Hinweis perev. : Der Autor des Originalartikels, Nicolas Leiva, ist ein Lösungsarchitekt von Cisco, der beschlossen hat, seinen Kollegen, Netzwerkingenieuren, die Funktionsweise des Kubernetes-Netzwerks von innen mitzuteilen. Zu diesem Zweck untersucht er die einfachste Konfiguration im Cluster und nutzt dabei aktiv den gesunden Menschenverstand, sein Wissen über Netzwerke und Standard-Linux / Kubernetes-Dienstprogramme. Es stellte sich voluminös heraus, aber sehr deutlich.
Zusätzlich zu der Tatsache, dass Kelsey Hightowers
Kubernetes The Hard Way- Handbuch nur funktioniert (
sogar unter AWS! ),
Gefiel mir, dass das Netzwerk sauber und einfach gehalten wurde. Dies ist eine großartige Gelegenheit, um beispielsweise die Rolle der Container Network Interface (
CNI ) zu verstehen. Trotzdem möchte ich hinzufügen, dass das Kubernetes-Netzwerk eigentlich nicht sehr intuitiv ist, insbesondere für Anfänger ... und vergessen Sie auch nicht, dass es
einfach kein Netzwerk für Container gibt.
Obwohl es zu diesem Thema bereits gute Materialien gibt (siehe Links
hier ), konnte ich kein solches Beispiel finden, dass ich alles Notwendige mit den Schlussfolgerungen der Teams kombinieren würde, die Netzwerktechniker lieben und hassen, um zu demonstrieren, was tatsächlich hinter den Kulissen passiert. Aus diesem Grund habe ich beschlossen, Informationen aus vielen Quellen zu sammeln. Ich hoffe, dies hilft und Sie verstehen besser, wie alles miteinander verbunden ist. Dieses Wissen ist nicht nur wichtig, um sich selbst zu testen, sondern auch, um die Diagnose von Problemen zu vereinfachen. Sie können dem Beispiel in Ihrem Cluster von
Kubernetes The Hard Way folgen: Alle IP-Adressen und Einstellungen werden von dort übernommen (Stand der Commits für Mai 2018, bevor
Nabla-Container verwendet werden ).
