
Viele Menschen, die maschinelles Lernen studieren, sind mit dem OpenAI-Projekt vertraut, zu dessen Gründern Elon Musk gehört, und nutzen die
OpenAI Gym- Plattform, um ihre neuronalen Netzwerkmodelle zu trainieren.
Das Fitnessstudio enthält eine Vielzahl von Umgebungen, von denen einige verschiedene Arten von physikalischen Simulationen sind: die Bewegungen von Tieren, Menschen,
Robotern . Diese Simulationen basieren auf der
MuJoCo- Physik-Engine, die für pädagogische und wissenschaftliche Zwecke kostenlos ist.
In diesem Artikel werden wir eine extrem einfache physikalische Simulation erstellen, die der OpenAI Gym-Umgebung ähnelt, jedoch auf der kostenlosen Physik-Engine Bullet (
PyBullet )
basiert . Erstellen Sie außerdem einen Agenten, der mit dieser Umgebung arbeitet.
PyBullet ist ein Python-Modul zum Erstellen einer physikalischen Simulationsumgebung basierend auf der
Bullet Physics- Physik-Engine. Es wird, wie MuJoCo, oft als Anregung für verschiedene Roboter verwendet, die sich für Habr interessieren. Es gibt
einen Artikel mit echten Beispielen.
Es gibt einen ziemlich guten
QuickStartGuide für PyBullet, der Links zu Beispielen auf der Quellseite von
GitHub enthält .
Mit PyBullet können Sie bereits erstellte Modelle im URDF-, SDF- oder MJCF-Format laden. In den Quellen gibt es eine Bibliothek von
Modellen in diesen Formaten sowie vollständig vorgefertigte Umgebungen von Simulatoren
realer Roboter.In unserem Fall erstellen wir die Umgebung selbst mit PyBullet. Die Umgebungsschnittstelle
ähnelt der OpenAI Gym-Schnittstelle. Auf diese Weise können wir unsere Agenten sowohl in unserer Umgebung als auch in der Turnhalle schulen.
Der gesamte Code (iPython) sowie die Funktionsweise des Programms können in
Google Colaboratory angezeigt werden .
Umwelt
Unsere Umgebung besteht aus einer Kugel, die sich innerhalb eines bestimmten Höhenbereichs entlang der vertikalen Achse bewegen kann. Der Ball hat Masse und die Schwerkraft wirkt auf ihn, und der Agent muss ihn unter Kontrolle der auf den Ball ausgeübten vertikalen Kraft zum Ziel bringen. Die Zielhöhe ändert sich mit jedem Neustart der Erfahrung.

Die Simulation ist sehr einfach und kann tatsächlich als Simulation eines elementaren Bewegers betrachtet werden.
Um mit der Umgebung zu arbeiten, werden 3 Methoden verwendet:
Zurücksetzen (Neustart des Experiments und Erstellen aller Objekte der Umgebung),
Schritt (Anwenden der ausgewählten Aktion und Abrufen des resultierenden Zustands der Umgebung),
Rendern (visuelle Anzeige der Umgebung).
Bei der Initialisierung der Umgebung muss unser Objekt mit der physischen Simulation verbunden werden. Es gibt zwei Verbindungsoptionen: mit grafischer Oberfläche (GUI) und ohne (DIRECT). In unserem Fall ist es DIRECT.
pb.connect(pb.DIRECT)
zurücksetzen
Bei jedem neuen Experiment setzen wir die Simulation
pb.resetSimulation () zurück und erstellen alle Umgebungsobjekte erneut.
In PyBullet haben Objekte zwei Formen: eine Kollisionsform und eine
visuelle Form . Die erste wird von der physikalischen Engine verwendet, um Kollisionen von Objekten zu berechnen, und um die Berechnung der Physik zu beschleunigen, hat sie normalerweise eine einfachere Form als ein reales Objekt. Die zweite ist optional und wird nur verwendet, wenn das Bild des Objekts erstellt wird.
