Es wird angenommen, dass die Entwicklung etwa 10% der Zeit und das Debuggen 90% der Zeit in Anspruch nimmt. Vielleicht ist diese Aussage übertrieben, aber jeder Entwickler wird zustimmen, dass das Debuggen ein äußerst ressourcenintensiver Prozess ist, insbesondere in großen Multithread-Systemen.
Die Optimierung und Systematisierung des Debugging-Prozesses kann daher erhebliche Vorteile in Form von eingesparten Arbeitsstunden bringen, die Geschwindigkeit der Problemlösung erhöhen und letztendlich die Loyalität Ihrer Benutzer erhöhen.
 Sergey Shchegrikovich
Sergey Shchegrikovich (dotmailer) schlug auf der
DotNext 2018 Piter- Konferenz vor, das Debuggen als einen Prozess zu betrachten, der beschrieben und optimiert werden kann. Wenn Sie immer noch keinen klaren Plan zum Auffinden von Fehlern haben - unter dem geschnittenen Video- und Textprotokoll von Sergeys Bericht.
(Und am Ende des Beitrags haben wir
John Skeets Appell an alle Partner hinzugefügt.
Mein Ziel ist es, die Frage zu beantworten: Wie können Fehler effizient behoben werden und worauf sollte der Schwerpunkt liegen? Ich denke, die Antwort auf diese Frage ist ein Prozess. Der Debugging-Prozess, der aus sehr einfachen Regeln besteht und Sie kennen sie gut, aber Sie verwenden ihn wahrscheinlich unwissentlich. Daher ist es meine Aufgabe, sie zu systematisieren und anhand eines Beispiels zu zeigen, wie man effektiver wird.
Wir werden eine gemeinsame Sprache für die Kommunikation während des Debuggens entwickeln und einen direkten Weg finden, um die Hauptprobleme zu finden. An meinen Beispielen werde ich zeigen, was aufgrund eines Verstoßes gegen diese Regeln passiert ist.
Debug-Dienstprogramme
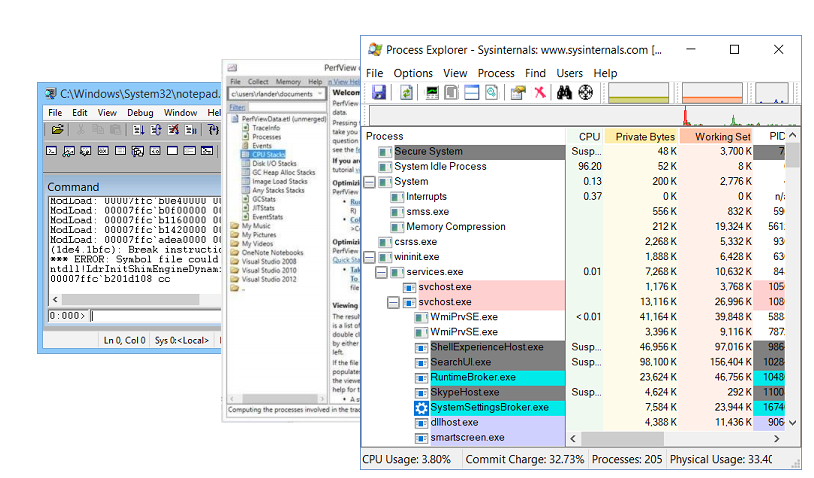
Natürlich ist ein Debuggen ohne Debugging-Dienstprogramme nicht möglich. Meine Favoriten sind:
- Windbg , das neben dem Debugger selbst über umfangreiche Funktionen zum Studieren von Speicherabbildern verfügt. Ein Speicherauszug ist ein Ausschnitt aus dem Status eines Prozesses. Darin finden Sie den Wert der Felder von Objekten, Call-Stacks, aber leider ist der Speicherauszug statisch.
- PerfView ist ein Profiler, der auf der ETW-Technologie basiert .
- Sysinternals ist ein von Mark Russinovich geschriebenes Dienstprogramm, mit dem Sie etwas weiter in das Gerät des Betriebssystems eintauchen können.
Fallender Dienst
Beginnen wir mit einem Beispiel aus meinem Leben, in dem ich zeigen werde, wie die unsystematische Natur des Debugging-Prozesses zu Ineffizienz führt.
Wahrscheinlich ist dies allen passiert, wenn Sie für ein neues Projekt zu einem neuen Unternehmen in einem neuen Team kommen und dann vom ersten Tag an irreparable Vorteile erzielen möchten. So war es bei mir. Zu dieser Zeit hatten wir einen Dienst, der HTML zur Eingabe und Ausgabe von Bildern zur Ausgabe erhielt.
Der Dienst wurde unter .Net 3.0 geschrieben und ist schon sehr lange her. Dieser Dienst hatte eine kleine Funktion - er stürzte ab. Fiel oft, etwa alle zwei bis drei Stunden. Wir haben dies elegant behoben - setzen Sie die Neustarteigenschaften in den Eigenschaften des Dienstes nach dem Herbst.
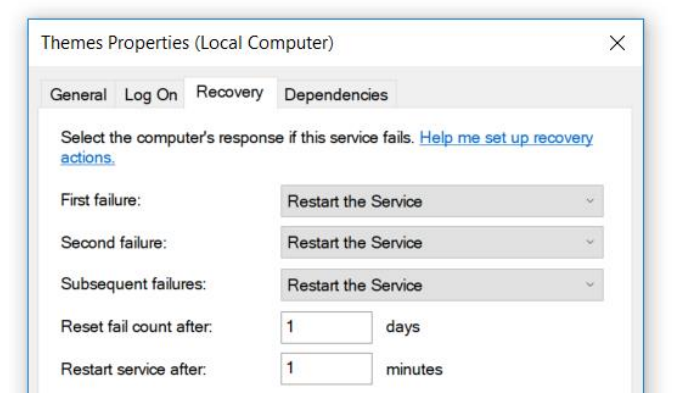
Der Service war für uns nicht kritisch und wir konnten es überleben. Aber ich habe mich dem Projekt angeschlossen und als erstes habe ich beschlossen, es zu reparieren.
Wohin gehen .NET-Entwickler, wenn etwas nicht funktioniert? Sie gehen zu EventViewer. Aber dort fand ich nichts außer der Aufzeichnung, dass der Dienst fiel. Es gab keine Nachrichten über den nativen Fehler oder einen Aufrufstapel.
Es gibt ein bewährtes Tool für die nächsten Schritte - wir verpacken die gesamte
main in
try-catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); }
Die Idee ist einfach:
try-catch wird funktionieren, es wird uns nerven, wir werden es lesen und den Service reparieren. Wir kompilieren, stellen für die Produktion bereit, der Service stürzt ab, es gibt keinen Fehler. Fügen Sie einen weiteren
catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); }
Wir wiederholen den Vorgang: Der Dienst stürzt ab, es gibt keine Fehler in den Protokollen. Das Letzte, was helfen kann, ist
finally , was immer aufgerufen wird.
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); } finally { LogEndOfExecution(); }
Wir kompilieren, implementieren, der Service stürzt ab, es gibt keine Fehler. Drei Tage vergehen hinter diesem Prozess, jetzt kommen bereits Gedanken, dass wir endlich anfangen müssen, etwas anderes zu denken und zu tun. Sie können viele Dinge tun: Versuchen Sie, den Fehler auf dem lokalen Computer zu reproduzieren, Speicherauszüge zu überwachen usw. Es schien noch zwei Tage und ich werde diesen Fehler beheben ...
Zwei Wochen sind vergangen.
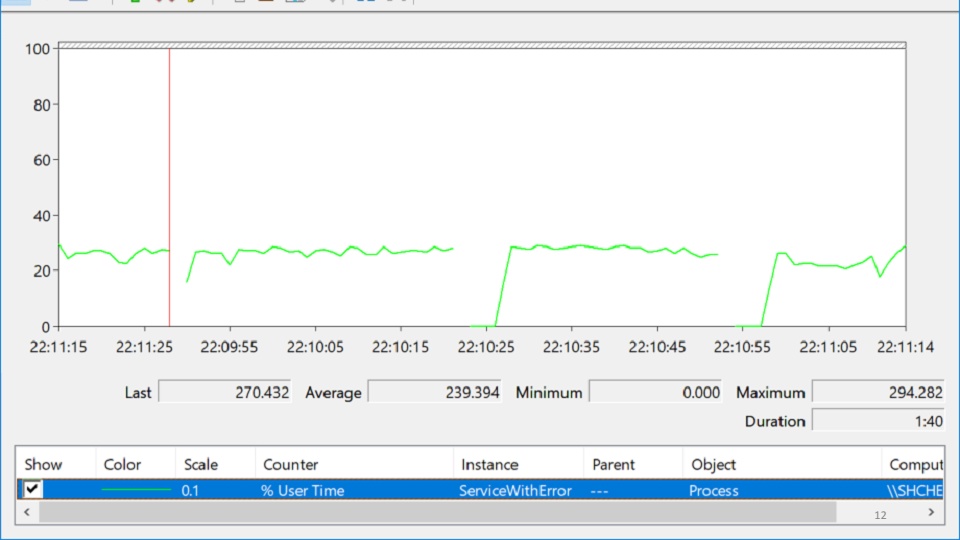
Ich habe in PerformanceMonitor nachgesehen, wo ich einen Dienst gesehen habe, der abstürzt, dann steigt und dann wieder fällt. Dieser Zustand wird
Verzweiflung genannt und sieht folgendermaßen aus:
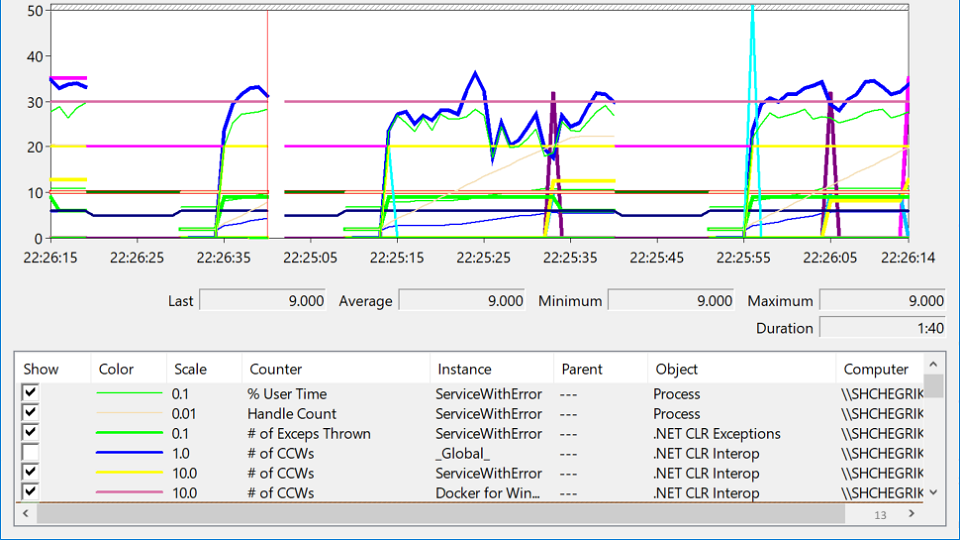
Versuchen Sie bei dieser Vielzahl von Etiketten herauszufinden, wo das Problem wirklich liegt? Nach mehreren Stunden Meditation tritt plötzlich das Problem auf:
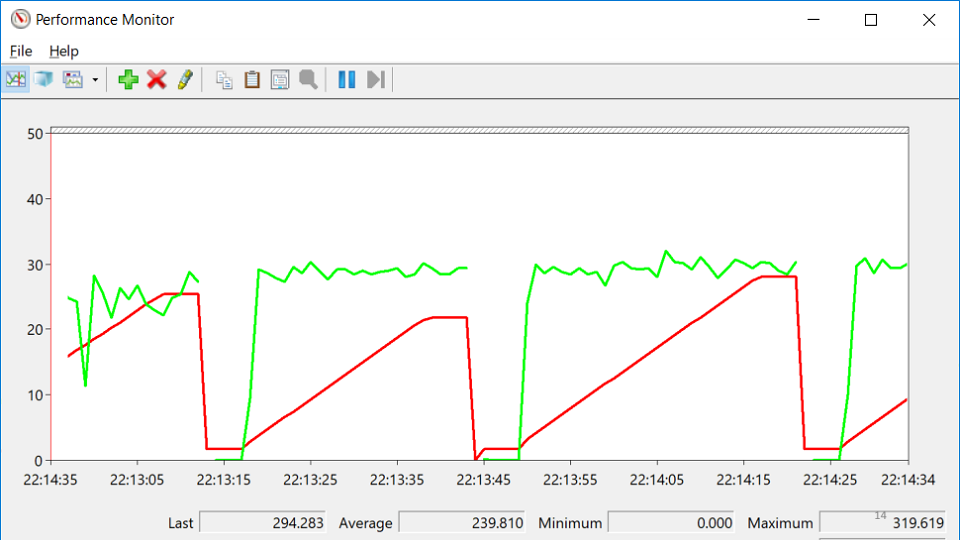
Die rote Linie gibt die Anzahl der nativen Handles an, die dem Prozess gehören. Ein natives Handle ist ein Verweis auf eine Betriebssystemressource: Datei, Registrierung, Registrierungsschlüssel, Mutex usw. Für eine seltsame Kombination von Umständen fällt der Rückgang der Anzahl der Griffe mit den Momenten zusammen, in denen der Service fiel. Dies führt zu der Idee, dass irgendwo ein Griffleck vorhanden ist.
Wir nehmen einen Speicherauszug und öffnen ihn in WinDbg. Wir beginnen Befehle auszuführen. Versuchen wir, die Finalisierungswarteschlange der Objekte anzuzeigen, die von der Anwendung freigegeben werden sollen.
0:000> !FinalizeQueue
Ganz am Ende der Liste fand ich einen Webbrowser.
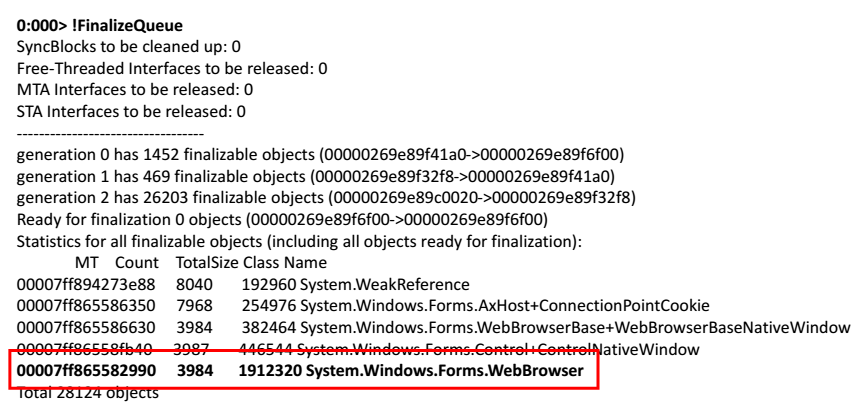
Die Lösung ist einfach: Nehmen Sie WebBrowser und rufen Sie
dispose dafür auf:
private void Process() { using (var webBrowser = new WebBrowser()) {
Die Schlussfolgerungen aus dieser Geschichte können wie folgt gezogen werden: Zwei Wochen sind zu lang und zu lang, um eine ungebetene
dispose zu finden; dass wir eine Lösung für das Problem gefunden haben - Glück, da es keinen spezifischen Ansatz gab, gab es keinen systematischen Charakter.
Danach hatte ich eine Frage: Wie kann man effektiv debütieren und was tun?
Dazu müssen Sie nur drei Dinge wissen:
- Debugging-Regeln
- Algorithmus zum Auffinden von Fehlern.
- Proaktive Debugging-Techniken.
Debugging-Regeln
- Wiederholen Sie den Fehler.
- Wenn Sie den Fehler nicht behoben haben, ist er nicht behoben.
- Verstehe das System.
- Überprüfen Sie den Stecker.
- Teilen und erobern.
- Erfrischen Sie sich.
- Das ist dein Fehler.
- Fünf warum.
Dies sind ziemlich klare Regeln, die sich selbst beschreiben.
