
Eine der wichtigsten Data Science-Konferenzen des Jahres hat heute in London begonnen. Ich werde versuchen, umgehend darüber zu sprechen, was interessant zu hören war.
Der Anfang erwies sich als nervös: Am selben Morgen fand im selben Zentrum ein Massentreffen der Zeugen Jehovas statt, so dass es nicht einfach war, den KDD-Registrierungsschalter zu finden, und als ich ihn schließlich fand, war die Leitung 150 bis 200 Meter lang. Trotzdem erhielt er nach ca. 20 Minuten Wartezeit ein begehrtes Abzeichen und ging in eine Meisterklasse.
Datenschutz bei der Datenanalyse
Der erste Workshop war der Wahrung der Privatsphäre bei der Datenanalyse gewidmet. Am Anfang war ich spät dran, aber anscheinend habe ich nicht viel verloren - sie sprachen darüber, wie wichtig Datenschutz ist und wie Angreifer die offengelegten privaten Informationen schlecht nutzen können. Übrigens sagen ziemlich respektable Leute von Google, LinkedIn und Apple. Da die Meisterklasse einen sehr positiven Eindruck hinterlassen hat, sind alle Folien hier erhältlich.
Es stellt sich heraus, dass das Konzept der
differenziellen Privatsphäre schon seit langer Zeit existiert. Die Idee besteht darin, Rauschen hinzuzufügen, das es schwierig macht, echte Einzelwerte zu ermitteln, aber die Fähigkeit behält, gemeinsame Verteilungen wiederherzustellen. Tatsächlich gibt es zwei Parameter:
e - wie schwierig es ist, die Daten offenzulegen, und
d - wie verzerrt die Antworten sind.
Das ursprüngliche Konzept legt nahe, dass zwischen dem Analysten und den Daten eine Art Zwischenverbindung besteht - der „Kurator“, der alle Anfragen verarbeitet und Antworten generiert, sodass das Rauschen private Daten verdeckt. In der Realität wird häufig das Local Differential Privacy-Modell verwendet, bei dem die Benutzerdaten auf dem Gerät des Benutzers verbleiben (z. B. einem Mobiltelefon oder PC). Wenn die Entwickler jedoch auf Entwickleranfragen reagieren, sendet sie ein Datenpaket vom persönlichen Gerät, mit dem nicht genau herausgefunden werden kann, was Dieser bestimmte Benutzer hat geantwortet. Wenn Sie die Antworten einer großen Anzahl von Benutzern kombinieren, können Sie das Gesamtbild mit hoher Genauigkeit wiederherstellen.
Ein gutes Beispiel ist die Umfrage „Hatten Sie eine Abtreibung?“. Wenn Sie eine Umfrage "auf der Stirn" durchführen, wird niemand die Wahrheit sagen. Wenn Sie die Umfrage jedoch wie folgt organisieren: „Werfen Sie eine Münze, wenn es einen Adler gibt, werfen Sie sie erneut und sagen Sie„ Ja “zum Adler, aber„ Nein “zu den Schwänzen, ansonsten antworten Sie der Wahrheit“, ist es einfach, die wahre Verteilung wiederherzustellen und gleichzeitig die Privatsphäre des Einzelnen zu wahren. Die Entwicklung dieser Idee war die Mechanik der Erfassung sensibler Statistiken
Google RAPPOR (RAndomized Privacy-Preserving Ordinal Report), mit der Daten über die Verwendung von Chrome und seinen Gabeln erfasst wurden.
Unmittelbar nach der Veröffentlichung von Chrome in Open Source erschien eine ziemlich große Anzahl von Leuten, die ihren eigenen Browser mit einer überschriebenen Homepage, einer Suchmaschine, ihren eigenen Werbewürfeln usw. erstellen wollten. Natürlich waren Nutzer und Google davon nicht begeistert. Weitere Aktionen sind im Allgemeinen verständlich: um die häufigsten Substitutionen herauszufinden und administrativ zu vernichten, aber das Unerwartete kam heraus ... Aufgrund der Datenschutzbestimmungen von Chrome konnte Google keine Informationen zum Einrichten der Startseite und der Suchmaschine des Nutzers abrufen und sammeln :(
Um diese Einschränkung zu überwinden und RAPPOR zu erstellen, funktioniert dies wie folgt:
- Die Daten auf der Homepage werden in einem kleinen, etwa 128-Bit-Bloom-Filter aufgezeichnet.
- Diesem Blütenfilter wird permanentes weißes Rauschen hinzugefügt. Permanent = für diesen Benutzer gleich, ohne Rauschen zu sparen, können mehrere Anforderungen Benutzerdaten anzeigen.