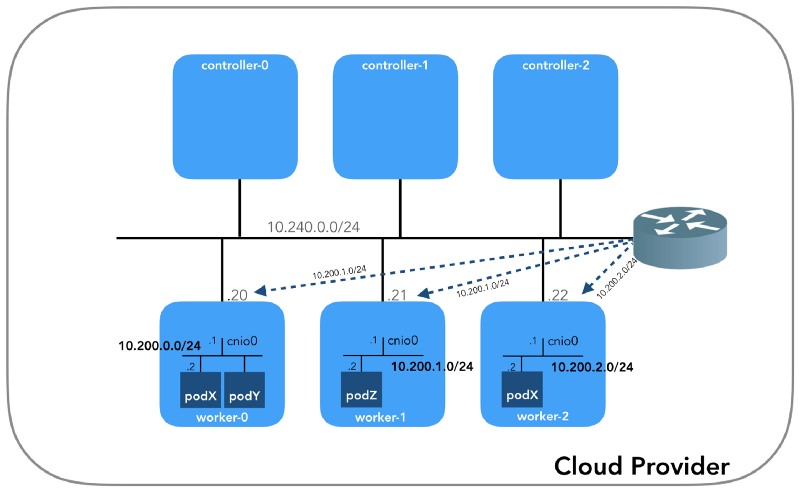
Und wir werden am Ende beginnen, wenn wir drei Controller und drei Arbeitsknoten haben:
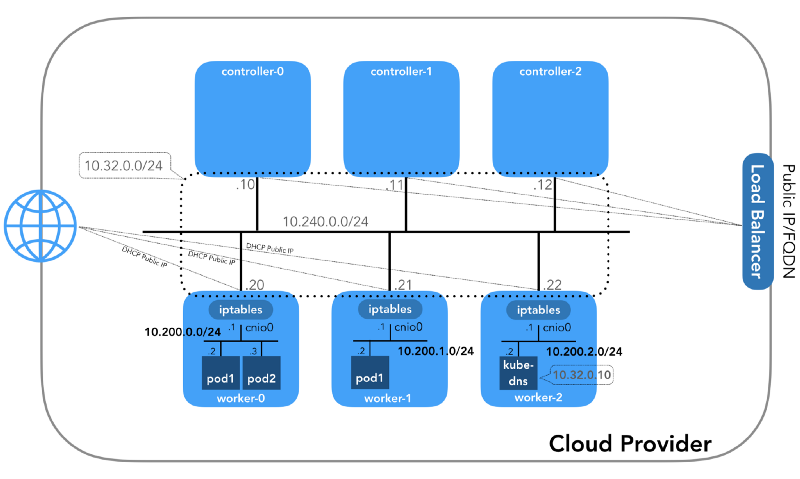
Sie können feststellen, dass es hier auch mindestens drei private Subnetze gibt! Ein wenig Geduld, und sie werden alle berücksichtigt. Denken Sie daran, dass wir uns zwar auf sehr spezifische IP-Präfixe beziehen, diese jedoch einfach aus
Kubernetes The Hard Way stammen , sodass sie nur lokale Bedeutung haben und Sie gemäß
RFC 1918 einen anderen Adressblock für Ihre Umgebung auswählen können. Für den Fall von IPv6 wird es einen separaten Blog-Artikel geben.
Host-Netzwerk (10.240.0.0/24)
Dies ist ein internes Netzwerk, zu dem alle Knoten gehören. Definiert durch das
--private-network-ip in
GCP oder die Option
--private-ip-address in
AWS beim
--private-ip-address Computerressourcen.
Initialisieren von Controller-Knoten in GCP
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
Initialisieren von Controller-Knoten in AWS
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
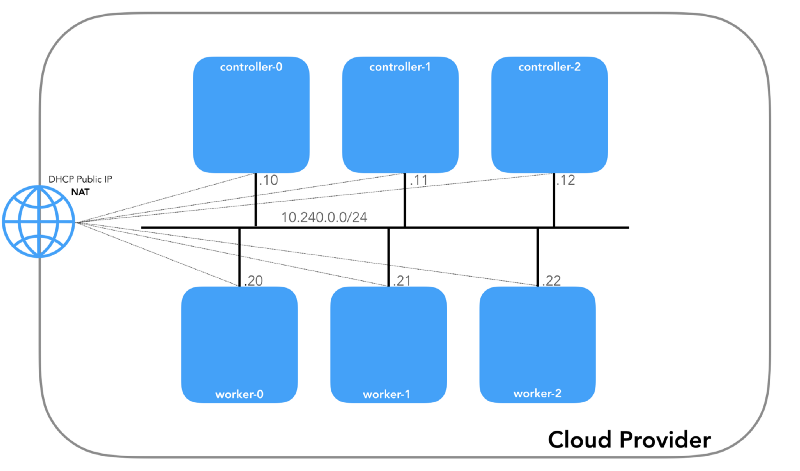
Jede Instanz hat zwei IP-Adressen: privat vom Host-Netzwerk (Controller -
10.240.0.1${i}/24 , Worker -
10.240.0.2${i}/24 ) und eine öffentliche, vom Cloud-Anbieter festgelegte, über die wir später sprechen werden wie man zu
NodePorts .
Gcp
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
Aws
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
Alle Knoten müssen in der Lage sein, sich gegenseitig zu pingen, wenn die
Sicherheitsrichtlinien korrekt sind (und wenn
ping auf dem Host installiert
ping ).
Herdnetzwerk (10.200.0.0/16)
Dies ist das Netzwerk, in dem die Pods leben. Jeder Arbeitsknoten verwendet ein Subnetz dieses Netzwerks. In unserem Fall ist
POD_CIDR=10.200.${i}.0/24 für
worker-${i} .
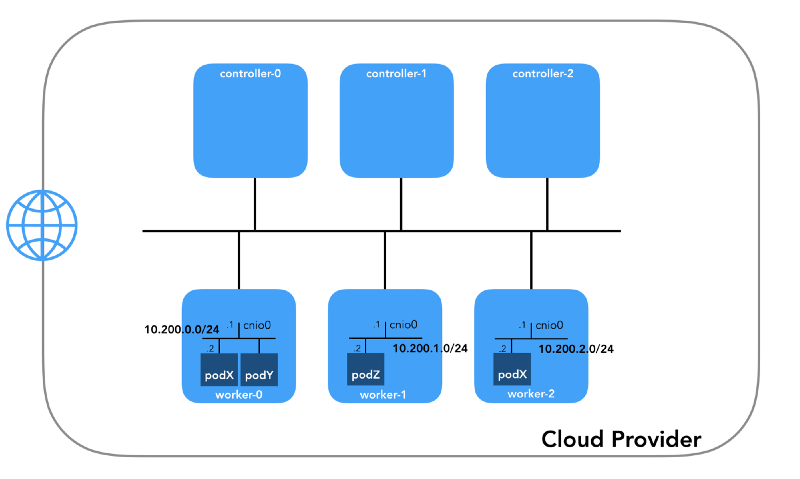
Um zu verstehen, wie alles konfiguriert ist, treten Sie einen Schritt zurück und sehen Sie sich
das Kubernetes-Netzwerkmodell an , für das Folgendes erforderlich ist:
- Alle Container können ohne Verwendung von NAT mit anderen Containern kommunizieren.
- Alle Knoten können mit allen Containern kommunizieren (und umgekehrt), ohne NAT zu verwenden.
- Die IP, die der Container sieht, muss mit der IP-Adresse übereinstimmen, die andere sehen.
All dies kann auf viele Arten implementiert werden, und Kubernetes übergibt das Netzwerk-Setup an das
CNI-Plugin .
„Das CNI-Plugin ist dafür verantwortlich, dem Netzwerk-Namespace des Containers eine Netzwerkschnittstelle hinzuzufügen (z. B. ein Ende eines veth-Paares ) und die erforderlichen Änderungen auf dem Host vorzunehmen (z. B. das zweite Ende von veth mit einer Bridge zu verbinden). Dann muss er eine IP-Schnittstelle zuweisen und die Routen gemäß dem Abschnitt IP-Adressverwaltung konfigurieren, indem er das gewünschte IPAM-Plugin aufruft. “ (aus der Spezifikation der Containernetzwerkschnittstelle )
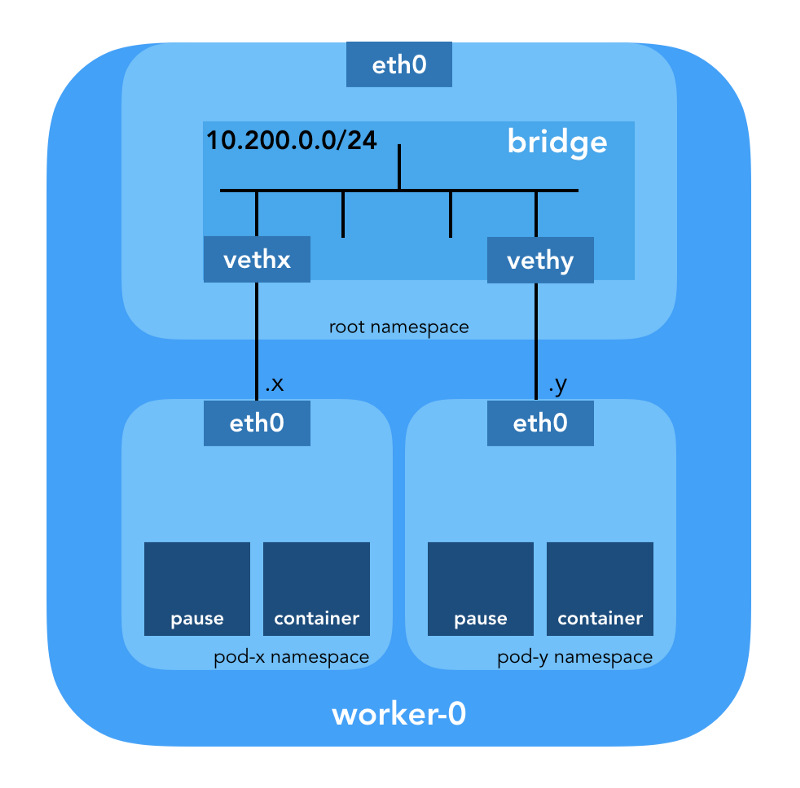
Netzwerk-Namespace
„Der Namespace verpackt die globale Systemressource in eine Abstraktion, die für Prozesse in diesem Namespace so sichtbar ist, dass sie über eine eigene isolierte Instanz der globalen Ressource verfügen. Änderungen in der globalen Ressource sind für andere in diesem Namespace enthaltene Prozesse sichtbar, für andere Prozesse jedoch nicht. “ ( von der Namespaces-Manpage )
Linux bietet sieben verschiedene Namespaces (
Cgroup ,
IPC ,
Network ,
Mount ,
PID ,
User ,
UTS ). Netzwerk-Namespaces (
CLONE_NEWNET ) definieren die Netzwerkressourcen, die dem Prozess zur Verfügung stehen: „Jeder Netzwerk-Namespace verfügt über eigene Netzwerkgeräte, IP-Adressen, IP-Routing-Tabellen,
/proc/net Verzeichnis, Portnummern usw.“
( aus dem Artikel „ Namespaces in Betrieb “) .
Virtuelle Ethernet-Geräte (Veth)
„Ein virtuelles Netzwerkpaar (veth) bietet eine Abstraktion in Form einer„ Pipe “, mit der Tunnel zwischen Netzwerk-Namespaces oder eine Brücke zu einem physischen Netzwerkgerät in einem anderen Netzwerkbereich erstellt werden können. Wenn der Namespace freigegeben wird, werden alle darin enthaltenen Geräte zerstört. “ (von der Manpage der Netzwerk-Namespaces )
Gehen Sie zu Boden und sehen Sie, wie sich alles auf den Cluster bezieht. Erstens sind
Netzwerk-Plugins in Kubernetes vielfältig, und CNI-Plugins sind eines davon (
warum nicht CNM? ).
Kubelet auf jedem Knoten teilt der Container-
Laufzeit mit, welches
Netzwerk-Plug-In verwendet werden soll. Die Container Network Interface (
CNI ) befindet sich zwischen der Container-Laufzeit und der Netzwerkimplementierung. Und schon baut das CNI-Plugin das Netzwerk auf.
„Das CNI-Plugin wird ausgewählt, indem die Befehlszeilenoption --network-plugin=cni an Kubelet übergeben wird. Kubelet liest die Datei aus --cni-conf-dir (der Standardwert ist /etc/cni/net.d ) und verwendet die CNI-Konfiguration aus dieser Datei, um das Netzwerk für jede Datei zu konfigurieren. " (aus den Anforderungen des Netzwerk-Plugins )
Die realen Binärdateien des CNI-Plugins befinden sich in
-- cni-bin-dir (der Standardwert ist
/opt/cni/bin ).
Bitte beachten Sie, dass die
kubelet.service von
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
Zunächst erstellt Kubernetes einen Netzwerk-Namespace für den Herd, noch bevor Plugins aufgerufen werden. Dies wird mithilfe des speziellen
pause implementiert, der „als„ übergeordneter Container “für alle Herdcontainer dient“
(aus dem Artikel „ Der allmächtige Pausencontainer “) . Kubernetes führt dann das CNI-Plugin aus, um den
pause an das Netzwerk anzuhängen. Alle Pod-Container verwenden den
netns dieses
netns .
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
Die verwendete
CNI-Konfiguration gibt die Verwendung des
bridge Plugins zum Konfigurieren der Linux (L2) -Softwarebrücke im Root-Namespace
cnio0 (der
Standardname ist
cni0 ) an, der als Gateway fungiert (
"isGateway": true ).

Ein veth-Paar wird ebenfalls konfiguriert, um den Herd mit der neu erstellten Brücke zu verbinden:
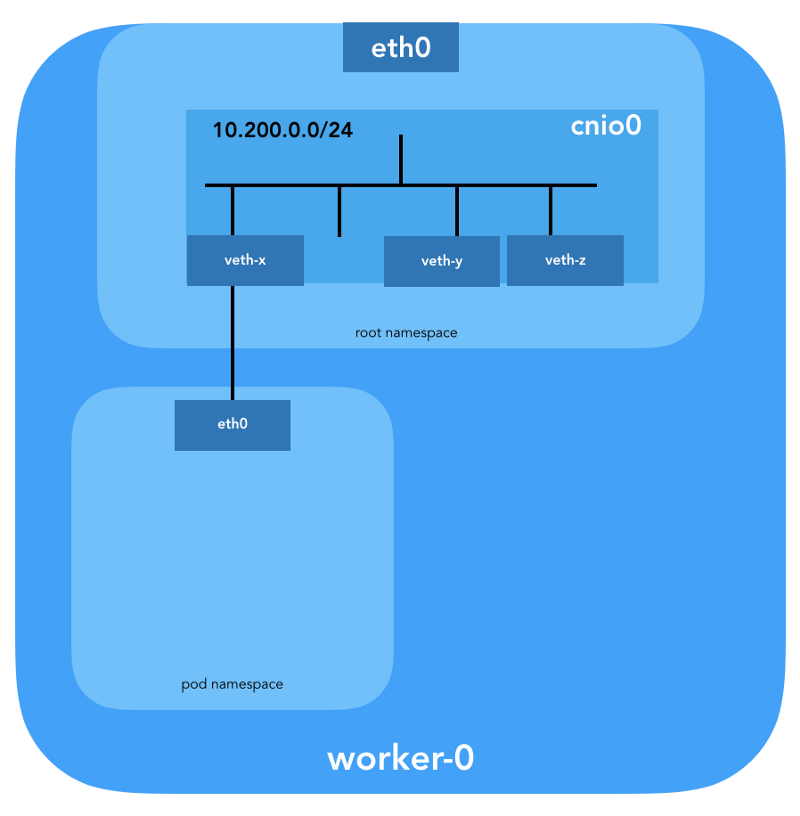
Um L3-Informationen wie IP-Adressen zuzuweisen, wird das
IPAM-Plugin (
ipam ) aufgerufen. In diesem Fall wird der
host-local Typ verwendet, "der den Status lokal im Hostdateisystem speichert, wodurch die Eindeutigkeit der IP-Adressen auf einem Host sichergestellt wird"
(aus der host-local ) . Das IPAM-Plugin gibt diese Informationen an das vorherige Plugin (
bridge ) zurück, sodass alle in der Konfiguration angegebenen Routen konfiguriert werden können (
"routes": [{"dst": "0.0.0.0/0"}] ). Wenn
gw nicht angegeben ist,
wird es aus dem Subnetz übernommen . Die Standardroute wird auch im Netzwerk-Namespace des Herdes konfiguriert und zeigt auf die Bridge (die als erstes IP-Subnetz des Herdes konfiguriert ist).
Und das letzte wichtige Detail: Wir haben Maskerading (
"ipMasq": true ) für den Datenverkehr aus dem
"ipMasq": true angefordert. Wir brauchen NAT hier nicht wirklich, aber dies ist die Konfiguration in
Kubernetes The Hard Way . Der Vollständigkeit halber muss ich daher erwähnen, dass die Einträge in den
iptables bridge Plugins für dieses spezielle Beispiel konfiguriert sind. Alle Pakete vom Herd, deren Empfänger nicht im Bereich
224.0.0.0/4 , befinden
sich hinter NAT , was die Anforderung "Alle Container können mit jedem anderen Container ohne Verwendung von NAT kommunizieren" nicht ganz erfüllt. Nun, wir werden beweisen, warum NAT nicht benötigt wird ...

Herdführung
Jetzt können wir die Pods anpassen. Schauen wir uns alle Netzwerkbereiche der Namen eines der Arbeitsknoten an und analysieren Sie einen davon, nachdem Sie
von hier aus die Bereitstellung von
nginx haben . Wir werden
lsns mit der Option
-t , um den gewünschten Typ des Namespace (d. H.
net ) auszuwählen:
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
Mit der Option
-i zu
ls können wir ihre Inode-Nummern finden:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Sie können auch alle Netzwerk-Namespaces mit
ip netns :
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
Um alle Prozesse
cni-912bcc63–712d-1c84–89a7–9e10510808a0 , die im Netzwerkbereich
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 ) ausgeführt werden, können Sie beispielsweise den folgenden Befehl ausführen:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
Es ist zu sehen, dass wir zusätzlich zur
pause in diesem Pod Nginx gestartet haben. Der
pause teilt die
net und
ipc Namespaces mit allen anderen Pod-Containern. Erinnern Sie sich an die PID aus
pause - 27255; wir werden darauf zurückkommen.
Nun wollen wir sehen, was
kubectl über diesen Pod erzählt:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
Weitere Details:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
Wir sehen den Namen des Pods -
nginx-65899c769f-wxdx6 - und die ID eines seiner Container (
nginx ), aber über die
pause nichts gesagt. Graben Sie einen tieferen Arbeitsknoten, um alle Daten abzugleichen. Denken Sie daran, dass
Kubernetes The Hard Way Docker nicht verwendet. Einzelheiten zum Container finden Sie im Konsolen-Dienstprogramm
Containerd - ctr
(siehe auch Artikel " Integration von Containerd mit Kubernetes, Ersetzen von Docker, produktionsbereit " - ca. Übertragung ). ::
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
Wenn Sie den Containerd-
k8s.io (
k8s.io ) kennen, können Sie die
nginx Container-ID
k8s.io :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
... und auch
pause :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
Die
nginx Container-ID mit der Endung
…983c7 stimmt mit der von
kubectl . Mal sehen, ob wir herausfinden können, welcher
pause zum
nginx Pod gehört:
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
Denken Sie daran, dass Prozesse mit PID 27331 und 27355 im Netzwerk-Namespace
cni-912bcc63–712d-1c84–89a7–9e10510808a0 werden.
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
... und:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
Jetzt wissen wir sicher, welche Container in diesem Pod (
nginx-65899c769f-wxdx6 ) und im Netzwerk-Namespace (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ) ausgeführt werden:
- nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ); - Pause (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 ).

Wie ist dies unter (
nginx-65899c769f-wxdx6 ) mit dem Netzwerk verbunden? Wir verwenden die zuvor von
pause empfangene PID 27255, um Befehle in ihrem Netzwerk-Namespace
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Für diese Zwecke verwenden wir
nsenter mit der Option
-t , die die Ziel-PID definiert, und
-n ohne eine Datei anzugeben, um in den Netzwerk-Namespace des
nsenter zu gelangen (27255). Hier ist, was
ip link show sagen wird:
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
... und
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Dies bestätigt, dass die zuvor über
kubectl get pod erhaltene IP-Adresse auf der
eth0 Schnittstelle konfiguriert ist. Diese Schnittstelle ist Teil eines
Veth-Paares , von dem sich ein Ende im Herd und das andere im Root-Namespace befindet. Um die Schnittstelle des zweiten Endes herauszufinden, verwenden wir
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
Wir sehen, dass der
ifindex Festes 7 ist. Überprüfen Sie, ob er sich im Root-Namespace befindet. Dies kann über den
ip link :
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
Um sicherzugehen, lassen Sie uns sehen:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
Großartig, jetzt ist mit dem virtuellen Link alles klar.
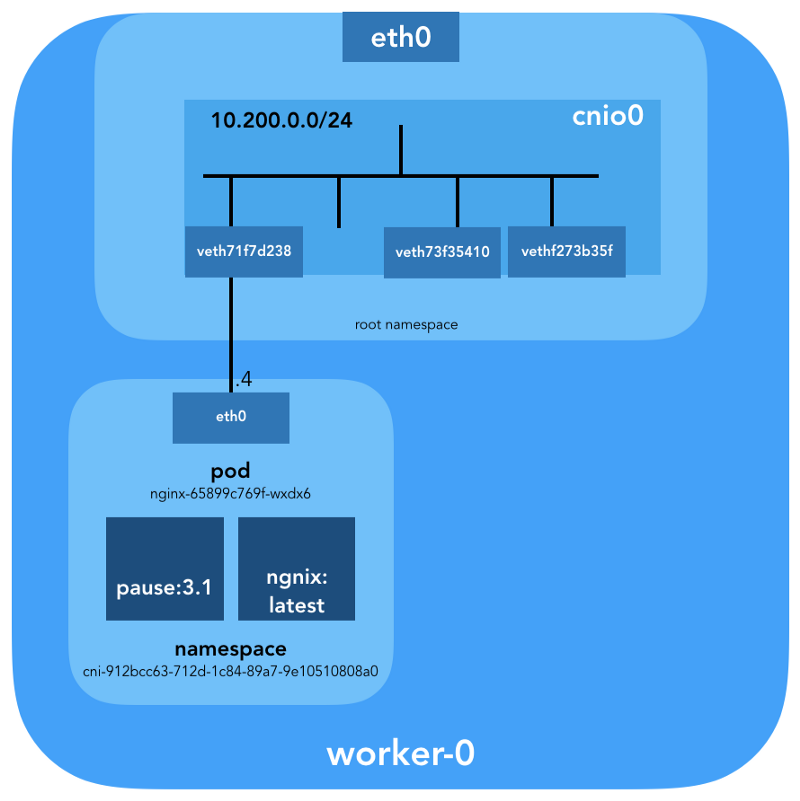
brctl Sie uns mit
brctl sehen, wer noch mit der Linux-Bridge verbunden ist:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
Das Bild sieht also wie folgt aus:
Routing-Prüfung
Wie leiten wir den Verkehr tatsächlich weiter? Schauen wir uns die Routing-Tabelle im Netzwerk-Namespace-Pod an:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
Zumindest wissen wir, wie man zum Root-Namespace kommt (
default via 10.200.0.1 ). Nun sehen wir uns die Host-Routing-Tabelle an:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
Wir wissen, wie Pakete an einen VPC-Router weitergeleitet werden (VPC
verfügt über einen „impliziten“ Router, der
normalerweise eine zweite Adresse aus dem Haupt-IP-Adressraum des Subnetzes hat). Jetzt: Weiß der VPC-Router, wie er zum Netzwerk jedes Herdes gelangt? Nein, das tut er nicht. Daher wird davon ausgegangen, dass die Routen vom CNI-Plug-In oder
manuell (wie im Handbuch) konfiguriert werden. Anscheinend macht das
AWS CNI-Plugin genau das für uns bei AWS. Denken Sie daran, dass es
viele CNI-Plugins gibt , und wir betrachten ein Beispiel für eine
einfache Netzwerkkonfiguration :
Tiefes Eintauchen in NAT
kubectl create -f busybox.yaml zwei identische
busybox Container mit Replication Controller:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
Wir bekommen:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
Pings von einem Container zum anderen sollten erfolgreich sein:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
Um die Bewegung des Datenverkehrs zu verstehen, können Sie Pakete mit
tcpdump oder
conntrack :
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
Die Quell-IP von Pod 10.200.0.21 wird in die IP-Adresse des Hosts 10.240.0.20 übersetzt.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
In iptables können Sie sehen, dass die Anzahl steigt:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
Wenn Sie andererseits
"ipMasq": true aus der CNI-Plugin-Konfiguration entfernen, sehen Sie Folgendes (dieser Vorgang wird ausschließlich zu Bildungszwecken ausgeführt - wir empfehlen, die Konfiguration in einem funktionierenden Cluster nicht zu ändern!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
Ping sollte noch bestehen:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
Und in diesem Fall - ohne NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Daher haben wir überprüft, dass "alle Container ohne Verwendung von NAT mit anderen Containern kommunizieren können".
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Clusternetzwerk (10.32.0.0/24)
Möglicherweise haben Sie im
busybox Beispiel
busybox dass die der
busybox zugewiesenen IP-Adressen jeweils
busybox waren. Was wäre, wenn wir diese Container für die Kommunikation von anderen Herden zur Verfügung stellen wollten? Man könnte die aktuellen IP-Adressen des Pods nehmen, aber sie werden sich ändern. Aus diesem Grund müssen Sie die Serviceressource konfigurieren, die Anfragen an viele kurzlebige Herde weiterleitet.
"Service in Kubernetes ist eine Abstraktion, die den logischen Satz von Herden und die Richtlinien definiert, über die auf sie zugegriffen werden kann." (aus der Dokumentation zu Kubernetes Services )
Es gibt verschiedene Möglichkeiten, einen Dienst zu veröffentlichen. Der Standardtyp ist
ClusterIP , der die IP-Adresse aus dem CIDR-Block des Clusters festlegt (d. h. nur über den Cluster zugänglich). Ein solches Beispiel ist das in Kubernetes The Hard Way konfigurierte DNS-Cluster-Add-on.
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
kubectl zeigt, dass der
Service Endpunkte
kubectl und übersetzt:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
Wie genau? .. wieder
iptables . Lassen Sie uns die für dieses Beispiel erstellten Regeln durchgehen. Ihre vollständige Liste kann mit dem Befehl
iptables-save angezeigt werden.
Sobald Pakete vom Prozess erstellt werden (
OUTPUT ) oder auf der Netzwerkschnittstelle ankommen (
PREROUTING ), durchlaufen sie die folgenden
iptables Ketten:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
Die folgenden Ziele entsprechen TCP-Paketen, die um 10.32.0.10 an den 53. Port gesendet und mit dem 53. Port an den Empfänger 10.200.0.27 übertragen werden:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
Gleiches gilt für UDP-Pakete (Empfänger 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
Es gibt andere Arten von
Services in Kubernetes. Insbesondere
NodePort Kubernetes The Hard Way über
NodePort - siehe
Smoke Test: Services .
kubectl expose deployment nginx --port 80 --type NodePort
NodePort veröffentlicht den Dienst unter der IP-Adresse jedes Knotens und platziert ihn an einem statischen Port (er heißt
NodePort ).
NodePort kann
NodePort von außerhalb des Clusters zugegriffen werden. Sie können den dedizierten Port (in diesem Fall - 31088) mit
kubectl :
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
Under ist jetzt im Internet unter
http://${EXTERNAL_IP}:31088/ . Hier ist
EXTERNAL_IP die öffentliche IP-Adresse
einer Arbeitsinstanz . In diesem Beispiel habe ich die öffentliche IP-Adresse von
worker-0 verwendet . Die Anforderung wird von einem Host mit einer internen IP-Adresse von 10.240.0.20 empfangen (der Cloud-Anbieter ist an öffentlichem NAT beteiligt). Der Dienst wird jedoch tatsächlich auf einem anderen Host gestartet (
Worker-1 , erkennbar an der IP-Adresse des Endpunkts - 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
Das Paket wird von
Worker-0 an
Worker-1 gesendet, wo es seinen Empfänger findet:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
Ist eine solche Schaltung ideal? Vielleicht nicht, aber es funktioniert. In diesem Fall lauten die programmierten
iptables Regeln wie folgt:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
Mit anderen Worten, die Adresse für den Empfänger von Paketen mit Port 31088 wird am 10.200.1.18 gesendet. Der Port sendet auch von 31088 bis 80.
Wir haben keinen anderen
LoadBalancer -
LoadBalancer - der den Dienst mithilfe eines Load Balancers eines Cloud-Anbieters öffentlich verfügbar macht, aber der Artikel hat sich bereits als umfangreich herausgestellt.
Fazit
Es scheint, dass es viele Informationen gibt, aber wir haben nur die Spitze des Eisbergs berührt. In Zukunft werde ich über IPv6, IPVS, eBPF und einige interessante aktuelle CNI-Plugins sprechen.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: