite Block schneidet die Sprachdaten mit einem aktiven Sprecher in Segmente. Der klassische Ansatz in dieser Hinsicht ist der Algorithmus zur Bestimmung des Sprecherwechsels basierend auf dem Bayes'schen Informationskriterium -
BIC . Das Wesentliche dieser Methode ist wie folgt: Ein Schiebefenster geht durch die Audioaufnahmen und beantwortet an jedem Punkt der Passage die Frage: "Wie werden die Daten an diesem Ort besser beschrieben - eine oder zwei Verteilungen?" Um diese Frage zu beantworten, wird der Parameter berechnet
DeltaBIC , basierend auf dem Vorzeichen, von dem eine Entscheidung getroffen wird, den Sprecher zu wechseln. Das Problem ist, dass diese Methode bei häufigen Lautsprecherwechseln und sogar bei Rauschen (die für die Aufzeichnung eines Telefongesprächs sehr charakteristisch sind) nicht sehr gut funktioniert.
Eine kleine ErklärungIm Original habe ich mit Telefonaufzeichnungen eines Callcenters mit einer durchschnittlichen Dauer von ca. 4 Minuten gearbeitet. Aus offensichtlichen Gründen kann ich diese Notizen nicht veröffentlichen. Für die Demonstration habe ich
ein Interview von einem Radiosender geführt. Im Falle eines langen Interviews würde diese Methode wahrscheinlich ein akzeptables Ergebnis liefern, aber sie funktionierte bei meinen Daten nicht.
Unter den Bedingungen, unter denen sich die Ansager nicht gegenseitig unterbrechen und ihre Stimmen sich nicht überschneiden, wird die VAD, die wir verwenden werden, mehr oder weniger mit der Aufgabe der Segmentierung fertig, daher werden die ersten beiden Schritte so aussehen.
In Wirklichkeit werden die Menschen sicherlich gleichzeitig sprechen. Darüber hinaus ist VAD an einigen Stellen fehlerhaft, da die Aufzeichnung nicht live ist, sondern ein Klebstoff, in dem Pausen herausgeschnitten werden. Sie können versuchen, das Schneiden in Segmente zu wiederholen, um die Aggressivität des VAD von 2 auf 3 zu erhöhen.
GMM-UBM
Jetzt haben wir separate Segmente und wir haben beschlossen, jeden Lautsprecher mit GMM zu modellieren. Wir extrahieren die Zeichen aus dem Segment und trainieren anhand dieser Daten das Modell. Lassen Sie es uns für jedes Segment tun und die resultierenden Modelle miteinander vergleichen. Es ist zu erwarten, dass Modelle, die in Segmenten derselben Person trainiert wurden, etwas ähnlich sind. Hier sind wir jedoch mit dem folgenden Problem konfrontiert: Wenn wir Zeichen aus einer 1 Sekunde langen Audiodatei mit einer Abtastfrequenz von 8000 Hz und einer Fenstergröße von 10 ms extrahieren, erhalten wir einen Satz von 800 MFCC-Vektoren. Unser Modell kann aus solchen Daten nicht lernen, da sie vernachlässigbar sind. Selbst wenn es nicht eine Sekunde, sondern zehn sind, reichen die Daten immer noch nicht aus. Und hier kommt das Universal Background Model (UBM) zur Rettung, es wird auch als sprecherunabhängig bezeichnet. Die Idee ist wie folgt. Wir werden GMM an einer großen Datenstichprobe trainieren (in unserem Fall ist dies eine vollständige Interviewaufzeichnung) und wir werden ein akustisches Modell eines verallgemeinerten Sprechers erhalten (dies wird unser UBM sein). Und dann werden wir dieses Modell mithilfe eines speziellen Anpassungsalgorithmus (siehe unten) in die aus jedem Segment extrahierten Merkmale „einpassen“. Dieser Ansatz wird nicht nur zur Diarisierung, sondern auch in Spracherkennungssystemen häufig verwendet. Um eine Person anhand der Stimme zu erkennen, müssen Sie zunächst ein Modell darauf trainieren. Ohne UBM müssen Sie mehrere Stunden Zeit haben, um die Sprache dieser Person aufzuzeichnen.
Aus jedem angepassten GMM extrahieren wir den Vektor der Scherkoeffizienten
mu (es ist auch ein Median oder eine mat. Erwartung, wenn Sie möchten) und basierend auf den Daten dieser Vektoren aus allen Segmenten werden wir Clustering durchführen (unten wird klar sein, warum es der Verschiebungsvektor ist).
