
In früheren Artikeln haben wir direkte Beleuchtung (Vorwärtsrendering oder Vorwärtsschattierung) verwendet . Dies ist ein einfacher Ansatz, bei dem wir ein Objekt unter Berücksichtigung aller Lichtquellen zeichnen und dann das nächste Objekt zusammen mit der gesamten Beleuchtung usw. für jedes Objekt zeichnen. Es ist recht einfach zu verstehen und zu implementieren, aber gleichzeitig fällt es aus Sicht der Leistung eher langsam aus: Für jedes Objekt müssen alle Lichtquellen sortiert werden. Darüber hinaus funktioniert die direkte Beleuchtung bei Szenen mit einer großen Anzahl von Objekten, die sich überlappen, ineffizient, da die meisten Pixel-Shader-Berechnungen nicht nützlich sind und mit Werten für nähere Objekte überschrieben werden.
Verzögerte Beleuchtung oder verzögerte Schattierung oder verzögertes Rendern umgehen dieses Problem und verändern die Art und Weise, wie wir Objekte zeichnen, dramatisch. Dies bietet neue Möglichkeiten, Szenen mit einer großen Anzahl von Lichtquellen erheblich zu optimieren, sodass Sie Hunderte und sogar Tausende von Lichtquellen mit einer akzeptablen Geschwindigkeit zeichnen können. Unten sehen Sie eine Szene mit 1847 Punktlichtquellen, die mit verzögerter Beleuchtung gezeichnet wurden (Bild mit freundlicher Genehmigung von Hannes Nevalainen). So etwas wäre mit einer direkten Berechnung der Beleuchtung unmöglich:

Die Idee der verzögerten Beleuchtung besteht darin, dass wir die rechnerisch komplexesten Teile (wie z. B. die Beleuchtung) für später verschieben. Die verzögerte Beleuchtung besteht aus zwei Durchgängen: Im ersten Durchgang, dem Geometrie-Durchgang (Geometrie-Durchgang) , wird die gesamte Szene gezeichnet und verschiedene Informationen werden in einer Reihe von Texturen gespeichert, die als G-Puffer bezeichnet werden. Zum Beispiel: Positionen, Farben, Normalen und / oder Oberflächenspiegelung für jedes Pixel. Die im G-Puffer gespeicherten Grafikinformationen werden später zur Berechnung der Beleuchtung verwendet. Das Folgende ist der Inhalt des G-Puffers für einen Frame:

Im zweiten Durchgang, dem Beleuchtungsdurchgang, verwenden wir die Texturen aus dem G-Puffer, wenn wir das Vollbild-Rechteck zeichnen. Anstatt Vertex- und Fragment-Shader für jedes Objekt separat zu verwenden, zeichnen wir die gesamte Szene Pixel für Pixel. Die Berechnung der Beleuchtung bleibt genau die gleiche wie bei einem direkten Durchgang, wir beziehen die erforderlichen Daten jedoch nur aus dem G-Puffer und den variablen Shadern (Uniformen) und nicht aus dem Vertex-Shader.
Das Bild unten zeigt den allgemeinen Zeichenvorgang gut.
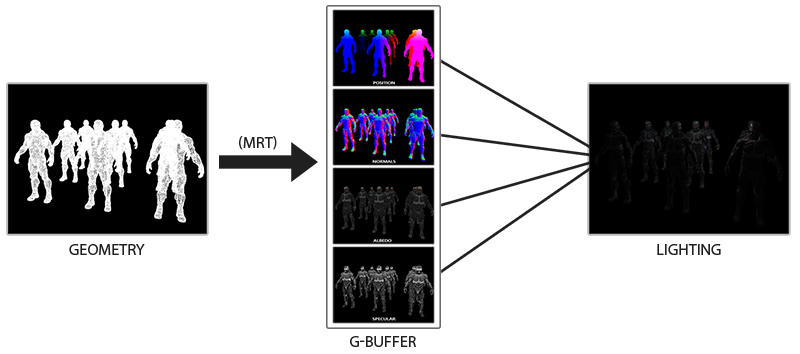
Der Hauptvorteil besteht darin, dass die im G-Puffer gespeicherten Informationen zu den nächsten Fragmenten gehören, die durch nichts verdeckt werden: Der Tiefentest lässt nur diese übrig. Dank dessen berechnen wir die Beleuchtung für jedes Pixel nur einmal, ohne zu viel Arbeit zu leisten. Darüber hinaus bietet die verzögerte Beleuchtung Möglichkeiten für weitere Optimierungen, sodass wir viel mehr Lichtquellen als bei direkter Beleuchtung verwenden können.
