
In diesem Artikel werden wir ein Grundmodell eines Faltungsnetzwerks erstellen, das in der Lage ist,
Emotionen in Bildern zu erkennen. Das Erkennen von Emotionen ist in unserem Fall eine binäre Klassifizierungsaufgabe, deren Zweck darin besteht, die Bilder in positive und negative zu unterteilen.
Alle Codes, Notizbuchdokumente und andere Materialien, einschließlich der Docker-Datei, finden Sie
hier .
Daten
Der erste Schritt bei praktisch allen maschinellen Lernaufgaben besteht darin, die Daten zu verstehen. Lass es uns tun.
Datensatzstruktur
Rohdaten können hier heruntergeladen
werden (im Dokument
Baseline.ipynb werden alle Aktionen in diesem Abschnitt automatisch ausgeführt). Die Daten befinden sich zunächst im Archiv des Zip * -Formats. Packen Sie es aus und machen Sie sich mit der Struktur der empfangenen Dateien vertraut.
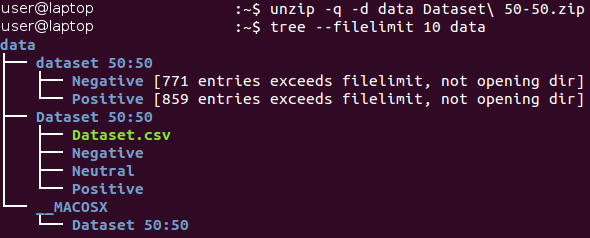
Alle Bilder werden im Katalog „Datensatz 50:50“ gespeichert und auf die beiden Unterverzeichnisse verteilt, deren Name ihrer Klasse entspricht - Negativ und Positiv. Bitte beachten Sie, dass die Aufgabe etwas
unausgewogen ist - 53 Prozent der Bilder sind positiv und nur 47 Prozent sind negativ. In der Regel werden Daten in Klassifizierungsproblemen als unausgewogen angesehen, wenn die Anzahl der Beispiele in verschiedenen Klassen sehr stark variiert. Es gibt eine
Reihe von Möglichkeiten, mit unausgeglichenen Daten zu arbeiten - zum Beispiel Überabtastung, Überabtastung, Änderung der Gewichtungsfaktoren von Daten usw. In unserem Fall ist das Ungleichgewicht unbedeutend und sollte den Lernprozess nicht dramatisch beeinflussen. Es ist nur zu beachten, dass der naive Klassifikator, der immer den Wert „positiv“ liefert, für diesen Datensatz einen Genauigkeitswert von ungefähr 53 Prozent liefert.
Schauen wir uns einige Bilder jeder Klasse an.
Negativ

 Positiv
Positiv


Auf den ersten Blick unterscheiden sich Bilder aus verschiedenen Klassen tatsächlich voneinander. Lassen Sie uns jedoch eine eingehendere Untersuchung durchführen und versuchen, schlechte Beispiele zu finden - ähnliche Bilder, die zu verschiedenen Klassen gehören.
Zum Beispiel haben wir ungefähr 90 Bilder von Schlangen, die als negativ markiert sind, und ungefähr 40 sehr ähnliche Bilder von Schlangen, die als positiv markiert sind.
Positives Bild einer Schlange Negatives Bild einer Schlange
Negatives Bild einer Schlange
Die gleiche Dualität tritt bei Spinnen (130 negative und 20 positive Bilder), Nacktheit (15 negative und 45 positive Bilder) und einigen anderen Klassen auf. Man hat das Gefühl, dass die Markierung der Bilder von verschiedenen Personen durchgeführt wurde und ihre Wahrnehmung des gleichen Bildes unterschiedlich sein kann. Daher enthält die Kennzeichnung ihre inhärente Inkonsistenz. Diese beiden Bilder von Schlangen sind fast identisch, während verschiedene Experten sie verschiedenen Klassen zuschrieben. Wir können daher den Schluss ziehen, dass es aufgrund seiner Natur kaum möglich ist, eine 100% ige Genauigkeit bei der Arbeit mit dieser Aufgabe sicherzustellen. Wir glauben, dass eine realistischere Schätzung der Genauigkeit ein Wert von 80 Prozent wäre - dieser Wert basiert auf dem Anteil ähnlicher Bilder, die während einer vorläufigen visuellen Überprüfung in verschiedenen Klassen gefunden wurden.
