SDSM-15. Über QoS. Jetzt mit der Möglichkeit
Pull-Anfragen .
Und so kamen wir zum Thema QoS.
Wissen Sie, warum erst jetzt und warum es der Abschlussartikel des gesamten SDSM-Kurses sein wird? Weil QoS ungewöhnlich komplex ist. Das Schwierigste, was es zuvor im Zyklus gab.
Dies ist keine Art magischer Archivierer, der den Datenverkehr im laufenden Betrieb geschickt komprimiert und Ihren Gigabit in einen 100-Megabit-Uplink verwandelt. Bei QoS geht es darum, etwas Unnötiges zu opfern und das Ungenießbare in den Rahmen des Zulässigen zu drängen.
QoS ist so in die Aura des Schamanismus und der Unzugänglichkeit verstrickt, dass alle jungen (und nicht nur) Ingenieure versuchen, seine Existenz sorgfältig zu ignorieren, weil sie glauben, dass es ausreicht, Probleme mit Geld zu werfen und die Verbindungen endlos zu erweitern. Es stimmt, bis sie erkennen, dass bei diesem Ansatz ein Misserfolg sie unweigerlich erwarten wird. Entweder wird das Unternehmen unangenehme Fragen stellen, oder es wird viele Probleme geben, die fast nicht mit der Kanalbreite zusammenhängen, sondern direkt von der Effizienz seiner Verwendung abhängen. Ja, VoIP schwenkt aktiv einen Stift hinter den Kulissen und Multicast-Verkehr streichelt Sie böswillig auf den Rücken.
Lassen Sie uns daher einfach erkennen, dass QoS obligatorisch ist. Sie müssen es auf die eine oder andere Weise kennen und aus irgendeinem Grund nicht jetzt in einer entspannten Atmosphäre beginnen.

Inhalt
1.
Was bestimmt die QoS?- Verlust
- Verzögerungen
- Jitter
2.
Drei QoS-Modelle- Beste Effekte
- Integrierte Dienste
- Differenzierte Dienstleistungen
3.
DiffServ-Mechanismen4.
Klassifizierung und Kennzeichnung- Verhaltensaggregation
- Multi-Feld
- Schnittstellenbasiert
5.
Warteschlangen6.
Vermeidung von Überlastungen- Tail Drop und Head Drop
- Rot
- Wred
7.
Überlastungsmanagement- Zuerst rein, zuerst raus
- Priority Queuing
- Faires Anstehen
- Round Robin
8.
Geschwindigkeitsbegrenzung- Formen
- Polizeiarbeit
- Undichter Eimer und Token-Eimer
9.
Hardware-Implementierung von QoS
Bevor der Leser in dieses Loch eintaucht, werde ich drei Einstellungen vornehmen:
- Nicht alle Probleme können durch Erweiterung des Bandes gelöst werden.
- QoS erweitert das Band nicht.
- QoS zur Verwaltung begrenzter Ressourcen.
1. Was bestimmt die QoS?
Das Unternehmen erwartet, dass der Netzwerkstapel seine einfache Funktion einwandfrei ausführt - um einen Bitstrom von einem Host zum anderen zu liefern: verlustfrei und in einer vorhersehbaren Zeit.
Aus diesem kurzen Satz können alle Netzwerkqualitätsmetriken abgeleitet werden:
- Verlust
- Verzögerungen
- Jitter
Diese drei Merkmale bestimmen die
Qualität des Netzwerks unabhängig von seiner Art: Paket, Kanal, IP, MPLS, Funk,
Tauben .
Verlust
Diese Metrik gibt an, wie viele der von der Quelle gesendeten Pakete das Ziel erreicht haben.
Die Ursache für den Verlust kann ein Problem in der Schnittstelle / im Kabel, eine Netzwerküberlastung oder Bitfehler sein, die die ACL-Regeln blockieren.
Was im Falle eines Verlustes zu tun ist, entscheidet der Antrag. Es kann sie ignorieren, wie im Fall eines Telefongesprächs, bei dem ein spätes Paket nicht mehr benötigt wird, oder es erneut senden - dies ist das, was TCP tut, um eine genaue Übermittlung der Quelldaten sicherzustellen.

Wie Sie Verluste verwalten, wenn sie unvermeidlich sind, finden Sie im Kapitel Überlastungsmanagement.
Wie Sie Verluste ausnutzen können, lesen Sie im Kapitel Verhinderung von Staus.
Verzögerungen
Dies ist die Zeit, die Daten benötigen, um von der Quelle zum Ziel zu gelangen.

Die kumulative Verzögerung besteht aus den folgenden Komponenten.
- Serialisierungsverzögerung - Die Zeit, die ein Knoten benötigt, um ein Paket in Bits zu zerlegen und eine Verbindung zum nächsten Knoten herzustellen. Sie wird durch die Geschwindigkeit der Schnittstelle bestimmt. So dauert beispielsweise die Übertragung eines Pakets mit einer Größe von 1500 Byte über eine Schnittstelle mit 100 Mbit / s 0,0001 s und für 56 Kb / s - 0,2 s.
- Die Ausbreitungsverzögerung ist das Ergebnis der berüchtigten Begrenzung der Ausbreitungsgeschwindigkeit elektromagnetischer Wellen. Die Physik erlaubt es Ihnen nicht, schneller als in 30 ms (tatsächlich etwa 70 ms) von New York nach Tomsk auf der Oberfläche des Planeten zu gelangen.
- Die durch QoS eingeführten Verzögerungen sind das Schmachten von Paketen in Warteschlangen ( Warteschlangenverzögerung ) und die Folgen der Formgebung ( Formverzögerung ). Wir werden heute im Kapitel Geschwindigkeitsregelung viel darüber sprechen.
- Verzögerung bei der Verarbeitung von Paketen ( Processing Delay ) - die Zeit, um zu entscheiden, was mit dem Paket geschehen soll: Lookup, ACL, NAT, DPI - und es von der Eingabeschnittstelle an die Ausgabe zu senden. An dem Tag, an dem Juniper Control und Data Plane in seinem M40 trennte, konnten Verarbeitungsverzögerungen vernachlässigt werden.
Verzögerungen sind nicht so schlimm für Anwendungen, bei denen keine Eile erforderlich ist: Dateifreigabe, Surfen, VoD, Internetradiosender usw. Umgekehrt sind sie für interaktive wichtig: 200 ms sind bereits während eines Telefongesprächs für das Ohr unangenehm.
Ein verzögerungsbezogener Begriff, der nicht gleichbedeutend mit
RTT (
Round Trip Time ) ist, ist der Round Trip. Beim Ping und Tracing sehen Sie genau RTT und keine Einwegverzögerung, obwohl die Werte eine Korrelation aufweisen.
Jitter
Der Unterschied in den Verzögerungen zwischen der Zustellung aufeinanderfolgender Pakete wird als Jitter bezeichnet.
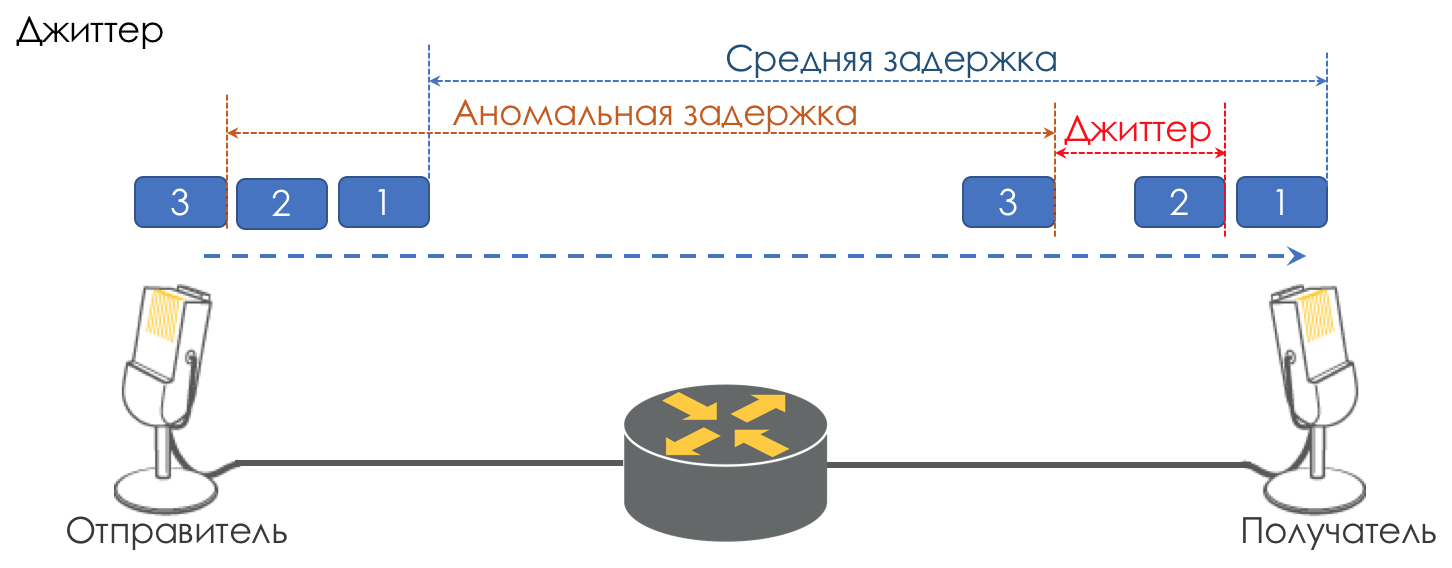
Wie bei der Latenz spielt Jitter für viele Anwendungen keine Rolle. Und selbst, wie es scheint, was ist der Unterschied - das Paket wurde geliefert, also was mehr?
Für interaktive Dienste ist dies jedoch wichtig.
Nehmen Sie die gleiche Telefonie als Beispiel. Tatsächlich handelt es sich um eine Digitalisierung von analogen Signalen mit einer Aufteilung in separate Datenblöcke. Die Ausgabe ist ein ziemlich gleichmäßiger Paketstrom. Auf der Empfangsseite befindet sich ein kleiner Puffer fester Größe, in den nacheinander ankommende Pakete passen. Um das analoge Signal wiederherzustellen, ist eine bestimmte Anzahl von ihnen erforderlich. Unter Bedingungen schwebender Verzögerungen kommt der nächste Datenblock möglicherweise nicht rechtzeitig an, was einem Verlust entspricht, und das Signal kann nicht wiederhergestellt werden.
Der größte Beitrag zur Verzögerungsvariabilität wird nur durch QoS geleistet. Dies ist auch sehr und langwierig in den gleichen Kapiteln Geschwindigkeitsbegrenzung.
Dies sind die drei Hauptmerkmale der Netzwerkqualität, aber es gibt zwei andere, die ebenfalls eine wichtige Rolle spielen.
Zufällige Lieferung
Eine Reihe von Anwendungen, wie Telefonie,
NAS ,
CES, reagieren äußerst empfindlich auf die zufällige Zustellung von Paketen, wenn sie in der falschen Reihenfolge beim Empfänger ankommen, in der sie gesendet wurden. Dies kann zu Verbindungsverlust, Fehlern und Schäden am Dateisystem führen.
Obwohl die zufällige Zustellung keine formale QoS-Funktion ist, bezieht sie sich definitiv auf die Netzwerkqualität.
Selbst wenn TCP diese Art von Problem toleriert, treten doppelte ACKs und Neuübertragungen auf.

Bandbreite
Es wird nicht als Maß für die Netzwerkqualität unterschieden, da sein Nachteil tatsächlich zu den drei oben genannten führt. In unserer Realität sollte MPLS TE es jedoch zumindest als schwache Metrik erwähnen, wenn es für einige Anwendungen garantiert oder im Gegenteil vertraglich begrenzt werden sollte, z. B. wenn MPLS TE es im gesamten LSP reserviert.
Geschwindigkeitsregelungsmechanismen werden in den Kapiteln Geschwindigkeitsbegrenzung erläutert.
Warum können Spezifikationen schlecht werden?
Wir beginnen also mit einer sehr primitiven Idee, dass ein Netzwerkgerät (sei es ein Switch, ein Router, eine Firewall oder was auch immer) nur ein weiteres Rohrstück ist, das als Kommunikationskanal bezeichnet wird, genau wie ein Kupferdraht oder ein optisches Kabel.

Dann fliegen alle Pakete in der Reihenfolge durch, in der sie angekommen sind, und es treten keine zusätzlichen Verzögerungen auf - es gibt keinen Ort zum Verweilen.
Tatsächlich stellt jeder Router Bits und Pakete aus dem Signal wieder her, macht etwas mit ihnen (wir denken noch nicht darüber nach) und wandelt die Pakete dann wieder in ein Signal um.
Eine Serialisierungsverzögerung wird angezeigt. Aber im Allgemeinen ist dies nicht beängstigend, weil es konstant ist. Nicht beängstigend, solange die Breite der Ausgabeschnittstelle größer als die Eingabe ist.
Am Eingang des Geräts befindet sich beispielsweise ein Gigabit-Port und am Ausgang eine 620-Mbit / s-Funkrelaisleitung, die an denselben Gigabit-Port angeschlossen ist.
Niemand wird eine Kugel durch den formal Gigabit-Link-Gigabit-Verkehr verbieten.
Es ist nichts zu tun - 380 Mbit / s werden auf den Boden verschüttet.
Hier sind sie - Verluste.
Gleichzeitig würde ich mir sehr wünschen, dass der schlimmste Teil abgeworfen wird - ein Video von Youtube, und das Telefongespräch des Geschäftsführers mit dem Betriebsleiter hat weder unterbrochen noch gequält.
Ich möchte, dass die Stimme eine Standleitung hat.
Oder es gibt fünf Eingabeschnittstellen, aber eine Ausgabe, und gleichzeitig haben fünf Knoten versucht, einem Empfänger Datenverkehr zuzuführen.
Fügen Sie eine Prise VoIP-Theorie hinzu (ein Artikel, über den niemand geschrieben hat) - sie reagiert sehr empfindlich auf Verzögerungen und deren Variationen.
Wenn für einen TCP-Videostream von YouTube (zum Zeitpunkt des Schreibens des
QUIC- Artikels - es ist immer noch ein Experiment) Verzögerungen in Sekunden aufgrund von Pufferung völlig wertlos sind, wird der Direktor nach dem ersten solchen Gespräch mit Kamtschatka den Leiter der technischen Abteilung anrufen.
In früheren Zeiten, als der Autor des Zyklus abends noch seine Hausaufgaben machte, war das Problem besonders akut. Modemverbindungen hatten eine
Geschwindigkeit von 56k .
Und als ein 1,5-KB-Paket in eine solche Verbindung kam, belegte es 200 ms lang die gesamte Leitung. Niemand sonst konnte in diesem Moment passieren. Eine Stimme? Nein, ich habe nicht gehört.
Daher ist die MTU-Frage so wichtig - das Paket sollte die Schnittstelle nicht zu lange belegen. Je weniger Geschwindigkeit es ist, desto weniger MTU wird benötigt.
Hier sind sie - Verzögerungen.
Jetzt ist der Kanal frei und die Verzögerung ist gering. Nach einer Sekunde hat jemand begonnen, eine große Datei herunterzuladen, und die Verzögerungen haben zugenommen. Hier ist er - Jitter.
Daher ist es notwendig, dass Sprachpakete mit minimalen Verzögerungen durch die Pipe fliegen und YouTube wartet.
Die verfügbaren 620 Mbit / s sollten für Sprache und Video sowie für B2B-Kunden verwendet werden, die VPNs kaufen. Ich möchte, dass ein Verkehr den anderen nicht unterdrückt, also brauchen wir eine Bandgarantie.
Alle oben genannten Merkmale sind in Bezug auf die Art des Netzwerks universell. Es gibt jedoch drei verschiedene Ansätze für ihre Bereitstellung.
2. Drei QoS-Modelle
- Bester Aufwand - keine Qualitätsgarantie. Alle sind gleich.
- IntServ ist eine Qualitätsgarantie für jeden Stream. Reservieren von Ressourcen von der Quelle zum Ziel.
- DiffServ - Es gibt keine Reservierung. Jeder Knoten selbst bestimmt, wie die richtige Qualität sichergestellt wird.
Bester Aufwand (BE)
Keine Gewährleistungen.Der einfachste Ansatz zur Implementierung von QoS, von dem aus IP-Netzwerke begonnen haben und bis heute praktiziert werden - manchmal, weil es ausreicht, aber häufiger, weil niemand an QoS gedacht hat.
Wenn Sie Datenverkehr ins Internet senden, wird dieser dort übrigens als BestEffort verarbeitet. Daher ist über ein über das Internet gerolltes VPN (im Gegensatz zu einem vom Anbieter bereitgestellten VPN) wichtiger Datenverkehr, z. B. ein Telefongespräch, möglicherweise nicht sehr sicher.
Im Fall von BE sind alle Verkehrskategorien gleich, keine wird bevorzugt. Dementsprechend gibt es keine Garantie für Verzögerung / Jitter oder Band.
Dieser Ansatz hat einen etwas eingängigen Namen - Best Effort, den der Neuling mit dem Wort "best" irreführt.
Der Ausdruck „Ich werde mein Bestes geben“ bedeutet jedoch, dass der Sprecher versuchen wird, alles zu tun, was möglich ist, aber nichts garantiert.
Für die Implementierung von BE ist nichts erforderlich - dies ist das Standardverhalten. Es ist billig in der Herstellung, die Mitarbeiter benötigen kein tiefes spezifisches Wissen, die QoS kann in diesem Fall nicht angepasst werden.
Diese Einfachheit und Statik führen jedoch nicht dazu, dass der Best Effort-Ansatz nirgendwo verwendet wird. Es findet Anwendung in Netzwerken mit hoher Bandbreite und ohne Überlastung und Bursts.
Zum Beispiel auf transkontinentalen Leitungen oder in Netzwerken einiger Rechenzentren, in denen keine Überzeichnung besteht.
Mit anderen Worten, in Netzwerken ohne Überlastung und in denen es nicht erforderlich ist, sich auf besondere Weise auf Verkehr (z. B. Telefonie) zu beziehen, ist BE durchaus angemessen.
Interv
Vorläufige Reservierung von Ressourcen für den gesamten Fluss von der Quelle zum Ziel.Die Väter der MIT-, Xerox- und ISI-Netzwerke haben beschlossen, dem wachsenden zufälligen Internet das Element der Vorhersehbarkeit hinzuzufügen und gleichzeitig seine Funktionsfähigkeit und Flexibilität beizubehalten.
So entstand 1994 die Idee von IntServ als Reaktion auf das schnelle Wachstum des Echtzeitverkehrs und die Entwicklung von Multicast. Es wurde dann auf IS reduziert.
Der Name spiegelt den Wunsch im selben Netzwerk wider, gleichzeitig Dienste für Echtzeit- und Nicht-Echtzeit-Verkehrstypen bereitzustellen, und bietet das Recht erster Priorität, Ressourcen durch Reservierung des Bandes zu nutzen. Die Möglichkeit, die Band wiederzuverwenden, mit der jeder Geld verdient und dank der der IP-Schuss erhalten blieb.
Die Sicherungsmission wurde dem RSVP-Protokoll zugewiesen, das für
jeden Stream ein Band auf
jedem Netzwerkgerät reserviert.
Grob gesagt senden die Endhosts vor dem Einrichten einer Single Rate Three Color MarkerP-Sitzung oder dem Starten des Datenaustauschs den RSVP-Pfad mit der erforderlichen Bandbreite. Und wenn beide RSVP Resv zurückgegeben haben, können sie anfangen zu kommunizieren. Wenn gleichzeitig keine Ressourcen verfügbar sind, gibt RSVP einen Fehler zurück und die Hosts können nicht kommunizieren oder BE mitmachen.
Lassen Sie sich nun die tapfersten Leser vorstellen, dass ein Kanal für
jeden Stream im Internet heute im Voraus signalisiert wird. Wir berücksichtigen, dass dies CPU- und Speicherkosten ungleich Null an
jedem Transitknoten erfordert, die eigentliche Interaktion für einige Zeit verschiebt und klar wird, warum sich IntServ als praktisch totgeborene Idee herausstellte - Skalierbarkeit Null.
In gewisser Weise ist die moderne Inkarnation von IntServ MPLS TE mit einer angepassten Kennzeichnungsversion von RSVP - RSVP TE. Obwohl hier natürlich nicht End-to-End und nicht Per-Flow.
IntServ ist in
RFC 1633 beschrieben .
Das Dokument ist im Prinzip neugierig zu bewerten, wie naiv Sie in Prognosen sein können.
Diffserv
DiffServ ist kompliziert.Als Ende der 90er Jahre klar wurde, dass der End-to-End-IntServ-IP-Ansatz fehlschlug, berief die IETF 1997 die Arbeitsgruppe Differentiated Services ein, die die folgenden Anforderungen für das neue QoS-Modell entwickelte:
- Keine Signalisierung (Adjos, RSVP!).
- Basierend auf der aggregierten Verkehrsklassifizierung, anstatt sich auf Flows, Kunden usw. zu konzentrieren.
- Es verfügt über eine begrenzte und deterministische Reihe von Aktionen zur Verarbeitung des Datenverkehrs von Klassen.
Infolgedessen wurden 1998 der Meilenstein
RFC 2474 (
Definition des Feldes für differenzierte Dienste (DS-Feld) in den IPv4- und IPv6-Headern ) und
RFC 2475 (
Eine Architektur für differenzierte Dienste ) geboren.
Und weiter werden wir nur über DiffServ sprechen.
Es ist erwähnenswert, dass der Name DiffServ nicht das Gegenteil von IntServ ist. Dies zeigt, dass wir die von verschiedenen Anwendungen bereitgestellten Dienste bzw. deren Datenverkehr unterscheiden, dh diese Arten von Datenverkehr gemeinsam nutzen / differenzieren.
IntServ macht dasselbe - es unterscheidet zwischen den Verkehrstypen BE und Real-Time, die im selben Netzwerk übertragen werden. Sowohl: als auch IntServ und DiffServ - beziehen sich auf Möglichkeiten zur Unterscheidung von Diensten.
3. DiffServ-Mechanismen
Was ist DiffServ und warum schlägt es IntServ?
Wenn es sehr einfach ist, wird der Verkehr in Klassen unterteilt. Ein Paket am Eingang zu jedem Knoten wird klassifiziert und mit einer Reihe von Werkzeugen versehen, die Pakete verschiedener Klassen auf unterschiedliche Weise verarbeiten und ihnen so ein unterschiedliches Serviceniveau bieten.
Aber es wird einfach
nicht sein .
Das Herzstück von DiffServ ist das ideal erfahrene IP IP
PHB- Konzept
- Per-Hop-Verhalten . Jeder Knoten auf dem Verkehrspfad entscheidet unabhängig von seinen Headern, wie er sich relativ zum eingehenden Paket verhält.
Die Aktionen des Paketrouters werden als Verhaltensmodell bezeichnet. Die Anzahl solcher Modelle ist deterministisch und begrenzt. Auf verschiedenen Geräten können sich die Verhaltensmodelle in Bezug auf denselben Datenverkehr unterscheiden, daher sind sie pro Hop.
Die Konzepte von Verhalten und PHB werde ich im Artikel als Synonyme verwenden.Es gibt eine leichte Verwirrung. PHB ist einerseits das allgemeine Konzept des unabhängigen Verhaltens jedes Knotens und andererseits ein spezifisches Modell auf einem bestimmten Knoten. Damit werden wir es herausfinden.

Das Verhaltensmodell wird durch eine Reihe von Tools und deren Parameter bestimmt: Überwachung, Löschen, Warteschlangen, Planen, Formen.
Mithilfe der verfügbaren Verhaltensmodelle kann das Netzwerk verschiedene Dienstklassen (
Serviceklasse ) bereitstellen.
Das heißt, verschiedene Verkehrskategorien können unterschiedliche Dienstebenen im Netzwerk empfangen, indem unterschiedliche PHBs auf sie angewendet werden.
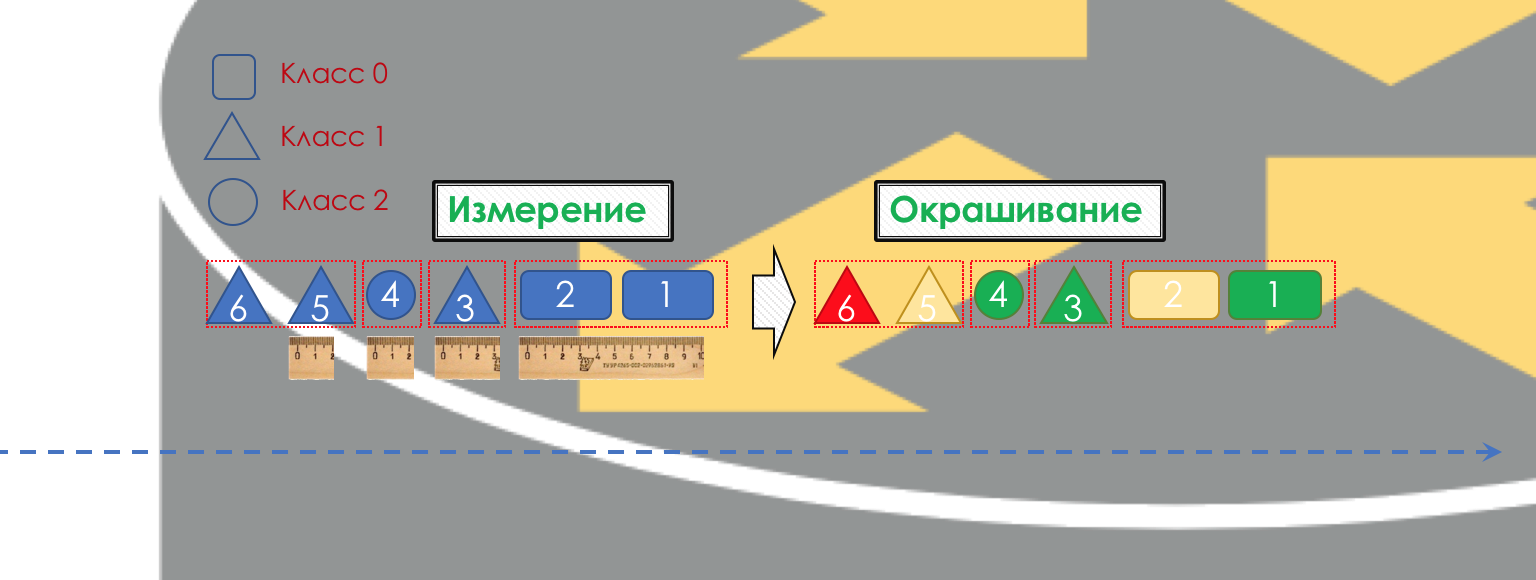
Dementsprechend müssen Sie zunächst bestimmen, auf welche Klasse von Service-Verkehr sich bezieht -
Klassifizierung .
Jeder Knoten klassifiziert eingehende Pakete unabhängig voneinander.

Nach der Klassifizierung erfolgt eine Messung (Messung) - wie viele Bits / Bytes des Verkehrs dieser Klasse am Router angekommen sind.
Basierend auf den Ergebnissen können Pakete gestrichen werden (
Färbung ): grün (innerhalb der festgelegten Grenze), gelb (außerhalb der Grenze), rot (die Küste vollständig verführt).
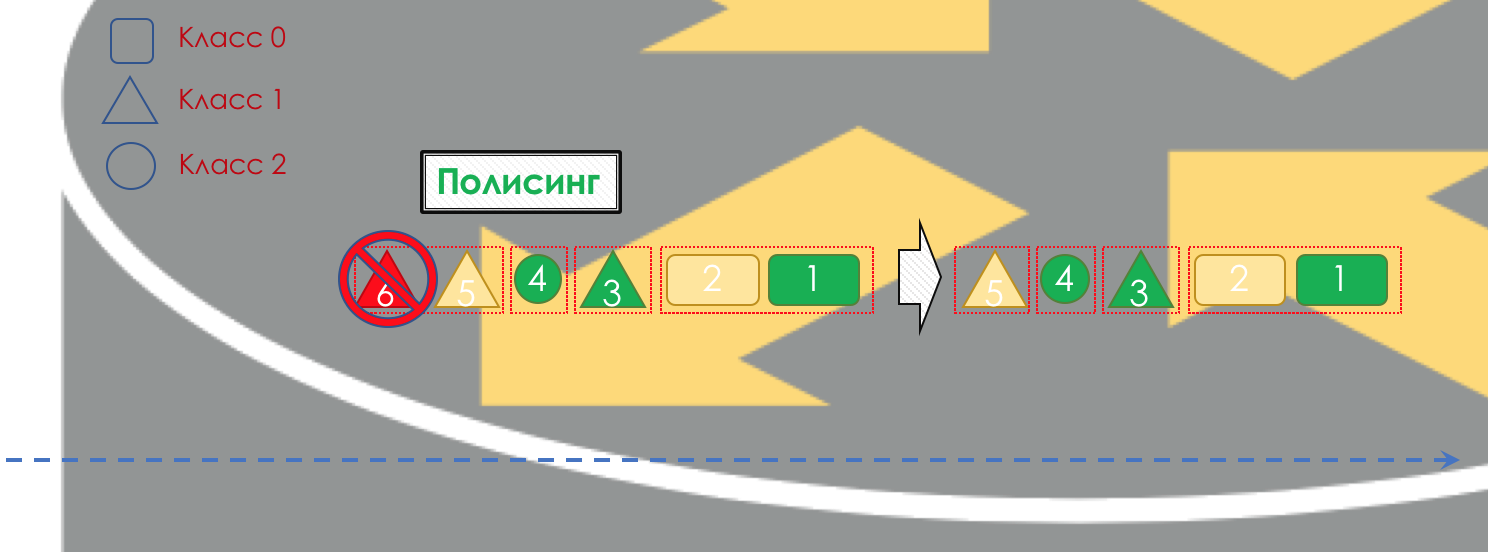
Wenn nötig, findet die
Überwachung statt (Entschuldigung für ein solches Transparentpapier, es gibt eine bessere Option - schreiben, ich werde es ändern). Ein Polierer, der auf der Farbe eines Pakets basiert, weist dem Paket eine Aktion zu - Senden, Verwerfen oder erneutes Markieren.
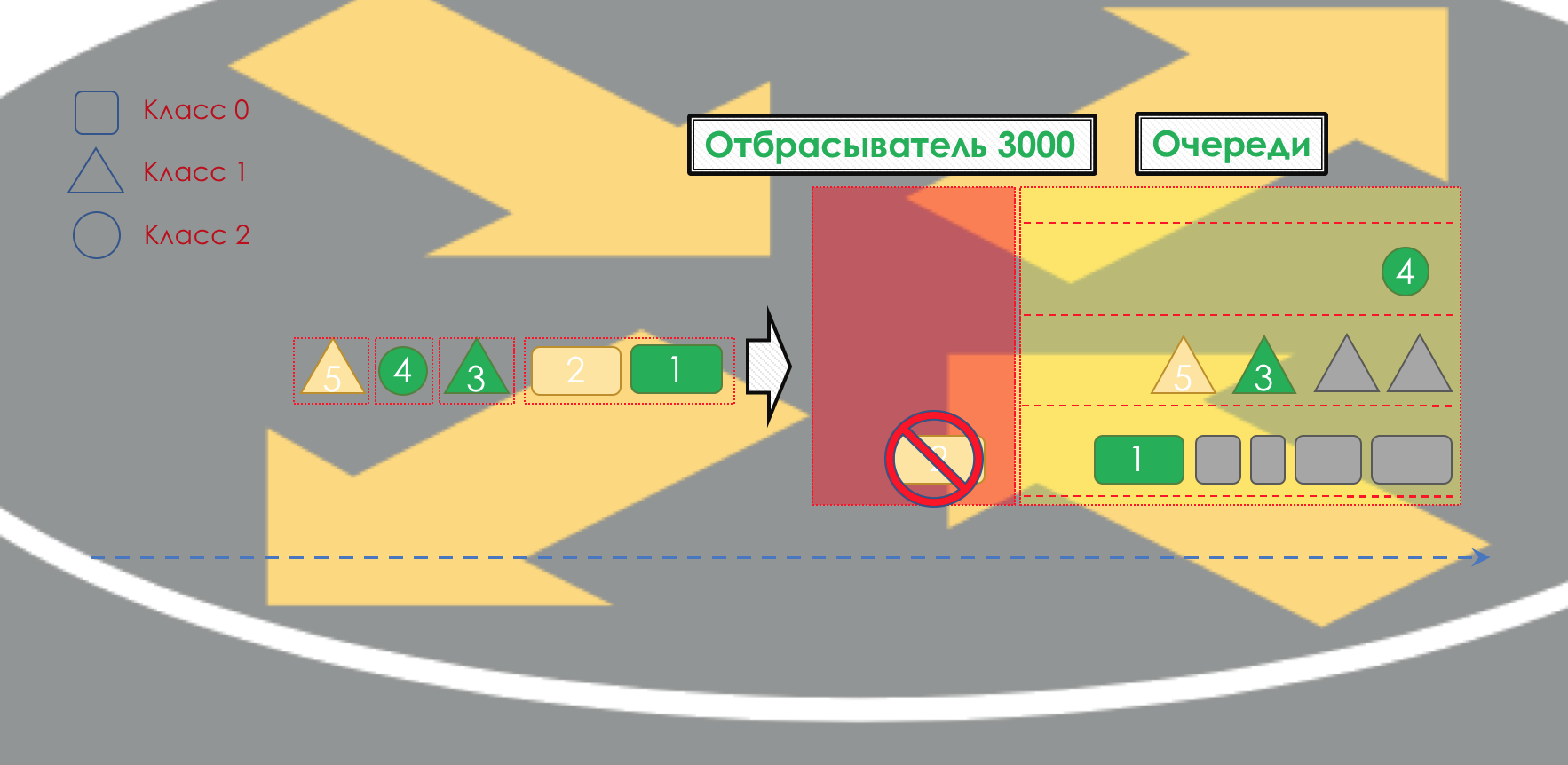
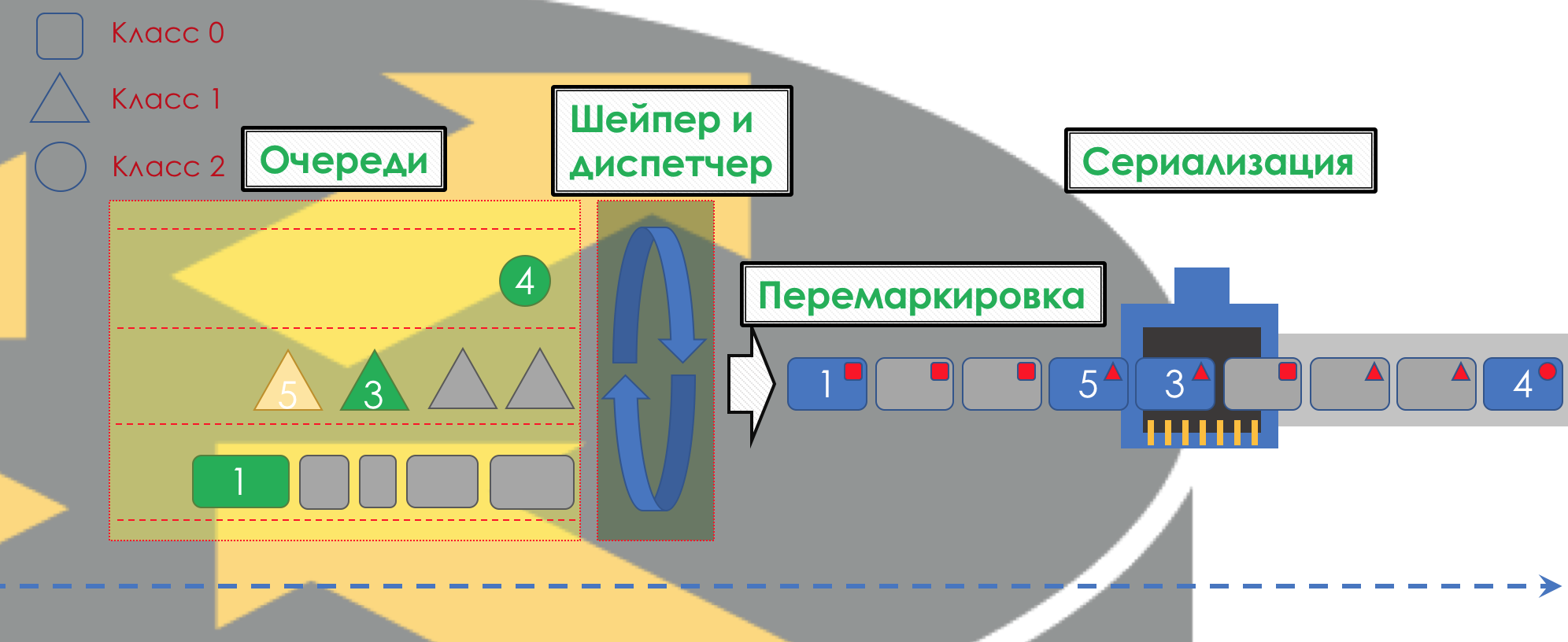
Danach sollte das Paket in eine der Warteschlangen fallen (
Queuing ). Für jede Serviceklasse wird eine separate Warteschlange zugewiesen, mit der sie anhand verschiedener PHBs unterschieden werden können.
Aber noch bevor das Paket in die Warteschlange gelangt, kann es
verworfen werden (
Dropper ), wenn die Warteschlange voll ist.
Wenn es grün ist, wird es passieren, wenn es gelb ist, wird es höchstwahrscheinlich verworfen, wenn die Linie voll ist und wenn Rot ein sicherer Selbstmordattentäter ist. Bedingt hängt die Wahrscheinlichkeit des Ablegens von der Farbe des Pakets und der Fülle der Warteschlange ab, in die es gelangen soll.
Am Ausgang der Warteschlange arbeitet ein
Shaper , dessen Aufgabe der Aufgabe des Polysers sehr ähnlich ist - den Verkehr auf einen bestimmten Wert zu begrenzen.
Sie können beliebige Shaper für einzelne Warteschlangen oder sogar innerhalb von Warteschlangen konfigurieren.
Über den Unterschied zwischen einem Former und einem Polyser im Kapitel Geschwindigkeitsbegrenzung.
Alle Warteschlangen sollten schließlich zu einer einzigen Ausgabeschnittstelle zusammengeführt werden.
Denken Sie an die Situation, in der auf der Straße 8 Fahrspuren in 3 übergehen. Ohne Verkehrskontrolleur führt dies zu Chaos. Eine abwechselnde Trennung wäre nicht sinnvoll, wenn wir dieselbe Ausgabe wie die Eingabe hätten.
Daher gibt es einen speziellen Dispatcher (
Scheduler ), der zyklisch Pakete aus verschiedenen Warteschlangen herausnimmt und an die Schnittstelle sendet (
Scheduling ).
Tatsächlich ist eine Kombination aus einer Reihe von Warteschlangen und einem Dispatcher der wichtigste QoS-Mechanismus, mit dem Sie verschiedene Regeln auf verschiedene Verkehrsklassen anwenden können, von denen eine eine große Bandbreite bietet, die andere eine geringe Latenz und der dritte Mangel an Drops.
Dann gehen die Pakete bereits zur Schnittstelle, wo die Pakete in einen Bitstrom umgewandelt werden - Serialisierung (
Serialisierung ) und dann das Umgebungssignal.
In DiffServ ist das Verhalten jedes Knotens unabhängig von den anderen. Es gibt keine Signalisierungsprotokolle, die angeben, welche QoS-Richtlinie sich im Netzwerk befindet. Gleichzeitig möchte ich, dass der Datenverkehr innerhalb des Netzwerks gleichmäßig verarbeitet wird. Wenn sich nur ein Knoten anders verhält, ist die gesamte QoS-Richtlinie nicht mehr verfügbar.
Dazu werden zum einen auf allen Routern die gleichen Klassen und PHB konfiguriert, und zum anderen wird die
Kennzeichnung des Pakets verwendet - seine Zugehörigkeit zu einer bestimmten Klasse wird im Header (IP, MPLS, 802.1q) aufgezeichnet.
Das Schöne an DiffServ ist, dass sich der nächste Knoten bei der Klassifizierung auf dieses Label verlassen kann.
Eine solche Vertrauenszone, in der dieselben Verkehrsklassifizierungsregeln und dasselbe Verhalten gelten, wird als DiffServ-Domäne (
DiffServ-Domäne ) bezeichnet.