Es gibt jedoch einige Nachteile: Der G-Puffer speichert eine große Menge an Informationen über die Szene. Außerdem müssen Positionsdaten mit hoher Genauigkeit gespeichert werden, so dass der G-Puffer ziemlich viel Speicherplatz beansprucht. Ein weiterer Nachteil ist, dass wir keine durchscheinenden Objekte verwenden können (da der Puffer Informationen nur für die nächstgelegene Oberfläche speichert) und Anti-Aliasing wie MSAA ebenfalls nicht funktioniert. Es gibt verschiedene Problemumgehungen, um diese Probleme zu lösen. Sie werden am Ende des Artikels erläutert.
(Hinweisspur. - Der G-Puffer nimmt viel Speicherplatz ein. Bei einem Bildschirm von 1920 * 1080 und 128 Bit pro Pixel benötigt der Puffer 33 MB. Die Anforderungen an die Speicherbandbreite steigen - es werden viel mehr Daten geschrieben und gelesen.)
G-Puffer
G-Puffer bezieht sich auf Texturen, die zum Speichern von Beleuchtungsinformationen verwendet werden, die im letzten Rendering-Durchgang verwendet wurden. Mal sehen, welche Informationen wir benötigen, um die Beleuchtung für das direkte Rendern zu berechnen:
- 3D-Positionsvektor: Wird verwendet, um die Position des Fragments relativ zur Kamera und zu den Lichtquellen zu ermitteln.
- Diffuse Farbe des Fragments (Reflexionsvermögen für Rot, Grün und Blau - im Allgemeinen Farbe).
- 3d normaler Vektor (um zu bestimmen, in welchem Winkel Licht auf die Oberfläche fällt)
- float zum Speichern der Spiegelkomponente
- Die Position der Lichtquelle und ihre Farbe.
- Kameraposition.
Mit diesen Variablen können wir die Abdeckung mit dem bereits bekannten Blinn-Fong-Modell berechnen. Die Farbe und Position der Lichtquelle sowie die Position der Kamera können allgemeine Variablen sein, die restlichen Werte sind jedoch für jedes Bildfragment unterschiedlich. Wenn wir genau dieselben Daten in den endgültigen Durchgang der verzögerten Beleuchtung übergeben, den wir für einen direkten Durchgang verwenden würden, erhalten wir das gleiche Ergebnis, obwohl wir Fragmente auf einem regulären 2D-Rechteck zeichnen.
OpenGL unterliegt keinen Einschränkungen hinsichtlich der Speicherung in der Textur. Daher ist es sinnvoll, alle Informationen in einer oder mehreren Texturen von der Größe eines Bildschirms (als G-Puffer bezeichnet) zu speichern und alle im Beleuchtungsdurchlauf zu verwenden. Da die Größe der Texturen und des Bildschirms gleich ist, erhalten wir die gleichen Eingabedaten wie bei direkter Beleuchtung.
