Vorwort
Alles begann vor mehr als zwei Jahren, und ich wechselte zum vierten Jahr der Fachrichtung "Wirtschaftsinformatik" der Staatlichen Universität für Steuerungssysteme und Radioelektronik (TUSUR) in Tomsk. Bis zum Ende der Universität blieb nicht viel Zeit, und die Aussicht, ein Diplom zu schreiben, zeichnete sich bereits vor unseren Augen ab. Die Idee, fertige Arbeiten zu kaufen, wurde nicht berücksichtigt. Ich wollte wirklich selbst etwas tun. Für die Themen Diplomprojekte gab es viele Möglichkeiten: sowohl Konfigurationsprojekte zur Automatisierung der Produktionsanforderungen des Unternehmens als auch das Projekt zur eigenständigen Implementierung des Dokumentenmanagements für 3 Gebietseinheiten und mehr als 500 aktive Benutzer sowie die Einführung von EDI. Kurz gesagt, viel von allem war in meinem Kopf, aber nichts davon inspirierte mich. Und das war die Hauptsache.
Zu dieser Zeit arbeitete ich in einem seriösen Unternehmen und traf in geschäftlichen Angelegenheiten einen coolen Programmierer und im Allgemeinen einen guten Menschen. Andrei Shcheglov (Hi Andrei!) Und irgendwie = während eines Gesprächs fragte er mich, ob ich etwas über OneScript und gehört habe Gurkenskriptsprache. Auf die ich eine Antwort erhielt, die ich nicht hörte. Natürlich führten der Abend Google / Yandex und die schlaflose Nacht zu der Idee, dass es hier ist - die Welt des Unbekannten. Die Idee, dass dies Gegenstand einer These sein könnte, ist jedoch noch nicht entstanden. Der routinemäßige Aufgabenkreis war die übliche Arbeit im 1C-Konfigurator in Bezug auf die Aufgaben, wie Sie mit manuellen Tests verstehen und es Ihnen nicht ermöglichten, vollständig in einen neuen Ansatz in der 1C-Welt einzutauchen.
Unbekannte Konzepte
Die erste Schwierigkeit, auf die ich stieß, war eine unglaubliche Menge verschiedener Terminologien und Tools, von denen ich überhaupt nichts gehört hatte - da ich in diesem Moment ein „typischer Odnosnik“ war (in diesem Moment beginnt der Holivar ...), insbesondere ohne andere Programmiersprachen zu kennen und Außerdem waren mir die Methoden der Big IT völlig unbekannt, ich musste von Thema zu Thema springen, um zumindest irgendwie mein Glossar zu füllen.
Fast im selben Moment stand ich (wir - und meine Kollegen) vor einem ziemlich spezifischen Problem. Sie nahmen das Softwaremodul vom Auftragnehmer und überprüften es auf Kopien. Alles scheint zu funktionieren. Aber da es viel Arbeit gab, unterschrieben sie einen Akt der abgeschlossenen Arbeit und warfen ihn in die Produktivität. Sechs Monate lang war alles in Ordnung, bis die Daten in diesem Subsystem die zulässigen Werte nicht überschritten. Und sehr seltsame Dinge begannen zu passieren. Das Durchführen eines Dokuments aus dem Modul begann 5-10 Minuten lang, es traten eine Reihe von Fehlern auf usw. Das Anzeigen des Programmcodes war schrecklich (fragen Sie nicht, warum dies vorher nicht getan wurde, als Sie akzeptierten ...). Die Anzahl der verschachtelten Zyklen lag knapp über dem vernünftigen Wert. Die einzige Anfrage im vierten Zyklus und die Berufung durch 4 Punkte waren Kleinigkeiten, die alle vorherigen Dokumente durchliefen, um das aktuelle Dokument auszufüllen, 10-faches Kopieren und Einfügen desselben Blocks und vieles mehr.
Verschachtelungsbeispiel:

Duplizieren von Feldern im Layout:

Um diese Felder auszufüllen, wird außerdem eine 14-fache Kopie kopiert.