Kartenanpassung
Die Methode, mit der wir UBM für jedes Segment anpassen, wird als maximale A-Posteriori-Anpassung bezeichnet. Im Allgemeinen ist der Algorithmus wie folgt. Zunächst wird die posteriore Wahrscheinlichkeit anhand der Anpassungsdaten und
ausreichender Statistiken für das Gewicht, den Median und die Varianz jedes Gaußschen berechnet. Dann werden die erhaltenen Statistiken mit den UBM-Parametern kombiniert und die Parameter des angepassten Modells werden erhalten. In unserem Fall werden wir nur die Mediane anpassen, ohne den Rest der Parameter zu beeinflussen. Trotz der Tatsache, dass ich versprochen habe, nicht tiefer in die Mathematik einzusteigen, werde ich immerhin drei Formeln zitieren, da die MAP-Anpassung der entscheidende Punkt in diesem Artikel ist.
Ei= frac1ni sumNt=1Pr(i|xt)xt
hat mui= betaiEi+(1− betai) mui
betai=ni/(ni+r beta)
Hier
Pr(i|xt) - hintere Wahrscheinlichkeit,
Ei - ausreichende Statistiken für
mu ,
hat mui - Median des angepassten Modells,
betai - Anpassungskoeffizient,
r beta - Compliance-Faktor.
Wenn all dies Unsinn erscheint und Verzweiflung verursacht - verzweifeln Sie nicht. Um die Funktionsweise des Algorithmus zu verstehen, ist es nicht erforderlich, sich mit diesen Formeln zu befassen. Die Funktionsweise des Algorithmus kann anhand des folgenden Beispiels leicht demonstriert werden:
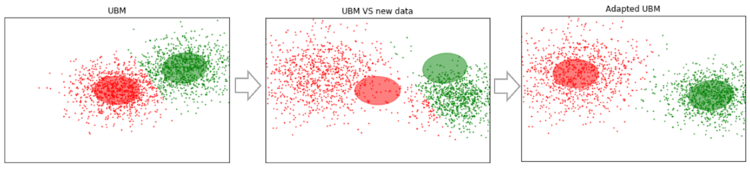
Angenommen, wir haben einige Daten, die groß genug sind, und wir haben UBM darauf trainiert (linkes Bild, UBM ist eine Zweikomponentenmischung von Gaußschen Verteilungen). Es erscheinen neue Daten, die nicht in unser Modell passen (Abbildung in der Mitte). Mit diesem Algorithmus verschieben wir die Zentren der Gaußschen so, dass sie auf den neuen Daten liegen (Abbildung rechts). Wenn wir diesen Algorithmus auf experimentelle Daten anwenden, erwarten wir, dass sich die Gaußschen auf Segmenten mit demselben Sprecher in eine Richtung verschieben und so Cluster bilden. Aus diesem Grund werden wir Scherdaten verwenden, um Segmente zu gruppieren
mu .
Nehmen wir also die MAP-Anpassung für jedes Segment vor. (Als Referenz: Zusätzlich zur MAP-Anpassung werden häufig die MLLR-Methode - Maximum Likelihood Linear Regression und einige ihrer Modifikationen verwendet. Sie versuchen auch, diese beiden Methoden zu kombinieren.)
SV = []
Nun, da wir für jedes Segment Daten haben
mu Endlich kommen wir zum letzten Schritt.
Spektrale Clusterbildung
Spektrale Clusterbildung wird in dem Artikel kurz beschrieben, auf den ich gleich zu Beginn verwiesen habe. Der Algorithmus erstellt einen vollständigen Graphen, in dem die Eckpunkte unsere Daten sind und die Kanten zwischen ihnen ein Maß für die Ähnlichkeit sind. Bei Spracherkennungsaufgaben wird eine Kosinusmetrik als solches Maß verwendet, da sie den Winkel zwischen den Vektoren berücksichtigt und deren Größe ignoriert (die keine Informationen über den Sprecher enthält). Durch Erstellen des Graphen werden die Eigenvektoren der Kirchhoff-Matrix berechnet (was im Wesentlichen eine Darstellung des resultierenden Graphen ist), und dann wird eine Standard-Clustering-Methode verwendet, beispielsweise die k-means-Methode. Es passt alles in zwei Codezeilen
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
Schlussfolgerungen und Zukunftspläne
Der beschriebene Algorithmus wurde mit verschiedenen Parametern getestet:
- MFCC-Nummer: 7, 13, 20
- MFCC in Kombination mit LPC
- Art und Anzahl der Gemische in GMM: voll [8, 16, 32], diag [8, 16, 32, 64, 256]
- UBM-Anpassungsmethoden: MAP (mit covariance_type = 'full') und MLLR (mit covariance_type = 'diag')
Infolgedessen blieben die Parameter subjektiv optimal: MFCC 13, GMM covariance_type = 'full' n_components = 16.