Im Pseudocode sieht das allgemeine Bild ungefähr so aus:
while(...) // render loop { // 1. : / g- glBindFramebuffer(GL_FRAMEBUFFER, gBuffer); glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); gBufferShader.use(); for(Object obj : Objects) { ConfigureShaderTransformsAndUniforms(); obj.Draw(); } // 2. : g- glBindFramebuffer(GL_FRAMEBUFFER, 0); glClear(GL_COLOR_BUFFER_BIT); lightingPassShader.use(); BindAllGBufferTextures(); SetLightingUniforms(); RenderQuad(); }
Informationen, die für jedes Pixel benötigt werden: Positionsvektor , Normalvektor , Farbvektor und Wert für die Spiegelkomponente . Im geometrischen Durchgang zeichnen wir alle Objekte in der Szene und speichern alle diese Daten im G-Puffer. Wir können mehrere Renderziele verwenden , um alle Puffer in einer Zeichnung zu füllen. Dieser Ansatz wurde im vorherigen Artikel über die Implementierung des Glühens erörtert: Bloom , Übersetzung auf dem Hub
Erstellen Sie für den geometrischen Durchlauf einen Framebuffer mit dem offensichtlichen Namen gBuffer, an den mehrere Farbpuffer und ein Tiefenpuffer angehängt werden. Um Positionen und Normalen zu speichern, ist es vorzuziehen, eine Textur mit hoher Genauigkeit zu verwenden (16- oder 32-Bit-Float-Werte für jede Komponente). Standardmäßig werden die diffusen Farb- und Spiegelwerte in der Textur gespeichert (8 Bit pro Komponentengenauigkeit).
unsigned int gBuffer; glGenFramebuffers(1, &gBuffer); glBindFramebuffer(GL_FRAMEBUFFER, gBuffer); unsigned int gPosition, gNormal, gColorSpec; // glGenTextures(1, &gPosition); glBindTexture(GL_TEXTURE_2D, gPosition); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGB, GL_FLOAT, NULL); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, gPosition, 0); // glGenTextures(1, &gNormal); glBindTexture(GL_TEXTURE_2D, gNormal); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGB, GL_FLOAT, NULL); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT1, GL_TEXTURE_2D, gNormal, 0); // + glGenTextures(1, &gAlbedoSpec); glBindTexture(GL_TEXTURE_2D, gAlbedoSpec); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGBA, GL_UNSIGNED_BYTE, NULL); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT2, GL_TEXTURE_2D, gAlbedoSpec, 0); // OpenGL, unsigned int attachments[3] = { GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1, GL_COLOR_ATTACHMENT2 }; glDrawBuffers(3, attachments); // . [...]
Da wir mehrere Rendering-Ziele verwenden, müssen wir OpenGL explizit mitteilen, an welche Puffer aus dem angehängten GBuffer wir in glDrawBuffers() zeichnen werden. Es ist auch erwähnenswert, dass wir Positionen und Normalen mit jeweils 3 Komponenten speichern und diese in RGB-Texturen speichern. Gleichzeitig setzen wir sofort die gleiche RGBA-Textur ein, sowohl die Farbe als auch den Spiegelreflexionskoeffizienten - dank dessen verwenden wir einen Puffer weniger. Wenn Ihre Implementierung des verzögerten Renderns komplexer wird und mehr Daten verwendet, können Sie leicht neue Möglichkeiten finden, Daten zu kombinieren und in Texturen anzuordnen.
In Zukunft müssen wir die Daten in den G-Puffer rendern. Wenn jedes Objekt einen Farb-, Normal- und Spiegelreflexionskoeffizienten hat, können wir so etwas wie den folgenden Shader schreiben:
#version 330 core layout (location = 0) out vec3 gPosition; layout (location = 1) out vec3 gNormal; layout (location = 2) out vec4 gAlbedoSpec; in vec2 TexCoords; in vec3 FragPos; in vec3 Normal; uniform sampler2D texture_diffuse1; uniform sampler2D texture_specular1; void main() { // G- gPosition = FragPos; // G- gNormal = normalize(Normal); // gAlbedoSpec.rgb = texture(texture_diffuse1, TexCoords).rgb; // gAlbedoSpec.a = texture(texture_specular1, TexCoords).r; }
Da wir mehrere Rendering-Ziele verwenden, geben layout mithilfe des layout an, was und in welchem Puffer des aktuellen Framebuffers wir rendern. Bitte beachten Sie, dass wir den Spiegelkoeffizienten nicht in einem separaten Puffer speichern, da wir den Float-Wert im Alpha-Kanal eines der Puffer speichern können.
Beachten Sie, dass es bei der Berechnung der Beleuchtung äußerst wichtig ist, alle Variablen im selben Koordinatenraum zu speichern. In diesem Fall speichern (und führen wir Berechnungen) im Raum der Welt durch.