Wiederholen Sie den Fehler. Eine sehr einfache Regel, denn wenn Sie keinen Fehler machen können, gibt es nichts zu beheben. Es gibt jedoch verschiedene Fälle, insbesondere bei Fehlern in einer Umgebung mit mehreren Threads. Wir hatten irgendwie einen Fehler, der nur auf Itanium-Prozessoren und nur auf Produktionsservern auftrat. Daher besteht die erste Aufgabe im Debugging-Prozess darin, eine Konfiguration des Prüfstands zu finden, auf dem der Fehler reproduziert werden würde.
Wenn Sie den Fehler nicht behoben haben, ist er nicht behoben. Manchmal passiert dies: Ein Bug-Tracker enthält einen Bug, der vor einem halben Jahr aufgetreten ist, niemand hat ihn lange gesehen, und es besteht der Wunsch, ihn einfach zu schließen. Aber in diesem Moment verpassen wir die Chance zu wissen, die Chance zu verstehen, wie unser System funktioniert und was wirklich damit passiert. Daher ist jeder Fehler eine neue Gelegenheit, etwas zu lernen und mehr über Ihr System zu erfahren.
Verstehe das System. Brian Kernighan hat einmal gesagt, wenn wir so schlau wären, dieses System zu schreiben, müssten wir doppelt schlau sein, um es zu debütieren.
Ein kleines Beispiel für die Regel. Unsere Überwachung zeichnet Diagramme:
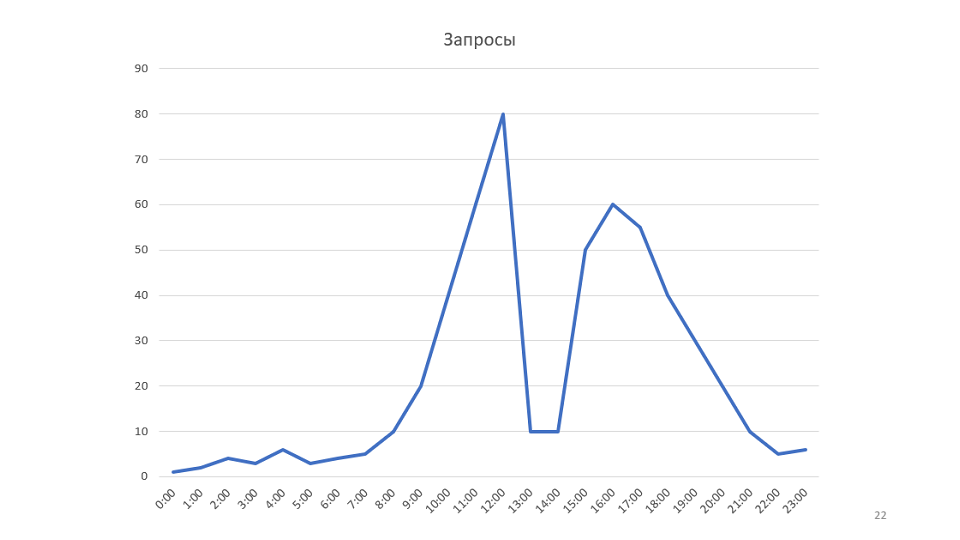
Dies ist eine grafische Darstellung der Anzahl der von unserem Service bearbeiteten Anfragen. Nachdem wir es uns angesehen hatten, kamen wir auf die Idee, dass es möglich sein würde, die Geschwindigkeit des Dienstes zu erhöhen. In diesem Fall steigt der Zeitplan und es kann möglich sein, die Anzahl der Server zu reduzieren.
Die Optimierung der Webleistung erfolgt einfach: Wir nehmen PerfView, führen es auf dem Produktionscomputer aus, entfernen den Trace innerhalb von 3-4 Minuten, bringen diesen Trace zum lokalen Computer und beginnen mit dem Studium.
Eine der Statistiken, die PerfView anzeigt, ist der Garbage Collector.
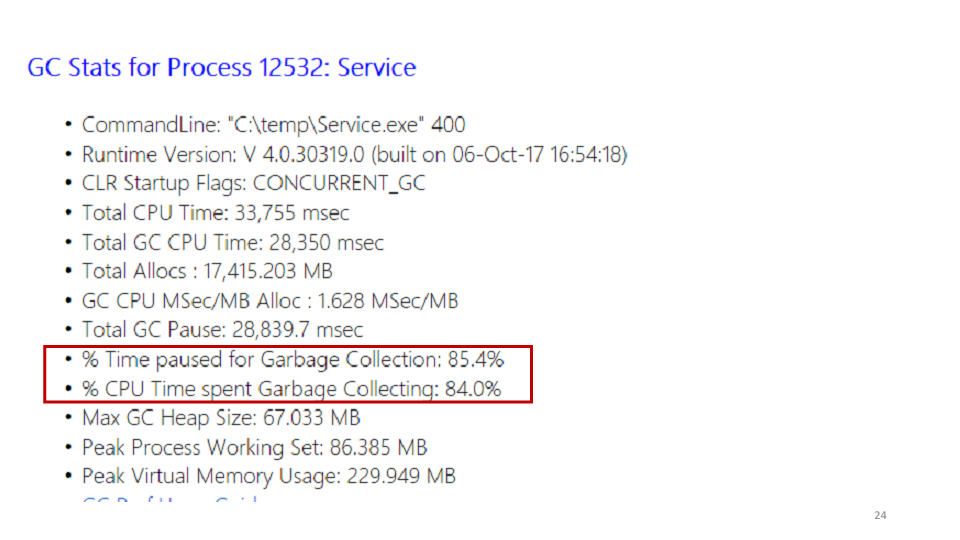
Bei Betrachtung dieser Statistiken haben wir festgestellt, dass der Dienst 85% seiner Zeit damit verbringt, Müll zu sammeln. In PerfView können Sie genau sehen, wo diese Zeit verbracht wird.
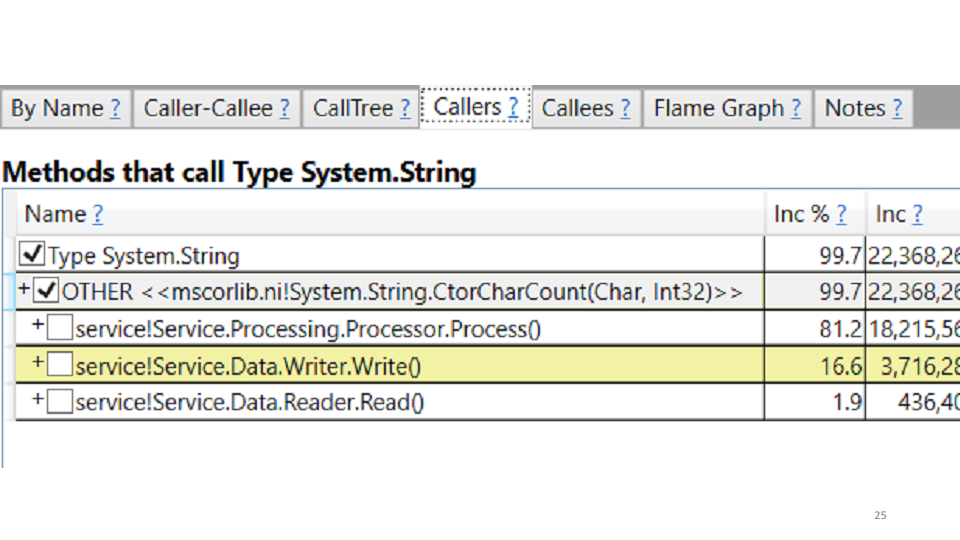
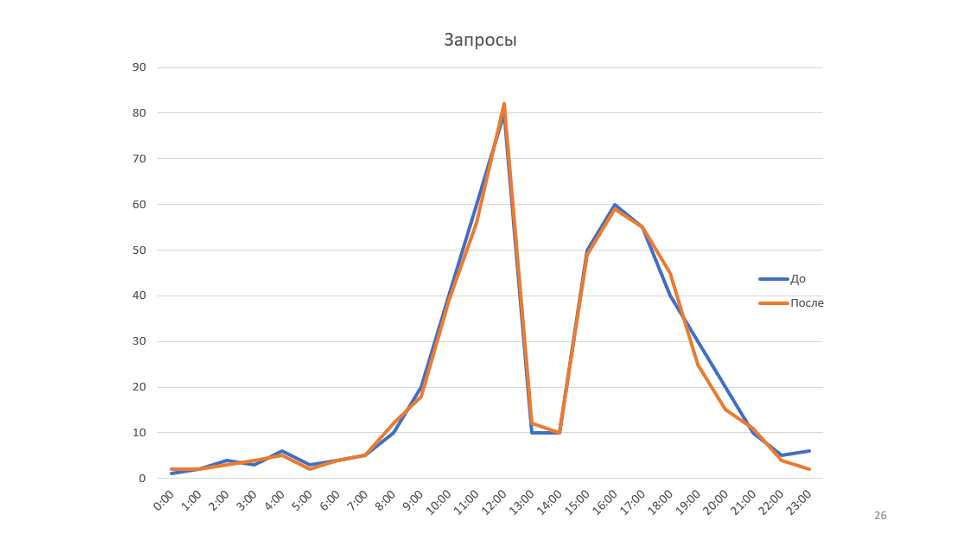
In unserem Fall werden dadurch Zeichenfolgen erstellt. Die Korrektur selbst bietet sich an: Wir ersetzen alle Strings durch StringBuilders. Vor Ort erzielen wir eine Produktivitätssteigerung von 20-30%. In der Produktion bereitstellen, sehen Sie die Ergebnisse im Vergleich zum alten Zeitplan:
Bei der Regel "System verstehen" geht es nicht nur darum zu verstehen, wie Interaktionen in Ihrem System ablaufen, wie Nachrichten ablaufen, sondern auch darum, Ihr System zu modellieren.
