
Wir haben zwei Ansätze für die Notfallwiederherstellung: einen "gestreckten" Cluster (Aktiv-Aktiv-Installation) und eine Plattform mit deaktivierten virtuellen Maschinen (Replikaten). Sie haben mehrere Punkte zum Speichern von Schnappschüssen.
Es gibt eine Anfrage nach Katastrophentoleranz, und viele unserer Kunden brauchen sie wirklich. Daher haben wir begonnen, beide Pläne im Rahmen unserer Produktion auszuarbeiten.
Methoden haben Vor- und Nachteile, jetzt erzähle ich Ihnen davon.
Gestreckter Cluster
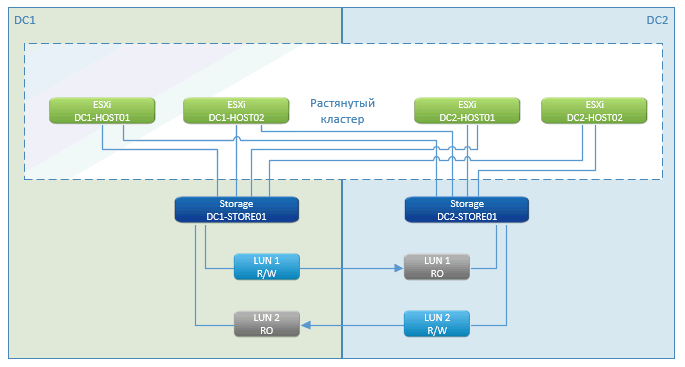
Wie Sie sehen können, handelt es sich hierbei um eine Standard-U-Bahn-Cluster-Story. Bei den Profis - fast keine Ausfallzeit, eine Pause nur zum Zeitpunkt des Starts der virtuellen Maschinen. Diese Funktion funktioniert - VMware High Availability (HA). Sie sieht, dass die Hosts verloren gehen, und startet die VM auf dem Remote-Standort sofort neu.
Der Start erfolgt sofort aus dem Speicher, der sich im Cluster befindet.
Die Speicherung mit einem geoverteilten Cluster ist eine Marketingfunktion von NetApp. Andere Hersteller haben etwas mit einem ähnlichen Namen. Im Wesentlichen handelt es sich hierbei um eine durchdachte asynchrone Replikation von einer Seite zur anderen. Wir schreiben auf einen Knoten im lokalen Netzwerk und synchronisieren über spezielle Kommunikationskanäle mit einem anderen.
Bei einem Ausfall eines der Speichersysteme zeigt der verbleibende (an einem anderen Standort) den Pfad zu den Festplatten den verbleibenden Hosts an. Abgestorbene VMs werden auf ihnen neu gestartet. Alles geschieht automatisch - das Rechenzentrum stürzte ab, alles wurde neu gestartet, der Speicher funktionierte, VMware funktionierte. Der Client sah, dass alles blinzelte und neu startete.
Der einzige Cache aus dem RAM der VM kann verloren gehen. Aber wenn die Datenbank es weggeworfen hat, ist der Verlust zeitlich Null.
Wenn wir die Kommunikation zwischen den Standorten verlieren, funktioniert alles an seinem Platz weiter und sobald die Verbindung wiederhergestellt ist, beginnt die Synchronisierung.
Der Nachteil ist der hohe Preis. Weil Sie tatsächlich eine doppelte SHD benötigen (außerdem ähnlich in Typ, Geschwindigkeit und Volumen der Festplatten der ersten SHD auf der Hauptwebsite), die nur als Reserve verwendet werden kann. Plus Bindung an den Speicher für den Metro-Cluster, das sind FC-Bridges, FC-Netzwerk und mehr.
Wir haben zwei DPCs, zwischen ihnen ein FC-Bündel entlang zweier Strahlen (vier dunkle Optiklinien und DWDM). Hierbei handelt es sich um zwei Eisenstücke, die jeweils eine Bandbreite von 200 Gbit / s für FC und Ethernet bieten.
Alternative mit DR

Es gibt Software mit einem intuitiv einprägsamen Namen - VMware vCloud Availability für Cloud-to-Cloud DR.
Dies ist ein System zum einmaligen Erstellen einer identischen VM an einem Remotestandort in 15 Minuten. Ein System, um all dies den Cloud-Kontrollmechanismen richtig darzustellen, ist auf Klebeband angebracht.
Das heißt, die VMware Replication-Technologie befindet sich im Backend. Im Falle eines Fehlers starten wir den DR-Plan manuell am zweiten Standort, er beendet automatisch den Replikationsversuch, registriert dann die VM in vCloud Director, passt die IP-Adressen an (damit sie nicht in die VM geändert werden muss) und startet die VM in der erforderlichen Reihenfolge. In unserer Lösung ist es nicht erforderlich, die Adressierung zu ändern. Wir dehnen die Netzwerke auf beide Rechenzentren aus.