Formulare werden in einem einzelnen Objekt (Körper) gesammelt -
MultiBody . Ein Körper kann wie in unserem Fall aus einer Form (
CollisionShape / Visual Shape- Paar) oder mehreren bestehen.
Zusätzlich zu den Formen, aus denen der Körper besteht, ist es notwendig, seine Masse, Position und Orientierung im Raum zu bestimmen.
Ein paar Worte zu Multi-Objekt-Körpern.In der Regel werden in realen Fällen zur Simulation verschiedener Mechanismen Körper verwendet, die aus vielen Formen bestehen. Beim Erstellen des Körpers werden dem Körper zusätzlich zur Grundform der Kollisionen und Visualisierung Ketten von Formen von untergeordneten Objekten (
Links ), deren Position und Ausrichtung relativ zum vorherigen Objekt sowie die Arten von Verbindungen (Gelenken) von Objekten untereinander (
Gelenk ) übertragen. Arten von Verbindungen können fest, prismatisch (um dieselbe Achse gleitend) oder rotierend (um eine Achse drehend) sein. Mit den letzten
beiden Verbindungstypen können Sie die Parameter der entsprechenden Motortypen (
JointMotor ) wie Kraft, Geschwindigkeit oder Drehmoment
einstellen und so die Motoren der "Gelenke" des Roboters simulieren. Weitere Details in der
Dokumentation .
Wir werden 3 Körper erschaffen: Ball, Ebene (Erde) und Zielzeiger. Das letzte Objekt hat nur eine Visualisierungsform und eine Masse von Null, daher wird es nicht an der physischen Interaktion zwischen Körpern teilnehmen:
Definieren Sie die Schwerkraft und die Zeit des Simulationsschritts.
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
Um zu verhindern, dass der Ball unmittelbar nach dem Start der Simulation fällt, gleichen wir die Schwerkraft aus.
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
Schritt
Der Agent wählt Aktionen basierend auf dem aktuellen Status der Umgebung aus. Anschließend ruft er die
Schrittmethode auf und erhält einen neuen Status.
Es werden zwei Arten von Aktionen definiert: Erhöhung und Verringerung der auf den Ball wirkenden Kraft. Kraftgrenzen sind begrenzt.
Nach dem Ändern der auf den Ball wirkenden Kraft wird ein neuer Schritt der physikalischen Simulation
pb.stepSimulation () gestartet und die folgenden Parameter werden an den Agenten zurückgegeben:
Beobachtung - Beobachtungen (Zustand der Umwelt)
Belohnung - Belohnung für perfekte Aktion
erledigt - die Flagge des Endes der Erfahrung
info - zusätzliche Informationen
Als Zustand der Umgebung werden 3 Werte zurückgegeben: die Entfernung zum Ziel, die aktuell auf den Ball ausgeübte Kraft und die Geschwindigkeit des Balls. Die Werte werden normalisiert zurückgegeben (0..1), da die Umgebungsparameter, die diese Werte bestimmen, je nach Wunsch variieren können.
Die Belohnung für die perfekte Aktion ist 1, wenn sich der Ball in der Nähe des Ziels befindet (Zielhöhe plus / minus des akzeptablen
Rollwerts TARGET_DELTA ) und in anderen Fällen 0.
Das Experiment ist abgeschlossen, wenn der Ball die Zone verlässt (zu Boden fällt oder hoch fliegt). Wenn der Ball das Ziel erreicht, endet das Experiment ebenfalls, jedoch erst nach einer bestimmten Zeit (
STEPS_AFTER_TARGET- Schritte des Experiments). So ist unser Agent geschult, sich nicht nur dem Ziel zu nähern, sondern auch anzuhalten und ihm nahe zu sein. Angesichts der Tatsache, dass die Belohnung, wenn Sie sich dem Ziel
nähern, 1 beträgt, sollte eine vollständig erfolgreiche Erfahrung eine Gesamtbelohnung von
STEPS_AFTER_TARGET haben .