So können wir am Eingang zur DiffServ-Domäne ein Paket basierend auf 5-Tupel oder einer Schnittstelle klassifizieren, es gemäß den Regeln der Domäne markieren (
Bemerkung / Umschreiben ), und weitere Knoten werden dieser Markierung vertrauen und keine komplexe Klassifizierung vornehmen.
Das heißt, es gibt keine explizite Signalisierung in DiffServ, aber der Knoten kann allen folgenden mitteilen, welche Klasse dieses Paket bereitgestellt werden muss, und darauf warten, dass es vertrauenswürdig ist.
An den Verbindungsstellen zwischen DiffServ-Domänen müssen Sie QoS-Richtlinien aushandeln (oder nicht).
Das ganze Bild sieht ungefähr so aus:
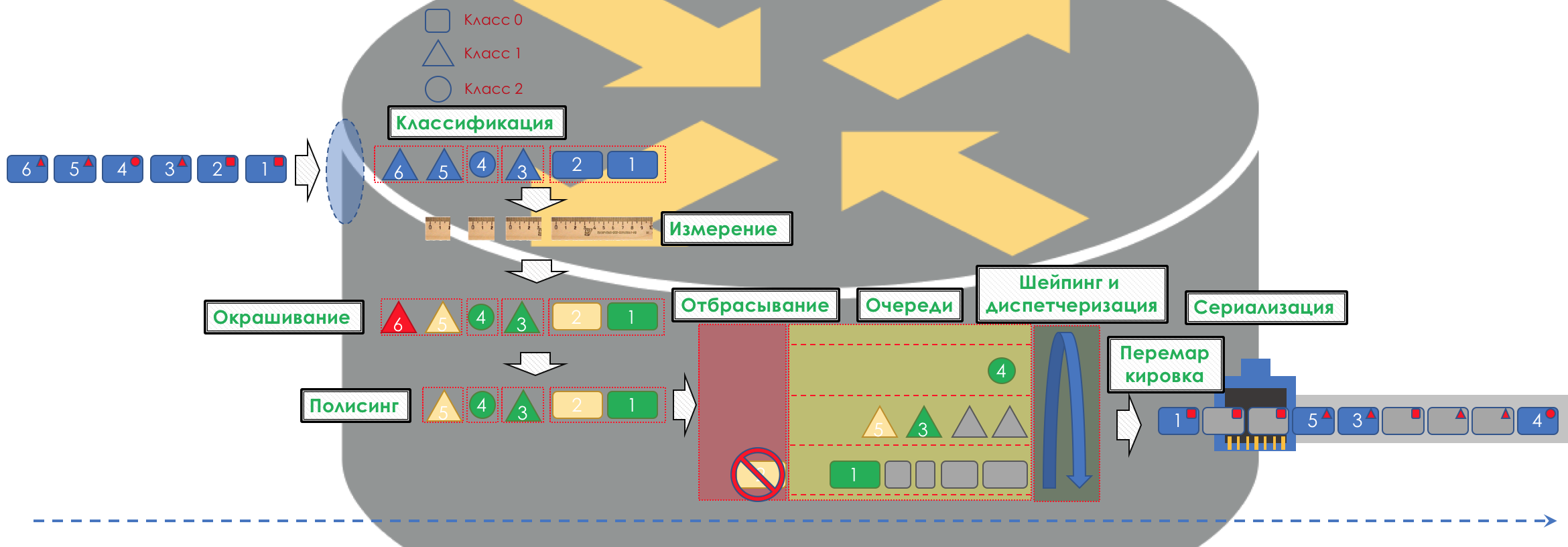
Um es klar zu machen, werde ich ein Analogon aus dem wirklichen Leben geben.
Flug mit dem Flugzeug (nicht Victory).
Es gibt drei Serviceklassen (CoS): Economy, Business, First.
Beim Kauf eines Tickets findet die Klassifizierung statt - der Passagier erhält eine bestimmte Serviceklasse basierend auf dem Preis.
Am Flughafen gibt es eine Markierung (Bemerkung) - ein Ticket wird ausgestellt, das die Klasse angibt.
Es gibt zwei Verhaltensweisen (PHBs): Best Effort und Premium.
Es gibt Mechanismen, die Verhaltensweisen implementieren: einen gemeinsamen Warteraum oder eine VIP-Lounge, einen Kleinbus oder einen gemeinsamen Bus, bequeme große Sitze oder enge Reihen, die Anzahl der Passagiere pro Flugbegleiter, die Möglichkeit, Alkohol zu bestellen.
Je nach Klasse werden Verhaltensmodelle zugeordnet - der Best Effort Economy, dem Business - Premium Basic und dem First - Premium SUPER-POWER-NINJA-TURBO-NEO-ULTRA-HYPER-MEGA-MULTI-ALPHA-META-EXTRA-UBER-PREFIX!
Gleichzeitig unterscheiden sich zwei Prämien darin, dass sie in einem ein Glas halbsüß geben und in dem anderen unbegrenzt Bacardi haben.
Bei der Ankunft am Flughafen kommen alle durch eine Tür. Diejenigen, die versucht haben, Waffen mitzubringen oder kein Ticket haben, sind nicht erlaubt (Drop). Wirtschaft und Wirtschaft geraten in unterschiedliche Warteräume und unterschiedliche Transportmittel (Queuing). Zuerst lassen sie First Class an Bord, dann Business, dann Economy (Scheduling), aber dann fliegen sie alle mit einem Flugzeug (Schnittstelle) an ihr Ziel.
Im selben Beispiel ist ein Flug in einem Flugzeug eine Ausbreitungsverzögerung, die Landung eine Serialisierungsverzögerung, das Warten auf ein Flugzeug in den Hallen ist Warteschlange und die Passkontrolle ist Verarbeitung. Beachten Sie, dass hier die Verarbeitungsverzögerung in Bezug auf die Gesamtzeit normalerweise vernachlässigbar ist.
Der nächste Flughafen kann ganz anders mit Passagieren umgehen - sein PHB ist anders. Wenn sich der Passagier jedoch nicht die Fluggesellschaft ändert, ändert sich höchstwahrscheinlich auch die Einstellung zu ihm nicht, da ein Unternehmen eine DiffServ-Domain ist.
Wie Sie vielleicht bemerkt haben, ist DiffServ extrem (oder unendlich) komplex. Wir werden aber alles analysieren, was oben beschrieben wurde. Gleichzeitig werde ich in dem Artikel nicht auf die Nuancen der physischen Implementierung eingehen (sie können sich sogar auf zwei Karten desselben Routers unterscheiden), sondern nicht auf HQoS und MPLS DS-TE.
Die Schwelle für den Eintritt in den Kreis der Ingenieure, die die Technologie für QoS verstehen, ist viel höher als für Routing-Protokolle, MPLS oder, verzeihen Sie, Radya, STP.
Trotzdem hat sich DiffServ Anerkennung und Implementierung in Netzwerken auf der ganzen Welt verdient, da es, wie sie sagen, hoch skalierbar ist.
Im weiteren Verlauf dieses Artikels werde ich nur DiffServ analysieren.
Im Folgenden werden alle in der Abbildung angegebenen Tools und Prozesse analysiert.
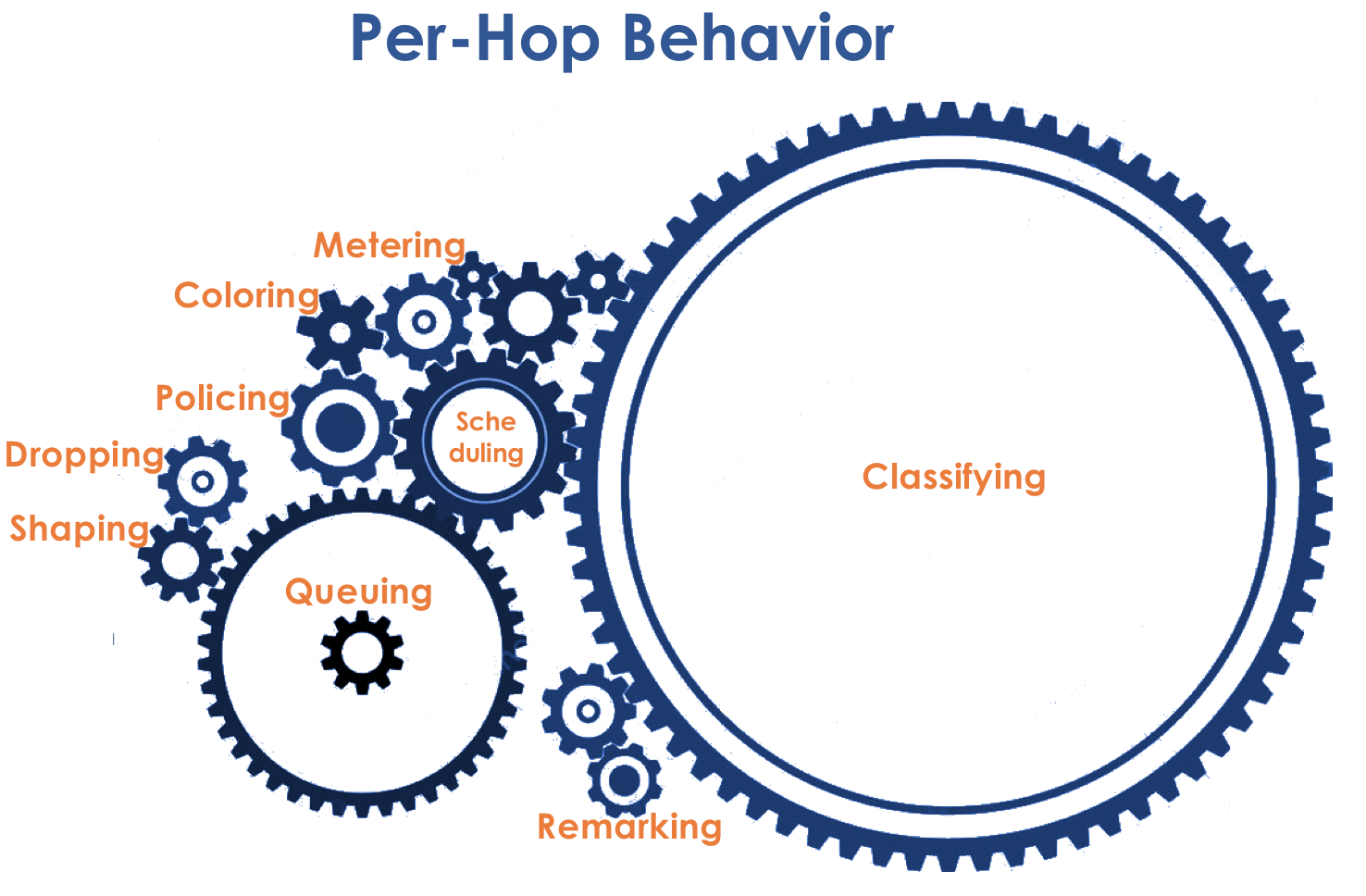
Im Zuge der Erweiterung des Themas werde ich einige Dinge in der Praxis zeigen.
Wir werden mit einem solchen Netzwerk arbeiten:
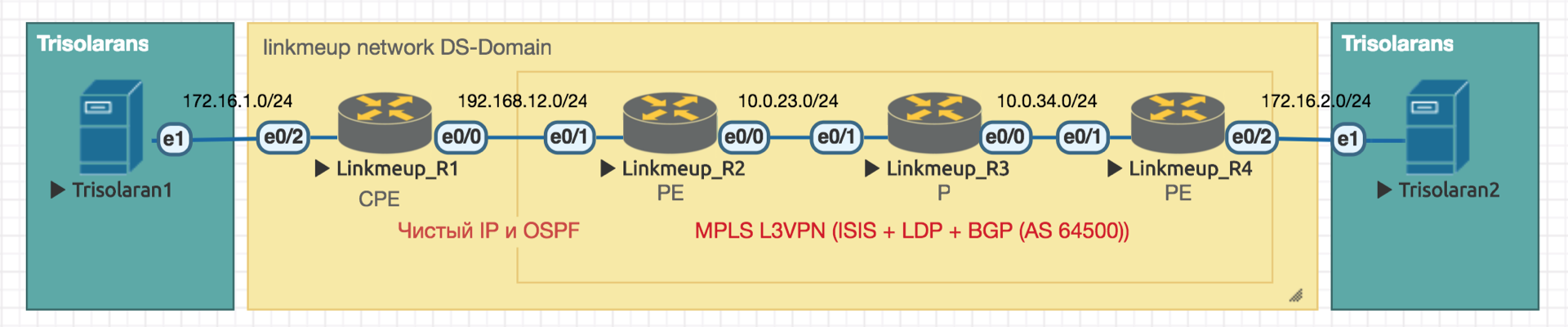
Trisolarans ist ein Linkmeup-Provider-Client mit zwei Verbindungspunkten.
Der gelbe Bereich ist die DiffServ-Domäne des Linkmeup-Netzwerks, in der eine einzelne QoS-Richtlinie wirksam ist.
Linkmeup_R1 ist ein CPE-Gerät, das vom Anbieter verwaltet wird und sich daher in einer vertrauenswürdigen Zone befindet. OSPF wird damit ausgelöst und die Interaktion erfolgt über eine saubere IP.
Im Kern des Netzwerks befinden sich MPLS + LDP + MP-BGP mit L3VPN, das von Linkmeup_R2 bis Linkmeup_R4 reicht.
Ich werde alle anderen Kommentare nach Bedarf geben.
Die anfängliche Konfigurationsdatei .
4. Klassifizierung und Kennzeichnung
Innerhalb seines Netzwerks definiert der Administrator die Serviceklassen, die er für den Datenverkehr bereitstellen kann.
Daher ist das erste, was jeder Knoten tut, wenn er ein Paket empfängt, es zu klassifizieren.
Es gibt drei Möglichkeiten:
- Verhaltensaggregat ( BA )
Vertrauen Sie einfach dem vorhandenen Paketetikett in der Kopfzeile. Zum Beispiel das IP DSCP-Feld.
Dies wird so genannt, weil unter derselben Bezeichnung im DSCP-Feld verschiedene Verkehrskategorien zusammengefasst werden, die dasselbe Verhalten in Bezug auf sich selbst erwarten. Beispielsweise werden alle SIP-Sitzungen zu einer Klasse zusammengefasst.
Die Anzahl möglicher Serviceklassen und damit Verhaltensmuster ist begrenzt. Dementsprechend ist es unmöglich, für jede Kategorie (oder noch mehr für den Stream) eine separate Klasse zuzuweisen - es ist eine Aggregation erforderlich. - Schnittstellenbasiert
Alles, was zu einer bestimmten Schnittstelle kommt, sollte in eine Verkehrsklasse eingeordnet werden. Zum Beispiel wissen wir sicher, dass der Datenbankserver mit diesem Port verbunden ist und nicht mehr. Und an einem anderen Mitarbeiterarbeitsplatz. - MultiField ( MF )
Analysieren Sie die Paket-Header-Felder - IP-Adressen, Ports, MAC-Adressen. Generell beliebige Felder.
Beispielsweise muss der gesamte Datenverkehr, der in das Subnetz 10.127.721.0/24 auf Port 5000 geleitet wird, als Datenverkehr markiert werden, sofern die 5. Dienstklasse erforderlich ist.
Der Administrator bestimmt die Serviceklassen, die das Netzwerk bereitstellen kann, und ordnet ihnen einen digitalen Wert zu.
Am Eingang zur DS-Domain vertrauen wir niemandem, daher erfolgt die Klassifizierung auf die zweite oder dritte Weise: Basierend auf den Adressen, Protokollen oder Schnittstellen werden die Serviceklasse und der entsprechende digitale Wert bestimmt.
Beim Verlassen des ersten Knotens wird diese Ziffer im DSCP-Feld des IP-Headers (oder einem anderen Feld der Verkehrsklasse: MPLS-Verkehrsklasse, IPv6-Verkehrsklasse, Ethernet 802.1p) codiert - eine Bemerkung tritt auf.
Es ist üblich, dieser Kennzeichnung innerhalb der DS-Domäne zu vertrauen, daher verwenden Transitknoten die erste Klassifizierungsmethode (BA) - die einfachste. Keine komplizierte Kursanalyse, sehen Sie sich nur die aufgezeichnete Nummer an.
An der Kreuzung zweier Domänen können Sie anhand einer Schnittstelle oder eines MF klassifizieren, wie oben beschrieben, oder Sie können der BA-Kennzeichnung mit Vorbehalten vertrauen.
Vertrauen Sie beispielsweise allen Werten außer 6 und 7 und weisen Sie 6 und 7 bis 5 neu zu.
Diese Situation ist möglich, wenn der Anbieter eine juristische Person mit einer eigenen Kennzeichnungsrichtlinie verbindet. Der Anbieter hat nichts dagegen, es zu speichern, möchte jedoch nicht, dass der Datenverkehr in die Klasse fällt, in der er Netzwerkprotokollpakete empfängt.
Verhaltensaggregation
BA verwendet eine sehr einfache Klassifizierung - ich sehe eine Zahl - ich verstehe die Klasse.
Was ist die Figur? Und in welchem Bereich wird es aufgezeichnet?
- IPv6-Verkehrsklasse
- MPLS-Verkehrsklasse
- Ethernet 802.1p
Die Klassifizierung basiert hauptsächlich auf dem Kommutierungsheader.
Ich rufe einen Pendler-Header auf, anhand dessen das Gerät festlegt, wohin das Paket gesendet werden soll, damit es näher am Empfänger ist.Das heißt, wenn ein IP-Paket am Router ankommt, werden der IP-Header und das DSCP-Feld analysiert. Wenn MPLS eintrifft, wird es analysiert - MPLS-Verkehrsklasse.
Wenn ein Ethernet + VLAN + MPLS + IP-Paket zu einem regulären L2-Switch gelangt ist, wird 802.1p analysiert (obwohl dies geändert werden kann).
IPv4-Nutzungsbedingungen
Das QoS-Feld begleitet uns genauso wie die IP. Das 8-Bit-TOS-Feld - Type Of Service - sollte die Priorität des Pakets tragen.
Noch vor dem Aufkommen von DiffServ hat
RFC 791 (
INTERNET PROTOCOL ) das Feld folgendermaßen beschrieben:
IP-Priorität (IPP) + DTR + 00.
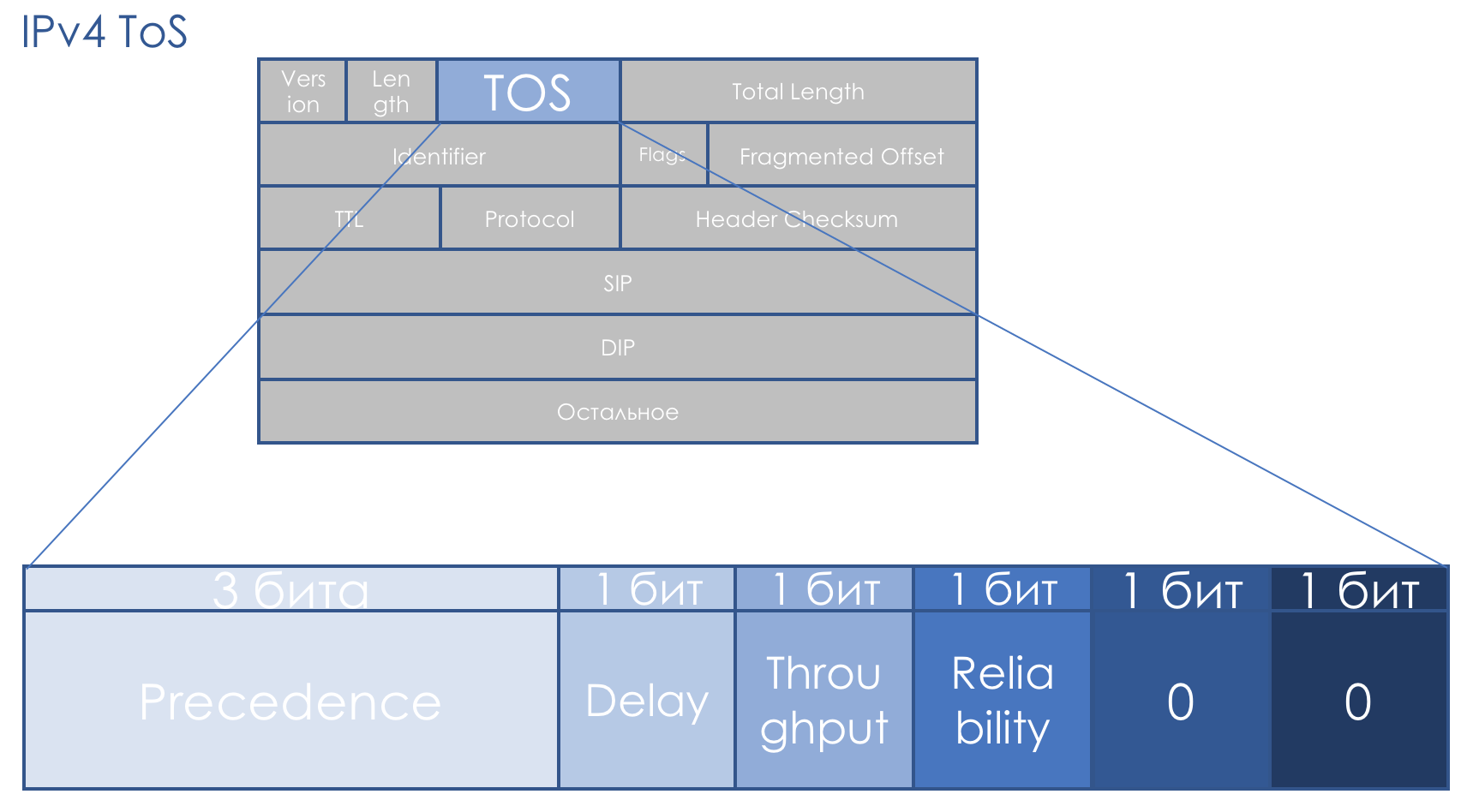
Das heißt, die Priorität des Pakets geht, dann die Genauigkeit, Verzögerung, Durchsatz, Zuverlässigkeit (0 - ohne Anforderungen, 1 - mit Anforderungen).
Die letzten beiden Bits müssen Null sein.
Priorität bestimmt die folgenden Werte ...111 - Netzwerksteuerung
110 - Internetwork-Kontrolle
101 - KRITISCH / ECP
100 - Flash Override
011 - Blitz
010 - Sofort
001 - Priorität
000 - Routine
Später in
RFC 1349 (
Art des Dienstes in der Internet Protocol Suite ) wurde das TOS-Feld leicht neu definiert:
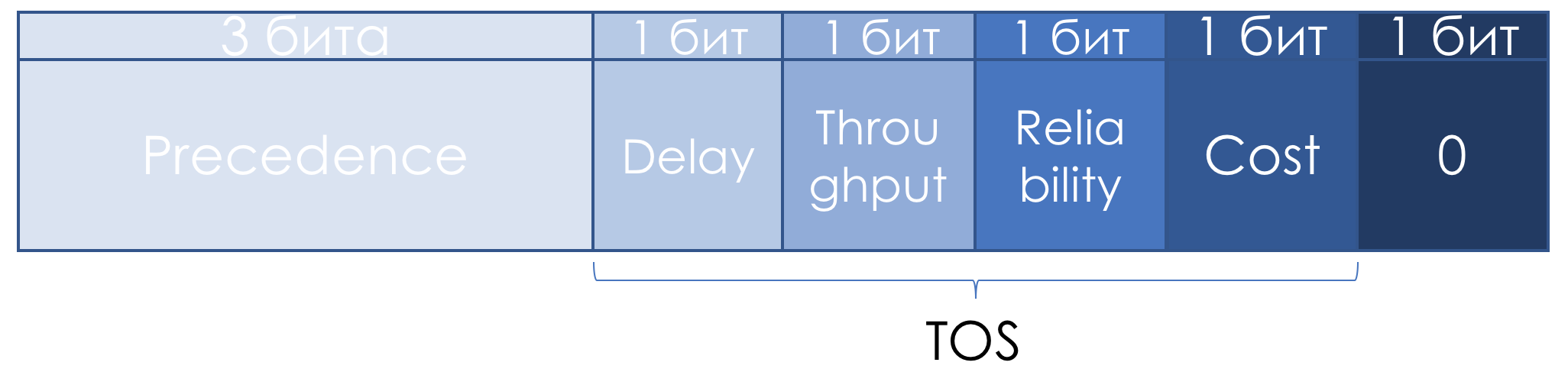
Die linken drei Bits blieben IP-Vorrang, die nächsten vier wurden nach dem Hinzufügen des Kostenbits zu TOS.
So lesen Sie die Einheiten in diesen TOS-Bits:
- D - "Minimierung der Verzögerung",
- T - "Maximierung des Durchsatzes",
- R - "Maximierung der Zuverlässigkeit",
- C - „Kosten minimieren“.
Trübe Beschreibungen trugen nicht zur Popularität dieses Ansatzes bei.
Es gab keinen systematischen Ansatz für die QoS auf dem gesamten Pfad, es gab keine klaren Empfehlungen zur Verwendung des Prioritätsfelds, die Beschreibung der Verzögerungs-, Durchsatz- und Zuverlässigkeitsbits war äußerst vage.
Daher wurde im Zusammenhang mit DiffServ das TOS-Feld in
RFC 2474 (
Definition des Feldes für differenzierte Dienste (DS-Feld) in den IPv4- und IPv6-Headern ) erneut neu definiert:

Anstelle der IPP- und DTRC-Bits wurde das Sechs-Bit-Feld DSCP -
Differentiated Services Code Point eingeführt, die beiden rechten Bits wurden nicht verwendet.
Von diesem Moment an war es das DSCP-Feld, das zur Hauptmarkierung von DiffServ hätte werden sollen: Es wird ein bestimmter Wert (Code) geschrieben, der innerhalb der DS-Domäne die spezifische Serviceklasse kennzeichnet, die für das Paket erforderlich ist, und seine Löschpriorität. Dies ist die gleiche Zahl.
Der Administrator kann alle 6 DSCP-Bits nach eigenem Ermessen verwenden und maximal 64 Serviceklassen gemeinsam nutzen.
Aus Gründen der Kompatibilität mit IP Precedence behielten sie jedoch die Rolle der Klassenauswahl für die ersten drei Bits bei.
Das heißt, wie in IPP können Sie mit 3 Bit Class Selector 8 Klassen definieren.

Dies ist jedoch immer noch nichts anderes als eine Vereinbarung, die der Administrator innerhalb der Grenzen seiner DS-Domäne nach eigenem Ermessen leicht ignorieren und alle 6 Bits verwenden kann.
Außerdem stelle ich fest, dass gemäß den IETF-Empfehlungen dieser Verkehr zum Dienst umso anspruchsvoller ist, je höher der in der CS aufgezeichnete Wert ist.
Dies sollte jedoch nicht als unbestreitbare Wahrheit angesehen werden.
Wenn die ersten drei Bits die Verkehrsklasse definieren, werden die nächsten drei verwendet, um die Paketabwurfpriorität (
Drop Precedence oder
Packet Loss Priority - PLP ) anzugeben.
Acht Klassen - ist es viel oder wenig? Auf den ersten Blick reicht es nicht aus - schließlich geht so viel unterschiedlicher Datenverkehr in das Netzwerk, dass man jedes Protokoll nach Klassen unterscheiden möchte. Es stellt sich jedoch heraus, dass acht für alle möglichen Szenarien ausreicht.
Für jede Klasse müssen Sie einen PHB definieren, der irgendwie anders damit umgeht als andere Klassen.
Und mit einer Erhöhung des Divisors steigt die Dividende (Ressource) nicht an.
Ich spreche absichtlich nicht über die genauen Werte der Verkehrsklasse, die sie beschreiben, da es keine Standards gibt und Sie diese nach eigenem Ermessen formell verwenden können. Im Folgenden werde ich Ihnen sagen, welche Klassen und ihre entsprechenden Werte empfohlen werden.
ECN-Bits ...Das Zwei-Bit-ECN-Feld wurde nur in
RFC 3168 (
Explicit Congestion Notification )
angezeigt . Das Feld wurde mit dem guten Zweck definiert, die End-Hosts explizit darüber zu informieren, dass auf dem Weg eine Überlastung aufgetreten ist.
Wenn beispielsweise Pakete in den Warteschlangen des Routers längere Zeit verzögert werden und diese beispielsweise um 85% füllen, ändert sich der ECN-Wert und teilt dem endgültigen Host mit, was langsamer sein muss - etwa Pause Frames on Ethernet.
In diesem Fall muss der Absender die Übertragungsrate und die Belastung des leidenden Knotens verringern.
Gleichzeitig ist theoretisch keine Unterstützung dieses Feldes durch alle Transitknoten erforderlich. Das heißt, die Verwendung von ECN unterbricht nicht das Netzwerk, das es nicht unterstützt.
Das Ziel ist gut, aber vor der Anwendung im Leben wird ECN nicht besonders gefunden. Heutzutage betrachten Mega- und Hyperscales diese beiden Teile mit
neuem Interesse .
ECN ist einer der nachstehend beschriebenen Mechanismen zur Vermeidung von Überlastungen.
DSCP-Klassifizierungspraxis
Es tut nicht weh, ein bisschen zu üben.
Das Schema ist das gleiche.
Senden Sie zunächst eine ICMP-Anfrage:
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Linkmeup_R1. E0 / 0. pcapng
pcapngUnd jetzt mit dem eingestellten DSCP-Wert.
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 tos 184 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Der Wert 184 ist die Dezimaldarstellung der Binärdatei 10111000. Von diesen sind die ersten 6 Bits 101110, dh die Dezimalzahl 46, und dies ist die Klasse EF.
Tabelle der Standard-TOS-Werte für bequemes Popingushki ...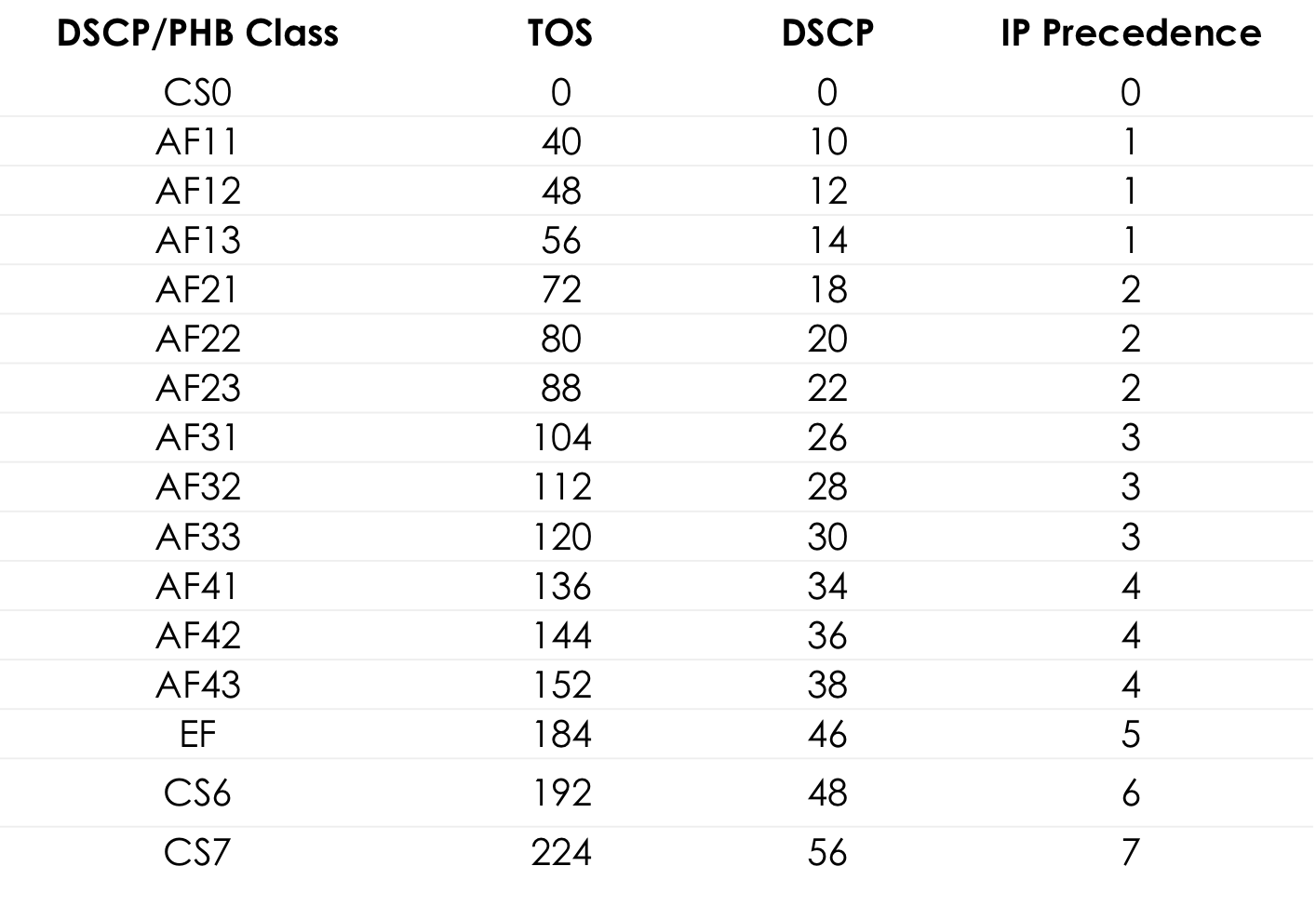 Weitere Details
Weitere DetailsUnten im Text im Kapitel der
IETF-Empfehlung werde ich Ihnen sagen, woher diese Nummern und Namen stammen.
Linkmeup_R2. E0 / 0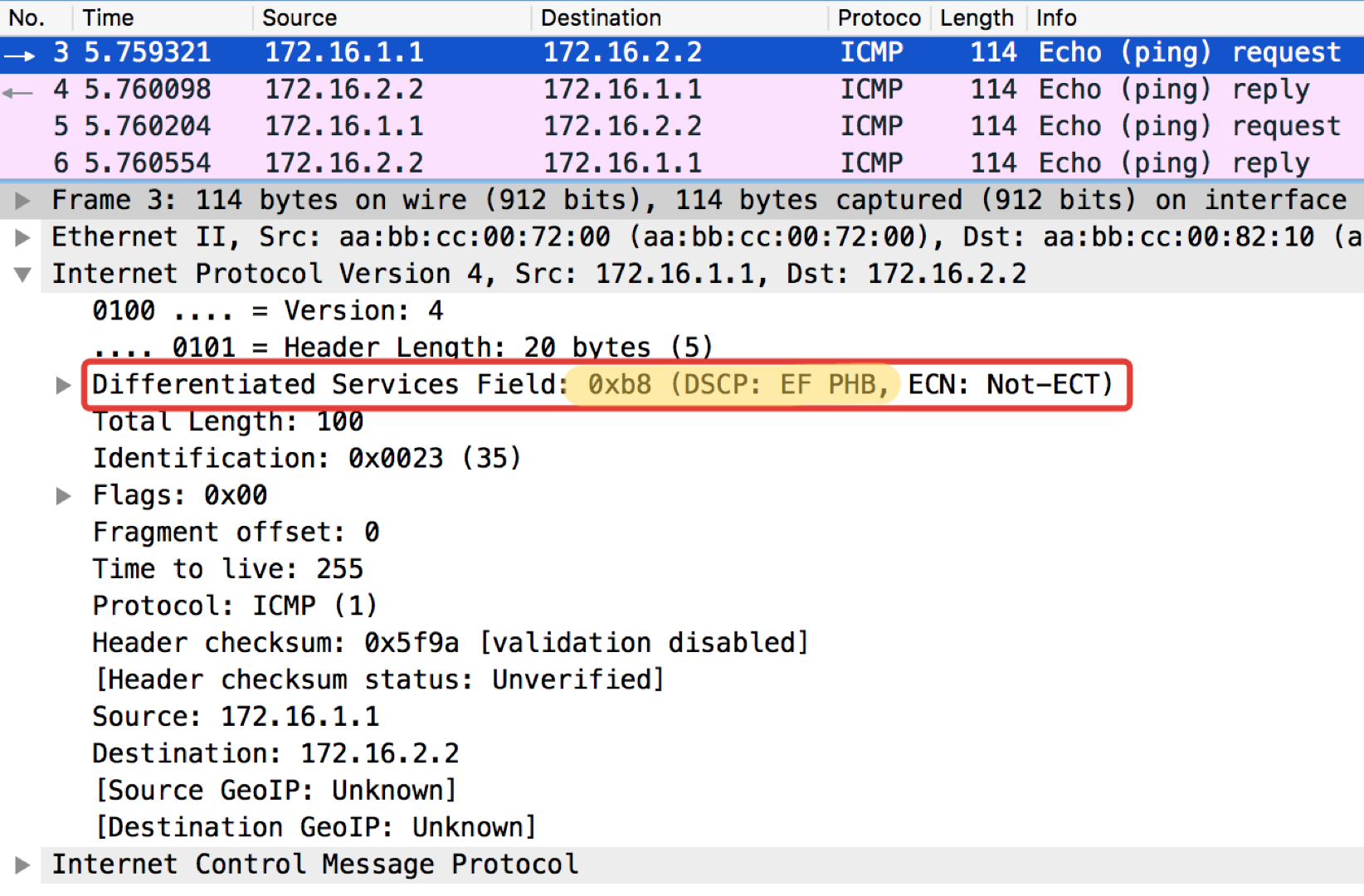 pcapng
pcapngEin merkwürdiger Hinweis: Das Ziel von Pingushka in der ICMP-Echoantwort setzt denselben Klassenwert wie in der Echoanforderung. Dies ist logisch - wenn der Absender ein Paket mit einer bestimmten Wichtigkeit gesendet hat, möchte er es offensichtlich garantiert zurückerhalten.
Linkmeup_R2. E0 / 0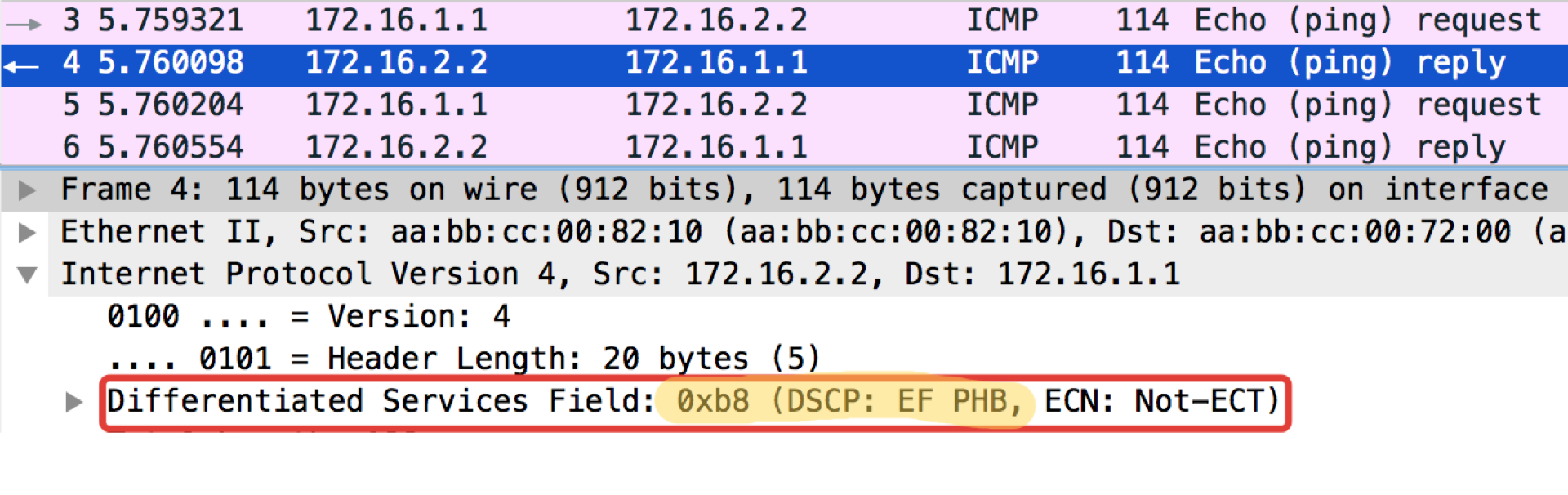 Konfigurationsdatei für die DSCP-Klassifizierung.
Konfigurationsdatei für die DSCP-Klassifizierung.IPv6-Verkehrsklasse
IPv6 unterscheidet sich in Bezug auf die QoS nicht wesentlich von IPv4. Das als Verkehrsklasse bezeichnete Acht-Bit-Feld ist ebenfalls in zwei Teile unterteilt. Die ersten 6 Bits - DSCP - spielen genau die gleiche Rolle.

Ja, Flow Label wurde angezeigt. Sie sagen, dass es für eine zusätzliche Differenzierung von Klassen verwendet werden könnte. Aber diese Idee wurde im Leben noch nicht angewendet.
MPLS-Verkehrsklasse
Das Konzept von DiffServ konzentrierte sich auf IP-Netzwerke mit IP-Header-Routing. Das ist einfach Pech - nach 3 Jahren veröffentlichten sie
RFC 3031 (
Multiprotocol Label Switching Architecture ). Und MPLS begann, Netzwerkanbieter zu übernehmen.
DiffServ konnte nicht auf ihn ausgedehnt werden.
Durch einen glücklichen Zufall wurde für jeden experimentellen Fall ein Drei-Bit-EXP-Feld in MPLS eingefügt. Und trotz der Tatsache, dass
RFC 5462 (
Feld „EXP“, das in Feld „Verkehrsklasse“ umbenannt wurde) vor langer Zeit offiziell zum Feld Verkehrsklasse wurde, wird es aufgrund der Trägheit IExPi genannt.
Es gibt ein Problem damit - seine Länge beträgt drei Bits, wodurch die Anzahl der möglichen Werte auf 9 begrenzt wird. Es ist nicht nur klein, es sind 3 binäre Ordnungen weniger als bei DSCP.

Da die MPLS-Verkehrsklasse häufig vom DSCP-IP-Paket geerbt wird, ist die Archivierung mit Verlust verbunden. Oder ... Nein, das willst du nicht wissen ...
L-LSP . Verwendet eine Kombination aus Verkehrsklasse + Beschriftungswert.
Im Allgemeinen ist die Situation seltsam - MPLS wurde als IP-Hilfe für schnelle Entscheidungen entwickelt - das MPLS-Label wird in CAM sofort durch Full Match anstelle des herkömmlichen Longest Prefix Match erkannt. Das heißt, sie wussten über IP Bescheid und nahmen am Wechsel teil, sahen jedoch kein normales Prioritätsfeld vor.
Tatsächlich haben wir oben bereits gesehen, dass nur die ersten drei Bits von DSCP verwendet werden, um die Verkehrsklasse zu bestimmen, und die anderen drei Bits sind Drop Precedence (oder PLP - Packet Loss Priority).
In Bezug auf Serviceklassen haben wir daher immer noch eine 1: 1-Korrespondenz, bei der nur Informationen zur Drop-Priorität verloren gehen.
Im Fall von MPLS kann die Klassifizierung wie in IP auf der Schnittstelle, MF, IP DSCP oder MPLS der Verkehrsklasse basieren.
Beschriftung bedeutet, einen Wert in das Feld Verkehrsklasse des MPLS-Headers zu schreiben.
Ein Paket kann mehrere MPLS-Header enthalten. Für DiffServ-Zwecke wird nur die Oberseite verwendet.
Es gibt drei verschiedene Szenarien zum erneuten Markieren, wenn ein Paket über die MPLS-Domäne von einem reinen IP-Segment in ein anderes verschoben wird: (Dies ist nur ein Auszug aus dem
Artikel ).
- Einheitlicher Modus
- Rohrmodus
- Kurzrohrmodus
Betriebsarten ...Einheitlicher Modus
Dies ist ein flaches End-to-End-Modell.
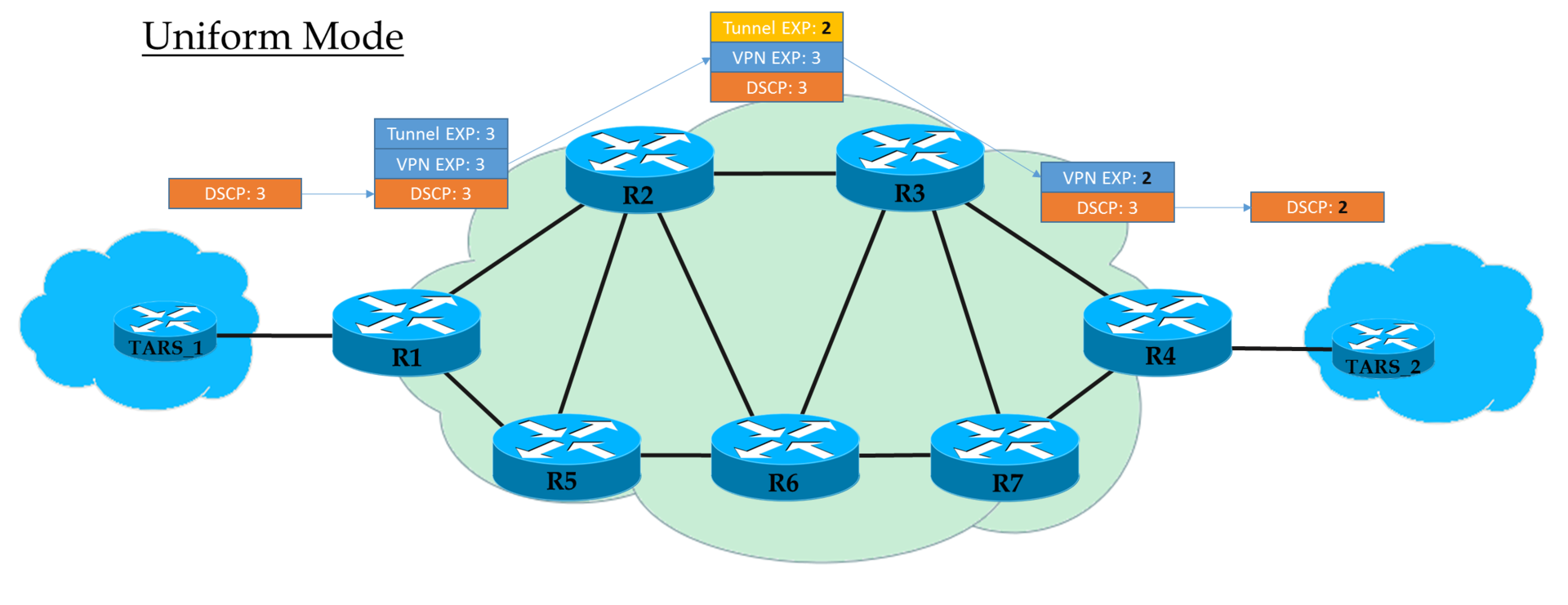
Bei Ingress PE vertrauen wir IP DSCP und kopieren (
genau genommen, Anzeige, aber der Einfachheit halber sagen wir "Kopieren" ) seinen Wert in MPLS EXP (sowohl Tunnel- als auch VPN-Header). Am Ausgang von Ingress PE wird das Paket bereits gemäß dem Wert des EXP-Feldes des oberen MPLS-Headers verarbeitet.
Jeder Transit P verarbeitet auch Pakete basierend auf der obersten EXP. Gleichzeitig kann er es ändern, wenn der Bediener es wünscht.
Der vorletzte Knoten entfernt das Transportetikett (PHP) und kopiert den EXP-Wert in den VPN-Header. Es spielt keine Rolle, was dort stand - im einheitlichen Modus erfolgt das Kopieren.
Egress PE, das das VPN-Label entfernt, kopiert auch den EXP-Wert nach IP DSCP, selbst wenn dort etwas anderes geschrieben ist.
Das heißt, wenn sich irgendwo in der Mitte der Wert des EXP-Labels im Tunnel-Header geändert hat, wird diese Änderung vom IP-Paket übernommen.
Rohrmodus
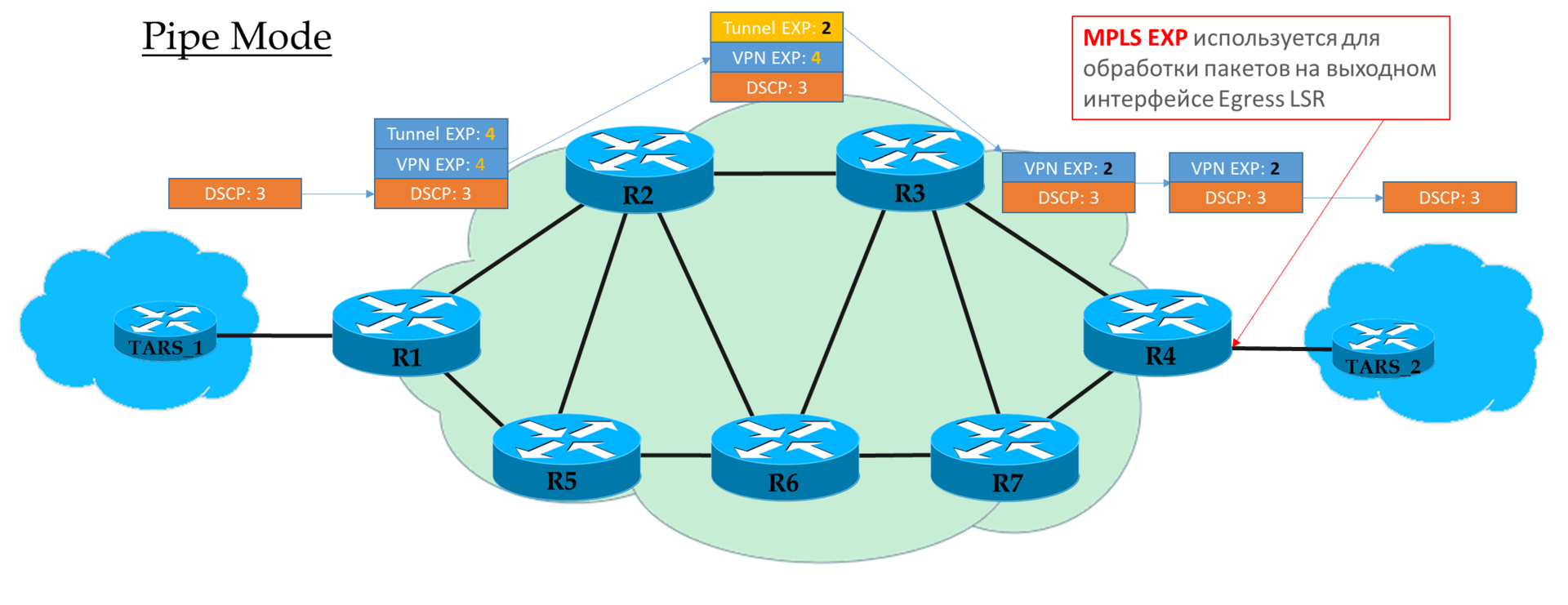
Wenn wir in Ingress PE entschieden haben, dem DSCP-Wert nicht zu vertrauen, wird der vom Operator gewünschte EXP-Wert in die MPLS-Header eingefügt.
Es ist jedoch akzeptabel, diejenigen zu kopieren, die in DSCP enthalten waren. Sie können beispielsweise Werte neu definieren - kopieren Sie alles auf EF und ordnen Sie CS6 und CS7 EF zu.
Jeder Transit P betrachtet nur die EXP des oberen MPLS-Headers.
Der vorletzte Knoten entfernt das Transportetikett (PHP) und
kopiert den EXP-Wert in den VPN-Header.
Egress PE verarbeitet das Paket zuerst basierend auf dem EXP-Feld im MPLS-Header und entfernt es erst dann,
ohne den Wert nach DSCP
zu kopieren .
Das heißt, unabhängig davon, was mit dem EXP-Feld in den MPLS-Headern passiert ist, bleibt der IP-DSCP unverändert.
Ein solches Szenario kann verwendet werden, wenn der Betreiber über eine eigene Diff-Serv-Domäne verfügt und nicht möchte, dass der Client-Verkehr diese irgendwie beeinflusst.
Kurzrohrmodus
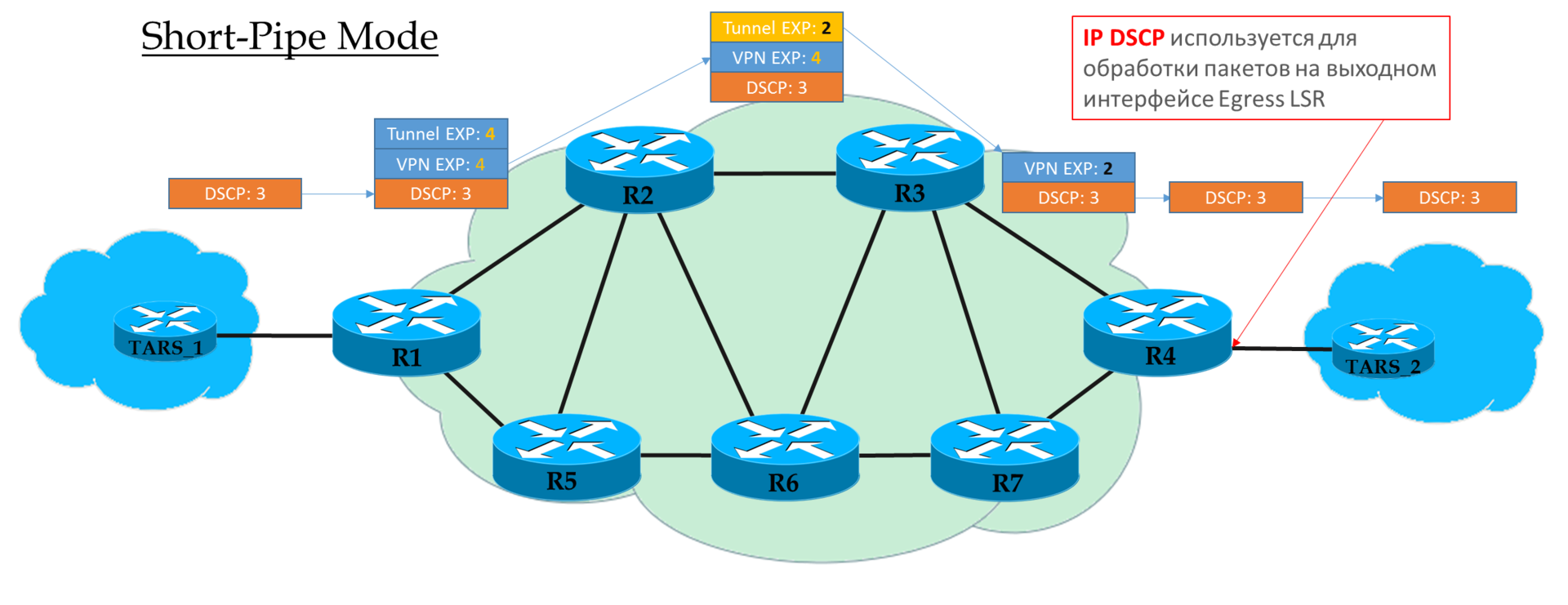
Sie können diesen Modus als eine Variation des Rohrmodus betrachten. Der einzige Unterschied besteht darin, dass beim Verlassen des MPLS-Netzwerks das Paket gemäß seinem IP-DSCP-Feld und nicht gemäß MPLS EXP verarbeitet wird.
Dies bedeutet, dass die Priorität des Pakets am Ausgang vom Client und nicht vom Operator bestimmt wird.
Ingress PE vertraut eingehenden IP DSCP-Paketen nicht
Transit Ps sehen Sie im EXP-Feld des oberen Headers.
Das vorletzte P entfernt das Transportetikett und kopiert den Wert auf das VPN-Etikett.
Egress PE entfernt zuerst das MPLS-Label und verarbeitet dann das Paket in den Warteschlangen.
Erklärung von
Cisco .
Klassifizierungspraxis MPLS Traffic Class
Das Schema ist das gleiche:
Die Konfigurationsdatei ist dieselbe.Im Linkmeup-Netzwerkdiagramm gibt es einen Übergang von IP zu MPLS zu Linkmeup_R2.
Mal sehen, was mit dem Markieren passiert, wenn
Ping IP 172.16.2.2 Quelle 172.16.1.1 tos 184 ping .
Linkmeup_R2. E0 / 0. pcapng
pcapngWir sehen also, dass das ursprüngliche EF-Label in IP DSCP in den Wert 5 des EXP MPLS-Felds (es ist auch die Verkehrsklasse, denken Sie daran) sowohl des VPN-Headers als auch des Transport-Headers umgewandelt wurde.
Hier sind wir Zeugen der einheitlichen Arbeitsweise.
Ethernet 802.1p
Das Fehlen eines Prioritätsfeldes in 802.3 (Ethernet) erklärt sich aus der Tatsache, dass Ethernet ursprünglich ausschließlich als Lösung für das LAN-Segment geplant war. Für bescheidenes Geld können Sie übermäßige Bandbreite erhalten, und der Uplink wird immer ein Engpass sein - Sie müssen sich keine Gedanken über die Priorisierung machen.
Es wurde jedoch schnell klar, dass die finanzielle Attraktivität von Ethernet + IP dieses Bundle auf die Backbone- und WAN-Ebene bringt. Und das Zusammenleben in einem LAN-Segment von Torrents und Telefonie muss gelöst werden.
Glücklicherweise kam 802.1q (VLAN) rechtzeitig dafür an, in dem ein (erneut) 3-Bit-Feld für Prioritäten zugewiesen wurde.
In diesem Feld können Sie im DiffServ-Plan dieselben 8 Verkehrsklassen definieren.
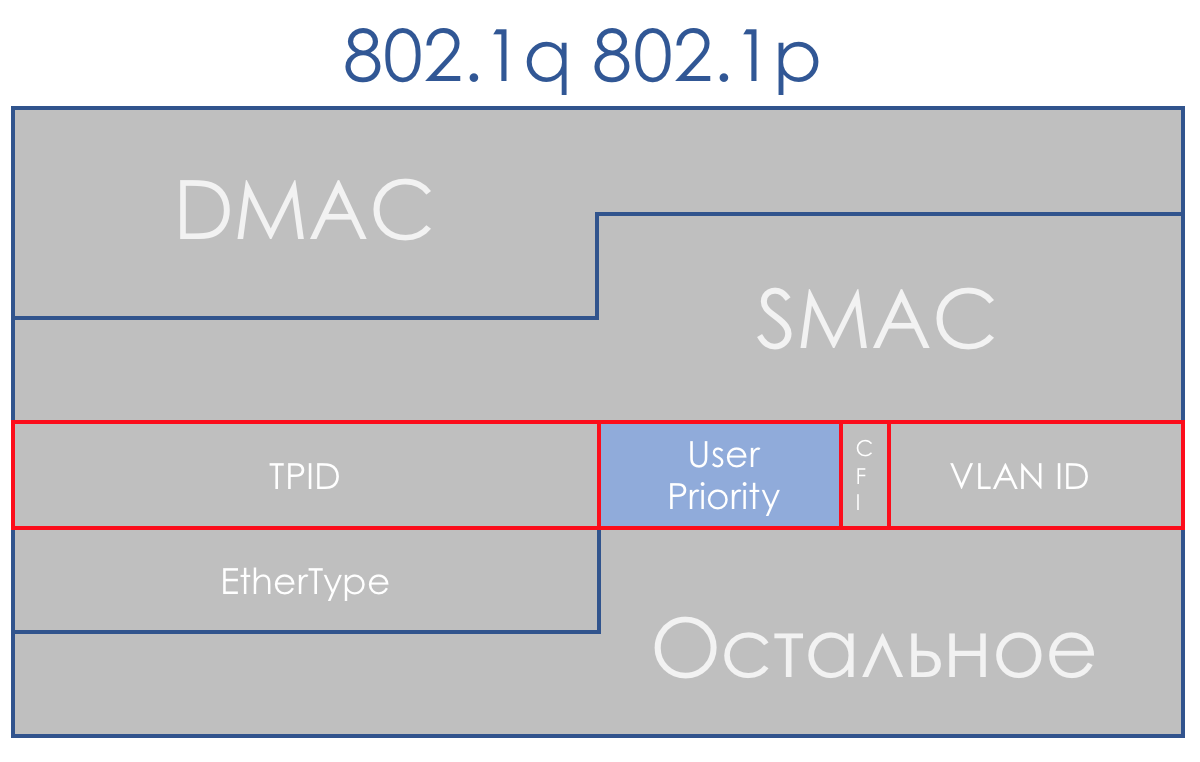
Beim Empfang eines Pakets berücksichtigt das Netzwerkgerät der DS-Domäne in den meisten Fällen den Header, den es zum Umschalten verwendet:
- Ethernet-Switch - 802.1p
- MPLS-Knoten - MPLS-Verkehrsklasse
- IP Router - IP DSCP
Dieses Verhalten kann zwar geändert werden: Schnittstellenbasierte Klassifizierung und Klassifizierung mehrerer Felder. Und manchmal können Sie im CoS-Feld sogar explizit angeben, welcher Header angezeigt werden soll.
Schnittstellenbasiert
Dies ist der einfachste Weg, um Pakete auf der Stirn zu klassifizieren. Alles, was in die angegebene Schnittstelle gegossen wird, ist mit einer bestimmten Klasse gekennzeichnet.
In einigen Fällen reicht diese Granularität aus, sodass Interface-basiert im Leben verwendet wird.
Schnittstellenbasierte Klassifizierungspraxis
Das Schema ist das gleiche:
Das Einrichten von QoS-Richtlinien in den Geräten der meisten Anbieter ist in Phasen unterteilt.
- Zunächst wird ein Klassifikator definiert:
class-map match-all TRISOLARANS_INTERFACE_CM
match input-interface Ethernet0/2
Alles, was zur Ethernet0 / 2-Schnittstelle gehört.
- Als Nächstes wird eine Richtlinie erstellt, in der der Klassifizierer und die erforderliche Aktion verknüpft sind.
policy-map TRISOLARANS_REMARK class TRISOLARANS_INTERFACE_CM set ip dscp cs7
Wenn das Paket den Klassifizierer TRISOLARANS_INTERFACE_CM erfüllt, schreiben Sie CS7 in das Feld DSCP.
Hier komme ich mit obskurem CS7 und dann EF, AF voran. Unten können Sie über diese Abkürzungen und akzeptierten Vereinbarungen lesen. In der Zwischenzeit reicht es zu wissen, dass es sich um verschiedene Klassen mit unterschiedlichen Servicelevels handelt.
- Der letzte Schritt besteht darin, die Richtlinie auf die Schnittstelle anzuwenden:
interface Ethernet0/2 service-policy input TRISOLARANS_REMARK
Hier ist der Klassifizierer etwas redundant, wodurch überprüft wird, ob das Paket an die e0 / 2-Schnittstelle gelangt ist, wo wir dann die Richtlinie anwenden. Man könnte jede Übereinstimmung schreiben:
class-map match-all TRISOLARANS_INTERFACE_CM match any
Die Richtlinie kann jedoch tatsächlich auf vlanif oder auf die Ausgabeschnittstelle angewendet werden, sodass dies möglich ist.
Führen Sie den üblichen Ping auf 172.16.2.2 (Trisolaran2) mit Trisolaran1 aus:
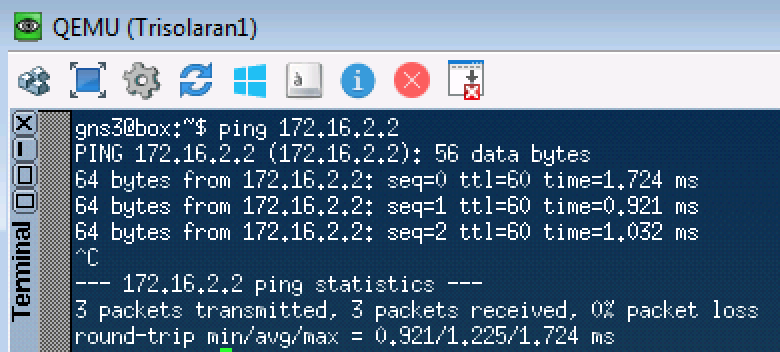
Und im Dump zwischen Linkmeup_R1 und Linkmeup_R2 sehen wir Folgendes:
 pcapngSchnittstellenbasierte Klassifizierung der Konfigurationsdatei.
pcapngSchnittstellenbasierte Klassifizierung der Konfigurationsdatei.Multi-Feld
Die häufigste Art der Klassifizierung am Eingang zur DS-Domäne. Wir vertrauen der vorhandenen Kennzeichnung nicht und weisen anhand der Paket-Header eine Klasse zu.
Oft ist dies eine Möglichkeit, QoS überhaupt zu "aktivieren", wenn Absender nicht markieren.
Ein ziemlich flexibles Werkzeug, aber gleichzeitig umständlich - Sie müssen für jede Klasse schwierige Regeln erstellen. Daher ist BA innerhalb der DS-Domäne relevanter.
MF-Klassifizierungspraxis
Das Schema ist das gleiche:
Aus den obigen praktischen Beispielen ist ersichtlich, dass Netzwerkgeräte standardmäßig der Kennzeichnung eingehender Pakete vertrauen.
Dies ist innerhalb der DS-Domäne in Ordnung, am Einstiegspunkt jedoch nicht akzeptabel.
Und jetzt lasst uns nicht blind vertrauen? In
Linkmeup_R2 wird ICMP als EF (nur zum Beispiel), TCP als AF12 und alles andere als CS0 bezeichnet.
Dies ist die MF-Klassifizierung (Multi-Field).
- Das Verfahren ist das gleiche, aber jetzt werden wir nach ACLs suchen, die die erforderlichen Verkehrskategorien aushängen, also erstellen wir sie zuerst.
Auf Linkmeup_R2:
ip access-list extended TRISOLARANS_ICMP_ACL permit icmp any any ip access-list extended TRISOLARANS_TCP_ACL permit tcp any any ip access-list extended TRISOLARANS_OTHER_ACL permit ip any any
- Als nächstes definieren wir die Klassifikatoren:
class-map match-all TRISOLARANS_TCP_CM match access-group name TRISOLARANS_TCP_ACL class-map match-all TRISOLARANS_OTHER_CM match access-group name TRISOLARANS_OTHER_ACL class-map match-all TRISOLARANS_ICMP_CM match access-group name TRISOLARANS_ICMP_ACL
- Und jetzt definieren wir die Regeln für Bemerkungen in der Politik:
policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_ICMP_CM set ip dscp ef class TRISOLARANS_TCP_CM set ip dscp af11 class TRISOLARANS_OTHER_CM set ip dscp default
- Und wir hängen Richtlinien an die Schnittstelle. Bei der Eingabe jeweils, da die Entscheidung am Eingang zum Netzwerk getroffen werden muss.
interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
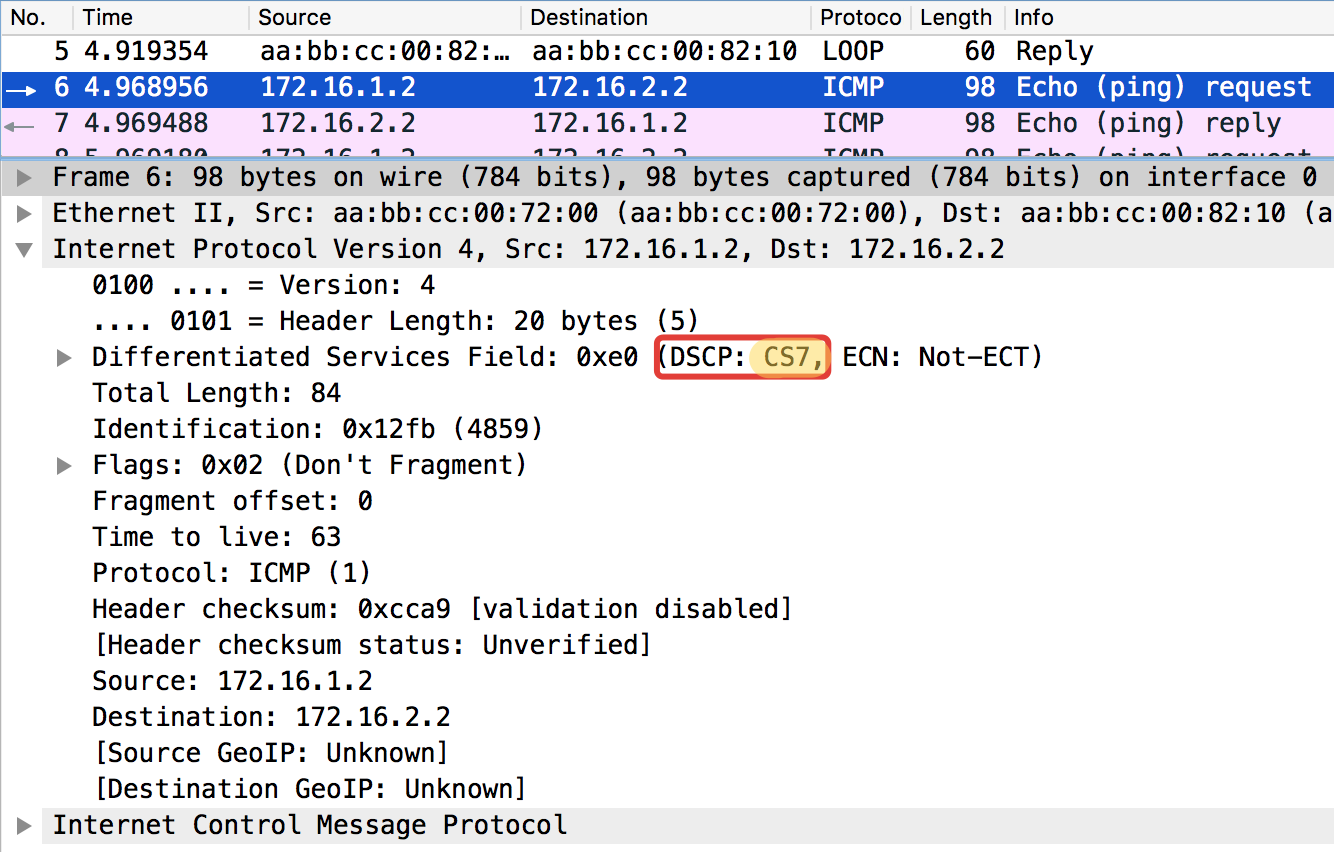
ICMP-Test vom endgültigen Wirt Trisolaran1. Wir geben die Klasse nicht wissentlich an - der Standardwert ist 0.
Ich habe die Richtlinie bereits mit Linkmeup_R1 entfernt, sodass der Datenverkehr mit der Markierung CS0 und nicht mit CS7 versehen ist.
Hier sind zwei Dumps in der Nähe, mit Linkmeup_R1 und Linkmeup_R2:
Linkmeup_R1. E0 / 0.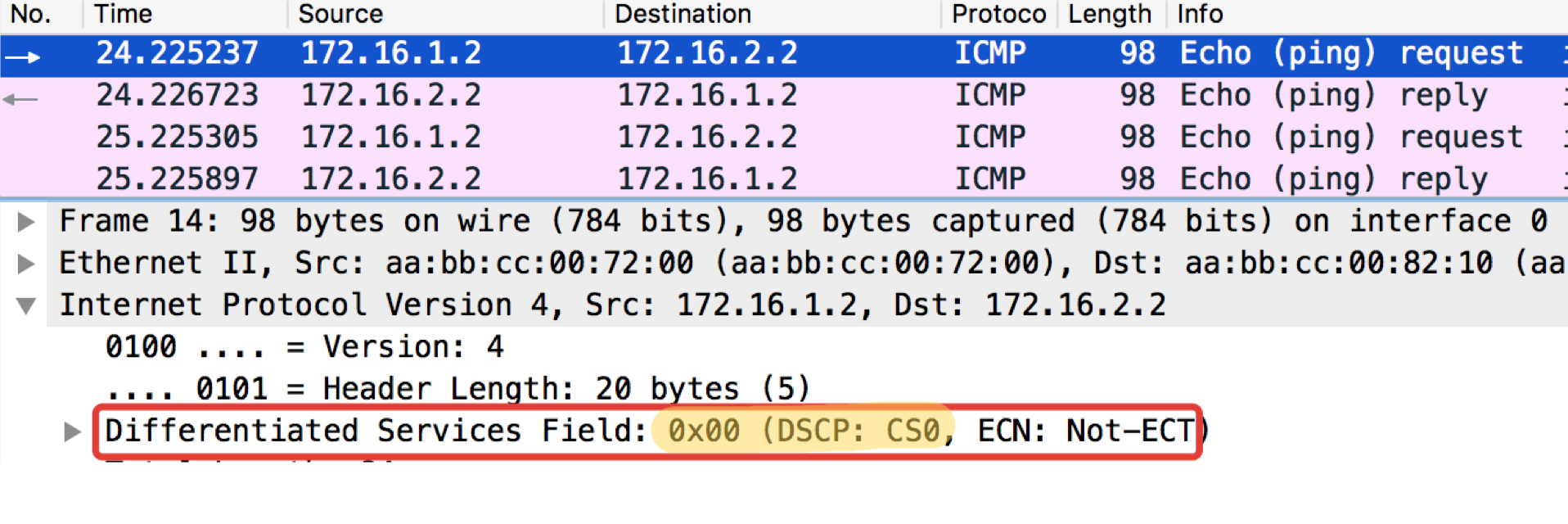 pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.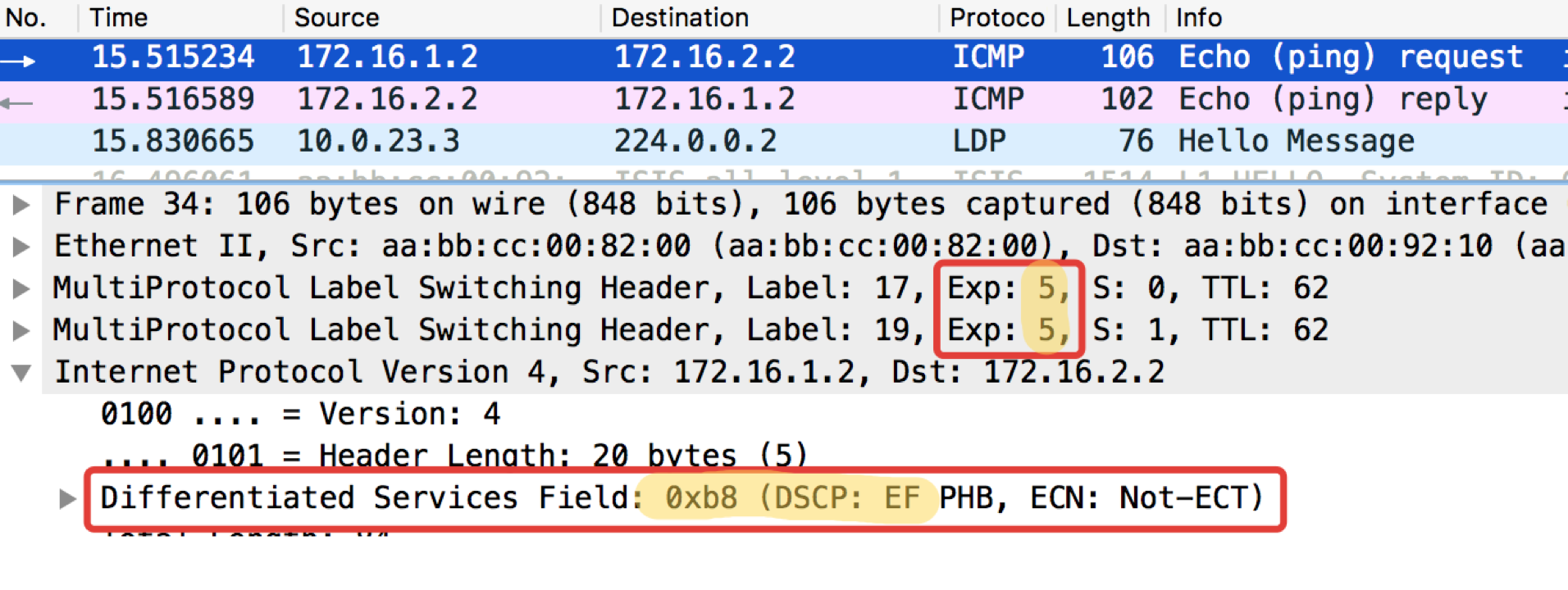 pcapng
pcapngEs ist ersichtlich, dass nach Klassifizierern und erneuter Kennzeichnung von Linkmeup_R2 in ICMP-Paketen nicht nur DSCP in EF geändert wurde, sondern die MPLS-Verkehrsklasse gleich 5 wurde.
Ein ähnlicher Test mit Telnet 172.16.2.2. 80 - also TCP überprüfen:
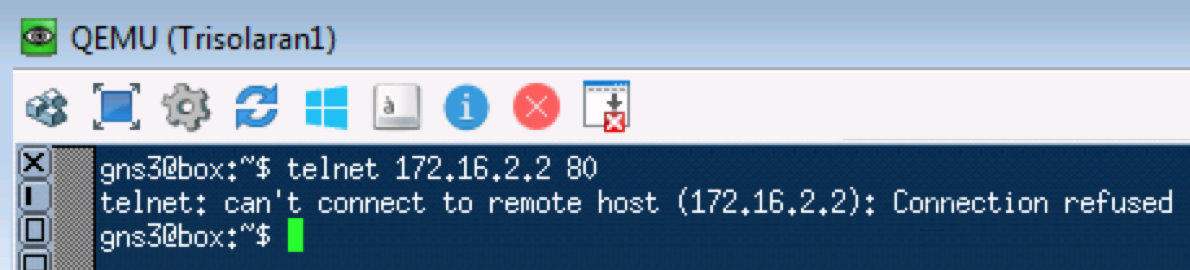 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0. pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.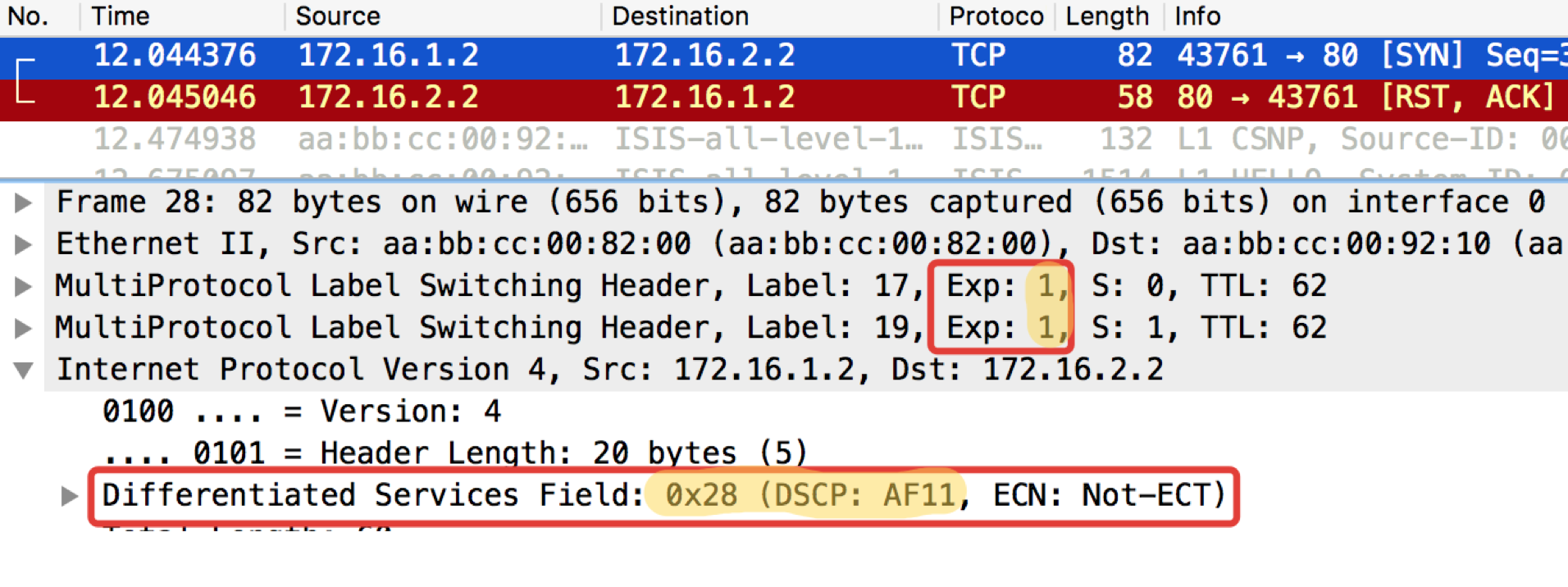 pcapng
pcapngLESEN - Was und zu erwarten. TCP wird als AF11 übertragen.
Der nächste Test testet UDP, das gemäß unseren Klassifikatoren zu CS0 gehen sollte. Wir werden dafür iperf verwenden (über Apps auf Linux Tiny Core bringen). Auf der Remote-Seite
iperf3 -s - Starten Sie den Server, auf dem lokalen
iperf3 -c -u -t1 - Client (
-c ), UDP-Protokoll (
-u ), testen Sie 1 Sekunde lang (
-t1 ).
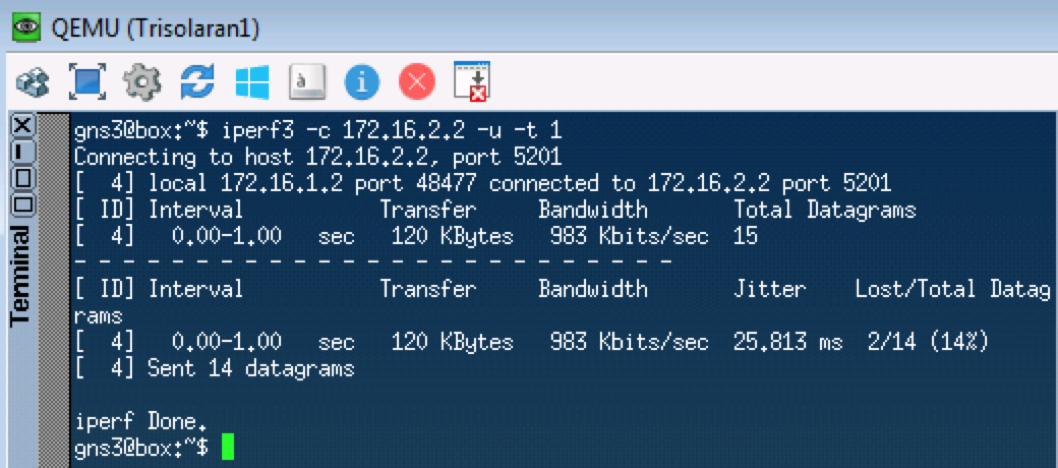 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0.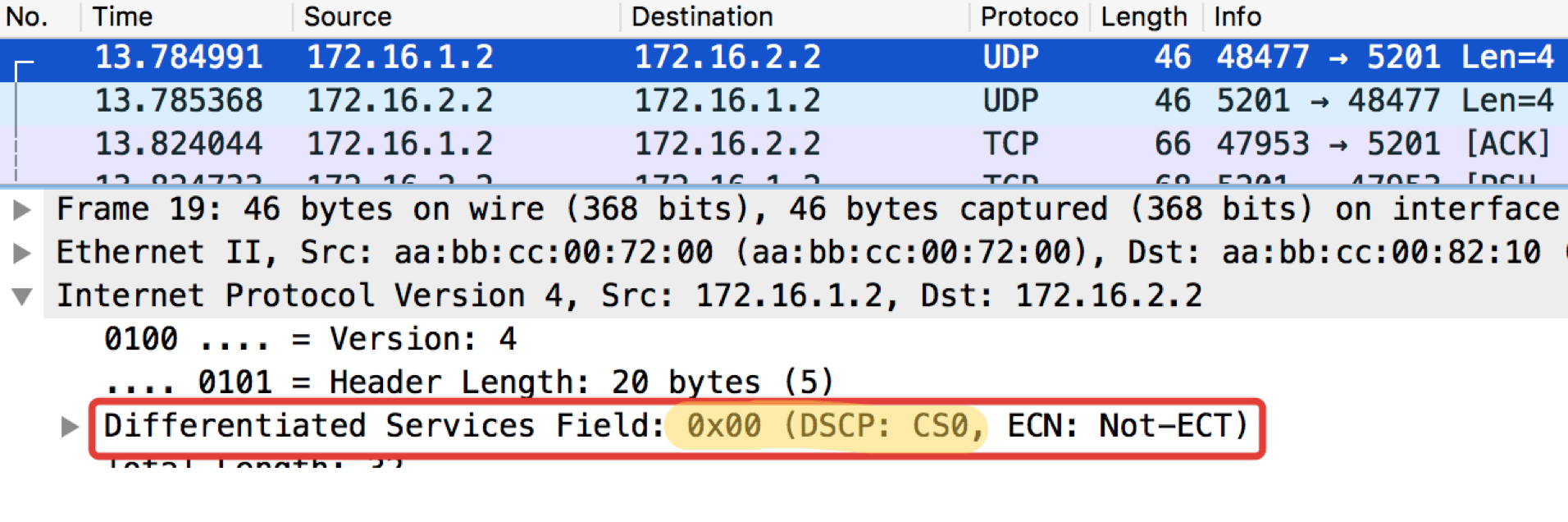 pcapngLinkmeup_R2. E0 / 0
pcapngLinkmeup_R2. E0 / 0 pcapng
pcapngVon nun an wird alles, was zu dieser Schnittstelle kommt, gemäß den konfigurierten Regeln klassifiziert.
Markierung im Gerät
Nochmals: Am Eingang zur DS-Domain kann die Klassifizierung MF, Interface-based oder BA erfolgen.
Zwischen den Knoten der DS-Domäne trägt das Paket im Header ein Vorzeichen über die erforderliche Dienstklasse und wird von BA klassifiziert.
Unabhängig von der Klassifizierungsmethode wird dem Paket danach eine innere Klasse innerhalb des Geräts zugewiesen, nach der es verarbeitet wird. Der Header wird entfernt und das nackte (kein) Paket wandert zum Ausgang.
Und am Ausgang wird die innere Klasse in das CoS-Feld des neuen Headers konvertiert.
Das heißt, Position 1 ⇒ Klassifizierung ⇒ Interne Serviceklasse ⇒ Position 2.
In einigen Fällen müssen Sie das Headerfeld eines Protokolls im Headerfeld eines anderen Protokolls anzeigen, z. B. DSCP in der Verkehrsklasse.
Dies geschieht nur durch die interne Zwischenmarkierung.
Zum Beispiel DSCP-Header ⇒ Klassifizierung ⇒ Interne Serviceklasse ⇒ Verkehrsklassen-Header.
Formal können innere Klassen nach Belieben aufgerufen oder einfach nummeriert werden, und ihnen ist nur eine bestimmte Warteschlange zugewiesen.
In der Tiefe, in die wir in diesem Artikel eintauchen, spielt es keine Rolle, wie sie genannt werden. Es ist wichtig, dass ein bestimmtes Verhaltensmodell bestimmten Werten von QoS-Feldern zugeordnet wird.
Wenn es sich um bestimmte QoS-Implementierungen handelt, ist die Anzahl der Serviceklassen, die das Gerät bereitstellen kann, nicht höher als die Anzahl der verfügbaren Warteschlangen. Oft gibt es acht von ihnen (entweder unter dem Einfluss von IPP oder manchmal durch ungeschriebene Vereinbarung). Je nach Hersteller, Gerät und Karte können sie jedoch mehr oder weniger sein.
Das heißt, wenn es 4 Warteschlangen gibt, machen die Serviceklassen einfach keinen Sinn, mehr als vier zu tun.
Lassen Sie uns im Kapitel Hardware näher darauf eingehen.
Wenn Sie noch wirklich ein wenig Spezifität wollen ...Die folgenden Tabellen mögen auf den ersten Blick für die Beziehung zwischen QoS-Feldern und inneren Klassen zweckmäßig erscheinen, sind jedoch beim Aufrufen von Klassen-PHB-Namen etwas irreführend. PHB ist jedoch, welche Art von Verhaltensmodell dem Verkehr einer bestimmten Klasse zugewiesen wird, dessen Name grob gesagt willkürlich ist.
Beziehen Sie sich daher mit einiger Skepsis (daher unter dem Spoiler) auf die folgenden Tabellen.
Am Beispiel von Huawei . Hier ist die Service-Klasse die innerste Klasse des Pakets.
Das heißt, wenn BA am Eingang klassifiziert ist, werden die DSCP-Werte in die entsprechenden Werte für Serviceklasse und Farbe übersetzt.

Es ist zu beachten, dass viele DSCP-Werte nicht verwendet werden und Pakete mit solchen Markierungen tatsächlich als BE verarbeitet werden.
Hier ist eine rückwärts übereinstimmende Tabelle, die zeigt, welche DSCP-Werte für den Datenverkehr festgelegt werden, wenn die Ausgabe erneut markiert wird.

Beachten Sie, dass nur AF eine Farbabstufung aufweist. BE, EF, CS6, CS7 - alles nur grün.
Dies ist eine Tabelle zum Konvertieren von IPP-, MPLS-Verkehrsklassen- und 802.1p-Ethernet-Feldern in interne Dienstklassen.

Und zurück.