Wenn wir nun mehrere Nanosuits in einen G-Puffer rendern und seinen Inhalt zeichnen, indem wir jeden Puffer auf ein Viertel des Bildschirms projizieren, sehen wir ungefähr Folgendes:
Versuchen Sie, die Position und die normalen Vektoren zu visualisieren, und stellen Sie sicher, dass sie korrekt sind. Beispielsweise sind die nach rechts zeigenden Normalenvektoren rot. Ähnlich verhält es sich mit Objekten rechts von der Mitte der Szene. Nachdem Sie mit dem Inhalt des G-Puffers zufrieden sind, fahren wir mit dem nächsten Teil fort: dem Durchgang der Beleuchtung.
Beleuchtungsdurchgang
Nachdem wir eine große Menge an Informationen im G-Puffer haben, können wir die Beleuchtung und die endgültigen Farben für jedes Pixel des G-Puffers vollständig berechnen und seinen Inhalt als Eingabe für Beleuchtungsberechnungsalgorithmen verwenden. Da die Werte des G-Puffers nur sichtbare Fragmente darstellen, führen wir komplexe Beleuchtungsberechnungen für jedes Pixel genau einmal durch. Aus diesem Grund ist die verzögerte Beleuchtung sehr effektiv, insbesondere in komplexen Szenen, in denen beim direkten Rendern für jedes Pixel die Beleuchtung häufig mehrmals berechnet werden muss.
Für den Durchgang der Beleuchtung werden wir ein Vollbild-Rechteck rendern (ein bisschen wie der Nachbearbeitungseffekt) und eine langsame Berechnung der Beleuchtung für jedes Pixel durchführen.
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D, gPosition); glActiveTexture(GL_TEXTURE1); glBindTexture(GL_TEXTURE_2D, gNormal); glActiveTexture(GL_TEXTURE2); glBindTexture(GL_TEXTURE_2D, gAlbedoSpec); // shaderLightingPass.use(); SendAllLightUniformsToShader(shaderLightingPass); shaderLightingPass.setVec3("viewPos", camera.Position); RenderQuad();
Wir binden alle erforderlichen G-Buffer-Texturen vor dem Rendern und legen zusätzlich die lichtbezogenen Variablenwerte im Shader fest.
Der Fragment-Passage-Shader ist dem in den Besprechungsstunden verwendeten sehr ähnlich. Grundsätzlich neu ist die Art und Weise, wie wir Eingaben für die Beleuchtung direkt aus dem G-Puffer erhalten.
#version 330 core out vec4 FragColor; in vec2 TexCoords; uniform sampler2D gPosition; uniform sampler2D gNormal; uniform sampler2D gAlbedoSpec; struct Light { vec3 Position; vec3 Color; }; const int NR_LIGHTS = 32; uniform Light lights[NR_LIGHTS]; uniform vec3 viewPos; void main() { // G- vec3 FragPos = texture(gPosition, TexCoords).rgb; vec3 Normal = texture(gNormal, TexCoords).rgb; vec3 Albedo = texture(gAlbedoSpec, TexCoords).rgb; float Specular = texture(gAlbedoSpec, TexCoords).a; // vec3 lighting = Albedo * 0.1; // vec3 viewDir = normalize(viewPos - FragPos); for(int i = 0; i < NR_LIGHTS; ++i) { // vec3 lightDir = normalize(lights[i].Position - FragPos); vec3 diffuse = max(dot(Normal, lightDir), 0.0) * Albedo * lights[i].Color; lighting += diffuse; } FragColor = vec4(lighting, 1.0); }
Der Licht-Shader akzeptiert 3 Texturen, die alle im geometrischen Durchgang aufgezeichneten Informationen enthalten und aus denen der G-Puffer besteht. Wenn wir die Eingabe für die Beleuchtung aus Texturen übernehmen, erhalten wir genau die gleichen Werte wie beim normalen direkten Rendern. Zu Beginn des Fragment-Shaders erhalten wir die Werte für Beleuchtungsvariablen durch einfaches Lesen aus der Textur. Beachten Sie, dass wir sowohl die Farbe als auch den Spiegelreflexionskoeffizienten von einer Textur erhalten - gAlbedoSpec .