Als zusätzliche Information zum Anzeigen von Statistiken werden die Gesamtzahl der im Experiment ausgeführten Schritte sowie die Anzahl der pro Sekunde ausgeführten Schritte zurückgegeben.
rendern
PyBullet verfügt über zwei Optionen zum Rendern von Bildern: GPU-Rendering basierend auf OpenGL und CPU basierend auf TinyRenderer. In unserem Fall ist nur eine CPU-Implementierung möglich.
Um den aktuellen Rahmen der Simulation zu erhalten, müssen die
Speziesmatrix und die
Projektionsmatrix bestimmt und dann das
RGB- Bild der angegebenen Größe von der Kamera
abgerufen werden .
camTargetPos = [0,0,5]
Am Ende jedes Experiments wird basierend auf den gesammelten Bildern ein Video generiert.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
Agent
Der GitHub
Jaara- Benutzercode wurde als Grundlage für den Agenten verwendet, als einfaches und verständliches Beispiel für die Implementierung eines Verstärkungstrainings für die Fitnessumgebung.
Der Agent enthält 2 Objekte:
Speicher - ein Speicher für die Bildung von Trainingsbeispielen und
Gehirn selbst ist das neuronale Netzwerk, das er trainiert.
Das trainierte neuronale Netzwerk wurde in TensorFlow mithilfe der Keras-Bibliothek erstellt, die kürzlich vollständig in TensorFlow integriert wurde.
Das neuronale Netzwerk hat eine einfache Struktur - 3 Schichten, d.h. Nur 1 versteckte Ebene.
Die erste Schicht enthält 512 Neuronen und verfügt über eine Anzahl von Eingaben, die der Anzahl der Parameter des Zustands des Mediums entsprechen (3 Parameter: Entfernung zum Ziel, Stärke und Geschwindigkeit des Balls). Die verborgene Schicht hat eine Dimension, die der ersten Schicht entspricht - 512 Neuronen, am Ausgang ist sie mit der Ausgangsschicht verbunden. Die Anzahl der Neuronen der Ausgangsschicht entspricht der Anzahl der vom Agenten ausgeführten Aktionen (2 Aktionen: Abnahme und Zunahme der einwirkenden Kraft).
Somit wird der Status des Systems dem Netzwerkeingang zugeführt, und am Ausgang haben wir einen Vorteil für jede der Aktionen.
Für die ersten beiden Schichten wird
ReLU (gleichgerichtete Lineareinheit) als Aktivierungsfunktion verwendet, für die letzte - eine
lineare Funktion (die Summe der Eingabewerte ist einfach).
Als Funktion des Fehlers
MSE (Standardfehler) als Optimierungsalgorithmus -
RMSprop (Root Mean Square Propagation).
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
Nach jedem Simulationsschritt speichert der Agent die Ergebnisse dieses Schritts in Form einer Liste
(s, a, r, s_) :
s - vorherige Beobachtung (Zustand der Umwelt)
a - abgeschlossene Aktion
r - Belohnung für die durchgeführte Aktion
s_ - letzte Beobachtung nach der Aktion
Danach empfängt der Agent aus dem Speicher eine zufällige Reihe von Beispielen für frühere Perioden und bildet ein Trainingspaket (
Batch ).
Die Anfangszustände
s der aus dem Speicher ausgewählten Zufallsschritte werden als Eingabewerte (
X ) des Pakets verwendet.
Die tatsächlichen Werte der Lernausgabe (
Y ' ) werden wie folgt berechnet: Am Ausgang (
Y ) des neuronalen Netzwerks für s gibt es Werte der
Q-Funktion für jede der Aktionen
Q (s) . Aus diesem Satz wählte der Agent die Aktion mit dem höchsten Wert
Q (s, a) = MAX (Q (s)) aus , schloss sie ab und erhielt die Auszeichnung
r . Der neue
Q- Wert für die ausgewählte Aktion
a ist
Q (s, a) = Q (s, a) + DF * r , wobei
DF der Abzinsungsfaktor ist. Die verbleibenden Ausgabewerte bleiben gleich.
