
Heute hat endlich das Hauptprogramm der Konferenz begonnen. Die Akzeptanzrate betrug in diesem Jahr nur 8%, d.h. muss das Beste vom Besten vom Besten sein. Angewandte und Forschungsströme sind klar voneinander getrennt, und es gibt mehrere getrennte verwandte Aktivitäten. Angewandte Streams sehen interessanter aus, dort stammen Berichte hauptsächlich von Majors (Google, Amazon, Alibaba usw.). Ich erzähle Ihnen von den Aufführungen, an denen ich teilgenommen habe.
Daten für immer
Der Tag begann mit einer ausreichend langen Präsentation, dass die Daten nützlich sein und für das Gute verwendet werden sollten. Ein
Professor an der University of California
spricht (es ist erwähnenswert, dass es an der KDD viele Frauen gibt, sowohl unter Studenten als auch unter Sprechern). All dies wird in der Abkürzung FATES ausgedrückt:
- Fairness - keine Vorurteile bei Modellprognosen, alles ist geschlechtsneutral und tolerant.
- Rechenschaftspflicht - Es muss jemanden oder etwas geben, der für die von der Maschine getroffenen Entscheidungen verantwortlich ist.
- Transparenz - Transparenz und Erklärbarkeit von Entscheidungen.
- Ethik - Bei der Arbeit mit Daten sollte ein besonderer Schwerpunkt auf Ethik und Datenschutz liegen.
- Sicherheit - Das System muss sicher (nicht schädlich) und geschützt (beständig gegen manipulative Einflüsse von außen) sein.
Dieses Manifest drückt leider eher einen Wunsch aus und ist schwach mit der Realität korreliert. Das Modell ist nur dann politisch korrekt, wenn alle Zeichen entfernt werden. Die Verantwortung, auf eine bestimmte Person zu übertragen, ist immer sehr schwierig. Je weiter sich der DS entwickelt, desto schwieriger ist es zu interpretieren, was im Modell vor sich geht. In Bezug auf Ethik und Datenschutz gab es am ersten Tag einige gute Beispiele, aber ansonsten werden die Daten oft recht frei behandelt.
Nun, man kann nur zugeben, dass moderne Modelle oft nicht sicher sind (ein Autopilot kann ein Auto mit einem Fahrer über Bord werfen) und nicht geschützt sind (Sie können Beispiele aufgreifen, die die Arbeit eines neuronalen Netzwerks unterbrechen, ohne zu wissen, wie das Netzwerk funktioniert). Eine interessante aktuelle Arbeit von
DeepExplore : Ein System zur Suche nach Schwachstellen in neuronalen Netzen erzeugt unter anderem Bilder, die den Autopiloten in die falsche Richtung lenken.

Das Folgende ist eine weitere Definition von Data Science als „DS ist das Studium des Extrahierens von Wertformdaten“. Im Prinzip ziemlich gut. Zu Beginn der Rede erwähnte der Redner ausdrücklich, dass DS Daten häufig erst ab dem Moment der Analyse betrachtet, während der gesamte Lebenszyklus viel breiter ist, was sich unter anderem in der Definition widerspiegelte.
Nun, es gab einige Beispiele für Laborarbeiten.
Wir werden erneut die Aufgabe analysieren, den Einfluss vieler Faktoren auf das Ergebnis zu bewerten, jedoch nicht von der Position der Werbung aus, sondern allgemein. Es gibt einen
Artikel, der noch nicht veröffentlicht wurde. Betrachten Sie zum Beispiel die Frage, welche Schauspieler für den Film ausgewählt werden sollen, um eine gute Abendkasse zu sammeln. Wir analysieren die Schauspiellisten der Filme mit den höchsten Einnahmen und versuchen, den Beitrag jedes einzelnen Schauspielers vorherzusagen. Aber! Es gibt sogenannte
Störfaktoren , die beeinflussen, wie effektiv ein Schauspieler sein wird (zum Beispiel wird Stallone in einem Thrash-Action-Film gut abschneiden, aber nicht in einer romantischen Komödie). Um den richtigen auszuwählen, müssen Sie alle Störfaktoren finden und bewerten, aber wir werden nie sicher sein, dass wir alle gefunden haben. Tatsächlich schlägt der Artikel einen neuen Ansatz vor - den Dekonfounder. Anstatt Störfaktoren hervorzuheben, führen wir latente Variablen explizit ein und bewerten sie unbeaufsichtigt. Anschließend untersuchen wir das darauf basierende Modell. Das klingt alles seltsam genug, denn es scheint eine einfache Variante von Einbettungen zu sein. Was neu ist, ist nicht klar.
Es wurden ein paar schöne Bilder gezeigt, Beispiele dafür, wie sich die KI an ihrer Universität usw. weiterentwickelt.
E-Commerce und Profiling
Ging zum Anwendungsbereich über Handel. Am Anfang gab es einige sehr interessante Berichte, am Ende gab es eine gewisse Menge Brei, aber das Wichtigste zuerst.
Neue Benutzermodellierung und Abwanderungsvorhersage
Snapchats interessante
Arbeit zur Vorhersage von Abflüssen. Die Jungs verwenden die Idee, die wir auch vor rund 4 Jahren erfolgreich umgesetzt haben: Bevor der Abfluss vorhergesagt werden kann, müssen die Benutzer je nach Art des Verhaltens in Cluster unterteilt werden. Gleichzeitig erwies sich der Vektorraum nach den Arten von Aktionen, die sich als ziemlich schlecht herausstellten, aus nur wenigen Arten von Interaktionen (wir mussten zu gegebener Zeit eine Auswahl von Zeichen treffen, um von dreihundert auf eineinhalb zu wechseln), aber sie bereichern den Raum mit zusätzlichen Statistiken und betrachten ihn als Zeitreihe Infolgedessen erhalten Cluster nicht so sehr Informationen darüber, was Benutzer tun, sondern darüber,
wie oft sie dies tun.
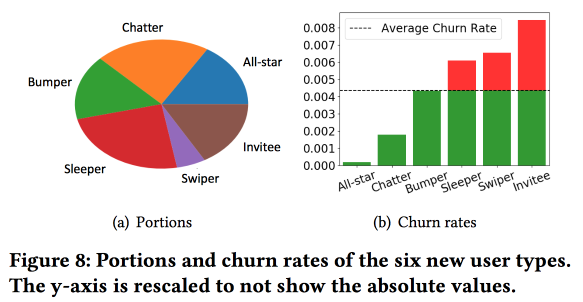
Eine wichtige Beobachtung: Das Netzwerk hat den „Kern“ der am engsten verbundenen und aktivsten Benutzer mit einer Größe von 1,7 Millionen Menschen. Gleichzeitig hängt das Verhalten und die Bindung des Benutzers stark davon ab, ob er mit jemandem aus dem "Kern" kommunizieren kann.
Dann beginnen wir ein Modell zu bauen. Nehmen wir die Neuankömmlinge in vierzehn Tagen (511 Tausend), einfache Funktionen und Ego-Vernetzung (Größe und Dichte) und sehen wir, ob sie mit dem "Kern" usw. verbunden sind. Wir füttern das Benutzerverhalten mit LSTM und erhalten eine etwas höhere Genauigkeit der Abflussprognose als die von logreg (um 7-8%). Aber dann beginnt der Spaß. Um die Besonderheiten einzelner Cluster zu berücksichtigen, werden wir mehrere LSTMs parallel trainieren und darüber eine Aufmerksamkeitsebene anbringen. Infolgedessen beginnt ein solches Schema sowohl mit dem Clustering (welches der LSTMs wurde beachtet) als auch mit der Abflussprognose. Es gibt eine weitere Qualitätssteigerung von + 5-7% und Logreg sieht bereits blass aus. Aber! Tatsächlich wäre es fair, es mit einem segmentierten Logreg zu vergleichen, das separat für Cluster trainiert wurde (was auf einfachere Weise erhalten werden kann).
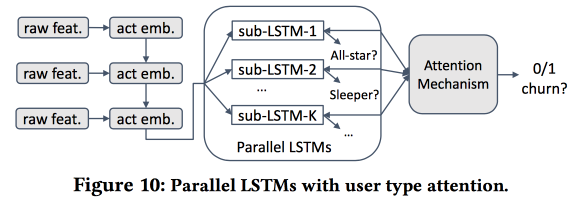
Ich fragte nach der Interpretierbarkeit: Schließlich werden Abflüsse oft nicht vorhergesagt, um eine Prognose zu erhalten, sondern um zu verstehen, welche Faktoren sie beeinflussen. Der Redner war eindeutig bereit für diese Frage: Hierfür werden dedizierte Cluster verwendet und analysiert, während diejenigen, bei denen die Abflussprognosen höher sind, von anderen unterschieden werden.
Universelle Benutzerdarstellung
Alibaba-Leute
sprechen darüber, wie man Benutzerassoziationen aufbaut. Es stellt sich heraus, dass es schlecht ist, viele Benutzerbeiträge zu haben: Viele sind nicht abgeschlossen, Kräfte werden verschwendet. Sie haben es geschafft, eine universelle Präsentation zu machen und zu zeigen, dass es besser funktioniert. Natürlich in neuronalen Netzen. Die Architektur ist ziemlich Standard, bereits in der einen oder anderen Form wurde auf der Konferenz wiederholt beschrieben. Fakten aus dem Benutzerverhalten werden in die Eingabe eingespeist, wir bauen darauf auf, geben alles an LSTM weiter, hängen eine Aufmerksamkeitsebene darüber und daneben ein zusätzliches Raster für statische Merkmale, das mit einer Multitask gekrönt wird (tatsächlich mehrere kleine Raster für eine bestimmte Aufgabe). . Wir trainieren dies alles zusammen. Die Ausgabe mit Aufmerksamkeit wird die Einbettung des Benutzers sein.
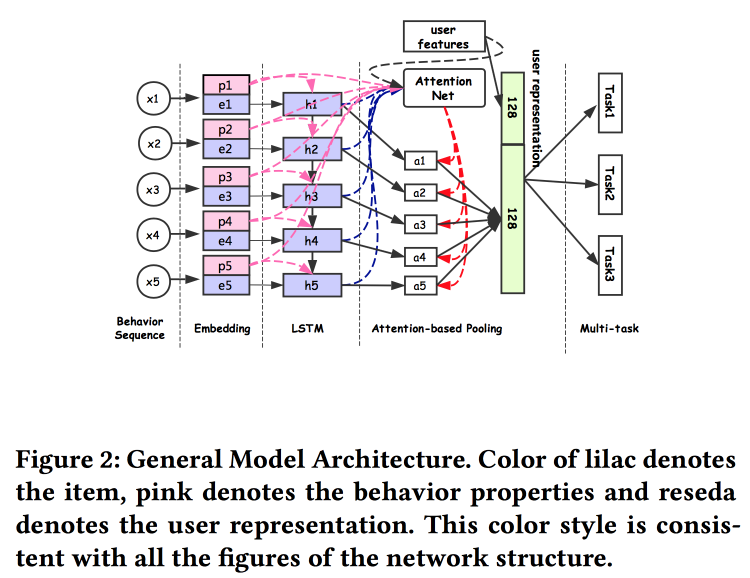
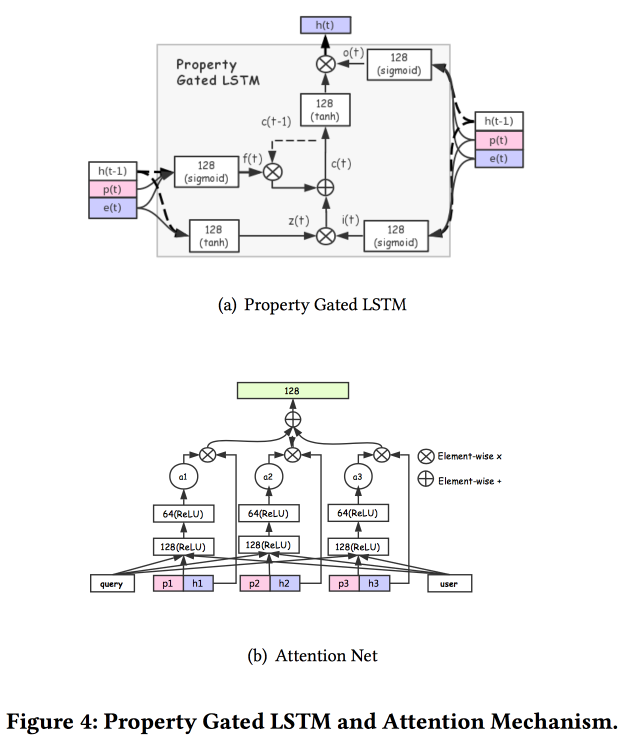
Es gibt mehrere komplexere Ergänzungen: Zusätzlich zur einfachen Aufmerksamkeit fügen sie ein „detailliertes“ Aufmerksamkeitsnetz hinzu und verwenden auch eine modifizierte Version von LSTM - Property Gated LSTM
Aufgaben, bei denen all dies im Umlauf ist: CTR-Vorhersage, Preispräferenzvorhersage, Ranglernen, Mode nach Vorhersage, Shoppräferenzvorhersage. Der Datensatz für 10 Tage enthält 6 * 10
9 Beispiele für Schulungen.
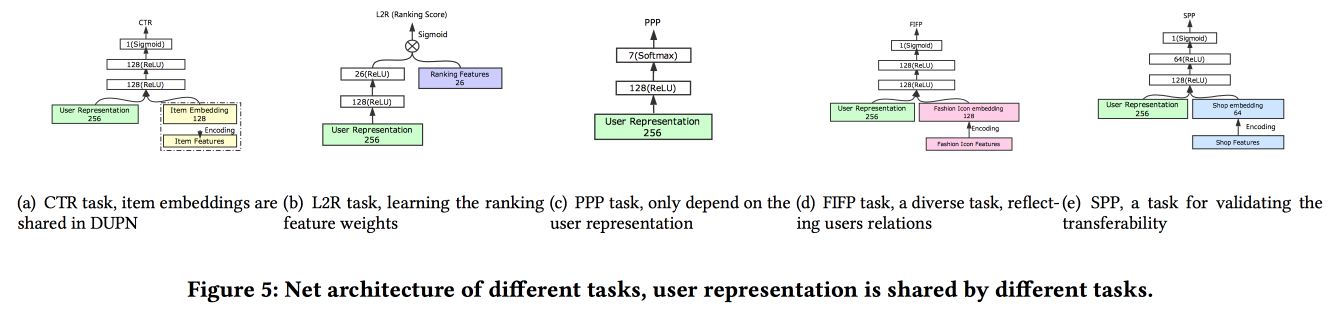
Dann gab es eine unerwartete Person: Sie trainieren dies alles auf TensorFlow, auf einem CPU-Cluster von 2000 Computern mit jeweils 15 Kernen. Es dauert 4 Tage, um die Daten 10 Tage lang zu vervollständigen. Daher trainieren sie Tag für Tag weiter (10 Stunden in diesem Cluster). Über GPU / FPGA hatte ich keine Zeit zu fragen :(. Das Hinzufügen einer neuen Aufgabe erfolgt entweder durch Umschulung als Ganzes oder durch Umschulung eines flachen Gitters (Netwrok-Feinabstimmung). Zur Laufzeit für Inferenz speichern sie Darstellungen (Ausgabe mit Aufmerksamkeit für bestimmte Benutzer) und nur die Köpfe der Gitter werden berechnet Spezifische Aufgaben Der A / B-Test ergab für verschiedene Indikatoren einen Anstieg von 2-3%.
Vorhersage der E-Tail-Produktrückgabe
Sie prognostizieren die Rücksendung von Waren durch den Benutzer nach dem Kauf, die
Arbeit wird von IBM präsentiert. Leider gibt es bisher keinen Text im Open Access. Die Rücksendung von Waren ist ein ernstes Problem im Wert von 200 Milliarden US-Dollar pro Jahr. Um eine Renditeprognose zu erstellen, verwendet er ein Modell eines Hypergraphen, der Produkte und Körbe miteinander verbindet. Mit diesem Korb versuchen sie, die nächstgelegenen per Hypergraph zu finden, wonach sie die Wahrscheinlichkeit einer Rendite schätzen. Um eine Rückgabe zu verhindern, bietet ein Online-Shop viele Möglichkeiten, beispielsweise einen Rabatt für das Entfernen bestimmter Produkte aus dem Warenkorb.
Wir haben sofort festgestellt, dass es einen signifikanten Unterschied zwischen Körben mit Duplikaten gibt (zum Beispiel zwei identische T-Shirts unterschiedlicher Größe), und ohne müssen wir daher sofort unterschiedliche Modelle für diese beiden Fälle bauen.
Der allgemeine Algorithmus heißt HyperGo:
- Wir erstellen einen Hypergraphen, um Einkäufe und Rückgaben mit Informationen des Benutzers, des Produkts und des Warenkorbs darzustellen.
- Als Nächstes verwenden wir den lokalen Grafikschnitt basierend auf einem zufälligen Spaziergang, um lokale Informationen für die Prognose zu erhalten.
- Wir betrachten Körbe mit und ohne Takes getrennt.
- Wir verwenden Bayes'sche Methoden, um die Auswirkungen eines einzelnen Produkts im Warenkorb zu bewerten.
Vergleichen Sie die Qualität der Renditeprognose mit KNN für Körbe, gewichtet nach Jacquard KNN, rationiert nach der Anzahl der Duplikate. Wir erhalten eine Steigerung des Ergebnisses. Auf den Folien flackerte ein Link zu GitHub, aber sie konnten ihre Quelle nicht finden, und der Artikel enthält keinen Link.
OpenTag: Offene Attributwertextraktion aus Produktprofilen
Interessant genug
Arbeit von Amazon. Herausforderung: Minen Sie verschiedene Fakten, damit Alexa Fragen besser beantworten kann. Sie sagen, wie kompliziert alles ist, die alten Systeme wissen nicht, wie man mit neuen Wörtern arbeitet, erfordern oft eine große Anzahl handgeschriebener Regeln und Heuristiken, die Ergebnisse sind mittelmäßig. Natürlich helfen neuronale Netze mit der bereits bekannten Einbettungs-LSTM-Aufmerksamkeitsarchitektur, alle Probleme zu lösen, aber wir werden LSTM verdoppeln und das
bedingte Zufallsfeld darüber rollen.

Wir werden das Problem des Markierens einer Folge von Wörtern lösen. Tags zeigen an, wo wir Sequenzen bestimmter Attribute beginnen und beenden (z. B. den Geschmack und die Zusammensetzung von Hundefutter), und LSTM versucht, diese vorherzusagen. Als Brötchen und Knicks gegenüber Mechanical Turk wird aktives Modelltraining eingesetzt. Um Beispiele auszuwählen, die für ein weiteres Markup gesendet werden müssen, verwenden Sie die Heuristik "Nehmen Sie die Beispiele, bei denen Tags am häufigsten zwischen Epochen wechseln".
Lernen und Übertragen von IDs Repräsentation im E-Commerce
In ihrer
Arbeit kehren Kollegen aus Alibaba erneut zum Thema Gebäudeeinbettungen zurück und betrachten diesmal nicht nur Benutzer, sondern im Prinzip IDs: für Produkte, Marken, Kategorien, Benutzer usw. Interaktionssitzungen werden als Datenquelle verwendet und zusätzliche Attribute werden ebenfalls berücksichtigt. Skipgramme werden als Hauptalgorithmus verwendet.
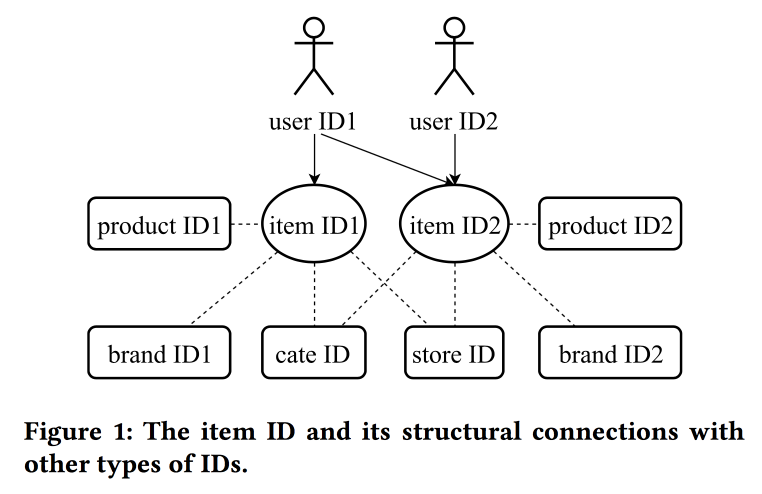
Der Sprecher hat eine sehr starke Aussprache mit einem starken chinesischen Akzent, zu verstehen, was passiert, ist fast unmöglich. Einer der "Tricks" der Arbeit ist die Mechanik der Übertragung von Darstellungen mit fehlenden Informationen, beispielsweise von Elementen an den Benutzer durch Mittelwertbildung (schnell müssen Sie nicht das gesamte Modell lernen). Aus alten Elementen können Sie neue initialisieren (anscheinend aufgrund von Inhaltsähnlichkeit) und die Ansicht des Benutzers von einer Domäne (Elektronik) auf eine andere (Kleidung) übertragen.
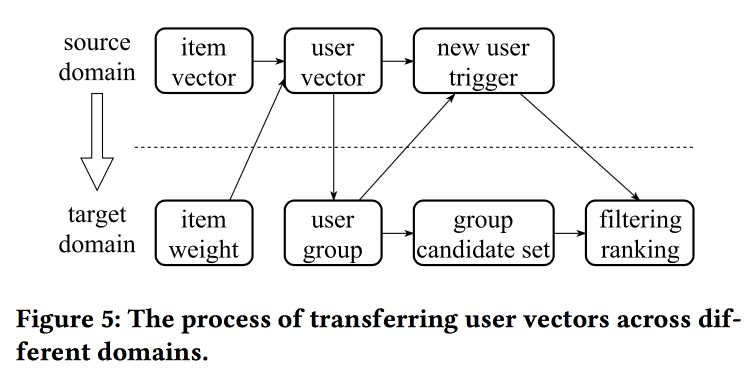
Im Großen und Ganzen ist nicht ganz klar, wo die Neuheit hier ist, anscheinend müssen Details ausgegraben werden; Darüber hinaus ist nicht klar, wie dies mit der vorherigen Geschichte über die einheitlichen Darstellungen von Benutzern verglichen wird.