Da für jedes Fragment Werte (sowie einheitliche Shader-Variablen) für die Berechnung der Beleuchtung nach dem Blinn-Fong-Modell erforderlich sind, müssen wir den Beleuchtungsberechnungscode nicht ändern. Das einzige, was geändert wurde, ist der Weg, um die Eingabewerte zu erhalten.
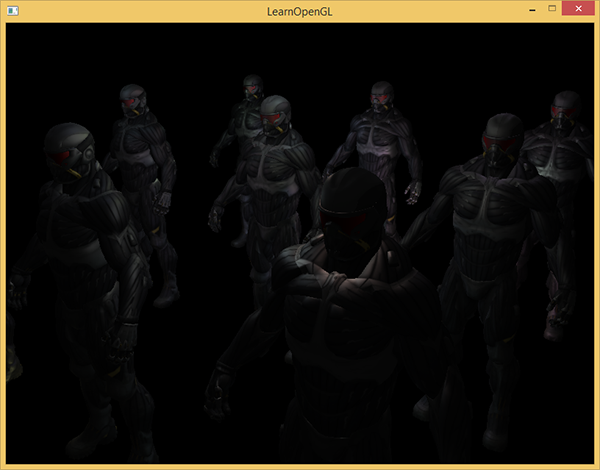
Das Starten einer einfachen Demo mit 32 kleinen Lichtquellen sieht ungefähr so aus:
Einer der Nachteile der verzögerten Beleuchtung ist die Unmöglichkeit des Mischens, da alle g-Puffer für jedes Pixel Informationen über nur eine Oberfläche enthalten, während das Mischen Kombinationen mehrerer Fragmente verwendet. (Mischen) , Übersetzung . Ein weiterer Nachteil der verzögerten Beleuchtung besteht darin, dass Sie gezwungen sind, eine gemeinsame Methode zur Berechnung der Beleuchtung für alle Objekte zu verwenden. obwohl diese Einschränkung irgendwie umgangen werden kann, indem dem g-Puffer Materialinformationen hinzugefügt werden.
Um diese Mängel (insbesondere das Fehlen einer Mischung) zu beheben, teilen sie das Rendering häufig in zwei Teile: Rendering mit verzögerter Beleuchtung und den zweiten Teil mit direktem Rendering, um etwas auf die Szene anzuwenden oder Shader zu verwenden, die nicht mit verzögertem Licht kompatibel sind. (Hinweis: Aus den Beispielen: Hinzufügen von durchscheinendem Rauch, Feuer, Glas) Zur Veranschaulichung der Arbeit werden die Lichtquellen als kleine Würfel mit direktem Rendering gezeichnet, da die Beleuchtungswürfel einen speziellen Shader benötigen (sie leuchten gleichmäßig in derselben Farbe).
Kombinieren Sie verzögertes Rendern mit direktem Rendern.
Angenommen, wir möchten jede Lichtquelle in Form eines 3D-Würfels zeichnen, dessen Mittelpunkt mit der Position der Lichtquelle übereinstimmt und Licht mit der Farbe der Quelle emittiert. Die erste Idee, die mir in den Sinn kommt, besteht darin, Würfel für jede Lichtquelle direkt über die verzögerten Renderergebnisse zu rendern. Das heißt, wir zeichnen Würfel wie gewohnt, jedoch erst nach verzögertem Rendern. Der Code sieht ungefähr so aus:
// [...] RenderQuad(); // shaderLightBox.use(); shaderLightBox.setMat4("projection", projection); shaderLightBox.setMat4("view", view); for (unsigned int i = 0; i < lightPositions.size(); i++) { model = glm::mat4(); model = glm::translate(model, lightPositions[i]); model = glm::scale(model, glm::vec3(0.25f)); shaderLightBox.setMat4("model", model); shaderLightBox.setVec3("lightColor", lightColors[i]); RenderCube(); }
Diese gerenderten Würfel berücksichtigen keine Tiefenwerte aus dem verzögerten Rendern und werden daher immer auf bereits gerenderte Objekte gezeichnet. Dies ist nicht das, was wir anstreben.