Beachten Sie, dass hier im Allgemeinen alle Informationen zur Drop-Priorität verloren gehen.
Es sollte wiederholt werden - dies ist nur ein spezielles Beispiel für Standardübereinstimmungen von
zufällig ausgewählten Anbietern. Für andere kann dies anders sein. Administratoren können in ihrem Netzwerk völlig unterschiedliche Klassen von Diensten und PHBs konfigurieren.
In Bezug auf PHB gibt es absolut keinen Unterschied, was für die Klassifizierung verwendet wird - DSCP, Verkehrsklasse, 802.1p.
Innerhalb des Geräts werden sie zu Verkehrsklassen, die vom Netzwerkadministrator definiert werden.
Das heißt, all diese Markierungen sind eine Möglichkeit, den Nachbarn mitzuteilen, welche Serviceklasse sie diesem Paket zuweisen sollen. Es geht um die BGP-Community, die für sich genommen nichts bedeutet, bis die Richtlinie für ihre Interpretation im Netzwerk definiert ist.
IETF-Empfehlungen (Verkehrskategorien, Serviceklassen und Verhalten)
Standards standardisieren überhaupt nicht, welche bestimmten Serviceklassen existieren sollten, wie sie zu klassifizieren und zu kennzeichnen sind und welche PHB auf sie anzuwenden sind.
Dies ist den Anbietern und Netzwerkadministratoren ausgeliefert.
Wir haben nur 3 Bits - wir verwenden, wie wir wollen.
Das ist gut:
- Jedes Stück Eisen (Anbieter) wählt unabhängig voneinander aus, welche Mechanismen für PHB verwendet werden sollen - keine Signalisierung, keine Kompatibilitätsprobleme.
- Der Administrator jedes Netzwerks kann den Datenverkehr flexibel auf verschiedene Klassen verteilen, die Klassen selbst und den entsprechenden PHB auswählen.
Das ist schlecht:
- An den Grenzen von DS-Domänen treten Konvertierungsprobleme auf.
- Unter Bedingungen völliger Handlungsfreiheit - einige sind im Wald, andere sind Dämonen.
Aus diesem Grund hat die IETF 2006 ein Schulungshandbuch zur Vorgehensweise bei der
Dienstdifferenzierung herausgegeben :
RFC 4594 (
Konfigurationsrichtlinien für DiffServ- Dienstklassen).
Das Folgende ist eine kurze Zusammenfassung dieses RFC.
Verhaltensmodelle (PHB)
DF - StandardweiterleitungStandardversand.Wenn einem Verkehrsmodell kein spezielles Verhaltensmodell zugewiesen ist, wird es mithilfe der Standardweiterleitung verarbeitet.
Dies ist Best Effort - das Gerät wird alles tun, aber nichts garantieren. Tropfen, Störungen, unvorhersehbare Verzögerungen und schwebender Jitter sind möglich, aber dies ist nicht genau.
Dieses Modell eignet sich für anspruchslose Anwendungen wie Mail- oder Dateidownloads.
Übrigens gibt es PHB und noch weniger eindeutig -
A Lower Effort .
AF - Gesicherte WeiterleitungGarantierter Versand.Dies ist eine verbesserte BE. Einige Garantien erscheinen hier, zum Beispiel Bänder. Drops und Floating Delays sind weiterhin möglich, jedoch in viel geringerem Maße.
Das Modell eignet sich für Multimedia: Streaming, Videokonferenzen, Online-Spiele.
RFC 2597 (
Assured Forwarding PHB Group ).
EF - Beschleunigte WeiterleitungNotversand.Alle Ressourcen und Prioritäten rasen hier. Dies ist ein Modell für Anwendungen, die keine Verluste, kurze Verzögerungen und stabilen Jitter benötigen, aber nicht gierig auf die Band sind. Wie zum Beispiel Telefonie oder ein Drahtemulationsdienst (CES - Circuit Emulation Service).
Verluste, Störungen und Verzögerungen bei der EF sind äußerst unwahrscheinlich.
RFC 3246 (
Ein Expedited Forwarding PHB ).
CS - KlassenauswahlHierbei handelt es sich um Verhaltensweisen, mit denen die Abwärtskompatibilität mit IP-Vorrang in DS-fähigen Netzwerken aufrechterhalten werden soll.
Die folgenden Klassen sind in IPP vorhanden: CS0, CS1, CS2, CS3, CS4, CS5, CS6, CS7.
Nicht immer gibt es für alle einen separaten PHB, normalerweise gibt es zwei oder drei, und der Rest wird einfach in die nächste DSCP-Klasse übersetzt und erhält den entsprechenden PHB.
So kann beispielsweise ein Paket mit der Bezeichnung CS 011000 als 011010 klassifiziert werden.
Von den CS sind sicherlich nur CS6, CS7, die für das NCP - Network Control Protocol empfohlen werden und einen separaten PHB erfordern, im Gerät erhalten.
Wie EF wurde PHB CS6.7 für Klassen entwickelt, die sehr hohe Latenz- und Verlustanforderungen haben, jedoch eine gewisse Toleranz gegenüber Bandunterscheidung aufweisen.
Die Aufgabe von PHB für CS6.7 besteht darin, ein Serviceniveau bereitzustellen, das Unterbrechungen und Verzögerungen auch bei extremer Überlastung der Schnittstelle, des Chips und der Warteschlangen verhindert.
Es ist wichtig zu verstehen, dass PHB ein abstraktes Konzept ist - und tatsächlich werden sie durch Mechanismen implementiert, die auf realen Geräten verfügbar sind.
Daher kann sich der in der DS-Domäne definierte PHB bei Juniper und Huawei unterscheiden.
Darüber hinaus ist ein einzelner PHB kein statischer Satz von Aktionen. Beispielsweise kann ein PHB-AF aus mehreren Optionen bestehen, die sich in der Höhe der Garantien unterscheiden (Band, akzeptable Verzögerungen).
Serviceklassen
Die IETF kümmerte sich um die Administratoren und identifizierte die Hauptkategorien von Anwendungen und deren Serviceklassen.
Ich werde hier nicht ausführlich sein, fügen Sie einfach ein paar Platten aus dieser Richtlinie RFC ein.Anwendungskategorien: Anforderungen an Netzwerkeigenschaften:
Anforderungen an Netzwerkeigenschaften: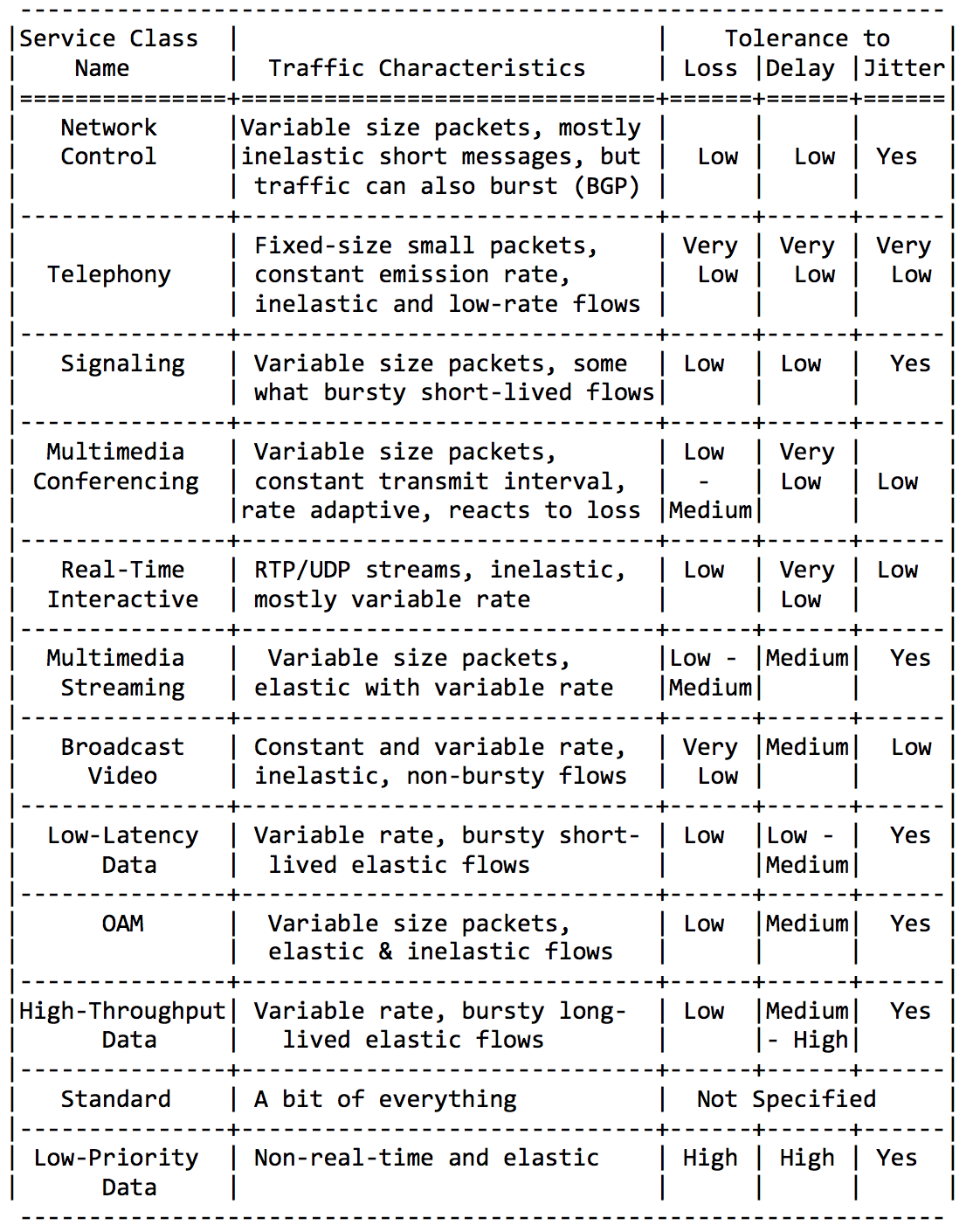 Und schließlich empfohlene Klassennamen und entsprechende DSCP-Werte:
Und schließlich empfohlene Klassennamen und entsprechende DSCP-Werte: Durch Kombinieren der oben genannten Klassen auf unterschiedliche Weise (passend zu den 8 verfügbaren) können Sie QoS-Lösungen für verschiedene Netzwerke erhalten.Am häufigsten ist dies vielleicht:
Durch Kombinieren der oben genannten Klassen auf unterschiedliche Weise (passend zu den 8 verfügbaren) können Sie QoS-Lösungen für verschiedene Netzwerke erhalten.Am häufigsten ist dies vielleicht: Klasse DF (oder BE) kennzeichnet absolut anspruchslosen Verkehr - er erhält Restaufmerksamkeit.PHB AF dient den Klassen AF1, AF2, AF3, AF4. Sie alle müssen eine Fahrspur zum Nachteil von Verzögerungen und Verlusten bereitstellen. Verluste werden durch die Drop Precedence-Bits gesteuert, weshalb sie als AFxy bezeichnet werden, wobei x die Serviceklasse und y Drop Precedence ist.EF benötigt eine Art Mindestbandgarantie, aber was noch wichtiger ist - eine Garantie für Verzögerungen, Jitter und keinen Verlust.CS6, CS7 benötigen noch weniger Bandbreite, da dies eine Vielzahl von Servicepaketen ist, bei denen Bursts noch möglich sind (z. B. BGP-Update), Verluste und Verzögerungen jedoch nicht akzeptabel sind - was ist die Verwendung von BFD mit einem Timer von 10 ms, wenn Hello abstürzt 100 ms Warteschlangen?Das heißt, 4 von 8 verfügbaren Klassen wurden unter AF angegeben.Und trotz der Tatsache, dass sie normalerweise genau das tun, wiederhole ich, dass dies nur Empfehlungen sind und nichts drei Klassen in Ihrer DS-Domäne daran hindert, EF und nur zwei AF zuzuweisen.
Klasse DF (oder BE) kennzeichnet absolut anspruchslosen Verkehr - er erhält Restaufmerksamkeit.PHB AF dient den Klassen AF1, AF2, AF3, AF4. Sie alle müssen eine Fahrspur zum Nachteil von Verzögerungen und Verlusten bereitstellen. Verluste werden durch die Drop Precedence-Bits gesteuert, weshalb sie als AFxy bezeichnet werden, wobei x die Serviceklasse und y Drop Precedence ist.EF benötigt eine Art Mindestbandgarantie, aber was noch wichtiger ist - eine Garantie für Verzögerungen, Jitter und keinen Verlust.CS6, CS7 benötigen noch weniger Bandbreite, da dies eine Vielzahl von Servicepaketen ist, bei denen Bursts noch möglich sind (z. B. BGP-Update), Verluste und Verzögerungen jedoch nicht akzeptabel sind - was ist die Verwendung von BFD mit einem Timer von 10 ms, wenn Hello abstürzt 100 ms Warteschlangen?Das heißt, 4 von 8 verfügbaren Klassen wurden unter AF angegeben.Und trotz der Tatsache, dass sie normalerweise genau das tun, wiederhole ich, dass dies nur Empfehlungen sind und nichts drei Klassen in Ihrer DS-Domäne daran hindert, EF und nur zwei AF zuzuweisen.
Klassifizierungszusammenfassung
Am Eingang eines Knotens wird ein Paket anhand einer Schnittstelle, eines MF oder seiner Kennzeichnung (BA) klassifiziert.Beschriftung ist der Wert der DSCP-Felder in IPv4, der Verkehrsklasse in IPv6 und in MPLS oder 802.1p in 802.1q.Es gibt 8 Dienstklassen, die verschiedene Verkehrskategorien zusammenfassen. Jeder Klasse wird ein eigener PHB zugewiesen, der die Anforderungen der Klasse erfüllt.Gemäß den IETF-Empfehlungen werden die folgenden Serviceklassen unterschieden: CS1, CS0, AF11, AF12, AF13, AF21, CS2, AF22, AF23, CS3, AF31, AF32, AF33, CS4, AF41, AF42, AF43, CS5, EF, CS6, CS7 in zunehmender Bedeutung des Verkehrs.Aus ihnen können Sie eine Kombination von 8 auswählen, die tatsächlich in CoS-Felder codiert werden kann.Die häufigste Kombination: CS0, AF1, AF2, AF3, AF4, EF, CS6, CS7 mit 3 Farbabstufungen für AF.Jeder Klasse ist ein PHB zugeordnet, von denen es 3 gibt - Standardweiterleitung, versicherte Weiterleitung, beschleunigte Weiterleitung in aufsteigender Reihenfolge des Schweregrads. Ein bisschen beiseite ist der PHB Class Selector. Jeder PHB kann je nach Werkzeugparameter variieren, aber dazu später mehr.
In einem entladenen Netzwerk sei QoS nicht erforderlich. Alle QoS-Probleme werden durch Erweitern der Links behoben. Mit Ethernet und DWDM sei es nie zu einer Überlastung der Leitungen gekommen.Sie sind diejenigen, die nicht verstehen, was QoS ist.Aber die Realität trifft VPN auf ILV.- Nicht überall gibt es Optik. RRL ist unsere Realität. Manchmal möchte zum Zeitpunkt des Unfalls (und nicht nur) in der engen Funkverbindung der gesamte Netzwerkverkehr gecrawlt werden.
- Verkehrsstöße sind unsere Realität. Kurzfristige Verkehrsstöße stellen sich leicht in Warteschlangen und zwingen dazu, die sehr notwendigen Pakete zu verwerfen.
- Telefonie, Videokonferenzen und Online-Spiele sind unsere Realität. Wenn die Warteschlange zumindest etwas besetzt ist, beginnen Verzögerungen zu tanzen.
In meiner Praxis gab es Beispiele, bei denen aus Telefonie in einem Netzwerk, das zu nicht mehr als 40% ausgelastet war, Morsecode wurde. Durch erneutes Markieren in EF wurde das Problem vorübergehend behoben.
Es ist Zeit, sich mit Tools zu befassen, mit denen Sie verschiedene Dienste für verschiedene Klassen bereitstellen können.
PHB Tools
Es gibt tatsächlich nur drei Gruppen von QoS-Tools, die Pakete aktiv manipulieren:- Vermeidung von Überlastungen - was tun, um nicht schlecht zu sein?
- Überlastungsmanagement - was tun, wenn es schon schlecht ist?
- Ratenbegrenzung - wie Sie nicht mehr in das Netzwerk stellen, als es sein sollte, und nicht so viel veröffentlichen, wie sie nicht akzeptieren können.
Aber im Großen und Ganzen wären sie alle nutzlos, wenn es nicht die Warteschlange gäbe.5. Warteschlangen
Im Vergnügungspark können Sie niemandem Priorität einräumen, wenn Sie keine separate Warteschlange für diejenigen organisieren, die mehr bezahlt haben.Die gleiche Situation in den Netzwerken.Wenn sich der gesamte Datenverkehr in einer Warteschlange befindet, können Sie wichtige Pakete nicht aus der Mitte herausziehen, um ihnen Priorität einzuräumen.Aus diesem Grund werden nach der Klassifizierung Pakete in die dieser Klasse entsprechende Warteschlange gestellt.Und dann bewegt sich eine Warteschlange (mit Sprachdaten) schnell, aber mit einem begrenzten Band, eine andere langsamer (Streaming), aber mit einem breiten Band, und einige Ressourcen werden nach dem Restprinzip betrieben.Innerhalb der Grenzen jeder einzelnen Warteschlange gilt jedoch dieselbe Regel - Sie können ein Paket nicht aus der Mitte ziehen - nur aus dem Kopf.Jede Warteschlange hat eine bestimmte begrenzte Länge. Dies wird einerseits durch Hardwareeinschränkungen bestimmt, andererseits macht es keinen Sinn, Pakete zu lange in der Warteschlange zu halten. Ein VoIP-Paket wird nicht benötigt, wenn es um 200 ms verzögert wird. TCP fordert die Weiterleitung unter bestimmten Bedingungen an, nachdem die RTT abgelaufen ist (konfiguriert in sysctl). Daher ist das Fallenlassen nicht immer schlecht.Entwickler und Designer von Netzwerkgeräten müssen einen Kompromiss zwischen den Versuchen finden, das Paket so lange wie möglich zu speichern, und im Gegenteil, um Bandbreitenverschwendung zu vermeiden und das Paket zu liefern, das nicht mehr benötigt wird.In einer normalen Situation, wenn die Schnittstelle / der Chip nicht überlastet ist, ist die Pufferauslastung nahe Null. Sie absorbieren kurzfristige Ausbrüche, dies führt jedoch nicht zu einer längeren Füllung.Wenn mehr Verkehr vorhanden ist, als der Vermittlungs-Chip oder die Ausgabeschnittstelle verarbeiten können, füllen sich die Warteschlangen. Und eine chronische Auslastung von über 20-30% ist bereits eine Situation, die angegangen werden muss.
6. Vermeidung von Überlastungen
Im Leben eines Routers kommt eine Zeit, in der die Warteschlange voll ist. Wo das Paket abgelegt werden soll, wenn es definitiv keinen Ort gibt, an dem es abgelegt werden kann - das ist alles, der Puffer ist vorbei und es wird nicht da sein, selbst wenn es gut aussieht, selbst wenn Sie extra bezahlen.Es gibt zwei Möglichkeiten: entweder dieses Paket zu verwerfen oder diejenigen, die bereits den Zug erzielt haben.Wenn sich diese bereits in der Warteschlange befinden, prüfen Sie, was fehlt.Und wenn dieser, dann denken Sie daran, dass er nicht gekommen ist.Diese beiden Ansätze werden als Tail Drop und Head Drop bezeichnet .Tail Drop und Head Drop
Tail Drop - der einfachste Mechanismus zur Warteschlangenverwaltung - verwirft alle neu angekommenen Pakete, die nicht in den Puffer passen. Head Drop verwirft Pakete, die sich schon sehr lange in der Warteschlange befinden. Es ist besser, sie wegzuwerfen als zu retten, da sie höchstwahrscheinlich nutzlos sind. Die relevanteren Pakete, die am Ende der Warteschlange eingetroffen sind, haben jedoch mehr Chancen, pünktlich anzukommen. Außerdem können Sie mit Head Drop das Netzwerk nicht mit unnötigen Paketen laden. Natürlich sind die ältesten Pakete diejenigen, die sich im Kopf der Warteschlange befinden, daher der Name des Ansatzes.
Head Drop verwirft Pakete, die sich schon sehr lange in der Warteschlange befinden. Es ist besser, sie wegzuwerfen als zu retten, da sie höchstwahrscheinlich nutzlos sind. Die relevanteren Pakete, die am Ende der Warteschlange eingetroffen sind, haben jedoch mehr Chancen, pünktlich anzukommen. Außerdem können Sie mit Head Drop das Netzwerk nicht mit unnötigen Paketen laden. Natürlich sind die ältesten Pakete diejenigen, die sich im Kopf der Warteschlange befinden, daher der Name des Ansatzes. Head Drop hat einen weiteren nicht offensichtlichen Vorteil: Wenn Sie das Paket am Anfang der Warteschlange ablegen, wird der Empfänger schnell über die Überlastung im Netzwerk informiert und den Absender informieren. Im Fall von Tail Drop erreichen Informationen über das verworfene Paket möglicherweise Hunderte von Millisekunden später - bis sie vom Ende der Leitung zu ihrem Kopf gelangen.Beide Mechanismen arbeiten wiederum mit Differenzierung. Das heißt, es ist tatsächlich nicht erforderlich, dass der gesamte Puffer voll ist. Wenn die zweite Warteschlange leer ist und die Null für die Augäpfel, werden nur Pakete von der Null verworfen.
Head Drop hat einen weiteren nicht offensichtlichen Vorteil: Wenn Sie das Paket am Anfang der Warteschlange ablegen, wird der Empfänger schnell über die Überlastung im Netzwerk informiert und den Absender informieren. Im Fall von Tail Drop erreichen Informationen über das verworfene Paket möglicherweise Hunderte von Millisekunden später - bis sie vom Ende der Leitung zu ihrem Kopf gelangen.Beide Mechanismen arbeiten wiederum mit Differenzierung. Das heißt, es ist tatsächlich nicht erforderlich, dass der gesamte Puffer voll ist. Wenn die zweite Warteschlange leer ist und die Null für die Augäpfel, werden nur Pakete von der Null verworfen. Tail Drop und Head Drop können gleichzeitig arbeiten.
Tail Drop und Head Drop können gleichzeitig arbeiten.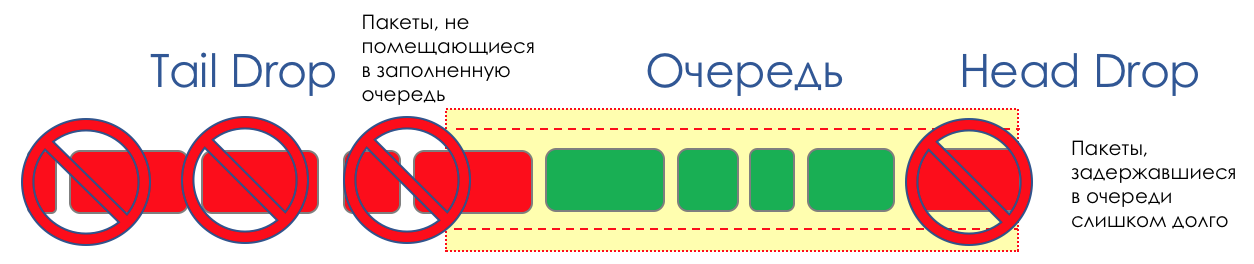
Schwanz und Kopf fallen sind Stauvermeidung "Stirn". Man kann sogar sagen - das ist seine Abwesenheit.Wir tun nichts, bis die Warteschlange zu 100% voll ist. Und danach beginnen wir, alle neu angekommenen (oder lange verzögerten) Pakete zu verwerfen.Wenn Sie nichts tun müssen, um das Ziel zu erreichen, gibt es irgendwo eine Nuance.Und diese Nuance ist TCP.Erinnern Sie sich ( tiefer und extrem tief ) daran, wie TCP funktioniert - wir sprechen über moderne Implementierungen.Es gibt ein Schiebefenster (Schiebefenster oder rwnd - Werbefenster des Empfängers), das der Empfänger steuert und dem Absender mitteilt, wie viel gesendet werden kann.Und es gibt ein Überlastungsfenster ( CWND - Congestion Window)), das auf Netzwerkprobleme reagiert und vom Absender gesteuert wird.Der Datenübertragungsprozess beginnt mit einem langsamen Start ( Slow Start ) mit einem exponentiellen Anstieg der CWND. Mit jedem bestätigten Segment wird dem CWND 1 MSS-Größe hinzugefügt, dh es verdoppelt sich tatsächlich in einer Zeit, die RTT entspricht (Daten dort, ACK zurück) (Rede über Reno / NewReno).Zum Beispiel
 Das exponentielle Wachstum setzt sich bis zu einem Wert fort, der als ssthreshold (Slow Start Threshold) bezeichnet wird und in der TCP-Konfiguration auf dem Host angegeben ist.Als nächstes beginnt für jedes bestätigte Segment ein lineares Wachstum von 1 / CWND, bis es entweder gegen RWND anliegt oder Verluste beginnen (Verlust wird durch erneute Bestätigung (Duplicated ACK) oder überhaupt keine Bestätigung bestätigt).Sobald ein Segmentverlust erkannt wird, tritt ein TCP-Backoff auf - TCP reduziert das Fenster drastisch, wodurch die Sendegeschwindigkeit tatsächlich verringert wird - und der Mechanismus für die schnelle Wiederherstellung wird gestartet :
Das exponentielle Wachstum setzt sich bis zu einem Wert fort, der als ssthreshold (Slow Start Threshold) bezeichnet wird und in der TCP-Konfiguration auf dem Host angegeben ist.Als nächstes beginnt für jedes bestätigte Segment ein lineares Wachstum von 1 / CWND, bis es entweder gegen RWND anliegt oder Verluste beginnen (Verlust wird durch erneute Bestätigung (Duplicated ACK) oder überhaupt keine Bestätigung bestätigt).Sobald ein Segmentverlust erkannt wird, tritt ein TCP-Backoff auf - TCP reduziert das Fenster drastisch, wodurch die Sendegeschwindigkeit tatsächlich verringert wird - und der Mechanismus für die schnelle Wiederherstellung wird gestartet :- verlorene Segmente senden (Fast Retransmission),
- das Fenster ist verdoppelt,
- Der Schwellenwert wird auch gleich der Hälfte des erreichten Fensters.
- Das lineare Wachstum beginnt wieder bis zum ersten Verlust.
- Wiederholen.
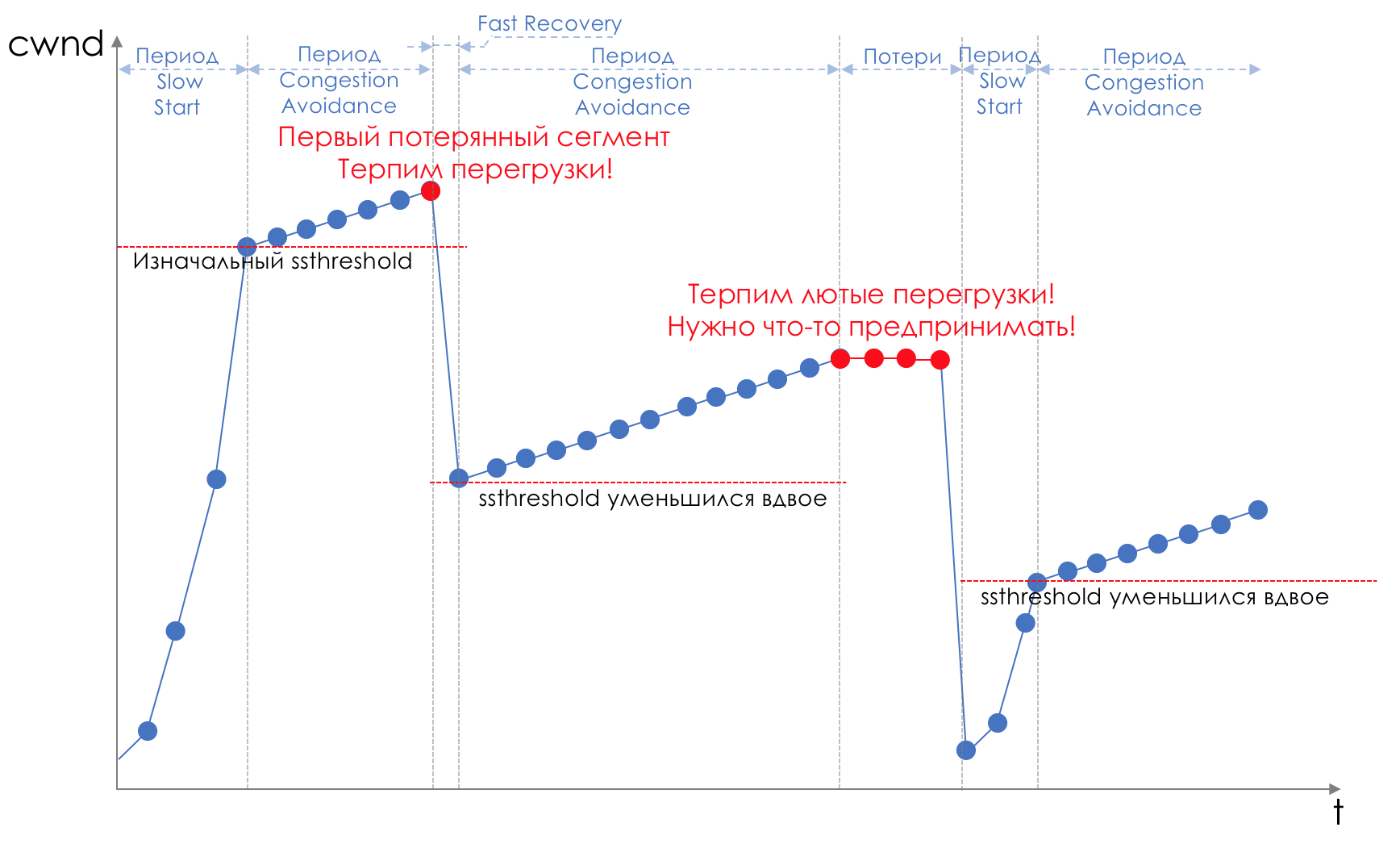 Verlust kann entweder den vollständigen Zusammenbruch eines Netzwerksegments bedeuten und dann als verloren betrachtet werden oder eine Überlastung der Leitung (Lesepufferüberlauf und Verwerfen eines Segments dieser Sitzung).Dies ist die Methode von TCP zur Maximierung der Nutzung der verfügbaren Bandbreite und zur Bewältigung von Überlastungen. Und es ist sehr effektiv.Was führt Tail Drop jedoch dazu?
Verlust kann entweder den vollständigen Zusammenbruch eines Netzwerksegments bedeuten und dann als verloren betrachtet werden oder eine Überlastung der Leitung (Lesepufferüberlauf und Verwerfen eines Segments dieser Sitzung).Dies ist die Methode von TCP zur Maximierung der Nutzung der verfügbaren Bandbreite und zur Bewältigung von Überlastungen. Und es ist sehr effektiv.Was führt Tail Drop jedoch dazu?- Angenommen, über einen Router liegt der Pfad von Tausenden von TCP-Sitzungen. Irgendwann erreichte der Sitzungsverkehr 1,1 Gbit / s, die Geschwindigkeit der Ausgabeschnittstelle 1 Gbit / s.
- Der Verkehr kommt schneller als er geht, Puffer füllen sich .
- Tail Drop wird aktiviert, bis der Dispatcher einige Pakete aus der Warteschlange entfernt.
- Fast Recovery ( Slow Start).
- , , Tail Drop .
- TCP- , .
- .
- Fast Recovery/Slow Start.
- .
Weitere Informationen zu Änderungen an TCP-Mechanismen finden Sie in RFC 2001 ( Algorithmen für langsamen Start von TCP, Vermeidung von Überlastungen, schnelle erneute Übertragung und schnelle Wiederherstellung ).Dies ist ein typisches Beispiel für eine Situation namens Global TCP Synchronization : Global, da viele über diesen Knoten eingerichtete Sitzungen darunter leiden.Synchronisation , weil sie gleichzeitig leiden. Und die Situation wird wiederholt, bis eine Überlastung vorliegt.TCP - weil UDP, das keine Überlastungskontrollmechanismen hat, davon nicht betroffen ist.In dieser Situation wäre nichts Schlimmes passiert, wenn nicht die nicht optimale Nutzung des Streifens - die Lücken zwischen den Sägezähnen - das verschwendete Geld verursacht worden wäre.Das zweite Problem ist TCP Starvation - TCP Depletion. Während TCP langsamer wird, um die Last zu reduzieren (seien wir nicht schlau - vor allem, um unsere Daten sicher zu übertragen), sendet UDP, all dieses moralische Leid im Allgemeinen durch das Datagramm, so viel wie möglich.Dadurch wird der TCP-Datenverkehr reduziert und UDP wächst (möglicherweise). Der nächste Zyklus von Loss - Fast Recovery erfolgt bei einem niedrigeren Schwellenwert. UDP nimmt Platz ein. Die Gesamtmenge des TCP-Verkehrs sinkt.Wie man das Problem löst, ist es besser, es zu vermeiden. Versuchen wir, die Last zu reduzieren, bevor sie die Warteschlange mit der schnellen Wiederherstellung / dem langsamen Start füllt, die gerade gegen uns war.
Global, da viele über diesen Knoten eingerichtete Sitzungen darunter leiden.Synchronisation , weil sie gleichzeitig leiden. Und die Situation wird wiederholt, bis eine Überlastung vorliegt.TCP - weil UDP, das keine Überlastungskontrollmechanismen hat, davon nicht betroffen ist.In dieser Situation wäre nichts Schlimmes passiert, wenn nicht die nicht optimale Nutzung des Streifens - die Lücken zwischen den Sägezähnen - das verschwendete Geld verursacht worden wäre.Das zweite Problem ist TCP Starvation - TCP Depletion. Während TCP langsamer wird, um die Last zu reduzieren (seien wir nicht schlau - vor allem, um unsere Daten sicher zu übertragen), sendet UDP, all dieses moralische Leid im Allgemeinen durch das Datagramm, so viel wie möglich.Dadurch wird der TCP-Datenverkehr reduziert und UDP wächst (möglicherweise). Der nächste Zyklus von Loss - Fast Recovery erfolgt bei einem niedrigeren Schwellenwert. UDP nimmt Platz ein. Die Gesamtmenge des TCP-Verkehrs sinkt.Wie man das Problem löst, ist es besser, es zu vermeiden. Versuchen wir, die Last zu reduzieren, bevor sie die Warteschlange mit der schnellen Wiederherstellung / dem langsamen Start füllt, die gerade gegen uns war.ROT - Zufällige Früherkennung
Aber was ist, wenn wir Tropfen auf einen Teil des Puffers nehmen und verschmieren?Beginnen Sie relativ gesehen damit, zufällige Pakete zu verwerfen, wenn die Warteschlange zu 80% voll ist, und zwingen Sie einige TCP-Sitzungen, das Fenster und dementsprechend die Geschwindigkeit zu verringern.Und wenn die Warteschlange zu 90% voll ist, werden zufällig 50% der Pakete verworfen.90% - Die Wahrscheinlichkeit steigt auf Tail Drop (100% der neuen Pakete werden verworfen).Die Mechanismen, die eine solche Warteschlangenverwaltung implementieren, werden als AQM - Adaptive (oder Active) Queue Management bezeichnet.So funktioniert RED .Früherkennung - mögliche Überlastung beheben;Zufällig - Pakete werden zufällig verworfen.Manchmal dekodieren sie ROT (meiner Meinung nach semantisch korrekter), wie Random Early Discard.Grafisch sieht es so aus: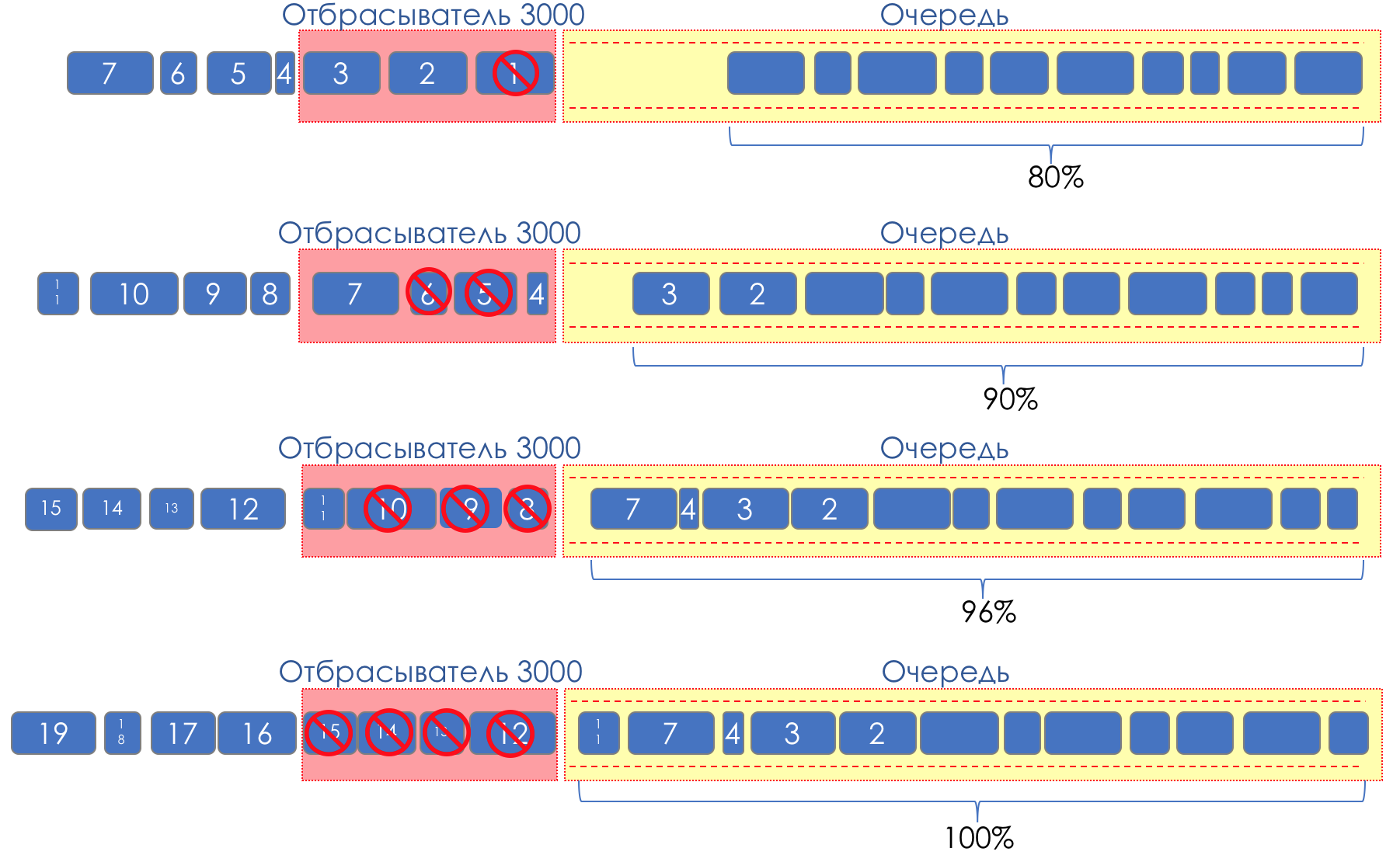
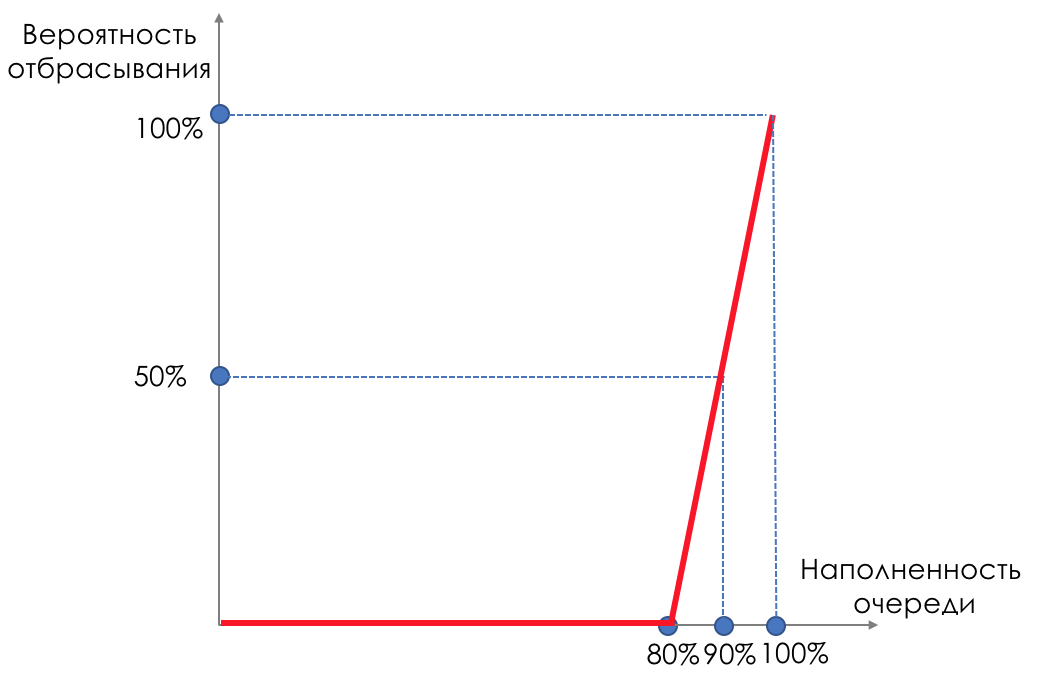 Bis der Puffer zu 80% voll ist, werden Pakete überhaupt nicht verworfen - die Wahrscheinlichkeit beträgt 0%.80 bis 100 Pakete werden verworfen, und je mehr, desto höher die Warteschlangenfüllung.Der Prozentsatz steigt also von 0 auf 30.Ein Nebeneffekt von RED ist, dass aggressive TCP-Sitzungen eher langsamer werden, einfach weil es viele Pakete gibt und sie eher verworfen werden.Die Ineffizienz bei der Verwendung des ROTEN Streifens wird behoben, indem ein viel kleinerer Teil der Sitzungen abgestumpft wird, ohne dass ein so schwerwiegender Druck zwischen den Zähnen auftritt.Genau aus dem gleichen Grund kann UDP nicht alles besetzen.
Bis der Puffer zu 80% voll ist, werden Pakete überhaupt nicht verworfen - die Wahrscheinlichkeit beträgt 0%.80 bis 100 Pakete werden verworfen, und je mehr, desto höher die Warteschlangenfüllung.Der Prozentsatz steigt also von 0 auf 30.Ein Nebeneffekt von RED ist, dass aggressive TCP-Sitzungen eher langsamer werden, einfach weil es viele Pakete gibt und sie eher verworfen werden.Die Ineffizienz bei der Verwendung des ROTEN Streifens wird behoben, indem ein viel kleinerer Teil der Sitzungen abgestumpft wird, ohne dass ein so schwerwiegender Druck zwischen den Zähnen auftritt.Genau aus dem gleichen Grund kann UDP nicht alles besetzen.WRED - Gewichtete zufällige Früherkennung
Aber bei der Anhörung von allen wahrscheinlich noch WRED . Der kluge Leser von Linkmeup hat bereits vorgeschlagen, dass dies das gleiche ROT ist, aber abwechselnd gewichtet. Und er hatte nicht ganz recht.RED arbeitet in derselben Warteschlange. Es macht keinen Sinn, auf EF zurückzublicken, wenn das BE voll ist. Dementsprechend bringt das Abwiegen nichts.Hier funktioniert Drop Precedence einfach.Und innerhalb derselben Warteschlange haben Pakete mit unterschiedlicher Drop-Priorität unterschiedliche Kurven. Je niedriger die Priorität, desto wahrscheinlicher ist es, dass sie zugeschlagen wird. Hier gibt es drei Kurven:Rot - Verkehr mit geringerer Priorität (in Bezug auf das Fallenlassen), Gelb - mehr, Grün - Maximum.Roter Verkehr wird verworfen, wenn der Puffer zu 20% voll ist. Von 20 auf 40 sinkt er auf 20% und dann auf Tail Drop.Gelb beginnt später - von 30 bis 50 wird es bis zu 10% verworfen, dann - Tail Drop.Grün ist am wenigsten anfällig: von 50 bis 100 wächst es sanft auf 5%. Als nächstes kommt Tail Drop.Im Fall von DSCP kann dies AF11, AF12 und AF13 sein, jeweils grün, gelb und rot.
Hier gibt es drei Kurven:Rot - Verkehr mit geringerer Priorität (in Bezug auf das Fallenlassen), Gelb - mehr, Grün - Maximum.Roter Verkehr wird verworfen, wenn der Puffer zu 20% voll ist. Von 20 auf 40 sinkt er auf 20% und dann auf Tail Drop.Gelb beginnt später - von 30 bis 50 wird es bis zu 10% verworfen, dann - Tail Drop.Grün ist am wenigsten anfällig: von 50 bis 100 wächst es sanft auf 5%. Als nächstes kommt Tail Drop.Im Fall von DSCP kann dies AF11, AF12 und AF13 sein, jeweils grün, gelb und rot. Hier ist es sehr wichtig, dass es mit TCP funktioniert und absolut nicht auf UDP anwendbar ist.Oder eine Anwendung, die UDP verwendet, ignoriert Verluste, wie im Fall von Telefonie oder Video-Streaming, und dies wirkt sich negativ auf das aus, was der Benutzer sieht.Oder die Anwendung selbst steuert die Zustellung und fordert Sie auf, dasselbe Paket erneut zu senden. Die Quelle muss jedoch nicht aufgefordert werden, die Übertragungsrate zu senken. Und anstatt die Last zu reduzieren, ist eine Erhöhung auf erneute Übertragungen zurückzuführen.Deshalb wird für EF nur Tail Drop verwendet.Für CS6, CS7 wird auch Tail Drop verwendet, da keine hohen Geschwindigkeiten angenommen werden und WRED nichts löst.Für AF wird WRED angewendet. AFxy, wobei x die Klasse des Dienstes ist, dh die Warteschlange, in die er fällt, und y die Ablagepriorität ist - dieselbe Farbe.Für BE wird die Entscheidung basierend auf dem vorherrschenden Verkehr in dieser Warteschlange getroffen.Innerhalb eines einzelnen Routers wird eine spezielle interne Paketkennzeichnung verwendet, die sich von der unterscheidet, die die Header enthält. Daher können MPLS und 802.1q, bei denen die Drop-Priorität nicht codiert werden kann, in Warteschlangen mit unterschiedlichen Drop-Prioritäten verarbeitet werden.Beispielsweise kam ein MPLS-Paket zu einem Knoten, trägt keine Drop-Precedence-Kennzeichnung, stellte sich jedoch nach den Ergebnissen des Polierens als gelb heraus und kann verworfen werden, bevor es in die Warteschlange gestellt wird (was durch das Feld Verkehrsklasse bestimmt werden kann).Es sei daran erinnert, dass dieser ganze Regenbogen nur innerhalb des Knotens existiert. Es gibt kein Konzept von Farbe in der Linie zwischen Nachbarn.Obwohl es natürlich möglich ist, Farben im Drop Precedence-Teil von DSCP zu codieren.
Hier ist es sehr wichtig, dass es mit TCP funktioniert und absolut nicht auf UDP anwendbar ist.Oder eine Anwendung, die UDP verwendet, ignoriert Verluste, wie im Fall von Telefonie oder Video-Streaming, und dies wirkt sich negativ auf das aus, was der Benutzer sieht.Oder die Anwendung selbst steuert die Zustellung und fordert Sie auf, dasselbe Paket erneut zu senden. Die Quelle muss jedoch nicht aufgefordert werden, die Übertragungsrate zu senken. Und anstatt die Last zu reduzieren, ist eine Erhöhung auf erneute Übertragungen zurückzuführen.Deshalb wird für EF nur Tail Drop verwendet.Für CS6, CS7 wird auch Tail Drop verwendet, da keine hohen Geschwindigkeiten angenommen werden und WRED nichts löst.Für AF wird WRED angewendet. AFxy, wobei x die Klasse des Dienstes ist, dh die Warteschlange, in die er fällt, und y die Ablagepriorität ist - dieselbe Farbe.Für BE wird die Entscheidung basierend auf dem vorherrschenden Verkehr in dieser Warteschlange getroffen.Innerhalb eines einzelnen Routers wird eine spezielle interne Paketkennzeichnung verwendet, die sich von der unterscheidet, die die Header enthält. Daher können MPLS und 802.1q, bei denen die Drop-Priorität nicht codiert werden kann, in Warteschlangen mit unterschiedlichen Drop-Prioritäten verarbeitet werden.Beispielsweise kam ein MPLS-Paket zu einem Knoten, trägt keine Drop-Precedence-Kennzeichnung, stellte sich jedoch nach den Ergebnissen des Polierens als gelb heraus und kann verworfen werden, bevor es in die Warteschlange gestellt wird (was durch das Feld Verkehrsklasse bestimmt werden kann).Es sei daran erinnert, dass dieser ganze Regenbogen nur innerhalb des Knotens existiert. Es gibt kein Konzept von Farbe in der Linie zwischen Nachbarn.Obwohl es natürlich möglich ist, Farben im Drop Precedence-Teil von DSCP zu codieren.Drops können auch in einem entladenen Netzwerk auftreten, in dem anscheinend kein Warteschlangenüberlauf auftreten sollte. Wie?
Der Grund dafür können kurze Verkehrsstöße sein. Das einfachste Beispiel - 5 Anwendungen gleichzeitig haben beschlossen, Datenverkehr auf einen Endhost zu übertragen.
Ein Beispiel ist komplizierter: Der Sender ist über die 10-Gbit / s-Schnittstelle verbunden und der Empfänger ist 1 Gbit / s. In der Umgebung selbst können Sie Pakete schneller auf dem Absender erstellen. Die Ethernet-Flusskontrolle des Empfängers fordert den nächsten Host auf, langsamer zu werden, und Pakete sammeln sich in den Puffern an.
Was tun, wenn alles schlimmer wird?7. Überlastungsmanagement
Wenn alles schlecht ist, sollte wichtigerem Verkehr die Verarbeitungspriorität eingeräumt werden. Die Wichtigkeit jedes Pakets wird in der Klassifizierungsphase bestimmt.Aber was ist schlecht?Nicht alle Puffer müssen verstopft sein, damit bei Anwendungen Probleme auftreten.Das einfachste Beispiel sind Sprachpakete, die sich um große Pakete großer Pakete einer Anwendung drängen, die eine Datei herunterlädt.Dies erhöht die Verzögerung, ruiniert den Jitter und verursacht möglicherweise Tropfen.Das heißt, wir haben Probleme mit der Bereitstellung hochwertiger Dienstleistungen, wenn keine tatsächliche Überlastung vorliegt.Dieses Problem soll den Mechanismus der Überlastungsverwaltung lösen.Der Datenverkehr verschiedener Anwendungen ist, wie oben gesehen, in Warteschlangen unterteilt.Aber nur deshalb sollte alles wieder zu einer Schnittstelle verschmelzen. Die Serialisierung erfolgt weiterhin nacheinander.Wie schaffen es verschiedene Warteschlangen, unterschiedliche Dienstebenen bereitzustellen?Entfernen Sie Pakete unterschiedlich aus verschiedenen Warteschlangen.Der Dispatcher ist damit beschäftigt.Wir werden heute die Mehrheit der Disponenten betrachten, beginnend mit den einfachsten:- FIFO - nur eine Zeile, alles in BE, C - Ungerechtigkeit.
- PQ - der Weg zu den Oligarchen, Lakaien geben nach.
- FQ - alle sind gleich.
- DWRR - alle sind gleich, aber einige sind gleichmäßiger.
FIFO - First In, First Out
Der einfachste Fall, in der Tat das Fehlen von QoS, ist, dass der gesamte Datenverkehr auf dieselbe Weise behandelt wird - in einer Warteschlange.Pakete verlassen die Warteschlange genau in der Reihenfolge, in der sie dort angekommen sind, daher der Name: zuerst eingegeben - zuerst und links .FIFO ist weder ein Dispatcher im wahrsten Sinne des Wortes noch ein DiffServ-Mechanismus im Allgemeinen, da es keine Klassen trennt.Wenn sich die Warteschlange füllt, Verzögerungen und Jitter zunehmen, können Sie sie nicht verwalten, da Sie kein wichtiges Paket aus der Mitte der Warteschlange ziehen können.Aggressive TCP-Sitzungen mit einer Paketgröße von 1.500 Byte können die gesamte Warteschlange belegen, wodurch kleine Sprachpakete leiden.Im FIFO werden alle Klassen in CS0 zusammengeführt. Trotz all dieser Mängel funktioniert das Internet jetzt so.Die meisten FIFO-Anbieter sind jetzt der Standard-Dispatcher mit einer Warteschlange für den gesamten Transitverkehr und einer weiteren für lokal generierte Servicepakete.Es ist einfach und extrem billig. Wenn die Kanäle breit sind und wenig Verkehr herrscht, ist alles in Ordnung.Die Quintessenz der Idee, dass QoS - für die Armen - das Band erweitert und die Kunden zufrieden sind und Ihr Gehalt um ein Vielfaches steigt.Nur so funktionierten Netzwerkgeräte einmal.Aber sehr bald wurde die Welt mit der Tatsache konfrontiert, dass es einfach nicht funktionieren würde.Mit dem Trend zu konvergierten Netzwerken wurde deutlich, dass verschiedene Arten von Verkehr (Dienst, Sprache, Multimedia, Surfen im Internet, Dateifreigabe) grundlegend unterschiedliche Netzwerkanforderungen haben.FIFO war nicht genug, daher erstellten sie mehrere Warteschlangen und begannen, Verkehrsplanungsschemata zu erstellen.FIFO verlässt jedoch nie unser Leben: In jeder Warteschlange werden Pakete immer nach dem FIFO-Prinzip verarbeitet.
Trotz all dieser Mängel funktioniert das Internet jetzt so.Die meisten FIFO-Anbieter sind jetzt der Standard-Dispatcher mit einer Warteschlange für den gesamten Transitverkehr und einer weiteren für lokal generierte Servicepakete.Es ist einfach und extrem billig. Wenn die Kanäle breit sind und wenig Verkehr herrscht, ist alles in Ordnung.Die Quintessenz der Idee, dass QoS - für die Armen - das Band erweitert und die Kunden zufrieden sind und Ihr Gehalt um ein Vielfaches steigt.Nur so funktionierten Netzwerkgeräte einmal.Aber sehr bald wurde die Welt mit der Tatsache konfrontiert, dass es einfach nicht funktionieren würde.Mit dem Trend zu konvergierten Netzwerken wurde deutlich, dass verschiedene Arten von Verkehr (Dienst, Sprache, Multimedia, Surfen im Internet, Dateifreigabe) grundlegend unterschiedliche Netzwerkanforderungen haben.FIFO war nicht genug, daher erstellten sie mehrere Warteschlangen und begannen, Verkehrsplanungsschemata zu erstellen.FIFO verlässt jedoch nie unser Leben: In jeder Warteschlange werden Pakete immer nach dem FIFO-Prinzip verarbeitet.PQ - Priority Queuing
Der zweitkomplizierteste Mechanismus und Versuch, den Dienst in Klassen zu unterteilen, ist eine Prioritätswarteschlange .Der Datenverkehr wird jetzt in mehreren Warteschlangen entsprechend seiner Klassenpriorität angeordnet (z. B., obwohl nicht unbedingt, dasselbe BE, AF1-4, EF, CS6-7). Der Dispatcher durchläuft eine Warteschlange nach der anderen.Zuerst werden alle Pakete aus der Warteschlange mit der höchsten Priorität übersprungen, dann von weniger und dann von weniger. Und so im Kreis.
Der Dispatcher beginnt erst mit dem Abrufen von Paketen mit niedriger Priorität, wenn die Warteschlange mit hoher Priorität leer ist. Wenn zum Zeitpunkt der Verarbeitung von Paketen mit niedriger Priorität ein Paket in einer Warteschlange mit höherer Priorität ankommt, wechselt der Dispatcher zu dieser und kehrt erst nach dem Entleeren zu den anderen zurück.
Wenn zum Zeitpunkt der Verarbeitung von Paketen mit niedriger Priorität ein Paket in einer Warteschlange mit höherer Priorität ankommt, wechselt der Dispatcher zu dieser und kehrt erst nach dem Entleeren zu den anderen zurück. PQ funktioniert fast so gut wie FIFO.Es eignet sich hervorragend für Verkehrstypen wie Protokollpakete und Sprache, bei denen Verzögerungen kritisch sind und das Gesamtvolumen nicht sehr groß ist.Nun, Sie müssen zugeben, Sie sollten BFD Hello nicht behalten, da mehrere große Video-Chunks von YouTube gekommen sind.Aber hier liegt das Fehlen von PQ - wenn die Prioritätswarteschlange mit Verkehr geladen ist, wird der Dispatcher niemals zu anderen wechseln.Und wenn ein Doktor Evil auf der Suche nach Methoden zur Eroberung der Welt beschließt, seinen gesamten bösartigen Verkehr mit der höchsten schwarzen Markierung zu markieren, werden alle anderen pflichtbewusst warten und dann verworfen werden.Es ist auch nicht erforderlich, für jede Linie über eine garantierte Fahrspur zu sprechen.Warteschlangen mit hoher Priorität können durch die Geschwindigkeit des in ihnen verarbeiteten Datenverkehrs gekürzt werden. Dann werden andere nicht verhungern. Dies zu kontrollieren ist jedoch nicht einfach.
PQ funktioniert fast so gut wie FIFO.Es eignet sich hervorragend für Verkehrstypen wie Protokollpakete und Sprache, bei denen Verzögerungen kritisch sind und das Gesamtvolumen nicht sehr groß ist.Nun, Sie müssen zugeben, Sie sollten BFD Hello nicht behalten, da mehrere große Video-Chunks von YouTube gekommen sind.Aber hier liegt das Fehlen von PQ - wenn die Prioritätswarteschlange mit Verkehr geladen ist, wird der Dispatcher niemals zu anderen wechseln.Und wenn ein Doktor Evil auf der Suche nach Methoden zur Eroberung der Welt beschließt, seinen gesamten bösartigen Verkehr mit der höchsten schwarzen Markierung zu markieren, werden alle anderen pflichtbewusst warten und dann verworfen werden.Es ist auch nicht erforderlich, für jede Linie über eine garantierte Fahrspur zu sprechen.Warteschlangen mit hoher Priorität können durch die Geschwindigkeit des in ihnen verarbeiteten Datenverkehrs gekürzt werden. Dann werden andere nicht verhungern. Dies zu kontrollieren ist jedoch nicht einfach.
Die folgenden Mechanismen durchlaufen nacheinander alle Warteschlangen und entnehmen ihnen eine bestimmte Datenmenge, um ehrlichere Bedingungen zu schaffen. Aber sie machen es anders.FQ-Fair Queuing
Der nächste Anwärter auf die Rolle eines idealen Dispatchers sind faire Warteschlangenmechanismen .FQ - Fair Queuing
Seine Geschichte begann 1985, als John Nagle vorschlug, für jeden Datenstrom eine Warteschlange zu erstellen. Im Geiste liegt dies nahe am IntServ-Ansatz und lässt sich leicht dadurch erklären, dass die Idee von Serviceklassen wie DiffServ damals nicht existierte.FQ extrahierte die gleiche Datenmenge nacheinander aus jeder Warteschlange.Ehrlichkeit liegt in der Tatsache, dass der Dispatcher nicht mit der Anzahl der Pakete arbeitet, sondern mit der Anzahl der Bits , die von jeder Warteschlange übertragen werden können.Ein aggressiver TCP-Stream kann die Schnittstelle also nicht überfluten, und alle erhalten gleiche Chancen.In der Theorie. FQ wurde in der Praxis nie als Mechanismus zum Versenden von Warteschlangen in Netzwerkgeräten implementiert.Es gibt drei Nachteile:Das erste - offensichtlich - es ist sehr teuer - eine Warteschlange für jeden Stream zu starten, das Gewicht jedes Pakets zu zählen und sich immer um die zu überspringenden Bits und die Größe des Pakets zu kümmern.Das zweite - weniger offensichtliche - alle Threads erhalten gleiche Chancen in Bezug auf die Bandbreite. Und wenn ich ungleich will?Die dritte - nicht offensichtliche - FQ-Ehrlichkeit ist absolut: Jeder hat gleiche Verzögerungen, aber es gibt Themen, die wichtiger sind als die Verzögerung als die Band.Unter 256 Streams gibt es beispielsweise Sprach-Streams, was bedeutet, dass jeder von ihnen nur 256 Threads erreicht.Und was mit ihnen zu tun ist, ist unklar. Hier können Sie sehen, dass wir aufgrund der Größe des Pakets in der 3. Stufe in den ersten beiden Zyklen ein Paket aus den ersten beiden verarbeitet haben.Die Beschreibung der bitweisen Mechanismen von Round Robin und GPS geht bereits über den Rahmen dieses Artikels hinaus, und ich verweise den Leser auf eine unabhängige Studie .
Hier können Sie sehen, dass wir aufgrund der Größe des Pakets in der 3. Stufe in den ersten beiden Zyklen ein Paket aus den ersten beiden verarbeitet haben.Die Beschreibung der bitweisen Mechanismen von Round Robin und GPS geht bereits über den Rahmen dieses Artikels hinaus, und ich verweise den Leser auf eine unabhängige Studie .WFQ - Weighted Fair Queuing
Der zweite und teilweise dritte Fehler des FQ versuchte, den 1989 veröffentlichten WFQ zu schließen.Jede Warteschlange war mit Gewicht und dementsprechend mit dem Recht ausgestattet, Verkehr in Vielfachen des Gewichts pro Zyklus zu geben.Das Gewicht wurde auf der Grundlage von zwei Parametern berechnet: noch relevant dann IP-Vorrang und die Paketlänge.Im Zusammenhang mit WFQ gilt: Je mehr Gewicht, desto schlechter.Je höher die IP-Priorität ist, desto geringer ist daher das Paketgewicht.Je kleiner die Packungsgröße ist, desto geringer ist das Gewicht.Somit erhalten kleine Pakete mit hoher Priorität die meisten Ressourcen, während Riesen mit niedriger Priorität warten.In der folgenden Abbildung haben Pakete solche Gewichte empfangen, dass zuerst ein Paket aus der ersten Warteschlange übersprungen wird, dann zwei aus der zweiten, erneut aus der ersten und erst dann das dritte. So könnte es beispielsweise passieren, wenn die Größe der Pakete in der zweiten Stufe relativ klein ist. Über die harte Technik von WFQ mit seiner Paketendzeit, virtuellen Zeit und dem Perückensatz können Sie in einem merkwürdigen Farbdokument lesen .Dies löste jedoch nicht das erste und dritte Problem. Der Flow-basierte Ansatz war ebenso unpraktisch, und die Flows, die kurze Verzögerungen und stabilen Jitter benötigten, erhielten sie nicht.Dies hinderte WFQ jedoch nicht daran, in einigen (meist alten) Cisco-Geräten verwendet zu werden. Es gab bis zu 256 Warteschlangen, in denen Threads basierend auf dem Hash ihrer Header platziert wurden. Ein Kompromiss zwischen dem Flow-basierten Paradigma und begrenzten Ressourcen.
Über die harte Technik von WFQ mit seiner Paketendzeit, virtuellen Zeit und dem Perückensatz können Sie in einem merkwürdigen Farbdokument lesen .Dies löste jedoch nicht das erste und dritte Problem. Der Flow-basierte Ansatz war ebenso unpraktisch, und die Flows, die kurze Verzögerungen und stabilen Jitter benötigten, erhielten sie nicht.Dies hinderte WFQ jedoch nicht daran, in einigen (meist alten) Cisco-Geräten verwendet zu werden. Es gab bis zu 256 Warteschlangen, in denen Threads basierend auf dem Hash ihrer Header platziert wurden. Ein Kompromiss zwischen dem Flow-basierten Paradigma und begrenzten Ressourcen.CBWFQ - Klassenbasiertes WFQ
CBWFQ hat mit dem Aufkommen von DiffServ den Ansatz für das Komplexitätsproblem gemacht. Behavior Aggregate klassifizierte alle Verkehrskategorien in 8 Klassen und dementsprechend in Warteschlangen. Dies gab ihm einen Namen und vereinfachte das Anstehen erheblich.Das Gewicht in CBWFQ hat eine andere Bedeutung erhalten. Das Gewicht wurde Klassen (nicht Threads) in der Konfiguration auf Anfrage des Administrators manuell zugewiesen , da das DSCP-Feld bereits für die Klassifizierung verwendet wurde.Das heißt, DSCP hat festgelegt, welche Warteschlange eingefügt werden soll, und das konfigurierte Gewicht - wie viele Spuren für diese Warteschlange verfügbar sind.Vor allem hat dies indirekt das Leben und die Abläufe mit geringer Latenz etwas erleichtert, die nun zu einer (zwei, drei, ...) Warteschlange zusammengefasst wurden und ihren Höhepunkt viel häufiger erhielten. Das Leben ist besser geworden, aber immer noch nicht gut - es gibt überhaupt keine Garantien - im Allgemeinen ist im WFQ alles in Bezug auf Verzögerungen immer noch gleich.Und die Notwendigkeit einer ständigen Überwachung der Größe von Paketen, ihrer Fragmentierung und Defragmentierung ist nicht verschwunden.CBWFQ + LLQ - Warteschlange mit geringer Latenz
Der letzte Ansatz, der Höhepunkt eines schrittweisen Ansatzes, ist die Vereinigung von CBWFQ mit PQ.Eine der Warteschlangen wird zur sogenannten LLQ (Warteschlange mit geringer Latenz), und während alle anderen Warteschlangen vom CBWFQ-Manager verarbeitet werden, wird der PQ-Manager zwischen den LLQs und den anderen ausgeführt.Das heißt, während sich Pakete in LLQ befinden, warten die verbleibenden Warteschlangen und ihre Verzögerungen nehmen zu. Sobald die Pakete in LLQ ausgegangen waren, gingen wir, um den Rest zu verarbeiten. Pakete erschienen in LLQ - sie vergaßen den Rest und kehrten dorthin zurück.FIFO funktioniert auch in LLQ, daher sollten Sie nicht alles verschieben, ohne dorthin zu gelangen, und gleichzeitig die Pufferauslastung und die Verzögerung erhöhen.Damit Warteschlangen ohne Priorität nicht verhungern, lohnt es sich jedoch, eine Bandbreitenbeschränkung in LLQ festzulegen. Die Schafe sind also voll und die Wölfe in Sicherheit.
Die Schafe sind also voll und die Wölfe in Sicherheit.RR - Round-Robin
Hand in Hand mit FQ ging und RR .Einer war ehrlich, aber nicht einfach. Der andere ist genau das Gegenteil. RR ging die Warteschlangen durch und extrahierte eine gleiche Anzahl von Paketen aus ihnen. Der Ansatz ist primitiver als FQ und daher in Bezug auf verschiedene Flüsse unehrlich. Aggressive Quellen können den Streifen leicht mit Paketen von 1500 Byte Größe überfluten.Die Implementierung war jedoch sehr einfach: Sie müssen die Größe des Pakets in der Warteschlange nicht kennen, es fragmentieren und dann wieder sammeln.Seine Ungerechtigkeit bei der Zuteilung des Streifens versperrte ihm jedoch den Weg in die Welt - in der Welt der Netzwerke wurde reines Round-Robin nicht umgesetzt.
RR ging die Warteschlangen durch und extrahierte eine gleiche Anzahl von Paketen aus ihnen. Der Ansatz ist primitiver als FQ und daher in Bezug auf verschiedene Flüsse unehrlich. Aggressive Quellen können den Streifen leicht mit Paketen von 1500 Byte Größe überfluten.Die Implementierung war jedoch sehr einfach: Sie müssen die Größe des Pakets in der Warteschlange nicht kennen, es fragmentieren und dann wieder sammeln.Seine Ungerechtigkeit bei der Zuteilung des Streifens versperrte ihm jedoch den Weg in die Welt - in der Welt der Netzwerke wurde reines Round-Robin nicht umgesetzt.WRR - Weighted Round Robin
Das gleiche Schicksal ist mit WRR, das den Warteschlangen basierend auf der IP-Priorität mehr Gewicht verlieh. In WRR wurde nicht die gleiche Anzahl von Paketen herausgenommen, sondern ein Vielfaches des Warteschlangengewichts.Es wäre möglich, Warteschlangen mit kleineren Paketen mehr Gewicht zu verleihen, aber dies dynamisch zu tun, war nicht möglich.
DWRR - Defizitgewichteter Round Robin
Und plötzlich wurde 1995 von M. Shreedhar und G. Varghese ein äußerst merkwürdiger Ansatz vorgeschlagen.Jede Zeile hat eine separate Kreditlinie in Bits.Beim Verlassen der Warteschlange werden so viele Pakete ausgegeben, wie genügend Guthaben vorhanden ist.Die Größe des Pakets im Kopf der Warteschlange wird vom Darlehensbetrag abgezogen.Wenn die Differenz größer als Null ist, wird dieses Paket entfernt und das nächste überprüft. Also bis die Differenz kleiner als Null ist.Wenn selbst das erste Paket nicht genug Guthaben hat, bleibt der Schlamm in der Warteschlange.Vor dem nächsten Durchgang wird das Guthaben jeder Zeile um einen bestimmten Betrag erhöht, der als Quantum bezeichnet wird .Für verschiedene Warteschlangen ist das Quantum unterschiedlich - je größer das Band ist, das Sie geben müssen, desto größer ist das Quantum.Somit erhalten alle Warteschlangen eine garantierte Bandbreite, unabhängig von der Größe der darin enthaltenen Pakete.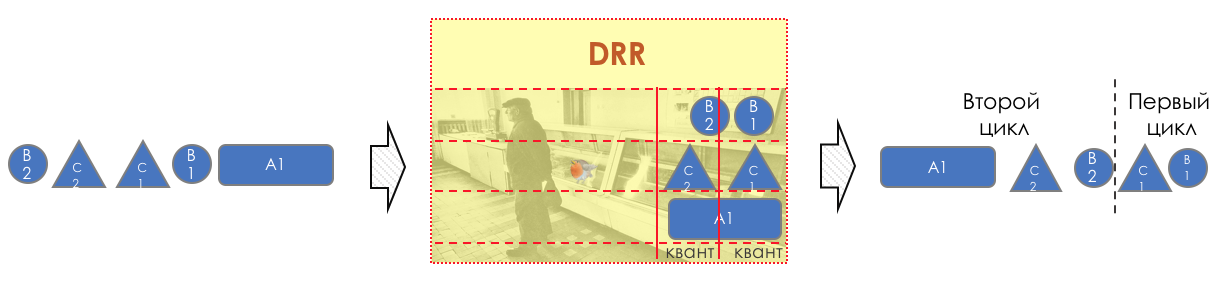 Aus der obigen Erklärung wäre mir nicht klar, wie das funktioniert.
Aus der obigen Erklärung wäre mir nicht klar, wie das funktioniert.Lassen Sie uns die Schritte zeichnen ...Lassen Sie uns den sphärischen Fall analysieren:- DRR (ohne W),
- 4 Zeilen
- in der 0. sind alle Pakete jeweils 500 Bytes,
- In der 1. - 1000 jeweils
- In der 2. bis 1500,
- Und im 3. liegt eine Wurst für 4000,
- Quantum - 1600 Bytes.