Online-Parameterauswahl für webbasierte Ranking-Probleme
Sehr interessante
Arbeit von Freunden auf LinkedIn. Das Wesentliche der Arbeit besteht darin, die optimalen Parameter der Algorithmusoperation online unter Berücksichtigung mehrerer konkurrierender Ziele auszuwählen. Betrachten Sie als Bereich das Band und versuchen Sie, die Anzahl der Sitzungen bestimmter Typen zu erhöhen:
- Sitzung mit einer viralen Aktion (VA).
- Fortsetzen der Übermittlungssitzung (JA).
- Inhaltsinteraktion in der Feed-Sitzung (EFS).
Die Ranking-Funktion im Algorithmus ist ein gewichteter Durchschnitt der Conversion-Prognosen für diese drei Ziele. Gewichte sind die Parameter, die wir online optimieren wollen. Zunächst formulieren sie eine Geschäftsaufgabe als „Maximierung der Anzahl der Virensitzungen unter Beibehaltung der beiden anderen Typen auf einem bestimmten Niveau“, transformieren sie dann jedoch zur Vereinfachung der Optimierung ein wenig.
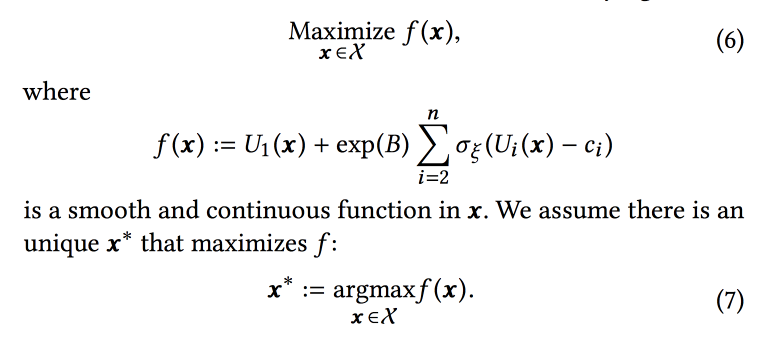
Wir simulieren die Daten mit einer Reihe von Binomialverteilungen (der Benutzer konvertiert zum gewünschten Ziel oder nicht, nachdem er das Band mit bestimmten Parametern gesehen hat), wobei die Erfolgswahrscheinlichkeit mit den angegebenen Parametern ein
Gaußscher Prozess ist (seine eigene für jede Art der Konvertierung). Als nächstes verwenden wir den
Thompson-Sampler mit "unendlich
robusten " Banditen, um die optimalen Parameter auszuwählen (nicht online, sondern offline für historische Daten, also für eine lange Zeit). Sie geben einige Tipps: Verwenden Sie fette Punkte, um das anfängliche Raster zu erstellen, und stellen Sie sicher, dass Sie eine
epsilon-gierige Stichprobe hinzufügen (mit der Wahrscheinlichkeit, dass epsilon einen zufälligen Punkt im Raum versucht), andernfalls können Sie das globale Maximum übersehen.
Sie simulieren die Offline-Probenahme einmal pro Stunde (Sie benötigen viele Proben). Das Ergebnis ist eine bestimmte Verteilung der optimalen Parameter. Wenn ein Benutzer von dieser Distribution aus eingibt, verwendet er bestimmte Parameter für die Erstellung des Bandes (es ist wichtig, dies konsistent mit dem Startwert aus der Benutzer-ID für die Initialisierung zu tun, damit sich das Band des Benutzers nicht radikal ändert).
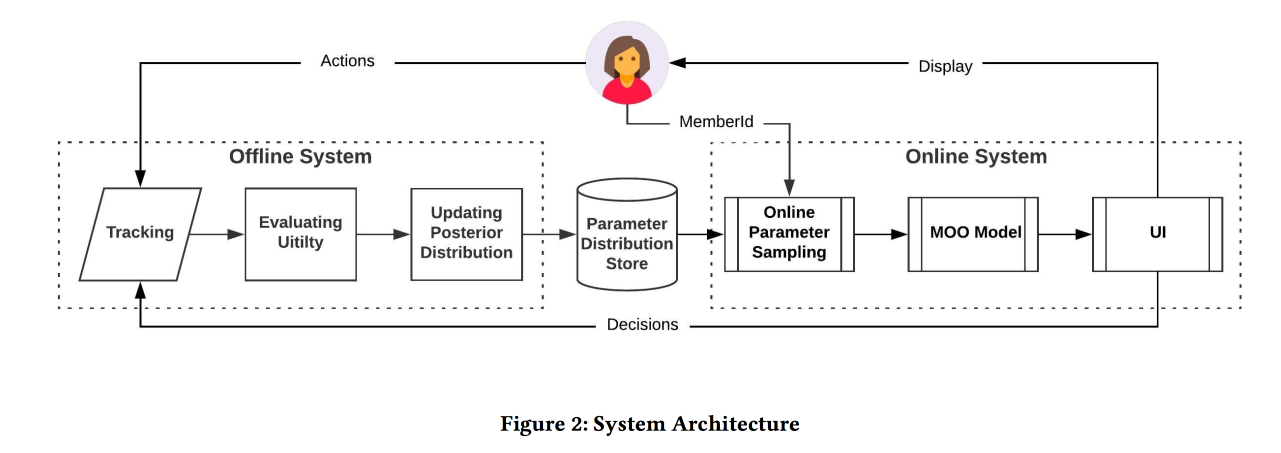
Nach den Ergebnissen des A / B-Experiments erhielten sie eine Zunahme der Lebensläufe um 12% und der Likes um 3%. Teilen Sie einige Beobachtungen:
- Es ist einfacher, mehr zu testen, als zu versuchen, dem Modell weitere Informationen hinzuzufügen (z. B. den Wochentag / die Stunde).
