
Ich konnte als Student meinen Arbeitsplatz abholen. Logischerweise habe ich AMD-Computerlösungen bevorzugt. weil es billig profitabel in Bezug auf Preis / Qualität. Ich habe die Komponenten für eine lange Zeit aufgenommen, am Ende bin ich mit 40k mit einem Satz FX-8320 und RX-460 2GB eingestiegen. Anfangs schien dieses Kit perfekt zu sein! Mein Mitbewohner und ich haben Monero leicht abgebaut und mein Set zeigte 650 h / s gegenüber 550 h / s auf einem Set von i5-85xx und Nvidia 1050Ti. Von meinem Set im Raum war es zwar nachts etwas heiß, aber dies wurde entschieden, als ich einen Turmkühler für die CPU kaufte.
Die Geschichte ist vorbei
Alles war genau wie in einem Märchen, bis ich mich für maschinelles Lernen im Bereich Computer Vision interessierte. Noch genauer - bis ich mit Eingabebildern mit einer Auflösung von mehr als 100x100px arbeiten musste (bis zu diesem Punkt kam mein 8-Core-FX zügig zurecht). Die erste Schwierigkeit war die Aufgabe, Emotionen zu bestimmen. 4 ResNet-Ebenen, geben Sie Bilder 100x100 und 3000 Bilder in das Trainingsset ein. Und jetzt - 9 Stunden Training 150 Epochen auf der CPU.
Aufgrund dieser Verzögerung leidet natürlich der iterative Entwicklungsprozess. Bei der Arbeit hatten wir Nvidia 1060 6 GB und trainierten für eine ähnliche Struktur (obwohl dort die Regression trainiert wurde, um Objekte zu lokalisieren). Sie flog in 15 bis 20 Minuten - 8 Sekunden für eine Ära von 3,5.000 Bildern. Wenn Sie einen solchen Kontrast unter der Nase haben, wird das Atmen noch schwieriger.
Ratet mal, mein erster Schritt nach all dem? Ja, ich habe mit meinem Nachbarn 1050Ti verhandelt. Mit Argumenten über die Nutzlosigkeit von CUDA für ihn, mit einem Angebot, meine Karte gegen Aufpreis umzutauschen. Aber alles umsonst. Und jetzt poste ich meinen RX 460 auf Avito und überprüfe den geschätzten 1050Ti auf den Websites von Citylink und TechnoPoint. Selbst im Falle eines erfolgreichen Verkaufs der Karte müsste ich weitere 10.000 finden (ich bin ein Student, wenn auch ein funktionierender).
Google
Okay Ich werde googeln, wie man Radeon unter Tensorflow benutzt. Da ich wusste, dass dies eine exotische Aufgabe war, hoffte ich nicht besonders, etwas Vernünftiges zu finden. Sammeln Sie unter Ubuntu, ob es startet oder nicht, und holen Sie sich einen Ziegelstein - Sätze aus den Foren.
Und so bin ich in die andere Richtung gegangen - ich habe nicht Tensorflow AMD Radeon, sondern Keras AMD Radeon googelt. Es bringt mich sofort auf die Seite von PlaidML . Ich starte es in 15 Minuten (obwohl ich Keras auf 2.0.5 downgraden musste) und stelle das Netzwerk so ein, dass es lernt. Die erste Beobachtung - die Ära ist 35 Sekunden statt 200.
Klettern, um zu erkunden
Die Autoren von PlaidML sind vertex.ai , das Teil der Intel-Projektgruppe (!) Ist . Das Entwicklungsziel ist maximale plattformübergreifende. Dies erhöht natürlich das Vertrauen in das Produkt. In ihrem Artikel heißt es, dass PlaidML aufgrund "gründlicher Optimierung" mit Tensorflow 1.3 + cuDNN 6 konkurrenzfähig ist.
