Eine Demonstration der Verwendung von Open Source-Tools wie Packer und Terraform, um kontinuierlich Infrastrukturänderungen an den bevorzugten Cloud-Umgebungen der Benutzer bereitzustellen.
Das Material basiert auf einer Präsentation von Paul Stack auf unserer Herbstkonferenz
DevOops 2017. Paul ist ein Infrastrukturentwickler, der früher bei HashiCorp gearbeitet und an der Entwicklung von Tools mitgewirkt hat, die von Millionen von Menschen (z. B. Terraform) verwendet wurden. Er spricht häufig auf Konferenzen und vermittelt die Praxis von der Spitze der CI / CD-Implementierungen, den Prinzipien der ordnungsgemäßen Organisation des Betriebsteils, und kann klar erklären, warum Administratoren dies überhaupt tun. Der Rest des Artikels wird in der ersten Person erzählt.
Beginnen wir also gleich mit einigen wichtigen Erkenntnissen.
Lang laufender Server ist scheiße

Ich habe zuvor in einer Organisation gearbeitet, in der wir 2008 Windows Server 2003 bereitgestellt haben, und heute sind sie noch in Produktion. Und ein solches Unternehmen ist nicht allein. Über den Remotedesktop auf diesen Servern installieren sie die Software manuell und laden Binärdateien aus dem Internet herunter. Dies ist eine sehr schlechte Idee, da die Server nicht typisch sind. Sie können nicht garantieren, dass in der Produktion dasselbe passiert wie in Ihrer Entwicklungsumgebung, in der Zwischenumgebung, in der QS-Umgebung.
Unveränderliche Infrastruktur
Im Jahr 2013 erschien auf Chad Foilers Blog ein Artikel mit dem Titel „Wirf deine Server und brenne deinen Code: unveränderliche Infrastruktur und Einwegkomponenten
“ (Chad Foiler
„ Mach
deine Server kaputt
und brenne deinen Code: Unveränderliche Infrastruktur und Einwegkomponenten
“ ). Dies ist meistens ein Gespräch darüber, dass unveränderliche Infrastruktur der Weg in die Zukunft ist. Wir haben die Infrastruktur geschaffen, und wenn wir sie ändern müssen, schaffen wir eine neue Infrastruktur. Dieser Ansatz ist in der Cloud sehr verbreitet, da er hier schnell und günstig ist. Wenn Sie physische Rechenzentren haben, ist dies etwas schwieriger. Wenn Sie die Virtualisierung von Rechenzentren ausführen, wird es natürlich einfacher. Wenn Sie jedoch jedes Mal physische Server starten, dauert die Eingabe eines neuen Servers etwas länger als die Änderung eines vorhandenen.
Einweginfrastruktur
Laut funktionalen Programmierern ist „unveränderlich“ der falsche Begriff für dieses Phänomen. Denn um wirklich unveränderlich zu sein, benötigt Ihre Infrastruktur ein schreibgeschütztes Dateisystem: Es werden keine Dateien lokal geschrieben, niemand kann SSH oder RDP usw. verwenden. Somit scheint die Infrastruktur tatsächlich nicht unveränderlich zu sein.
Die Terminologie wurde sechs oder sogar acht Tage lang von mehreren Personen auf Twitter diskutiert. Am Ende waren sie sich einig, dass eine „einmalige Infrastruktur“ eine geeignetere Formulierung ist. Wenn der Lebenszyklus der „einmaligen Infrastruktur“ endet, kann er leicht zerstört werden. Sie müssen sich nicht daran festhalten.
Ich werde eine Analogie geben. Farmkühe gelten im Allgemeinen nicht als Haustiere.

Wenn Sie Rinder auf der Farm haben, geben Sie ihnen keine individuellen Namen. Jede Person hat eine Nummer und ein Etikett. So ist es auch mit Servern. Wenn Sie 2006 noch manuell Server in der Produktion erstellt haben, haben diese signifikante Namen, z. B. "SQL-Datenbank in Produktion 01". Und sie haben eine ganz bestimmte Bedeutung. Und wenn einer der Server abstürzt, beginnt die Hölle.
Wenn eines der Tiere in der Herde stirbt, kauft der Bauer einfach ein neues. Dies ist die "einmalige Infrastruktur".
Kontinuierliche Lieferung
Wie kombinieren Sie dies mit Continuous Delivery?
Alles, worüber ich jetzt spreche, gibt es schon seit einiger Zeit. Ich versuche nur, die Ideen der Infrastrukturentwicklung und der Softwareentwicklung zu kombinieren.
Softwareentwickler setzen sich seit langem für eine kontinuierliche Bereitstellung und Integration ein. Zum Beispiel schrieb Martin Fowler Anfang der 2000er Jahre in seinem Blog über kontinuierliche Integration. Jez Humble fördert seit langem die kontinuierliche Lieferung.
Bei näherer Betrachtung wird nichts speziell für den Quellcode der Software erstellt. Es gibt eine Standarddefinition von Wikipedia:
Continuous Delivery ist eine Reihe von Praktiken und Prinzipien, die darauf abzielen, Software so schnell wie möglich zu erstellen, zu testen und freizugeben .
Die Definition bedeutet nicht Webanwendungen oder APIs, sondern Software im Allgemeinen. Das Erstellen einer Puzzlesoftware erfordert viele Puzzleteile. Auf diese Weise können Sie auf die gleiche Weise die kontinuierliche Bereitstellung von Infrastrukturcode üben.
Die Entwicklung von Infrastruktur und Anwendungen ist ziemlich eng. Und Leute, die Anwendungscode schreiben, schreiben auch Infrastrukturcode (und umgekehrt). Diese Welten beginnen sich zu vereinen. Es gibt keine solche Trennung mehr und die spezifischen Fallen jeder der Welten.
Grundsätze und Praktiken für die kontinuierliche Lieferung
Kontinuierliche Lieferung hat eine Reihe von Prinzipien:
- Der Software-Release- / Bereitstellungsprozess muss wiederholbar und zuverlässig sein.
- Alles automatisieren!
- Wenn ein Eingriff schwierig oder schmerzhaft ist, tun Sie es öfter.
- Behalten Sie alles in der Quellcodeverwaltung.
- Fertig - bedeutet "unveröffentlicht".
- Arbeit mit Qualität verbinden!
- Jeder ist für den Release-Prozess verantwortlich.
- Erhöhen Sie die Kontinuität.
Noch wichtiger ist jedoch, dass die kontinuierliche Lieferung vier Praktiken umfasst. Nehmen Sie sie und übertragen Sie sie direkt in die Infrastruktur:
- Erstellen Sie Binärdateien nur einmal. Erstellen Sie Ihren Server einmal. Hier geht es von Anfang an um „Verfügbarkeit“.
- Verwenden Sie in jeder Umgebung denselben Bereitstellungsmechanismus. Üben Sie keine unterschiedlichen Bereitstellungen in Entwicklung und Produktion. Sie müssen in jeder Umgebung denselben Pfad verwenden. Es ist sehr wichtig.
- Testen Sie Ihre Bereitstellung. Ich habe viele Anwendungen erstellt. Ich habe viele Probleme verursacht, weil ich den Bereitstellungsmechanismus nicht befolgt habe. Sie sollten immer überprüfen, was passiert. Und ich sage nicht, dass Sie fünf oder sechs Stunden für groß angelegte Tests aufwenden sollten. Genug "Rauchtest". Sie haben einen wichtigen Teil des Systems, mit dem Sie und Ihr Unternehmen bekanntlich Geld verdienen können. Seien Sie nicht zu faul, um mit dem Testen zu beginnen. Wenn Sie dies nicht tun, kann es zu Unterbrechungen kommen, die Ihr Unternehmen Geld kosten.
- Und schließlich das Wichtigste. Wenn etwas kaputt geht, halten Sie an und reparieren Sie es sofort! Sie können nicht zulassen, dass das Problem wächst und immer schlimmer wird. Sie müssen es reparieren. Das ist wirklich wichtig.
Hat jemand das Buch
Continuous Delivery gelesen?