Im Beispiel zeigt das Diagramm die Bandbreite. Wenn Sie jedoch das gesamte System unter dem Gesichtspunkt der Warteschlangentheorie betrachten, stellt sich heraus, dass der Durchsatz unseres Systems nur von einem Parameter abhängt - der Geschwindigkeit des Eintreffens neuer Nachrichten. Tatsächlich hatte das System einfach nicht mehr als 80 Nachrichten gleichzeitig, sodass es keine Möglichkeit gibt, diesen Zeitplan zu optimieren.
Überprüfen Sie den Stecker. Wenn Sie die Dokumentation eines Haushaltsgeräts öffnen, wird diese auf jeden Fall dort geschrieben: Wenn das Gerät nicht funktioniert, überprüfen Sie, ob der Stecker in die Steckdose gesteckt ist. Nach einigen Stunden im Debugger denke ich oft, dass ich nur die neueste Version neu kompilieren oder einfach abholen musste.
Bei der Regel „Check the Plug“ geht es um Fakten und Daten. Das Debuggen beginnt nicht mit der Ausführung von WinDbg oder PerfView auf Produktionsmaschinen, sondern mit der Überprüfung von Fakten und Daten. Wenn der Dienst nicht antwortet, wird er möglicherweise nicht ausgeführt.
Teilen und erobern. Dies ist die erste und wahrscheinlich einzige Regel, die das Debuggen als Prozess umfasst. Es geht um Hypothesen, deren Förderung und Prüfung.
Einer unserer Dienste wollte nicht aufhören.
Wir stellen eine Hypothese auf: Vielleicht gibt es einen Zyklus im Projekt, der etwas endlos verarbeitet.
Sie können die Hypothese auf verschiedene Arten testen. Eine Möglichkeit besteht darin, einen Speicherauszug zu erstellen. Wir ziehen Call-Stacks mit dem
~*e!ClrStack aus dem Dump und allen Threads. Wir fangen an, drei Ströme zu sehen.
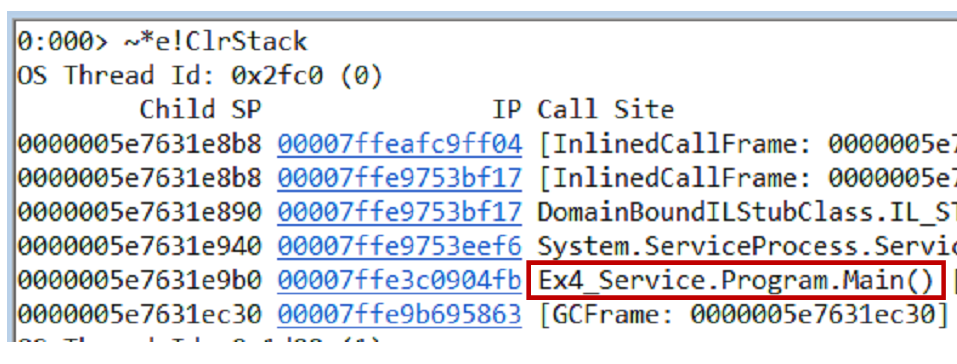
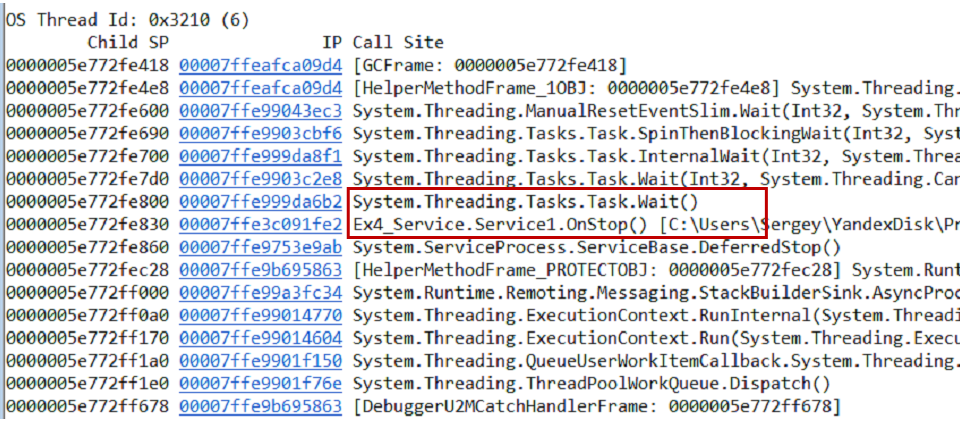
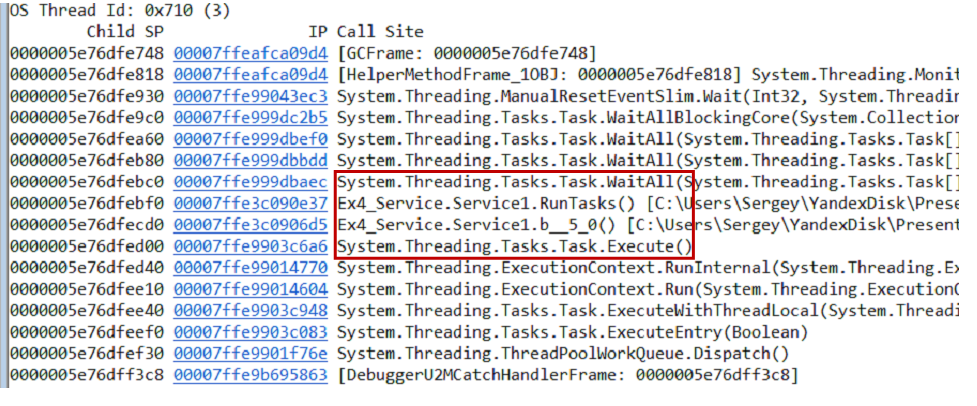
Der erste Thread befindet sich in Main, der zweite im
OnStop() Handler und der dritte Thread wartete auf einige interne Aufgaben. Daher ist unsere Hypothese nicht gerechtfertigt. Es gibt keine Schleife, alle Threads warten auf etwas. Höchstwahrscheinlich Deadlock.
Unser Service funktioniert wie folgt. Es gibt zwei Aufgaben - Initialisierung und Arbeiten. Durch die Initialisierung wird eine Verbindung zur Datenbank hergestellt, der Worker beginnt mit der Verarbeitung der Daten. Die Kommunikation zwischen ihnen erfolgt über ein gemeinsames Flag, das mithilfe von
TaskCompletionSource implementiert
TaskCompletionSource .
Wir stellen die zweite Hypothese auf: Vielleicht haben wir einen Stillstand einer Aufgabe für die zweite. Um dies zu überprüfen, können Sie jede Aufgabe separat über WinDbg anzeigen.
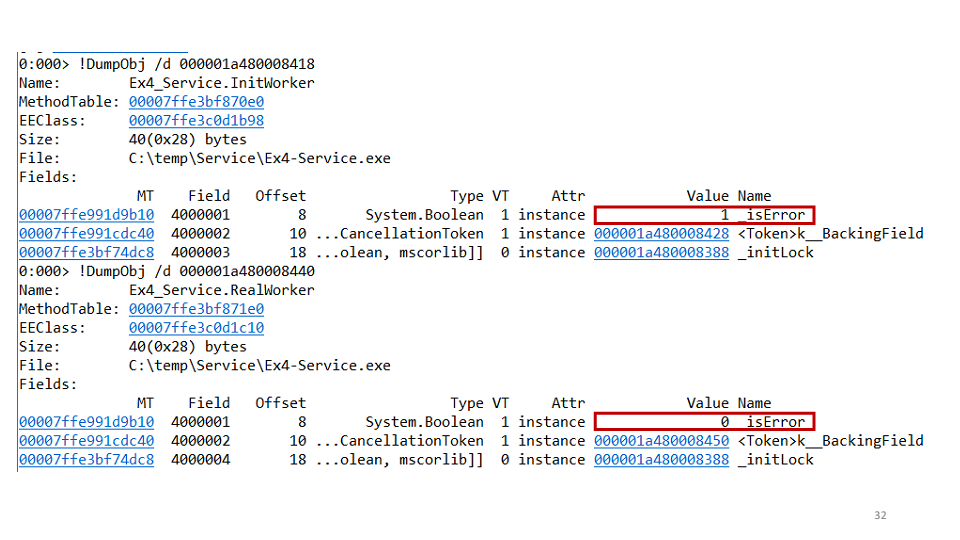
Es stellt sich heraus, dass eine der Aufgaben fiel und die zweite nicht. Im Projekt haben wir den folgenden Code gesehen:
await openAsync(); _initLock.SetResult(true);
TaskCompletionSource bedeutet, dass die Initialisierungsaufgabe die Verbindung öffnet und danach
TaskCompletionSource auf true setzt. Aber was ist, wenn hier eine Ausnahme fällt? Dann haben wir keine Zeit,
SetResult auf true zu setzen, daher war die Behebung dieses Fehlers wie
SetResult :
try { await openAsync(); _initLock.SetResult(true); } catch(Exception ex) { _initLock.SetException(ex); }
In diesem Beispiel stellen wir zwei Hypothesen auf: die Endlosschleife und den Deadlock. Die Regel "Teilen und Erobern" hilft, den Fehler zu lokalisieren. Aufeinanderfolgende Näherungen lösen solche Probleme.
Das Wichtigste in dieser Regel sind Hypothesen, da sie sich im Laufe der Zeit in Muster verwandeln. Und je nach Hypothese verwenden wir unterschiedliche Aktionen.
Erfrischen Sie sich. Diese Regel besagt, dass Sie nur vom Tisch aufstehen und gehen, Wasser, Saft oder Kaffee trinken, alles tun müssen, aber das Wichtigste ist, von Ihrem Problem abzulenken.
Es gibt eine sehr gute Methode namens Ente. Nach der Methode müssen wir über das Problem des
Entens erzählen. Sie können einen Kollegen als
Ente verwenden . Außerdem muss er nicht antworten, nur zuhören und zustimmen. Und oft finden Sie nach dem ersten Gespräch über das Problem selbst eine Lösung.
Das ist dein Fehler. Ich werde anhand eines Beispiels über diese Regel berichten.
Bei einer
AccessViolationException ein Problem
AccessViolationException . Im Call-Stack habe ich festgestellt, dass es aufgetreten ist, als wir die LinqToSql-Abfrage im SQL-Client generiert haben.

Aus diesem Fehler wurde deutlich, dass irgendwo die Integrität des Speichers verletzt wird. Glücklicherweise haben wir zu diesem Zeitpunkt bereits ein Änderungsmanagementsystem verwendet. Als Ergebnis wurde nach ein paar Stunden klar, was passiert ist: Wir haben .Net 4.5.2 auf unseren Produktionsmaschinen installiert.
Dementsprechend senden wir den Fehler an Microsoft, sie untersuchen ihn, wir kommunizieren mit ihnen, sie beheben den Fehler in .Net 4.6.1.
Für mich führte dies natürlich zu einer elfmonatigen Zusammenarbeit mit dem Microsoft-Support, nicht jeden Tag, aber die Reparatur dauerte von Anfang an elf Monate. Außerdem haben wir ihnen Dutzende von Gigabyte Speicherauszügen gesendet und Hunderte von privaten Assemblys platziert, um diesen Fehler abzufangen. Und die ganze Zeit konnten wir unseren Kunden nicht sagen, dass Microsoft schuld war, nicht wir. Daher liegt der Fehler immer bei Ihnen.
Fünf warum. Wir in unserer Firma verwenden Elastic. Elastic ist gut für die Protokollaggregation.
Du kommst morgens zur Arbeit und Elastic lügt.
Die erste Frage ist, warum Elastic ist? Fast sofort wurde klar - Master Nodes fielen. Sie koordinieren die Arbeit des gesamten Clusters und wenn sie fallen, reagiert der gesamte Cluster nicht mehr. Warum sind sie nicht aufgestanden? Vielleicht sollte es einen Autostart geben? Nach der Suche nach der Antwort haben wir festgestellt, dass die Plugin-Version nicht übereinstimmt. Warum sind Master Nodes überhaupt gefallen? Sie wurden von OOM Killer getötet. Dies ist auf Linux-Rechnern der Fall, die bei Speichermangel unnötige Prozesse schließen. Warum gibt es nicht genug Speicher? Weil der Update-Prozess gestartet wurde, der aus den Systemprotokollen folgt. Warum hat es früher funktioniert, aber jetzt nicht? Und da wir eine Woche zuvor neue Knoten hinzugefügt haben, benötigten Master-Knoten entsprechend mehr Speicher zum Speichern von Indizes und Cluster-Konfigurationen.
Die Fragen "warum?" helfen Sie, die Wurzel des Problems zu finden. In diesem Beispiel könnten wir den richtigen Pfad oft ausschalten, aber die vollständige Korrektur sieht folgendermaßen aus: Wir aktualisieren das Plugin, starten Dienste, erhöhen den Speicher und notieren uns für die Zukunft, dass wir beim nächsten Hinzufügen neuer Knoten zum Cluster sicherstellen müssen, dass auf dem Master genügend Speicher vorhanden ist Knoten
Durch die Anwendung dieser Regeln können Sie echte Probleme aufdecken, sich auf die Lösung dieser Probleme konzentrieren und zur Kommunikation beitragen. Aber es wäre noch besser, wenn diese Regeln ein System bilden würden. Und es gibt ein solches System, das als Debugging-Algorithmus bezeichnet wird.
Debugging-Algorithmus
Zum ersten Mal las ich über den Debugging-Algorithmus in John Robbins 'Buch Debugging-Anwendungen. Es beschreibt den Debugging-Prozess wie folgt:
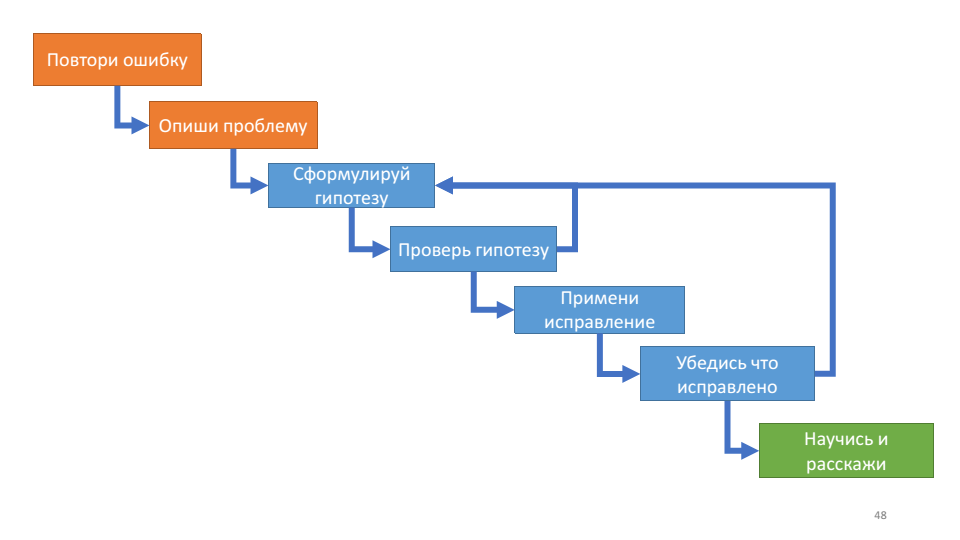
Dieser Algorithmus ist nützlich für seine innere Schleife - Arbeiten mit einer Hypothese.
Mit jeder Umdrehung des Zyklus können wir uns selbst überprüfen: Wissen wir mehr über das System oder nicht? Wenn wir Hypothesen aufstellen, prüfen, ob sie nicht funktionieren, wir nichts Neues über den Betrieb des Systems erfahren, ist es wahrscheinlich an der Zeit, sich zu erfrischen. Zwei aktuelle Fragen an dieser Stelle: Welche Hypothesen haben Sie getestet und welche Hypothese testen Sie jetzt?
Dieser Algorithmus stimmt sehr gut mit den Debugging-Regeln überein, über die wir oben gesprochen haben: Wiederholen Sie den Fehler - dies ist Ihr Fehler, beschreiben Sie das Problem - verstehen Sie das System, formulieren Sie eine Hypothese - teilen und erobern Sie, testen Sie die Hypothese - überprüfen Sie den Stecker, stellen Sie sicher, dass er behoben ist - fünf warum.
Ich habe ein gutes Beispiel für diesen Algorithmus. Eine Ausnahme bildete einer unserer Webdienste.
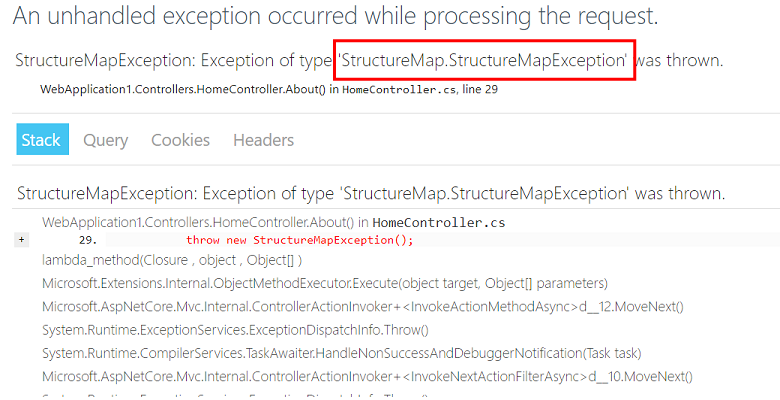
Unser erster Gedanke ist nicht unser Problem. Aber nach den Regeln ist dies immer noch unser Problem.
Wiederholen Sie zunächst den Fehler. Für jeweils tausend Anfragen gibt es ungefähr eine
StructureMapException , sodass wir das Problem reproduzieren können.
Zweitens versuchen wir, das Problem zu beschreiben: Wenn der Benutzer zu dem Zeitpunkt, zu dem StructureMap versucht, eine neue Abhängigkeit herzustellen, eine http-Anfrage für unseren Dienst stellt, tritt eine Ausnahme auf.
Drittens nehmen wir an, dass StructureMap ein Wrapper ist und etwas darin eine interne Ausnahme auslöst. Wir testen die Hypothese mit procdump.exe.
procdump.exe -ma -e -f StructureMap w3wp.exe
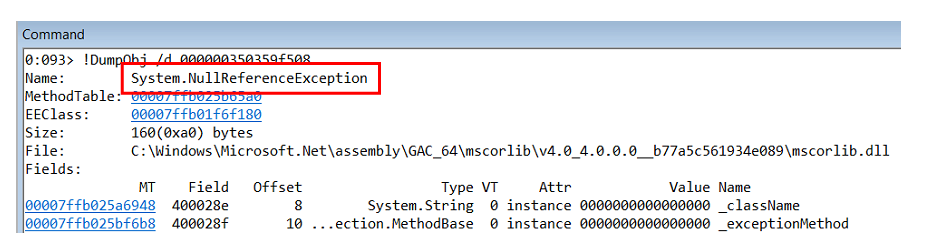
Es stellt sich heraus, dass im Inneren eine
NullReferenceException .
Wenn wir den Aufrufstapel dieser Ausnahme untersuchen, verstehen wir, dass dies innerhalb des Objekt-Builders in der StructureMap selbst geschieht.
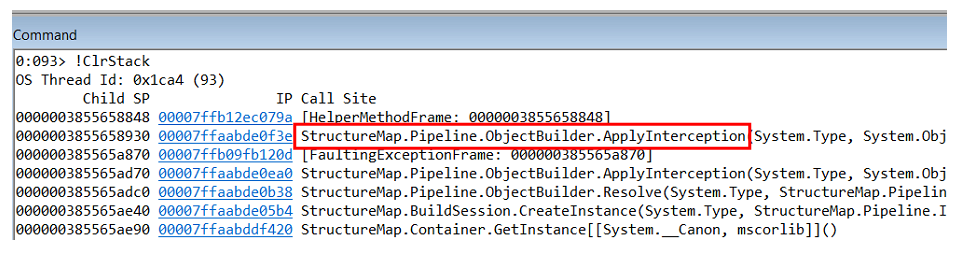
NullReferenceException ist jedoch nicht das Problem selbst, sondern die Konsequenz. Sie müssen verstehen, wo es auftritt und wer es generiert.
Wir stellen die folgende Hypothese auf: Aus irgendeinem Grund gibt unser Code eine Nullabhängigkeit zurück. Angesichts der Tatsache, dass sich in .Net alle Objekte im Speicher nacheinander befinden, werden die Objekte auf dem Heap, die vor der
NullReferenceException , wahrscheinlich auf den Code verweisen, der die Ausnahme
NullReferenceException hat.
In WinDbg gibt es einen Befehl - List Near Objects
!lno . Es zeigt, dass das Objekt, an dem wir interessiert sind, die Lambda-Funktion ist, die im folgenden Code verwendet wird.
public CompoundInterceptor FindInterceptor(Type type) { CompoundInterceptop interceptor; if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { lock (_locker) { if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { var interceptorArray = _interceptors.FindAll(i => i.MatchesType(type)); interceptor = new CompoundInterceptor(interceptorArray); _analyzedInterceptors.Add(type, interceptor); } } } return interceptor; }
In diesem Code prüfen wir zunächst, ob der Wert im
Dictionary in
_analyzedInterceptors ist. Wenn wir ihn nicht finden, fügen wir einen neuen Wert in die
lock .
Theoretisch kann dieser Code niemals null zurückgeben. Das Problem liegt hier jedoch in
_analyzedInterceptors , die ein reguläres
Dictionary in einer Umgebung mit mehreren Threads verwenden, kein
ConcurrentDictionary .
Die Wurzel des Problems wurde gefunden. Wir haben auf die neueste Version von StructureMap aktualisiert, bereitgestellt und sichergestellt, dass alles behoben wurde. Der letzte Schritt unseres Algorithmus ist „lernen und erzählen“. In unserem Fall war es eine Suche im Code aller
Dictionary , die im Schloss verwendet werden, und die Überprüfung, ob alle korrekt verwendet werden.
Der Debugging-Algorithmus ist also ein intuitiver Algorithmus, der erheblich Zeit spart. Er konzentriert sich auf die Hypothese - und dies ist das Wichtigste beim Debuggen.
Proaktives Debuggen
Im Kern beantwortet proaktives Debuggen die Frage "Was passiert, wenn ein Fehler auftritt?".
Die Bedeutung proaktiver Debugging-Techniken zeigt das Fehlerlebenszyklusdiagramm.
