Vor einem Jahr haben wir unserem Agenten eine Sammlung von Metriken aus SMART-Festplattenattributen auf Client-Servern hinzugefügt. In diesem Moment haben wir sie nicht zur Benutzeroberfläche hinzugefügt und sie den Kunden gezeigt. Tatsache ist, dass wir keine Metriken über smartctl verwenden, sondern ioctl direkt aus dem Code abrufen, sodass diese Funktionalität ohne die Installation von smartmontools auf Client-Servern funktioniert.
Der Agent entfernt nicht alle verfügbaren Attribute, sondern nur die unserer Meinung nach wichtigsten und die am wenigsten herstellerspezifischen (andernfalls müsste er eine Festplattenbasis unterstützen, die Smartmontools ähnelt).
Jetzt haben die Hände endlich den Punkt erreicht, um zu überprüfen, was wir dort gedreht haben. Es wurde beschlossen, mit dem Attribut "Media Wearout Indicator" zu beginnen, das den Prozentsatz der verbleibenden SSD-Aufzeichnungsressource anzeigt. Unter dem Schnitt einige Geschichten in Bildern darüber, wie diese Ressource im wirklichen Leben auf Servern ausgegeben wird.
Gibt es getötete SSDs?
Es wird angenommen, dass neue, produktivere SSDs häufiger veröffentlicht werden als alte. Daher war es als erstes interessant, die am meisten getöteten Ressourcen in Bezug auf die Aufzeichnung von Ressourcen zu betrachten. Der Mindestwert für alle ssd aller Clients beträgt 1%.
Wir haben dem Kunden sofort darüber geschrieben, es stellte sich heraus, dass es sich bei hetzner um einen Dedik handelt. Der Hosting-Support ersetzte sofort ssd:

Es wäre sehr interessant zu sehen, wie die Situation aus Sicht des Betriebssystems aussieht, wenn ssd den Datensatz nicht mehr bereitstellt (wir suchen jetzt nach der Möglichkeit, ssd absichtlich zu verspotten, um die Metriken dieses Szenarios zu betrachten :)
Wie schnell werden SSDs getötet?
Da wir vor einem Jahr mit dem Sammeln von Metriken begonnen haben und keine Metriken löschen, ist es möglich, diese Metrik rechtzeitig zu betrachten. Leider wurde der Server mit der höchsten Durchflussrate erst vor 2 Monaten an okmeter angeschlossen.

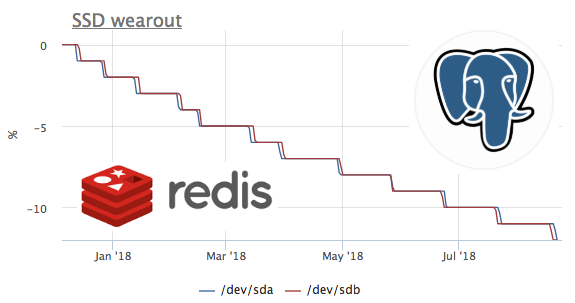
In dieser Grafik sehen wir, wie in 2 Monaten 8% der Aufzeichnungsressource verbrannt wurden. Das heißt, mit demselben Aufnahmeprofil reicht diese SSD für 100 / (8/2) = 25 Monate. Ich weiß nicht viel oder wenig, aber mal sehen, welche Art von Ladung es gibt.

Wir sehen, dass nur Ceph mit der Festplatte funktioniert, aber wir verstehen, dass Ceph nur eine Ebene ist. In diesem Fall fungiert der ceph-Client als Repository für den kubernetes-Cluster auf mehreren Knoten. Sehen wir uns an, was in k8s die meisten Festplattenschreibvorgänge generiert:

Die absoluten Werte stimmen höchstwahrscheinlich nicht überein, da ceph im Cluster arbeitet und der Datensatz von redis aufgrund der Datenreplikation zunimmt. Mit dem Lastprofil können Sie jedoch sicher sagen, dass der Datensatz genau Redis initiiert. Mal sehen, was auf dem Rettich passiert:

Hier sehen Sie, dass durchschnittlich weniger als 100 Anforderungen pro Sekunde ausgeführt werden, wodurch Daten geändert werden können. Denken Sie daran, dass redis zwei Möglichkeiten hat, Daten auf die Festplatte zu schreiben :
- RDB - Periodische Snapshots der gesamten Datenbank auf der Festplatte. Beim Starten von Redis lesen wir den letzten Speicherauszug in den Speicher und verlieren Daten zwischen den Speicherauszügen
- AOF - Wir schreiben ein Protokoll aller Änderungen. Beim Start verliert Redis dieses Protokoll und alle Daten werden im Speicher angezeigt. Wir verlieren nur Daten zwischen fsync dieses Protokolls
Wie wahrscheinlich jeder in diesem Fall bereits vermutet hat, wird RDB mit einer Speicherauszugsfrequenz von 1 Minute verwendet:

SSD + RAID
Nach unseren Beobachtungen gibt es drei Hauptkonfigurationen des Festplattensubsystems von Servern mit SSDs:
- in Server 2 SSDs in Raid-1 gesammelt und alles lebt dort
- Der Server verfügt über HDD + raid-10 von ssd. Er wird normalerweise für klassische RDBMS verwendet (System, WAL und ein Teil der Daten auf der Festplatte und auf der SSD die heißesten Daten in Bezug auf das Lesen).
- Der Server verfügt über eine freistehende SSD (JBOD), die normalerweise für Cassandra vom Typ nosql verwendet wird
Wenn ssd in raid-1 gesammelt werden, wird die Aufzeichnung auf beide Festplatten übertragen, sodass der Verschleiß mit der gleichen Geschwindigkeit erfolgt:
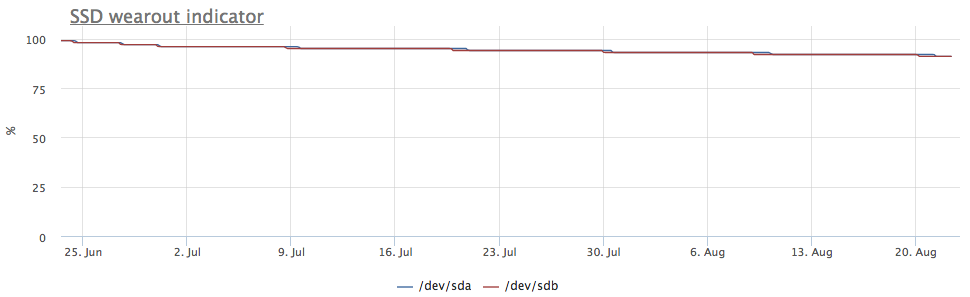
Aber der Server ist mir aufgefallen, bei dem das Bild anders ist:

In diesem Fall werden nur mdraid-Partitionen gemountet (alle raid-1-Arrays):

Die Aufzeichnungsmetriken zeigen auch, dass es mehr Einträge in / dev / sda gibt:

Es stellte sich heraus, dass eine der Partitionen auf / dev / sda als Swap verwendet wird und Swap-E / A auf diesem Server ziemlich auffällig ist:

Abschreibung von SSD und PostgreSQL
Eigentlich wollte ich die SSD-Verschleißrate bei verschiedenen Schreiblasten in Postgres sehen, aber in der Regel werden sie in geladenen SSD-Datenbanken sehr sorgfältig verwendet und massive Aufzeichnungen werden auf die Festplatte übertragen. Bei der Suche nach einem geeigneten Fall bin ich auf einen sehr interessanten Server gestoßen:

Der Verschleiß von zwei ssd in raid-1 für 3 Monate betrug 4%, aber gemessen an der WAL-Aufzeichnungsgeschwindigkeit schreibt dieser Postgres weniger als 100 Kb / s:
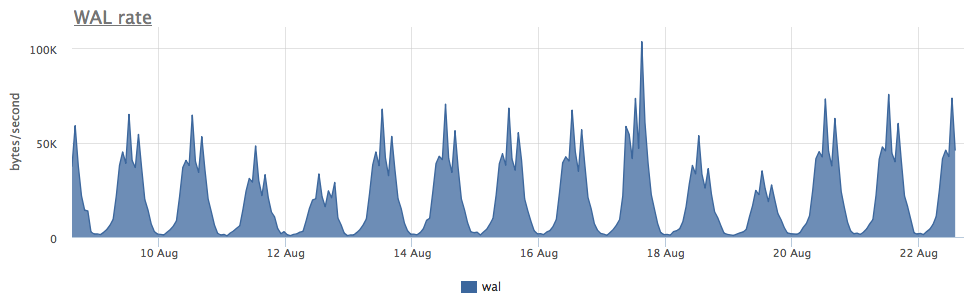
Es stellte sich heraus, dass postgres temporäre Dateien aktiv verwendet, wodurch ein konstanter Schreibstrom auf die Festplatte entsteht:

Da postgresql mit Diagnose ziemlich gut ist, können wir bis zur Anfrage herausfinden, was genau wir reparieren müssen:

Wie Sie hier sehen können, generiert dieses spezielle SELECT eine Reihe von temporären Dateien. Im Allgemeinen generieren sie in SELECT postgres manchmal einen Datensatz ohne temporäre Dateien - hier haben wir bereits darüber gesprochen.
Insgesamt
- Die Menge an Schreibzugriff auf die Festplatte, die Redis + RDB erstellt, hängt nicht von der Anzahl der Änderungen in der Datenbank ab, sondern von der Größe des Datenbank- + Speicherauszugsintervalls (und im Allgemeinen ist dies die höchste Stufe der Schreibverstärkung in den mir bekannten Datenspeichern).
- Aktiv verwendeter Swap auf SSD ist schlecht, aber wenn Sie Jitter zum SSD-Verschleiß hinzufügen müssen (für die Zuverlässigkeit von RAID-1), ist dies möglicherweise eine Option :)
- Zusätzlich zu WAL und Datendateien können Datenbanken weiterhin alle Arten von temporären Daten auf die Festplatte schreiben.
Wir bei okmeter.io glauben, dass der Ingenieur viele Metriken für alle Ebenen der Infrastruktur benötigt, um der Ursache des Problems auf den Grund zu gehen. Wir geben unser Bestes, um zu helfen :)