Leider hatte ich nicht die Geduld (ich habe vor mehr als einem Monat angefangen, diesen Artikel zu schreiben), um die empfangenen Segmente zu markieren und DER (Diariztion Error Rate) zu berechnen. Subjektiv bewerte ich die Funktionsweise des Algorithmus als "im Prinzip nicht schlecht, aber alles andere als ideal". Durch Clustering auf Vektoren aus den ersten hundert Segmenten (mit einem MAP-Durchgang) und anschließende Auswahl derjenigen, bei denen der Interviewer sagt (Mädchen, sie spricht viel weniger als der Gast dort), wird durch Clustering eine Liste erstellt
[1,2,25,26,46,48,49,61,85,86] das ist 100% getroffen. Gleichzeitig fallen Segmente aus, in denen beide Lautsprecher vorhanden sind (z. B. 14). Dies kann jedoch bereits auf den VAD-Fehler zurückgeführt werden. Darüber hinaus beginnen solche Segmente mit einer Zunahme der Anzahl von MAP-Durchgängen berücksichtigt zu werden. Ein wichtiger Punkt. Das Interview, mit dem wir gearbeitet haben, ist mehr oder weniger "sauber". Wenn verschiedene musikalische Einfügungen, Geräusche und andere nonverbale Dinge hinzugefügt werden, beginnt das Clustering zu hinken. Daher gibt es Pläne, unser eigenes VAD zu trainieren (weil webrtcvad beispielsweise Musik nicht von Sprache trennt).
Aufgrund der Tatsache, dass ich anfangs mit einem Telefongespräch gearbeitet habe, musste ich die Anzahl der Sprecher nicht schätzen. Die Anzahl der Sprecher ist jedoch nicht immer vorbestimmt, auch wenn es sich um ein Interview handelt. Zum Beispiel gibt es in
diesem Interview in der Mitte eine Ansage, die der Musik überlagert ist und von zwei weiteren Personen geäußert wird. Daher wäre es interessant, die Methode zur Schätzung der Anzahl der Sprecher auszuprobieren, die im ersten Artikel im Abschnitt der Referenzliste angegeben wurde (basierend auf einer Analyse der Eigenwerte der normalisierten Laplace-Matrix).
Referenzliste
Zusätzlich zu den Materialien unter den Links im Text und den Jupyter-Laptops wurden die folgenden Quellen zur Erstellung dieses Artikels verwendet:
- Lautsprecherdiarisierung mit GMM Supervector und Advanced Reduction Algorithms. Nurit Spingarn
- Merkmalsextraktionsmethoden LPC, PLP und MFCC bei der Spracherkennung. Namrata Dave
- MAP-Bewertung für mulivariate Gauß-Mischungsbeobachtungen von Markov-Ketten. Jean-Luc Gauvain und Chin-Hui Lee
- Zur Spektralclusteranalyse und einem Algorithmus. Andrew Y. Ng, Michael I. Jordan, Yair Weiss
- Sprechererkennung mit universellem Hintergrundmodell in der YOHO-Datenbank. Alexandre Majetniak
Ich werde auch einige Tagebuchprojekte hinzufügen:
- Sidekit- und s4d- Diarisierungserweiterung . Eine Python-Bibliothek zum Arbeiten mit Sprache. Leider ist die Dokumentation schlecht.
- Bob und seine verschiedenen Teile wie bob.bio , bob.learn.em - eine Python-Bibliothek zur Signalverarbeitung und zum Arbeiten mit biometrischen Daten. Windows wird nicht unterstützt.
- LIUM ist eine schlüsselfertige Lösung, die in Java geschrieben wurde.
Der gesamte Code wird auf dem
Github veröffentlicht . Der Einfachheit halber habe ich mehrere Jupyter-Laptops mit einer Demonstration bestimmter Dinge hergestellt - MFCC, GMM, MAP-Anpassung und Diarisierung. Letzteres ist der Hauptprozess. Ebenfalls im Repository befinden sich Pickle-Dateien mit einigen vorgefertigten Modellen und das Interview selbst.