
Heute bei KDD 2018 ist ein Seminartag - zusammen mit einer großen Konferenz, die morgen beginnt, versammelten mehrere Gruppen Zuhörer zu bestimmten Themen. War schon bei zwei solchen Parteien.
Zeitreihenanalyse
Am Morgen wollte ich zu einem Seminar über
Graphanalyse gehen , aber er wurde 45 Minuten lang festgehalten, also wechselte ich zum nächsten, um Zeitreihen zu analysieren. Plötzlich eröffnet ein
blonder Professor aus Kalifornien das Seminar mit dem Thema „Künstliche Intelligenz in der Medizin“. Seltsam, denn dafür gibt es im Nebenzimmer eine eigene Spur. Dann stellt sich heraus, dass sie mehrere Doktoranden hat, die hier über Zeitreihen sprechen werden. Aber eigentlich auf den Punkt.
Künstliche Intelligenz in der Medizin
Medizinische Fehler sind die Ursache für 10% der Todesfälle in den USA. Dies ist eine der drei Haupttodesursachen im Land. Das Problem ist, dass es nicht genug Ärzte gibt; diejenigen, die überlastet sind, und Computer verursachen mit größerer Wahrscheinlichkeit Probleme für Ärzte, als sie lösen können, zumindest Ärzte. Die meisten Daten werden jedoch nicht wirklich für die Entscheidungsfindung verwendet. All dies muss bekämpft werden. Beispielsweise ist ein Bakterium,
Clostridium difficile, hoch virulent und arzneimittelresistent. Im vergangenen Jahr hat sie 4 Milliarden Dollar Schaden zugefügt. Versuchen wir, das Infektionsrisiko anhand der Zeitreihen der medizinischen Unterlagen zu bewerten. Im Gegensatz zu früheren Arbeiten nehmen wir viele Zeichen (10k-Vektor für jeden Tag) und erstellen individuelle Modelle für jedes Krankenhaus (in vielerlei Hinsicht anscheinend eine notwendige Maßnahme, da alle Krankenhäuser ihren eigenen Datensatz haben). Als Ergebnis erhalten wir nach 5 Tagen eine Genauigkeit von etwa 0,82 AUC mit einer CDI-Risikoprognose.
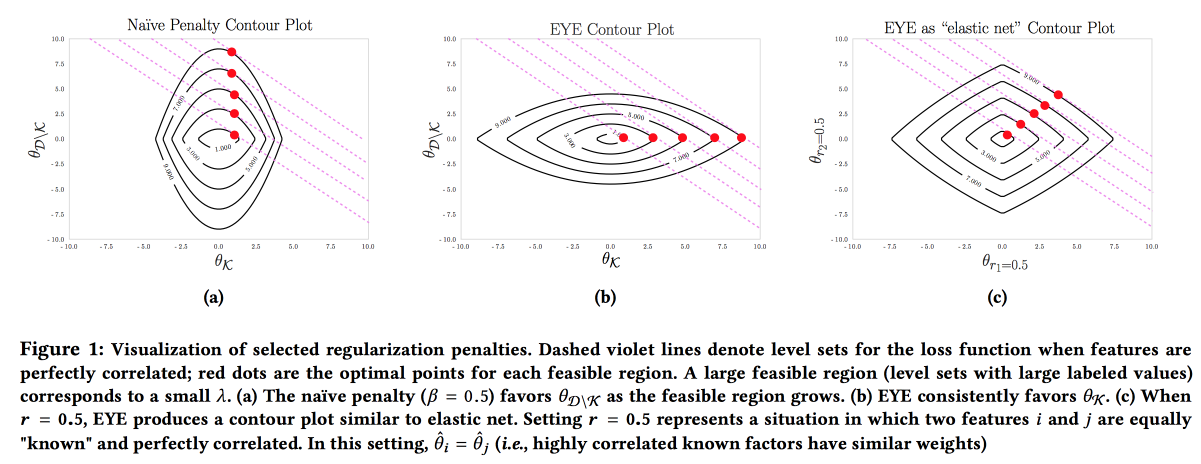
Es ist wichtig, dass das Modell genau, interpretierbar und robust ist. Wir müssen zeigen, was wir tun können, um die Krankheit zu verhindern. Ein solches Modell kann aufgebaut werden, indem Wissen aus dem Fachgebiet aktiv genutzt wird. Es ist der Wunsch nach Interpretierbarkeit, der häufig die Anzahl der Merkmale verringert und zur Erstellung einfacher Modelle führt. Aber selbst ein einfaches Modell mit einem großen Merkmalsraum verliert an Interpretierbarkeit, und die Verwendung der L1-Regularisierung führt häufig dazu, dass das Modell zufällig eines der kollinearen Merkmale auswählt. Infolgedessen glauben Ärzte dem Modell trotz einer guten AUC nicht. Die Autoren schlagen vor, eine andere Art der Regularisierung
EYE (Expert Yield Estimation) zu verwenden. Wenn bekannt ist, ob Daten über die Auswirkung auf das Ergebnis bekannt sind, konzentriert sich das Modell auf die erforderlichen Merkmale. Es liefert gute Ergebnisse, auch wenn der Experte es vermasselt hat. Durch den Vergleich der Qualität mit Standard-Regularisierungen können Sie beurteilen, wie sehr der Experte Recht hat.
