Hallo allerseits!
Heute werden wir über die Erfahrungen eines unserer DevOps-Projekte sprechen. Wir haben uns entschlossen, eine neue Anwendung für Linux mit .Net Core auf einer Microservice-Architektur zu implementieren.
Wir erwarten, dass sich das Projekt aktiv weiterentwickelt und es immer mehr Benutzer geben wird. Daher sollte es sowohl hinsichtlich der Funktionalität als auch der Leistung leicht skalierbar sein.
Wir brauchen ein fehlertolerantes System - wenn einer der Funktionsblöcke nicht funktioniert, sollte der Rest funktionieren. Wir möchten auch eine kontinuierliche Integration sicherstellen, einschließlich der Bereitstellung der Lösung auf den Servern des Kunden.
Daher haben wir folgende Technologien verwendet:
- .Net Core für die Implementierung von Microservices. Unser Projekt verwendete Version 2.0,
- Kubernetes für die Orchestrierung von Microservices,
- Docker zum Erstellen von Microservice-Bildern,
- Integrationsbus Rabbit MQ und Mass Transit,
- Elasticsearch und Kibana für die Protokollierung,
- TFS zur Implementierung der CI / CD-Pipeline.
In diesem Artikel werden die Details unserer Lösung erläutert.

Dies ist eine Abschrift unserer Rede auf dem .NET-Meeting. Hier ist ein
Link zum Video der Rede.
Unsere geschäftliche Herausforderung
Unser Kunde ist ein Bundesunternehmen, in dem es Merchandiser gibt - das sind Leute, die dafür verantwortlich sind, wie Waren in Geschäften präsentiert werden. Und es gibt Vorgesetzte - das sind die Führer der Merchandiser.
Das Unternehmen hat einen Prozess der Schulung und Bewertung der Arbeit von Merchandisern durch Vorgesetzte, der automatisiert werden musste.
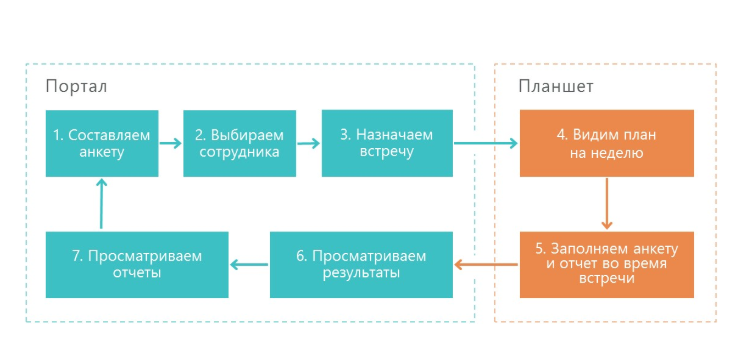
So funktioniert unsere Lösung:
1. Der Supervisor erstellt einen Fragebogen - dies ist eine Checkliste dessen, was Sie in der Arbeit des Merchandisers überprüfen müssen.
2. Als nächstes wählt der Vorgesetzte den Mitarbeiter aus, dessen Arbeit überprüft wird. Das Fragedatum ist zugewiesen.
3. Als nächstes wird die Aktivität an das mobile Gerät des Supervisors gesendet.
4. Anschließend wird der Fragebogen ausgefüllt und an das Portal gesendet.
5. Das Portal generiert Ergebnisse und verschiedene Berichte.
Microservices helfen uns bei der Lösung von drei Problemen:
1. In Zukunft möchten wir die Funktionalität einfach erweitern, da es im Unternehmen viele ähnliche Geschäftsprozesse gibt.
2. Wir möchten, dass die Lösung fehlertolerant ist. Wenn ein Teil nicht mehr funktioniert, kann die Lösung ihre Arbeit selbst wiederherstellen, und ein Ausfall eines Teils hat keinen großen Einfluss auf den Betrieb der gesamten Lösung.
3. Das Unternehmen, für das wir die Lösung implementieren, hat viele Niederlassungen. Dementsprechend wächst die Anzahl der Benutzer der Lösung ständig. Daher wollte ich, dass dies die Leistung nicht beeinträchtigt.
Aus diesem Grund haben wir uns für die Verwendung von Microservices für dieses Projekt entschieden, was eine Reihe nicht trivialer Entscheidungen erforderte.
Welche Technologien haben zur Implementierung dieser Lösung beigetragen:
• Docker vereinfacht die Verteilung der Lösungsverteilung. Die Verteilung in unserem Fall besteht aus einer Reihe von Microservice-Bildern
• Da unsere Lösung viele Microservices enthält, müssen wir diese verwalten. Dafür verwenden wir Kubernetes.