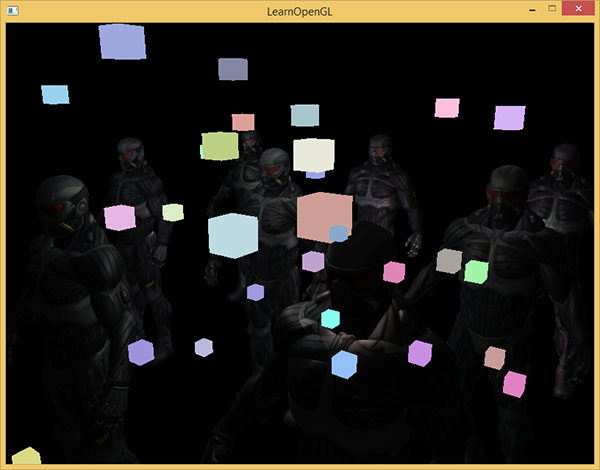
Zuerst müssen wir die Tiefeninformationen aus dem geometrischen Durchgang in den Tiefenpuffer kopieren und erst danach die Leuchtwürfel zeichnen. Fragmente von Leuchtwürfeln werden daher nur gezeichnet, wenn sie näher als bereits gezeichnete Objekte sind.
Mit der Funktion glBlitFramebuffer können wir den Inhalt des Framebuffers in einen anderen Framebuffer glBlitFramebuffer . Wir haben diese Funktion bereits im Anti-Aliasing- Beispiel verwendet: ( Anti-Aliasing ), Übersetzung . Die Funktion glBlitFramebuffer kopiert den benutzerdefinierten Teil des Framebuffers in den angegebenen Teil eines anderen Framebuffers.
Für Objekte, die im verzögerten Beleuchtungsdurchgang gezeichnet wurden, haben wir die Tiefe im g-Puffer des Framebuffer-Objekts gespeichert. Wenn wir einfach den Inhalt des G-Puffer-Tiefenpuffers in den Standardtiefenpuffer kopieren, werden die Leuchtwürfel so gezeichnet, als ob die gesamte Geometrie der Szene mit einem direkten Rendering-Durchgang gezeichnet worden wäre. Wie im Anti-Aliasing-Beispiel kurz erläutert wurde, müssen Framebuffer zum Lesen und Schreiben festgelegt werden:
glBindFramebuffer(GL_READ_FRAMEBUFFER, gBuffer); glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0); // - glBlitFramebuffer( 0, 0, SCR_WIDTH, SCR_HEIGHT, 0, 0, SCR_WIDTH, SCR_HEIGHT, GL_DEPTH_BUFFER_BIT, GL_NEAREST ); glBindFramebuffer(GL_FRAMEBUFFER, 0); // [...]
Hier kopieren wir den gesamten Inhalt des Framebuffer-Tiefenpuffers in den Standardtiefenpuffer (ggf. können Sie die Farbpuffer oder den Stensilpuffer auf die gleiche Weise kopieren). Wenn wir jetzt die leuchtenden Würfel rendern, werden sie so gezeichnet, als ob die Geometrie der Szene real wäre (obwohl sie so einfach gezeichnet ist).

Den Quellcode der Demo finden Sie hier .
Mit diesem Ansatz können wir das verzögerte Rendern leicht mit dem direkten Rendern kombinieren. Dies ist hervorragend, da wir Objekte mischen und zeichnen können, für die spezielle Shader erforderlich sind, die für das verzögerte Rendern nicht geeignet sind.