Beginn des Zyklus:

Und bis die FF-Variable 15 erreicht:

Nun, und eine Reihe anderer ebenso einzigartiger Kunstwerke.
Plötzlich fiel mir ein, dass es für OneScript eine einfache Bibliothek zur Berechnung der "Zyklomatizität" von Modul (1) (der Komplexität eines Moduls oder einer Methode) gibt. Gefunden, berechnet. Ich erhielt einen Wert von 163 Einheiten mit einem gültigen Wert von nicht mehr als 10. Und ich kam zu dem Schluss, dass die Abnahmeprüfung des Programmcodes obligatorisch und automatisch und kontinuierlich sein sollte. Dann erfuhr ich von Continuous Inspection - und wie sich 2006 herausstellte, veröffentlichte IBM (2) eine Veröffentlichung zu diesem Thema.
Weiter mehr. Wahrscheinlich sind viele Mitarbeiter großer Unternehmen auf das Problem gestoßen, eine Kopie der Arbeitsbasis auf dem lokalen Computer des Entwicklers bereitzustellen. Wenn diese Basis 5-10 Gigabyte wiegt - das ist kein Problem, und wenn sie nur im Backup fast ein Terabyte wiegt, ist dies bereits ernst. Infolgedessen dauerte die Bereitstellung einer neuen Kopie 5 bis 6 Stunden. Als ich es satt hatte, fing ich an, ein sehr gutes Tool 1C-Deploy-and-CopyDB zu verwenden (Anton danke!). Dann wurde mir klar, dass Automatisierung cool ist.
Darüber hinaus gab es andere Aufgaben, z. B. regelmäßige Aktualisierung der Haupt- und verteilten Basis aus dem Speicher bei Nacht, Formulartests, Szenariotests usw. Einiges davon wurde realisiert, andere nicht.
Aber das alles war nur für mich notwendig. Bei der Suche nach Gleichgesinnten in seiner Stadt scheiterte er praktisch. Sie sind nicht da. Obwohl schrecklich seltsam, da die Probleme typisch sind. Zu diesem Zeitpunkt wusste ich bereits, dass ich meine Diplomarbeit zu diesem Thema schreiben wollte. Aber ich wusste nicht, was ich schreiben sollte. Deshalb musste ich mich der Community anschließen, um nicht nur zu lesen, sondern zumindest zu schreiben und Fragen zu stellen. Die wichtigsten Orte, an denen Sie Fragen stellen können, waren
Github-Projekte:
• https://github.com/silverbulleters/add
• https://github.com/oscript-library/opm
• https://github.com/EvilBeaver/OneScript
• https://github.com/silverbulleters/vanessa-runner/
XDD-Forum:
• 1Script-Abschnitt
• Testabschnitt
• Abschnitt Prozessautomatisierung
Gut und als Mittel zur schnellen Kommunikation - Profilgruppen in Gitter
Die Sammlung von Material hat begonnen. Wie es das Schicksal wollte, gelang es mir, Alexey Lustin alexey-lustin (Hallo Alexey!) Zu kontaktieren und im XDD-Forum über meine Diplomidee zu sprechen. Zu dem ich überrascht war, zustimmendes Feedback und sogar eine Einladung zu hören, sich bei Silver Bullet vor dem Abschluss zu üben. Es war schon ein Sieg. Mehrere Stunden lang haben wir uns mit dem Thema und dem Inhalt des Diploms befasst. Wir stellen Aufgaben für die praktische Arbeit. Ich habe den Leiter des Diplomprojekts von der Firma bekommen - Arthur Ayukhanov (Arthur hi!) Wie der junge Padawan Zugang zum Videokurs des Release Engineers bekam und die Fähigkeit, Nikita Gryzlov (Hi Nikita!) Unbegrenzt mit seinen Fragen zu bekommen, für die er sehr dankbar ist.
Zusammenfassend:
Das Thema des Diploms lautet „Automatisiertes Lebenszyklusmanagement von Informationssystemen - System- und Softwareentwicklung von Lösungen auf der 1C: Enterprise-Plattform unter den Bedingungen einer kontinuierlichen Verbesserung der Qualität des Produktionsprozesses“.

Der Zweck der abschließenden Qualifizierungsarbeit (WRC) besteht darin, die Beziehung zwischen Softwaretools und eine Beschreibung des Geschäftsprozesses der DevOps-Schaltung im 1C-Bereich zu identifizieren.
Die theoretische Begründung des Projekts war der Standard für die kontinuierliche Verbesserung der Servicequalität von ITIL 3.0, und das praktische Ziel war die Erstellung einer kontinuierlichen Integrationsschleife für die neue Anwendungslösung, die wir entwickelt haben - das persönliche Konto des Kunden. Zu diesem Zweck wurden der GitLab-Quellserver und die Jenkins-Build-Schleife bereitgestellt. Die Tests wurden auf einem dedizierten Server (Windows Slave) ausgeführt. Die Konfiguration wurde mithilfe der Gitsync- Bibliothek, Version 3.0, aus dem 1C-Repository entladen
(derzeit in der Entwicklungsabteilung) bereits mit den Erfolgen von Alexei Khorev (Lech hallo!) mit einer Frequenz von 30 Minuten in der Entwicklungsabteilung. Der Grund für die Wahl dieser speziellen Version war die Möglichkeit, über das TCP-Protokoll eine Verbindung zum Repository herzustellen, das zu diesem Zeitpunkt leider kein typisches GitSync 2.x unterstützte. Wenn Änderungen in GitLab aufgezeichnet wurden, wurde der Lauf der kontinuierlichen Integrationsschleife automatisch gestartet.
Da das Budget der gesamten Veranstaltung Null war und die Möglichkeit, eine vollständige Qualitätskontrolle des Programmcodes zu erstellen, ohne ein Modul für SonarQube zu kaufen, unmöglich war, wurde eine standardmäßige 1C-Syntaxprüfung als vereinfachte Lösung verwendet. Obwohl das einmalige Entladen dennoch durchgeführt wurde, wurden die Ergebnisse erhalten und analysiert. Zusätzliche Überprüfungen auf Zyklizität und auf das Vorhandensein von wiederverwendbarem Code wurden ebenfalls verwendet.
Beim Testen der Funktionalität wurden 2 Vanessa-Behaviour- und XUnitFor1C-Frameworks in ihrer kombinierten Version namens Vanessa Automation Driven Development (Vanessa ADD) verwendet. Der erste wurde verwendet, um das erwartete Verhalten zu testen, der zweite war das Überprüfen des Öffnens von Formularen (Rauchtest). Das Bestehen der kontinuierlichen Integrationsschleife führte zu automatisch generierten Berichten.
Den Testergebnissen zufolge traf der Release-Ingenieur die Entscheidung, die Entwicklungs- und Master-Zweige zusammenzuführen, und startete (bereits manuell) die dritte Aufgabe - die Veröffentlichung von Änderungen an der Produktivdatenbank. Die produktive Datenbank ist nicht mit dem Repository verbunden und wird aufgrund manueller Änderungen vollständig geschlossen. Die Aktualisierung erfolgt nur durch Lieferung und im automatischen Modus.
Um den Geschäftsprozess der Schaltung zu beschreiben, wurde ein IDEF0-Diagramm gebildet, das aus 4 aufeinanderfolgenden Blöcken besteht, die den Durchgang der Schaltung bilden. Ein Fehler, der beim Durchlaufen einer der Phasen auftritt, unterbricht den Assemblierungsprozess mit einer Benachrichtigung an den Release-Techniker und überträgt die Steuerung an den 5. Block des Assemblierungsprozesses, in dem Berichte im Format ALLURE, JUNIT und natürlich cucumber.json generiert werden.