Zyklus 1
1. 0, 1600 ()
0- . :
— (1600 — 500 = 1100).
— — (1100 — 500 = 600).
— — (600 — 500 = 100).
— (100 — 500 = -400). .
— 100 .
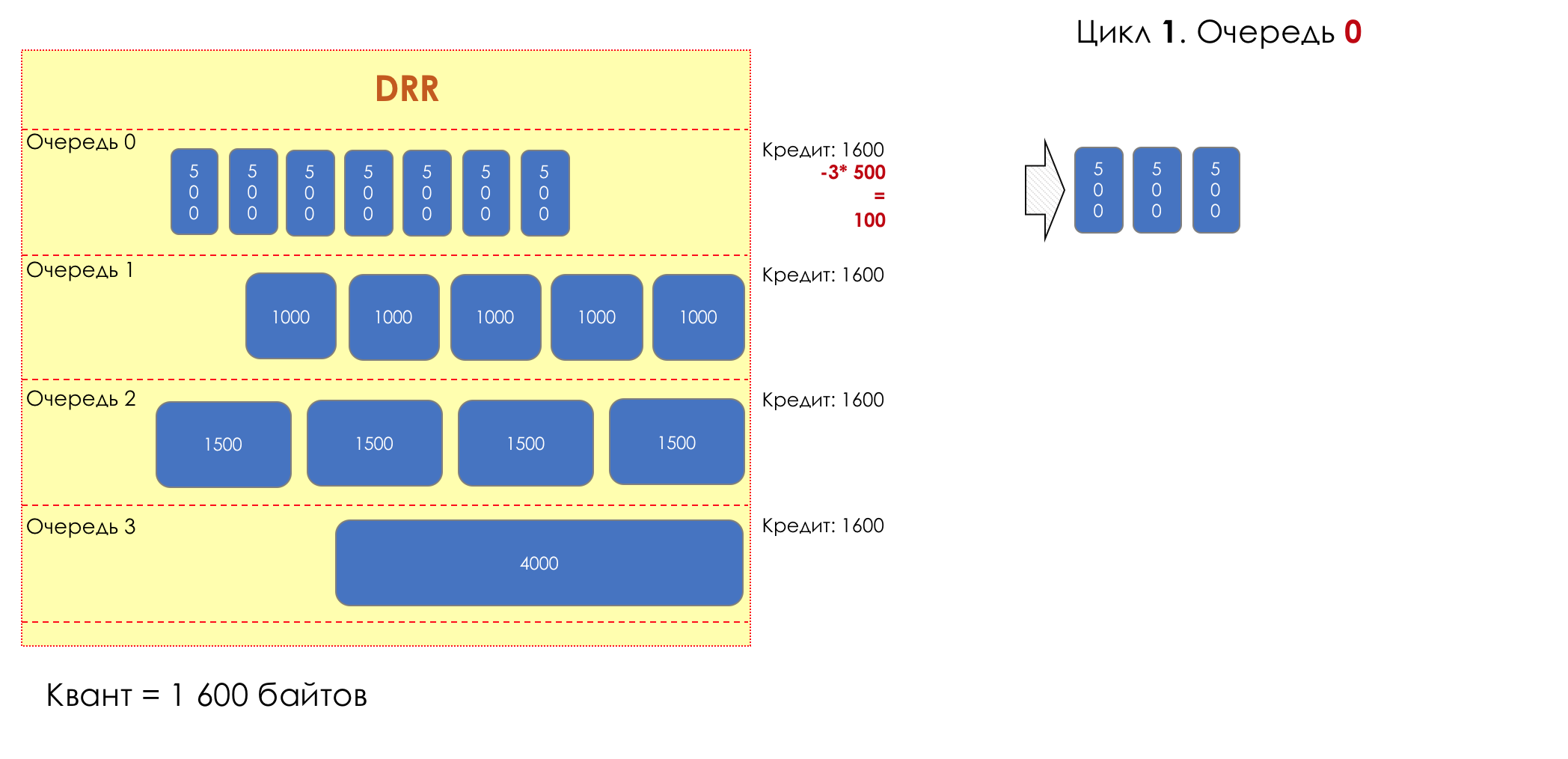 1. 1
1. 1— (1600 — 1000 = 600).
(600 — 1000 = -400). .
— 600 .
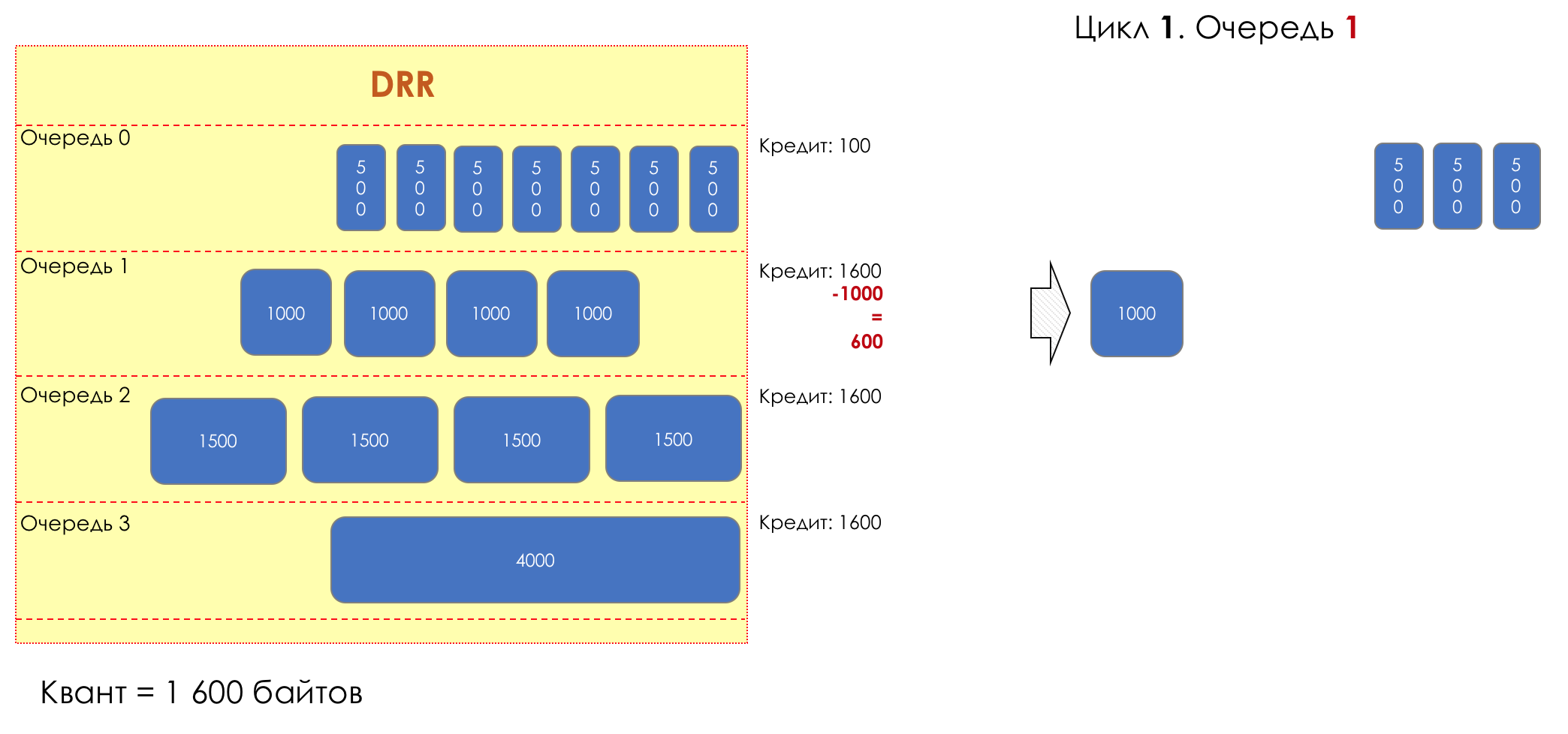 1. 2
1. 2— (1600 — 1500 = 100).
(100 — 1000 = -900). .
— 100 .
 1. 3
1. 3. (1600 — 4000 = -2400).
.
— 1600 .
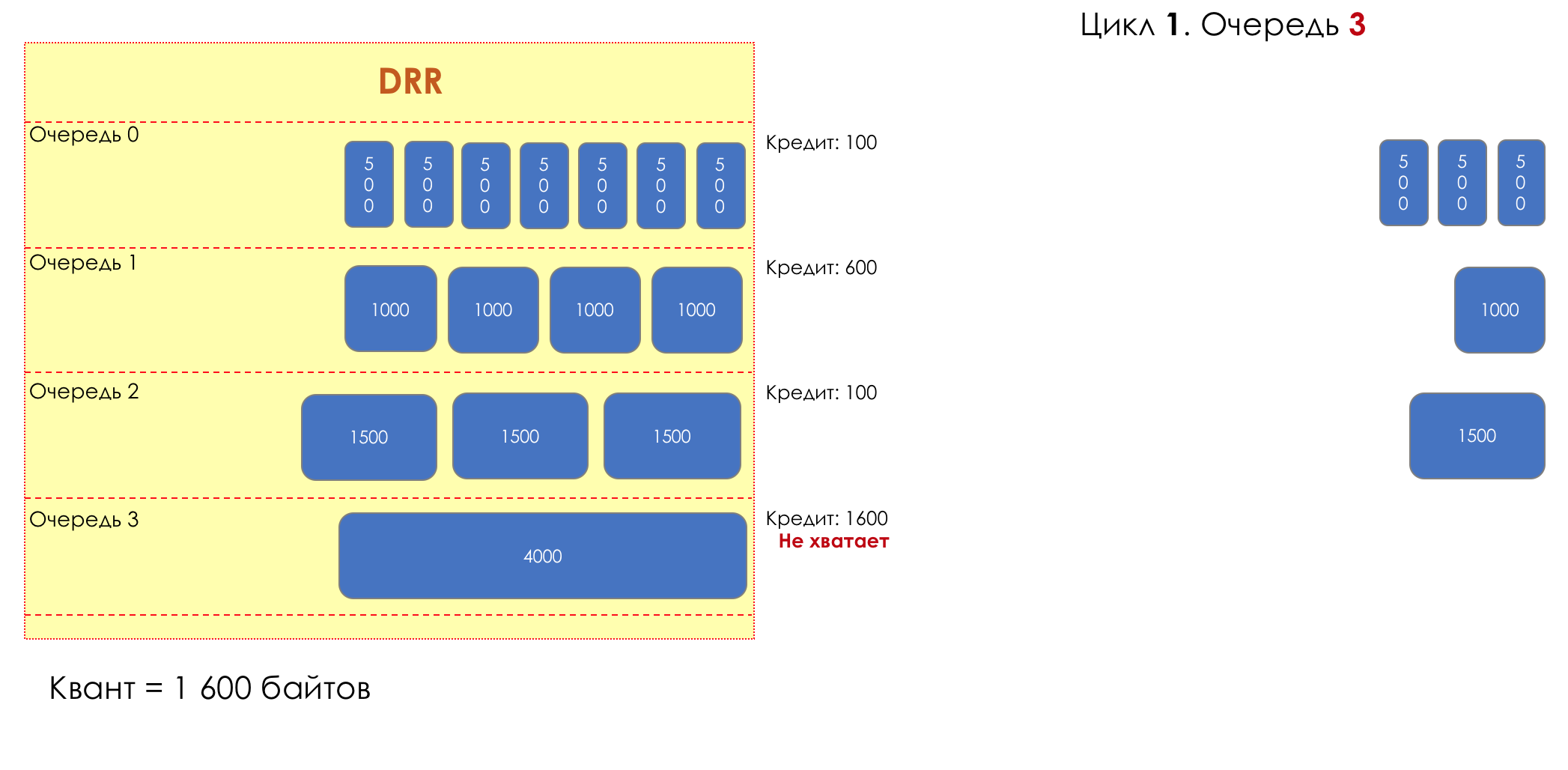
, :
- 0 — 1500
- 1 — 1000
- 2 — 1500
- 3 — 0
:
- 0 — 100
- 1 — 600
- 2 — 100
- 3 — 1600
2
— 1600 .
2. 01700 (100 + 1600).
— (1700 — 3*500 = 200).
.
— 200 .
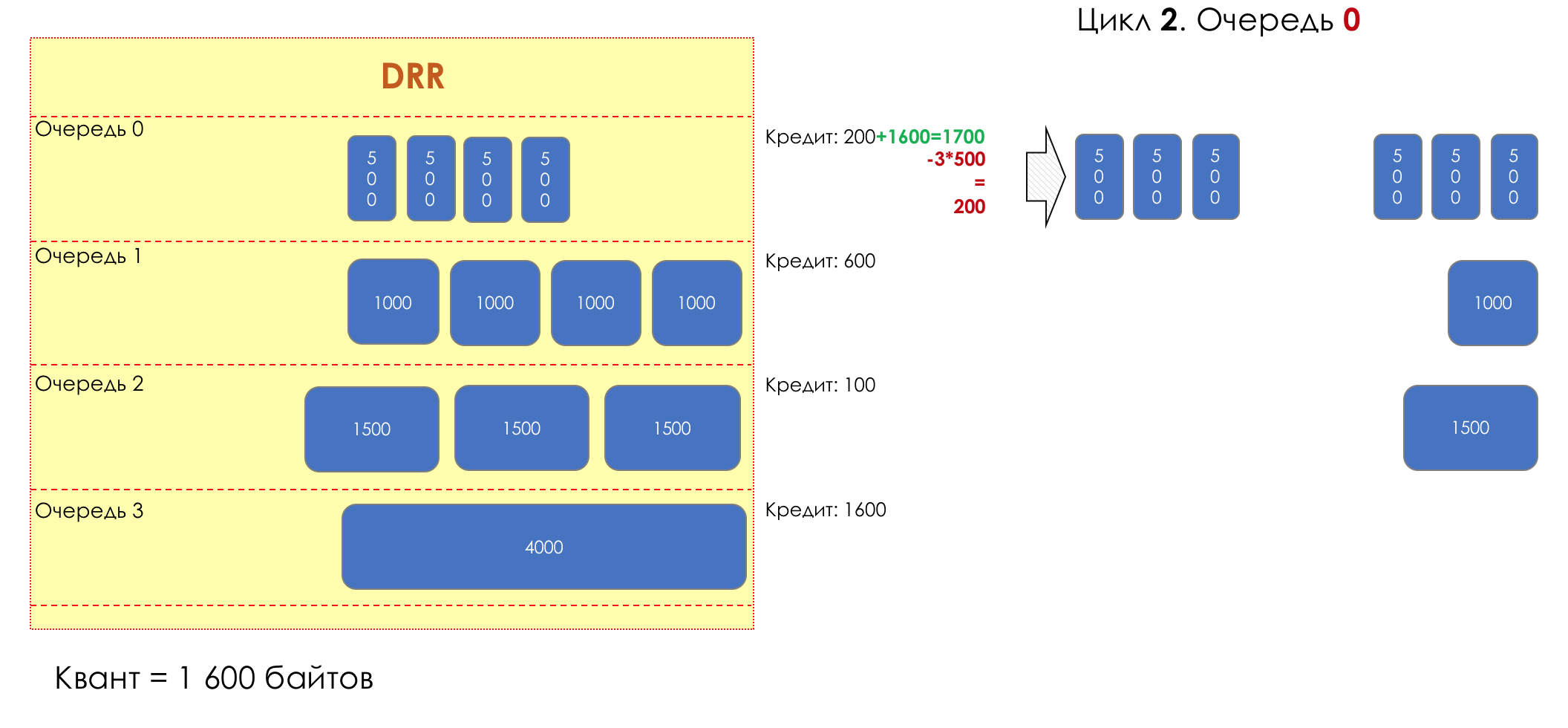 2. 1
2. 12200 (600 + 1600).
— (2200 — 2*1000 = 200).
.
— 200 .
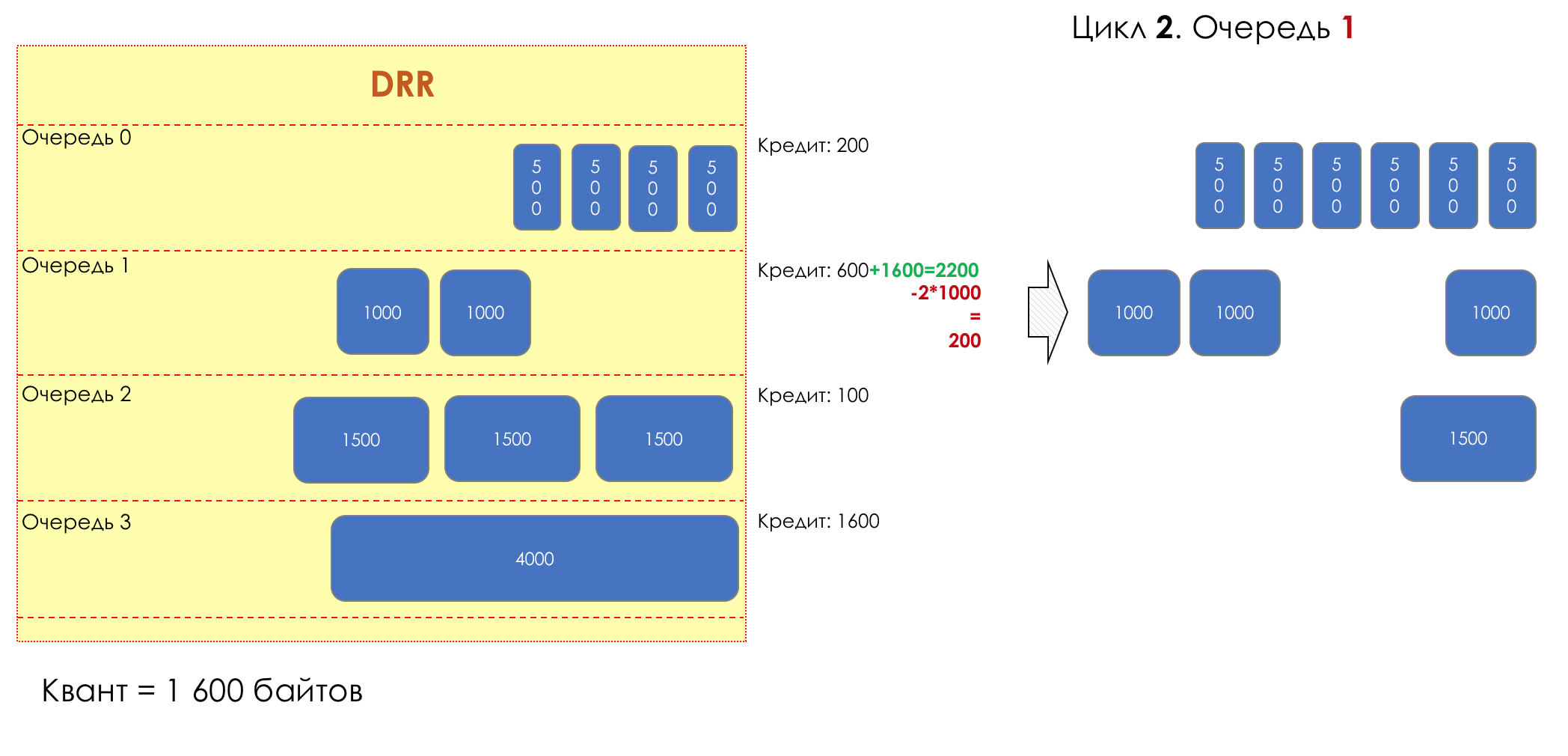 2. 2
2. 21700 (100 + 1600).
— (2200 — 1500 = 200).
— .
— 200 .
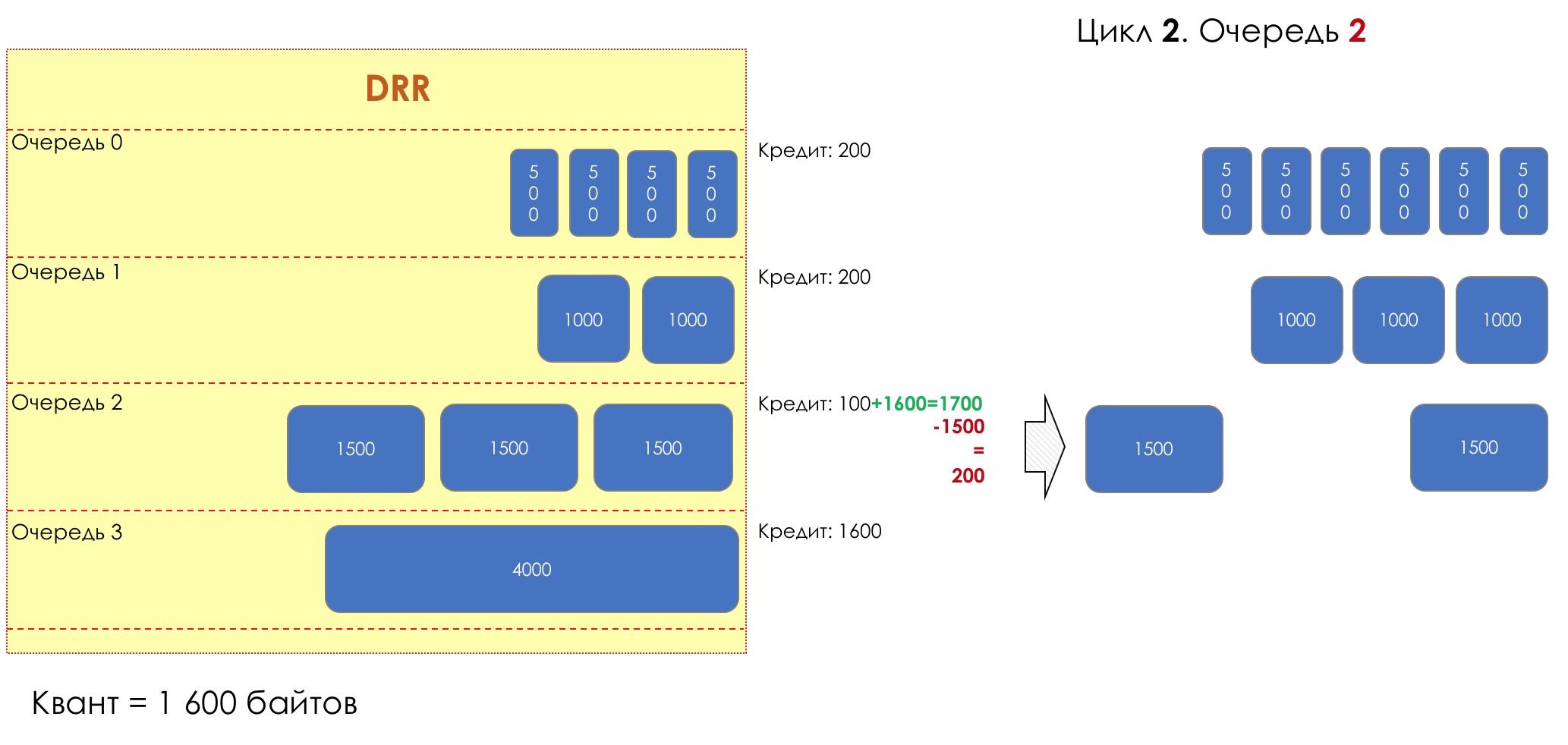 2. 3
2. 33200 (1600 + 1600).
(3200 — 4000 = -800)
— 3200 .
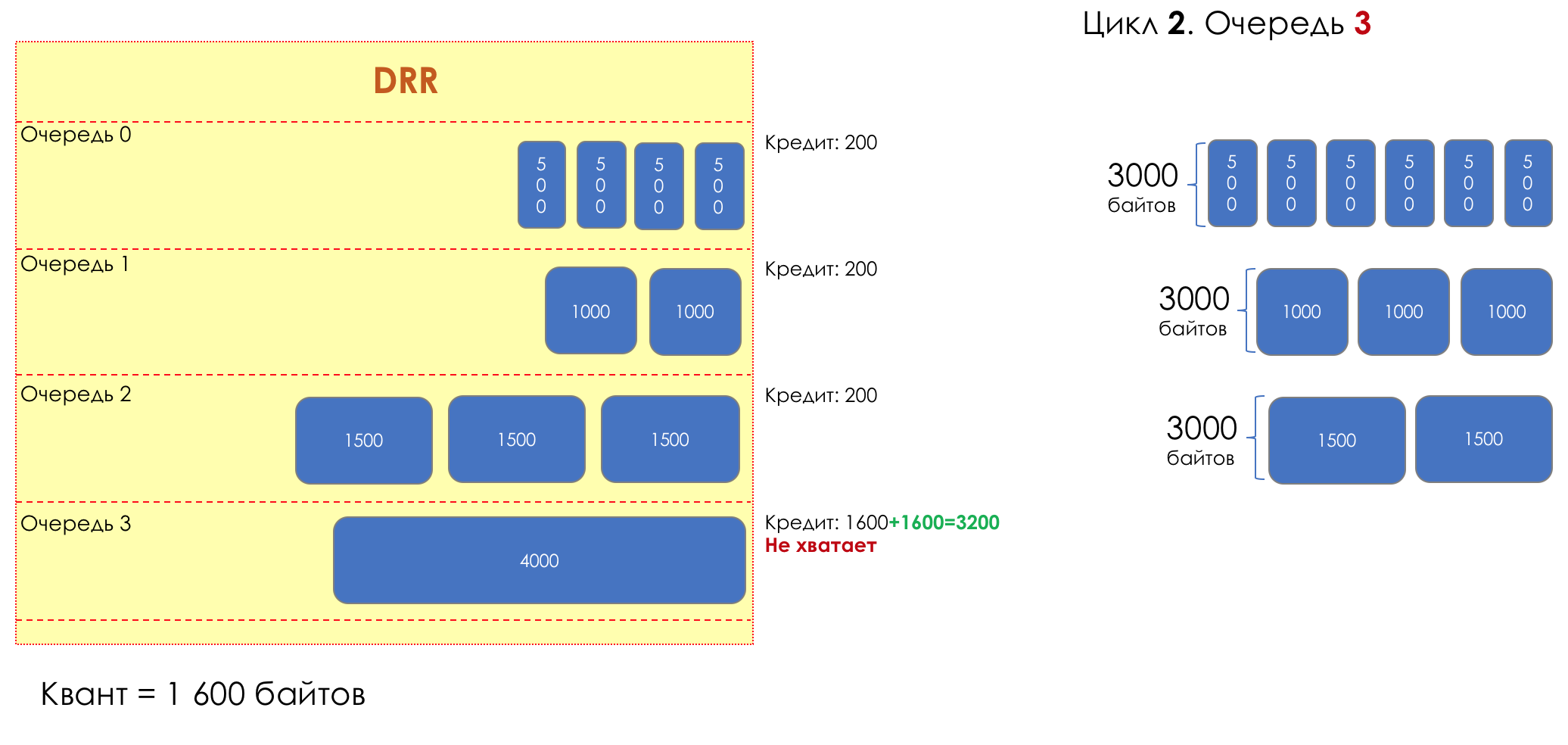
, :
- 0 — 3000
- 1 — 3000
- 2 — 3000
- 3 — 0
:
- 0 — 200
- 1 — 200
- 2 — 200
- 3 — 3200
3
— 1600 .
3. 01800 (200 + 1600).
— (1800 — 3*500 = 300).
.
— 300 .
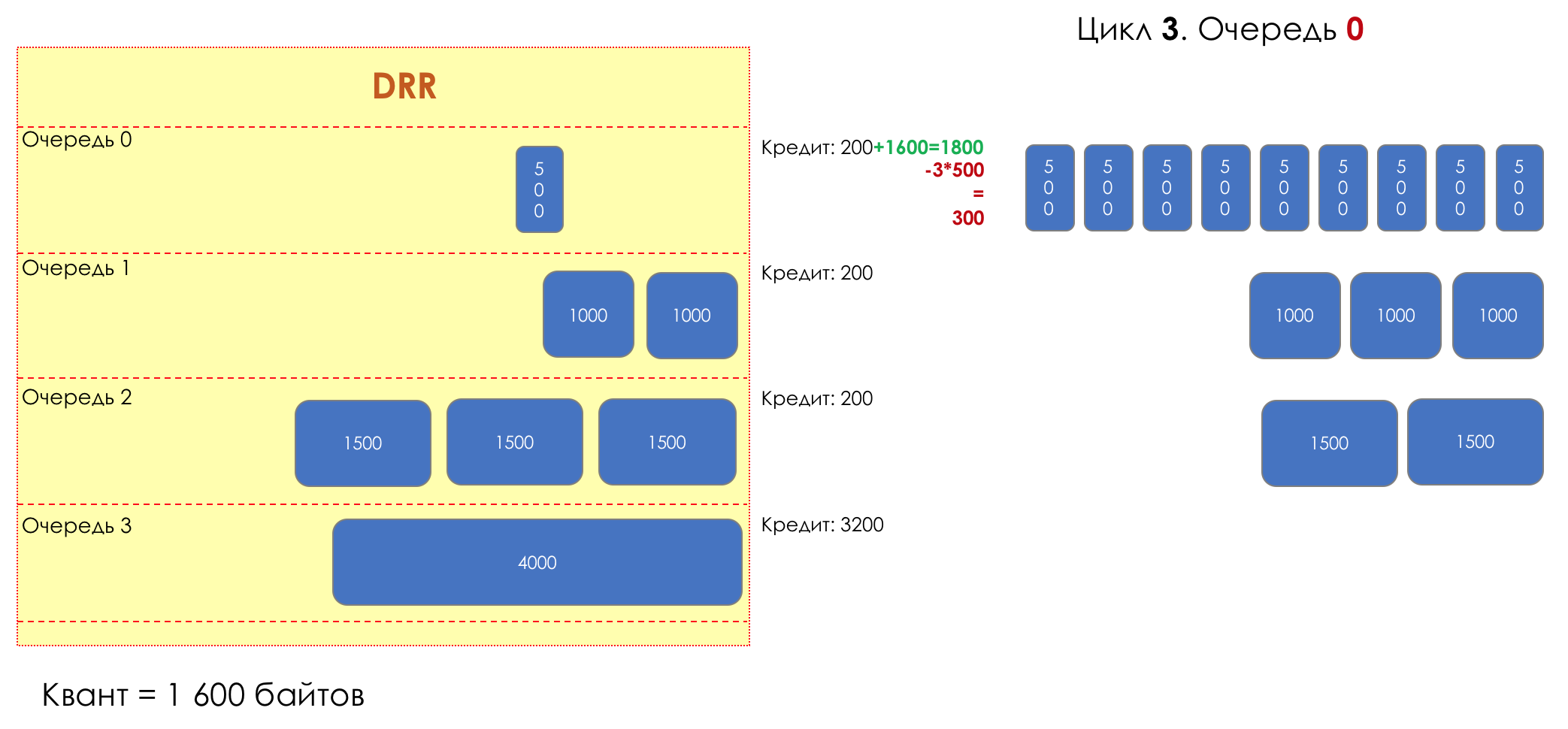 3. 1
3. 11800 (200 + 1600).
— (1800 — 1000 = 800).
— 800 .
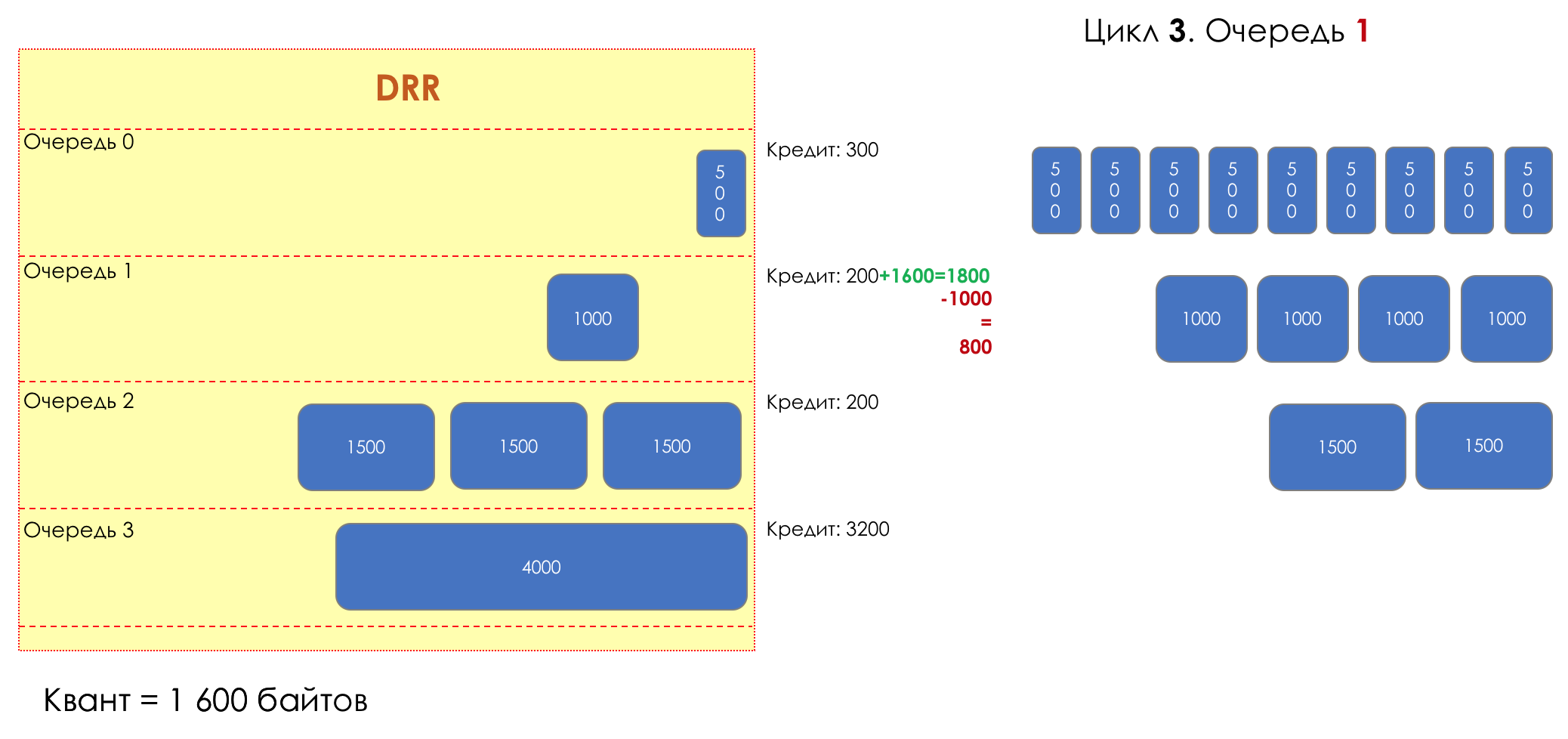 3. 2
3. 21800 (200 + 1600).
— (1800 — 1500 = 300).
— 300 .
 3. 3
3. 33- !
4800 (3200 + 1600).
— (4800 — 4000 = 800).
— 800 .
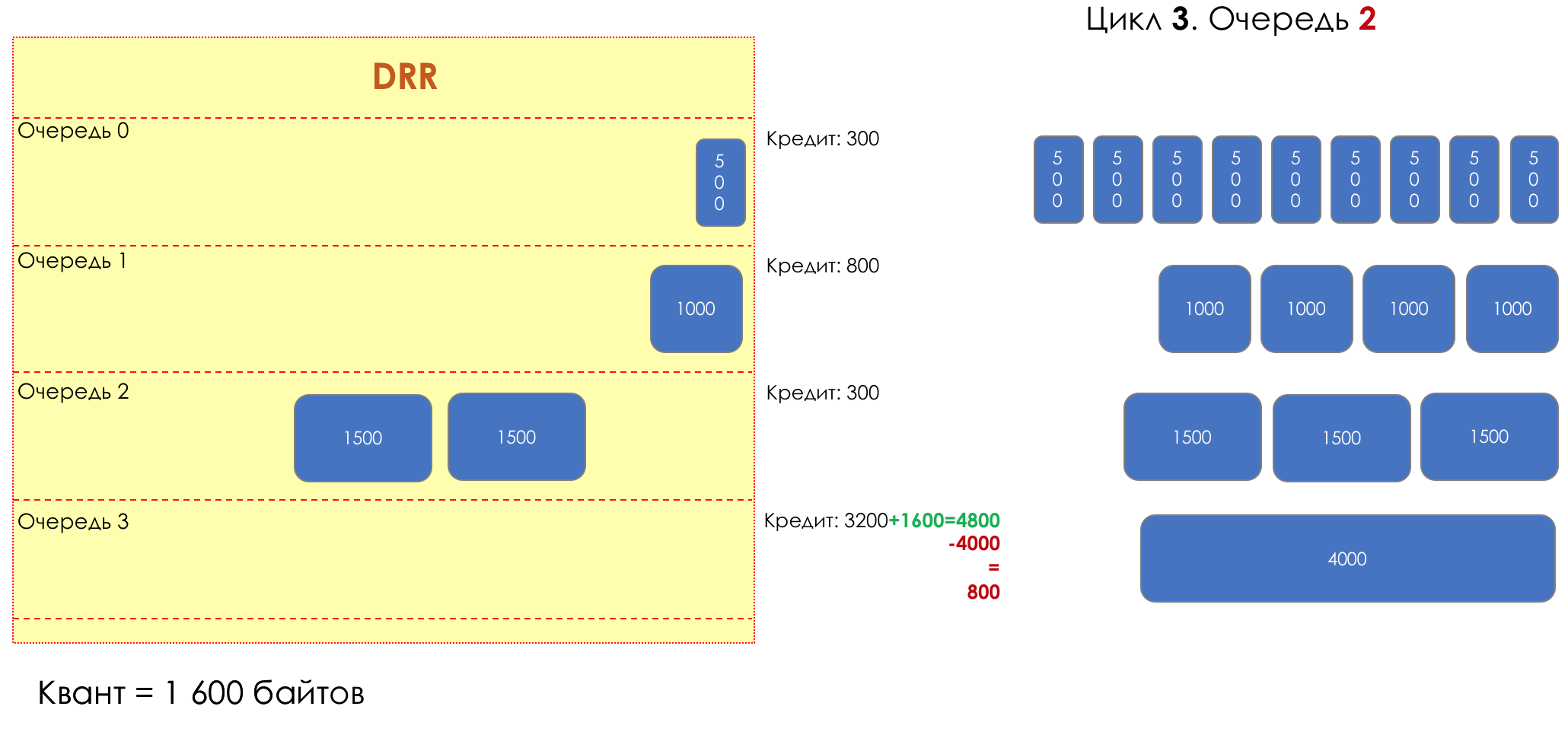
, :
- 0 — 4500
- 1 — 4000
- 2 — 4500
- 3 — 4000
:
- 0 — 300
- 1 — 800
- 2 — 300
- 3 — 800
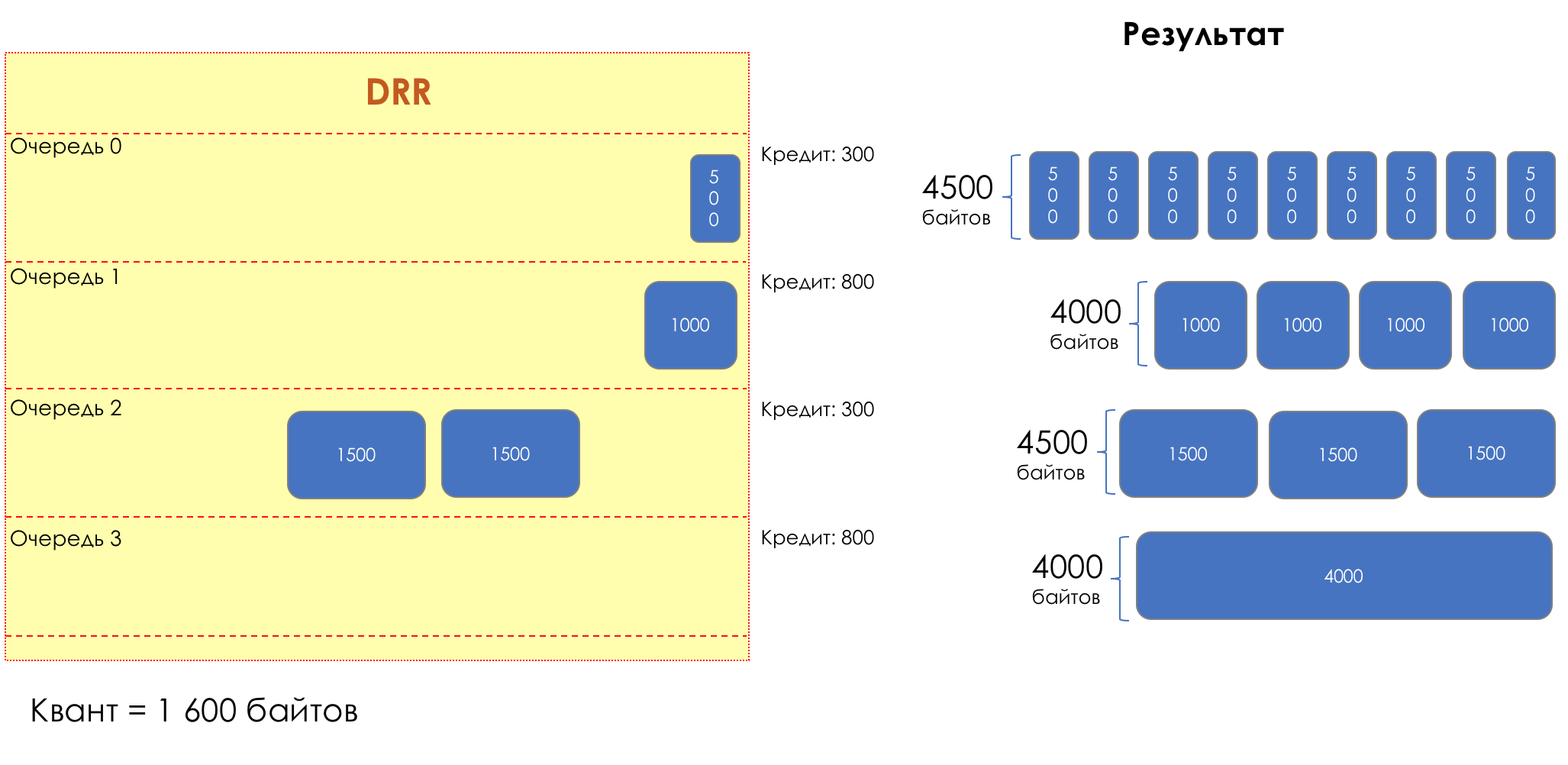
DRR. .
, .
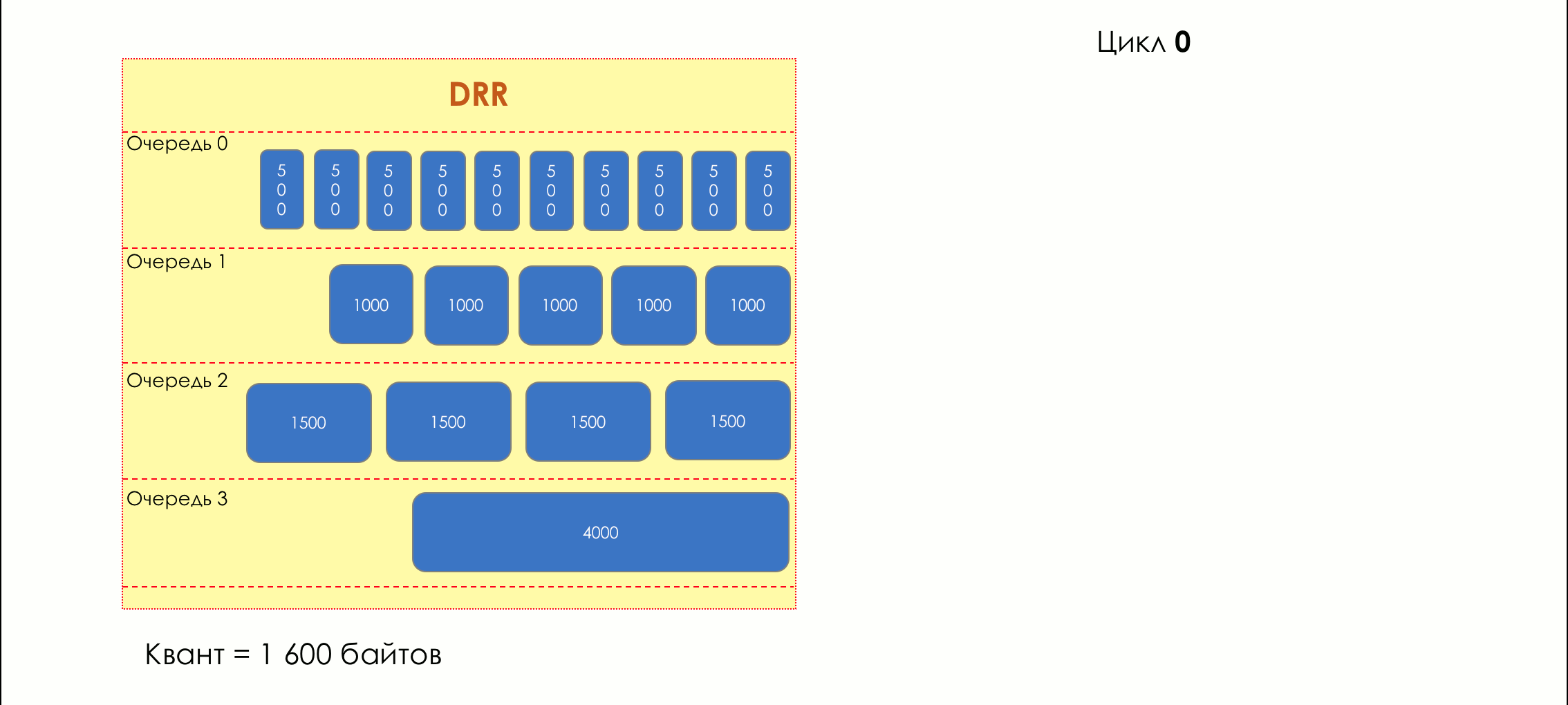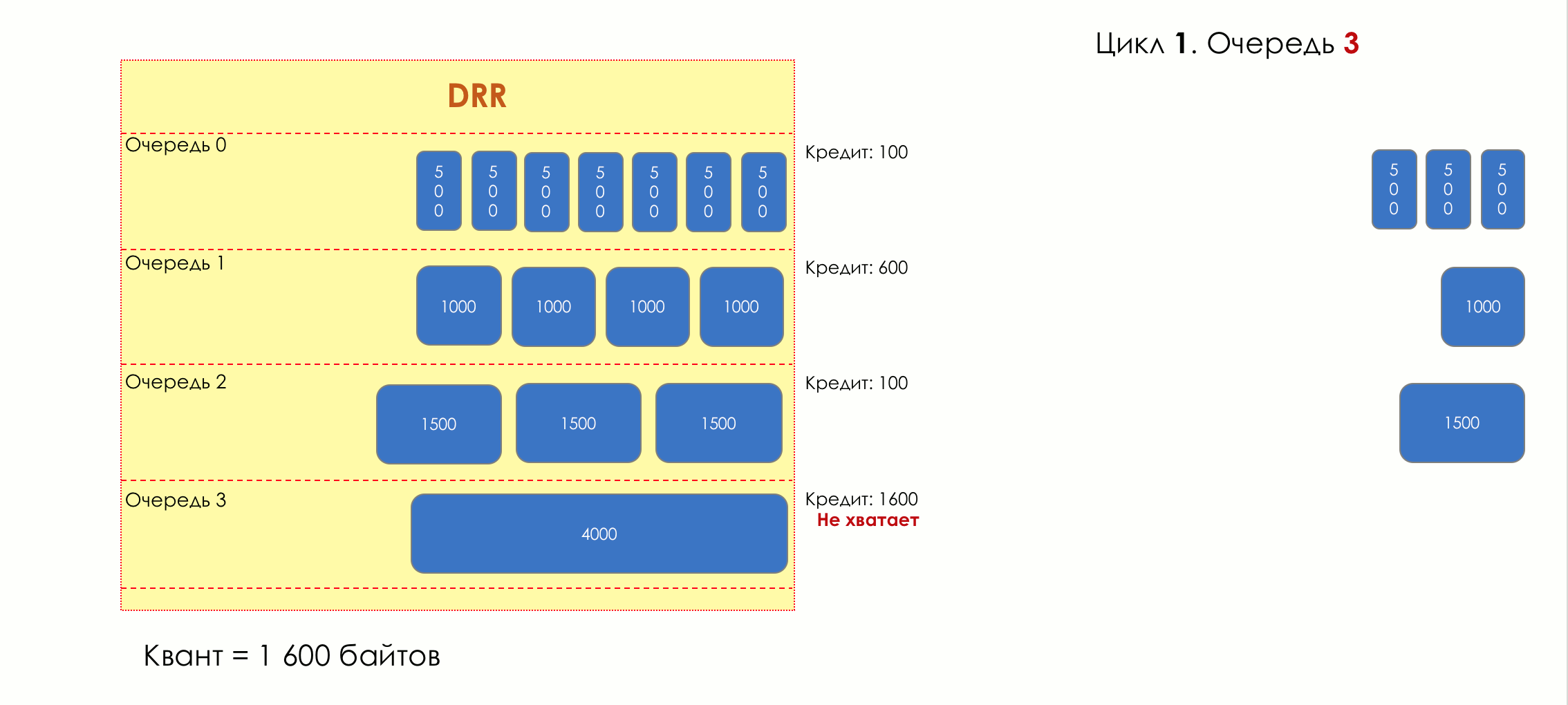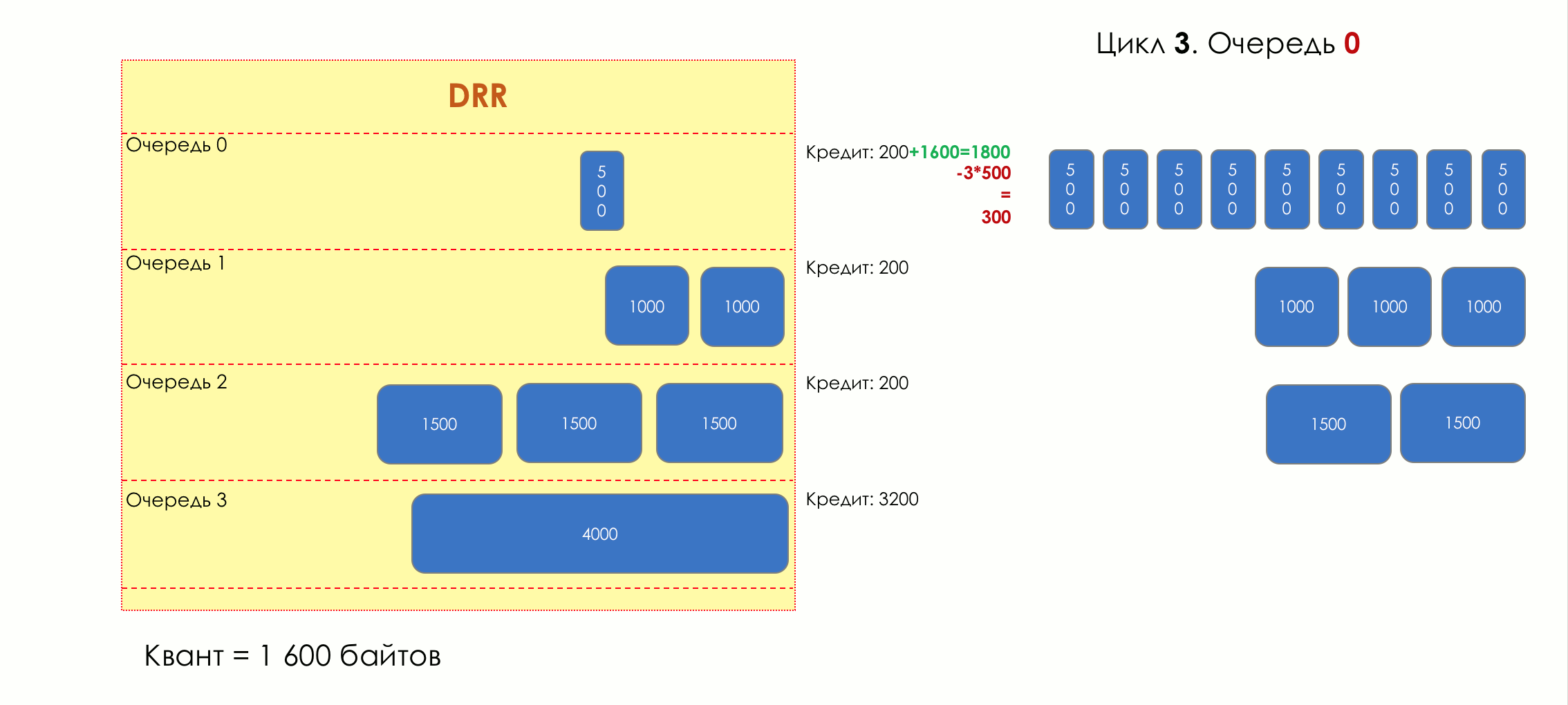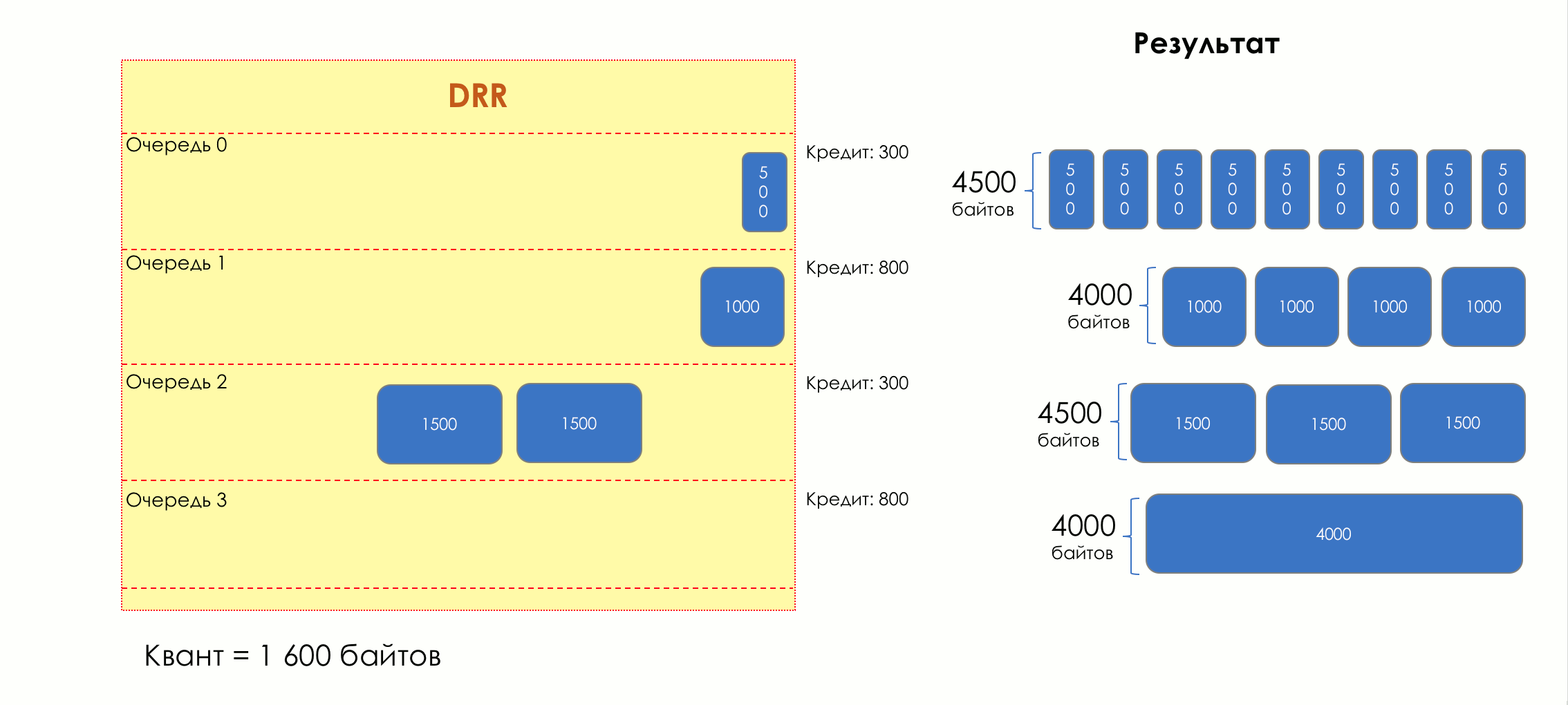
DWRR DRR , , , .
DRR, — , .
: , . .
Bei DWRR bleibt die Frage bei der Garantie von Verzögerungen und Jitter - das Gewicht löst sie in keiner Weise.Theoretisch können Sie dasselbe wie mit CB-WFQ tun, indem Sie LLQ hinzufügen.Dies ist jedoch nur eines der möglichen Szenarien der heutigen wachsenden Popularität.PB-DWRR - Prioritätsbasiertes DWRR
Tatsächlich wird der heutige Mainstream zu PB-DWRR - Priority Based Deficit Weighted Round Robin.Dies ist das gleiche alte böse DWRR, in dem eine weitere Warteschlange hinzugefügt wird - Priorität, in der Pakete mit einer höheren Priorität verarbeitet werden. Dies bedeutet nicht, dass sie einen größeren Streifen erhält, sondern dass Pakete häufiger von dort genommen werden.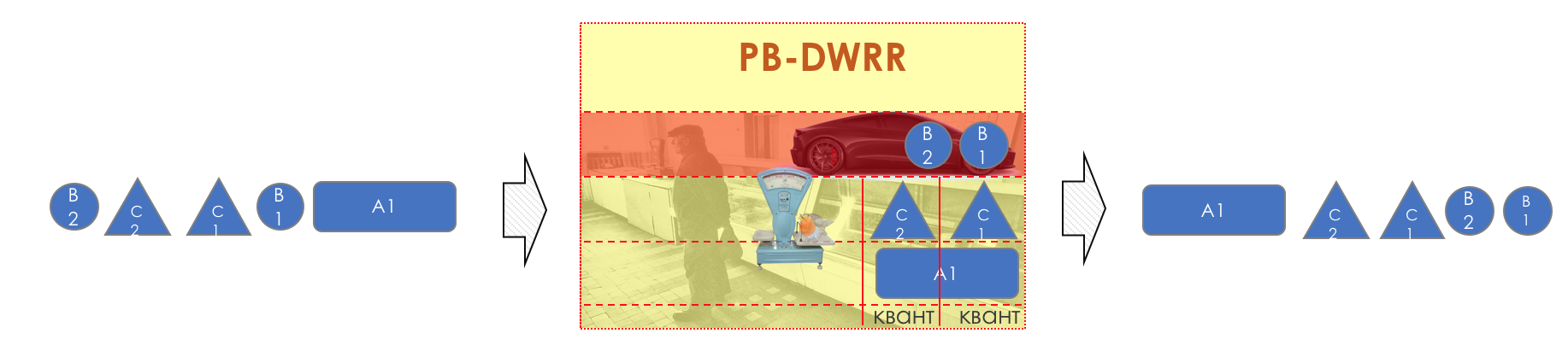 Es gibt verschiedene Ansätze zur Implementierung von PB-DWRR. In einigen von ihnen, wie in PQ, wird jedes Paket, das in der Prioritätswarteschlange ankommt, sofort entfernt. In anderen Fällen wird jedes Mal darauf zugegriffen, wenn der Dispatcher zwischen Warteschlangen wechselt. Drittens werden ein Kredit und ein Quantum dafür eingeführt, so dass die Prioritätswarteschlange nicht den gesamten Streifen quetschen kann.Natürlich werden wir sie nicht analysieren.
Es gibt verschiedene Ansätze zur Implementierung von PB-DWRR. In einigen von ihnen, wie in PQ, wird jedes Paket, das in der Prioritätswarteschlange ankommt, sofort entfernt. In anderen Fällen wird jedes Mal darauf zugegriffen, wenn der Dispatcher zwischen Warteschlangen wechselt. Drittens werden ein Kredit und ein Quantum dafür eingeführt, so dass die Prioritätswarteschlange nicht den gesamten Streifen quetschen kann.Natürlich werden wir sie nicht analysieren.Eine kurze Zusammenfassung der Versandmechanismen
Seit Jahrzehnten versucht die Menschheit, das schwierigste Problem zu lösen, das richtige Serviceniveau und eine faire Verteilung der Band sicherzustellen. Warteschlangen waren das Hauptwerkzeug. Die einzige Frage war, wie Pakete aus den Warteschlangen abgerufen und in eine Schnittstelle verschoben werden können.Beginnend mit FIFO erfand es PQ - die Stimme konnte mit dem Surfen koexistieren, aber es gab keine Frage, die Band zu garantieren.Es erschienen mehrere monströse FQ, WFQ, die funktionierten, wenn nicht pro Flow, dann fast so. CB-WFQ kam in die Klassengesellschaft, aber es wurde nicht einfacher.Als Alternative entwickelte er RR. Es wurde ein WRR und dann ein DWRR.Und in den Tiefen jedes Dispatchers lebt FIFO.Wie Sie sehen, gibt es jedoch keinen universellen Dispatcher, der alle erforderlichen Klassen verarbeitet. Es handelt sich immer um eine Kombination von Dispatchern, von denen einer das Problem der Sicherstellung von Verzögerungen, Jitter und fehlenden Verlusten löst und der andere die Bandzuweisung.CBWFQ + LLQ oder PB-WDRR oder WDRR + PQ.Auf realen Geräten können Sie angeben, welche Warteschlangen mit welchem Dispatcher verarbeitet werden sollen.CBWFQ, WDRR und ihre Derivate sind heute die Favoriten.PQ, FQ, WFQ, RR, WRR - wir trauern nicht und erinnern uns nicht (es sei denn, wir bereiten uns natürlich auf CCIE Clipper vor).
Disponenten können also Geschwindigkeit garantieren, aber wie kann man sie von oben begrenzen?8. Geschwindigkeitsbegrenzung
Die Notwendigkeit, die Verkehrsgeschwindigkeit auf den ersten Blick zu begrenzen, liegt auf der Hand - lassen Sie den Kunden nicht gemäß der Vereinbarung aus seiner Band.Ja Aber nicht nur das.
Angenommen, es gibt eine RRL-Spanne mit einer Breite von 620 Mbit / s, die über einen 1-Gbit / s-Port verbunden ist. Wenn Sie den gesamten Gigabit hineinschießen, beginnen irgendwo auf der RRL, die höchstwahrscheinlich keine Ahnung von Warteschlangen und QoS hat, monströse Tropfen zufälliger Art, die nicht an die tatsächlichen Prioritäten des Verkehrs gebunden sind.Wenn Sie jedoch die Formgebung von bis zu 600 Mbit / s auf dem Router aktivieren, werden EF, CS6, CS7 überhaupt nicht verworfen, und in BE, AFx werden das Band und die Tropfen entsprechend ihrer Gewichtung verteilt. RRL wird 600 Mb / s erreichen und wir werden ein vorhersehbares Bild erhalten.Ein weiteres Beispiel ist die Zugangskontrolle. Beispielsweise haben sich zwei Betreiber darauf geeinigt, den Markierungen des anderen zu vertrauen, mit Ausnahme von CS7 - falls etwas in CS7 enthalten ist - verwerfen. Geben Sie für CS6 und EF eine separate Warteschlange mit Garantie für Verzögerung und ohne Verlust an.Aber was wäre, wenn der listige Partner anfangen würde, Ströme in diese Zeilen zu gießen? Auf Wiedersehen Telefonie. Und die Protokolle werden höchstwahrscheinlich auseinanderfallen.In diesem Fall ist es logisch, sich mit einem Partner über den Streifen zu einigen. Alles, was in den Vertrag passt, wird übersprungen. Was nicht passt - verwerfen oder in eine andere Warteschlange übertragen - BE zum Beispiel. So schützen wir unser Netzwerk und unsere Dienstleistungen.Es gibt zwei grundlegend unterschiedliche Ansätze zur Geschwindigkeitsbegrenzung: Polieren und Formen. Sie lösen ein Problem, aber auf unterschiedliche Weise.Betrachten Sie den Unterschied anhand eines Beispiels für ein solches Verkehrsprofil:
Verkehrspolizei
Die Überwachung begrenzt die Geschwindigkeit, indem überschüssiger Verkehr abfällt.Alles, was den eingestellten Wert überschreitet, schneidet und wirft der Polyser weg. Was geschnitten wird, wird vergessen. Das Bild zeigt, dass das rote Paket nach dem Polyser nicht im Verkehr ist.Und so sieht das ausgewählte Profil nach dem Polyser aus:
Was geschnitten wird, wird vergessen. Das Bild zeigt, dass das rote Paket nach dem Polyser nicht im Verkehr ist.Und so sieht das ausgewählte Profil nach dem Polyser aus: Aufgrund der Schwere der ergriffenen Maßnahmen wird dies als Hard Policing bezeichnet .Es gibt jedoch andere mögliche Aktionen.Der Polizist arbeitet normalerweise in Verbindung mit einer Verkehrsanzeige. Das Messgerät färbt die Taschen, wie Sie sich erinnern, in Grün, Gelb oder Rot.Und aufgrund dieser Farbe darf der Polyser das Paket nicht verwerfen, sondern in eine andere Klasse einordnen. Dies sind weiche Maßnahmen - Soft Policing .Es kann sowohl auf eingehenden als auch auf ausgehenden Verkehr angewendet werden.Eine Besonderheit des Polysers ist die Fähigkeit, Verkehrsstöße zu absorbieren und dank des Token-Bucket-Mechanismus die maximal zulässige Geschwindigkeit zu bestimmen.Das heißt, alles, was nicht über dem eingestellten Wert liegt, wird nicht abgeschnitten - es darf ein wenig darüber hinausgehen - kurze Bursts oder kleine Überschüsse des zugewiesenen Bandes werden übersprungen.Der Name „Polizeiarbeit“ wird durch das ziemlich strenge Verhältnis des Tools zu übermäßigem Datenverkehr bestimmt - Verwerfen oder Herabstufen zu einer niedrigeren Klasse.