- Wir gehen bei diesem Ansatz von einer Unabhängigkeit der Ziele aus, aber es ist unklar, ob dies der Fall ist (eher nicht). Der Ansatz funktioniert jedoch.
- Unternehmen sollten Ziele und Schwellenwerte festlegen.
- Es ist wichtig, eine Person vom Prozess auszuschließen und sie etwas Nützliches tun zu lassen.
Nahezu Echtzeitoptimierung der aktivitätsbasierten Benachrichtigung
Eine weitere
Arbeit von LinkedIn, diesmal zum Verwalten von Benachrichtigungen. Wir haben Mitarbeiter, Veranstaltungen, Übermittlungskanäle und langfristige Ziele, um das Engagement der Benutzer ohne nennenswerte Negativität in Form von Beschwerden und Abmeldungen von Pushs zu erhöhen. Die Aufgabe ist wichtig und schwierig, und Sie müssen alles richtig machen: an die richtigen Leute zur richtigen Zeit, um die richtigen Inhalte auf dem richtigen Kanal und in der richtigen Menge zu senden.
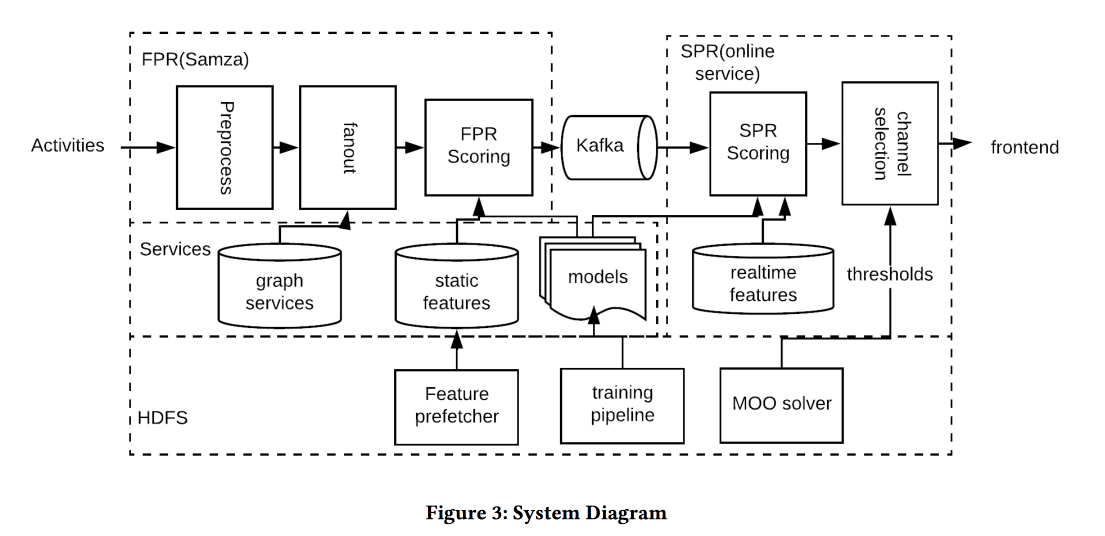
Die Architektur des Systems im obigen Bild, die Essenz dessen, was passiert, ist ungefähr die folgende:
- Wir filtern jeden Spam am Eingang.
- Richtige Leute: Ein Helm für alle, die eng mit dem Autor / Inhalt verbunden sind, der die Schwelle für die Stärke der Kommunikation ausgleicht, die Berichterstattung und Relevanz verwaltet.
- Der richtige Zeitpunkt: Senden Sie sofort Inhalte, für die Zeit wichtig ist (Ereignisse von Freunden), der Rest kann für weniger dynamische Kanäle aufbewahrt werden.
- Der richtige Inhalt: benutze logreg! Ein Prognosemodell für einen Klick auf einen Zeichenhaufen wird separat erstellt, wenn sich eine Person in der Anwendung befindet und wenn nicht.
- Richtiger Kanal: Wir legen unterschiedliche Schwellenwerte für die Relevanz fest, die strengsten für das Pushing, niedriger - wenn der Benutzer jetzt in der Anwendung ist, noch niedriger - für E-Mails (sie enthalten alle Arten von Digests / Anzeigen).
- Richtiges Volumen: Das Beschneidungsmodell nach Volumen befindet sich am Ausgang, es wird auch die Relevanz geprüft. Es wird empfohlen, dies einzeln zu tun (eine gute Schwellenwertheuristik ist eine Mindestpunktzahl für gesendete Objekte in den letzten Tagen).
Beim A / B-Test wurde die Anzahl der Sitzungen um einige Prozent erhöht.
Personalisierung in Echtzeit mithilfe von Einbettungen für das Suchranking bei Airbnb
Und das war das
beste Bewerbungspapier von AirBnB. Ziel: Optimierung der Ausgabe ähnlicher Placements und Suchergebnisse. Wir entscheiden durch die Konstruktion von Einbettungen von Placements und Benutzern in einem Raum, um die Ähnlichkeit weiter zu bewerten. Es ist wichtig zu bedenken, dass es eine langfristige Historie (Benutzereinstellungen) und eine kurzfristige (aktuelle Benutzer- / Sitzungsabsicht) gibt.
