Die Verwendung der von Neumann-Architektur für Anwendungen mit künstlicher Intelligenz ist ineffizient. Was wird sie ersetzen?
Die Verwendung vorhandener Architekturen zur Lösung der Probleme des maschinellen Lernens (MO) und der künstlichen Intelligenz (AI) ist unpraktisch geworden. Der Energieverbrauch der KI ist erheblich gestiegen, und die CPU und die GPU scheinen zunehmend ungeeignete Werkzeuge für diese Arbeit zu sein.
Die Teilnehmer mehrerer Symposien waren sich einig, dass sich die besten Möglichkeiten für signifikante Änderungen ergeben, wenn keine geerbten Merkmale vorhanden sind, die mitgeschleppt werden müssen. Die meisten Systeme haben sich im Laufe der Zeit schrittweise weiterentwickelt - und selbst wenn dies einen sicheren Fortschritt gewährleistet, bietet ein solches Schema keine optimalen Lösungen. Wenn etwas Neues auftaucht, wird es möglich, die Dinge neu zu betrachten und eine bessere Richtung zu wählen, als dies herkömmliche Technologien bieten. Genau dies wurde kürzlich auf einer Konferenz diskutiert, auf der die Frage untersucht wurde, ob die komplementäre Metalloxid-Halbleiter-Struktur (
CMOS ) die beste Basistechnologie ist, auf der es sich lohnt, AI-Anwendungen zu erstellen.
Ein Chen, der von IBM zum Executive Director der Nanoelectronics Research Initiative (NRI) ernannt wurde, bereitete die Diskussion vor. „Seit vielen Jahren erforschen wir neue, moderne Technologien, einschließlich der Suche nach einer Alternative zu CMOS, insbesondere aufgrund der Probleme im Zusammenhang mit dem Stromverbrauch und der Skalierung. Nach all diesen Jahren hat sich die Meinung entwickelt, dass wir nichts Besseres als Grundlage für die Erstellung von Logikschaltungen gefunden haben. Heutzutage konzentrieren sich viele Forscher auf KI, und sie bietet wirklich neue Denkweisen und neue Muster und sie haben neue technologische Produkte. Werden neue KI-Geräte CMOS ersetzen können? “
KI heute
Die meisten Anwendungen für MO und AI verwenden die von Neumann-Architektur. "Es verwendet Speicher zum Speichern von Datenarrays und die CPU führt alle Berechnungen durch", erklärt Marvin Chen, Professor für Elektrotechnik an der Xinhua National University. „Große Datenmengen bewegen sich über den Bus. Heutzutage werden GPUs häufig auch für eingehende Schulungen verwendet, einschließlich Faltungsnetzwerke. Eines der Hauptprobleme ist das Auftreten von Zwischendaten, die erforderlich sind, um Schlussfolgerungen zu ziehen. Das Verschieben von Daten, insbesondere über den Chip hinaus, führt zu Energieverlust und Verzögerungen. Dies ist ein Technologieengpass. “