Ich bin sicher, Ihre Unternehmen werden Ihnen eine Kopie bezahlen, die Sie innerhalb des Teams übertragen können. Ich sage nicht, dass Sie sich hinsetzen und einen Tag frei haben sollten, um es zu lesen. Wenn Sie dies tun, möchten Sie wahrscheinlich die IT beenden. Ich empfehle jedoch, regelmäßig kleine Teile des Buches zu beherrschen, sie zu verarbeiten und darüber nachzudenken, wie Sie dies auf Ihre Umgebung, Ihre Kultur und Ihren Prozess übertragen können. Ein kleines Stück nach dem anderen. Denn kontinuierliche Versorgung ist ein Gespräch über kontinuierliche Verbesserung. Es ist nicht einfach, sich mit Kollegen und dem Chef ins Büro zu setzen und ein Gespräch mit der Frage zu beginnen: „Wie implementieren wir die kontinuierliche Lieferung?“. Schreiben Sie dann 10 Dinge an die Tafel und verstehen Sie nach 10 Tagen, dass Sie sie implementiert haben. Dies nimmt viel Zeit in Anspruch, verursacht viele Proteste, weil sich mit der Einführung der Kultur Veränderungen ergeben.
Heute werden wir zwei Tools verwenden: Terraform und Packer (beide sind Hashicorp-Entwicklungen). In einer weiteren Diskussion geht es darum, warum wir Terraform verwenden sollten und wie wir es in unsere Umgebung integrieren können. Es ist kein Zufall, dass ich über diese beiden Tools spreche. Bis vor kurzem habe ich auch bei Hashicorp gearbeitet. Aber selbst nachdem ich Hashicorp verlassen habe, trage ich immer noch zum Code dieser Tools bei, weil ich sie tatsächlich sehr nützlich finde.
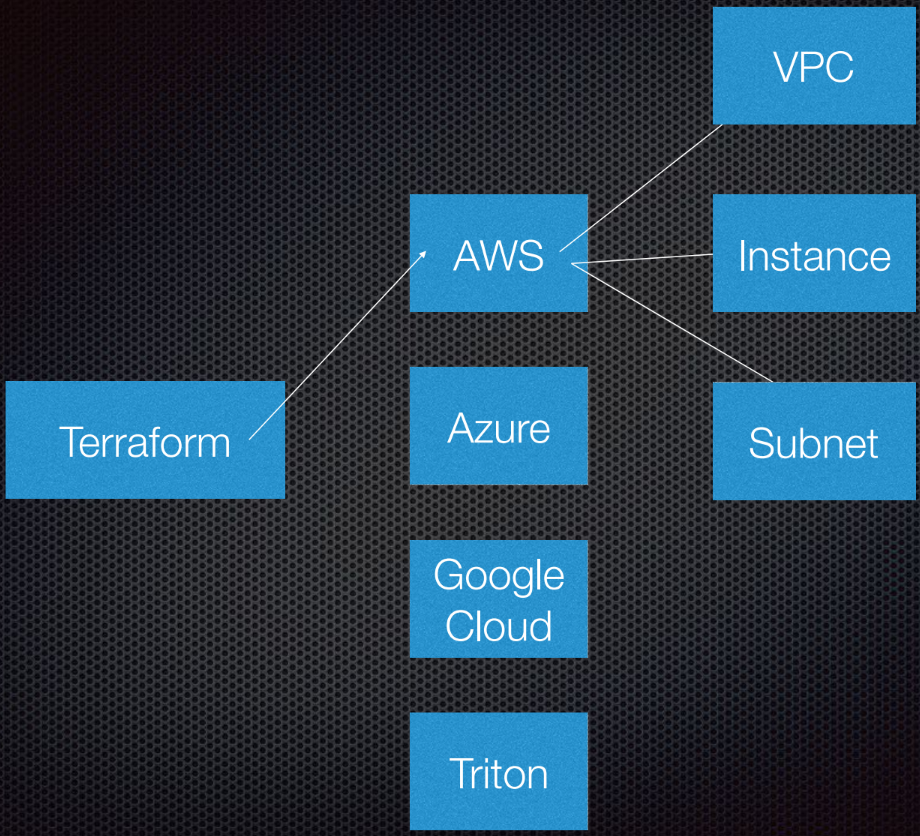
Terraform unterstützt die Interaktion mit Anbietern. Anbieter sind Clouds, Saas-Dienste usw.
Innerhalb jedes Cloud-Dienstanbieters gibt es mehrere Ressourcen, z. B. ein Subnetz, eine VPC, einen Load Balancer usw. Mit DSL (domänenspezifische Sprache) teilen Sie Terraform mit, wie Ihre Infrastruktur aussehen wird.
Terraform verwendet die Graphentheorie.

Sie kennen wahrscheinlich die Graphentheorie. Knoten sind Teile unserer Infrastruktur, z. B. ein Load Balancer, ein Subnetz oder eine VPC. Rippen sind die Beziehungen zwischen diesen Systemen. Dies ist alles, was ich persönlich für notwendig halte, um etwas über die Graphentheorie zu wissen, um Terraform verwenden zu können. Den Rest überlassen wir den Experten.

Terraform verwendet tatsächlich einen gerichteten Graphen, da es nicht nur die Beziehungen, sondern auch deren Reihenfolge kennt: A (angenommen, A ist VPC) muss auf B gesetzt werden, das ein Subnetz ist. Und B muss vor C (Instanz) erstellt werden, da es ein vorgeschriebenes Verfahren zum Erstellen von Abstraktionen in Amazon oder einer anderen Cloud gibt.
Weitere Informationen zu diesem Thema finden Sie auf
YouTube von Paul Hinze, der noch immer Infrastrukturdirektor bei Hashicorp ist. Als Referenz - ein großartiges Gespräch über Infrastruktur und Graphentheorie.
Übe
Einen Code zu schreiben ist viel besser als eine Theorie zu diskutieren.
Ich habe zuvor AMI (Amazon Machine Images) erstellt. Ich benutze Packer, um sie zu erstellen und werde Ihnen zeigen, wie es geht.
AMI ist eine Instanz eines virtuellen Servers in Amazon. Sie ist vordefiniert (in Bezug auf Konfiguration, Anwendungen usw.) und wird aus einem Image erstellt. Ich finde es toll, dass ich neue AMIs erstellen kann. AMIs sind im Wesentlichen meine Docker-Container.
Also, ich habe AMI, sie haben einen Ausweis. Wenn wir zur Amazon-Oberfläche gehen, sehen wir, dass wir nur einen AMI haben und nichts weiter:

Ich kann Ihnen zeigen, was in diesem AMI steckt. Alles ist sehr einfach.
Ich habe eine JSON-Dateivorlage:
{ "variables": { "source_ami": "", "region": "", "version": "" }, "builders": [{ "type": "amazon-ebs", "region": "{{user 'region'}}", "source_ami": "{{user 'source_ami'}}", "ssh_pty": true, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ssh_timeout": "5m", "associate_public_ip_address": true, "ami_virtualization_type": "hvm", "ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}", "tags": { "Version": "{{user 'version'}}" } }], "provisioners": [ { "type": "shell", "start_retry_timeout": "10m", "inline": [ "sudo apt-get update -y", "sudo apt-get install -y ntp nginx" ] }, { "type": "file", "source": "application-files/nginx.conf", "destination": "/tmp/nginx.conf" }, { "type": "file", "source": "application-files/index.html", "destination": "/tmp/index.html" }, { "type": "shell", "start_retry_timeout": "5m", "inline": [ "sudo mkdir -p /usr/share/nginx/html", "sudo mv /tmp/index.html /usr/share/nginx/html/index.html", "sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf", "sudo systemctl enable nginx.service" ] } ] }
Wir haben Variablen, die wir übergeben, und Packer hat eine Liste sogenannter Builder für verschiedene Bereiche. es gibt viele von ihnen. Builder verwendet eine spezielle AMI-Quelle, die ich in einer AMI-ID übergebe. Ich gebe ihm den SSH-Benutzernamen und das Passwort und gebe an, ob er eine öffentliche IP-Adresse benötigt, damit die Leute von außen darauf zugreifen können. In unserem Fall spielt dies keine Rolle, da es sich um eine AWS-Instanz für Packer handelt.
Wir setzen auch den AMI-Namen und die Tags.
Sie müssen diesen Code nicht analysieren. Er ist nur hier, um Ihnen zu zeigen, wie er arbeitet. Der wichtigste Teil hier ist die Version. Es wird später relevant, wenn wir Terraform betreten.
Nachdem der Builder die Instanz aufgerufen hat, werden die Bereitstellungsagenten darauf gestartet. Ich installiere tatsächlich NCP und Nginx, um Ihnen zu zeigen, was ich hier tun kann. Ich kopiere einige Dateien und richte einfach die Nginx-Konfiguration ein. Alles ist sehr einfach. Dann aktiviere ich nginx so, dass es startet, wenn die Instanz startet.
Ich habe also einen Anwendungsserver und es funktioniert. Ich kann es in Zukunft verwenden. Ich überprüfe jedoch immer meine Packer-Vorlagen. Da es sich um eine JSON-Konfiguration handelt, bei der möglicherweise Probleme auftreten.
Dazu führe ich den folgenden Befehl aus:
make validate
Ich erhalte die Antwort, dass die Packer-Vorlage erfolgreich überprüft wurde:
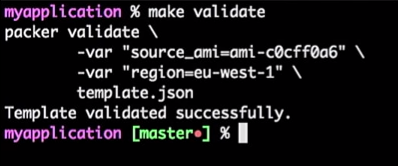
Dies ist nur ein Befehl, damit ich ihn mit dem CI-Tool (jedem) verbinden kann. Tatsächlich handelt es sich um einen Prozess: Wenn der Entwickler die Vorlage ändert, wird die Pull-Anforderung generiert, das CI-Tool überprüft die Anforderung, führt das Äquivalent zur Überprüfung der Vorlage durch und veröffentlicht die Vorlage bei erfolgreicher Überprüfung. All dies kann im "Master" kombiniert werden.
Wir erhalten einen Stream für AMI-Vorlagen - Sie müssen nur die Version erhöhen.
Angenommen, der Entwickler hat eine neue Version von AMI erstellt.
Ich werde nur die Version in den Dateien von 1.0.0 bis 1.0.1 korrigieren, um Ihnen den Unterschied zu zeigen:
<html> <head> <tittle>Welcome to DevOops!</tittle> </head> <body> <h1>Welcome!</h1> <p>Welcome to DevOops!</p> <p>Version: 1.0.1</p> </body> </html>
Ich werde zur Befehlszeile zurückkehren und mit der Erstellung von AMI beginnen.
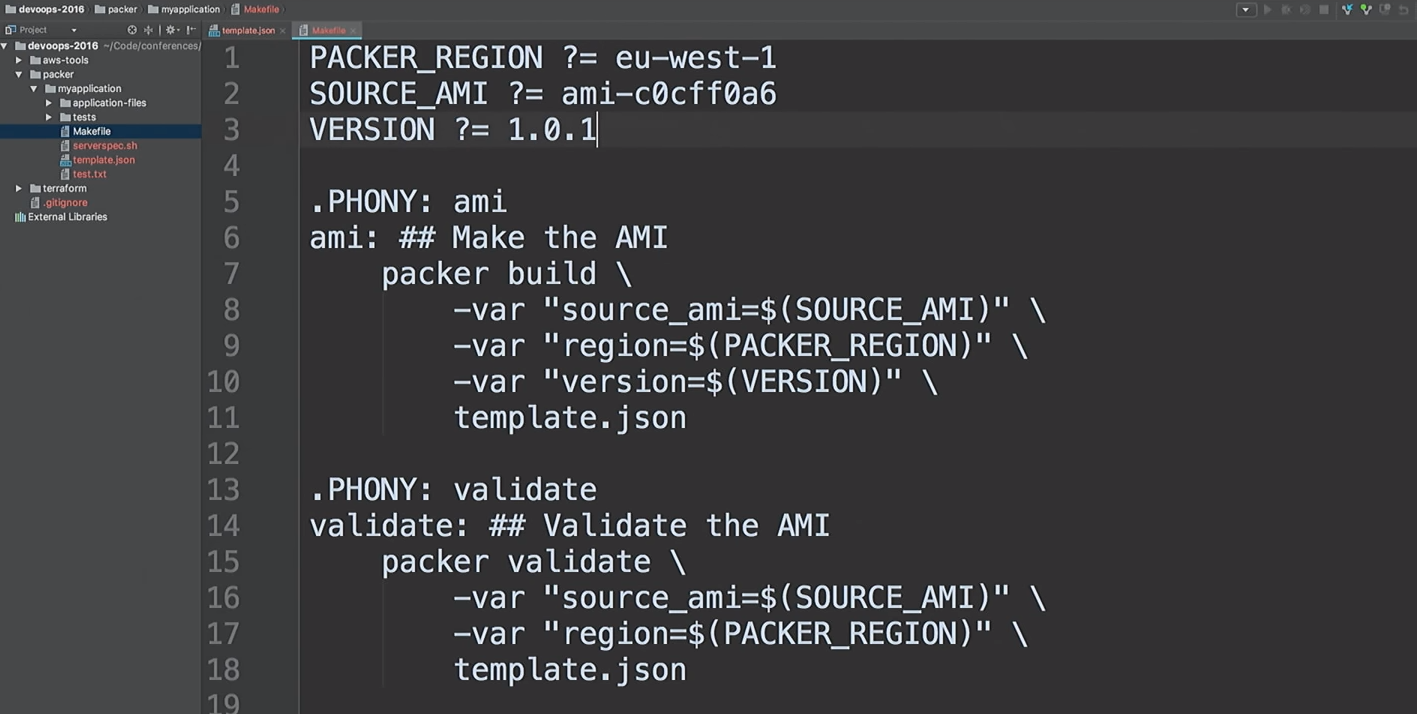
Ich mag es nicht, die gleichen Teams zu leiten. Ich mag es, AMI schnell zu erstellen, also benutze ich Makefiles. Werfen wir einen Blick mit
cat in meinem Makefile:
cat Makefile

Das ist mein Makefile. Ich habe sogar Hilfe bereitgestellt: Ich tippe
make und klicke auf die Registerkarte. Daraufhin werden alle Ziele angezeigt.

Also werden wir eine neue AMI Version 1.0.1 erstellen.
make ami

Zurück zu Terraform.
Ich betone, dass dies kein Produktionscode ist. Dies ist eine Demonstration. Es gibt Möglichkeiten, dasselbe besser zu machen.
Ich benutze überall Terraform-Module. Da ich nicht mehr an Hashicorp arbeite, kann ich meine Meinung zu den Modulen äußern. Für mich befinden sich die Module auf der Kapselungsebene. Zum Beispiel möchte ich alles zusammenfassen, was mit VPC zu tun hat: Netzwerke, Subnetze, Routing-Tabellen usw.
Was ist drinnen los? Entwickler, die damit arbeiten, interessieren sich möglicherweise nicht dafür. Sie müssen ein grundlegendes Verständnis dafür haben, wie die Cloud funktioniert und was VPC ist. Es ist jedoch nicht notwendig, sich mit den Details zu befassen. Nur Leute, die ein Modul wirklich ändern müssen, sollten es verstehen.
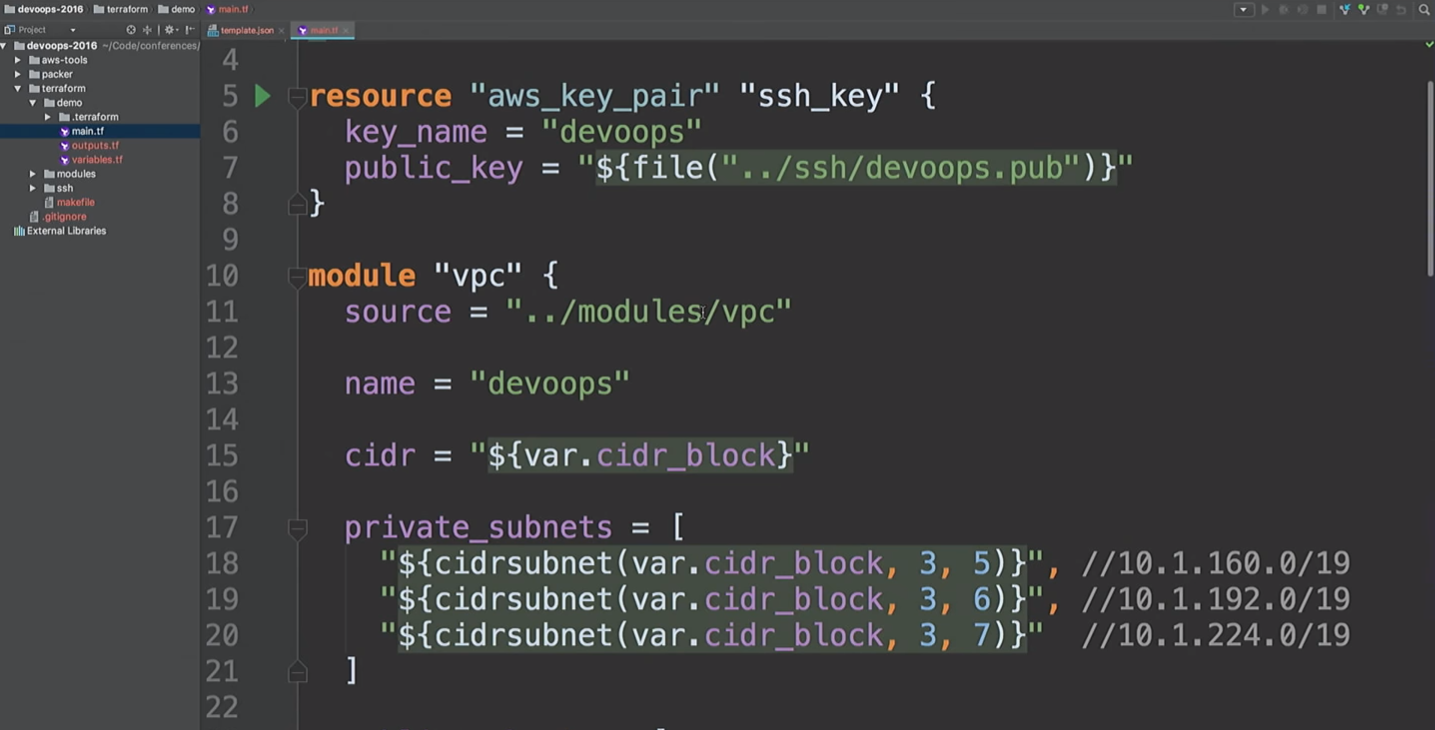

Hier werde ich eine AWS-Ressource und ein VPC-Modul erstellen. Was ist hier los? Nehmen Sie
cidr_block obersten Ebene und erstellen Sie drei private und drei öffentliche Subnetze. Das Folgende ist eine Liste von acailability_zones. Wir wissen jedoch nicht, um welche Zugänglichkeitszonen es sich handelt.

Wir werden ein VPN erstellen. Verwenden Sie dieses VPN-Modul einfach nicht. Dies ist openVPN, mit dem eine AWS-Instanz ohne Zertifikat erstellt wird. Es verwendet nur die öffentliche IP-Adresse und wird hier nur erwähnt, um Ihnen zu zeigen, dass wir eine Verbindung zum VPN herstellen können. Es gibt bequemere Tools zum Erstellen eines VPN. Ich brauchte ungefähr 20 Minuten und zwei Biere, um meine eigenen zu schreiben.
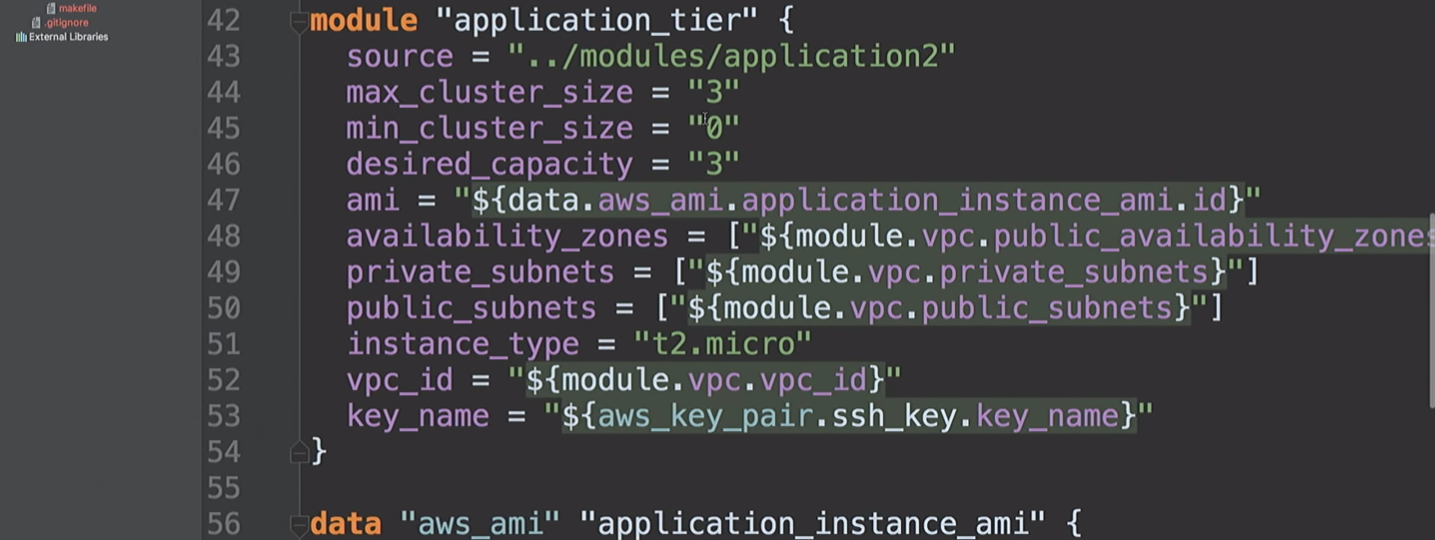


Dann erstellen wir eine
application_tier , eine automatische Skalierungsgruppe - einen Load Balancer. Einige Startkonfigurationen basieren auf der AMI-ID, kombinieren mehrere Subnetze und Verfügbarkeitszonen und verwenden auch einen SSH-Schlüssel.
Kommen wir gleich darauf zurück.
Ich habe bereits Verfügbarkeitszonen erwähnt. Sie unterscheiden sich für verschiedene AWS-Konten. Mein Konto in den USA im Osten hat möglicherweise Zugriff auf die Zonen A, B und D. Ihr AWS-Konto hat möglicherweise Zugriff auf B, C und E. Wenn Sie diese Werte im Code korrigieren, treten Probleme auf. Wir von Hashicorp schlugen vor, solche Datenquellen zu erstellen, damit wir Amazon fragen können, was uns zur Verfügung steht. Unter der Haube fordern wir eine Beschreibung der Verfügbarkeitszonen an und geben dann eine Liste aller Zonen für Ihr Konto zurück. Dank dessen können wir Datenquellen für AMI verwenden.
Jetzt gehen wir meiner Demonstration auf den Grund. Ich habe eine automatische Skalierungsgruppe erstellt, in der drei Instanzen ausgeführt werden. Standardmäßig haben alle die Version 1.0.0.
Wenn wir die neue Version von AMI bereitstellen, starte ich die Terraform-Konfiguration erneut, dies ändert die Startkonfiguration und der neue Dienst erhält die nächste Version des Codes usw. Und wir können sie steuern.

Wir sehen, dass Packer fertig ist und wir haben einen neuen AMI.
Ich gehe zurück zu Amazon, aktualisiere die Seite und sehe einen zweiten AMI.

Zurück zu Terraform.
Ab Version 0.10 hat Terraform Anbieter in separate Repositorys aufgeteilt. Der Befehl
init terraform erhält eine Kopie des Anbieters, der zum Ausführen benötigt wird.

Anbieter geladen. Wir sind bereit, vorwärts zu kommen.
Als nächstes müssen wir
terraform get ausführen - die notwendigen Module laden. Sie sind jetzt auf meinem lokalen Computer. Terraform erhält also alle Module lokal. Im Allgemeinen können Module in ihren eigenen Repositorys auf GitHub oder anderswo gespeichert werden. Deshalb habe ich über das VPC-Modul gesprochen. Sie können dem Netzwerkteam Zugriff gewähren, um Änderungen vorzunehmen. Und dies ist die API, mit der das Entwicklungsteam zusammenarbeiten kann. Wirklich hilfreich.
Der nächste Schritt besteht darin, ein Diagramm zu erstellen.
Beginnen Sie mit
terraform plan

Terraform nimmt den aktuellen lokalen Status und vergleicht ihn mit dem AWS-Konto, wobei die Unterschiede angezeigt werden. In unserem Fall wird er 35 neue Ressourcen erstellen.
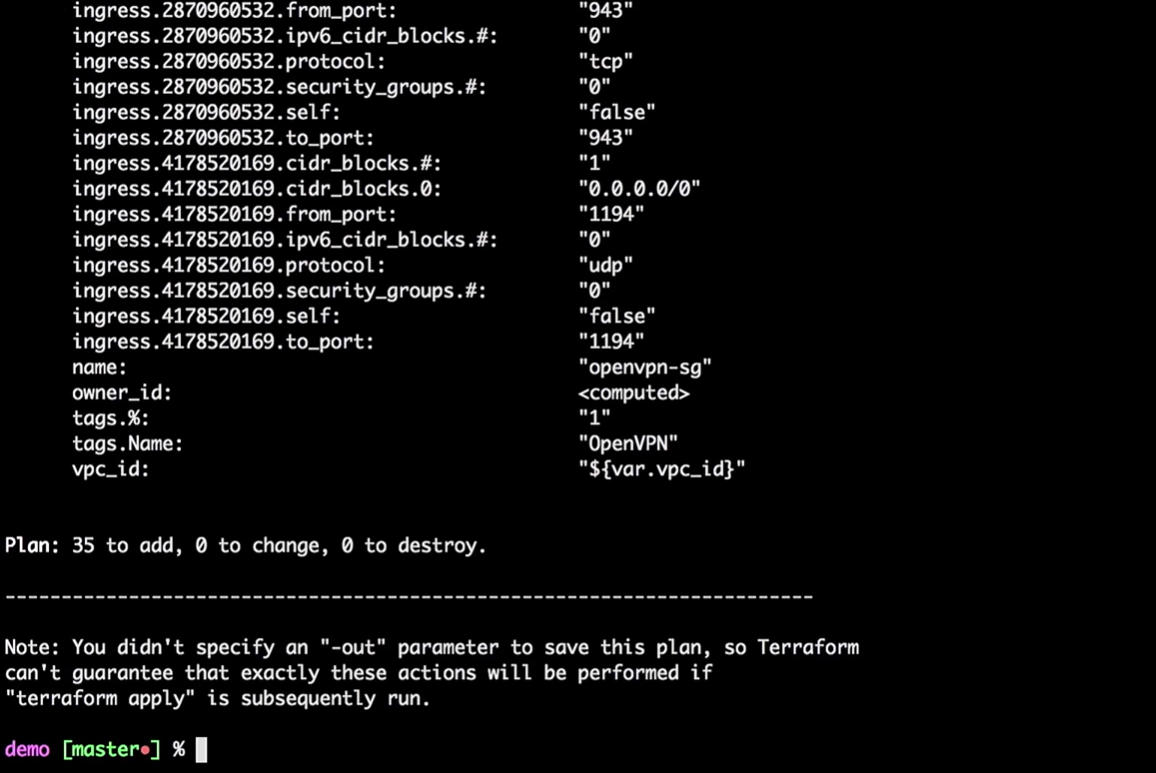
Jetzt wenden wir die Änderungen an:
terraform apply
Sie müssen dies nicht alles vom lokalen Computer aus tun. Dies sind nur Befehle, die Variablen an Terraform übergeben. Sie können diesen Prozess auf CI-Tools portieren.
Wenn Sie dies in CI verschieben möchten, müssen Sie den Remote-Status verwenden. Ich möchte, dass jeder, der Terraform jemals verwendet, mit Remote-Status arbeitet. Bitte verwenden Sie nicht den lokalen Staat.
Einer meiner Freunde bemerkte, dass er auch nach all den Jahren der Arbeit mit Terraform immer noch etwas Neues entdeckt. Wenn Sie beispielsweise eine AWS-Instanz erstellen, müssen Sie ihr ein Kennwort geben, damit sie in Ihrem Status gespeichert werden kann. Als ich bei Hashicorp arbeitete, gingen wir davon aus, dass es einen kollaborativen Prozess geben würde, der dieses Passwort ändert. Versuchen Sie daher nicht, alles lokal zu speichern. Und dann können Sie all dies in die CI-Tools einfügen.
So wird die Infrastruktur für mich geschaffen.

Terraform kann ein Diagramm erstellen:
terraform graph
Wie ich schon sagte, er baut einen Baum. In der Tat gibt es Ihnen die Möglichkeit zu bewerten, was in Ihrer Infrastruktur passiert. Er zeigt Ihnen die Beziehung zwischen all den verschiedenen Teilen - allen Knoten und Kanten. Da Verbindungen Richtungen haben, sprechen wir von einem gerichteten Graphen.
Das Diagramm ist eine JSON-Liste, die in einer PNG- oder DOC-Datei gespeichert werden kann.
Zurück zu Terraform. Wir erstellen wirklich eine automatische Skalierungsgruppe.

Die automatische Skalierungsgruppe hat eine Kapazität von 3.

Eine interessante Frage: Können wir Vault verwenden, um Geheimnisse in Terraform zu verwalten? Leider nein. In Terraform gibt es keine Vault-Datenquelle zum Lesen von Geheimnissen. Es gibt andere Möglichkeiten, z. B. Umgebungsvariablen. Mit ihrer Hilfe müssen Sie keine Geheimnisse in den Code eingeben, sondern können sie als Umgebungsvariablen lesen.
Wir haben also einige Infrastruktureinrichtungen:
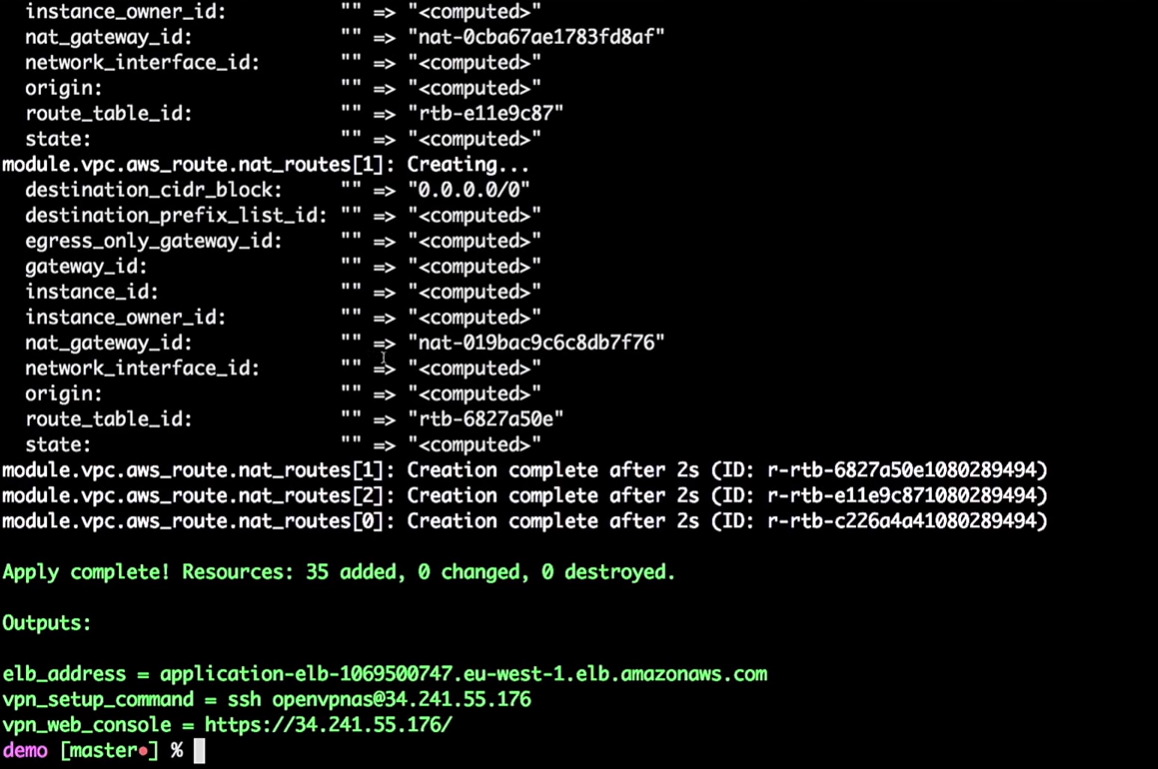
Ich gebe mein sehr geheimes VPN ein (knacke meine VPNs nicht).
Das Wichtigste dabei ist, dass wir drei Instanzen der Anwendung haben. Es stimmt, ich hätte notieren sollen, welche Version der Anwendung auf ihnen ausgeführt wird. Es ist sehr wichtig.
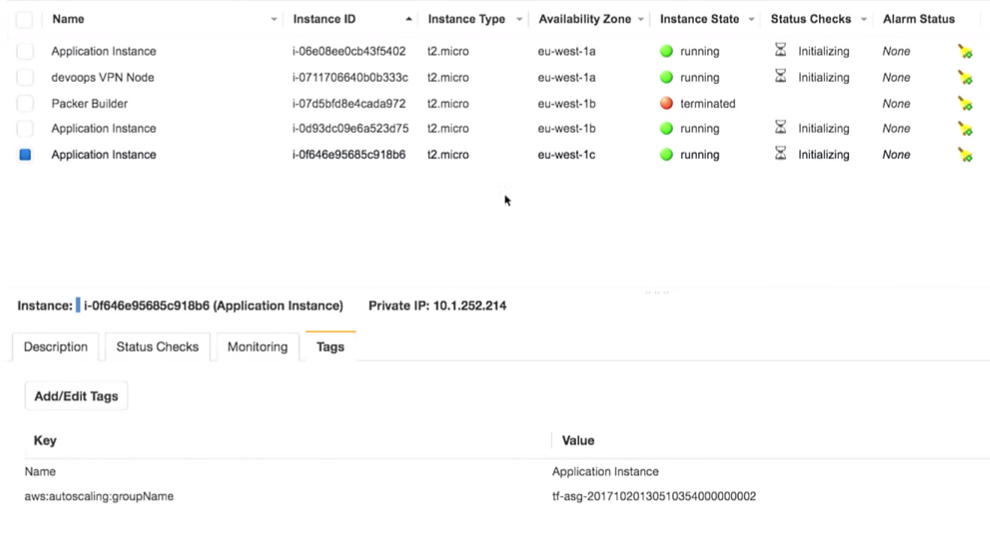
Alles steckt wirklich hinter dem VPN:

Wenn ich dies nehme (
application-elb-1069500747.eu-west-1.elb.amazonaws.com ) und es in die Adressleiste des Browsers einfüge, erhalte ich Folgendes:

Ich möchte Sie daran erinnern, dass ich mit einem VPN verbunden bin. Wenn ich mich abmelde, ist die angegebene Adresse nicht verfügbar.
Wir sehen Version 1.0.0. Und egal wie oft wir die Seite aktualisieren, wir erhalten 1.0.0.
Was passiert, wenn ich die Version im Code von 1.0.0 auf 1.0.1 ändere?
filter { name = "tag:Version" values = ["1.0.1"] }
Mit CI-Tools stellen Sie natürlich sicher, dass Sie die richtige Version erstellen.
Ich stelle keine manuellen Updates fest! Wir sind unvollkommen, machen Fehler und können bei manueller Aktualisierung Version 1.0.6 anstelle von 1.0.1 verwenden.
filter { name = "tag:Version" values = ["1.0.6"] }
Aber fahren wir mit unserer Version (1.0.1) fort.
terraform plan
Terraform aktualisiert den Status:
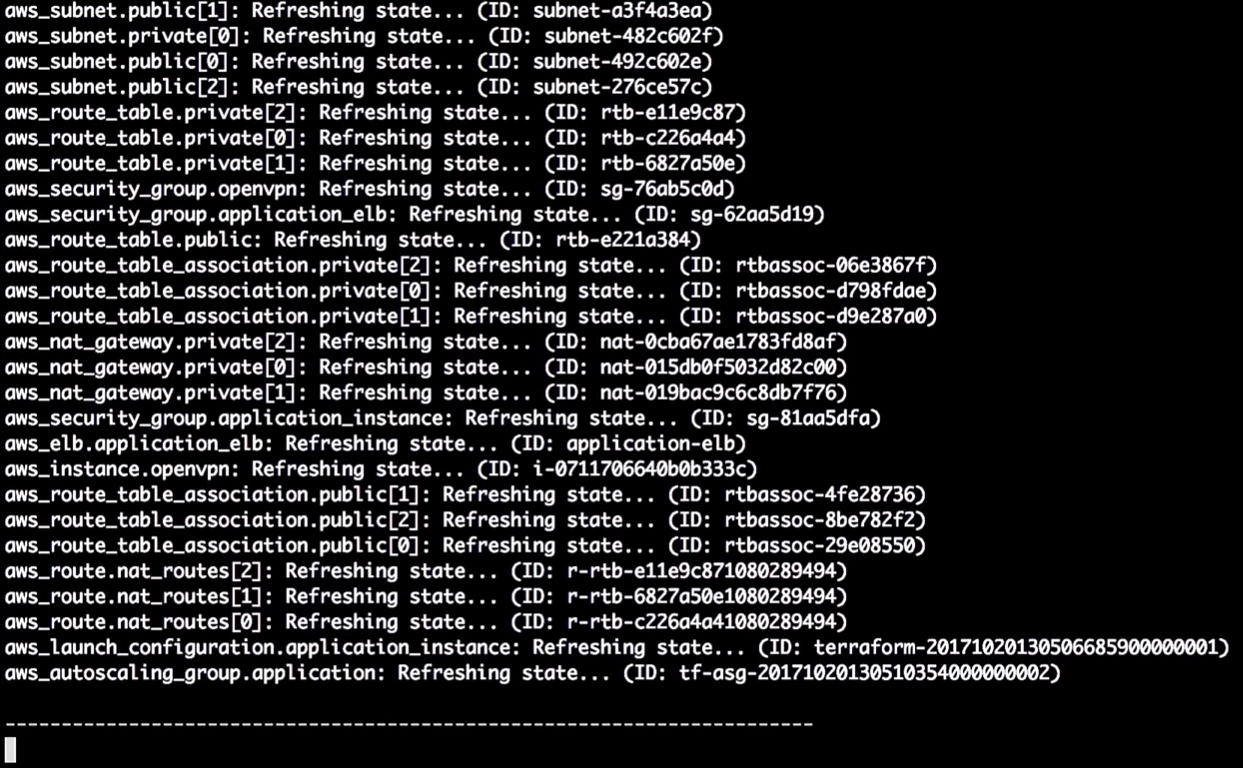

In diesem Moment teilt er mir mit, dass er die Version in der Startkonfiguration ändern wird. Aufgrund der Änderung der Kennung wird ein Neustart der Konfiguration erzwungen, und die Gruppe für die automatische Skalierung ändert sich (dies ist erforderlich, um die neue Startkonfiguration zu aktivieren).
Dies ändert keine laufenden Instanzen. Das ist wirklich wichtig. Sie können diesen Prozess verfolgen und testen, ohne die Instanzen in der Produktion zu ändern.
Hinweis: Sie müssen immer eine neue Startkonfiguration erstellen, bevor Sie die alte zerstören. Andernfalls tritt ein Fehler auf.
Wenden wir die Änderungen an:
terraform apply
Nun zurück zu AWS. Wenn alle Änderungen übernommen wurden, wechseln wir zur Gruppe für die automatische Skalierung.
Fahren wir mit der AWS-Konfiguration fort. Wir sehen, dass es drei Instanzen mit einer Startkonfiguration gibt. Sie sind die gleichen.
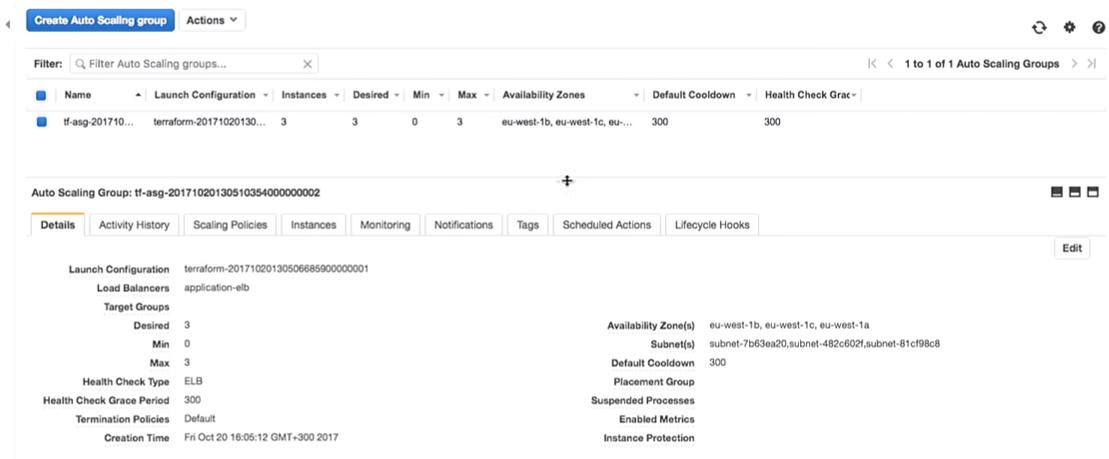
Amazon garantiert, dass drei Instanzen des Dienstes tatsächlich gestartet werden, wenn wir sie ausführen möchten. Deshalb zahlen wir ihnen Geld.
Fahren wir mit den Experimenten fort.
Eine neue Startkonfiguration wurde erstellt. Wenn ich eine der Instanzen lösche, wird der Rest nicht beschädigt. Es ist wichtig. Wenn Sie die Instanzen jedoch direkt verwenden, während Sie die Benutzerdaten ändern, werden die "Live" -Instanzen zerstört. Bitte tu das nicht.
Löschen Sie also eine der Instanzen:

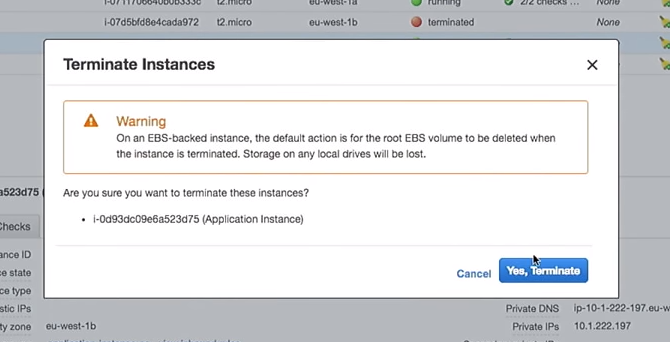
Was passiert in der automatischen Skalierungsgruppe, wenn sie heruntergefahren wird? An seiner Stelle wird eine neue Instanz angezeigt.
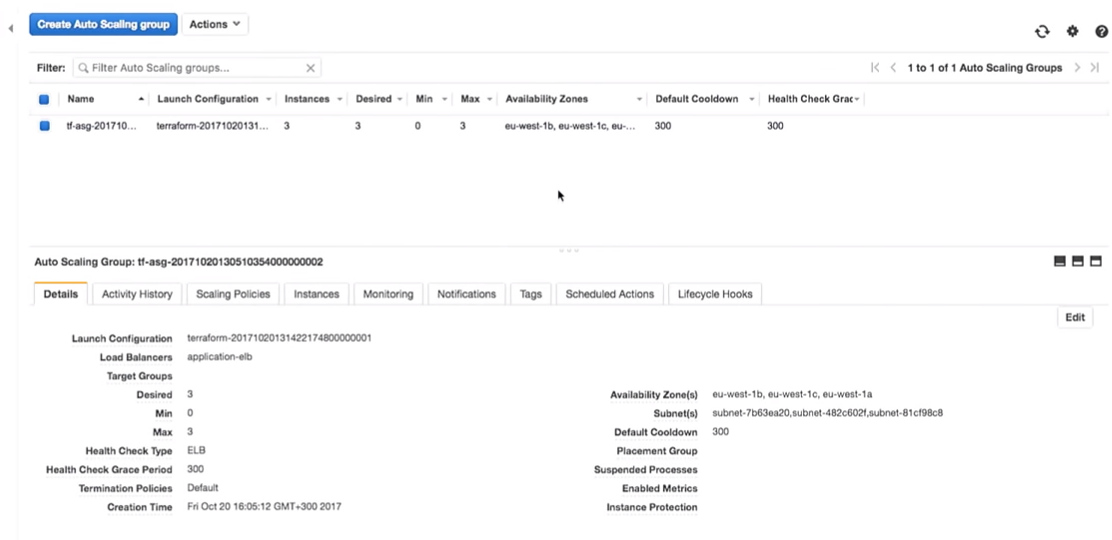
Hier befinden Sie sich in einer interessanten Situation. Die Instanz wird mit der neuen Konfiguration gestartet. Das heißt, im System haben Sie möglicherweise mehrere unterschiedliche Images (mit unterschiedlichen Konfigurationen). Manchmal ist es besser, die alte Startkonfiguration nicht sofort zu löschen, um bei Bedarf eine Verbindung herzustellen.
Hier wird alles noch interessanter. Warum nicht mit CI-Skripten und -Tools und nicht manuell, wie ich zeige? Es gibt Tools, die dies tun können, z. B. die hervorragenden AWS-Missing-Tools auf GitHub.

Und was macht dieses Tool? Dies ist ein Bash-Skript, das alle Instanzen im Load Balancer durchläuft, sie einzeln zerstört und sicherstellt, dass an ihrer Stelle neue erstellt werden.
Wenn ich eine meiner Instanzen mit Version 1.0.0 verloren habe und eine neue erschien - 1.1.1, möchte ich alle 1.0.0 beenden und alles auf die neue Version übertragen. Weil ich mich immer vorwärts bewege. Ich möchte Sie daran erinnern, dass es mir nicht gefällt, wenn der Anwendungsserver lange lebt.
In einem der Projekte hatte ich alle sieben Tage ein Kontrollskript, das alle Instanzen in meinem Konto zerstörte. Der Server war also nicht älter als sieben Tage. Eine andere Sache (mein Favorit) ist es, die Server mit SSH in einer Box als "befleckt" zu markieren und sie jede Stunde mit einem Skript zu zerstören. Wir möchten nicht, dass die Leute dies manuell tun.
Mit solchen Steuerungsskripten haben Sie immer die neueste Version mit behobenen Fehlern und Sicherheitsupdates.
Sie können das Skript einfach verwenden, indem Sie Folgendes ausführen:
aws-ha-relesae.sh -a my-scaling-group
-a ist Ihre automatische Skalierungsgruppe. Das Skript durchläuft alle Instanzen Ihrer automatischen Skalierungsgruppe und ersetzt sie. Sie können es nicht nur manuell, sondern auch über das CI-Tool ausführen.
Sie können dies in der Qualitätssicherung oder in der Produktion tun. Sie können dies sogar in Ihrem lokalen AWS-Konto tun. Sie tun jedes Mal, wenn Sie denselben Mechanismus verwenden, was Sie wollen.
Zurück zu Amazon. Wir haben eine neue Instanz:

Nachdem wir die Seite im Browser aktualisiert haben, auf dem wir zuvor Version 1.0.0 gesehen haben, erhalten wir:

Das Interessante ist, dass wir seit der Erstellung des AMI-Erstellungsskripts die Erstellung von AMI testen können.
Es gibt einige großartige Tools wie ServerScript oder Serverspec.
Mit Serverspec können Sie Spezifikationen im Ruby-Stil erstellen, um zu testen, wie Ihr Anwendungsserver aussieht. Im Folgenden gebe ich zum Beispiel einen Test, der überprüft, ob nginx auf dem Server installiert ist.
require 'spec_helper' describe package('nginx') do it { should be_installed } end describe service('nginx') do it { sould be_enabled } it { sould be_running } end describe port(80) do it { should be_listening } end
Nginx muss auf dem Server installiert sein und ausgeführt werden und Port 80 überwachen. Sie können sagen, dass Benutzer X auf dem Server verfügbar sein muss. Und Sie können all diese Tests an ihre Stelle setzen. Wenn Sie also eine AMI erstellen, kann das CI-Tool prüfen, ob diese AMI für einen bestimmten Zweck geeignet ist. Sie werden wissen, dass AMI produktionsbereit ist.
Anstelle einer Schlussfolgerung
Mary Poppendieck ist wahrscheinlich eine der erstaunlichsten Frauen, von denen ich je gehört habe. Einmal sprach sie darüber, wie sich die schlanke Softwareentwicklung im Laufe der Jahre entwickelt hat. Und wie sie in den 60er Jahren mit 3M in Verbindung gebracht wurde, als sich das Unternehmen wirklich mit Lean Development beschäftigte.
Und sie stellte die Frage: Wie lange dauert es, bis Ihr Unternehmen die mit einer Codezeile verbundenen Änderungen implementiert hat? Können Sie diesen Prozess zuverlässig und wiederholbar machen?
Diese Frage betraf in der Regel immer den Softwarecode. Wie lange brauche ich, um einen Fehler in dieser Anwendung bei der Bereitstellung in der Produktion zu beheben? Es gibt jedoch keinen Grund, warum wir nicht dieselbe Frage für Infrastruktur oder Datenbanken verwenden können.
Ich habe für eine Firma namens OpenTable gearbeitet. Darin nannten wir dies die Dauer des Zyklus. Und in OpenTable war sie sieben Wochen alt. Und das ist relativ gut. Ich kenne Unternehmen, die Monate brauchen, um einen Code an die Produktion zu senden. Bei OpenTable haben wir den Prozess vier Jahre lang überprüft. Dies hat viel Zeit in Anspruch genommen, da die Organisation groß ist - 200 Personen. Und wir haben die Zykluszeit auf drei Minuten reduziert. Dies war möglich dank Messungen des Effekts unserer Transformationen.
Jetzt ist alles in Skripten geschrieben. Wir haben so viele Tools und Beispiele, dass es GitHub gibt. Nehmen Sie daher Ideen von Konferenzen wie DevOops und implementieren Sie sie in Ihrem Unternehmen. Versuchen Sie nicht, alles zu implementieren. Nimm eine winzige Sache und verkaufe sie. Zeigen Sie jemanden. Die Auswirkungen einer kleinen Änderung können gemessen, gemessen und fortgesetzt werden!
Paul Stack wird auf der DevOops 2018- Konferenz in St. Petersburg mit einem Bericht „Nachhaltige Systemtests mit Chaos“ eintreffen. Paul wird über die Chaos Engineering-Methodik sprechen und zeigen, wie diese Methodik in realen Projekten angewendet werden kann.