- Zusätzlich zum konstanten Rauschen wird das für jede Anforderung erzeugte individuelle Rauschen überlagert.
- Der resultierende Bitvektor wird an Google gesendet, wo die Entschlüsselung des Gesamtbildes beginnt.
- Zunächst subtrahieren wir mit statistischen Methoden den Effekt von Rauschen vom Gesamtbild.
- Als nächstes erstellen wir Kandidatenbitvektoren (im Prinzip die beliebtesten Websites / Suchmaschinen).
- Auf der Grundlage der erhaltenen Vektoren konstruieren wir eine lineare Regression, um das Bild zu rekonstruieren.
- Kombinieren Sie die lineare Regression mit LASSO, um irrelevante Kandidaten zu unterdrücken.
Schematisch sieht der Aufbau des Filters folgendermaßen aus:

Die Erfahrungen mit der Implementierung von RAPPOR waren sehr positiv, und die Zahl der mit seiner Hilfe gesammelten privaten Statistiken wächst rasant. Unter den wichtigsten Erfolgsfaktoren identifizierten die Autoren:
- Einfachheit und Klarheit des Modells.
- Offenheit und Dokumentation des Codes.
- Das Vorhandensein der Fehlergrenzen in den endgültigen Diagrammen.
Dieser Ansatz weist jedoch eine erhebliche Einschränkung auf: Es ist erforderlich, Listen mit Kandidatenantworten für die Entschlüsselung zu haben (weshalb O - Ordinal). Als Apple anfing, Statistiken über die in Textnachrichten verwendeten Wörter und Emoji zu sammeln, wurde klar, dass dieser Ansatz nicht gut war. Infolgedessen war auf der WDC-2016-Konferenz eine der wichtigsten neuen Funktionen, die unter iOS angekündigt wurden, die Hinzufügung eines differenzierten Datenschutzes. Eine Kombination einer Skizzenstruktur mit zusätzlichem Rauschen wurde ebenfalls als Grundlage verwendet, jedoch mussten viele technische Probleme gelöst werden:
- Der Kunde (Telefon) sollte in der Lage sein, diese Antwort in angemessener Zeit zu erstellen und zu speichern.
- Ferner sollte diese Antwort in eine Netzwerknachricht mit begrenzter Größe gepackt werden.
- Auf der Apple-Seite sollte dies alles in angemessener Zeit aggregierbar sein.
Als Ergebnis haben wir ein Schema mit einer
Count-Min-Skizze zum Codieren von Wörtern entwickelt. Anschließend haben wir zufällig die Antwort nur einer der Hash-Funktionen ausgewählt (wobei jedoch die Auswahl für das Benutzer / Wort-Paar festgelegt wurde). Der Vektor wurde mithilfe der
Hadamard-Transformation konvertiert und nur an den Server gesendet ein signifikantes "Bit" für die ausgewählte Hash-Funktion.
Um das Ergebnis auf dem Server wiederherzustellen, mussten auch die Kandidatenhypothesen überprüft werden. Es stellte sich jedoch heraus, dass es mit einem großen Wörterbuch selbst für einen Cluster zu kompliziert ist. Es war notwendig, die vielversprechendsten Suchbereiche heuristisch auszuwählen. Das Experiment mit Bigrams als Ausgangspunkt, von dem aus Sie das Mosaik zusammensetzen können, war erfolglos - alle Bigrams waren ungefähr gleich beliebt. Der Bigram + Word-Hash-Ansatz löste das Problem, führte jedoch zu einer Verletzung der Privatsphäre. Infolgedessen haben wir uns für Präfixbäume entschieden: Statistiken wurden über die ersten Teile des Wortes und dann über das gesamte Wort gesammelt.
Eine Analyse des von Apple von der Forschungsgemeinschaft verwendeten Datenschutzalgorithmus hat jedoch gezeigt, dass der Datenschutz durch Langzeitstatistiken immer
noch gefährdet sein kann.
LinkedIn befand sich mit seiner Studie zur Verteilung der Benutzergehälter in einer schwierigeren Situation. Tatsache ist, dass die differenzielle Privatsphäre gut funktioniert, wenn wir eine sehr große Anzahl von Messungen haben, da es sonst nicht möglich ist, Rauschen zuverlässig zu subtrahieren. In der Gehaltsumfrage ist die Anzahl der Berichte begrenzt, und LinkedIn hat sich für einen anderen Weg entschieden: Kombinieren Sie technische Kryptografie- und Cybersicherheitstools mit dem Konzept der
k-Anonymität : Benutzerdaten gelten als ausreichend verschleiert, wenn Sie sie in einem Paket einreichen, in dem k Antworten mit denselben Eingabeattributen vorliegen (z. B. Standort und Beruf), die sich nur in der Zielvariablen (Gehalt) unterscheiden.