Mehr Lichtquellen
Die verzögerte Beleuchtung wird oft dafür gelobt, dass sie eine große Anzahl von Lichtquellen ohne signifikante Leistungsminderung zeichnen kann. Eine verzögerte Beleuchtung allein erlaubt es uns nicht, eine sehr große Anzahl von Lichtquellen zu zeichnen, da wir immer noch den Beitrag aller Lichtquellen für jedes Pixel berechnen müssen. Um eine große Anzahl von Lichtquellen zu zeichnen, wird eine sehr schöne Optimierung verwendet, die auf verzögertes Rendern anwendbar ist - den Wirkungsbereich von Lichtquellen. (leichte Mengen)
Wenn wir Fragmente in einer stark beleuchteten Szene zeichnen, berücksichtigen wir normalerweise den Beitrag jeder Lichtquelle in der Szene, unabhängig von ihrem Abstand zum Fragment. Wenn die meisten Lichtquellen das Fragment niemals beeinflussen, warum verschwenden wir dann Zeit damit, für sie zu rechnen?
Die Idee des Umfangs der Lichtquelle besteht darin, den Radius (oder das Volumen) der Lichtquelle zu ermitteln, dh den Bereich, in dem das Licht die Oberfläche erreichen kann. Da die meisten Lichtquellen eine Art Dämpfung verwenden, können wir die maximale Entfernung (Radius) ermitteln, die Licht erreichen kann. Danach führen wir komplexe Beleuchtungsberechnungen nur für die Lichtquellen durch, die dieses Fragment betreffen. Dies erspart uns eine Vielzahl von Berechnungen, da wir die Beleuchtung nur dort berechnen, wo sie benötigt wird.
Bei diesem Ansatz besteht der Haupttrick darin, die Größe des Aktionsbereichs der Lichtquelle zu bestimmen.
Berechnung des Umfangs einer Lichtquelle (Radius)
Um den Radius der Lichtquelle zu erhalten, müssen wir die Dämpfungsgleichung für die Helligkeit lösen, die wir als dunkel betrachten - sie kann 0,0 oder etwas beleuchteter sein, aber immer noch dunkel: zum Beispiel 0,03. Um zu demonstrieren, wie der Radius berechnet wird, verwenden wir eine der komplexesten und am häufigsten verwendeten Dämpfungsfunktionen aus dem Beispiel des Lichtgießers
F l i g h t = f r a c I K c + K l ∗ d + K q ∗ d 2
Wir wollen diese Gleichung für den Fall lösen, wenn F l i g h t = 0,0 wenn die Lichtquelle vollständig dunkel ist. Diese Gleichung wird jedoch niemals den exakten Wert von 0,0 erreichen, sodass es keine Lösung gibt. Wir können jedoch stattdessen die Helligkeitsgleichung für einen Wert nahe 0,0 lösen, der als praktisch dunkel angesehen werden kann. In diesem Beispiel halten wir den Helligkeitswert in für akzeptabel f r a c 5 256 - geteilt durch 256, da der 8-Bit-Framebuffer 256 verschiedene Helligkeitswerte enthalten kann.
Die ausgewählte Dämpfungsfunktion wird in einem Entfernungsbereich fast dunkel. Wenn wir sie auf eine niedrigere Helligkeit als 5/256 beschränken, wird der Bereich der Lichtquelle zu groß - dies ist nicht so effektiv. Idealerweise sollte eine Person keinen plötzlichen scharfen Lichtrand von einer Lichtquelle sehen. Dies hängt natürlich von der Art der Szene ab, ein größerer Wert der minimalen Helligkeit ergibt kleinere Aktionsbereiche von Lichtquellen und erhöht die Effizienz von Berechnungen, kann jedoch zu merklichen Artefakten im Bild führen: Die Beleuchtung bricht an den Grenzen des Aktionsbereichs der Lichtquelle abrupt ab.
Die Dämpfungsgleichung, die wir lösen müssen, lautet:
f r a c 5 256 = f r a c I m a x D ä m p f u n g
Hier Imax - die hellste Lichtkomponente (aus den Kanälen r, g, b). Wir werden die hellste Komponente verwenden, da die anderen Komponenten den Umfang der Lichtquelle schwächer einschränken.