Ohne weiteres erstellen wir Word2vec-Platzierungen auf Klicksequenzen in Suchsitzungen (eine Sitzung - ein Dokument). Aber wir machen noch einige Modifikationen (schließlich KDD):
- Wir nehmen an der Sitzung teil, in der eine Reservierung stattgefunden hat.
- Was letztendlich reserviert ist, halten wir als globalen Kontext für alle Elemente der Sitzung während des w2v-Updates.
- Negative im Training werden in derselben Stadt beprobt.

Die Wirksamkeit eines solchen Modells wird auf drei Standardmethoden überprüft:
- Offline prüfen: Wie schnell können wir das richtige Hotel in der Suchsitzung finden?
- Testen durch Prüfer: Entwickelte ein spezielles Tool zur Visualisierung ähnlicher.
- A / B-Test: Spoiler, CTR ist deutlich gewachsen, Buchungen haben nicht zugenommen, aber jetzt passieren sie früher
Wir versuchen, die Ergebnisse der Suchergebnisse nicht nur im Voraus zu bewerten, sondern sie auch nach Erhalt einer Antwort neu zu ordnen (daher in Echtzeit) - indem Sie auf einen Satz klicken und einen anderen ignorieren. Der Ansatz besteht darin, die angeklickten und ignorierten Stellen in zwei Gruppen zu sammeln, Einbettungen in jedem Schwerpunkt zu finden (es gibt eine spezielle Formel) und dann in der Rangfolge wie Klicks zu erhöhen, wie Sprünge zu senken.
Der A / B-Test verzeichnete eine Zunahme der Buchungen, der Ansatz hat sich bewährt: Er wurde vor anderthalb Jahren erfunden und dreht sich immer noch in der Produktion.
Und wenn Sie in einer anderen Stadt suchen müssen? Sie können keine Prioritäten durch Klicks setzen. Es gibt keine Informationen über die Einstellung der Benutzer zu Orten in dieser Siedlung. Um dieses Problem zu umgehen, führen wir „Einbettungen von Inhalten“ ein. Zunächst werden wir einen einfachen diskreten Raum von Schildern (billig / teuer, in der Mitte / am Stadtrand usw.) mit einer Größe von etwa 500.000 Typen (für Orte und Menschen) erstellen. Als nächstes erstellen wir Einbettungen nach Typ. Vergessen Sie beim Lernen nicht, ein klares Negativ zu den Ablehnungen hinzuzufügen (wenn der Eigentümer des Ortes die Reservierung nicht bestätigt hat).
