Vor nicht allzu langer Zeit ereignete sich in dem Rechenzentrum, in dem wir Server mieten, ein weiterer kleiner Vorfall. Infolgedessen gab es keine ernsthaften Konsequenzen für unseren Service. Gemäß den verfügbaren Metriken konnten wir in buchstäblich einer Minute verstehen, was geschah. Und dann stellte ich mir vor, wie ich mir den Kopf zerbrechen müsste, wenn nur zwei einfache Metriken fehlen würden. Unter dem Schnitt eine Kurzgeschichte in Bildern.
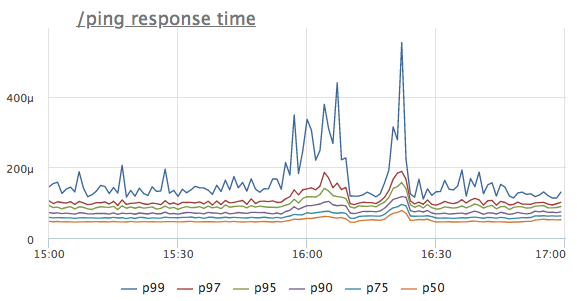
Stellen Sie sich vor, wir haben eine Anomalie in der Antwortzeitleiste eines bestimmten Dienstes festgestellt. Der Einfachheit halber verwenden wir den / ping-Handler, der weder auf die Datenbank noch auf benachbarte Dienste zugreift, sondern einfach '200 OK' zurückgibt (er wird für Load Balancer und k8s für den Health Check Service benötigt).

Was ist der erste Gedanke? Das stimmt, der Dienst verfügt nicht über genügend Ressourcen, höchstwahrscheinlich die CPU! Wir betrachten den Verbrauch des Prozessors:
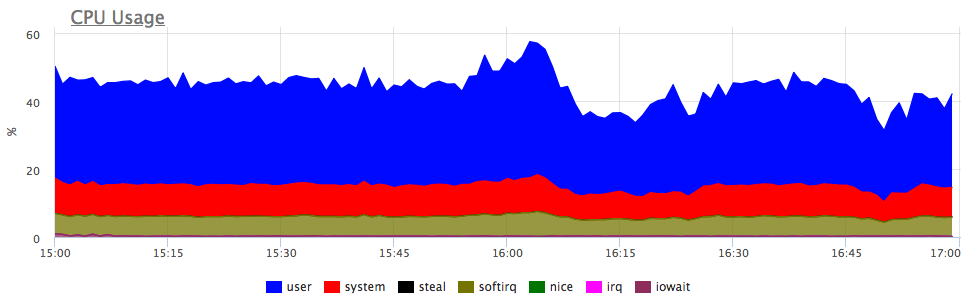
Ja, es gibt ähnliche Ausbrüche. Als nächstes betrachten wir den Verbrauch durch Dienste auf dem Server:
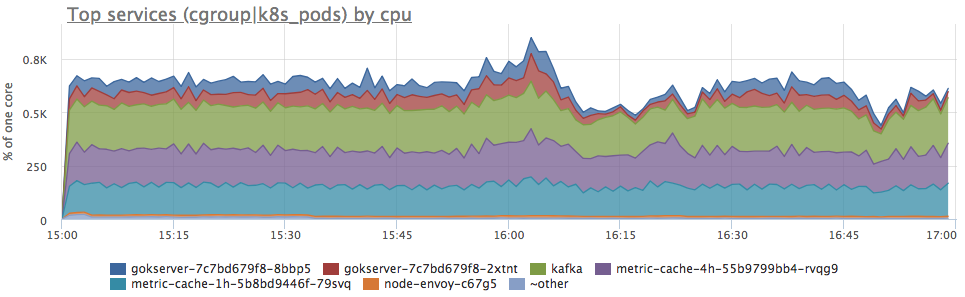
Wir sehen, dass der Verbrauch von Proca für alle Dienstleistungen proportional gestiegen ist. Sie können nichts explizit weiter sagen: Sie können nachsehen, ob sich das Lastprofil geändert hat (da alle Komponenten verbunden sind und eine Zunahme der Eingabeanforderungen tatsächlich zu einer proportionalen Zunahme des Ressourcenverbrauchs führen kann) oder nachvollziehen, was aus Serverressourcen geworden ist.