• Wir implementieren Microservices mit .Net Core.
• Um die Lösung beim Kunden schnell zu aktualisieren, müssen wir eine bequeme kontinuierliche Integration und Lieferung implementieren.
Hier ist unser gesamter Satz von Technologien:
• .Net Core, mit dem wir Microservices erstellen,
• Microservice ist in einem Docker-Image verpackt.
• Kontinuierliche Integration und kontinuierliche Bereitstellung wird mithilfe von TFS implementiert.
• Das Frontend ist in Angular implementiert.
• Zur Überwachung und Protokollierung verwenden wir Elasticsearch und Kibana.
• RabbitMQ und MassTransit werden als Integrationsbus verwendet.
.NET Core für Linux-Lösungen
Wir alle wissen, was das klassische .Net Framework ist. Der Hauptnachteil der Plattform besteht darin, dass sie nicht plattformübergreifend ist. Dementsprechend können wir in Docker keine Lösungen auf dem .NET Framework für Linux ausführen.
Um die Verwendung von C # in Docker zu ermöglichen, hat Microsoft das .Net Framework überarbeitet und .Net Core erstellt. Um dieselben Bibliotheken zu verwenden, hat Microsoft die .Net Standard Library-Spezifikation erstellt. .Net Standart Library-Assemblys können sowohl im .Net Framework als auch im .Net Core verwendet werden.
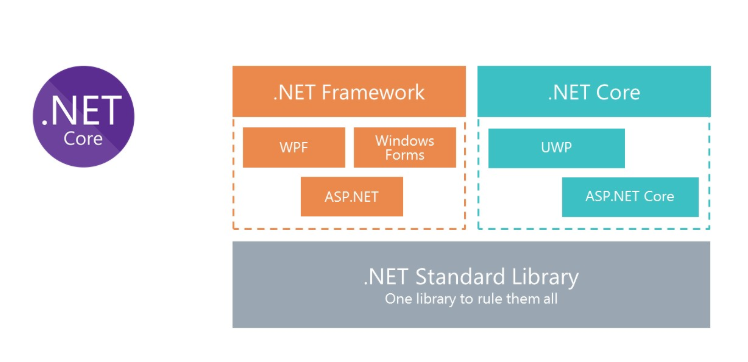
Kubernetes - für die Orchestrierung von Microservices
Kubernetes wird zum Verwalten und Clustering von Docker-Containern verwendet. Hier sind die Hauptvorteile von Kubernetes, die wir genutzt haben:
- bietet die Möglichkeit, die Umgebung von Microservices einfach zu konfigurieren,
- vereinfacht das Umweltmanagement (Dev, QA, Stage),
- Out of the Box bietet die Möglichkeit, Microservices und den Lastausgleich auf Replikaten zu replizieren.
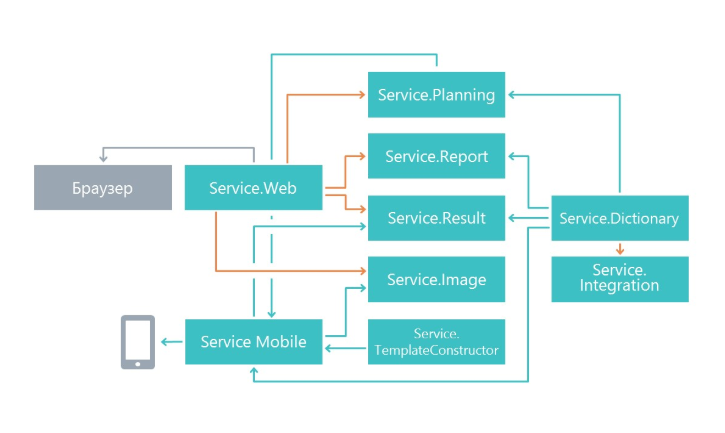
Lösungsarchitektur
Zu Beginn der Arbeit haben wir uns gefragt, wie die Funktionalität in Microservices unterteilt werden kann. Die Aufteilung erfolgte nach dem Prinzip einer einzigen Verantwortung, nur auf einer größeren Ebene. Die Hauptaufgabe besteht darin, Änderungen an einem Dienst so wenig wie möglich auf andere Mikrodienste auszuwirken. In unserem Fall begannen Microservices daher, einen separaten Funktionsbereich zu erfüllen.
Infolgedessen sind Dienste erschienen, die sich mit der Planung von Fragebögen, einem Mikrodienst zum Anzeigen von Ergebnissen, einem Mikrodienst zum Arbeiten mit einer mobilen Anwendung und anderen Mikrodiensten befassen.
Optionen für die Interaktion mit externen Kunden
Microsoft in seinem Buch über Microservices „
.NET Microservices. .NET Container Application Architecture “bietet drei mögliche Implementierungen für die Interaktion mit Microservices. Wir haben alle drei überprüft und die am besten geeignete ausgewählt.
• API-Gateway-Dienst
Die Gateway-Service-API ist eine Fassadenimplementierung für Benutzeranforderungen für andere Services. Das Problem mit der Lösung ist, dass, wenn die Fassade nicht funktioniert, die gesamte Lösung nicht mehr funktioniert. Sie beschlossen, diesen Ansatz aus Gründen der Fehlertoleranz aufzugeben.
• API-Gateway mit Azure API-Verwaltung
Microsoft bietet die Möglichkeit, eine Cloud-Fassade in Azure zu verwenden. Diese Lösung passte jedoch nicht, da wir die Lösung nicht in der Cloud, sondern auf den Servern des Kunden bereitstellen wollten.
• Direkte Client-zu-Microservice-Kommunikation
Als Ergebnis haben wir die letzte Option - direkte Benutzerinteraktion mit Microservices. Wir haben ihn gewählt.
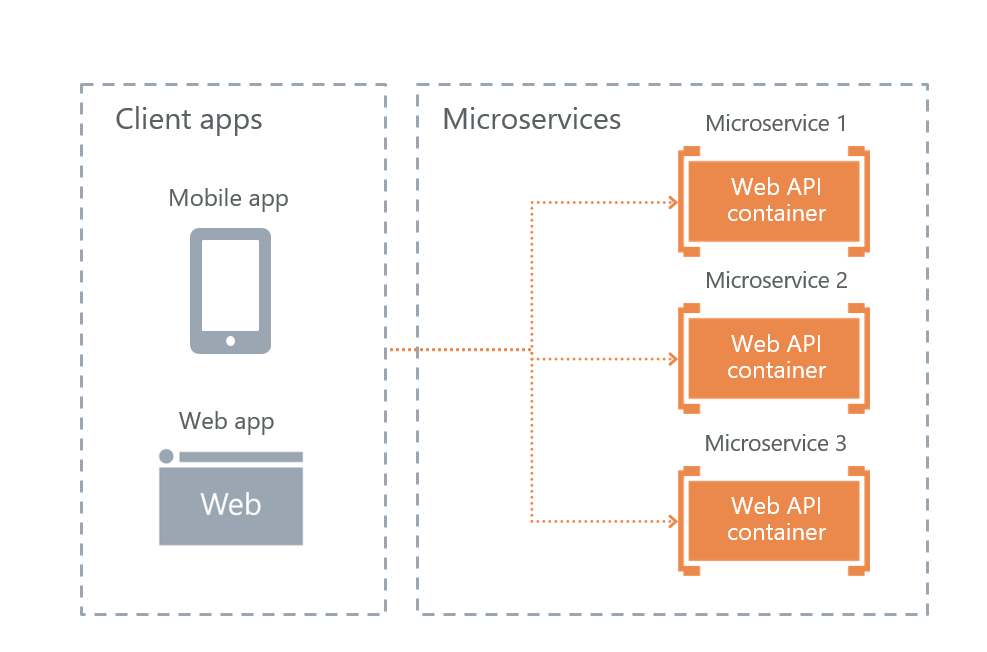
Sein Plus in der Fehlertoleranz. Der Nachteil ist, dass ein Teil der Funktionalität für jeden Dienst separat reproduziert werden muss. Beispielsweise musste die Autorisierung für jeden Mikrodienst, auf den Benutzer Zugriff haben, separat konfiguriert werden.
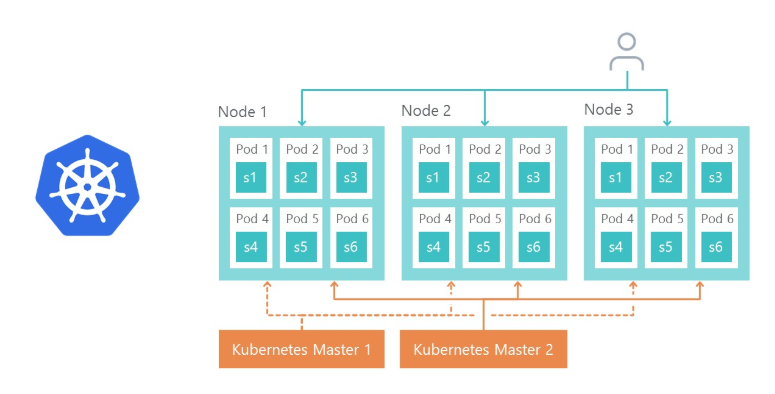
Natürlich stellt sich die Frage, wie wir die Last ausgleichen und wie die Fehlertoleranz umgesetzt wird. Hier ist alles einfach - Ingress Controller Kubernetes macht das.

