
Vom 18. bis 19. August veranstaltete Tele2 einen Data Science Hackathon. Dieser Hackathon konzentriert sich auf die Analyse von Dialogen des technischen Supports in sozialen Netzwerken, um Kundeninteraktionen zu beschleunigen und zu vereinfachen.
Die Aufgabe hatte keine bestimmte Metrik, die optimiert werden musste, die Aufgabe konnte für sich selbst erfunden werden. Die Hauptsache ist, den Service zu verbessern. Die Jury des Wettbewerbs bestand aus den Direktoren verschiedener Bereiche von Tele2 sowie der berühmten Kaggle-Großmeistergemeinschaft in Data Science Pavel Pleskov.
Unter dem Schnitt die Geschichte des Teams, das den 1. Platz belegte.
Als mich ein Kollege zur Teilnahme an diesem Hackathon einlud, stimmte ich ziemlich schnell zu.
Ich interessierte mich für das Thema NLP und es gab auch einige Entwicklungen in neuronalen Netzen, die ich in der Praxis testen wollte.
Die Organisatoren des Hackathons schickten im Voraus kleine Fragmente von Datensätzen, die eine Vorstellung davon gaben, welche Art von Daten auf der Veranstaltung verfügbar sein würden.
Die Daten erwiesen sich als ziemlich schmutzig, fremde Trolle kamen in die Dialoge, es war nicht immer offensichtlich, welche Art von Frage der Bediener beantwortet.
Es wurde klar, dass es nicht einfach sein würde, die Idee innerhalb der vorgegebenen 24 Stunden umzusetzen, also nahm ich mir einen Tag frei und verbrachte sie damit, das neuronale Netzwerk vorzubereiten, das ich ausprobieren wollte. Dies ermöglichte es uns, keine Hackathon-Zeit mit der Suche nach Fehlern zu verschwenden, sondern uns auf Anwendungs- und Geschäftsfälle zu konzentrieren.
Das Tele2-Büro befindet sich auf dem Gebiet von New Moscow im Gewerbegebiet Rumyantsevo. Ich bin schon seit einiger Zeit dort, aber der Gewerbepark macht einen guten Eindruck (mit Ausnahme von Stromleitungen).
 Stromleitungen vor dem Hintergrund eines Business Centers
Stromleitungen vor dem Hintergrund eines Business CentersDirekt an der U-Bahnstation trafen uns die Organisatoren und zeigten uns, wie wir ins Büro kommen. Das Gebäude des Business Centers selbst wird von vielen Unternehmen bewohnt, das Tele2-Büro befindet sich im 5. Stock. Den Hackathon-Teilnehmern wurde ein spezieller Bereich im Büro zugewiesen, es gab eine Küche, einen Entspannungsbereich mit einer PlayStation und Hockern. Besonders zufrieden mit der Geschwindigkeit von Wi-Fi wurden keine Probleme beobachtet, die Massenereignissen inhärent sind.
 Frühstück
FrühstückDer von Tele2 bereitgestellte reale Datensatz bestand aus 3 großen CSV-Dateien mit Dialogen für technischen Support: Dialoge in sozialen Netzwerken, Telegramm und E-Mail. Insgesamt sind mehr als 4 Millionen Treffer erforderlich, um ein neuronales Netzwerk zu trainieren.
Was war ein neuronales Netzwerk?
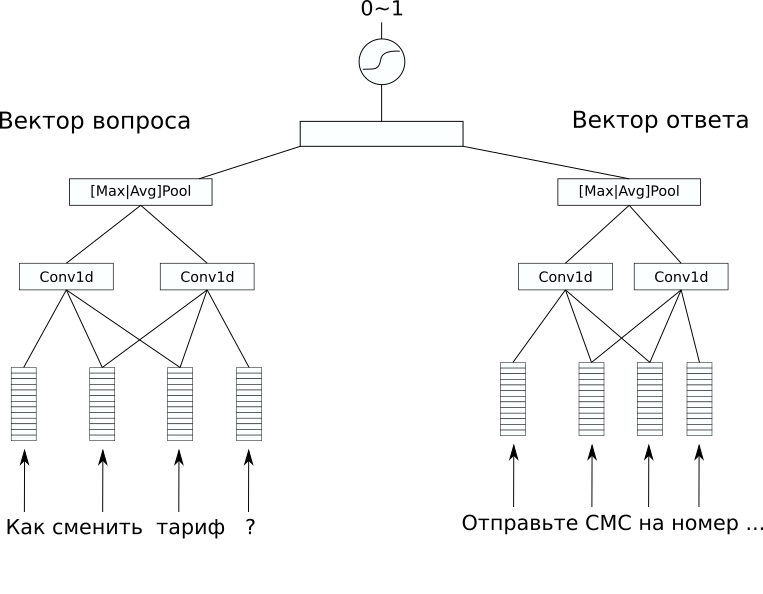 Netzwerkarchitektur
NetzwerkarchitekturIm Datensatz gab es kein zusätzliches Markup, dessen Vorhersage interessant wäre, aber ich wollte ein überwachtes Problem lösen. Aus diesem Grund haben wir uns entschlossen, Antworten auf Fragen vorherzusagen, damit aus einem solchen Modell zumindest ein einfacher Chat-Bot erstellt werden kann. Dafür haben wir die CDSSM-Architektur (Convolution Deep Semantic Similarity Model) gewählt. Dies ist eines der einfachen neuronalen Netzwerkmodelle zum Vergleichen von Texten nach Bedeutung, das ursprünglich von Microsoft für das Ranking von Bing-Suchergebnissen vorgeschlagen wurde.
