Hallo Kollegen.
Wir hoffen, noch vor Ende August mit der Übersetzung eines kleinen, aber wirklich
grundlegenden Buches über die Implementierung von KI-Funktionen in Python beginnen zu können.

Mr. Gift benötigt möglicherweise keine zusätzliche Werbung (für Neugierige - das
Profil des Masters auf GitHub):

Der Artikel, der heute angeboten wird, wird kurz über die Ray-Bibliothek sprechen, die an der University of California (Berkeley) entwickelt und in Peters Buch von petite erwähnt wurde. Wir hoffen, dass als frühen Teaser - was Sie brauchen. Willkommen unter Katze
Mit der Entwicklung von Algorithmen und Techniken für maschinelles Lernen müssen immer mehr Anwendungen für maschinelles Lernen auf vielen Maschinen gleichzeitig ausgeführt werden, und sie können nicht ohne Parallelität auskommen. Die Infrastruktur für das maschinelle Lernen in Clustern ist jedoch immer noch situativ aufgebaut. Jetzt gibt es bereits gute Lösungen (z. B. Parameterserver oder Suche nach Hyperparametern) und hochwertige verteilte Systeme (z. B. Spark oder Hadoop), die ursprünglich nicht für die Arbeit mit KI entwickelt wurden. Praktiker erstellen jedoch häufig die Infrastruktur für ihre eigenen verteilten Systeme von Grund auf neu. Hierfür wird viel zusätzlicher Aufwand betrieben.
Betrachten Sie als Beispiel einen konzeptionell einfachen Algorithmus, beispielsweise
evolutionäre Strategien zur Stärkung des Lernens . Auf dem Pseudocode passt dieser Algorithmus in ungefähr ein Dutzend Zeilen, und seine Implementierung in Python ist etwas größer. Die effektive Verwendung dieses Algorithmus auf einer größeren Maschine oder einem größeren Cluster erfordert jedoch ein wesentlich komplexeres Software-Engineering. Bei der Implementierung dieses Algorithmus durch die Autoren dieses Artikels gibt es Tausende von Codezeilen. Hier müssen Kommunikationsprotokolle, Strategien zur Nachrichtenserialisierung und -deserialisierung sowie verschiedene Methoden zur Datenverarbeitung festgelegt werden.
Eines der Ziele von
Ray ist es, einem Praktiker dabei zu helfen, einen Prototyp-Algorithmus, der auf einem Laptop ausgeführt wird, in eine verteilte Hochleistungsanwendung umzuwandeln, die auf einem Cluster (oder auf einem einzelnen Multi-Core-Computer) effizient funktioniert, indem relativ wenige Codezeilen hinzugefügt werden. In Bezug auf die Leistung sollte ein solches Framework alle Vorteile eines manuell optimierten Systems aufweisen und nicht erfordern, dass der Benutzer über Planung, Datenübertragung und Maschinenabstürze nachdenkt.
Kostenloses AI FrameworkVerknüpfung mit anderen Deep-Learning-Frameworks : Ray ist vollständig kompatibel mit Deep-Learning-Frameworks wie TensorFlow, PyTorch und MXNet. Daher ist es in vielen Anwendungen völlig selbstverständlich, ein oder mehrere andere Deep-Learning-Frameworks mit Ray zu verwenden (z. B. in unseren verstärkten Lernbibliotheken aktiv) TensorFlow und PyTorch anwenden).
Kommunikation mit anderen verteilten Systemen : Heutzutage werden viele gängige verteilte Systeme verwendet. Die meisten von ihnen wurden jedoch ohne Berücksichtigung der mit KI verbundenen Aufgaben entwickelt. Daher verfügen sie nicht über die erforderliche Leistung zur Unterstützung von KI und über keine API zum Ausdrücken der angewandten Aspekte von KI. In modernen verteilten Systemen gibt es keine (je nach System erforderlichen) Funktionen:
- Aufgabenunterstützung auf Millisekundenebene und Unterstützung für Millionen von Aufgaben pro Sekunde
- Verschachtelte Parallelität (Parallelisierung von Aufgaben innerhalb von Aufgaben, z. B. parallele Simulationen bei der Suche nach Hyperparametern) (siehe folgende Abbildung)
- Beliebige Abhängigkeiten zwischen Aufgaben, dynamisch während der Ausführung (z. B. um nicht warten zu müssen und sich an das Tempo langsamer Mitarbeiter anzupassen)
- Aufgaben, die mit einem gemeinsam genutzten variablen Zustand arbeiten (z. B. Gewichte in neuronalen Netzen oder einem Simulator)
- Unterstützung für heterogene Ressourcen (CPU, GPU usw.)
 Ein einfaches Beispiel für verschachtelte Parallelität. In unserer Anwendung werden zwei Experimente parallel durchgeführt (jedes ist eine langfristige Aufgabe), und in jedem Experiment werden mehrere parallele Prozesse simuliert (jeder Prozess ist auch eine Aufgabe).
Ein einfaches Beispiel für verschachtelte Parallelität. In unserer Anwendung werden zwei Experimente parallel durchgeführt (jedes ist eine langfristige Aufgabe), und in jedem Experiment werden mehrere parallele Prozesse simuliert (jeder Prozess ist auch eine Aufgabe).Es gibt zwei Möglichkeiten, Ray zu verwenden: über seine Low-Level-APIs und über High-Level-Bibliotheken. High-Level-Bibliotheken basieren auf Low-Level-APIs. Dazu gehören derzeit
Ray RLlib (eine skalierbare Bibliothek für das verstärkte Lernen) und
Ray.tune , eine effiziente Bibliothek für die verteilte Suche nach Hyperparametern.
Ray Low Level APIsDer Zweck der Ray-API besteht darin, einen natürlichen Ausdruck der gängigsten Rechenmuster und -anwendungen bereitzustellen, ohne auf feste Muster wie MapReduce beschränkt zu sein.
Dynamische AufgabendiagrammeDas Grundelement in der Anwendung (Aufgabe) Ray ist ein dynamischer Aufgabendiagramm. Es unterscheidet sich stark vom Rechengraphen in TensorFlow. Während in TensorFlow ein Rechengraph ein neuronales Netzwerk darstellt und in jeder einzelnen Anwendung viele Male ausgeführt wird, entspricht der Taskgraph in Ray der gesamten Anwendung und wird nur einmal ausgeführt. Das Aufgabendiagramm ist nicht im Voraus bekannt. Es wird dynamisch erstellt, während die Anwendung ausgeführt wird, und die Ausführung einer Aufgabe kann die Ausführung vieler anderer Aufgaben auslösen.
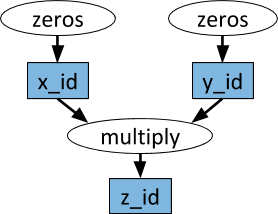 Ein Beispiel für einen Rechengraphen. In weißen Ovalen werden Aufgaben und in blauen Rechtecken Objekte angezeigt. Die Pfeile zeigen an, dass einige Aufgaben von Objekten abhängen, während andere Objekte erstellen.
Ein Beispiel für einen Rechengraphen. In weißen Ovalen werden Aufgaben und in blauen Rechtecken Objekte angezeigt. Die Pfeile zeigen an, dass einige Aufgaben von Objekten abhängen, während andere Objekte erstellen.Beliebige Python-Funktionen können als Aufgaben ausgeführt werden und hängen in beliebiger Reihenfolge von der Ausgabe anderer Aufgaben ab. Siehe das folgende Beispiel.
SchauspielerMit Hilfe von Remote-Funktionen allein und der oben beschriebenen Bearbeitung von Aufgaben ist es unmöglich zu erreichen, dass mehrere Aufgaben gleichzeitig auf demselben gemeinsamen veränderlichen Zustand arbeiten. Ein solches Problem beim maschinellen Lernen tritt in verschiedenen Kontexten auf, in denen der Zustand des Simulators, Gewichte im neuronalen Netzwerk oder etwas völlig anderes geteilt werden können. Die Akteurabstraktion wird in Ray verwendet, um einen veränderlichen Zustand zu kapseln, der von vielen Aufgaben gemeinsam genutzt wird. Hier ist ein anschauliches Beispiel, das zeigt, wie dies mit dem Atari-Simulator gemacht wird.
import gym @ray.remote class Simulator(object): def __init__(self): self.env = gym.make("Pong-v0") self.env.reset() def step(self, action): return self.env.step(action)
Bei aller Einfachheit ist der Schauspieler sehr flexibel im Gebrauch. Beispielsweise kann eine Simulator- oder neuronale Netzwerkrichtlinie in einem Akteur gekapselt sein, sie kann auch für verteiltes Training (z. B. mit einem Parameterserver) oder zum Bereitstellen von Richtlinien in einer "Live" -Anwendung verwendet werden.
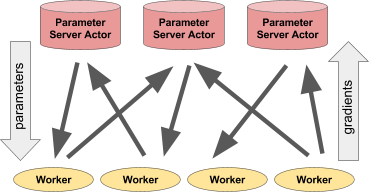 Links: Der Akteur gibt Prognosen / Aktionen für eine Reihe von Client-Prozessen ab. Rechts: Viele Akteure des Parameterservers führen verteilte Schulungen für viele Workflows durch.Beispiel für einen Parameterserver
Links: Der Akteur gibt Prognosen / Aktionen für eine Reihe von Client-Prozessen ab. Rechts: Viele Akteure des Parameterservers führen verteilte Schulungen für viele Workflows durch.Beispiel für einen ParameterserverDer Parameterserver kann wie folgt als Ray-Akteur implementiert werden:
@ray.remote class ParameterServer(object): def __init__(self, keys, values): # , . values = [value.copy() for value in values] self.parameters = dict(zip(keys, values)) def get(self, keys): return [self.parameters[key] for key in keys] def update(self, keys, values): # , # for key, value in zip(keys, values): self.parameters[key] += value
Hier ist ein
vollständigeres Beispiel .
Um einen Parameterserver zu instanziieren, führen wir dies aus.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
Um vier langjährige Mitarbeiter zu erstellen, die ständig Parameter extrahieren und aktualisieren, werden wir dies tun.
@ray.remote def worker_task(parameter_server): while True: keys = ['key1', 'key2', 'key3'] # values = ray.get(parameter_server.get.remote(keys)) # updates = … # parameter_server.update.remote(keys, updates) # 4 for _ in range(4): worker_task.remote(parameter_server)
Ray High Level BibliothekenRay RLlib ist eine skalierbare Verstärkungslernbibliothek, die für die Verwendung auf mehreren Computern entwickelt wurde. Sie kann mithilfe der als Beispiel bereitgestellten Schulungsskripte sowie über die Pytho-API aktiviert werden. Derzeit umfasst es Implementierungen von Algorithmen:
- A3C
- Dqn
- Evolutionsstrategien
- PPO
An der Implementierung anderer Algorithmen wird gearbeitet. RLlib ist voll kompatibel mit
OpenAI Gym .
Ray.tune ist eine effiziente Bibliothek für die verteilte Suche nach Hyperparametern. Es bietet eine Python-API für vertieftes Lernen, verstärktes Lernen und andere Aufgaben, die viel Rechenleistung erfordern. Hier ist ein anschauliches Beispiel dieser Art:
from ray.tune import register_trainable, grid_search, run_experiments
Aktuelle Ergebnisse können mithilfe spezieller Tools wie Tensorboard und VisKit aus rllab dynamisch visualisiert werden (oder JSON-Protokolle direkt lesen). Ray.tune unterstützt Rastersuche, Zufallssuche und nicht triviale Early-Stop-Algorithmen wie HyperBand.
Mehr zu Ray