Natürlich habe ich versucht, die Intrige so gut wie möglich zu bewahren, aber am Anfang des Artikels haben Sie wahrscheinlich bereits vermutet, dass der Server einfach die Anzahl der verfügbaren CPU-Ticks reduziert hat. In dmesg sieht es ungefähr so aus:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
Grob gesagt haben wir die Frequenz aufgrund von Überhitzung des Prozessors reduziert. Wir schauen uns die Temperatur an:
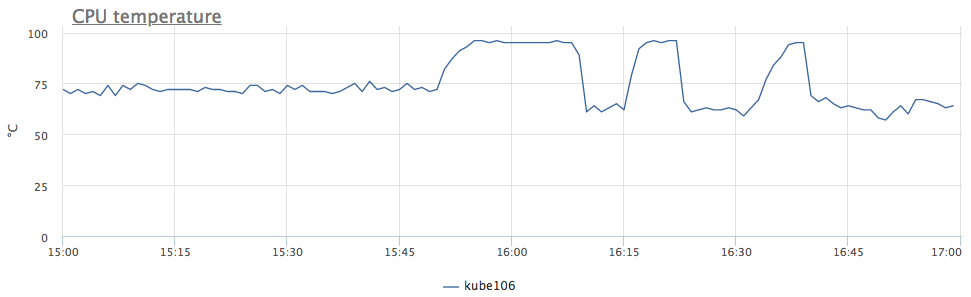
jetzt ist alles klar. Da wir auf 6 Servern sofort ein ähnliches Verhalten hatten, stellten wir fest, dass das Problem im DC liegt und nicht in allen, sondern nur in bestimmten Rackreihen.
Aber zurück zu den Metriken. Wir möchten möglicherweise wissen, ob die Server in Zukunft überhitzen werden. Dies ist jedoch kein Grund, allen Dashboards ein Diagramm der Prozessortemperaturen hinzuzufügen und dies jedes Mal zu überprüfen.
Normalerweise werden Trigger verwendet, um einige Metriken zu verfolgen und den Prozess zu optimieren. Aber welchen Schwellenwert sollte ich für einen Trigger nach Prozessortemperatur wählen?
Aufgrund der Schwierigkeit, einen guten Schwellenwert für den Auslöser zu wählen, träumen viele Ingenieure von einem Anomaliedetektor, der sich ohne Einstellungen wiederfinden wird, ich weiß nicht was :)Der erste Gedanke ist, die Schwellentemperatur festzulegen, bei der unser Service Probleme zu bekommen begann. Und wenn Sie noch nie überhitzt waren? Natürlich können Sie sich meinen Zeitplan ansehen und selbst entscheiden, dass 95 ° C das sind, was Sie brauchen, aber lassen Sie uns etwas mehr darüber nachdenken.
Das Problem bei uns liegt nicht an den Graden, sondern daran, dass die Frequenz abgenommen hat! Lassen Sie uns die Anzahl solcher Ereignisse verfolgen.
Unter Linux kann dies aus sysfs entfernt werden:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

Um ehrlich zu sein, wird diese Metrik nirgendwo angezeigt. Wir haben nur einen automatischen Auslöser für alle Clients, die ausgelöst werden, wenn der Schwellenwert "> 10 Ereignisse / Sekunde" erreicht ist. Nach unseren Statistiken gibt es bei dieser Schwelle praktisch keine Fehlalarme.
Ja, dieser Auslöser funktioniert selten, aber wenn dies passiert, macht es das Leben sehr einfach!
Wir bei okmeter.io beschäftigen uns die meiste Zeit mit der Entwicklung unserer Datenbank mit automatischen Auslösern, die es unseren Kunden erleichtern, ihnen unbekannte Probleme zu finden.