Wir lösen weiterhin die Gleichung:
frac5256 cdotAttenuation=Imax
Attenuation=Imax cdot frac2565
Kc+Kl cdotd+Kq cdotd2=Imax cdot frac2565
Kc+Kl cdotd+Kq cdotd2−Imax cdot frac2565=0
Die letzte Gleichung ist eine quadratische Gleichung in der Form ax2+bx+c=0 mit folgender Lösung:
x= frac−Kl+ sqrtK2l−4Kq(Kc−Imax frac2565)2Kq
Wir haben eine allgemeine Gleichung erhalten, die es uns ermöglicht, die Parameter (konstante Dämpfung, lineare und quadratische Koeffizienten) zu ersetzen, um x - den Radius der Lichtquelle - zu finden.
float constant = 1.0; float linear = 0.7; float quadratic = 1.8; float lightMax = std::fmaxf(std::fmaxf(lightColor.r, lightColor.g), lightColor.b); float radius = (-linear + std::sqrtf(linear * linear - 4 * quadratic * (constant - (256.0 / 5.0) * lightMax))) / (2 * quadratic);
Die Formel gibt abhängig von der maximalen Helligkeit der Lichtquelle einen Radius zwischen ungefähr 1,0 und 5,0 zurück.
Wir finden diesen Radius für jede Lichtquelle auf der Bühne und verwenden ihn, um nur die Lichtquellen zu berücksichtigen, innerhalb derer er sich im Rahmen jedes Fragments befindet. Unten finden Sie eine überarbeitete Lichtpassage, die die Wirkbereiche von Lichtquellen berücksichtigt. Bitte beachten Sie, dass dieser Ansatz nur zu Bildungszwecken implementiert wird und nicht für den praktischen Gebrauch geeignet ist (wir werden bald diskutieren, warum).
struct Light { [...] float Radius; }; void main() { [...] for(int i = 0; i < NR_LIGHTS; ++i) { // float distance = length(lights[i].Position - FragPos); if(distance < lights[i].Radius) { // [...] } } }
Das Ergebnis ist genau das gleiche wie zuvor, aber jetzt wird für jede Lichtquelle ihre Wirkung nur im Bereich ihrer Wirkung berücksichtigt.
Der endgültige Code ist eine Demo. .
Die reale Anwendung des Umfangs der Lichtquelle.
Der oben gezeigte Fragment-Shader funktioniert in der Praxis nicht und dient nur zur Veranschaulichung, wie unnötige Beleuchtungsberechnungen beseitigt werden können. In Wirklichkeit optimieren die Grafikkarte und die GLSL-Shader-Sprache Schleifen und Verzweigungen nur sehr schlecht. Der Grund dafür ist, dass die Ausführung des Shaders auf der Grafikkarte für verschiedene Pixel parallel ausgeführt wird und viele Architekturen die Einschränkung auferlegen, dass bei paralleler Ausführung verschiedene Threads denselben Shader berechnen müssen. Dies führt häufig dazu, dass der laufende Shader immer alle Zweige berechnet, sodass alle Shader gleichzeitig arbeiten. (Spur beachten. Dies hat keinen Einfluss auf das Ergebnis der Berechnungen, kann jedoch die Leistung des Shaders beeinträchtigen.) Aus diesem Grund kann sich herausstellen, dass unsere Radiusprüfung nutzlos ist: Wir berechnen weiterhin die Beleuchtung für alle Quellen!
Ein geeigneter Ansatz zur Nutzung des Lichtumfangs besteht darin, Kugeln mit einem Radius wie dem einer Lichtquelle zu rendern. Der Mittelpunkt der Kugel fällt mit der Position der Lichtquelle zusammen, so dass die Kugel in sich den Wirkungsbereich der Lichtquelle enthält. Hier gibt es einen kleinen Trick: Wir verwenden im Grunde den gleichen verzögerten Fragment-Shader, um eine Kugel zu zeichnen. Beim Zeichnen einer Kugel wird der Fragment-Shader speziell für die Pixel aufgerufen, die von der Lichtquelle betroffen sind. Wir rendern nur die erforderlichen Pixel und überspringen alle anderen. :

, . , , . _*__
_ + __ , .
: ( ) , , , - ( ). stenil .
, , , . ( ) : c (deferred lighting) (tile-based deferred shading) . MSAA. .
vs
( ) - , , . , — , MSAA, .
( ), ( g- ..) . , .
: , , , . , , , . . parallax mapping, , . , .
PS - . , !