Erfolg in maschinellen Lernprojekten hängt normalerweise nicht nur mit der Fähigkeit zusammen, verschiedene Bibliotheken zu verwenden, sondern auch mit dem Verständnis des Bereichs, aus dem die Daten stammen. Ein hervorragendes Beispiel für diese These war die vom Team von Alexei Kayuchenko, Sergey Belov, Alexander Drobotov und Alexey Smirnov im Wettbewerb PIK Digital Day vorgeschlagene Lösung. Sie belegten den zweiten Platz und sprachen nach ein paar Wochen über ihre Teilnahme und die gebauten Modelle beim nächsten
Yandex ML-Training .
Alexey Kayuchenko:
- Guten Tag! Wir werden über den PIK Digital Day-Wettbewerb sprechen, an dem wir teilgenommen haben. Ein bisschen über das Team. Wir waren zu viert. Alle mit einem völlig anderen Hintergrund aus verschiedenen Bereichen. Tatsächlich haben wir uns beim Finale getroffen. Das Team bildete sich nur einen Tag vor dem Finale. Ich werde über den Verlauf des Wettbewerbs, die Organisation der Arbeit sprechen. Dann wird Seryozha herauskommen, er wird über die Daten berichten, und Sasha wird über die Einreichung, den endgültigen Arbeitsablauf und wie wir uns entlang der Rangliste bewegt haben.

Kurz über den Wettbewerb. Die Aufgabe wurde sehr angewendet. PIC organisierte diesen Wettbewerb mit Daten zum Wohnungsverkauf. Als Trainingsdatensatz gab es eine Geschichte mit Attributen für zweieinhalb Jahre in Moskau und der Region Moskau. Der Wettbewerb bestand aus zwei Phasen. Es war eine Online-Bühne, auf der jeder der Teilnehmer einzeln versuchte, sein eigenes Modell zu erstellen, und die nicht so lange Offline-Bühne dauerte nur einen Tag von morgens bis abends. Es traf die Führer der Online-Bühne.
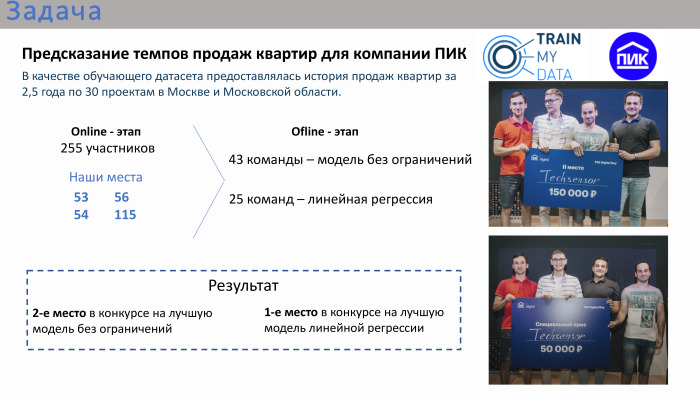
Nach den Ergebnissen des Online-Wettbewerbs waren unsere Plätze nicht einmal in den Top 10 und nicht einmal in den Top 20. Wir waren dort an Orten 50+. Ganz am Ende, also in der Offline-Phase, gab es 43 Teams. Es gab viele Teams, die aus einer Person bestanden, obwohl es möglich war, sich zu vereinen. Etwa ein Drittel der Teams hatte mehr als eine Person. Es gab zwei Wettbewerbe im Finale. Der erste Wettbewerb ist ein Modell ohne Einschränkungen. Es konnten beliebige Algorithmen verwendet werden: Deep Learning, maschinelles Lernen. Parallel dazu fand ein Wettbewerb um die beste lineare Regressionslösung statt. Der Veranstalter war der Ansicht, dass die lineare Regression ebenfalls durchaus angewendet wurde, da der Wettbewerb selbst insgesamt sehr angewendet wurde. Das heißt, die Aufgabe wurde gestellt - es war notwendig, das Verkaufsvolumen von Wohnungen vorherzusagen, wobei historische Daten für die letzten 2,5 Jahre mit Attributen vorliegen.
Unser Team belegte im Wettbewerb um das beste Modell ohne Einschränkungen den zweiten Platz und im Wettbewerb um die beste Regression den ersten Platz. Doppelter Preis.