Infolgedessen wurde ein komplexer Förderer gebaut, in dem verschiedene Dienste Daten untereinander übertragen und ständig verschlüsseln, sodass eine einzelne Maschine sie nicht vollständig öffnen kann. Infolgedessen werden Benutzer nach Attributen in Kohorten unterteilt. Wenn die Kohorte die Mindestgröße erreicht, werden ihre Statistiken zur Analyse an HDFS gesendet.
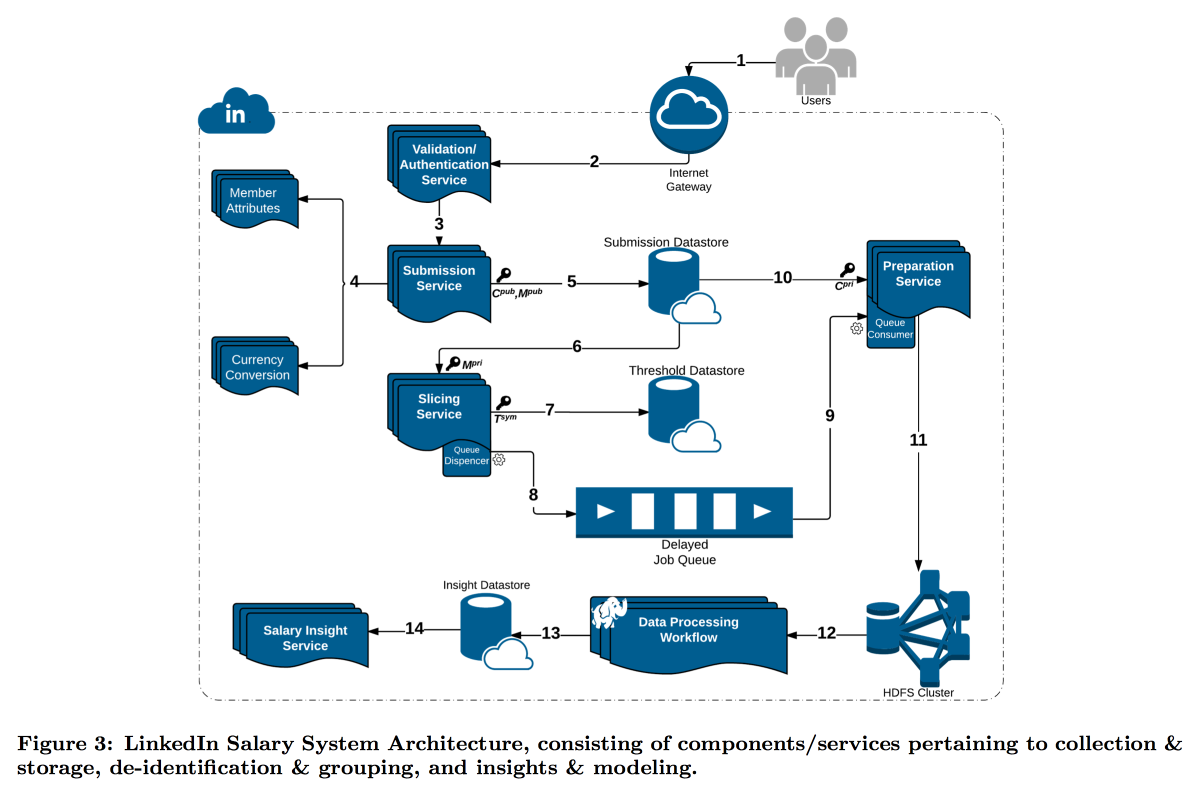
Der Zeitstempel verdient besondere Aufmerksamkeit: Er muss auch anonymisiert werden, sonst können Sie herausfinden, wessen Antwort das Protokoll der Anrufe ist. Aber ich möchte mir keine Zeit nehmen, weil es interessant ist, der Dynamik zu folgen. Aus diesem Grund haben wir beschlossen, den Attributen, mit denen die Kohorte erstellt wird, einen Zeitstempel hinzuzufügen und ihren Wert darin zu mitteln.
Das Ergebnis ist ein interessantes Premium-Feature und einige interessante offene Fragen:
Die DSGVO schlägt vor, dass wir auf Anfrage alle Benutzerdaten löschen können, aber wir haben versucht, sie auszublenden, damit wir jetzt nicht finden können, um welche Daten es sich handelt. Mit Daten zu einer großen Anzahl verschiedener Slices / Kohorten können Sie Übereinstimmungen isolieren und die Liste der offenen Attribute erweitern
Dieser Ansatz funktioniert für große Datenmengen, jedoch nicht für kontinuierliche Daten. Die Praxis zeigt, dass es keine gute Idee ist, Daten einfach abzutasten, aber Microsoft hat auf der NIPS2017
eine Lösung
vorgeschlagen, wie man damit arbeitet. Leider hatten die Details keine Zeit zur Offenlegung.
Analyse großer Graphen
Der zweite Workshop zur Analyse großer Graphen begann am Nachmittag. Trotz der Tatsache, dass er auch von den Jungs von Google geführt wurde und es mehr Erwartungen von ihm gab, mochte er ihn viel weniger - sie sprachen über ihre geschlossenen Technologien, fielen dann in Banalismus und allgemeine Philosophie, tauchten dann in wilde Details ein und hatten nicht einmal Zeit, die Aufgabe zu formulieren. Trotzdem konnte ich einige interessante Aspekte erfassen. Folien finden Sie
hier .
Erstens hat mir das Schema
Ego-Network Clustering gefallen.
Ich denke, es ist möglich, auf dieser Grundlage interessante Lösungen zu entwickeln. Die Idee ist sehr einfach:
- Wir betrachten das lokale Diagramm aus der Sicht eines bestimmten Benutzers, ABER ohne sich selbst.
- Wir gruppieren diesen Graphen.
- Als Nächstes „klonen“ wir die Oberseite unseres Benutzers, fügen jedem Cluster eine Instanz hinzu und verbinden sie nicht durch Kanten miteinander.
In einem ähnlichen transformierten Diagramm lassen sich viele Probleme leichter lösen und Ranking-Algorithmen funktionieren sauberer. Zum Beispiel ist es viel einfacher, ein solches Diagramm in ausgewogener Weise zu partitionieren, und wenn Sie in der Empfehlung von Freunden rangieren, sind die Brückenknoten viel weniger verrauscht. Für diese Aufgabe wurden die Empfehlungen von Freunden von ENC berücksichtigt / gefördert.
Im Allgemeinen war ENC jedoch nur ein Beispiel. Bei Google ist eine ganze Abteilung damit beschäftigt, Algorithmen für Diagramme zu entwickeln und diese anderen Abteilungen als Bibliothek zur Verfügung zu stellen. Die deklarierte Funktionalität der Bibliothek ist beeindruckend: eine Traumbibliothek für SNA, aber alles ist geschlossen. Im besten Fall kann versucht werden, einzelne Blöcke durch Artikel zu reproduzieren. Es wird behauptet, dass die Bibliothek Hunderte von Implementierungen in Google hat, einschließlich Grafiken mit mehr als einer Billion Kanten.
Dann gab es ungefähr 20 Minuten Werbung für das MapReduce-Modell, als ob wir nicht wüssten, wie cool es war. Danach zeigten die Jungs, dass viele komplexe Probleme (ungefähr) mit dem Modell Randomized Composable Core Sets gelöst werden können. Die Hauptidee ist, dass die Daten über die Kanten zufällig in N Knoten gestreut werden, dort in den Speicher gezogen werden und das Problem lokal gelöst wird, wonach die Ergebnisse der Lösung an die zentrale Maschine übertragen und aggregiert werden. Es wird argumentiert, dass Sie auf diese Weise kostengünstig gute Annäherungen für viele Probleme erhalten können: Konnektivitätskomponenten, minimale Spanning Forest, maximale Übereinstimmung, maximale Abdeckung usw. In einigen Fällen lösen sowohl Mapper als auch Reduce gleichzeitig das gleiche Problem, können jedoch geringfügig voneinander abweichen. Ein gutes Beispiel dafür, wie man eine einfache Lösung intelligent benennt, damit die Leute daran glauben.