IDEF0 Modellbeschreibung
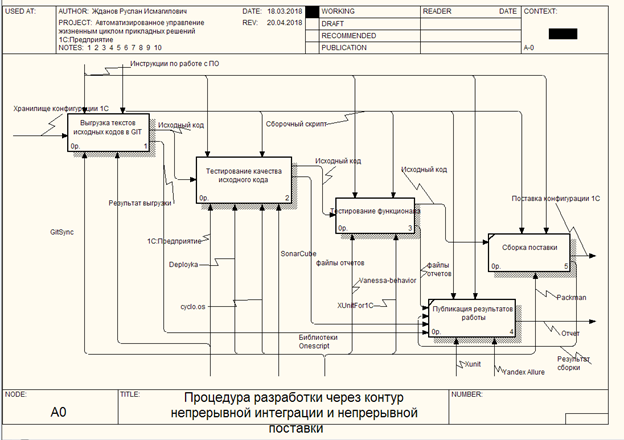
Der Prozess des "Entladens des Quellcodes in GIT"
Eingabedaten: - Konfigurations-Repository
Ausgabe (Ausgabe): - Quellcode
Steuerung: Anweisungen zum Arbeiten mit Software, Assemblerskript
Mechanismus: 1C: Enterprise, Gitsync .
Voraussetzung für das Vorhandensein der Kontur ist das Vorhandensein von Quelldateien. Ab der Plattformversion 8.3.6 bot 1C die Möglichkeit, Konfigurationsquellcodes in Dateien hochzuladen. Es ist zu beachten, dass dieser Prozess abhängig von den Besonderheiten der Entwicklung in der IT-Abteilung mehrere Optionen haben kann. In der aktuellen Version wurde zur Vereinfachung des Übergangs von Mitarbeitern zur neuen Methodik die Integration in den aktuellen Entwicklungsprozess über den Konfigurationsspeicher und die Verwendung des 1C-Konfigurators durchgeführt.
In der Phase des Prozesses „Entladen von Quellen in GIT“ wird die Datei, Service Information Base 1C, erstellt. Es wurde mit dem Konfigurationsspeicher unter dem Dienstkonto verbunden. Alle Änderungen werden zum aktuellen Zeitpunkt (oder zum letzten Commit im Repository) empfangen. Quellcodes wurden in das Assembly-Verzeichnis entladen. dem Speichersystem der GIT-Version verpflichtet; Änderungen werden an den GitLab-Quellserver gesendet
Der Prozess des „Testens der Qualität des Quellcodes“
Eingabedaten: - Quellcode
Ausgabe (Ausgabe): - Quellcode
Steuerung: Anweisungen zum Arbeiten mit Software, Assemblerskript
Mechanismus: 1C: Enterprise, Deployka , SonarQube , Cyclo.os - (leider gibt es keinen Link)
Zu Beginn dieses Prozesses wird der Quellcode im GitLab-Repository gespeichert. Mit dem Steuerungsskript (Assembly) wird es im Assemblyverzeichnis empfangen. Mit Hilfe der 1C: Enterprise-Plattform, die auf diesen Quellcodes basiert, wird eine Service-Informationsbasis bereitgestellt. Eine Fehleranalyse wird mit den Plattform-Tools durchgeführt. Wenn während der Analyse Programmcodefehler festgestellt werden, die keine Zusammenstellung der Konfiguration ermöglichen, wird der Prozess unterbrochen. Ziel dieses Schritts ist es, Zeitverschwendung bei der Analyse des Programmcodes einer nicht funktionsfähigen Konfiguration zu vermeiden.
Nach der Überprüfung auf Fehler wird die Berechnung der zyklomatischen Komplexität des Programmcodes gestartet. Eine Erhöhung dieses Koeffizienten wirkt sich erheblich auf das Debuggen und die Analyse von Programmcode aus. Der maximal zulässige Wert ist 10. Bei Überschreitung wird eine Ausnahme ausgelöst und der Code zur Überarbeitung zurückgegeben.
Der letzte Schritt bei der Analyse der Qualität des Programmcodes besteht darin, die Einhaltung der Entwicklungsstandards zu überprüfen. Für diese Zwecke verwendet das vorgeschlagene Schema den SonarQube-Dienst und das von ihm von Silver Bullet entwickelte 1C-Syntaxunterstützungsmodul. Basierend auf den Ergebnissen der Analyse berechnet das System den Wert der technischen Schulden für jeden Mitarbeiter, der den Programmcode gebucht hat.
Funktionstestprozess
Eingabedaten: - Quellcode
Ausgabe (Ausgabe): - Quellcode
Steuerung: Anweisungen zum Arbeiten mit Software, Assemblerskript
Mechanismus: 1C: Unternehmen, Vanessa-Verhalten, XunitFor1C .
Während des Entwicklungsprozesses können Situationen auftreten, in denen neue Funktionen den Betrieb vorhandener Subsysteme stören können. Dies kann sich sowohl in der Bildung von Ausnahmen als auch in der Schlussfolgerung des nicht erwarteten Ergebnisses manifestieren. Zu diesem Zweck wird das erwartete Verhalten des Systems getestet.
Für diese Schaltung sind verschiedene Entwicklungs- und Testmethoden anwendbar: TDD (Test Driven Development) und BDD (Behavior Driven Development)
Zum Zeitpunkt des Schreibens von WRC wurde das Vanessa-Bahavior- Framework verwendet, um Tests unter Verwendung der BDD- Methodik und des XunitFor1C für TDD durchzuführen . Sie werden derzeit unter einem Vanessa-ADD-Produkt zusammengefasst. Die Entwicklerunterstützung für ältere Produkte wurde eingestellt. Die Testergebnisse werden in die Berichtsdateien Yandex Allure und Xunit ausgegeben.
Prozess "Montage der Lieferung"
Eingabedaten: - Quellcode
Ausgabedaten: - Lieferung der Konfiguration
Steuerung: Anweisungen zum Arbeiten mit Software, Assemblerskript
Mechanismus: 1C: Enterprise, Packman .
In diesem Prozess erfolgt die endgültige Übermittlung der Konfigurationsübermittlung für die Bereitstellung auf dem Zielsystem. Der verifizierte Quellcode befindet sich im Entwicklungszweig des GitLab-Quellcode-Repositorys. Um eine Lieferung zu bilden, müssen Änderungen aus dem Entwicklungszweig im Hauptzweig angezeigt werden. Diese Aktion kann sowohl manuell als auch automatisch erfolgen und wird durch die Anforderungen der IT-Abteilung mithilfe der CI / CD-Schleife geregelt. Nach dem Zusammenführen der Zweige beginnt der Prozess des Zusammenbaus der fertigen Lieferung. Zu diesem Zweck wird im Assembly-Verzeichnis auf der Grundlage der vorhandenen Quellen erneut eine Service-Informationsbasis erstellt und anschließend mithilfe der Tools der 1C: Enterprise-Plattform eine Konfigurationsbereitstellung generiert und archiviert. Die Konfigurationsbereitstellung ist das Endprodukt des Montageprozesses und wird über etablierte Kommunikationskanäle an den Kunden geliefert oder direkt in ein produktives Informationssystem installiert.
Ergebnisprozess veröffentlichen
Eingabedaten: - Ergebnis entladen, Dateien melden
Ausgabedaten: - Bericht
Steuerung: Anweisungen zum Arbeiten mit Software, Assemblerskript
Mechanismus: Yandex Allure , Xunit .
Bei der Ausführung der Prozessschritte erstellen die Testtools Berichtsdateien in bestimmten Formaten als Nebenprodukt. Die Aufgabe dieses Prozesses besteht darin, die Datenanalyse zu gruppieren, zu transformieren und zu veröffentlichen. Wenn zu einem bestimmten Zeitpunkt der Assembly und mit den erforderlichen Einstellungen eine Ausnahme generiert wird, sollte das System den Schleifenadministrator automatisch über Probleme informieren. Diese Phase wird in der Nachbearbeitung des Montageprozesses durchgeführt und sollte unabhängig von den Ergebnissen früherer Prozesse durchgeführt werden.
Für Feedback wurde zusätzlich zur Mailingliste die Integration mit dem Slack-Unternehmensmanager verwendet, bei der alle Informationsnachrichten bezüglich des Build-Status, des Auftretens neuer Commits, der Bildung von Backups sowie der Überwachung der Funktionsweise von Diensten im Zusammenhang mit der DevOps-Schaltung und von 1C bis gesendet wurden ganz.
Das Ergebnis meines Projekts war der Schutz der WRC Ende Mai dieses Jahres mit dem Ergebnis „ausgezeichnet“. Zusätzlich wurden die methodischen Informationen zur Konturbildung aktualisiert.

Allgemeine Schlussfolgerungen:
- Der wirtschaftliche Effekt ist nur langfristig möglich. Erfahrungsgemäß wurde festgestellt, dass beim Start des Projekts zur Implementierung von Engineering-Praktiken ein Rückgang der Entwicklungsproduktivität um 20 bis 30% gegenüber dem aktuellen Niveau verzeichnet wird. Dieser Zeitraum ist vorübergehend, und in der Regel kehrt die Leistung nach drei bis vier Betriebsmonaten zu ihren ursprünglichen Werten zurück. Der Leistungsabfall ist hauptsächlich darauf zurückzuführen, dass sich der Entwickler an die neuen Entwicklungsanforderungen gewöhnen muss: Schreiben von Skripten, Tests und Erstellen technischer Dokumentation.
- Die Stabilität eines produktiven Informationssystems hat sich durch das Testen des Programmcodes erheblich erhöht. Der garantierte Betrieb kritischer Subsysteme wird durch die Abdeckung von Szenariotests gewährleistet. Dadurch wurden die Risiken des Unternehmens in einem kritischen Bereich - der operativen Interaktion mit Kunden - reduziert.
- Der Ausschluss dynamischer Korrekturen auf einer produktiven Informationsbasis ermöglichte es, die Entwicklung konstruktiver zu planen und zu verhindern, dass Softwarecode die Testschleife umgeht.
- Reduzierte Arbeitskosten für die Wartung der Informationsbasis aufgrund der Automatisierung der Montageschaltung.
- Die Verwendung von Feedback über Slack ermöglichte die Online-Überwachung und Behebung von Systemlebenszyklusproblemen. Laut Teambewertungen ist die Verwendung eines Messenger bequemer als das Versenden (obwohl er auch vorhanden ist).
- Die Verwendung der automatisierten kontinuierlichen Code-Inspektion (Continuous Inspection) zur Einhaltung der Entwicklungsstandards (SonarQube) zwingt Entwickler dazu, ihre Kompetenz unabhängig zu erhöhen, und die festgestellten technischen Schulden direkt während der Entwicklung eines Softwaremoduls zu beheben, ist viel schneller, da Sie keine Zeit damit verbringen müssen, den Kontext der Aufgabe wiederherzustellen.
- Durch Aktivieren der Funktionalität der automatischen Dokumentation und der Generierung von Videoanweisungen kann die Anzahl der Benutzeranforderungen verringert werden.
- Im Verlauf des Projekts wurde ein Geschäftsprozess gebildet, der den Lebenszyklus der Entwicklung und Erprobung von 1C-Anwendungslösungen beschreibt, was wiederum die Bildung eines Projekts zur Implementierung von Engineering-Praktiken beeinflusste . , 1.
, . 90% .
, :
- , " 1. - , , ( 5 ).
- “ 1”. . ( , " ". ).
- CICD 1 , 5.5.0 .
, , 1 , DevOps. , — DevOps 1 .
, DevOps 1. ?