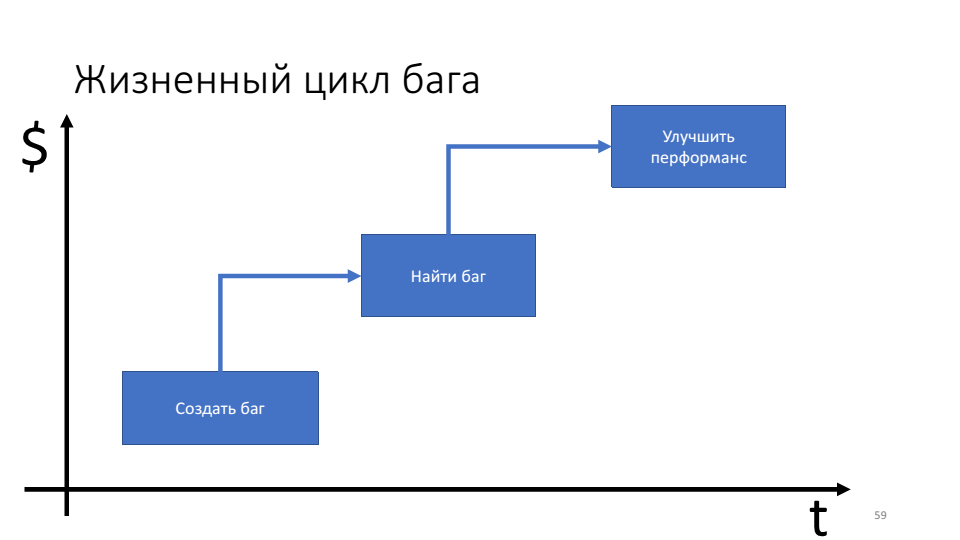
Das Problem ist, dass je länger der Fehler lebt, desto mehr Ressourcen (Zeit) wir dafür aufwenden.
Die Debugging-Regeln und der Debugging-Algorithmus konzentrieren uns auf den Moment, in dem der Fehler gefunden wird, und wir können herausfinden, was als nächstes zu tun ist. Tatsächlich möchten wir unseren Fokus zum Zeitpunkt der Erstellung des Fehlers verschieben. Ich bin der Meinung, dass wir das Minimum Debuggable Product (MDP) durchführen sollten, dh ein Produkt, das über die minimal erforderliche Infrastruktur für ein effizientes Debugging in der Produktion verfügt.
MDP besteht aus zwei Dingen: Fitnessfunktion und USE-Methode.
Fitnessfunktionen. Sie wurden von Neil Ford und Co-Autoren in dem Buch Building Evolutionary Architectures populär gemacht. Im Kern sehen Fitnessfunktionen laut den Autoren des Buches folgendermaßen aus: Es gibt eine Anwendungsarchitektur, die wir aus verschiedenen Winkeln schneiden können, wobei architektonische Eigenschaften wie
Wartbarkeit ,
Leistung usw. erhalten werden, und für jeden dieser Abschnitte müssen wir einen Test schreiben - Fitness -Funktion. Eine Fitnessfunktion ist also ein Architekturtest.
Bei MDP ist die Fitnessfunktion ein Debuggbarkeitstest. Sie können alles verwenden, was Sie möchten, um solche Tests zu schreiben: NUnit, MSTest und so weiter. Da das Debuggen jedoch häufig mit externen Tools funktioniert, werde ich anhand von Pester (Powershell Unit Testing Framework) als Beispiel demonstrieren. Das Plus hier ist, dass es gut mit der Kommandozeile funktioniert.
Innerhalb des Unternehmens stimmen wir beispielsweise zu, dass wir bestimmte Bibliotheken für die Protokollierung verwenden werden. Bei der Protokollierung werden bestimmte Muster verwendet. PDF-Zeichen sollten immer an den Symbolserver übergeben werden. Dies sind die Konventionen, die wir in unseren Tests testen werden.
Describe 'Debuggability' { It 'Contains line numbers in PDBs' { Get-ChildItem -Path . -Recurse -Include @("*.exe", "*. dll ") ` | ForEach-Object { &symchk.exe /v "$_" /s "\\network\" *>&1 } ` | Where-Object { $_ -like "*Line nubmers: TRUE*" } ` | Should -Not –BeNullOrEmpty } }
Dieser Test überprüft, ob alle PDF-Zeichen an den Symbolserver übergeben wurden und korrekt angegeben wurden, dh diejenigen, die Zeilennummern enthalten. Nehmen Sie dazu die kompilierte Version der Produktion, suchen Sie alle exe- und dll-Dateien und übergeben Sie alle diese Binärdateien über das Dienstprogramm syschk.exe, das im Paket Debugging-Tools für Windows enthalten ist. Das Dienstprogramm syschk.exe überprüft die Binärdatei mit dem Symbolserver und druckt einen Bericht darüber, wenn es dort eine PDF-Datei findet. Im Bericht suchen wir nach der Zeile „Zeilennummern: WAHR“. Und im Finale prüfen wir, ob das Ergebnis nicht „null oder leer“ ist.
Diese Tests müssen in eine kontinuierliche Bereitstellungspipeline integriert werden. Nachdem die Integrationstests und Komponententests bestanden wurden, werden die Fitnessfunktionen gestartet.
Ich werde ein weiteres Beispiel mit der Überprüfung der erforderlichen Bibliotheken im Code zeigen.
Describe 'Debuggability' { It 'Contains package for logging' { Get-ChildItem -Path . -Recurse -Name "packages.config" ` | ForEach-Object { Get-Content "$_" } ` | Where-Object { $_ -like "*nlog*" } ` | Should -Not –BeNullOrEmpty } }
Im Test nehmen wir alle packages.config-Dateien und versuchen, die darin enthaltenen nlog-Bibliotheken zu finden. In ähnlicher Weise können wir überprüfen, ob das Korrelations-ID-Feld innerhalb des nlog-Felds verwendet wird.
USE-Methoden. Das Letzte, woraus MDP besteht, sind die Metriken, die Sie sammeln müssen.
Ich werde am Beispiel der USE-Methode demonstrieren, die von Brendan Gregg populär gemacht wurde.
Die Idee ist einfach: Wenn der Code ein Problem aufweist, reichen drei Metriken aus: Auslastung (Sättigung), Fehler (Fehler), um zu verstehen, wo das Problem liegt.Einige Unternehmen, z. B. Circonus (sie überwachen Soft), erstellen ihre Dashboards in Form von festgelegten Metriken.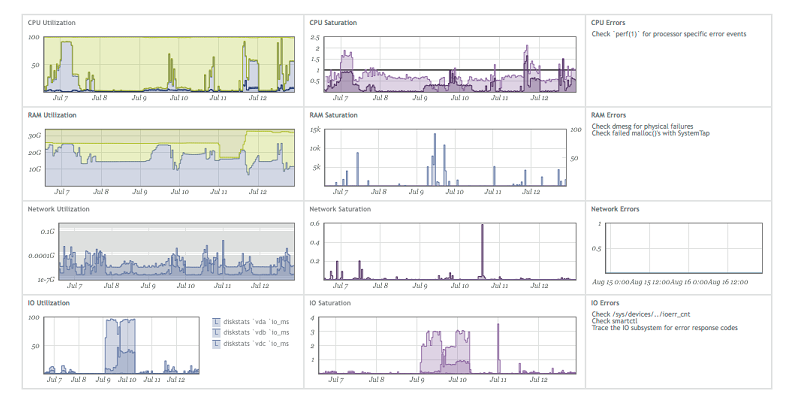 Wenn Sie sich beispielsweise den Speicher genauer ansehen, ist die Verwendung die Menge an freiem Speicher, die Sättigung die Anzahl der Festplattenzugriffe und Fehler alle aufgetretenen Fehler. Um Produkte für das Debuggen bequem zu machen, müssen Sie daher USE-Metriken für alle Funktionen und alle Teile des Subsystems erfassen.Wenn Sie eine Geschäftsfunktion verwenden, können Sie höchstwahrscheinlich drei Metriken darin unterscheiden:
Wenn Sie sich beispielsweise den Speicher genauer ansehen, ist die Verwendung die Menge an freiem Speicher, die Sättigung die Anzahl der Festplattenzugriffe und Fehler alle aufgetretenen Fehler. Um Produkte für das Debuggen bequem zu machen, müssen Sie daher USE-Metriken für alle Funktionen und alle Teile des Subsystems erfassen.Wenn Sie eine Geschäftsfunktion verwenden, können Sie höchstwahrscheinlich drei Metriken darin unterscheiden:- Verwendung - Anforderungsverarbeitungszeit.
- Die Sättigung ist die Länge der Warteschlange.
- Fehler - alle Ausnahmesituationen.
Schauen wir uns als Beispiel ein Diagramm der Anzahl der verarbeiteten Anforderungen an, die eines unserer Systeme stellt. Wie Sie sehen, hat der Dienst in den letzten drei Stunden keine Anfragen bearbeitet.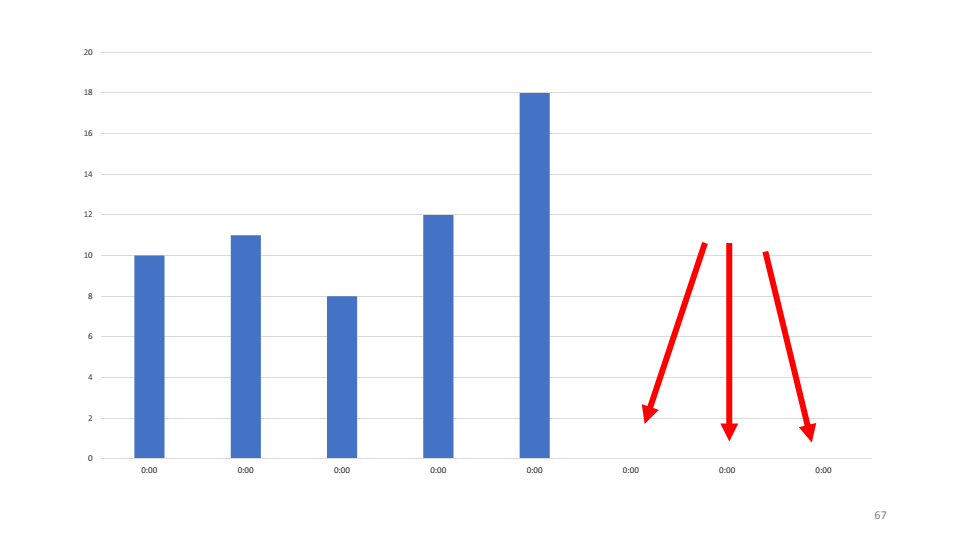 Die erste Hypothese, die wir aufgestellt haben, ist, dass der Dienst gesunken ist und wir ihn neu starten müssen. Bei der Überprüfung stellt sich heraus, dass der Dienst funktioniert und 4-5% der CPU verbraucht.
Die erste Hypothese, die wir aufgestellt haben, ist, dass der Dienst gesunken ist und wir ihn neu starten müssen. Bei der Überprüfung stellt sich heraus, dass der Dienst funktioniert und 4-5% der CPU verbraucht. Die zweite Hypothese ist, dass ein Fehler in den Dienst fällt, den wir nicht sehen. Wir werden das Dienstprogramm etrace verwenden.
Die zweite Hypothese ist, dass ein Fehler in den Dienst fällt, den wir nicht sehen. Wir werden das Dienstprogramm etrace verwenden. etrace --kernel Process ^ --where ProcessName=Ex5-Service ^ --clr Exception
Mit dem Dienstprogramm können Sie ETW-Ereignisse in Echtzeit abonnieren und auf dem Bildschirm anzeigen.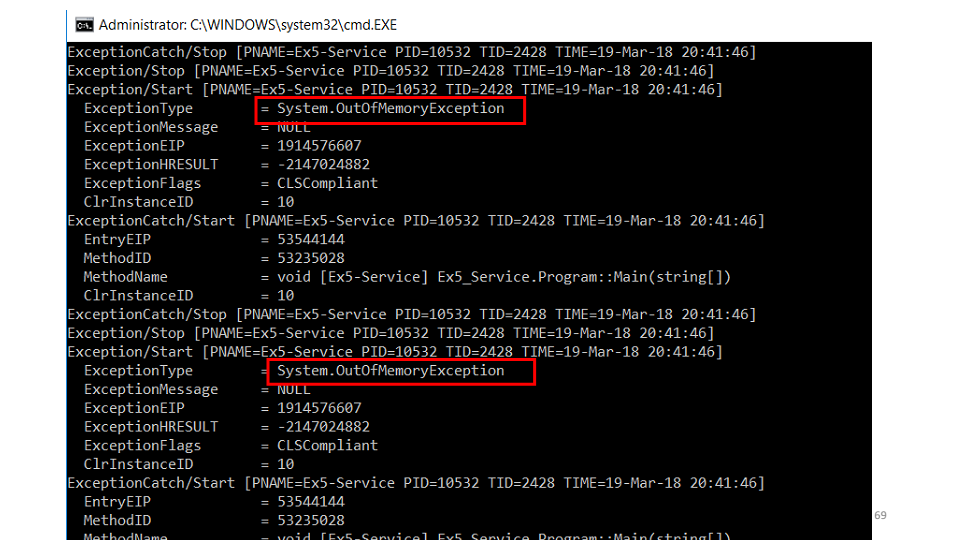 Wir sehen, dass es fällt
Wir sehen, dass es fällt OutOfMemoryException. Aber die zweite Frage, warum ist es nicht in den Protokollen? Die Antwort ist schnell - wir fangen sie ab, versuchen den Speicher aufzuräumen, warten ein bisschen und beginnen wieder zu arbeiten. while (ShouldContinue()) { try { Do(); } catch (OutOfMemoryException) { Thread.Sleep(100); GC.CollectionCount(2); GC.WaitForPendingFinalizers(); } }
Die nächste Hypothese ist, dass jemand die gesamte Erinnerung auffrisst. Laut Speicherauszug befinden sich die meisten Objekte im Cache. public class Cache { private static ConcurrentDictionary<int, String> _items = new ... private static DateTime _nextClearTime = DateTime.UtcNow; public String GetFromCache(int key) { if (_nextClearTime < DateTime.UtcNow) { _nextClearTime = DateTime.UtcNow.AddHours(1); _items.Clear(); } return _items[key]; } }
Der Code zeigt, dass der Cache stündlich geleert werden sollte. Aber die Erinnerung war nicht genug, sie erreichten nicht einmal die Reinigung. Schauen wir uns ein Beispiel für die USE-Cache-Metrik an.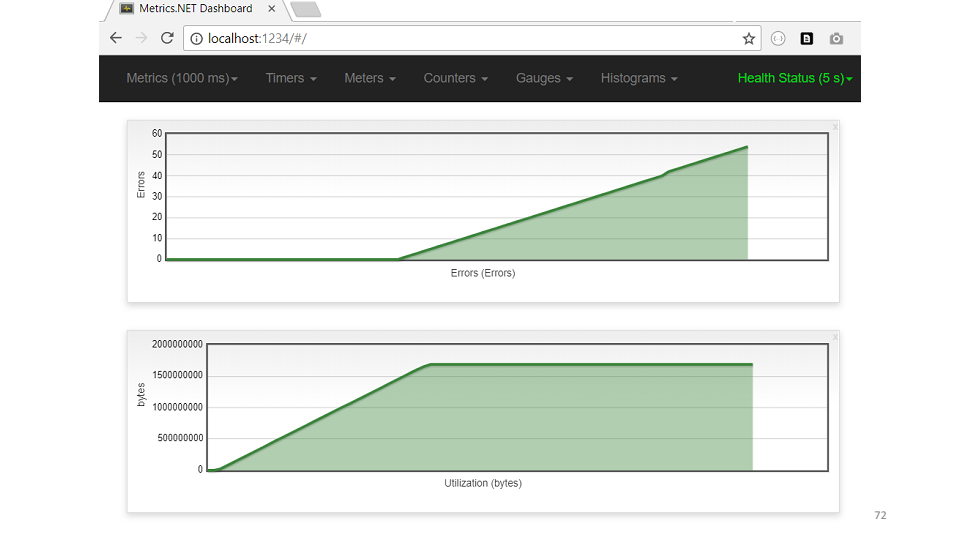 Laut Zeitplan ist es sofort sichtbar - der Speicher hat zugenommen, Fehler haben sofort begonnen.Also Schlussfolgerungen darüber, was proaktives Debuggen ist.
Laut Zeitplan ist es sofort sichtbar - der Speicher hat zugenommen, Fehler haben sofort begonnen.Also Schlussfolgerungen darüber, was proaktives Debuggen ist.- — . , , — . — , -. , .
- . ; Exception , , - .
- Minimum Debuggable Product — , .
, ?
- .
- .
- .
Diesmal ist Jon Skeet der Sponsor unserer Anzeige. Auch wenn Sie nicht für den neuen DotNext nach Moskau fahren , ist das Video einen Blick wert (John hat sich sehr bemüht).