Knoten 1, Knoten 2 und Knoten 3 sind Replikate desselben Mikrodienstes. Wenn eines der Replikate ausfällt, leitet der Load Balancer die Last automatisch an andere Microservices weiter.
Physische Architektur
So haben wir unsere Lösungsinfrastruktur organisiert:
• Jeder Mikrodienst verfügt über eine eigene Datenbank (wenn er diese natürlich benötigt), andere Dienste greifen nicht auf die Datenbank eines anderen Mikrodienstes zu.
• Microservices kommunizieren nur über den RabbitMQ + Mass Transit-Bus sowie über HTTP-Anforderungen miteinander.
• Jeder Dienst hat seine eigene klar definierte Verantwortung.
• Für die Protokollierung verwenden wir Elasticsearch und Kibana sowie die Bibliothek für die Arbeit mit
Serilog .
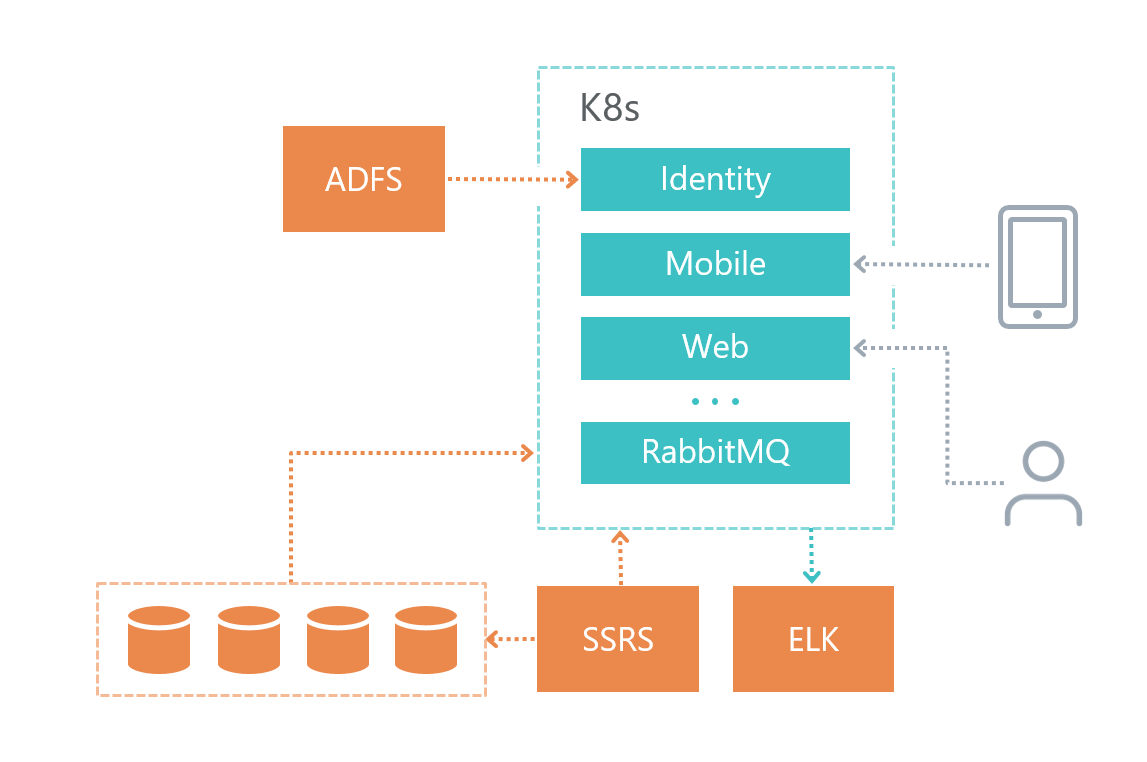
Der Datenbankdienst wurde auf einer separaten virtuellen Maschine und nicht in Kubernetes bereitgestellt, da Microsoft DBMS die Verwendung von Docker in Produktumgebungen nicht empfiehlt.