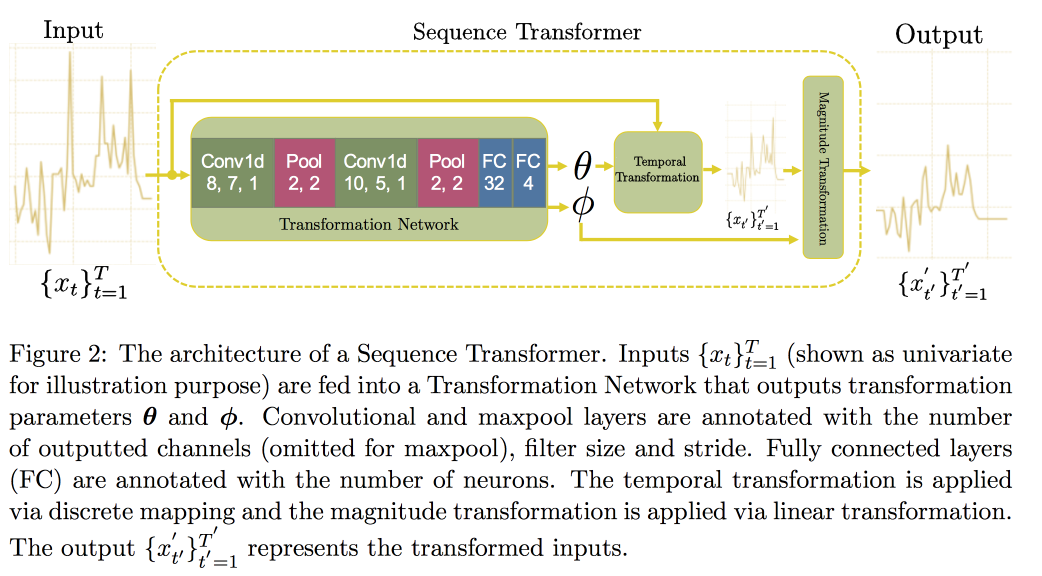
Als nächstes fahren wir mit der Analyse von Zeitreihen fort. Es stellt sich heraus, dass es wichtig ist, nach Invarianten zu suchen, um die Qualität in ihnen zu verbessern (tatsächlich - führen Sie zu einer kanonischen Form). In einem
kürzlich erschienenen Artikel schlug eine Gruppe von Professoren einen Ansatz vor, der auf zwei Faltungsnetzwerken basiert. Der erste, Sequence Transformer, bringt die Serie in eine kanonische Form, und der zweite, Sequence Decoder, löst das Klassifizierungsproblem.
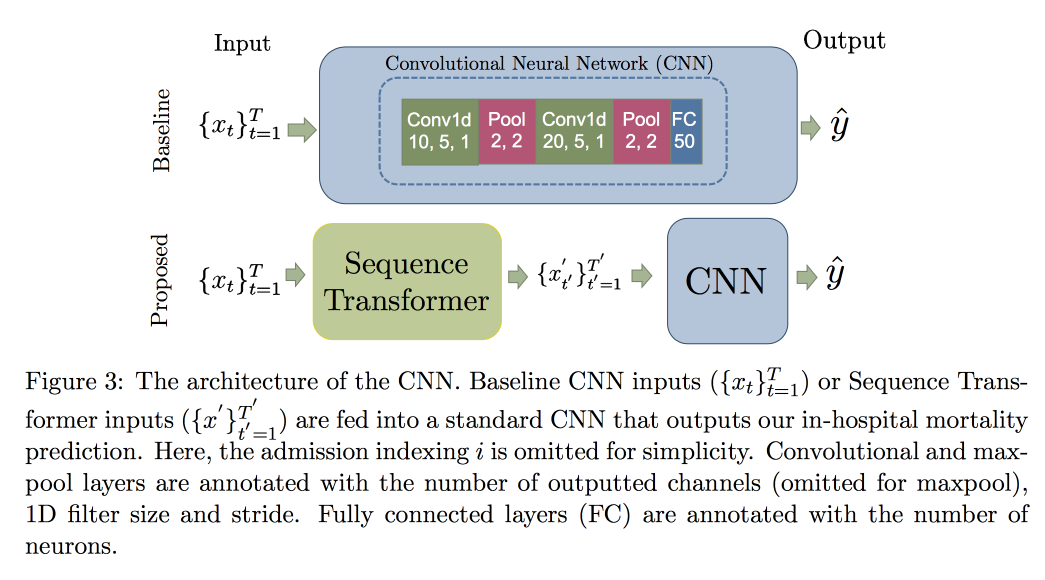
Die Verwendung von CNN anstelle von RNN wird durch die Tatsache erklärt, dass sie mit Zeilen fester Länge arbeiten. Der MIMIC-
Datensatz wurde überprüft und versucht, den Tod im Krankenhaus innerhalb von 48 Stunden vorherzusagen. Das Ergebnis war eine Verbesserung von 0,02 AUC im Vergleich zu normalem CNN mit zusätzlichen Schichten, aber die Konfidenzintervalle überlappen sich.
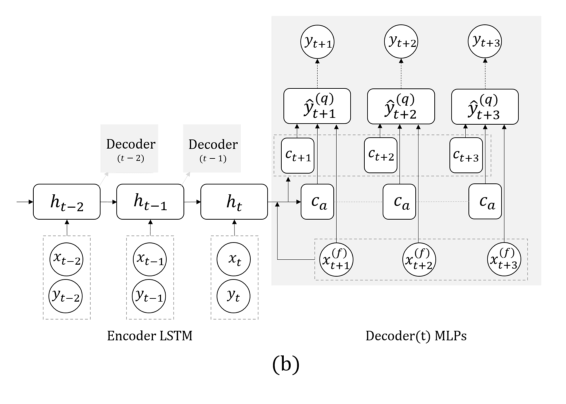
Nun noch eine Aufgabe: Wir werden nur auf der Grundlage der tatsächlichen Reihen prognostizieren, ohne externe Signale (die gegessen haben usw.). Hier schlug das Team vor, die RNN zu ersetzen, um einige Schritte voraus durch ein Raster mit mehreren Ausgaben ohne Rekursion zwischen ihnen vorherzusagen. Die Erklärung für diese Lösung ist, dass sich während der Rekursion kein Fehler ansammelt. Kombinieren Sie diese Technik mit der vorherigen (Suche nach Invarianten). Unmittelbar nach der Präsentation des Professors sprach der Postdoc ausführlich über dieses Modell. Abschließend stellen wir fest, dass es bei der Validierung wichtig ist, nicht nur den allgemeinen Fehler, sondern auch die Fehlerklassifizierung gefährlicher Fälle von zu hohem oder zu niedrigem Glukosegehalt zu betrachten.
Ich warf eine Frage zum Feedback des Modells auf: Obwohl dies eine sehr offene Frage ist, sollten wir versuchen zu verstehen, welche Veränderungen in der Verteilung der Symptome infolge der Tatsache der Intervention auftreten und welche natürlichen Verschiebungen durch externe Faktoren verursacht werden. Tatsächlich erschwert das Vorhandensein solcher Verschiebungen die Situation erheblich: Es ist unmöglich, das Modell neu zu trainieren, da sich die Qualität verschlechtert. Eine zufällige Vermischung (keine Behandlung von jemandem und Überprüfung, ob es sterben wird) ist nicht ethisch, aber aus den Daten zu lernen, bei denen jeder gemäß der Empfehlung des Modells behandelt wurde, ist garantiert Voreingenommenheit ...
Beispielpfadgenerierung
Ein Beispiel dafür, wie man keine Präsentationen macht: Sehr schnell, schwer zu hören und die Idee zu verstehen, ist fast unmöglich. Die Arbeit selbst ist
hier verfügbar.
Die Jungs entwickeln ihr bisheriges Prognoseergebnis mehrere Schritte vorwärts. In der vorherigen Arbeit gab es zwei Hauptideen: Verwenden Sie anstelle von RNN ein Netzwerk mit mehreren Ausgängen zu unterschiedlichen Zeitpunkten. Anstelle bestimmter Zahlen versuchen wir, Verteilungen vorherzusagen und Quantile auszuwerten. Dies alles wird als
MQ-RNN / CNN (Multi-Horizont Forecasting Quantile Regression) bezeichnet.
Dieses Mal haben wir versucht, die Prognose mithilfe der Nachbearbeitung zu verfeinern. Betrachtet zwei Ansätze. Als Teil des ersten versuchen wir, die Verteilung des neuronalen Netzwerks unter Verwendung von posterioren Daten zu „kalibrieren“ und die Kovarianzmatrix von Ausgaben und Beobachtungen, die sogenannte Kovarianzschrumpfung, zu lernen. Die Methode ist recht einfach und funktioniert, aber ich möchte mehr. Der zweite Ansatz bestand darin, generative Modelle zu verwenden, um eine „Pfadstichprobe“ zu erstellen: Sie verwenden den generativen Ansatz für Prognosen (GAN, VAE). Gute, aber instabile Ergebnisse wurden mit Hilfe von
WaveNet erzielt, das für die Klangerzeugung
entwickelt wurde .
Strukturierte Netzwerke grafisch darstellen
Eine interessante Arbeit zum Transfer von "Wissen über das Fachgebiet" im neuronalen Netz. Sie zeigten am Beispiel der Vorhersage des Ausmaßes der Kriminalität im Raum (nach Stadtregionen) und in der Zeit (nach Tagen und Stunden). Die Hauptschwierigkeit: stark spärliche Daten und das Vorhandensein seltener lokaler Ereignisse. Infolgedessen funktionieren viele Methoden nicht gut. Im Durchschnitt ist es immer noch möglich, täglich zu raten, jedoch nicht für bestimmte Bereiche und Stunden. Versuchen wir, eine Struktur auf hoher Ebene und Mikromuster in einem neuronalen Netzwerk zu kombinieren.
Wir erstellen ein Kommunikationsdiagramm unter Verwendung von Postleitzahlen und bestimmen den Einfluss eines auf das andere mithilfe des
multivariaten Hawkes-Prozesses . Als nächstes bauen wir auf der Grundlage des erhaltenen Diagramms die Topologie des neuronalen Netzwerks auf und verbinden die Blöcke der Stadtregionen mit einem Verbrechen, das eine Korrelation aufweist.
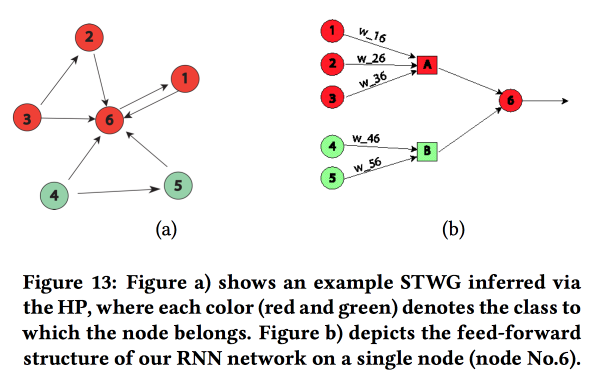
Wir haben diesen Ansatz mit zwei anderen verglichen: Das Training in einem Raster für einen Distrikt oder in einem Raster für eine Gruppe von Regionen mit einer ähnlichen Kriminalitätsrate zeigte eine Erhöhung der Genauigkeit. Für jede Region wird ein zweischichtiges LSTM mit zwei vollständig verbundenen Schichten eingeführt.
Neben Verbrechen zeigten sie auch Beispiele für Arbeiten zur Verkehrsprognose. Hier wird der Graph zum Aufbau eines Netzwerks bereits geografisch von kNN aufgenommen. Es ist nicht ganz klar, inwieweit ihre Ergebnisse mit anderen verglichen werden können (sie haben die Metriken in der Analyse frei geändert), aber im Allgemeinen sieht die Heuristik für den Aufbau eines Netzwerks angemessen aus.
Nichtparametrischer Ansatz für die Ensemble-Vorhersage
Ensembles sind ein sehr beliebtes Thema, aber wie man das Ergebnis aus einzelnen Prognosen ableitet, ist nicht immer offensichtlich. In ihrer Arbeit schlagen die Autoren einen
neuen Ansatz vor .
Oft funktionieren einfache Ensembles gut, sogar noch besser. als das neumodische
Bayes'sche Modell Mittelwertbildung und Mittelwertbildung-NN. Regression ist auch nicht schlecht, führt jedoch häufig zu seltsamen Ergebnissen bei der Auswahl der Gewichte (z. B. erhalten einige Prognosen ein negatives Gewicht usw.). Tatsächlich liegt der Grund dafür häufig in der Tatsache, dass die Aggregationsmethode einige Annahmen über die Verteilung des Prognosefehlers verwendet (z. B. nach Gauß oder normal), aber wenn er verwendet wird, vergessen sie, diese Annahme zu überprüfen. Die Autoren versuchten, einen annahmefreien Ansatz vorzuschlagen.
Wir betrachten zwei zufällige Prozesse: Der Datengenerierungsprozess (DGP) modelliert die Realität und kann von der Zeit abhängen, und der Prognosegenerierungsprozess (FGP) modelliert die Erstellung von Prognosen (es gibt viele davon - einen pro Ensemblemitglied). Der Unterschied zwischen diesen beiden Prozessen ist auch ein zufälliger Prozess, den wir zu analysieren versuchen werden.
- Wir sammeln historische Daten und konstruieren die Fehlerverteilungsdichte für die Prädiktoren unter Verwendung der Kernel-Dichteschätzung.
- Als nächstes erstellen wir eine Prognose und wandeln sie durch Hinzufügen des konstruierten Fehlers in eine Zufallsvariable um.
- Dann lösen wir das Problem der Maximierung der Wahrscheinlichkeit.
Die resultierende Methode ähnelt fast EMOS (Ensemble Model Output Statistics) mit einem Gaußschen Fehler und viel besser mit Nicht-Gaußschen. In der Realität ist beispielsweise (
Wikipedia Page Traffic Dataset ) häufig ein nicht-Gaußscher Fehler.
Verschachteltes LSTM: Modellierung von Taxonomie und zeitlicher Dynamik in standortbasierten sozialen Netzwerken
Die Arbeit wird von Autoren von Google eingereicht. Wir versuchen, die nächste Benutzerprüfung vorherzusagen. unter Verwendung seiner Geschichte der jüngsten Chekins und Metadaten von Orten, vor allem ihrer Beziehung zu Tags / Kategorien. Die Kategorien sind dreistufig, wir verwenden die beiden oberen Ebenen: Die übergeordnete Kategorie beschreibt die Absicht des Benutzers (zum Beispiel den Wunsch zu essen) und die untergeordnete Kategorie beschreibt die Vorlieben des Benutzers (zum Beispiel mag der Benutzer spanisches Essen). Die Nebenkategorie des nächsten Schecks sollte angezeigt werden, um mehr Einnahmen aus Online-Werbung zu erzielen.
Wir verwenden zwei verschachtelte LSTMs: die obere wie üblich gemäß der Reihenfolge der Überprüfungen und die verschachtelte - gemäß den Übergängen im Kategoriebaum von übergeordnet zu untergeordnet.
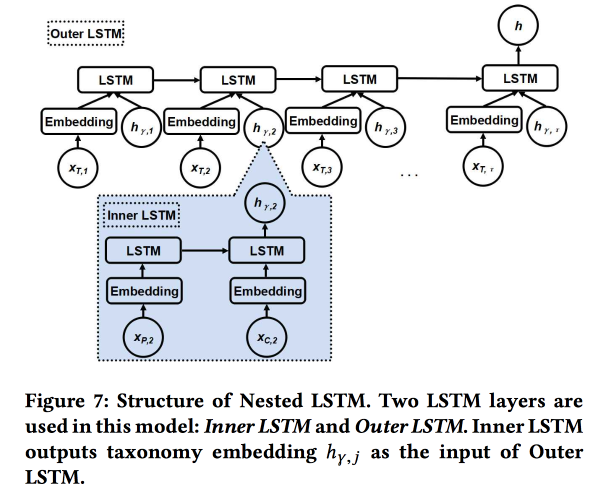
Es ist 5-7% besser als bei einfachem LSTM mit Einbettungen in Rohkategorien. Darüber hinaus haben wir gezeigt, dass LSTM-Übergangsübergänge im Kategoriebaum schöner aussehen als einfache und besser gruppiert sind.
Verschiebungen im evolutionären semantischen Raum identifizieren
Fröhlich genug Rede des
chinesischen Professors . Unter dem Strich soll versucht werden zu verstehen, wie Wörter ihre Bedeutung ändern.
Jetzt trainiert jeder erfolgreich Worteinbettungen, sie funktionieren gut, aber zu unterschiedlichen Zeiten trainiert zu werden ist nicht zum Vergleich geeignet - Sie müssen Allining machen.
- Sie können das alte zur Initialisierung verwenden, dies gibt jedoch keine Garantie.
- Sie können die Transformationsfunktion für Allining lernen, sie funktioniert jedoch nicht immer, da Dimensionen nicht immer gleichermaßen geteilt werden.
- Und Sie können topologischen, nicht Vektorraum verwenden!
Am Ende das Wesentliche der Lösung: Wir erstellen in verschiedenen Zeiträumen ein knNN-Diagramm in den Nachbarn des Wortes, um die Bedeutungsänderung zu bewerten, und versuchen zu verstehen, ob es eine signifikante Änderung gibt. Hierfür verwenden wir das
Bayesian Surprise- Modell. Tatsächlich betrachten wir die
KL-Divergenz der Verteilung einer Hypothese (vor) und einer Hypothese, die Beobachtungen unterliegt (posterior) - dies ist eine Überraschung. Bei Wörtern und CNN-Graphen verwenden wir Dirichlet basierend auf den Häufigkeiten der Nachbarn in der Vergangenheit als A-priori-Verteilung und vergleichen es mit dem realen Multinom in der jüngeren Geschichte. Gesamt:
- Wir haben die Geschichte geschnitten.
- Wir erstellen Einbettungen (LINE unter Beibehaltung der Initialisierung).
- Wir betrachten KNN auf den Einbettungen.
- Schätzen Sie die Überraschung.
Wir validieren, indem wir zwei zufällige Wörter mit der gleichen Häufigkeit nehmen und uns gegenseitig austauschen - die Qualitätssteigerung beträgt überraschenderweise 80%. Dann nehmen wir 21 Wörter mit bekannten Bedeutungsverschiebungen und prüfen, ob wir sie automatisch finden können. Open Source haben noch keine detaillierte Beschreibung dieses Ansatzes, aber
es gibt eine bei SIGIR 2018 .
AdKDD & TargetAd
Nach dem Mittagessen ging ich zu einem Seminar über Online-Werbung. Es gibt viel mehr Redner aus der Branche und alle denken darüber nach, wie sie mehr Geld verdienen können.
Ad Tech bei Airbnb
Als großes Unternehmen mit einem großen DS-Team investiert AirBnB viel in die korrekte Werbung für sich selbst und seine internen Angebote auf externen Websites. Einer der Entwickler sprach ein wenig über die Herausforderungen.
Beginnen wir mit der Werbung in einer Suchmaschine: Bei der Suche nach Hotels bei Google sind die ersten beiden Seiten Werbung :(. Der Nutzer versteht dies jedoch häufig nicht einmal, da die Werbung sehr relevant ist. Standardschema: Wir stimmen die Werbeanfragen nach Stichwörtern ab und erhalten die Bedeutung des Musters / Musters ( Stadt, billig oder Luxus usw.)
Nachdem die Kandidaten ausgewählt wurden, arrangieren wir eine Auktion zwischen ihnen (jetzt wird überall der
allgemeine zweite Preis verwendet). Bei der Teilnahme an der Auktion besteht das Ziel darin, die Wirkung auf ein festes Budget mithilfe eines Modells mit einer Kombination aus Klickwahrscheinlichkeit und Einkommen zu maximieren: Gebot = P (Klick | Suchabfrage) * Buchungswert. Ein wichtiger Punkt: Geben Sie nicht das ganze Geld zu schnell aus, also fügen Sie Spend Pacer hinzu.
AirBnB verfügt über ein leistungsstarkes System für A / B-Tests, kann hier jedoch nicht angewendet werden, da es den größten Teil des Google-Prozesses steuert. Dort versprachen sie, weitere Tools für Werbetreibende hinzuzufügen, große Player freuen sich wirklich darauf.
Separates Problem: Benutzerkontakt mit Werbung an mehreren Stellen. Wir reisen durchschnittlich ein paar Mal im Jahr, der Zyklus der Reisevorbereitung und Buchung ist sehr lang (Wochen und sogar Monate), es gibt mehrere Kanäle, über die wir den Benutzer erreichen können, und wir müssen das Budget nach Kanälen aufteilen. Dieses Thema ist sehr schmerzhaft, es gibt einfache Methoden (linear, sorgfältig, durch den letzten Klick oder durch die Ergebnisse des
Hebetests ). AirBnB hat zwei neue Ansätze ausprobiert: basierend auf Markov-Modellen und
dem Shapley-Modell .
Mit dem Markov-Modell ist alles mehr oder weniger klar: Wir bauen eine diskrete Kette auf, deren Knoten den Berührungspunkten mit Werbung entsprechen, es gibt auch einen Knoten für die Konvertierung. Entsprechend den Daten wählen wir Gewichte für Übergänge aus und geben den Knoten, bei denen die Wahrscheinlichkeit eines Übergangs größer ist, mehr Budget. Ich warf ihnen eine Frage zu: Warum eine einfache Markov-Kette verwenden, während es logischer ist, MDP zu verwenden? Sie sagten, dass sie an diesem Thema arbeiten.
Bei Shapley ist es interessanter: Tatsächlich ist dies ein seit langem bekanntes Schema zur Bewertung des additiven Effekts, bei dem verschiedene Kombinationen von Effekten berücksichtigt werden, der Effekt von jedem von ihnen bewertet wird und dann ein bestimmtes Aggregat für jeden einzelnen Effekt bestimmt wird. Die Schwierigkeit besteht darin, dass es Synergien zwischen den Effekten geben kann (seltener Antagonismus) und das Ergebnis der Summe nicht gleich der Summe der Ergebnisse ist. Im Allgemeinen, eine ziemlich interessante und schöne Theorie,
rate ich
Ihnen zu lesen .
Im Fall von AirBnB sieht die Anwendung des Shapley-Modells ungefähr so aus:
- Wir haben in den beobachteten Daten Beispiele mit unterschiedlichen Kombinationen von Effekten und dem tatsächlichen Ergebnis.
- Füllen Sie die Lücken in den Daten (nicht alle Kombinationen werden dargestellt) mit ML aus.
- Wir berechnen das Darlehen für jede Art von Shapley-Auswirkungen.
Microsoft: {AI} -Grenzen verschieben
Weiter ein wenig darüber. Microsoft beschäftigt sich mit Werbung, jetzt von der Seite der Website, hauptsächlich Bing. Ein bisschen geschlachtet:
- Der Werbemarkt wächst sehr schnell (exponentiell).
- Werbung auf einer Seite kannibalisiert sich gegenseitig. Sie müssen die gesamte Seite analysieren.
- Die Conversion auf einigen Seiten ist höher, obwohl der CTP schlechter ist.
Es gibt ungefähr 70 Modelle in der Bing-Werbe-Engine, 2000 Experimente offline, 400 online. Jede Woche eine wesentliche Änderung der Plattform. Im Allgemeinen arbeiten sie unermüdlich. Was sind die Änderungen in der Plattform:
- Der Mythos einer Metrik: Es funktioniert nicht so, Metriken wachsen und konkurrieren.
- Wir haben das System der Werbung für Matching-Anfragen von NLP zu DL neu gestaltet, das auf FPGA berechnet wird.
- Sie verwenden föderale Modelle und kontextbezogene Banditen: Interne Modelle erzeugen Wahrscheinlichkeit und Unsicherheit, der Bandit von oben trifft eine Entscheidung. Sie sprach viel über Banditen, sie werden verwendet, um Modelle zu starten und mit Reisegeschwindigkeit zu starten. Sie umgehen die Tatsache, dass eine Verbesserung des Modells häufig zu niedrigeren Einkommen führt :(
- Es ist sehr wichtig, die Unsicherheit zu bewerten (na ja, ohne sie kann man keinen Banditen bauen).
- Für kleine Werbetreibende funktioniert die Einrichtung der Werbung durch Banditen nicht, es gibt wenig Statistiken, es ist notwendig, separate Modelle für einen Kaltstart zu erstellen.
- Es ist wichtig, die Leistung bei verschiedenen Kohorten von Benutzern zu überwachen. Sie verfügen über ein automatisches System zum Schneiden gemäß den Ergebnissen des Experiments.
Wir haben ein wenig über die Abflussanalyse gesprochen. Nicht immer sind die Hypothesen der Verkäufer über die Ursachen des Abflusses wahr, Sie müssen tiefer graben. Dazu müssen Sie interpretierbare Modelle (oder ein spezielles Modell zur Erklärung von Prognosen) erstellen und viel nachdenken. Und dann mache die Experimente. Es ist jedoch immer schwierig, Experimente mit dem Abfluss durchzuführen. Sie empfehlen die Verwendung von Metriken zweiter Ordnung und
eines Artikels von Google .
Sie verwenden auch so etwas wie Commercial Knowledge Graph, das den Themenbereich beschreibt: Marken, Produkte usw. Das Diagramm wird vollautomatisch und unbeaufsichtigt erstellt. Marken sind mit Kategorien gekennzeichnet, dies ist wichtig, da es im Allgemeinen nicht immer möglich ist, unbeaufsichtigt die Marke als Ganzes zu isolieren, aber innerhalb eines bestimmten Kategoriethemas ist das Signal stärker. Leider habe ich nach ihrer Methode keine offenen Werke gefunden.
Google-Anzeigen
Der gleiche Typ, der gestern über die Grafen gesprochen hat, sagt, alles sei genauso traurig und arrogant. Ging zu mehreren Themen.
Erster Teil: Robuste stochastische Anzeigenzuordnung. Wir haben Knoten (Anzeigen) und Online-Knoten (Benutzer) budgetiert, und es gibt auch einige Gewichte zwischen ihnen. Jetzt müssen Sie auswählen, welche Anzeigen den neuen Knoten anzeigen sollen. Sie können es gierig machen (immer nach maximalem Gewicht), aber dann laufen wir Gefahr, ein Budget vorzeitig auszuarbeiten und eine ineffektive Lösung zu erhalten (theoretische Grenze ist 1/2 des Optimums). Sie können auf verschiedene Arten damit umgehen, tatsächlich haben wir hier einen traditionellen Konflikt zwischen Rache und Gerechtigkeit.
Bei der Auswahl der Zuordnungsmethode kann man eine zufällige Reihenfolge des Auftretens von Online-Knoten gemäß einer bestimmten Verteilung annehmen, aber in der Praxis kann es auch eine kontroverse Reihenfolge geben (d. H. Mit Elementen mit einem entgegengesetzten Effekt). Die Methoden in diesen Fällen sind unterschiedlich und enthalten Links zu den neuesten Artikeln:
1 und
2 .
Zweiter Teil: Inceptive-Aware Learning / Robust Pricing. Jetzt versuchen wir, die Frage der Wahl des Reservierungspreises zu lösen, um die Einnahmen von Werbeseiten zu steigern. Wir erwägen auch die Verwendung anderer Auktionen wie
Myerson Auction ,
BINTAC , Rollback auf die Auktion des ersten Preises im Falle eines Kontakts mit der Reservierung. Sie gehen nicht auf Details ein, sondern senden sie an
ihren Artikel .
Dritter Teil: Online-Bündelung. Wieder lösen wir das Problem der Einkommenssteigerung, aber jetzt gehen wir von der anderen Seite. Wenn Sie Anzeigen in großen Mengen kaufen könnten (Offline-Bündelung), können Sie in vielen Situationen eine optimalere Lösung anbieten. In einer Online-Auktion ist dies jedoch nicht möglich. Sie müssen komplexe Modelle mit Speicher erstellen, und unter rauen Bedingungen schiebt RTB dies nicht.
Dann erscheint ein magisches Modell, bei dem der gesamte Speicher auf eine Ziffer (Bankkonto) reduziert wird, die Zeit jedoch abläuft und der Lautsprecher hektisch durch die Folien blättert.
Für Antworten, in seinem besten Stil, sendet an den Artikel .Deep Policy-Optimierung von Alibaba
Wir arbeiten mit gesponserter Suche. Wir haben uns für RL entschieden, wie der Name schon sagt - tief. Detaillierte Informationen finden Sie im Artikel .Als einer der wichtigen Punkte sprachen sie über die Trennung des Offline-Teils des Trainings, in dem das tiefe Netzwerk selbst trainiert wird, und des Online-Teils, in dem die Zeichen angepasst werden.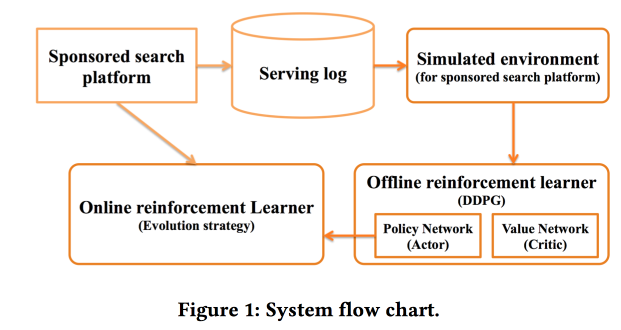 Als Belohnung verwenden sie eine Mischung aus Klickrate und Einkommen, wenden das DDPG- Modell an .
Als Belohnung verwenden sie eine Mischung aus Klickrate und Einkommen, wenden das DDPG- Modell an .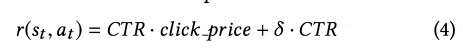 Am Ende sprach der Redner drei offene Fragen an das Publikum, "um nachzudenken":
Am Ende sprach der Redner drei offene Fragen an das Publikum, "um nachzudenken":- Es gibt keine reale Umgebung für Radar.
- Viel Rauschen in der Realität, was die Analyse erheblich erschwert.
- ?
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
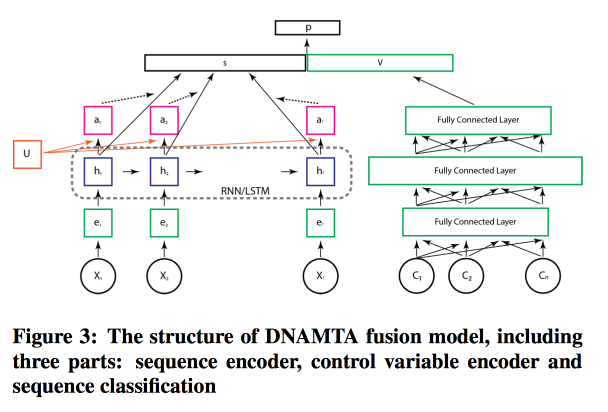
, attention- .
Fazit
Dann gab es eine Pathos-Eröffnungssitzung mit einem IMAX-Video in der besten Tradition von Blockbuster-Trailern. Vielen Dank an alle, die mitgeholfen haben, dies alles zu organisieren - ein Rekord-KDD in jeder Hinsicht (einschließlich 1,2 Millionen US-Dollar Sponsoring), der die Worte von Lord Bytes (Minister für Innovation) trennte UK) und eine Postersession, für die es keine Kraft mehr gibt. Wir müssen uns auf morgen vorbereiten.