Ich kann über den allgemeinen Verlauf der Organisation sagen, dass das Finale sehr stressig war, ziemlich stressig. Zum Beispiel wurde unsere Gewinnerentscheidung nur zwei Minuten vor dem Stoppspiel hochgeladen. Die vorherige Entscheidung hat uns meiner Meinung nach auf den vierten oder fünften Platz gebracht. Das heißt, wir haben bis zum Ende gearbeitet, ohne uns zu entspannen. PIC hat alles sehr gut organisiert. Es gab solche Tische, es gab sogar eine Veranda, auf der man auf der Straße sitzen und frische Luft atmen konnte. Essen, Kaffee, alles war vorhanden. Das Bild zeigt, dass alle in ihren Gruppen saßen und arbeiteten.
Sergey wird mehr über die Daten erzählen.
Sergey Belov:
- Vielen Dank. PIC stellte uns mehrere Datendateien zur Verfügung. Die beiden wichtigsten sind train.csv und test.csv, in denen etwa 50 Funktionen vom PIC selbst generiert wurden. Zug bestand aus ungefähr 10 Tausend Linien, Test - von 2 Tausend.
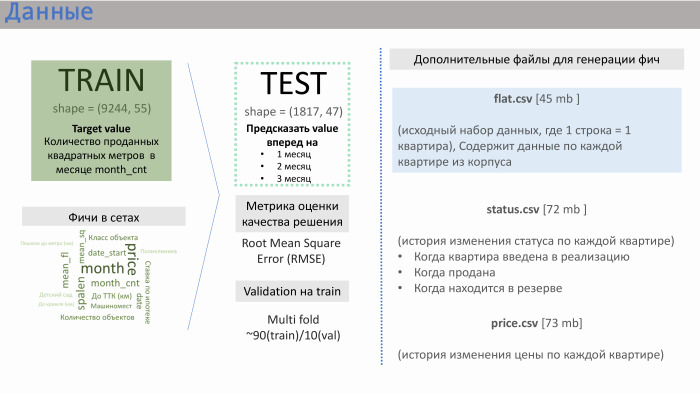
Was hat die Zeichenfolge geliefert? Es enthielt Verkaufsdaten. Das heißt, als Wert (in diesem Fall Ziel) hatten wir einen Quadratmeterumsatz für Wohnungen, die über ein bestimmtes Gebäude gemittelt wurden. Es gab ungefähr 10 Tausend solcher Zeilen. Die Merkmale in den Sets, die das PIK selbst generiert hat, werden auf der Folie mit der ungefähren Bedeutung angezeigt, die wir erhalten haben.
Erfahrung in Entwicklungsunternehmen hat mir hier geholfen. Merkmale wie die Entfernung der Wohnung zum Kreml oder zum Transportring, die Anzahl der Parkplätze - sie haben keinen großen Einfluss auf den Verkauf. Der Einfluss wird durch die Klasse des Objekts, die Ruhezeit und vor allem die Anzahl der Wohnungen in der Implementierung im Moment ausgeübt. PIC hat diese Funktion nicht generiert, aber sie hat uns drei zusätzliche Dateien zur Verfügung gestellt: flat.csv, status.csv und price.csv. Und wir haben uns entschlossen, einen Blick auf flat.csv zu werfen, da es nur Daten über die Anzahl der Wohnungen und deren Status gab.
Und wenn man sich fragt, was der Erfolg unserer Entscheidung war, dann ist dies eine definitive Teamarbeit. Von Anfang an haben wir sehr harmonisch gearbeitet. Wir haben sofort irgendwo in ungefähr 20 Minuten besprochen, was wir tun werden. Wir sind zu dem allgemeinen Schluss gekommen, dass das erste, was Sie für die Arbeit mit Daten benötigen, darin besteht, dass jeder Datenwissenschaftler versteht, dass die Daten viele Daten enthalten, und dass der Sieg häufig auf eine vom Team generierte Funktion zurückzuführen ist. Nach der Arbeit mit den Daten haben wir hauptsächlich verschiedene Modelle verwendet. Wir haben uns entschlossen zu sehen, welches Ergebnis unsere Funktionen in jedem dieser Modelle liefern, und uns dann auf das unbegrenzte Modell und das lineare Regressionsmodell konzentriert.
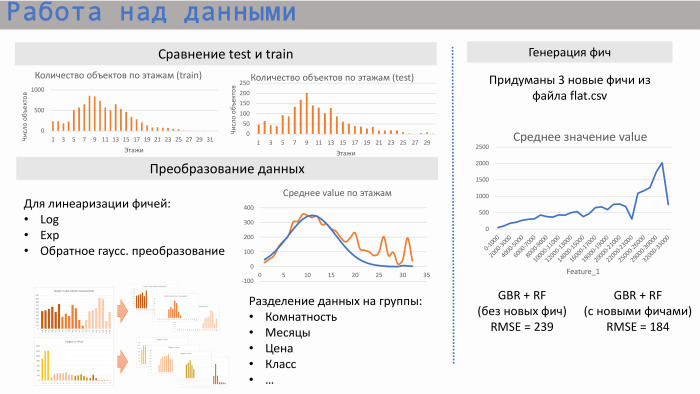
Wir haben angefangen mit Daten zu arbeiten. Zunächst haben wir untersucht, in welcher Beziehung Zugsatztests zueinander stehen, dh ob sich die Bereiche dieser Daten überschneiden. Ja, sie kreuzen sich: in der Anzahl der Wohnungen und im Ruhezustand und in einer bestimmten durchschnittlichen Anzahl von Stockwerken.
Für die lineare Regression haben wir begonnen, bestimmte Transformationen durchzuführen. Es ist wie die Standardlogarithmen eines Exponenten. Im Fall des mittleren Stockwerks war dies beispielsweise die inverse Gaußsche Transformation für die Linearisierung. Wir haben auch festgestellt, dass es manchmal besser ist, die Daten in Gruppen aufzuteilen. Wenn wir zum Beispiel die Entfernung von der Wohnung zur U-Bahn oder ihrem Zimmer nehmen, dann gibt es leicht unterschiedliche Märkte, und es ist besser zu teilen, unterschiedliche Modelle für jede dieser Gruppen zu erstellen.
Wir haben drei Features aus der Datei flat.csv generiert. Einer von ihnen wird hier vorgestellt. Es ist ersichtlich, dass es neben dieser Absenkung eine ziemlich gute lineare Beziehung hat. Was war das für eine Funktion? Es entsprach der Anzahl der Wohnungen, die derzeit umgesetzt werden. Und diese Funktion funktioniert sehr gut bei niedrigen Werten. Das heißt, es können nicht mehr Wohnungen verkauft werden als der Betrag, der im Verkauf ist. In diesen Akten wurde jedoch tatsächlich ein bestimmter menschlicher Faktor festgelegt, da sie häufig von Menschen zusammengestellt werden. Wir haben dort direkt Punkte gesehen, die aus diesem Bereich herausgeschlagen wurden, weil sie etwas falsch verstopft waren.
Beispiel aus Scikit-Learn. Ein Modell von GBR und Random Forest ohne Merkmale ergab RMSE 239 und mit diesen drei Merkmalen - 184.
Sasha wird über die Modelle sprechen, die wir verwendet haben.
Alexander Drobotov:
- Ein paar Worte zu unserem Ansatz. Wie die Jungs sagten, sind wir alle unterschiedlich, kommen aus unterschiedlichen Bereichen, unterschiedlicher Ausbildung. Und wir hatten verschiedene Ansätze. In der letzten Phase verwendete Lesha mehr XGBoost von Yandex (höchstwahrscheinlich meine ich CatBoost - Hrsg.), Seryozha - die Scikit-Lernbibliothek, I - LightGBM und lineare Regression.

XGBoost-Modelle, lineare Regression und Prophet sind die drei Optionen, die uns die beste Punktzahl zeigten. Für die lineare Regression hatten wir eine Mischung aus zwei Modellen und für die allgemeine Konkurrenz XGBoost, und wir haben eine kleine lineare Regression hinzugefügt.