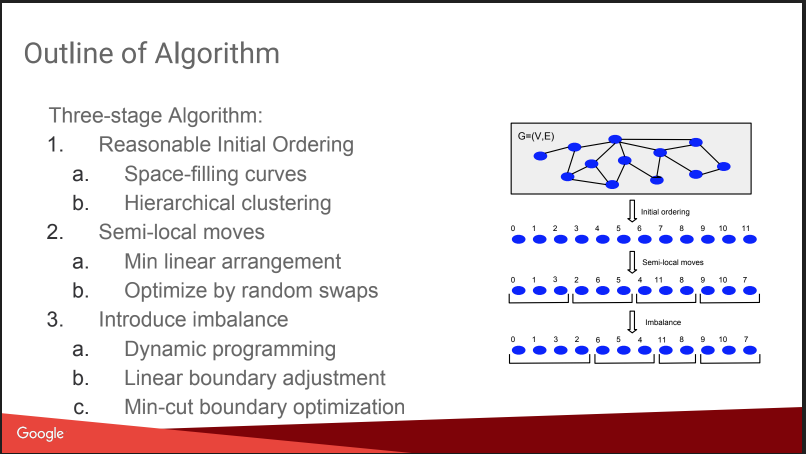
Dann gab es ein Gespräch darüber, was ich hier vorhatte: Balanced Graph Partitioning. Das heißt, wie man einen Graphen in N Teile schneidet, so dass die Teile ungefähr gleich groß sind und die Anzahl der Bindungen innerhalb der Teile signifikant größer ist als die Anzahl der externen Bindungen. Wenn Sie in der Lage sind, ein solches Problem gut zu lösen, werden viele Algorithmen einfacher, und sogar A / B-Tests können effizienter ausgeführt werden, wobei der virale Effekt kompensiert wird. Aber die Geschichte war ein wenig enttäuscht, alles sah aus wie ein „gnomischer Plan“: Zahlen basierend auf hierarchischen affinen Clustern zuweisen, verschieben, Ungleichgewicht hinzufügen. Keine Details. Darüber auf KDD wird es später einen separaten Bericht geben, ich werde versuchen zu gehen. Außerdem gibt es einen
Blog-Beitrag .
Trotzdem haben sie einen Vergleich mit einigen Konkurrenten gemacht, einige von ihnen sind offen:
Spinner ,
UB13 von FB,
Fenchel von Microsoft,
Metis . Sie können sie auch ansehen.
Dann haben wir ein bisschen über technische Details gesprochen. Sie verwenden verschiedene Paradigmen für die Arbeit mit Grafiken:
- MapReduce auf Flume. Ich wusste nicht, dass es möglich ist - Flume wird im Internet nicht viel zum Sammeln, aber nicht zum Analysieren von Daten geschrieben. Ich denke, das ist eine Intra-Google-Perversion. UPD: Ich habe herausgefunden, dass dies wirklich ein internes Google-Produkt ist. Es hat nichts mit Apache Flume zu tun. In der Cloud gibt es einen Ersatz namens Datenfluss
- MapReduce + Distributed Hash Table. Sie sagen, dass es hilft, die Anzahl der MP-Runden signifikant zu reduzieren, aber im Internet wird zum Beispiel hier nicht viel über diese Technik geschrieben
- Pregel - sie sagen, dass er bald sterben wird.
- ASYnchronous Message Passing ist das coolste, schnellste und vielversprechendste.
Die Idee von ASYMP ist Pregel sehr ähnlich:
- Knoten sind verteilt, behalten ihren Status und können eine Nachricht an Nachbarn senden.
- Auf dem Computer wird eine Warteschlange mit Prioritäten erstellt, die gesendet werden sollen (die Reihenfolge kann von der Reihenfolge der Hinzufügung abweichen).
- Nachdem der Knoten eine Nachricht empfangen hat, kann er den Status ändern oder nicht. Wenn er sich ändert, senden wir eine Nachricht an die Nachbarn.
- Beenden, wenn alle Warteschlangen leer sind.
Wenn wir beispielsweise nach verbundenen Komponenten suchen, initialisieren wir alle Scheitelpunkte mit zufälligen Gewichten U [0,1]. Danach senden wir mindestens Nachbarn aneinander. Dementsprechend suchen wir, nachdem wir ihre Mindestwerte von den Nachbarn erhalten haben, nach einem Mindestbetrag für sie usw., bis sich der Mindestbetrag stabilisiert hat. Sie stellen einen wichtigen Punkt für die Optimierung fest: Nachrichten von einem Knoten zu reduzieren (dies ist die Runde), wobei nur der letzte übrig bleibt. Sie sprechen auch darüber, wie einfach es ist, Fehler zu beheben und gleichzeitig den Status der Knoten beizubehalten.
Sie sagen, dass sie sehr schnelle Algorithmen ohne Probleme erstellen, es scheint wahr zu sein - das Konzept ist einfach und rational. Es gibt
Veröffentlichungen .
Infolgedessen bietet sich die Schlussfolgerung an: Es ist traurig, Geschichten über geschlossene Technologien zu erzählen, aber einige nützliche Punkte können aufgegriffen werden.