Der Protokollierungsdienst wurde aus Gründen der Fehlertoleranz auch auf einer separaten virtuellen Maschine bereitgestellt. Wenn wir Probleme mit Kubernetes haben, können wir herausfinden, wo das Problem liegt.
Bereitstellung: Wie wir Entwicklungs- und Produktumgebungen organisiert haben
Unsere Infrastruktur verfügt über 3 Namespaces in Kubernetes. Alle drei Umgebungen greifen auf einen Datenbankdienst und einen Protokollierungsdienst zu. Und natürlich betrachtet jede Umgebung ihre eigene Datenbank.
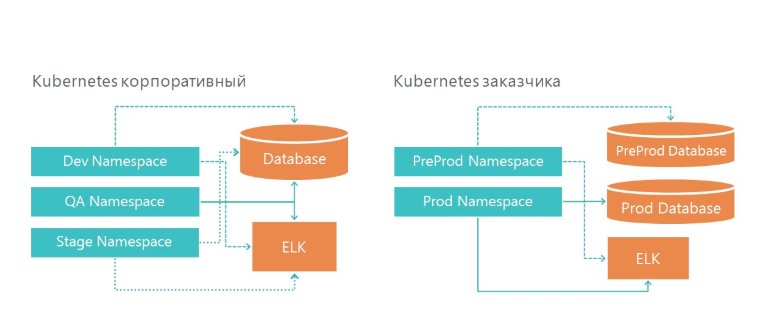
In der Infrastruktur des Kunden haben wir auch zwei Umgebungen - Vorproduktion und Produktion. In der Produktion verfügen wir über separate Datenbankserver für den Vorverkauf und die Produktumgebung. Für die Protokollierung haben wir einen ELK-Server in unserer Infrastruktur und in der Infrastruktur des Kunden zugewiesen.
Wie kann ich 5 Umgebungen mit jeweils 10 Microservices bereitstellen?
Im Durchschnitt haben wir 10 Services pro Projekt und drei Umgebungen: QA, DEV, Stage, auf denen insgesamt etwa 30 Microservices bereitgestellt werden. Und das nur auf der Entwicklungsinfrastruktur! Fügen Sie der Infrastruktur des Kunden zwei weitere Umgebungen hinzu, und wir erhalten 50 Microservices.
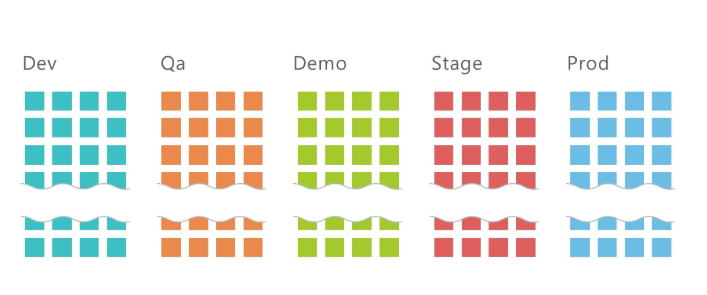
Es ist klar, dass eine solche Anzahl von Diensten irgendwie verwaltet werden muss. Kubernetes hilft uns dabei.
Um einen Microservice bereitzustellen, müssen Sie
• Geheimnis erweitern,
• Bereitstellung bereitstellen,
• Erweitern Sie den Service.
Über das Geheimnis schreiben Sie unten.
Die Bereitstellung ist eine Anweisung für Kubernetes, auf deren Grundlage der Docker-Container unseres Microservices gestartet wird. Hier ist der Befehl, für den die Bereitstellung bereitgestellt wird:
kubectl apply -f .\(yaml deployment-) --namespace=DEV apiVersion: apps/v1beta1 kind: Deployment metadata: name: imtob-etr-it-dictionary-api spec: replicas: 1 template: metadata: labels: name: imtob-etr-it-dictionary-api spec: containers: - name: imtob-etr-it-dictionary-api image: nexus3.company.ru:18085/etr-it-dictionary-api:18289 resources: requests: memory: "256Mi" limits: memory: "512Mi" volumeMounts: - name: secrets mountPath: /app/secrets readOnly: true volumes: - name: secrets secret: secretName: secret-appsettings-dictionary
Diese Datei beschreibt, wie die Bereitstellung heißt (imtob-etr-it-dictionary-api), welches Image für die Ausführung verwendet werden muss und andere Einstellungen. Im geheimen Bereich werden wir unsere Umgebung anpassen.
Nach der Bereitstellung der Bereitstellung müssen wir den Dienst bei Bedarf bereitstellen.
Services werden benötigt, wenn der Zugriff auf den Microservice von außen erforderlich ist. Zum Beispiel, wenn Sie möchten, dass ein Benutzer oder ein anderer Microservice eine Get-Anfrage an einen anderen Microservice senden kann.
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV apiVersion: v1 kind: Service metadata: name: imtob-etr-it-dictionary-api-services spec: ports: - name: http port: 80 targetPort: 80 protocol: TCP selector: name: imtob-etr-it-dictionary-api
Normalerweise ist die Beschreibung des Dienstes klein. Darin sehen wir den Namen des Dienstes, wie darauf zugegriffen werden kann und die Portnummer.
Um die Umgebung bereitzustellen, benötigen wir daher
• eine Reihe von Dateien mit Geheimnissen für alle Mikrodienste,
• eine Reihe von Dateien mit der Bereitstellung aller Microservices,
• eine Reihe von Dateien mit den Diensten aller Microservices.
Wir speichern alle diese Skripte im Git-Repository.
Für die Bereitstellung der Lösung wurden drei Arten von Skripten bereitgestellt:
• Ordner mit Geheimnissen - dies sind Konfigurationen für jede Umgebung,
• Ordner mit Bereitstellung für alle Microservices,
• Ordner mit Diensten für einige Microservices,
in jedem - ungefähr zehn Teams, eines für jeden Microservice. Der Einfachheit halber haben wir in Confluence eine Seite mit Skripten erstellt, mit deren Hilfe wir schnell eine neue Umgebung bereitstellen können.
Hier ist ein Bereitstellungsbereitstellungsskript (es gibt ähnliche Sätze für geheime und für den Dienst):
Bereitstellungsskriptkubectl apply -f. \ imtob-etr-it-image-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-mobile-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-Planning-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-result-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-web.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-report-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-template-Konstruktor-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-dictionary-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-integration-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-identity-api.yml --namespace = DEV
CI / CD-Implementierung
Jeder Dienst befindet sich in einem eigenen Ordner. Außerdem haben wir einen Ordner mit gemeinsamen Komponenten.
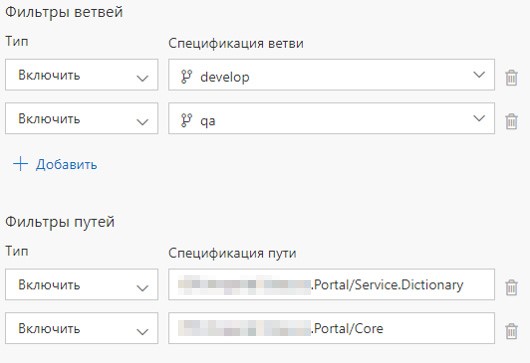
Es gibt auch eine Build-Definition und eine Release-Definition für jeden Microservice. Wir haben den Start von Build Definion konfiguriert, wenn Sie sich für den entsprechenden Dienst oder für den entsprechenden Ordner festlegen. Wenn der Inhalt des Ordners mit allgemeinen Komponenten aktualisiert wird, werden alle Microservices bereitgestellt.
Was sind die Vorteile einer solchen Build-Organisation?
1. Die Lösung befindet sich in einem Git-Repository.
2. Beim Wechsel in mehreren Mikrodiensten beginnt die Montage parallel zu freien Montagemitteln.
3. Jede Build-Definition enthält ein einfaches Skript zum Erstellen und Verschieben des Images in die Nexus-Registrierung.
Build-Definition und Release-Definition
Informationen zum Bereitstellen eines VSTS-Agenten finden Sie
in diesem Artikel .
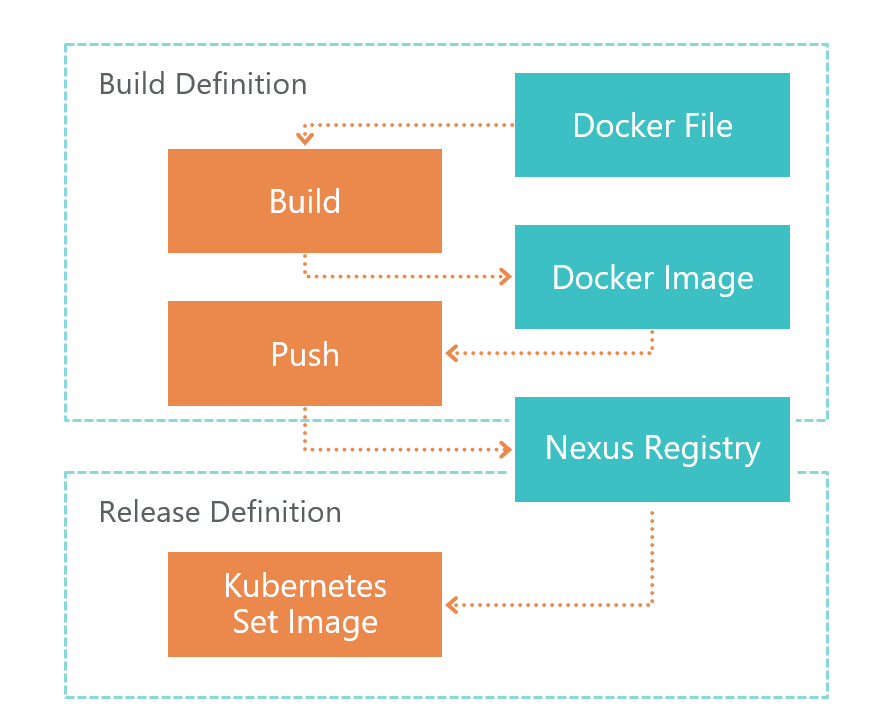
Zuerst kommt die Build-Definition. Beim Befehl TFS VSTS startet der Agent den Dockerfile-Build. Als Ergebnis erhalten wir das Bild eines Microservices. Dieses Image wird lokal in der Umgebung gespeichert, in der der VSTS-Agent ausgeführt wird.
Nach dem Build wird Push gestartet, das das im vorherigen Schritt erhaltene Image an die Nexus-Registrierung sendet. Jetzt kann es extern verwendet werden. Nexus Registry ist eine Art Nuget, nicht nur für Bibliotheken, sondern auch für Docker-Images und mehr.
Nachdem das Image von außen bereit und zugänglich ist, müssen Sie es bereitstellen. Dafür haben wir Release Definition. Hier ist alles einfach - wir führen den Befehl set image aus:
kubectl set image deployment/imtob-etr-it-dictionary-api imtob-etr-it-dictionary-api=nexus3.company.ru:18085/etr-it-dictionary-api:$(Build.BuildId)Danach aktualisiert er das Image für den gewünschten Microservice und startet einen neuen Container. Infolgedessen wurde unser Service aktualisiert.
Vergleichen wir nun den Build mit und ohne Dockerfile.
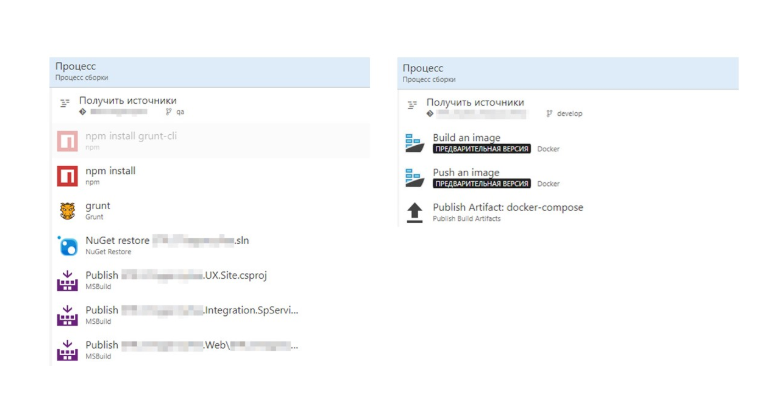
Ohne die Docker-Datei erhalten wir viele Schritte, die viele .Net-Besonderheiten enthalten. Rechts sehen wir ein Docker-Image. Alles ist viel einfacher geworden.
Der gesamte Prozess zum Erstellen des Images wird in der Docker-Datei beschrieben. Diese Assembly kann lokal debuggt werden.

Insgesamt: Wir haben eine einfache und transparente CI / CD erhalten
1. Trennung von Entwicklung und Bereitstellung. Die Baugruppe wird in Dockerfile beschrieben und liegt auf den Schultern des Entwicklers.
2. Bei der Konfiguration von CI / CD müssen Sie die Details und Funktionen der Assembly nicht kennen. Die Arbeit wird nur mit der Docker-Datei ausgeführt.
3. Wir aktualisieren nur die geänderten Microservices.
Als nächstes müssen Sie RabbitMQ im K8S konfigurieren: Wir haben einen
separaten Artikel darüber geschrieben.
Umgebungseinstellung
Auf die eine oder andere Weise müssen wir Microservices konfigurieren. Der Hauptteil der Umgebung wird in der Stammkonfigurationsdatei Appsettings.json konfiguriert. Diese Datei enthält Einstellungen, die von der Umgebung unabhängig sind.
Die Einstellungen, die von der Umgebung abhängen, werden im Ordner "Geheimnisse" in der Datei "appsettings.secret.json" gespeichert. Wir haben den im Artikel
Verwalten der ASP.NET Core App-Einstellungen auf Kubernetes beschriebenen Ansatz gewählt.
var configuration = new ConfigurationBuilder() .AddJsonFile($"appsettings.json", true) .AddJsonFile("secrets/appsettings.secrets.json", optional: true) .Build();
Die Datei appsettings.secrets.json enthält die Einstellungen für die Elastic Search-Indizes und die Datenbankverbindungszeichenfolge.
{ "Serilog": { "WriteTo": [ { "Name": "Elasticsearch", "Args": { "nodeUris": "http://192.168.150.114:9200", "indexFormat": "dev.etr.it.ifield.api.dictionary-{0:yyyy.MM.dd}", "templateName": "dev.etr.it.ifield.api.dictionary", "typeName": "dev.etr.it.ifield.api.dictionary.event" } } ] }, "ConnectionStrings": { "DictionaryDbContext": "Server=192.168.154.162;Database=DEV.ETR.IT.iField.Dictionary;User Id=it_user;Password=PASSWORD;" } }
Konfigurationsdatei zu Kubernetes hinzufügen
Um diese Datei hinzuzufügen, müssen Sie sie im Docker-Container bereitstellen. Dies erfolgt in der Kubernetis-Bereitstellungsdatei. In der Bereitstellung wird beschrieben, in welchem Ordner die c-Geheimdatei erstellt werden soll und mit welchem Geheimnis die Datei verknüpft werden muss.
apiVersion: apps/v1beta1 kind: Deployment metadata: name: imtob-etr-it-dictionary-api spec: replicas: 1 template: metadata: labels: name: imtob-etr-it-dictionary-api spec: containers: - name: imtob-etr-it-dictionary-api image: nexus3.company.ru:18085/etr-it-dictionary-api:18289 resources: requests: memory: "256Mi" limits: memory: "512Mi" volumeMounts: - name: secrets mountPath: /app/secrets readOnly: true volumes: - name: secrets secret: secretName: secret-appsettings-dictionary
Sie können ein Geheimnis in Kubernetes mit dem Dienstprogramm kubectl erstellen. Wir sehen hier den Namen des Geheimnisses und den Pfad zur Datei. Wir geben auch den Namen der Umgebung an, für die wir ein Geheimnis erstellen.
kubectl create secret generic secret-appsettings-dictionary
--from-file=./Dictionary/appsettings.secrets.json --namespace=DEMOSchlussfolgerungen
Nachteile des gewählten Ansatzes
1. Hohe Eintrittsschwelle. Wenn Sie ein solches Projekt zum ersten Mal durchführen, gibt es viele neue Informationen.
2. Microservices → komplexeres Design. Es ist notwendig, viele nicht offensichtliche Lösungen anzuwenden, da wir keine monolithische, sondern eine Mikroservice-Lösung haben.
3. Nicht alles ist für Docker implementiert. Nicht alles kann in einer Microservice-Architektur ausgeführt werden. Zum Beispiel, während SSRS nicht im Docker ist.
Vorteile eines selbst getesteten Ansatzes
1. Infrastruktur als Code
Die Infrastrukturbeschreibung wird in der Quellcodeverwaltung gespeichert. Zum Zeitpunkt der Bereitstellung müssen Sie die Umgebung nicht anpassen.
2. Skalierung sowohl auf der Ebene der Funktionalität als auch auf der Ebene der sofort einsatzbereiten Leistung.
3. Microservices sind gut isoliert
Es gibt praktisch keine kritischen Teile, deren Ausfall zur Inoperabilität des gesamten Systems führt.
4. Schnelle Lieferung von Änderungen
Es werden nur die Microservices aktualisiert, bei denen Aktualisierungen vorgenommen wurden. Wenn Sie die Zeit für die Koordination und andere Dinge, die mit dem menschlichen Faktor zusammenhängen, nicht berücksichtigen, erfolgt die Aktualisierung eines Mikrodienstes in maximal 2 Minuten.
Schlussfolgerungen für uns
1. In .NET Core können und sollten Sie industrielle Lösungen implementieren.
2. K8S hat das Leben wirklich erleichtert, die Aktualisierung von Umgebungen vereinfacht und die Konfiguration von Diensten erleichtert.
3. Mit TFS kann CI / CD für Linux implementiert werden.