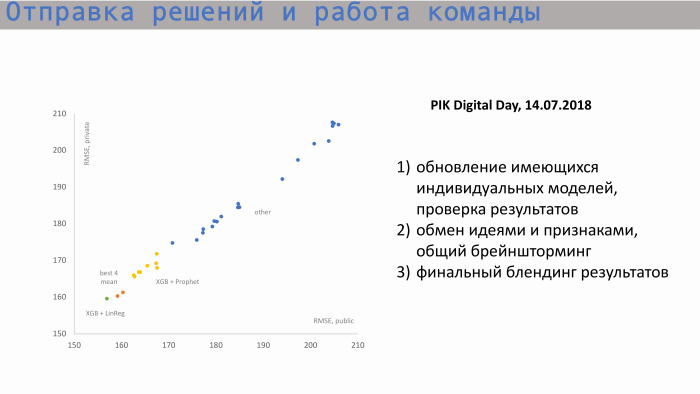
Hier ist der Prozess des Sendens von Entscheidungen und Teamarbeit. In der Grafik links ist die X-Achse der öffentliche RMSE, der Metrikwert, und die Y-Achse ist der private Score, RMSE. Wir gingen von ungefähr diesen Positionen aus. Hier sind individuelle Modelle von jedem der Teilnehmer. Nachdem wir uns ausgetauscht und neue Funktionen entwickelt hatten, näherten wir uns unserer besten Punktzahl. Unsere Werte für einzelne Modelle waren ungefähr gleich. Das beste Einzelmodell ist XGBoost und Prophet. Der Prophet erstellte eine Prognose für die angesammelten Verkäufe. Es gab so ein Zeichen wie Startquadrat. Das heißt, wir wussten, wie viele Wohnungen wir insgesamt haben, wir verstanden, welchen historischen Wert und welchen inkrementellen Wert der Gesamtwert anstrebte. Der Prophet machte eine Prognose für die Zukunft, gab Werte in den folgenden Zeiträumen heraus und übermittelte sie XGBoost.
Die Mischung unserer besten Einzelwertung ist irgendwo hier, diese beiden orangefarbenen Punkte. Aber diese Punktzahl reichte uns nicht aus, um an die Spitze zu gelangen.
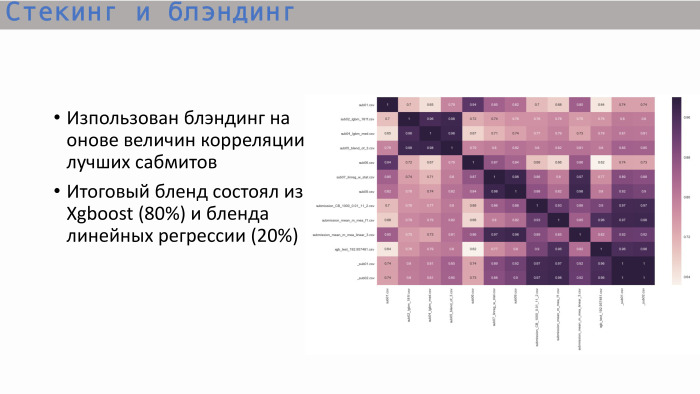
Nachdem wir die übliche Korrelationsmatrix der besten Einreichungen untersucht hatten, sahen wir Folgendes: Bäume - und das ist logisch - zeigten eine Korrelation nahe der Einheit, und der beste Baum ergab XGBoost. Es zeigt keine so hohe Korrelation mit der linearen Regression. Wir haben uns entschlossen, diese beiden Optionen im Verhältnis 8 zu 2 zu kombinieren. So haben wir die beste endgültige Lösung erhalten.
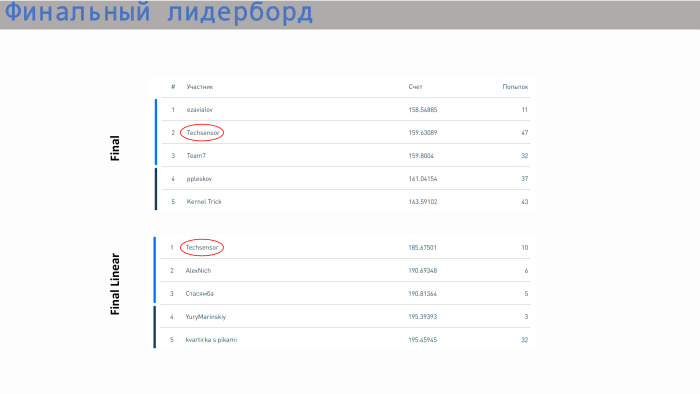
Dies ist eine Rangliste mit Ergebnissen. Unser Team belegte bei unbegrenzten Modellen den zweiten Platz und bei linearen Modellen den ersten Platz. Was die Punktzahl betrifft - hier sind alle Werte ziemlich nahe beieinander. Der Unterschied ist nicht sehr groß. Eine lineare Regression macht in Bereich 5 bereits einen Schritt. Wir haben alles, danke!