Aufgrund der Schwere der ergriffenen Maßnahmen wird dies als Hard Policing bezeichnet .Es gibt jedoch andere mögliche Aktionen.Der Polizist arbeitet normalerweise in Verbindung mit einer Verkehrsanzeige. Das Messgerät färbt die Taschen, wie Sie sich erinnern, in Grün, Gelb oder Rot.Und aufgrund dieser Farbe darf der Polyser das Paket nicht verwerfen, sondern in eine andere Klasse einordnen. Dies sind weiche Maßnahmen - Soft Policing .Es kann sowohl auf eingehenden als auch auf ausgehenden Verkehr angewendet werden.Eine Besonderheit des Polysers ist die Fähigkeit, Verkehrsstöße zu absorbieren und dank des Token-Bucket-Mechanismus die maximal zulässige Geschwindigkeit zu bestimmen.Das heißt, alles, was nicht über dem eingestellten Wert liegt, wird nicht abgeschnitten - es darf ein wenig darüber hinausgehen - kurze Bursts oder kleine Überschüsse des zugewiesenen Bandes werden übersprungen.Der Name „Polizeiarbeit“ wird durch das ziemlich strenge Verhältnis des Tools zu übermäßigem Datenverkehr bestimmt - Verwerfen oder Herabstufen zu einer niedrigeren Klasse.Verkehrsgestaltung
Das Formen begrenzt die Geschwindigkeit, indem überschüssiger Verkehr gepuffert wird.Der gesamte eingehende Verkehr wird durch den Puffer geleitet. Ein Shaper entfernt Pakete mit konstanter Geschwindigkeit aus diesem Puffer.Wenn die Paketankunftsrate zum Puffer niedriger als die Ausgabe ist, werden sie im Puffer nicht verzögert - sie fliegen direkt durch.Und wenn die Ankunftsrate höher als die Ausgabe ist, beginnen sie sich anzusammeln.Die Ausgangsgeschwindigkeit ist immer gleich.Somit werden Verkehrsstöße zum Puffer hinzugefügt und gesendet, wenn sie die Warteschlange erreichen.Daher ist die Formgebung neben der Planung in Warteschlangen das zweite Werkzeug, das zur Gesamtverzögerung beiträgt .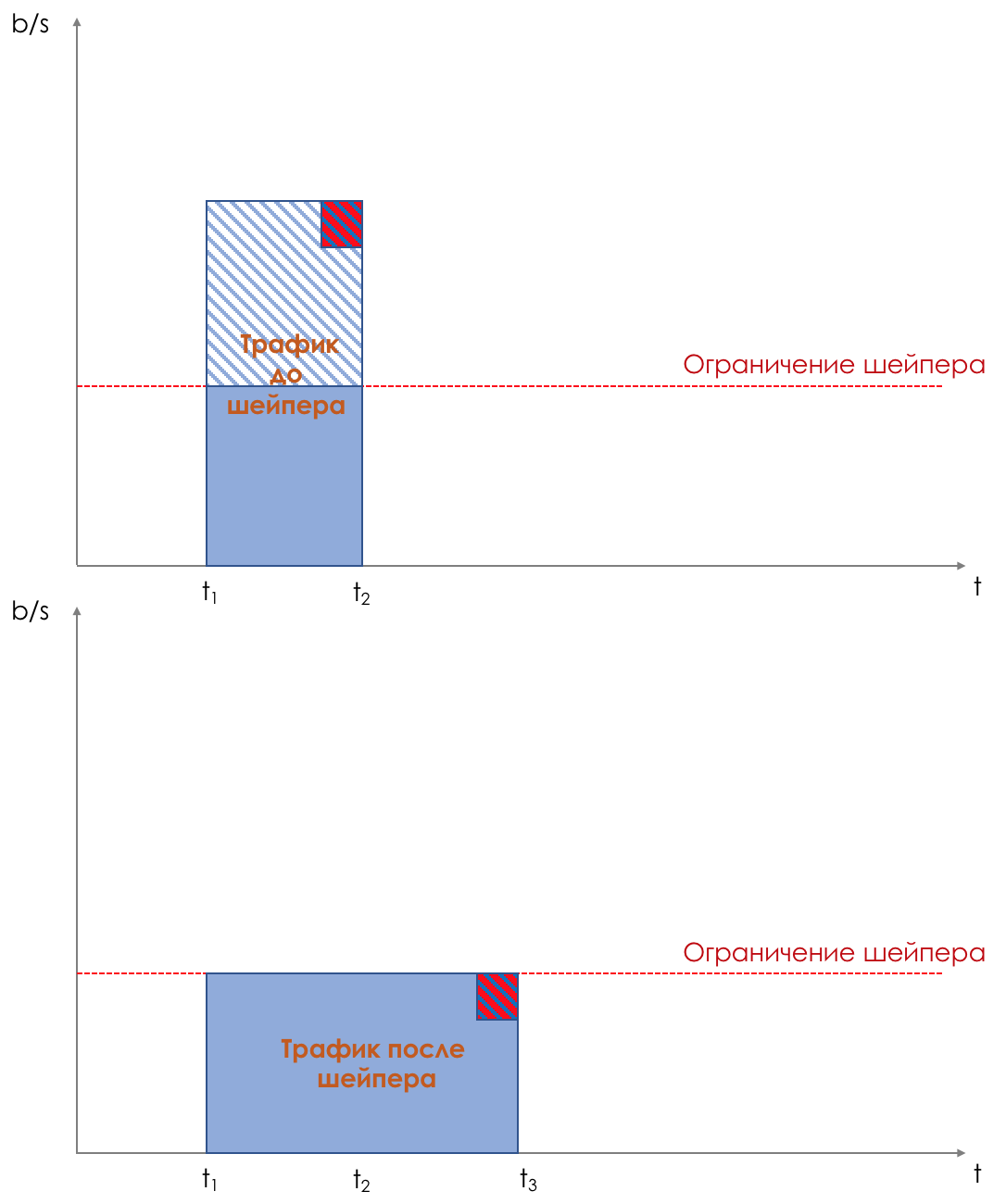 Die Abbildung zeigt deutlich, wie das zum Zeitpunkt t2 ankommende Paket zum Zeitpunkt t3 am Ausgang ankommt. t3-t2 ist die vom Former eingeführte Verzögerung.Shaper wird normalerweise auf ausgehenden Verkehr angewendet.So sieht das Profil nach dem Former aus.
Die Abbildung zeigt deutlich, wie das zum Zeitpunkt t2 ankommende Paket zum Zeitpunkt t3 am Ausgang ankommt. t3-t2 ist die vom Former eingeführte Verzögerung.Shaper wird normalerweise auf ausgehenden Verkehr angewendet.So sieht das Profil nach dem Former aus.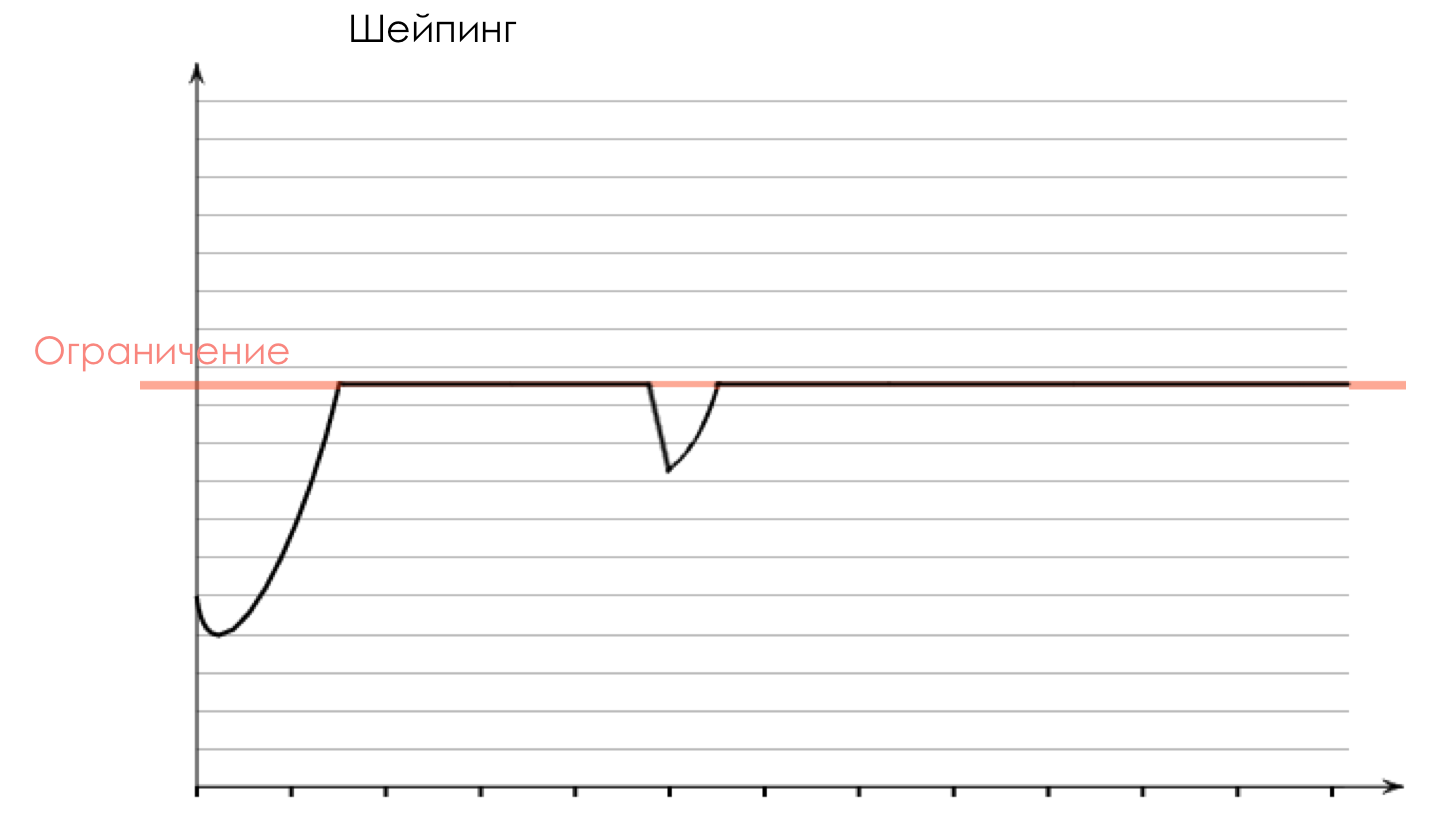 Der Name „Shaping“ gibt an, dass das Tool dem Verkehrsprofil eine Form gibt und es glättet.Der Hauptvorteil dieses Ansatzes ist die optimale Nutzung des vorhandenen Bandes - anstatt übermäßigen Datenverkehr abzubauen, verschieben wir ihn.Der Hauptnachteil ist eine unvorhersehbare Verzögerung - wenn der Puffer voll ist, werden Pakete für eine lange Zeit darin schmachten. Daher ist die Formgebung nicht für alle Arten von Verkehr geeignet.Beim Formen wird der Leaky Bucket-Mechanismus verwendet.
Der Name „Shaping“ gibt an, dass das Tool dem Verkehrsprofil eine Form gibt und es glättet.Der Hauptvorteil dieses Ansatzes ist die optimale Nutzung des vorhandenen Bandes - anstatt übermäßigen Datenverkehr abzubauen, verschieben wir ihn.Der Hauptnachteil ist eine unvorhersehbare Verzögerung - wenn der Puffer voll ist, werden Pakete für eine lange Zeit darin schmachten. Daher ist die Formgebung nicht für alle Arten von Verkehr geeignet.Beim Formen wird der Leaky Bucket-Mechanismus verwendet.Formen versus Polieren
Die Arbeit des Polysers ähnelt einem Messer, das sich entlang der Oberfläche des Öls bewegt und die scharfe Seite des Tuberkels abschneidet.Die Arbeit eines Formers ähnelt einer Walze, die die Tuberkel glättet und gleichmäßig auf der Oberfläche verteilt.Shaper versucht, Pakete nicht zu verwerfen, während sie auf Kosten einer erhöhten Verzögerung gepuffert werden.Der Polierer führt keine Verzögerungen ein, verwirft jedoch Pakete leichter.Anwendungen, die unempfindlich gegenüber Verzögerungen sind, für die jedoch ein Verlust unerwünscht ist, sollten auf einen Former beschränkt werden.Für diejenigen, für die ein spätes Paket genauso ist wie ein verlorenes, ist es besser, es sofort fallen zu lassen - als zu polieren.Ein Shaper hat keinen Einfluss auf die Paket-Header und deren Schicksal außerhalb des Knotens, während das Gerät nach dem Polieren die Klasse im Header neu klassifizieren kann. Zum Beispiel hatte das Paket am Eingang die Klasse AF11, die Messung hat es im Gerät gelb gestrichen, am Ausgang hat es seine Klasse auf AF12 neu markiert - auf dem nächsten Knoten hat es eine höhere Wahrscheinlichkeit, verworfen zu werden.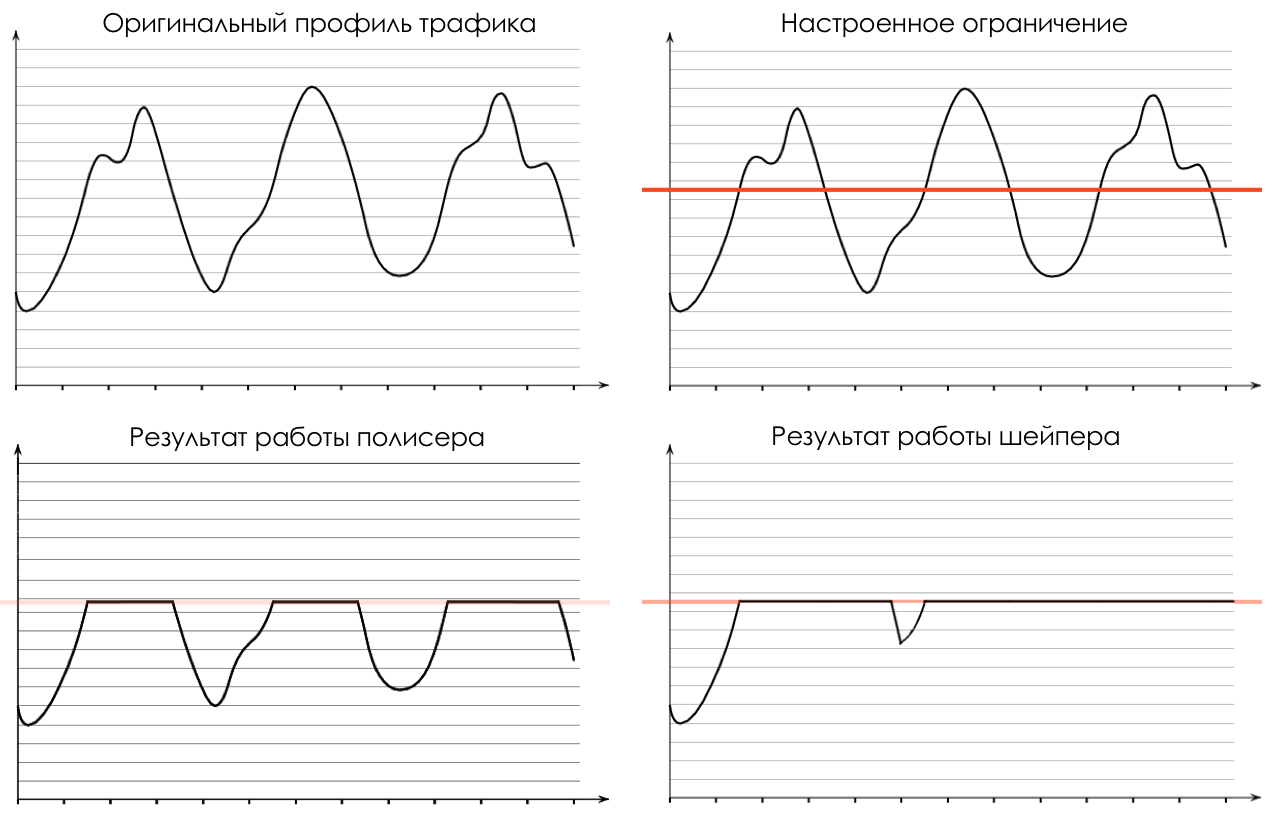
Üben Sie das Polieren und Formen
Das Schema ist das gleiche:Konfigurationsdatei. Wirbeobachten dieses Bild ohne Einschränkungen: Wir werden wie folgt vorgehen:
Wir werden wie folgt vorgehen:- Auf der Eingabeschnittstelle Linkmeup_R2 (e0 / 1) konfigurieren wir das Polieren - dies ist die Eingabesteuerung. Im Rahmen der Vereinbarung geben wir 10 Mb / s.
- Konfigurieren Sie auf der Ausgangsschnittstelle Linkmeup_R4 (e0 / 2) die Formgebung mit 20 Mbit / s.
Beginnen wir mit dem Shaper auf Linkmeup_R4 .Alles zusammenpassen: class-map match-all TRISOLARANS_ALL_CM match any
Form bis zu 20Mb / s: policy-map TRISOLARANS_SHAPING class TRISOLARANS_ALL_CM shape average 20000000
Auf die Ausgabeschnittstelle anwenden: interface Ethernet0/2 service-policy output TRISOLARANS_SHAPING
Alles, was die Ethernet0 / 2-Schnittstelle verlassen (ausgeben) soll, formt bis zu 20 Mb / s.Shaper-Konfigurationsdatei.Und hier ist das Ergebnis: Es ergibt sich eine ziemlich flache Linie des Gesamtdurchsatzes und der zerrissenen Grafiken für jeden einzelnen Stream.Tatsache ist, dass wir den Shaper auf das allgemeine Band beschränken. Je nach Plattform können einzelne Streams jedoch auch individuell gestaltet werden, wodurch Chancengleichheit entsteht.
Es ergibt sich eine ziemlich flache Linie des Gesamtdurchsatzes und der zerrissenen Grafiken für jeden einzelnen Stream.Tatsache ist, dass wir den Shaper auf das allgemeine Band beschränken. Je nach Plattform können einzelne Streams jedoch auch individuell gestaltet werden, wodurch Chancengleichheit entsteht.
Konfigurieren Sie nun das Polieren auf Linkmeup_R2.Wir werden der bestehenden Richtlinie einen Polyser hinzufügen. policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_TCP_CM police cir 10000000 bc 1875000 conform-action transmit exceed-action drop
Die Richtlinie wurde bereits auf die Schnittstelle angewendet: interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
Hier geben wir die durchschnittlich zulässige Geschwindigkeit CIR (10 MBit / s) und den zulässigen Burst Bc (1.875.000 Byte, ca. 14,6 MB) an.Später erkläre ich Ihnen, wie der Polyser funktioniert, und erkläre Ihnen, was CIR und Bc sind und wie Sie diese Werte bestimmen können.Polyser-Konfigurationsdatei.Dieses Bild wird beim Polieren beobachtet. Plötzliche Änderungen des Geschwindigkeitsniveaus sind sofort erkennbar:
Ein solch interessantes Bild wird jedoch erhalten, wenn wir die zulässige Burst-Größe zu klein machen, beispielsweise 10.000 Bytes. police cir 10000000 bc 10000 conform-action transmit exceed-action drop
 Die Gesamtgeschwindigkeit fiel sofort auf etwa 2 Mbit / s.Seien Sie vorsichtig mit der Einstellung von Bursts :)Testtabelle.
Die Gesamtgeschwindigkeit fiel sofort auf etwa 2 Mbit / s.Seien Sie vorsichtig mit der Einstellung von Bursts :)Testtabelle.
Undichter Eimer und Token-Eimer
Es klingt einfach und klar. Aber wie funktioniert es in der Praxis und ist in Hardware implementiert?Ein Beispiel.
Ist die Grenze von 400 Mbit / s viel (oder wenig)? Im Durchschnitt verwendet ein Client nur 320. Manchmal steigt er jedoch für 5 Minuten auf 410. Und manchmal bis zu 460 pro Minute. Und manchmal bis zu 500 für eine halbe Sekunde.Wie der Vertragsanbieter linkmeup sagen kann - 400 und das wars! Wenn Sie mehr wollen, verbinden Sie sich mit dem Tarif von 1 Gbit / s + 27 Anime-Kanälen.Und wir können die Kundenbindung erhöhen, wenn dies andere nicht beeinträchtigt, indem wir solche Spannungsspitzen zulassen.Wie kann man 460 Mb / s nur für eine Minute und nicht für 30 oder für immer zulassen?Wie kann man 500 Mbit / s zulassen, wenn das Band frei ist, und auf 400 drücken, wenn andere Verbraucher aufgetreten sind?Machen Sie jetzt eine Pause, gießen Sie einen Eimer stark.Beginnen wir mit dem einfacheren Mechanismus, den der Former verwendet - einem undichten Eimer.Leaky-Bucket-Algorithmus
Leaky Bucket ist ein undichter Eimer. Wir haben einen Eimer mit einem Loch einer bestimmten Größe am Boden. Taschen werden von oben in diesen Eimer gegossen. Und von unten fließen sie mit konstanter Bitrate.Wenn der Bucket voll ist, werden neue Pakete verworfen.Die Größe des Lochs wird durch die angegebene Geschwindigkeitsbegrenzung bestimmt, die für Leaky Bucket in Bit pro Sekunde gemessen wird.Das Volumen des Eimers, seine Fülle und seine Ausgangsgeschwindigkeit bestimmen die vom Former eingebrachte Verzögerung.Der Einfachheit halber wird das Schaufelvolumen normalerweise in ms oder μs gemessen.In Bezug auf die Implementierung ist Leaky Bucket ein regulärer Puffer, der auf SD-RAM basiert.Selbst wenn die Formgebung nicht explizit konfiguriert ist, werden Pakete bei Bursts, die nicht in die Schnittstelle gelangen, vorübergehend gepuffert und übertragen, wenn die Schnittstelle freigegeben wird. Das prägt auch.Leaky Bucket wird nur zum Formen verwendet und ist nicht zum Polieren geeignet.
Wir haben einen Eimer mit einem Loch einer bestimmten Größe am Boden. Taschen werden von oben in diesen Eimer gegossen. Und von unten fließen sie mit konstanter Bitrate.Wenn der Bucket voll ist, werden neue Pakete verworfen.Die Größe des Lochs wird durch die angegebene Geschwindigkeitsbegrenzung bestimmt, die für Leaky Bucket in Bit pro Sekunde gemessen wird.Das Volumen des Eimers, seine Fülle und seine Ausgangsgeschwindigkeit bestimmen die vom Former eingebrachte Verzögerung.Der Einfachheit halber wird das Schaufelvolumen normalerweise in ms oder μs gemessen.In Bezug auf die Implementierung ist Leaky Bucket ein regulärer Puffer, der auf SD-RAM basiert.Selbst wenn die Formgebung nicht explizit konfiguriert ist, werden Pakete bei Bursts, die nicht in die Schnittstelle gelangen, vorübergehend gepuffert und übertragen, wenn die Schnittstelle freigegeben wird. Das prägt auch.Leaky Bucket wird nur zum Formen verwendet und ist nicht zum Polieren geeignet.Token-Bucket-Algorithmus
Viele Leute denken, dass Token Bucket und Leaking Bucket dasselbe sind. Nur Einstein täuschte sich viel mehr und fügte eine kosmologische Konstante hinzu.Schaltchips verstehen nicht wirklich, wie spät es ist, sie werden noch schlimmer, wie viele Bits sie pro Zeiteinheit übertragen haben. Ihre Aufgabe ist es zu dreschen.Nähert sich dieses Bit weiteren 400.000.000 Bits pro Sekunde oder bereits 400.000 001? ASIC-Entwickler hatten eine nicht triviale technische Herausforderung.Es wurde in zwei Unteraufgaben unterteilt:
ASIC-Entwickler hatten eine nicht triviale technische Herausforderung.Es wurde in zwei Unteraufgaben unterteilt:- Begrenzung der Geschwindigkeit durch Verwerfen unnötiger Pakete basierend auf einer sehr einfachen Bedingung. Wird beim Schalten von Chips durchgeführt.
- Erstellen dieser einfachen Bedingung, die sich mit einem komplexeren (spezialisierteren) Chip befasst und die Zeit verfolgt.
Der Algorithmus, der das zweite Problem löst, wird als Token Bucket bezeichnet. Seine Idee ist elegant und einfach (nein).Die Aufgabe von Token Bucket besteht darin, Verkehr weiterzuleiten, wenn er unter die Beschränkung fällt, und wenn nicht, rot zu verwerfen / zu malen.Es ist wichtig, Verkehrsstöße zuzulassen, da dies normal ist.Und wenn in Leaky Bucket Bursts gepuffert wurden, puffert der Token Bucket nichts.Single Rate - Zweifarbige Markierung
Achten Sie vorerst nicht auf den Namen =) Wir haben einen Eimer, in den Münzen mit konstanter Geschwindigkeit fallen - zum Beispiel 400 Megamonet pro Sekunde.Das Volumen des Eimers beträgt 600 Millionen Münzen. Das heißt, es ist in anderthalb Sekunden gefüllt.In der Nähe befinden sich zwei Förderbänder: eines liefert Pakete, das zweite nimmt weg.Um zum Förderer zu gelangen, muss das Paket bezahlt werden.Dafür nimmt er entsprechend seiner Größe Münzen aus einem Eimer. Grob gesagt - wie viele Bits - so viele Münzen.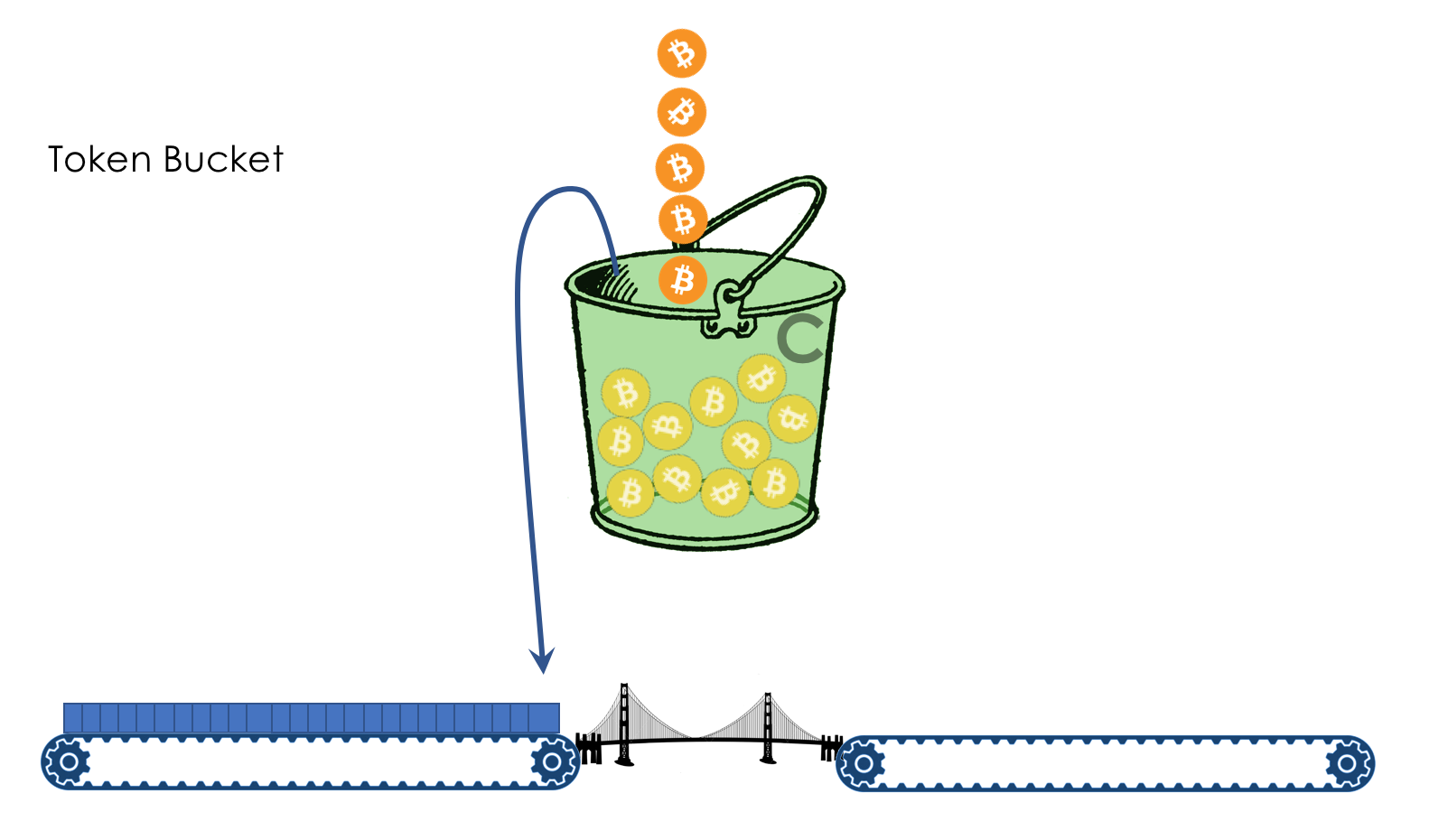
 Wenn der Eimer leer ist und sich nicht genügend Münzen im Beutel befinden, wird er in einer roten Signalfarbe gestrichen und weggeworfen. Ach, Selyava. In diesem Fall werden keine Münzen aus dem Eimer entfernt.
Wenn der Eimer leer ist und sich nicht genügend Münzen im Beutel befinden, wird er in einer roten Signalfarbe gestrichen und weggeworfen. Ach, Selyava. In diesem Fall werden keine Münzen aus dem Eimer entfernt.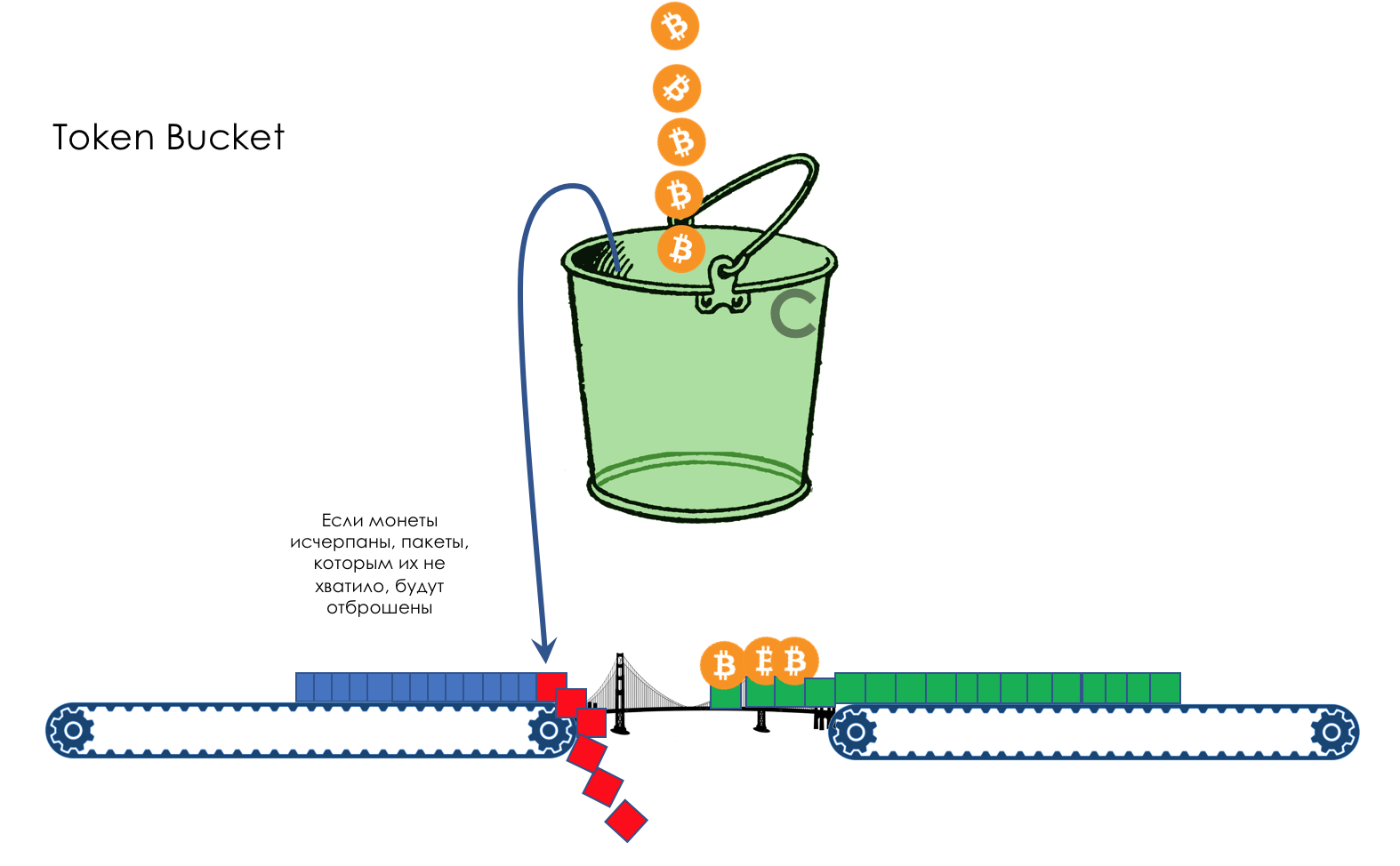 Das nächste Münzpaket reicht möglicherweise bereits aus - erstens ist das Paket möglicherweise kleiner, und zweitens greift es in dieser Zeit mehr Münzen an.Wenn der Eimer bereits voll ist, werden alle neuen Münzen weggeworfen.
Das nächste Münzpaket reicht möglicherweise bereits aus - erstens ist das Paket möglicherweise kleiner, und zweitens greift es in dieser Zeit mehr Münzen an.Wenn der Eimer bereits voll ist, werden alle neuen Münzen weggeworfen.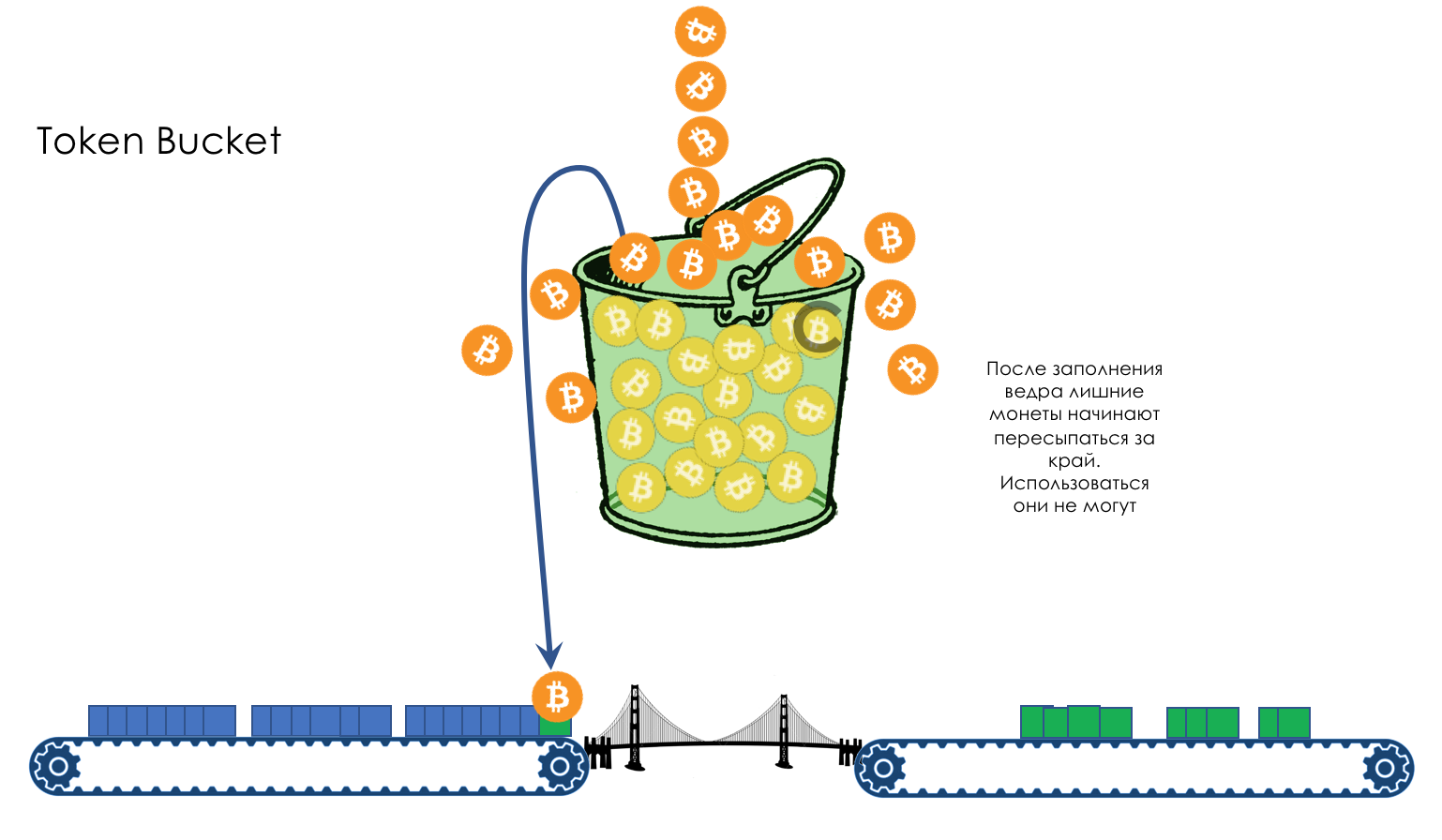 Es hängt alles von der Paketankunftsrate und ihrer Größe ab.Wenn es stabil niedriger oder gleich 400 MB pro Sekunde ist, gibt es immer genug Münzen.Wenn höher, gehen einige der Pakete verloren.
Es hängt alles von der Paketankunftsrate und ihrer Größe ab.Wenn es stabil niedriger oder gleich 400 MB pro Sekunde ist, gibt es immer genug Münzen.Wenn höher, gehen einige der Pakete verloren.Ein spezifischeres Beispiel mit Gifs, wie wir alle lieben.
- Es gibt einen Bucket mit einer Kapazität von 2500 Bytes. Zum ersten Mal enthält es 550 Token.
Die Pipeline enthält drei Pakete mit 1000 Byte, die an die Schnittstelle gesendet werden sollen.
Zu jedem Zeitschlitz fallen 500 Bytes in den Bucket (500 * 8 = 4.000 Bit / Zeitschlitz - Polyser-Limit). - 500 . . 1000 , 1050 — . . 1000 .
50 . - 500 — 550. — 1000 — .
, . - 500 — 1050. — 1000 — .
, .
2500 , 2500 — . MTU , , , 1,5-2 .
:
CBS = CIR ( )*1,5 ()/8 ( )
, (Bc), , (1 875 000 ) . (10 000 ), , MTU, .
Warum Eimervolumen? Der Bitstrom ist nicht immer gleichmäßig, dies ist offensichtlich. Ein Limit von 400 Mb / s ist keine Asymptote - der Verkehr kann es überschreiten. Das Volumen der gespeicherten Münzen ermöglicht das Überfliegen kleiner Bursts, ohne dass sie weggeworfen werden. Die Durchschnittsgeschwindigkeit liegt jedoch bei 400 MBit / s.Zum Beispiel kann der Eimer mit einem stabilen Strom von 399 Mbit / s in 600 Sekunden bis zum Rand gefüllt werden.Darüber hinaus kann der Verkehr auf 1000 Mbit / s ansteigen und 1 Sekunde lang auf diesem Niveau bleiben - 600 Mm (Megamonet) Lagerbestand und 400 Mm / s garantiertes Band.Oder der Datenverkehr kann bis zu 410 Mbit / s betragen und 60 Sekunden lang so bleiben.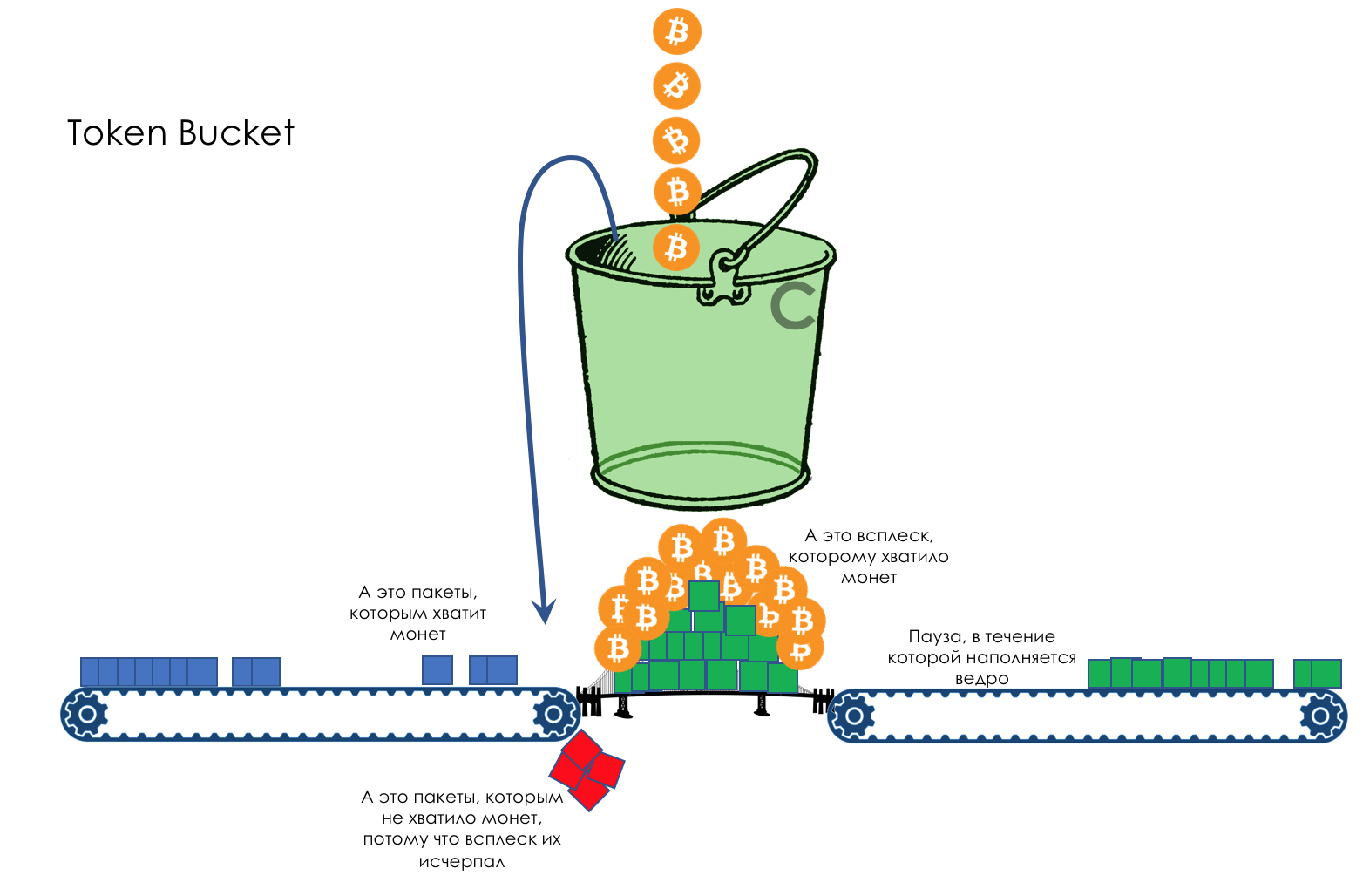 Das heißt, der Vorrat an Münzen ermöglicht es Ihnen, die Beschränkung für eine lange Zeit leicht zu überschreiten oder einen kurzen, aber hohen Anstieg zu verursachen.Nun zur Terminologie.Die Empfangsrate der Münzen im Eimer - CIR - Committed Information Rate (Garantierte Durchschnittsgeschwindigkeit). Gemessen in Bits pro Sekunde.Die Anzahl der Münzen, die im Eimer gespeichert werden können - CBS - Committed Burst Size . Zulässige maximale Burst-Größe. Gemessen in Bytes. Wie Sie vielleicht bemerkt haben, wird es manchmal Bc genannt .Tc - Die Anzahl der Münzen (Token) im C- Eimer (CBS) im Moment.
Das heißt, der Vorrat an Münzen ermöglicht es Ihnen, die Beschränkung für eine lange Zeit leicht zu überschreiten oder einen kurzen, aber hohen Anstieg zu verursachen.Nun zur Terminologie.Die Empfangsrate der Münzen im Eimer - CIR - Committed Information Rate (Garantierte Durchschnittsgeschwindigkeit). Gemessen in Bits pro Sekunde.Die Anzahl der Münzen, die im Eimer gespeichert werden können - CBS - Committed Burst Size . Zulässige maximale Burst-Größe. Gemessen in Bytes. Wie Sie vielleicht bemerkt haben, wird es manchmal Bc genannt .Tc - Die Anzahl der Münzen (Token) im C- Eimer (CBS) im Moment.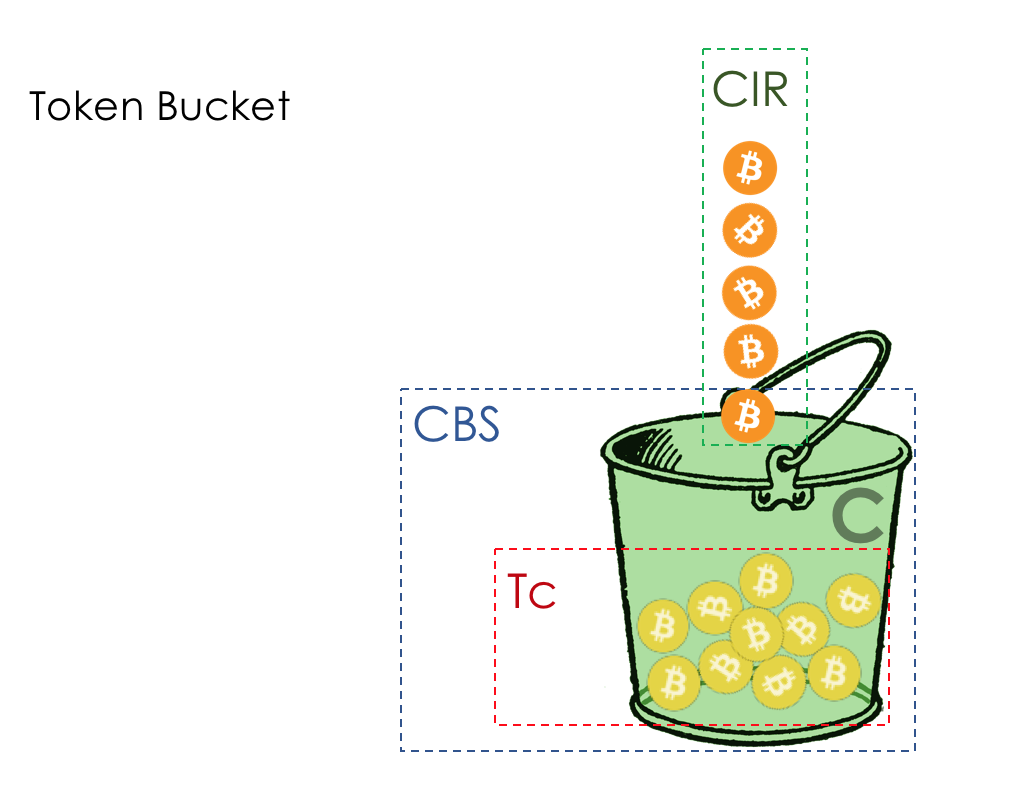
" Tc ", , RFC 2697 ( A Single Rate Three Color Marker ).
Tc, , .
.
, , Token Bucket, TDM (Time-Division Multiplexing) — .
— , , .
CIR . .
, — , — , — .
, .
( Cisco) Tc , — Bc . Bc = CIR*Tc .
Tc Bc .
Dies ist das einfachste Szenario. Es heißt Single Rate - Two Color .Single Rate bedeutet, dass es nur eine durchschnittliche zulässige Geschwindigkeit gibt und Two Color - dass Sie den Verkehr in einer von zwei Farben einfärben können: grün oder rot.- Wenn die Anzahl der verfügbaren Münzen (Bits) in Eimer C größer ist als die Anzahl der Bits, die momentan übersprungen werden müssen, wird das Paket grün gefärbt - eine geringe Wahrscheinlichkeit, in Zukunft fallen zu lassen. Münzen werden aus dem Eimer entfernt.
- Andernfalls ist die Verpackung rot gestrichen - eine hohe Wahrscheinlichkeit eines Tropfens (oder häufiger eines vorübergehenden Tropfens). Münzen so Eimer C zurückgenommen .
Wird zum Polieren in PHB CS und EF verwendet, wo keine Beschleunigung erwartet wird. Wenn dies jedoch auftritt, ist es besser, es sofort zu verwerfen.Weiter werden wir schwieriger betrachten: Single Rate - Three Color.Einzelpreis - Dreifarbige Markierung
Der Nachteil des vorherigen Schemas besteht darin, dass es nur zwei Farben gibt. Was ist, wenn wir nicht alles über die durchschnittlich zulässige Geschwindigkeit senken wollen, sondern noch loyaler sein wollen?die TCM-sr ( Einzel Rate - die drei die Farbe der Markierung ) in den zweiten Eimer in - E . Zu diesem Zeitpunkt werden die Münzen nicht in einem Eimer gegeben , der mit gefüllten C , goß in E . EBS wird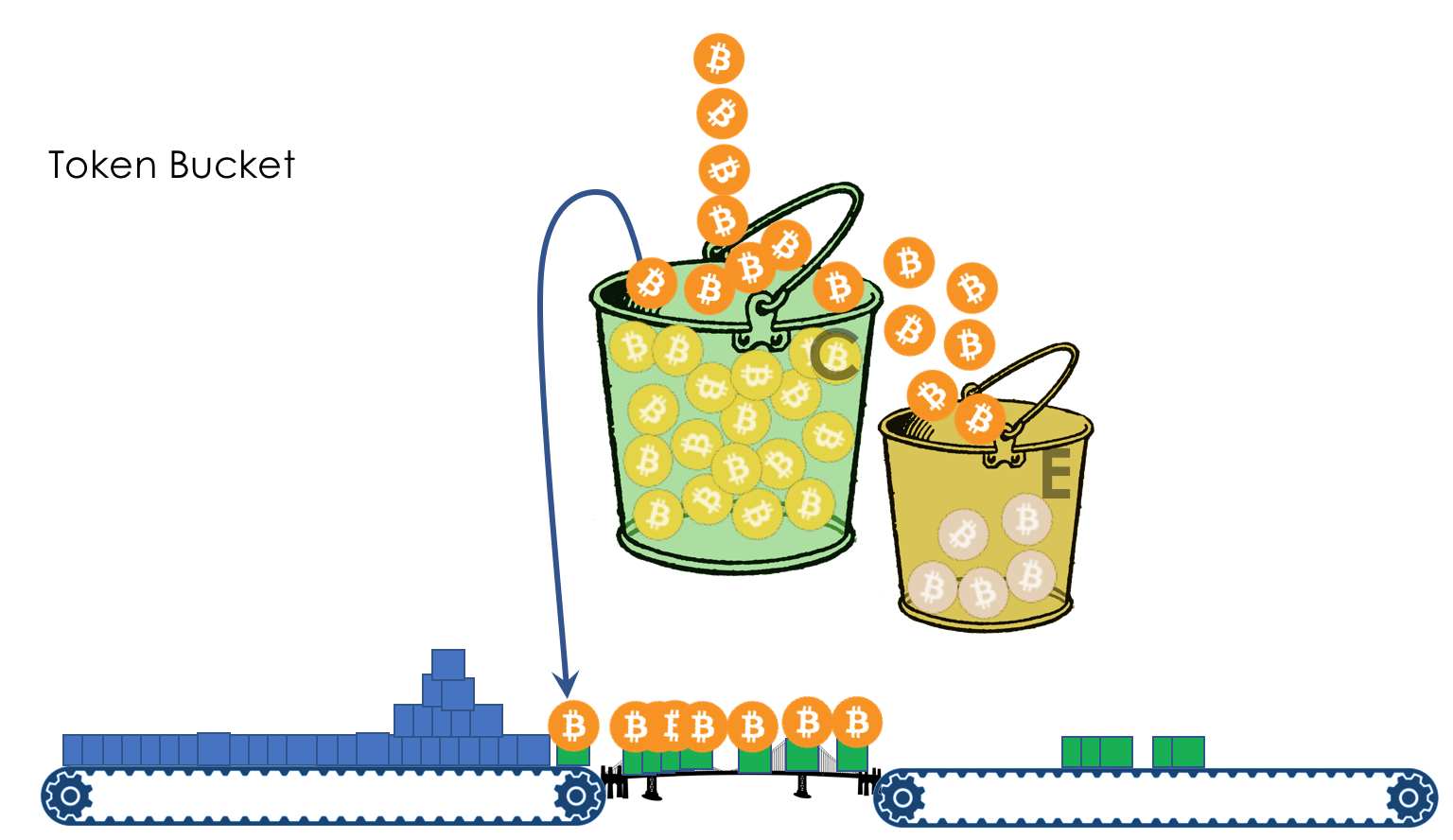 zu CIR und CBS hinzugefügt - Übermäßige Burst-Größe - Zulässige Burst-Größe während Spitzenwerten. Te - die Anzahl der Münzen in einem Eimer E .
zu CIR und CBS hinzugefügt - Übermäßige Burst-Größe - Zulässige Burst-Größe während Spitzenwerten. Te - die Anzahl der Münzen in einem Eimer E . Nehmen wir an, ein Paket der Größe B kam entlang der Pipeline.
Nehmen wir an, ein Paket der Größe B kam entlang der Pipeline. Dann
- C , . C B (: Tc — B).
- C , E . , ( ), E B .