 Für AI verwendete Architekturen
Für AI verwendete ArchitekturenWas Sie heute brauchen, ist die Kombination von Datenverarbeitung und Speicher. „Das Konzept des In-Memory-Computing wird seit vielen Jahren von Experten für Computerarchitektur vorgeschlagen“, sagt Chen. - Es gibt verschiedene Schemata für SRAM und nichtflüchtigen Speicher, mit denen versucht wurde, ein solches Konzept zu verwenden und umzusetzen. Wenn dies gelingt, können Sie im Idealfall viel Energie sparen, indem Sie die Datenübertragung zwischen CPU und Speicher eliminieren. Das ist aber ideal. “
Aber für heute haben wir keine Berechnungen im Sinn. "Wir haben immer noch AI 1.0 mit von Neumann-Architektur, weil Siliziumgeräte, die die Verarbeitung im Speicher implementieren, nie aufgetaucht sind", beklagt sich. Chen "Die einzige Möglichkeit, 3D-TSV in irgendeiner Weise zu verwenden, besteht darin, Hochgeschwindigkeitsspeicher mit der GPU zu verwenden, um das Bandbreitenproblem zu lösen." Aber es bleibt immer noch ein Engpass für Energie und Zeit. "
Wird es genügend Datenverarbeitung im Speicher geben, um das Problem des Energieverlusts zu lösen? "Das menschliche Gehirn enthält hundert Milliarden Neuronen und 10
15 Synapsen", sagte Sean Lee, stellvertretender Direktor der Taiwan Semiconductor Manufacturing Company. "Schauen Sie sich jetzt IBM TrueNorth an." TrueNorth ist ein Multi-Core-Prozessor, der 2014 von IBM entwickelt wurde. Er verfügt über 4.096 Kerne und jeweils 256 programmierbare künstliche Neuronen. „Angenommen, wir möchten es skalieren und die Größe des Gehirns reproduzieren. Die Differenz beträgt 5 Größenordnungen. Wenn wir jedoch die Anzahl direkt erhöhen und TrueNorth multiplizieren und 65 mW verbrauchen, erhalten wir eine Maschine mit einem Verbrauch von 65 kW gegen das Gehirn einer Person, die 25 Watt verbraucht. Der Verbrauch muss um mehrere Größenordnungen reduziert werden. "
Lee bietet eine andere Möglichkeit, sich diese Gelegenheit vorzustellen. "Der bisher effizienteste Supercomputer ist der Green500 aus Japan, der 17 Gflops pro Watt oder 1
Flop bei 59 pJ ausgibt." Auf der Green500-Website heißt es, dass das im japanischen Advanced Computing and Communications Center (RIKEN) installierte ZettaScaler-2.2-System während des Linpack-Testlaufs 18,4 Gflops / W gemessen hat, für den 858 TFlops erforderlich waren. „Vergleichen Sie dies mit
dem Landauer-Prinzip , wonach bei Raumtemperatur die minimale Schaltenergie des Transistors in der Größenordnung von 2,75 zJ [10
-21 J] liegt. Auch hier beträgt der Unterschied mehrere Größenordnungen. 59 pJ ist ungefähr 10
-11 gegenüber dem theoretischen Tief von ungefähr 10
-21 . Wir haben ein riesiges Forschungsfeld. "
Ist es fair, solche Computer mit dem Gehirn zu vergleichen? „Nachdem wir die jüngsten Erfolge einer eingehenden Ausbildung untersucht haben, werden wir feststellen, dass in den meisten Fällen Menschen und Maschinen in den letzten sieben Jahren in Folge miteinander konkurrieren“, sagt Kaushik Roy, emeritierter Professor für Elektrotechnik und Informatik an der Purdue University. „1997 besiegte Deep Blue Kasparov, 2011 gewann IBM Watson das Spiel Jeopardy! Und 2016 besiegte Alpha Go Lee Sedola. Dies sind die größten Erfolge. Aber zu welchem Preis? Diese Maschinen verbrauchten 200 bis 300 kW. Das menschliche Gehirn verbraucht etwa 20 Watt. Riesige Lücke. Woher kommt die Innovation?
Im Mittelpunkt der meisten Anwendungen stehen MO und AI, die einfachsten Berechnungen, die in großem Maßstab durchgeführt werden. „Wenn Sie das einfachste neuronale Netzwerk verwenden, führt es eine gewichtete Summierung durch, gefolgt von einer Schwellenwertoperation“, erklärt Roy. - Dies kann in verschiedenen Arten von Matrizen erfolgen. Es kann sich um ein Gerät aus der Spintronik oder einem resistiven Speicher handeln. In diesem Fall werden die Eingangsspannung und die resultierende Leitfähigkeit jedem Schnittpunkt zugeordnet. Am Ausgang erhalten Sie die Summe der Spannungen multipliziert mit der Leitfähigkeit. Dies ist der Strom. Dann können Sie ähnliche Geräte verwenden, die eine Schwellenwertoperation ausführen. Architektur kann man sich als eine Ansammlung dieser Knoten vorstellen, die miteinander verbunden sind, um Berechnungen durchzuführen. “
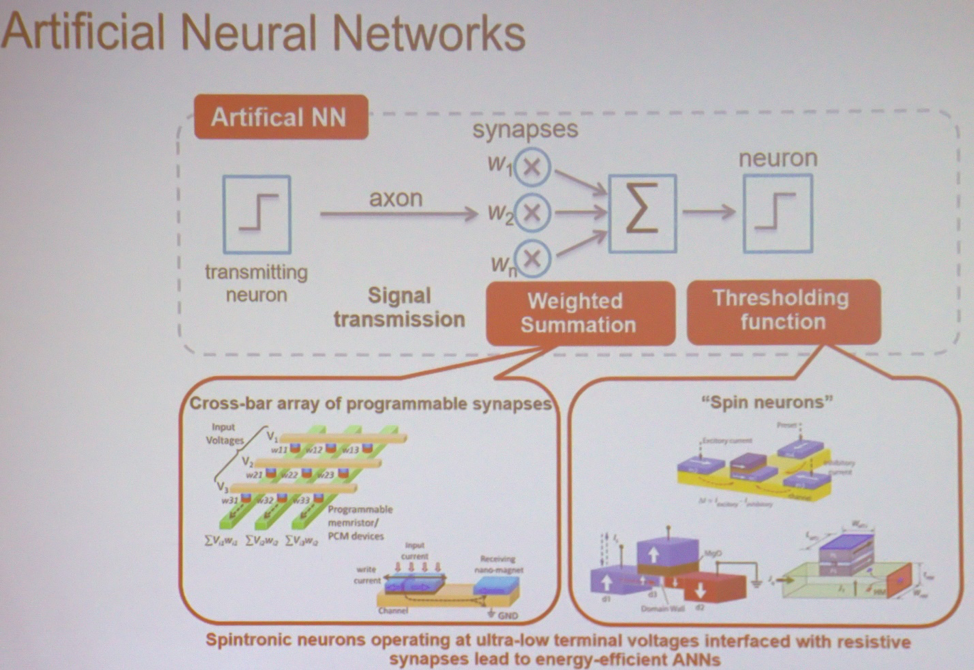 Die Hauptkomponenten des neuronalen Netzwerks
Die Hauptkomponenten des neuronalen NetzwerksNeue Arten von Speicher
Die meisten potenziellen Architekturen sind mit neu auftretenden Arten von nichtflüchtigem Speicher verbunden. "Was sind die wichtigsten Merkmale?" „Fragt Jeffrey Barr, ein Forscher bei IBM Research. „Ich würde einen nichtflüchtigen analogen Widerstandsspeicher wie einen Speicher mit Phasenwechsel, Memristoren usw. einsetzen. Die Idee ist, dass diese Geräte alle Multiplikationen für vollständig verbundene Schichten neuronaler Netze in einem Zyklus ausführen können. Bei einem Prozessorsatz kann dies eine Million Taktzyklen dauern, und bei einem analogen Gerät kann dies mithilfe der am Datenort arbeitenden Physik erfolgen. Es gibt genug sehr interessante Aspekte in Bezug auf Zeit und Energie, damit sich aus dieser Idee etwas mehr entwickelt. "
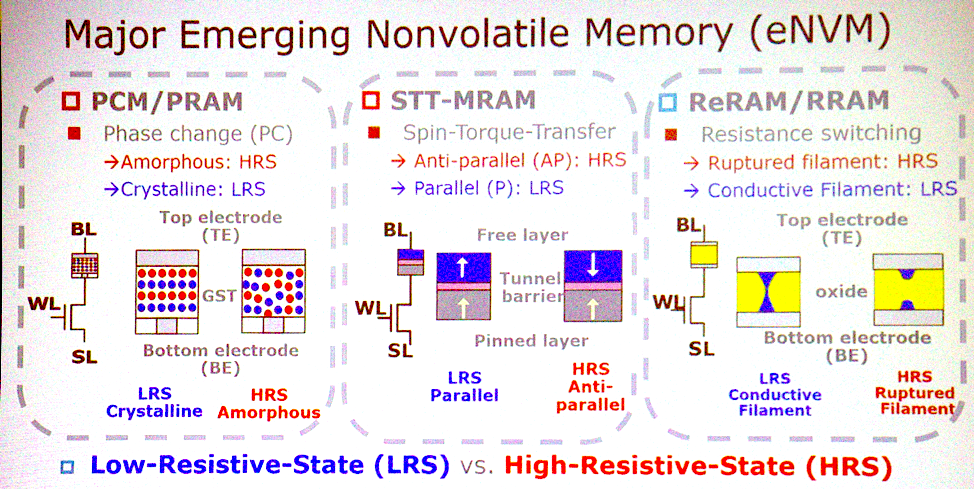 Neue Speichertechnologien
Neue SpeichertechnologienChen stimmt dem zu. „PCM, STT hat ernsthafte Angebote zu gewinnen. Diese drei Speichertypen sind gute Kandidaten für die Implementierung von In-Memory-Computing. Sie sind zu grundlegenden logischen Operationen fähig. Einige Arten haben Probleme mit der Zuverlässigkeit und können nicht für das Training verwendet werden, aber es ist möglich, eine Schlussfolgerung zu ziehen. "
Es kann sich jedoch herausstellen, dass es nicht erforderlich ist, in diesen Speicher zu wechseln. "Die Leute reden davon, SRAM genau für den gleichen Zweck zu verwenden", fügt Lee hinzu. "Sie machen analoges Rechnen mit SRAM." Der einzige Nachteil ist, dass der SRAM zu groß ist - 6 oder 8 Transistoren pro Bit. Daher ist es keine Tatsache, dass wir diese neuen Technologien im analogen Rechnen einsetzen werden. “
Der Übergang zum analogen Rechnen impliziert auch, dass die Genauigkeit der Berechnungen keine Notwendigkeit mehr sein wird. "AI ist spezialisiert, klassifiziert und prognostiziert", sagt er. "Er trifft Entscheidungen, die unhöflich sein können." In Sachen Genauigkeit können wir etwas aufgeben. Wir müssen feststellen, welche Berechnungen fehlerresistent sind. Dann können einige Technologien angewendet werden, um den Stromverbrauch zu reduzieren oder das Rechnen zu beschleunigen. Probabilistische CMOS arbeiten seit 2003. Dies beinhaltet das Verringern der Spannung bis zum Auftreten mehrerer Fehler, deren Anzahl tolerierbar bleibt. Bereits heute verwenden die Menschen ungefähre Berechnungstechniken wie die Quantisierung. Anstelle einer 32-Bit-Gleitkommazahl haben Sie 8-Bit-Ganzzahlen. Analoge Computer sind ein weiteres bereits erwähntes Merkmal. “
Verlasse das Labor
Die Verlagerung von Technologie aus dem Labor in die Öffentlichkeit kann eine Herausforderung sein. "Manchmal muss man nach Alternativen suchen", sagt Barr. - Als der zweidimensionale Flash-Speicher nicht gestartet wurde, schien der dreidimensionale Flash-Speicher keine so schwierige Aufgabe mehr zu sein. Wenn wir vorhandene Technologien weiter verbessern, hier und dort eine Verdoppelung der Eigenschaften erzielen, werden die analogen Berechnungen im Speicher aufgegeben. Wenn sich die folgenden Verbesserungen jedoch als unbedeutend herausstellen, sieht der analoge Speicher attraktiver aus. Als Forscher müssen wir auf neue Möglichkeiten vorbereitet sein. “
Die Wirtschaft verlangsamt häufig die Entwicklung, insbesondere im Bereich des Gedächtnisses, aber Barr sagt, dass dies in diesem Fall nicht passieren wird. „Einer unserer Vorteile ist, dass dieses Produkt nicht speicherbezogen ist. Es wird nicht etwas mit geringfügigen Verbesserungen sein. Dies ist kein Verbraucherprodukt. Dies ist eine Sache, die mit der GPU konkurriert. Sie werden zu einem Preis verkauft, der das 70-fache des DRAM-Preises beträgt. Es handelt sich also eindeutig um ein Nicht-Speicherprodukt. Und die Kosten des Produkts unterscheiden sich nicht wesentlich vom Speicher. Es hört sich gut an, aber wenn Sie Entscheidungen im Wert von Milliarden von Dollar treffen, sollten alle Kosten und der Produktentwicklungsplan glasklar sein. Um diese Barriere zu überwinden, müssen wir beeindruckende Prototypen liefern. “
CMOS-Ersatz
Die speicherinterne Datenverarbeitung kann beeindruckende Vorteile bieten, für die Implementierung der Technologie ist jedoch mehr erforderlich. Kann irgendein anderes Material außer CMOS dabei helfen? „Mit Blick auf den Übergang von verbrauchsarmen CMOS zu Tunnel-FETs sprechen wir von einer 1-2-fachen Verbrauchsreduzierung“, sagt Lee. - Eine andere Möglichkeit sind dreidimensionale integrierte Schaltkreise. Sie reduzieren die Kabellänge mit TSV. Dies reduziert sowohl den Stromverbrauch als auch die Latenz. Schauen Sie sich die Rechenzentren an, alle entfernen die Metallkabel und schließen die Optik an. "
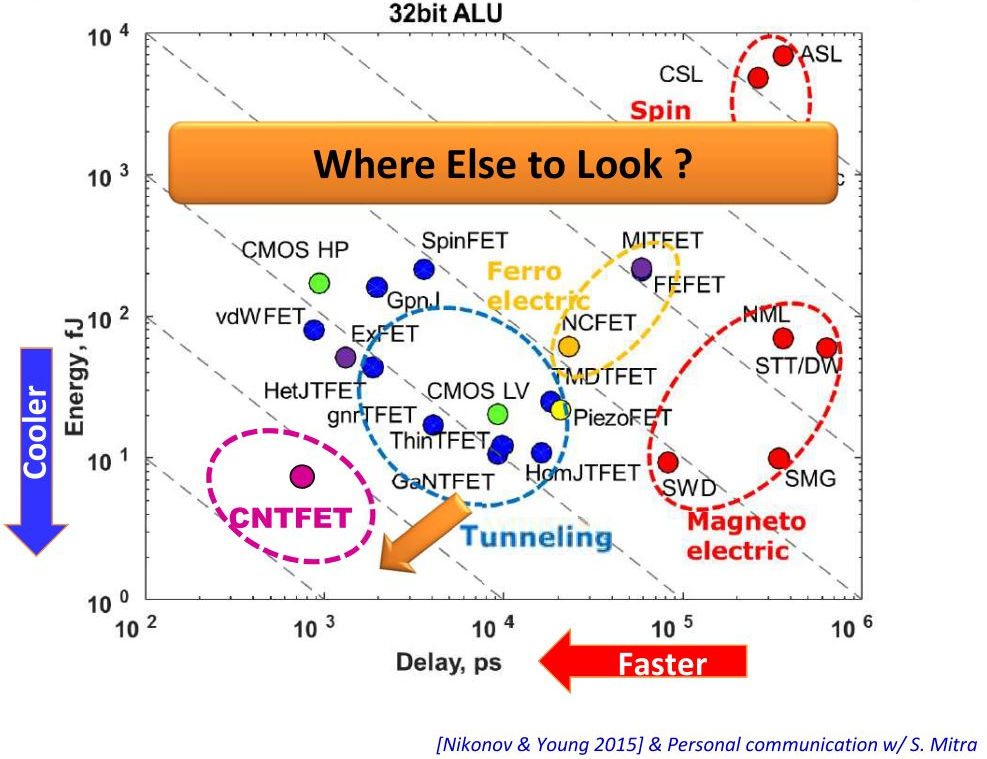 Vertikal - Stromverbrauch, horizontal - Geräteverzögerungen
Vertikal - Stromverbrauch, horizontal - GeräteverzögerungenObwohl Sie einige Vorteile erzielen können, wenn Sie auf eine andere Technologie umsteigen, sind sie möglicherweise nicht wert. "Es wird sehr schwierig sein, CMOS zu ersetzen, aber einige der besprochenen Geräte können die CMOS-Technologie ergänzen, sodass Berechnungen im Speicher durchgeführt werden", sagt Roy. - CMOS kann speicherinterne Berechnungen in analoger Form unterstützen, möglicherweise in Zelle 8T. Ist es möglich, eine Architektur mit einem klaren Vorteil gegenüber CMOS zu erstellen? Wenn alles richtig gemacht ist, gibt mir CMOS tausendfach mehr Energieeffizienz. Aber es braucht Zeit. “
CMOS wird eindeutig nicht ersetzt. „Neue Technologien werden die alten nicht ablehnen und nicht auf anderen Substraten als CMOS hergestellt werden“, schließt Barr.