Trennung des Schulungs- / Verifizierungsprozesses
Wir sind immer bemüht, das bestmögliche Modell zu erstellen. Was bedeutet dieses Konzept jedoch? Hierfür gibt es viele verschiedene Kriterien, wie z. B. Qualität, Vorlaufzeit (Lernen + Ausgabe) und Speicherverbrauch. Einige von ihnen können einfach und objektiv gemessen werden (z. B. Zeit und Speichergröße), während andere (Qualität) viel schwieriger zu bestimmen sind. Zum Beispiel kann Ihr Modell eine 100-prozentige Genauigkeit aufweisen, wenn Sie aus Beispielen lernen, die so oft verwendet wurden, aber nicht mit neuen Beispielen arbeiten. Dieses Problem wird als
Überanpassung bezeichnet und ist eines der wichtigsten beim maschinellen Lernen. Es gibt auch das Problem der
Unteranpassung : In diesem Fall kann das Modell nicht aus den dargestellten Daten lernen und zeigt schlechte Vorhersagen, selbst wenn ein fester Trainingsdatensatz verwendet wird.
Um das Problem der Überanpassung zu lösen, wird die sogenannte Technik zum
Halten eines Teils der Proben verwendet . Die Hauptidee besteht darin, die Quelldaten in zwei Teile aufzuteilen:
- Ein Trainingssatz , der normalerweise den größten Teil des Datensatzes ausmacht und zum Trainieren des Modells verwendet wird.
- Der Testsatz besteht normalerweise aus einem kleinen Teil der Quelldaten, der vor Durchführung aller Trainingsverfahren in zwei Teile geteilt wird. Dieses Set wird im Training überhaupt nicht verwendet und gilt als neues Beispiel für das Testen des Modells nach Abschluss des Trainings.
Mit dieser Methode können wir beobachten, wie gut sich unser Modell
verallgemeinert (dh es funktioniert mit bisher unbekannten Beispielen).
In diesem Artikel wird ein Verhältnis von 4/1 für die Trainings- und Testsätze verwendet. Eine andere Technik, die wir verwenden, ist die sogenannte
Schichtung . Dieser Begriff bezieht sich auf die Partitionierung jeder Klasse unabhängig von allen anderen Klassen. Dieser Ansatz ermöglicht es, das gleiche Gleichgewicht zwischen den Klassengrößen in den Trainings- und Testsätzen aufrechtzuerhalten. Bei der Schichtung wird implizit davon ausgegangen, dass sich die Verteilung der Beispiele nicht ändert, wenn sich die Quelldaten ändern, und dass sie bei Verwendung neuer Beispiele gleich bleibt.
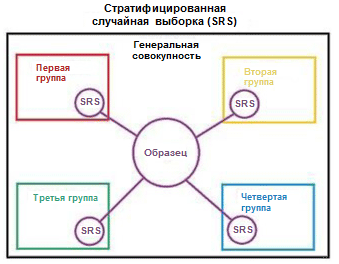
Wir veranschaulichen das Konzept der Schichtung anhand eines einfachen Beispiels. Angenommen, wir haben vier Datengruppen / Klassen mit einer angemessenen Anzahl von Objekten: Kinder (5), Jugendliche (10), Erwachsene (80) und ältere Menschen (5); siehe Bild rechts (aus
Wikipedia ). Jetzt müssen wir diese Daten in zwei Sätze von Stichproben in einem Verhältnis von 3/2 aufteilen. Bei Verwendung der Beispielschichtung erfolgt die Auswahl der Objekte unabhängig von jeder Gruppe: 2 Objekte aus der Gruppe der Kinder, 4 Objekte aus der Gruppe der Jugendlichen, 32 Objekte aus der Gruppe der Erwachsenen und 2 Objekte aus der Gruppe der älteren Menschen. Der neue Datensatz enthält 40 Objekte, was genau 2/5 der Originaldaten entspricht. Gleichzeitig entspricht das Gleichgewicht zwischen den Klassen im neuen Datensatz ihrem Gleichgewicht in den Quelldaten.
Alle oben genannten Aktionen werden in einer Funktion implementiert, die als
prepare_data bezeichnet wird . Diese Funktion finden Sie in der Python-Datei
utils.py . Diese Funktion lädt die Daten, teilt sie mit einer festen Zufallszahl (für die spätere Wiedergabe) in Trainings- und Testsätze auf und verteilt die Daten zur späteren Verwendung entsprechend auf die Verzeichnisse auf der Festplatte.
Vorbehandlung und Augmentation
In einem der vorherigen Artikel wurden Vorverarbeitungsaktionen und mögliche Gründe für ihre Verwendung in Form einer Datenerweiterung beschrieben. Faltungs-Neuronale Netze sind recht komplexe Modelle, für deren Training große Datenmengen erforderlich sind. In unserem Fall gibt es nur 1600 Beispiele - das reicht natürlich nicht aus.
Daher möchten wir den Datensatz erweitern, der von der Datenerweiterung verwendet wird. In Übereinstimmung mit den Informationen im Artikel zur Datenvorverarbeitung bietet die Keras * -Bibliothek die Möglichkeit, Daten im laufenden Betrieb zu erweitern, wenn sie von der Festplatte gelesen werden. Dies kann über die
ImageDataGenerator- Klasse erfolgen.
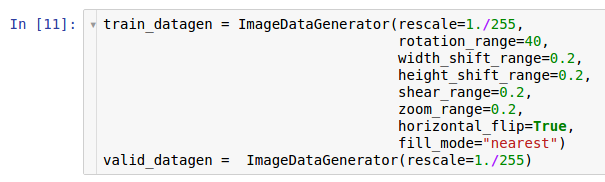
Hier werden zwei Instanzen der Generatoren erstellt. Die erste Instanz dient dem Training und verwendet viele zufällige Transformationen - wie Rotation, Verschiebung, Faltung, Skalierung und horizontale Rotation -, während Daten von der Festplatte gelesen und auf das Modell übertragen werden. Infolgedessen empfängt das Modell die konvertierten Beispiele, und jedes vom Modell empfangene Beispiel ist aufgrund der Zufälligkeit dieser Konvertierung eindeutig. Die zweite Kopie dient zur Überprüfung und vergrößert nur die Bilder. Generatoren lernen und testen haben nur eine gemeinsame Transformation - das Zoomen. Um die Rechenstabilität des Modells sicherzustellen, muss der Bereich [0; 1] anstelle von [0; 255].
Modellarchitektur
Nach dem Studieren und Vorbereiten der Anfangsdaten folgt die Phase der Erstellung des Modells. Da uns eine kleine Datenmenge zur Verfügung steht, werden wir ein relativ einfaches Modell erstellen, um es angemessen trainieren und die Situation der Überanpassung beseitigen zu können. Probieren wir die
VGG-Architektur aus , verwenden jedoch weniger Ebenen und Filter.
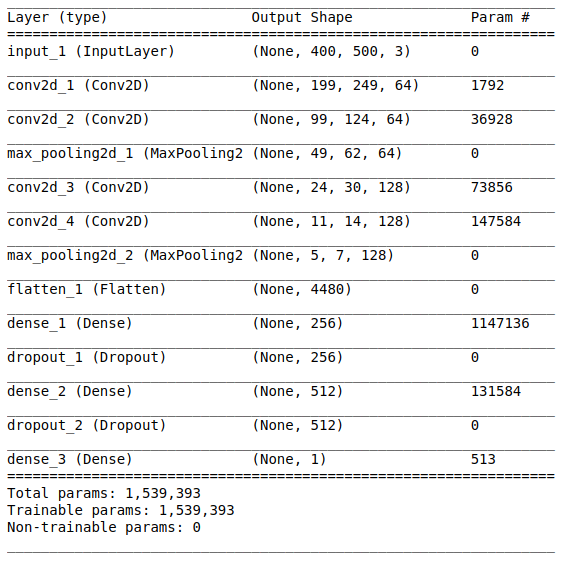

Die Netzwerkarchitektur besteht aus folgenden Teilen:
[Faltungsschicht + Faltungsschicht + Maximalwertauswahl] × 2Der erste Teil enthält zwei überlagerte Faltungsschichten mit 64 Filtern (mit Größe 3 und Schritt 2) und eine Schicht zur Auswahl des Maximalwerts (mit Größe 2 und Schritt 2), die sich danach befindet. Dieser Teil wird allgemein auch als
Merkmalsextraktionseinheit bezeichnet , da Filter aussagekräftige Merkmale effizient aus Eingabedaten extrahieren (weitere Informationen finden Sie im Artikel
Übersicht über Faltungsneurale Netze zur Bildklassifizierung ).
AusrichtungDieser Teil ist obligatorisch, da am Ausgang des Faltungsteils vier Beispiele erhalten werden (Beispiele, Höhe, Breite und Kanäle). Für eine gewöhnliche vollständig verbundene Schicht benötigen wir jedoch einen zweidimensionalen Tensor (Beispiele, Merkmale) als Eingabe. Daher ist es notwendig,
den Tensor um die letzten drei Achsen
auszurichten , um sie zu einer Achse zu kombinieren. Tatsächlich bedeutet dies, dass wir jeden Punkt in jeder Feature-Map als separate Eigenschaft betrachten und sie in einem Vektor ausrichten. Die folgende Abbildung zeigt ein Beispiel für ein 4 × 4-Bild mit 128 Kanälen, das in einem erweiterten Vektor mit einer Länge von 1024 Elementen ausgerichtet ist.
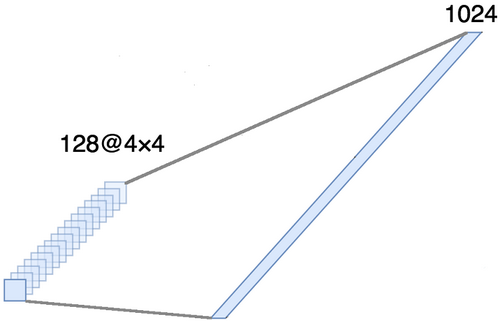 [Vollschicht + Ausschlussmethode] × 2
[Vollschicht + Ausschlussmethode] × 2Hier ist der
Klassifizierungsteil des Netzwerks. Sie betrachtet die Eigenschaften der Bilder ausgerichtet und versucht, sie bestmöglich zu klassifizieren. Dieser Teil des Netzwerks besteht aus zwei überlagerten Blöcken, die aus einer vollständig verbundenen Schicht und
einer Ausschlussmethode bestehen . Wir haben bereits vollständig verbundene Schichten kennengelernt - normalerweise sind dies Schichten mit einer vollständig verbundenen Verbindung. Aber was ist die "Ausschlussmethode"? Die Ausschlussmethode ist eine
Regularisierungstechnik , die eine Überanpassung verhindert. Eines der möglichen Anzeichen für eine Überanpassung sind extrem unterschiedliche Werte der Gewichtskoeffizienten (Größenordnungen). Es gibt viele Möglichkeiten, dieses Problem zu lösen, einschließlich Gewichtsreduzierung und Eliminierungsmethode. Die Idee der Eliminierungsmethode besteht darin, zufällige Neuronen während des Trainings zu trennen (die Liste der nicht verbundenen Neuronen sollte nach jedem Paket / jeder Trainingsära aktualisiert werden). Dies verhindert sehr stark, dass völlig unterschiedliche Werte für die Gewichtungskoeffizienten erhalten werden - auf diese Weise wird das Netzwerk reguliert.
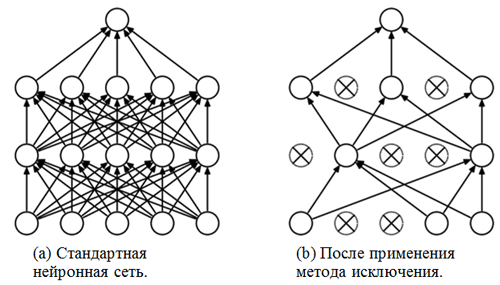
Ein Beispiel für die Anwendung der Ausschlussmethode (die Abbildung stammt aus dem Artikel
Ausschlussmethode: Ein einfacher Weg, um eine Überanpassung in neuronalen Netzen zu verhindern ):
Sigmoid-ModulDie Ausgabeschicht sollte der Aussage des Problems entsprechen. In diesem Fall haben wir es mit dem Problem der binären Klassifizierung zu tun, daher benötigen wir ein Ausgangsneuron mit einer
Sigmoid- Aktivierungsfunktion, die die Wahrscheinlichkeit P der Zugehörigkeit zur Klasse mit der Nummer 1 schätzt (in unserem Fall sind dies positive Bilder). Dann kann die Wahrscheinlichkeit der Zugehörigkeit zur Klasse mit der Nummer 0 (negative Bilder) leicht als 1 - P berechnet werden.
Einstellungen und Trainingsoptionen
Wir haben die Modellarchitektur ausgewählt und sie mithilfe der Keras-Bibliothek für die Python-Sprache angegeben. Darüber hinaus ist es vor Beginn des Modelltrainings erforderlich
, es zu
kompilieren .

In der Kompilierungsphase wird das Modell auf das Training abgestimmt. In diesem Fall müssen drei Hauptparameter angegeben werden:
- Der Optimierer . In diesem Fall verwenden wir den Standardoptimierer Adam *, einen stochastischen Gradientenabstiegsalgorithmus mit Moment und adaptiver Lerngeschwindigkeit (weitere Informationen finden Sie im Blogeintrag von S. Ruder Übersicht über Algorithmen zur Gradientenabstiegsoptimierung ).
- Verlustfunktion . Unsere Aufgabe ist ein binäres Klassifizierungsproblem, daher wäre es angebracht, die binäre Kreuzentropie als Verlustfunktion zu verwenden.
- Metriken . Dies ist ein optionales Argument, mit dem Sie zusätzliche Metriken angeben können, die während des Trainingsprozesses verfolgt werden sollen. In diesem Fall müssen wir die Genauigkeit zusammen mit der Zielfunktion verfolgen.
Jetzt sind wir bereit, das Modell zu trainieren. Bitte beachten Sie, dass der Schulungsvorgang mit den im vorherigen Abschnitt initialisierten Generatoren durchgeführt wird.
Die Anzahl der Epochen ist ein weiterer Hyperparameter, der angepasst werden kann. Hier weisen wir ihm einfach den Wert 10 zu. Wir möchten auch das Modell und den Lernverlauf speichern, um es später herunterladen zu können.

Bewertung
Nun wollen wir sehen, wie gut unser Modell funktioniert. Zunächst betrachten wir die Änderung der Metriken im Lernprozess.
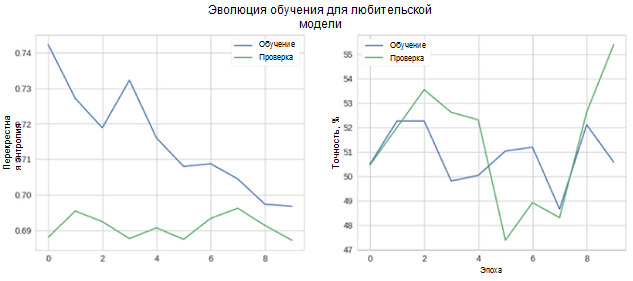
In der Abbildung sehen Sie, dass die Kreuzentropie von Verifikation und Genauigkeit mit der Zeit nicht abnimmt. Darüber hinaus schwankt die Genauigkeitsmetrik für den Trainings- und Testsatz einfach um den Wert eines Zufallsklassifikators. Die endgültige Genauigkeit für den Testsatz beträgt 55 Prozent, was nur geringfügig besser ist als eine zufällige Schätzung.
Schauen wir uns an, wie Modellvorhersagen zwischen Klassen verteilt werden. Zu diesem Zweck ist es erforderlich, eine
Matrix von Ungenauigkeiten mit der entsprechenden Funktion aus dem Sklearn * -Paket für die Python-Sprache zu erstellen und zu visualisieren.
Jede Zelle in der Matrix der Ungenauigkeiten hat ihren eigenen Namen:
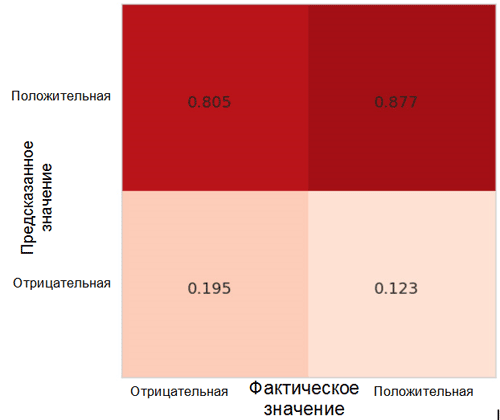
- True Positive Rate = TPR (obere rechte Zelle) repräsentiert den Anteil positiver Beispiele (in unserem Fall Klasse 1, dh positive Emotionen), die korrekt als positiv eingestuft wurden.
- Falsch positive Rate = FPR (untere rechte Zelle) repräsentiert den Anteil positiver Beispiele, die fälschlicherweise als negativ eingestuft werden (Klasse 0, dh negative Emotionen).
- True Negative Rate = TNR (untere linke Zelle) repräsentiert den Anteil negativer Beispiele, die korrekt als negativ klassifiziert wurden.
- Falsch negative Rate = FNR (obere linke Zelle) repräsentiert den Anteil negativer Beispiele, die fälschlicherweise als positiv klassifiziert werden.
In unserem Fall liegen sowohl TPR als auch FPR nahe bei 1. Dies bedeutet, dass fast alle Objekte als positiv eingestuft wurden. Daher ist unser Modell nicht weit vom naiven Basismodell mit konstanten Vorhersagen einer größeren Klasse entfernt (in unserem Fall sind dies positive Bilder).
Eine weitere interessante Metrik, die interessant zu beobachten ist, ist die Empfängerleistungskurve (ROC-Kurve) und die Fläche unter dieser Kurve (ROC AUC). Eine formale Definition dieser Konzepte finden Sie
hier . Kurz gesagt, die ROC-Kurve zeigt, wie gut der binäre Klassifikator funktioniert.
Der Klassifikator unseres Faltungs-Neuronalen Netzwerks hat ein Sigmoid-Modul als Ausgabe, das die Wahrscheinlichkeit des Beispiels der Klasse 1 zuordnet. Nehmen wir nun an, unser Klassifikator zeigt gute Arbeit und weist Beispiele der Klasse 0 (das grüne Histogramm in der folgenden Abbildung) niedrige Wahrscheinlichkeitswerte für Beispiele mit niedrigen Wahrscheinlichkeitswerten zu Klasse 1 (blaues Histogramm).
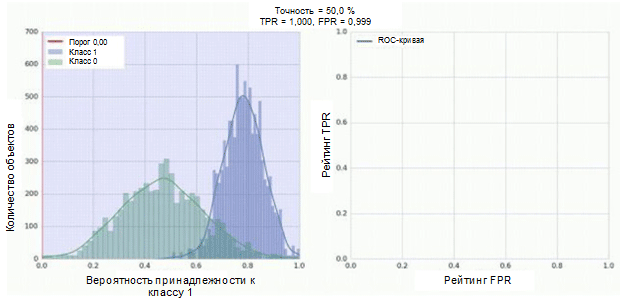
Die ROC-Kurve zeigt, wie der TPR-Indikator vom FPR-Indikator abhängt, wenn der Klassifizierungsschwellenwert von 0 auf 1 verschoben wird (rechte Abbildung, oberer Teil). Denken Sie zum besseren Verständnis des Schwellenwertkonzepts daran, dass wir für jedes Beispiel die Wahrscheinlichkeit haben, zur Klasse 1 zu gehören. Die Wahrscheinlichkeit ist jedoch noch keine Klassenbezeichnung. Daher sollte es mit einem Schwellenwert verglichen werden, um festzustellen, zu welcher Klasse das Beispiel gehört. Wenn der Schwellenwert beispielsweise 1 ist, sollten alle Beispiele als zur Klasse 0 gehörend klassifiziert werden, da der Wahrscheinlichkeitswert nicht mehr als 1 betragen kann und die Werte der FPR- und TPR-Indikatoren in diesem Fall 0 sind (da keine der Stichproben als positiv klassifiziert ist ) Diese Situation entspricht dem Punkt ganz links auf der ROC-Kurve. Auf der anderen Seite der Kurve befindet sich ein Punkt, an dem der Schwellenwert 0 ist: Dies bedeutet, dass alle Stichproben als zur Klasse 1 gehörend klassifiziert sind und die Werte von TPR und FPR gleich 1 sind. Die Zwischenpunkte zeigen das Verhalten der TPR / FPR-Abhängigkeit, wenn sich der Schwellenwert ändert.
Die diagonale Linie im Diagramm entspricht einem zufälligen Klassifikator. Je besser unser Klassifikator funktioniert, desto näher liegt seine Kurve am oberen linken Punkt des Diagramms. Der objektive Indikator für die Qualität des Klassifikators ist somit die Fläche unter der ROC-Kurve (ROC AUC-Indikator). Der Wert dieses Indikators sollte so nahe wie möglich an 1 liegen. Der AUC-Wert von 0,5 entspricht einem zufälligen Klassifikator.
Die AUC in unserem Modell (siehe Abbildung oben) beträgt 0,57, was bei weitem nicht das beste Ergebnis ist.
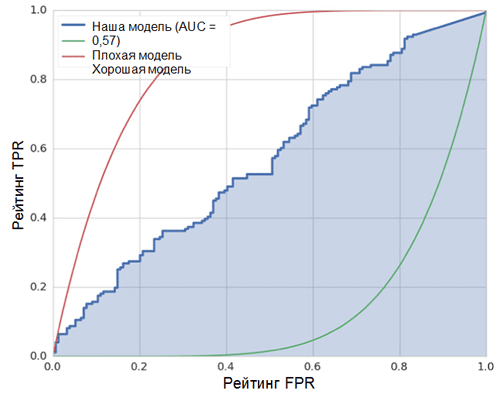
Alle diese Metriken zeigen, dass das resultierende Modell nur geringfügig besser ist als der Zufallsklassifizierer. Dafür gibt es mehrere Gründe, die wichtigsten werden nachfolgend beschrieben:
- Sehr kleine Datenmenge für das Training, die nicht ausreicht, um die charakteristischen Merkmale von Bildern hervorzuheben. Selbst eine Datenerweiterung konnte in diesem Fall nicht helfen.
- Ein relativ komplexes Faltungsmodell für neuronale Netze (im Vergleich zu anderen Modellen für maschinelles Lernen) mit einer großen Anzahl von Parametern.
Fazit
In diesem Artikel haben wir ein einfaches Faltungsmodell für neuronale Netze zum Erkennen von Emotionen in Bildern erstellt. Gleichzeitig wurden in der Trainingsphase eine Reihe von Methoden zur Datenerweiterung verwendet, und das Modell wurde auch unter Verwendung einer Reihe von Metriken wie Genauigkeit, ROC-Kurve, ROC-AUC und Ungenauigkeitsmatrix bewertet. Das Modell zeigte Ergebnisse, nur einige der besten Zufallszahlen.
Der Grund dafür ist die unzureichende Datenmenge.