- E , , .

Beachten Sie, dass Tc und Te für ein bestimmtes Paket nicht kumulativ sind .Das heißt, die Paketgröße von 8000 Bytes wird nicht funktionieren, wenn auch in einem Eimer C 3.000 Münzen sind, und E - 7000. Die C ist nicht genug, in der E ist nicht genug - wir einen roten Stempel aufgedrückt - shuruy hier.Dies ist ein sehr elegantes Design. Der gesamte Datenverkehr, der unter die durchschnittliche CIR + CBS-Beschränkung fällt (der Autor weiß, dass es unmöglich ist, Bits / s und Bytes so direkt hinzuzufügen), wird grün. In Spitzenzeiten, wenn dem Kunden die Münzen in Eimer C ausgehen , hat er während der Ausfallzeit immer noch Te-Vorräte in Eimer E angesammelt .Das heißt, Sie können etwas mehr überspringen, aber im Falle einer Überlastung werden sie eher verworfen.sr-TCM ist in RFC 2697 beschrieben .Wird zum Polieren in PHB AF verwendet.Nun, das letzte System ist das flexibelste und daher komplexeste - Two Rate - Three Color.Zwei Rate - Dreifarbige Markierung
Das Tr-TCM- Modell entstand aus der Idee heraus, dass es nicht zu Lasten anderer Benutzer und Verkehrstypen geht. Warum nicht dem Kunden ein wenig angenehmere Möglichkeiten bieten oder besser verkaufen?Sagen wir ihm, dass ihm 400 Mbit / s garantiert sind, und wenn es freie Ressourcen gibt, dann 500. Sind Sie bereit, 30 Rubel mehr zu zahlen?Ein weiterer Eimer P wird hinzugefügt .Auf diese Weise:
CIR - garantierte Durchschnittsgeschwindigkeit.CBS hat die gleiche zulässige Spritzgröße (Bucket-Volumen C ).PIR - Peak Information Rate - maximale Durchschnittsgeschwindigkeit.EBS - erlaubte Burst-Größe während Peaks (Bucket Volume P ).Im Gegensatz zu sr-TCM werden Münzen in tr-TCM jetzt unabhängig voneinander an beide Eimer geliefert. In C - mit der Geschwindigkeit von CIR, in P - PIR.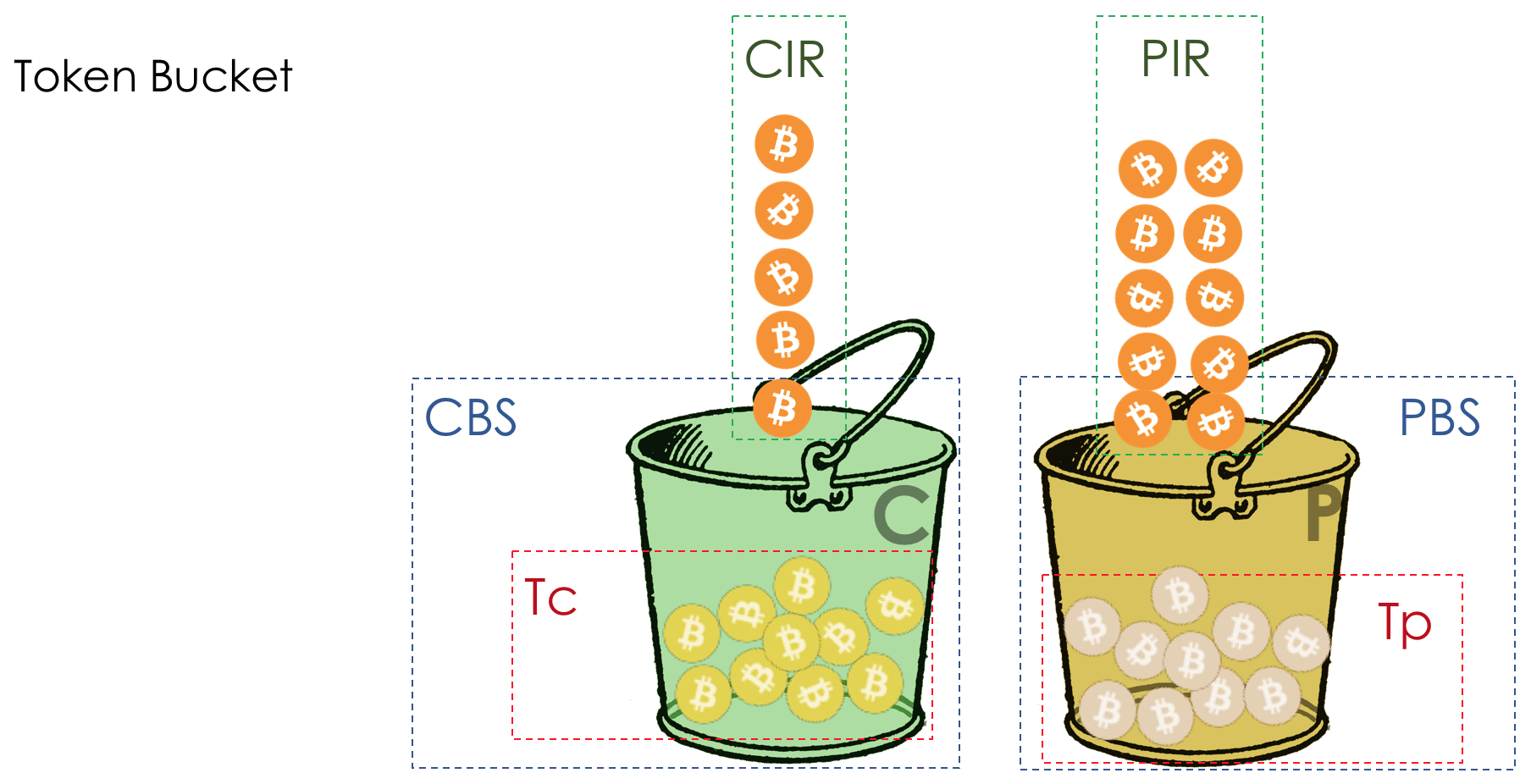 Was sind die Regeln?Ein Paket mit Bytes der Größe B kommt an .
Was sind die Regeln?Ein Paket mit Bytes der Größe B kommt an .- Befinden sich nicht genügend Münzen im Eimer P , wird das Paket rot markiert. Münzen werden nicht herausgezogen . Ansonsten:
- C — , P B . Ansonsten:
- B .
 Das heißt, die Regeln in tr-TCM sind unterschiedlich.Solange der Verkehr innerhalb der garantierten Geschwindigkeit liegt, werden Münzen aus beiden Eimern entfernt. Aus diesem Grunde, wenn die Eimer C Münzen ausgehen, in dem bleiben P , aber gerade genug , um nicht den PIR zu überschreiten (wenn auch nur aus herausgenommen C , dann P gefüllt , um mehr und gab eine viel höhere Geschwindigkeit).Dementsprechend werden die Münzen nur aus P entfernt, wenn sie über dem garantierten, aber unter dem Peak liegen , da in C bereits nichts vorhanden ist.tr-TCM überwacht nicht nur Bursts, sondern auch eine konstante Spitzengeschwindigkeit.tr-TCM ist in RFC 2698 beschrieben .Wird auch zum Polieren in PHB AF verwendet.
Das heißt, die Regeln in tr-TCM sind unterschiedlich.Solange der Verkehr innerhalb der garantierten Geschwindigkeit liegt, werden Münzen aus beiden Eimern entfernt. Aus diesem Grunde, wenn die Eimer C Münzen ausgehen, in dem bleiben P , aber gerade genug , um nicht den PIR zu überschreiten (wenn auch nur aus herausgenommen C , dann P gefüllt , um mehr und gab eine viel höhere Geschwindigkeit).Dementsprechend werden die Münzen nur aus P entfernt, wenn sie über dem garantierten, aber unter dem Peak liegen , da in C bereits nichts vorhanden ist.tr-TCM überwacht nicht nur Bursts, sondern auch eine konstante Spitzengeschwindigkeit.tr-TCM ist in RFC 2698 beschrieben .Wird auch zum Polieren in PHB AF verwendet.
Zusammenfassung der Geschwindigkeitsbegrenzung
Während das Formen den Verkehr verzögert, wenn er überschritten wird, wird er durch Polieren verworfen.Die Formgebung ist nicht für latenz- und jitterempfindliche Anwendungen geeignet.Um das Polieren in Hardware zu implementieren, wird der Token Bucket-Algorithmus zum Formen von Leaky Bucket verwendet.Token Bucket kann sein:- Mit einem Eimer - Single Rate - Zweifarbige Markierung. Ermöglicht gültige Bursts.
- Mit zwei Eimern - Single Rate - Dreifarbige Markierung (sr-TCM). Überschüsse aus Eimer C (CBS) werden in Eimer E gegossen. Ermöglicht zulässige und redundante Überspannungen.
- Mit zwei Eimern - Two Rate - Three Color Marking (tr-TCM). Die Eimer C und P (PBS) füllen sich unabhängig voneinander mit unterschiedlichen Geschwindigkeiten auf. Ermöglicht Spitzengeschwindigkeit und zulässige und übermäßige Bursts.
sr-TCM konzentriert sich auf das Verkehrsaufkommen über dem Limit. tr-TCM - mit der Geschwindigkeit, mit der es ankommt.Das Polieren kann am Ein- und Ausgang des Geräts verwendet werden. Die Formgebung erfolgt überwiegend am Ausgang.Für PHB CS und EF wird Single Rate Two Color Marking verwendet.Für AF, sr-TCM oder tr-TCM.Zum besseren Verständnis empfehle ich, auf den Original-RFC zu verweisen oder hier zu lesen .Token Bucket . , , , , .
, — , . , , , — .
, . — . .
Oben habe ich alle grundlegenden Mechanismen der QoS beschrieben, wenn nicht sogar die hierarchische QoS. Ein ausgeklügeltes System mit vielen beweglichen Teilen.Alles war in Ordnung (richtig?) Hat bisher geklungen, aber was passiert unter der Vanille-Außenverkleidung des Routers?Im Laufe der Jahre haben Anbieter immer mehr Konturen hinzugefügt, ausgefeilte Chips entwickelt und Puffer erweitert, um einerseits mit dem wachsenden Verkehrsaufkommen und seinen neuen Kategorien Schritt zu halten und andererseits die durch den ersten Absatz verursachten wachsenden Probleme zu lösen.Das laufende Rennen. Pakete dürfen nicht verloren gehen, wenn der Wettbewerber sie nicht verliert. Sie können die Funktionalität nicht ablehnen, wenn ein Gegner mit ihm unter den Türen des Kunden steht.Ida in die Höhle des Eigentums!9. Hardware-Implementierung von QoS
In diesem Kapitel übernehme ich die undankbare Aufgabe. Wenn Sie es so einfach wie möglich beschreiben, wird es immer diejenigen geben, die sagen, dass in der Realität nicht alles so ist.Wenn Sie es so beschreiben, wie es ist, lässt der Leser den Artikel fallen, da er sich in eine U-Boot-Zeichnung verwandelt, genauer gesagt in Zeichnungen von drei Booten mit Bleistiften unterschiedlicher Farbe auf einem Blatt.Im Allgemeinen werde ich einen Haftungsausschluss machen, dass in Wirklichkeit nicht alles das gleiche ist wie in der Realität, und ich werde nach der Version einer einfachen Präsentation vorgehen.Vergib mir, mein Perfektionist.Was steuert das Verhalten des Knotens und löst die entsprechenden Mechanismen in Bezug auf das Paket aus? Welche Priorität hat es in einer der Überschriften? Ja und nein.
 Wie oben erwähnt, existiert in einem Netzwerkgerät der Standard-Switching-Header normalerweise nicht mehr.
Wie oben erwähnt, existiert in einem Netzwerkgerät der Standard-Switching-Header normalerweise nicht mehr. Sobald ein Paket am Vermittlungs-Chip ankommt, werden Header von diesem entfernt und zur Analyse gesendet, und die Nutzlast schwindet in einer Art temporärem Puffer.Basierend auf den Headern findet eine Klassifizierung (BA oder MF) statt und eine Entscheidung über die Weiterleitung wird getroffen.Nach einem Moment wird ein interner Header mit Metadaten zum Paket an das Paket gehängt.Diese Metadaten enthalten viele wichtige Informationen - die Adresse des Absenders und Empfängers, der Ausgangschip, die Seriennummer der Zelle, wenn eine Paketfragmentierung aufgetreten ist, sowie die Klassenmarkierung (CoS) und die Drop-Priorität sind obligatorisch. Nur Markierung im internen Format - es kann mit dem DSCP übereinstimmen oder nicht.Im Prinzip können Sie innerhalb der Box eine beliebige Markierungslänge festlegen, ohne an Standards gebunden zu sein, und mit dem Paket sehr flexible Aktionen definieren.Bei Cisco heißt die interne Kennzeichnung QoS Group, bei Juniper - Forwarding Class hat Huawei nicht entschieden: irgendwo werden interne Prioritäten genannt, irgendwo lokale Prioritäten, irgendwo Service-Class und irgendwo nur CoS. Fügen Sie Namen für andere Anbieter in den Kommentaren hinzu - ich werde hinzufügen.Diese interne Markierung wird basierend auf der vom Knoten durchgeführten Klassifizierung zugewiesen.Es ist wichtig, dass die interne Kennzeichnung, sofern nicht anders angegeben, nur innerhalb des Knotens funktioniert, dann aber nicht auf dem Etikett in den Headern des Pakets erscheint, das vom Knoten gesendet wird - sie bleibt gleich.Am Eingang zur DS-Domäne nach der Klassifizierung erfolgt jedoch normalerweise eine Neukennzeichnung in einer bestimmten in diesem Netzwerk akzeptierten Dienstklasse. Anschließend wird die interne Kennzeichnung in den für diese Klasse im Netzwerk akzeptierten Wert konvertiert und im Header des gesendeten Pakets aufgezeichnet.Die interne Kennzeichnung von CoS und Drop Precedence definiert das Verhalten nur innerhalb eines bestimmten Knotens und wird nicht explizit an die Nachbarn weitergegeben, außer für die erneute Kennzeichnung von Headern.CoS und Drop Precedence definieren den PHB, seine Mechanismen und Parameter: Stauverhütung, Überlastungsmanagement, Planung und Neukennzeichnung.
Sobald ein Paket am Vermittlungs-Chip ankommt, werden Header von diesem entfernt und zur Analyse gesendet, und die Nutzlast schwindet in einer Art temporärem Puffer.Basierend auf den Headern findet eine Klassifizierung (BA oder MF) statt und eine Entscheidung über die Weiterleitung wird getroffen.Nach einem Moment wird ein interner Header mit Metadaten zum Paket an das Paket gehängt.Diese Metadaten enthalten viele wichtige Informationen - die Adresse des Absenders und Empfängers, der Ausgangschip, die Seriennummer der Zelle, wenn eine Paketfragmentierung aufgetreten ist, sowie die Klassenmarkierung (CoS) und die Drop-Priorität sind obligatorisch. Nur Markierung im internen Format - es kann mit dem DSCP übereinstimmen oder nicht.Im Prinzip können Sie innerhalb der Box eine beliebige Markierungslänge festlegen, ohne an Standards gebunden zu sein, und mit dem Paket sehr flexible Aktionen definieren.Bei Cisco heißt die interne Kennzeichnung QoS Group, bei Juniper - Forwarding Class hat Huawei nicht entschieden: irgendwo werden interne Prioritäten genannt, irgendwo lokale Prioritäten, irgendwo Service-Class und irgendwo nur CoS. Fügen Sie Namen für andere Anbieter in den Kommentaren hinzu - ich werde hinzufügen.Diese interne Markierung wird basierend auf der vom Knoten durchgeführten Klassifizierung zugewiesen.Es ist wichtig, dass die interne Kennzeichnung, sofern nicht anders angegeben, nur innerhalb des Knotens funktioniert, dann aber nicht auf dem Etikett in den Headern des Pakets erscheint, das vom Knoten gesendet wird - sie bleibt gleich.Am Eingang zur DS-Domäne nach der Klassifizierung erfolgt jedoch normalerweise eine Neukennzeichnung in einer bestimmten in diesem Netzwerk akzeptierten Dienstklasse. Anschließend wird die interne Kennzeichnung in den für diese Klasse im Netzwerk akzeptierten Wert konvertiert und im Header des gesendeten Pakets aufgezeichnet.Die interne Kennzeichnung von CoS und Drop Precedence definiert das Verhalten nur innerhalb eines bestimmten Knotens und wird nicht explizit an die Nachbarn weitergegeben, außer für die erneute Kennzeichnung von Headern.CoS und Drop Precedence definieren den PHB, seine Mechanismen und Parameter: Stauverhütung, Überlastungsmanagement, Planung und Neukennzeichnung.
Welche Kreise passieren Pakete zwischen den Eingabe- und Ausgabeschnittstellen? Ich habe dies in einem vorherigen Artikel überprüft . Tatsächlich stellte sich heraus, dass dies nicht geplant war, da sich irgendwann herausstellte, dass es verfrüht war, über QoS zu sprechen, ohne die Architektur zu verstehen.Lassen Sie uns jedoch wiederholen.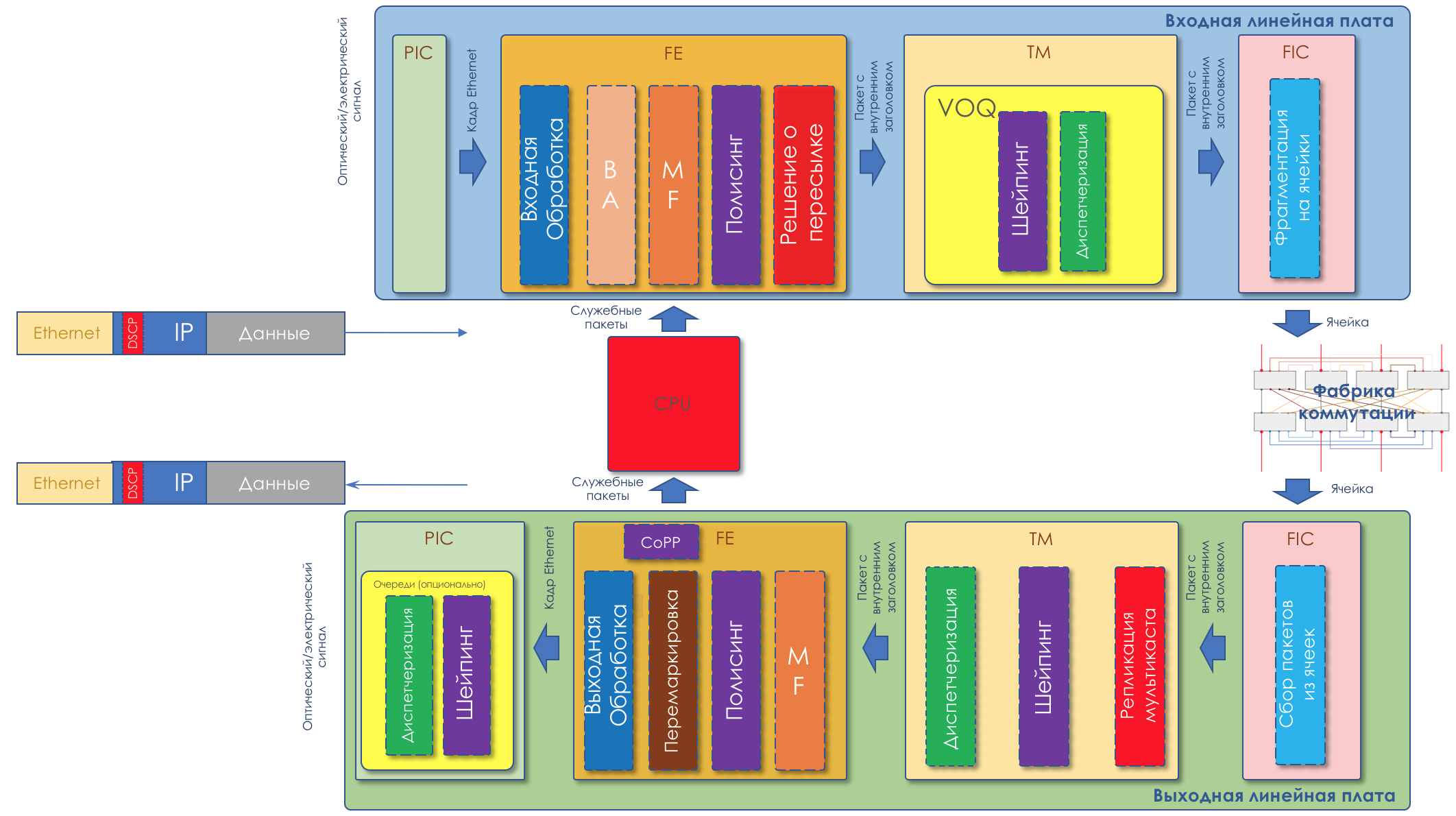
- Das Signal trifft auf die physikalische Eingangsschnittstelle und ihren Chip (PIC). Daraus fließt ein Bitstrom und dann ein Paket mit allen Headern.
- Neben dem Eingangsvermittlungschip (FE), wo die Header vom Paketkörper getrennt sind. Die Klassifizierung erfolgt und es wird bestimmt, wohin das Paket weiter gesendet werden muss.
- Neben der Eingabewarteschlange (TM / VOQ). Bereits hier sind die Pakete je nach Klasse in verschiedenen Warteschlangen angeordnet.
- Weiter zur Schaltfabrik (falls vorhanden).
- Neben der Ausgabewarteschlange (TM).
- (FE), .
- (, ) (PIC).
In diesem Fall muss der Router eine komplexe Gleichung lösen.Erweitern Sie alles in Klassen, stellen Sie jemandem ein breites Band zur Verfügung, jemandem mit geringer Latenz, jemandem, der keine Verluste sicherstellt.Und gleichzeitig Zeit haben, wenn möglich den gesamten Verkehr zu überspringen.Darüber hinaus müssen Sie formen, möglicherweise polieren. Wenn plötzlich eine Überlastung auftritt, gehen Sie damit um.Dabei werden die Suchvorgänge, die ACL-Verarbeitung und die Statistik nicht berücksichtigt.Nicht beneidenswerter Anteil. Aber Roboter spritzen, kein Mann.Tatsächlich gibt es nur zwei Stellen, an denen QoS-Mechanismen funktionieren - einen Switching-Chip und einen Traffic Management-Chip / eine Warteschlange.Gleichzeitig treten auf dem Vermittlungs-Chip Operationen auf, die eine Analyse oder Aktionen mit Headern erfordern.- Klassifizierung
- Polieren
- Umbenennen
TM kümmert sich um den Rest. Grundsätzlich handelt es sich hierbei um Routineoperationen mit einem vordefinierten Algorithmus und benutzerdefinierten Parametern:- Stauprävention
- Überlastungsmanagement
- Formen
TM ist ein intelligenter Puffer, der normalerweise auf SD-RAM basiert.Er ist schlau, weil er a) programmierbar ist, b) mit Warteschlangen alle möglichen kniffligen Dinge tun kann.Es wird häufig verteilt - SD-RAM-Chips befinden sich auf jeder Schnittstellenkarte und werden zusammen zu VOQ (Virtual Output Queue) kombiniert, wodurch das Problem des Head of Line Blocking gelöst wird.Tatsache ist, dass wenn der Schaltchip oder die Ausgangsschnittstelle verstopft sind, sie den Eingangschip auffordern, langsamer zu werden und für einige Zeit keinen Verkehr zu senden. Wenn es nur eine Warteschlange in alle Richtungen gibt, ist es sehr enttäuschend, dass alle anderen unter einer Ausgabeschnittstelle leiden. Dies ist der Head of Line Blocking.VOQ erstellt auf der Eingabeschnittstellenkarte mehrere virtuelle Ausgabewarteschlangen für jede vorhandene Ausgabeschnittstelle.Darüber hinaus berücksichtigen diese Linien in modernen Geräten die Kennzeichnung der Verpackung.Über VOQ ausreichend in einer Reihe von Notizen detailliert hier .Übrigens werden sie wirklich in die Warteschlange gestellt, sie werden befördert, es sind nicht die Pakete selbst, die von ihnen beschlagnahmt werden usw., sondern nur die Aufzeichnungen über sie. Es macht keinen Sinn, so viele Gesten mit großen Bit-Arrays auszuführen. Während QoS über die Datensätze verspottet wird, befinden sich die Pakete perfekt in ihrem Speicher und werden von dort unter der Adresse abgerufen.VOQ ist eine Software-Warteschlange (der englische Begriff Software-Warteschlange ist genauer). Unmittelbar vor der Schnittstelle befindet sich eine Hardware-Warteschlange, die immer streng nach FIFO arbeitet. Es ist fast unmöglich, einen seiner Parameter zu steuern (mit Cisco können Sie beispielsweise nur die Tiefe mit dem Befehl tx-ring-limit konfigurieren).Nur zwischen den Software- und Hardware-Warteschlangen können Sie beliebige Dispatcher ausführen. In der Programmwarteschlange arbeiten Head / Tail-Drop und AQM, Polieren und Formen.Die Größe der Hardware-Warteschlange ist sehr klein (Einheiten von Paketen), da der Dispatcher die gesamte Arbeit zum Stapeln der Leitungsrate erledigt.Leider können Sie hier viele Reservierungen vornehmen und in der Tat alles mit einem roten Stift streichen und sagen "Anbieter X ist nicht so".
Ich möchte noch eine Bemerkung zu Servicepaketen machen. Sie werden anders behandelt als Transitbenutzerpakete.Sie werden lokal generiert und nicht auf Einhaltung der ACL-Regeln und Geschwindigkeitsbegrenzungen überprüft.Pakete von außen, die für die CPU vom Ausgangsvermittlungschip bestimmt sind, fallen je nach Protokolltyp in andere Warteschlangen - an die CPU.Zum Beispiel hat BFD die höchste Priorität, OSPF kann länger warten und ICMP ist im Allgemeinen nicht unheimlich zu fallen. Das heißt, je wichtiger das Paket für das Netzwerk ist, desto höher ist seine Serviceklasse beim Senden an die CPU. Aus diesem Grund ist es normal, dass beim Ping oder Tracing unterschiedliche Verzögerungen beim Transit-Hop auftreten. ICMP ist kein vorrangiger Datenverkehr für die CPU.Zusätzlich werden Protokollpakete angewendetCoPP - Control Plane Protection (oder Policing) - Geschwindigkeitsbegrenzung zur Vermeidung einer hohen CPU-Auslastung - wieder besser vorhersehbare Einbrüche in Warteschlangen mit niedriger Priorität, bevor Probleme auftreten.CoPP hilft sowohl bei gezielten DoS als auch bei abnormalem Netzwerkverhalten (z. B. Schleifen), wenn viel Broadcast-Verkehr auf das Gerät gelangt.
Nützliche Links
- Das beste Buch über Theorie und Philosophie von QoS: QOS-fähige Netzwerke: Tools und Grundlagen .
Einige Auszüge davon können hier gelesen werden , aber ich würde empfehlen, es von und nach zu lesen und nicht auszutauschen. - QoS Huawei: Special Edition QoS(v6.0) . PHB .
- sr-TCM tr-TCM : Understanding Single-Rate and Dual-Rate Traffic Policing .
- VOQ: What is VOQ and why you should care?
- QoS MPLS: MPLS and Quality of Service .
- QoS Juniper: Juniper CoS notes .
- QoS TCP UDP. : The TCP/IP Guide
- , , : TCP .
- , FQ: Queuing and Scheduling .
, , An Introduction to Computer Networks , , Introduction, . .
- WFQ , , , , , : Weighted Fair Queueing: a packetized approximation for FFS/GP.
- Es gibt auch den LFI-Mechanismus, auf den ich nicht eingegangen bin, da er in unserer Realität auch mit 100-Gigabyte-Schnittstellen schwierig ist, aber es könnte interessant sein, sich mit folgenden Themen vertraut zu machen: Link Fragmentation and Interleaving .
Und natürlich die RFC-Suite ... Fazit
Diese Version hatte viele Rezensenten.Vielen Dank.
Alexander Fatin ( LoxmatiyMamont ) für ein einleitendes Wort und wertvolle Ratschläge zur Ausdruckskraft und Klarheit des Textes.Alexander Clipper (@ metallicat20) für sein Peer Review.Alexander Klimenko (@ v00lk) für scharfe Kritik und die massivsten Veränderungen der letzten Tage.Andrey Glazkov (@glazgoo) für Kommentare zu Struktur, Terminologie und Kommas.Artyom Chernobay für KDPV.Anton Klochkov (@NAT_GTX) für Kontakte mit Miran.Miran (miran.ru) für die Organisation eines Servers mit Eva und Broadcast. Traditionell meine Familie, die diesmal jedoch am wenigsten unter ihrer Abwesenheit in den schwierigsten Momenten litt.