Graph Convolutional Neural Networks für Empfehlungssysteme im Web-Maßstab
Arbeiten Sie von Pinterest an der Empfehlung von Pins. Wir betrachten die zweiteiligen Graph-Benutzer-Pins und fügen den Empfehlungen Netzwerkfunktionen hinzu. Der Graph ist sehr groß - 3 Milliarden Pins, 16 Milliarden Interaktionen, klassische Graph-Einbettungen konnten nicht vorgenommen werden. ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
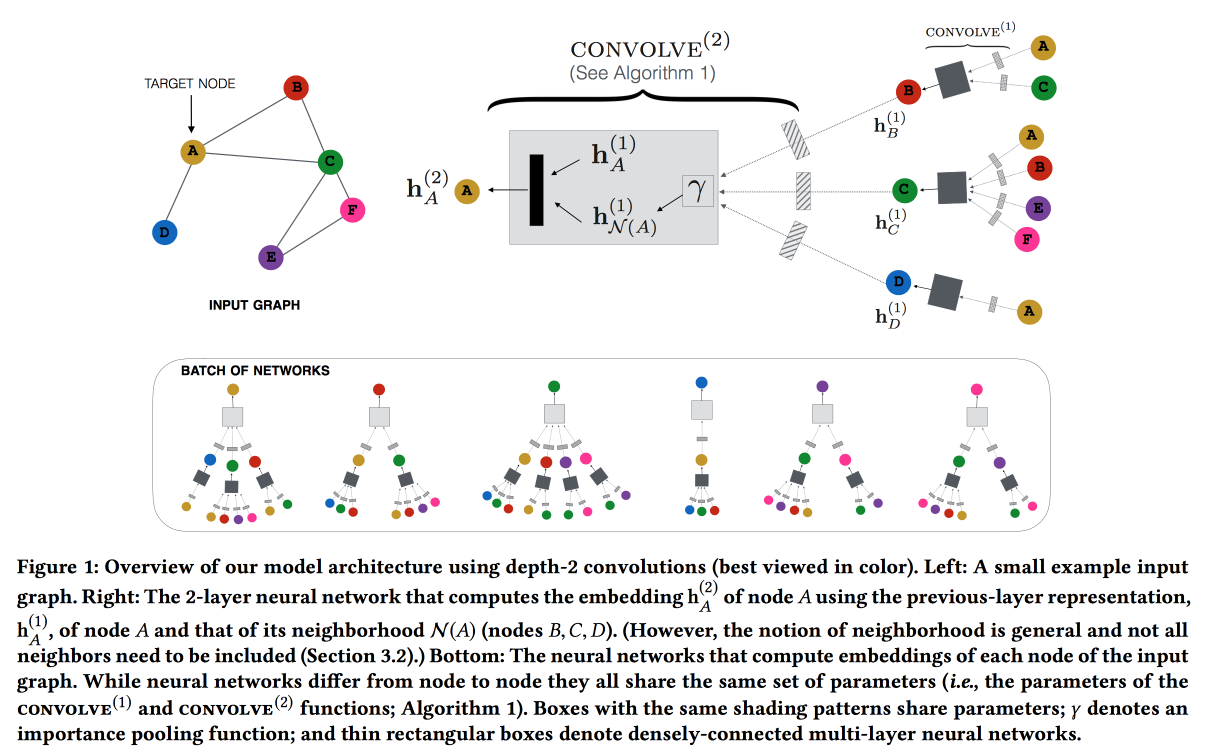
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
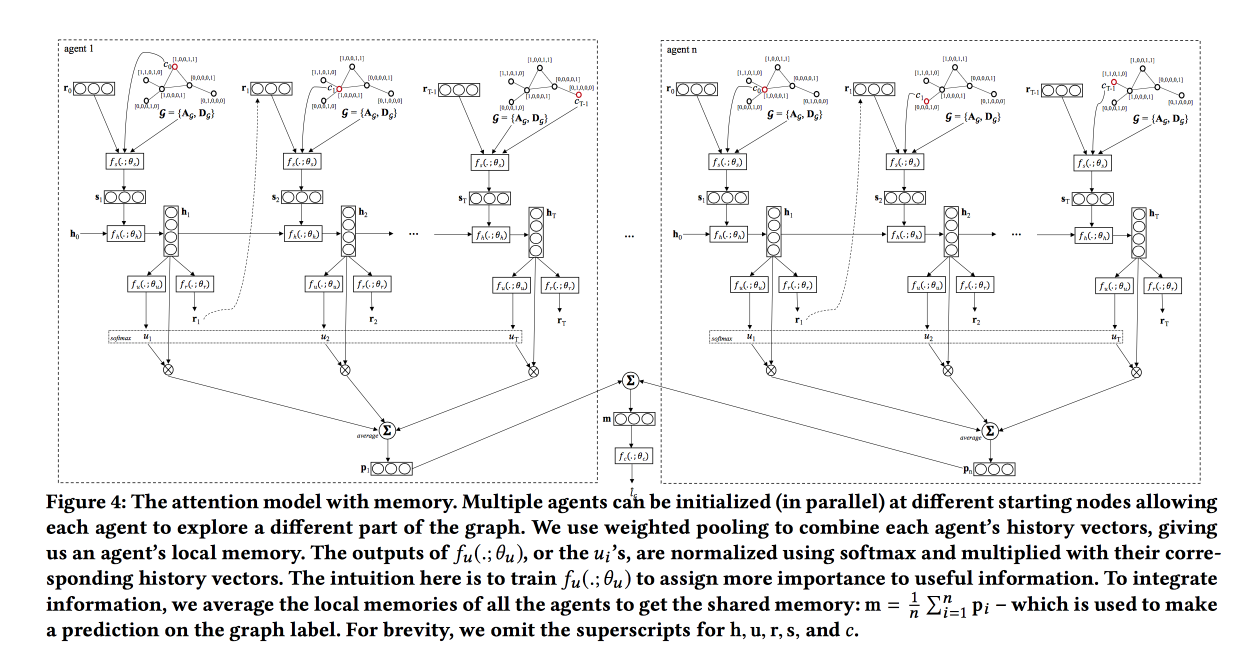
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
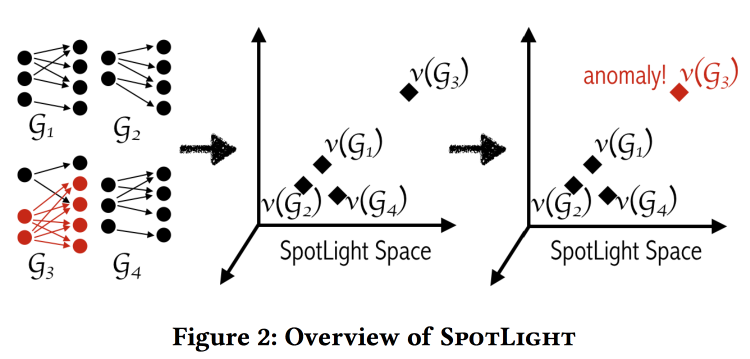
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . Tatsächlich. , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
Jetzt haben es Versicherungsunternehmen schwer: 2011 wurde die Diskriminierung aufgrund des Geschlechts endgültig verboten, jetzt kann das Geschlecht in der Versicherung nicht mehr berücksichtigt werden (was verdammt schwierig ist - selbst wenn Sie das Merkmal „Geschlecht“ explizit verbergen, wird das Modell es wahrscheinlich aus anderen Gründen annähern). Dies führte in Großbritannien zu einem interessanten Effekt:- Frauen fahren genauer und geraten seltener in Unfälle, weshalb die Versicherung für sie günstiger war.
- Nach dem Leveling stiegen die Versicherungskosten für Frauen und für Männer.
- Der Markt funktioniert: Infolgedessen sind mehr Männer und weniger Frauen unterwegs.
- Als die durchschnittliche "Genauigkeit" der Fahrer auf den Straßen abnahm, gab es mehr Unfälle.
- Danach begann natürlich der Preis für Versicherungen zu steigen.
- Die Reiseversicherung begann, ordentliche Fahrer noch härter auszuwaschen.
Als Ergebnis erhielten sie die "Todesspirale".
Dieses Thema spiegelt die Eröffnungsperformance des Tages wider. F - Fairness, dies ist eine unerreichbare Wolkenburg. ML-Modelle lernen, Beispiele (einschließlich Personen) im Raum der Attribute zu trennen, daher können sie per Definition nicht „fair“ sein.