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
Das Netzwerktraining findet auf dem gebildeten Paket statt
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
Nach Abschluss des Experiments wird ein Video generiert
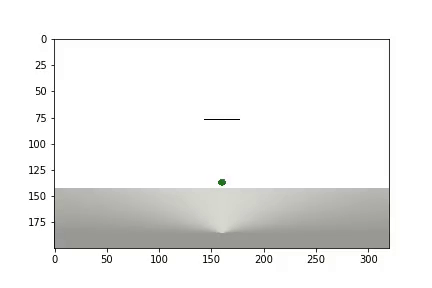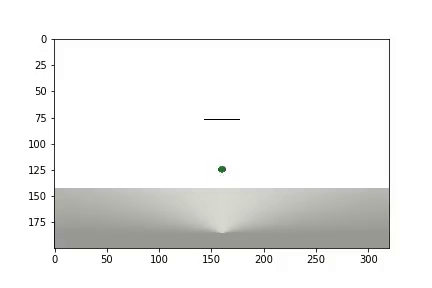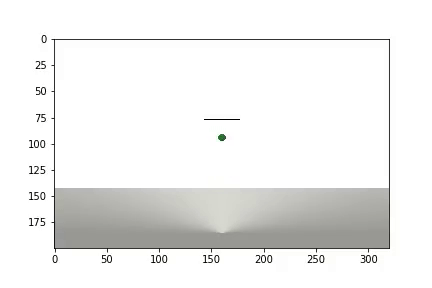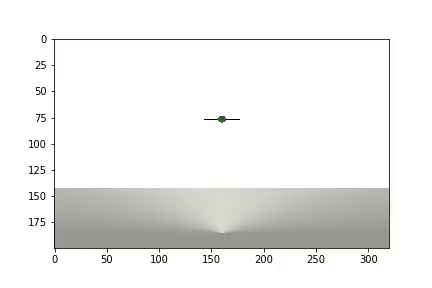
und Statistiken werden angezeigt
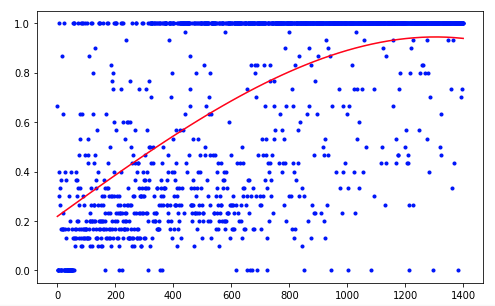
Der Agent benötigte 1.200 Versuche, um ein Ergebnis von etwa 95 Prozent zu erzielen (Anzahl der erfolgreichen Schritte). Und beim 50. Experiment hatte der Agent gelernt, den Ball zum Ziel zu bewegen (erfolglose Experimente verschwinden).
Um die Ergebnisse zu verbessern, können Sie versuchen, die Größe der Netzwerkschichten (LAYER_SIZE), den Parameter des Abzinsungsfaktors (GAMMA) oder die Abnahmerate der Wahrscheinlichkeit der Auswahl einer zufälligen Aktion (LAMBDA) zu ändern.
Unser Agent hat die einfachste Architektur - DQN (Deep Q-Network). Bei einer so einfachen Aufgabe reicht es aus, ein akzeptables Ergebnis zu erzielen.
Die Verwendung der DDQN-Architektur (Double DQN) sollte beispielsweise ein reibungsloseres und genaueres Training ermöglichen. Das RDQN-Netzwerk (Recurrent DQN) kann die Muster von Umgebungsänderungen im Laufe der Zeit verfolgen, wodurch es möglich wird, den Ballgeschwindigkeitsparameter zu entfernen und die Anzahl der Netzwerkeingabeparameter zu verringern.
Sie können unsere Simulation auch erweitern, indem Sie eine variable Kugelmasse oder den Neigungswinkel ihrer Bewegung hinzufügen.
Aber das ist das nächste Mal.