Maschinen werden ständig repliziert, aber nicht das gesamte Rechenzentrum, sondern nur die ausgewählten sind kritische Prozesse. Es wird von Zeit zu Zeit repliziert, das Mindestintervall beträgt 15 Minuten (dies ist ein idealer Fall, wenn alles funktioniert und ein dedizierter Replikationsserver und ein Minimum an Änderungen an der VM vorhanden sind). In der Praxis haben Sie vor einer halben oder einer Stunde eine Kopie. Wenn etwas schief gelaufen ist, sind die Daten, die in das Intervall fielen, verloren gegangen. 15 Minuten ist die Frage des Agenten, der die neue Replikation sammelt. Laut Veeam können sie weniger als 15 Minuten dauern, in der Praxis ist es jedoch auch länger, wenn sie keine Speicherfunktionen verwenden. Ich habe auf einer Industriemaschine (nicht auf einem Test) nicht gesehen, dass es anders sein würde.
NetApp verfügt wie viele andere Hersteller von Speichersystemen lange Zeit über die SnapMirror-Technologie, mit der Sie die Replikationsarbeit von Hypervisoren auf Speichersysteme verlagern und von VMware Replication verwenden können.
Während der Replikationsdienst ausgeführt wird, fährt der Zug weit. Aber es ist billig.
Warum ist es immer noch billig - da Sie jeden Speicher auf jeder Seite (von verschiedenen Herstellern, verschiedenen Klassen) verwenden können, müssen Sie nicht im Voraus ein großes Volumen an Festplatten zuweisen.
Es ist nicht erforderlich, eine große Plattengruppe zuzuweisen, in die die Monde geschnitten werden. Es nimmt nur einen Platz im lokalen Speicher ein und wird aufgrund der Verfügbarkeit des Datensatzes von der virtuellen Maschine angewendet. Aus diesem Grund ist der Platz auf dem Speichersystem optimal belegt, wenn er für andere Aufgaben verwendet wird. Und es wird verwendet, da wir nicht allen Kunden einen solchen Service bieten.
Minus - Sie müssen die Replikation auf VM-Ebene konfigurieren, dh steuern, ob alles korrekt konfiguriert ist, dass dies der Computer ist, sicherstellen, dass die Replikation erfolgreich ist und keine Fehler vorliegen. Erstellen Sie DR-Pläne für jeden Kunden und führen Sie deren Tests durch.
Im ersten Fall wird die Speicherung bedingt, infrastrukturell, fast nach Sektoren (genauer gesagt nach Objekten) durchgeführt. Und dann kann eine Maschine aufgrund einer Aufgabe herunterfallen, die aufgrund einiger Software-Gründe im Zusammenhang mit einem Fehler auf hoher Ebene oder aufgrund von Problemen mit der Barrierefreiheit ausfällt. Dies passiert etwas häufiger, als wenn Sie nur niedrige Werte einnehmen.
In plus - DR werden mehrere Punkte gespeichert. Sie können einige Schnappschüsse zurücksetzen.
Außerhalb des Gastbetriebssystems benötigen Sie zusätzliche Software.
Um alle erforderlichen Netzwerke zu Vcloud Director zu bringen, benötigen wir die Arbeit unseres Administrators. Im Allgemeinen verbleibt die gesamte Netzwerkverbindung in dieser Version bei unserem Administrator. Für einen Cloud-Client bedeutet dies eine Anwendung, die auch Zeit braucht.
Die Replikation wird auch über die Anwendung konfiguriert. VM hinzugefügt - Sie müssen eine Anforderung senden, die Sie zum Replizieren benötigen. Es fällt nicht automatisch in Replikationsaufgaben. Es ist notwendig, den Administrator zu beachten.
Der Unterschied
Infolgedessen kann der Preis um mehr als das Zweifache abweichen. Durch die Replikation werden die Kosten für den Speicherplatz mit zwei oder mehr multipliziert (zwei vollständige Kopien + Änderungsverlauf) sowie etwas für den Dienst und die Reservierung von Computerressourcen. Im Fall des U-Bahn-Clusters werden die Platzkosten mit zwei multipliziert, aber der Platz selbst kostet erheblich mehr, und Sie müssen Knoten an einem entfernten Standort fest reservieren. Das heißt, Rechenressourcen müssen mit zwei multipliziert werden, wir können sie für nichts anderes verwenden.
Im Fall des Metro-Clusters können nur die gleichen Festplattentypen verwendet werden, sodass ein vollständiger Spiegel vorhanden ist. Wenn im Hauptdatenzentrum einige Laufwerke schnell sind, andere mit 10.000 Umdrehungen pro Minute langsam, ist eine identische Konfiguration erforderlich. Im Falle eines Replikats sind langsamere Festplatten am Sicherungsstandort möglich, was aufgrund des Speichers billiger ist. Wenn Sie jedoch zu einer Reserve wechseln, wird sich herausstellen, dass die Leistung geringer ist. Das heißt, wenn es etwas auf der SSD im Hauptcluster speichert und auf normale Festplatten repliziert wird, ist der Speicher auf Kosten der Verlangsamung der Reserveinfrastruktur viel billiger.
Im Moment wählen wir aus, was in einer früheren Version enthalten sein soll. Wir möchten daher Folgendes konsultieren: Können Sie uns kurz mitteilen, wie Sie Ihre DR-Sites organisieren und was sie im Allgemeinen tun sollen?