 Projektcode ist im Repository verfügbar .
Projektcode ist im Repository verfügbar .Einführung
Wenn ich die Beschreibungen des Aussehens von Charakteren in Büchern las, war ich immer daran interessiert, wie sie im Leben aussahen. Es ist durchaus möglich, sich eine Person als Ganzes vorzustellen, aber die Beschreibung der auffälligsten Details ist eine schwierige Aufgabe, und die Ergebnisse variieren von Person zu Person. Oft konnte ich mir bis zum Ende der Arbeit nur ein sehr verschwommenes Gesicht des Charakters vorstellen. Erst wenn das Buch in einen Film verwandelt wird, füllt sich das verschwommene Gesicht mit Details. Zum Beispiel konnte ich mir nie vorstellen, wie Rachels Gesicht aus dem Buch "
Mädchen im Zug " aussieht. Aber als der Film herauskam, konnte ich Emily Blunts Gesicht mit Rachels Charakter in Einklang bringen. Sicherlich nehmen sich die an der Auswahl der Schauspieler beteiligten Personen viel Zeit, um die Charaktere im Drehbuch korrekt darzustellen.
Dieses Problem hat mich inspiriert und motiviert, eine Lösung zu finden. Danach begann ich, die Literatur über tiefes Lernen auf der Suche nach etwas Ähnlichem zu studieren. Glücklicherweise gibt es einige Studien zur Synthese von Bildern aus Text. Hier sind einige von denen, auf denen ich aufgebaut habe:
[
Projekte verwenden generative gegnerische Netze, GSS (Generative gegnerische Netze, GAN) / ca. perev. ]]
Nachdem ich die Literatur studiert hatte, entschied ich mich für eine Architektur, die im Vergleich zu StackGAN ++ vereinfacht war und mein Problem ziemlich gut bewältigt. In den folgenden Abschnitten werde ich erklären, wie ich dieses Problem gelöst habe, und vorläufige Ergebnisse teilen. Ich werde auch einige der Programmier- und Trainingsdetails beschreiben, für die ich viel Zeit aufgewendet habe.
Datenanalyse
Der wichtigste Aspekt der Arbeit sind zweifellos die Daten, die zum Trainieren des Modells verwendet werden. Wie Professor Andrew Eun in seinen Kursen zu deeplearning.ai sagte: „Auf dem Gebiet des maschinellen Lernens hat nicht derjenige den besten Algorithmus, sondern derjenige, der die besten Daten hat.“ So begann meine Suche nach einem Datensatz über Gesichter mit guten, reichhaltigen und verschiedenen Textbeschreibungen. Ich bin auf verschiedene Datensätze gestoßen - entweder waren es nur Gesichter oder Gesichter mit Namen oder Gesichter mit einer Beschreibung der Augenfarbe und der Gesichtsform. Aber es gab keine, die ich brauchte. Meine letzte Option bestand darin,
ein frühes Projekt zu verwenden - eine Beschreibung der Strukturdaten in einer natürlichen Sprache zu erstellen. Eine solche Option würde jedoch einem bereits recht verrauschten Datensatz zusätzliches Rauschen hinzufügen.
Die Zeit verging und irgendwann erschien ein neues
Face2Text- Projekt. Es war eine Sammlung einer Datenbank mit detaillierten Textbeschreibungen von Personen. Ich danke den Autoren des Projekts für den bereitgestellten Datensatz.
Der Datensatz enthielt Textbeschreibungen von 400 zufällig ausgewählten Bildern aus der LFW-Datenbank (markierte Gesichter). Beschreibungen wurden bereinigt, um mehrdeutige und geringfügige Merkmale zu beseitigen. Einige Beschreibungen enthielten nicht nur Informationen über die Gesichter, sondern auch einige Schlussfolgerungen, die auf der Grundlage der Bilder gezogen wurden - zum Beispiel „die Person auf dem Foto ist wahrscheinlich ein Verbrecher“. All diese Faktoren sowie die geringe Größe des Datensatzes haben dazu geführt, dass mein Projekt bisher nur Beweise für die Funktionsfähigkeit der Architektur liefert. Anschließend kann dieses Modell auf einen größeren und vielfältigeren Datensatz skaliert werden.
Architektur
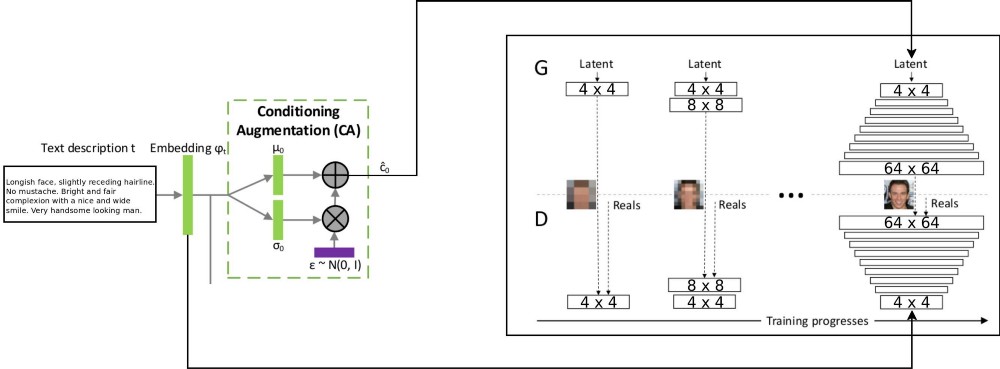
Die Architektur des T2F-Projekts kombiniert zwei StackGAN-Architekturen zum Codieren von bedingt inkrementiertem Text und ProGAN (
progressives GSS-Wachstum ) zum Synthetisieren von Gesichtsbildern. Die ursprüngliche Stackgan ++ - Architektur verwendete mehrere GSSs mit unterschiedlichen räumlichen Auflösungen, und ich entschied, dass dies ein zu schwerwiegender Ansatz für jede Korrespondenzverteilungsaufgabe war. ProGAN verwendet jedoch nur ein GSS, das schrittweise in immer detaillierteren Auflösungen geschult wird. Ich habe beschlossen, diese beiden Ansätze zu kombinieren.
Es gibt eine Erklärung für den Datenfluss durch: Textbeschreibungen werden durch Einbetten in das Netzwerk LSTM (Embedding) (psy_t) in den endgültigen Vektor codiert (siehe Abbildung). Dann wird die Einbettung durch den Conditioning Augmentation-Block (eine lineare Schicht) übertragen, um den Textteil des Eigenvektors (unter Verwendung der VAE-Reparametrisierungstechnik) für das GSS als Eingabe zu erhalten. Der zweite Teil des Eigenvektors ist zufälliges Gaußsches Rauschen. Der resultierende Eigenvektor wird dem GSS-Generator zugeführt, und die Einbettung wird der letzten Diskriminatorschicht zur bedingten Verteilung der Korrespondenz zugeführt. Das Training von GSS-Prozessen verläuft genauso wie im Artikel über ProGAN - in Schichten mit zunehmender räumlicher Auflösung. Mit der Einblendtechnik wird eine neue Ebene eingeführt, um zu vermeiden, dass frühere Lernergebnisse gelöscht werden.
Implementierung und andere Details
Die Anwendung wurde mit dem PyTorch-Framework in Python geschrieben. Früher habe ich mit Tensorflow- und Keras-Paketen gearbeitet, aber jetzt wollte ich PyTorch ausprobieren. Ich mochte es, den integrierten Python-Debugger zu verwenden, um mit der Netzwerkarchitektur zu arbeiten - alles dank der frühen Ausführungsstrategie. Tensorflow hat kürzlich auch den eifrigen Ausführungsmodus aktiviert. Ich möchte jedoch nicht beurteilen, welches Framework besser ist, sondern nur betonen, dass der Code für dieses Projekt mit PyTorch geschrieben wurde.
Nicht wenige Teile des Projekts scheinen mir wiederverwendbar zu sein, insbesondere ProGAN. Daher habe ich als
Erweiterung des PyTorch-Moduls separaten Code für sie geschrieben, der auch für andere Datensätze verwendet werden kann. Es ist nur erforderlich, die Tiefe und Größe der Merkmale des GSS anzugeben. GSS kann für jeden Datensatz schrittweise trainiert werden.
Trainingsdetails
Ich habe einige Versionen des Netzwerks mit verschiedenen Hyperparametern trainiert. Arbeitsdetails sind wie folgt:
- Der Diskriminator verfügt nicht über Batch-Norm- oder Layer-Norm-Operationen, sodass der Verlust von WGAN-GP explosionsartig zunehmen kann. Ich habe eine Driftstrafe mit einem Lambda von 0,001 verwendet.
- Um Ihre eigene Vielfalt zu steuern, die aus dem codierten Text erhalten wird, ist es erforderlich, den Kullback-Leibler-Abstand für die Verluste des Generators zu verwenden.
- Um die resultierenden Bilder besser an die Verteilung des eingehenden Textes anzupassen, ist es besser, die WGAN-Version des entsprechenden (Matching-Aware) Diskriminators zu verwenden.
- Die Einblendzeit für die oberen Ebenen sollte die Einblendzeit für die unteren Ebenen überschreiten. Ich habe 85% als Einblendwert beim Training verwendet.
- Ich fand heraus, dass Beispiele mit höherer Auflösung (32 x 32 und 64 x 64) mehr Hintergrundrauschen erzeugen als Beispiele mit niedrigerer Auflösung. Ich denke, das liegt an fehlenden Daten.
- Während eines progressiven Trainings ist es besser, mehr Zeit mit niedrigeren Auflösungen zu verbringen und die Zeit mit höheren Auflösungen zu reduzieren.
Das Video zeigt den Zeitraffer des Generators. Das Video wird aus Bildern mit unterschiedlichen räumlichen Auflösungen zusammengestellt, die während des Trainings des GSS erhalten wurden.
Fazit
Nach vorläufigen Ergebnissen kann beurteilt werden, dass das T2F-Projekt praktikabel ist und interessante Anwendungen hat. Angenommen, es kann zum Erstellen von Fotobots verwendet werden. Oder für Fälle, in denen es notwendig ist, die Vorstellungskraft zu steigern. Ich werde weiterhin daran arbeiten, dieses Projekt auf Datensätze wie Flicker8K, Coco-Untertitel usw. zu skalieren.
Progressives GSS-Wachstum ist eine phänomenale Technologie für ein schnelleres und stabileres GSS-Training. Es kann mit verschiedenen modernen Technologien kombiniert werden, die in anderen Artikeln erwähnt werden. GSS kann in verschiedenen Bereichen von MO eingesetzt werden.