Wir fahren jedoch fort. Der folgende Artikel zeigt uns zum Teil die interne Struktur der Bibliothek. Der Hauptunterschied zu allen anderen Frameworks besteht in der automatischen Generierung von Berechnungskernen (in der Tensorflow-Notation ist der „Kern“ der vollständige Prozess der Ausführung einer bestimmten Operation in einem Diagramm). Für die automatische Kernelgenerierung in PlaidML sind die genauen Abmessungen aller Tensoren, Konstanten, Schritte, Faltungsgrößen und Grenzwerte, mit denen Sie später arbeiten müssen, sehr wichtig. Beispielsweise wird argumentiert, dass die weitere Erstellung effektiver Kernel für 1 und 32 Stapelgrößen oder für Windungen der Größen 3x3 und 7x7 unterschiedlich ist. Mit diesen Daten generiert das Framework selbst die effizienteste Methode zum Parallelisieren und Ausführen aller Vorgänge für ein bestimmtes Gerät mit bestimmten Merkmalen. Wenn Sie sich Tensorflow ansehen, müssen wir beim Erstellen neuer Operationen auch den Kernel für diese implementieren - und die Implementierungen sind für Single-Threaded-, Multi-Threaded- oder CUDA-kompatible Kernel sehr unterschiedlich . Das heißt, PlaidML ist deutlich flexibler.
Wir gehen weiter. Die Implementierung ist in der selbstgeschriebenen Sprache Tile geschrieben . Diese Sprache hat die folgenden Hauptvorteile - die Nähe der Syntax zu mathematischen Notationen (aber verrückt werden!):
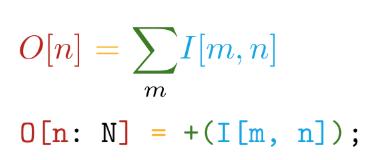
Und automatische Differenzierung aller deklarierten Operationen. In TensorFlow wird beispielsweise beim Erstellen einer neuen benutzerdefinierten Operation dringend empfohlen, eine Funktion zum Berechnen der Verläufe zu schreiben. Wenn wir also unsere eigenen Operationen in der Tile-Sprache erstellen, müssen wir nur sagen, WAS wir berechnen möchten, ohne darüber nachzudenken, wie dies in Bezug auf Hardwaregeräte zu berücksichtigen ist.
Zusätzlich wird eine Optimierung der Arbeit mit DRAM und einem Analogon des L1-Cache in der GPU durchgeführt. Rufen Sie das schematische Gerät auf:
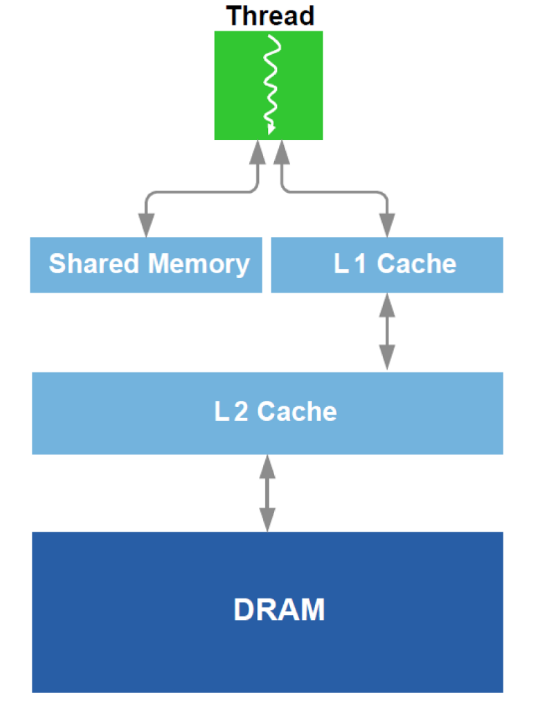
Zur Optimierung werden alle verfügbaren Daten über das Gerät verwendet - Cache-Größe, Cache-Zeilenbreite, DRAM-Bandbreite usw. Die Hauptmethoden bestehen darin, das gleichzeitige Lesen von ausreichend großen Blöcken aus dem DRAM sicherzustellen (ein Versuch, eine Adressierung an verschiedene Bereiche zu vermeiden) und zu erreichen, dass die in den Cache geladenen Daten mehrmals verwendet werden (ein Versuch, zu vermeiden, dass dieselben Daten mehrmals neu geladen werden).
Alle Optimierungen finden in der ersten Ära des Trainings statt und verlängern gleichzeitig die Zeit des ersten Laufs erheblich:
Darüber hinaus ist anzumerken, dass dieses Framework an OpenCL gebunden ist. Der Hauptvorteil von OpenCL ist, dass es ein Standard für heterogene Systeme ist und nichts Sie daran hindert, den Kernel auf der CPU auszuführen . Ja, hier liegt eines der Hauptgeheimnisse des plattformübergreifenden PlaidML.
Fazit
Natürlich ist das Training auf dem RX 460 immer noch 5-6 mal langsamer als auf dem 1060, aber Sie können die Preiskategorien von Grafikkarten vergleichen! Dann bekam ich einen RX 580 8 GB (sie liehen mir!) Und die Zeit, die für die Ausführung der Ära benötigt wurde, wurde auf 20 Sekunden reduziert, was fast vergleichbar ist.
Der vertex.ai-Blog enthält ehrliche Grafiken (mehr ist besser):
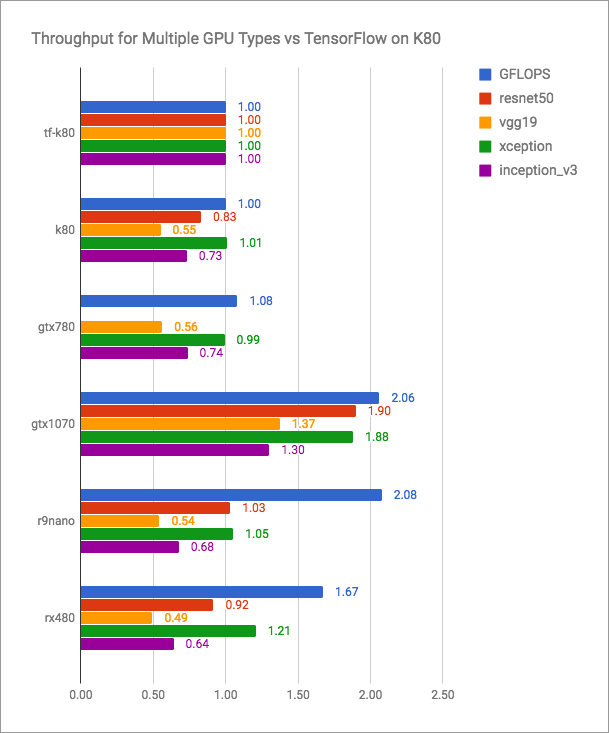
Es ist ersichtlich, dass PlaidML mit Tensorflow + CUDA konkurrenzfähig ist, für aktuelle Versionen jedoch sicherlich nicht schneller. Aber PlaidML-Entwickler planen wahrscheinlich nicht, in einen so offenen Kampf einzutreten. Ihr Ziel ist Universalität, plattformübergreifend.
Ich werde hier eine nicht ganz vergleichende Tabelle mit meinen Leistungsmessungen hinterlassen:
| Computergerät | Laufzeit der Ära (Batch - 16), s |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2 GB Plaid | 35 |
| RX 580 8 GB Plaid | 20 |
| 1060 6 GB TF | 8 |
| 1060 6 GB Plaid | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 Plaid | 240 |
| GT 640 Plaid | 46 |
Der neueste vertex.ai-Blogbeitrag und die neuesten Änderungen am Repository sind vom Mai 2018. Es scheint, dass wenn die Entwickler dieses Tools nicht aufhören, neue Versionen zu veröffentlichen, und immer mehr Leute, die von Nvidia beleidigt sind, mit PlaidML vertraut sind, sie viel häufiger über vertex.ai sprechen werden.
Entdecken Sie Ihre Radeons!