Sein Wesen ist wie folgt: Zuerst wird jeder Text unter Verwendung einer Folge von Faltungs- und Pooling-Schichten in einen Vektor umgewandelt.
Dann werden die resultierenden Vektoren auf irgendeine Weise verglichen. In unserem Problem ergab eine zusätzliche lineare Schicht, die beide Vektoren mit einem Sigmoid als Aktivierungsfunktion kombinierte, ein gutes Ergebnis. Die Gewichte der Netzwerkcodierungssätze in Vektoren können für ein Textpaar gleich sein (solche Netzwerke werden als siamesisch bezeichnet) und können unterschiedlich sein.
In unserem Fall ergab die Variante mit unterschiedlichen Gewichten das beste Ergebnis, da die Texte der Frage und Antwort signifikant unterschiedlich waren.
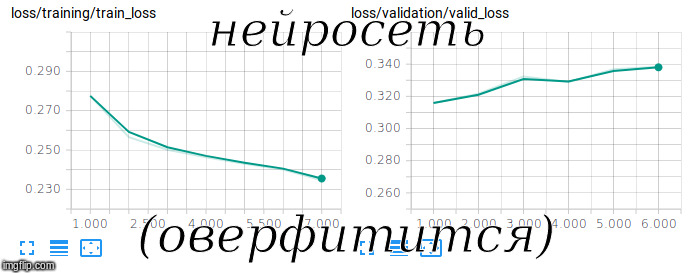 Ich versuche ein siamesisches Netzwerk zu trainieren
Ich versuche ein siamesisches Netzwerk zu trainierenFastText mit RusVectōrēs wurde als vorab trainierte
Einbettung verwendet und ist resistent gegen Tippfehler, die häufig in Benutzerfragen vorkommen.
Um ein solches Modell zu trainieren, muss es nicht nur an positiven, sondern auch an negativen Beispielen trainiert werden. Zu diesem Zweck haben wir dem Trainingssatz zufällige Fragen- und Antwortpaare im Verhältnis 1 zu 10 hinzugefügt.
Um die Qualität einer solchen unausgeglichenen Stichprobe zu bewerten, wurde die ROC-AUC-Metrik verwendet. Nach 3 Stunden Training auf der GPU gelang es uns, in dieser Metrik einen Wert von 0,92 zu erreichen.
Mit diesem Modell ist es möglich, nicht nur das direkte Problem zu lösen - die geeignete Antwort auf die Frage zu wählen, sondern auch das Gegenteil -, um Bedienungsfehler, minderwertige und seltsame Antworten auf Benutzerfragen zu finden.
Wir haben es geschafft, einige dieser Antworten direkt beim Hackathon zu finden und sie in die Abschlusspräsentation aufzunehmen. Es scheint mir, dass dies den größten Eindruck auf die Jury gemacht hat.
Eine interessante Anwendung findet sich auch in der Vektordarstellung von Texten, die das Netzwerk im Rahmen seiner Arbeit generiert.
Mit ihm können Sie mit
verschiedenen unbeaufsichtigten Methoden nach Anomalien in Fragen und Antworten suchen.
Infolgedessen wurde unsere Entscheidung sowohl aus technischer als auch aus geschäftlicher Sicht gut getroffen. Der Rest der Teams versuchte im Grunde, das Problem der Schlüsselanalyse und der thematischen Modellierung zu lösen, sodass sich unsere Lösung positiv unterschied. Infolgedessen belegten wir den 1. Platz, trennten uns zufrieden und müde.
 Auf dem Foto (von links nach rechts): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (Autor) und Shvetsov Egor
Auf dem Foto (von links nach rechts): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (Autor) und Shvetsov EgorWas noch zu lesen: