
Der zweite Tag des Hauptprogramms von KDD. Wieder unter dem Schnitt viele interessante Dinge: vom maschinellen Lernen auf Pinterest bis zu verschiedenen Möglichkeiten, in Wasserleitungen zu graben. Einschließlich der Rede des Nobelpreisträgers für Wirtschaftswissenschaften - eine Geschichte darüber, wie die NASA mit Telemetrie arbeitet, und viele Einbettungen von Graphen :)
Marktdesign und computergestützter Marktplatz
Eine gute Leistung des
Nobelpreisträgers, der mit Shapley auf Märkten zusammengearbeitet hat. Der Markt ist eine künstliche Sache, deren Gerät sich die Leute einfallen lassen. Es gibt sogenannte Rohstoffmärkte, wenn Sie ein bestimmtes Produkt kaufen und es Ihnen egal ist, wer, es ist nur zu welchem Preis wichtig (zum Beispiel die Börse). Und es gibt passende Märkte, in denen der Preis nicht der einzige Faktor ist (und manchmal überhaupt nicht).
Zum Beispiel die Verteilung von Kindern in Schulen. Früher funktionierte das Programm in den USA folgendermaßen: Eltern schreiben die Liste der Schulen nach Priorität auf (1, 2, 3 usw.), Schulen betrachten zunächst diejenigen, die sie als Nummer 1 angegeben haben, sortieren sie nach ihren Schulkriterien und nehmen so viel wie möglich . Für diejenigen, die nicht getroffen haben, nehmen wir die zweite Schule und wiederholen den Vorgang. Aus Sicht der Spieltheorie ist das Schema sehr schlecht: Eltern müssen sich „strategisch“ verhalten, es ist unpraktisch, ihre Vorlieben ehrlich zu sagen - wenn Sie in der zweiten Runde nicht in die Schule 1 kommen, ist die Schule 2 möglicherweise bereits voll und Sie werden nicht in die Schule kommen. selbst wenn Ihre Eigenschaften höher sind als diejenigen, die in der ersten Runde akzeptiert wurden. In der Praxis führt Missachtung der Spieltheorie zu Korruption und internen Vereinbarungen zwischen Eltern und Schulen. Mathematiker haben einen anderen Algorithmus vorgeschlagen - "verzögerte Akzeptanz". Die Hauptidee ist, dass die Schule nicht sofort ihre Zustimmung erteilt, sondern einfach eine Rangliste der Kandidaten „im Gedächtnis“ behält. Wenn jemand über den Schwanz hinausgeht, erhält er sofort eine Ablehnung. In diesem Fall gibt es eine vorherrschende Strategie für die Eltern: Zuerst gehen wir zur Schule 1, wenn wir irgendwann eine Ablehnung bekommen, dann gehen wir zur Schule 2 und haben keine Angst, etwas zu verlieren - die Chancen, zur Schule 2 zu gelangen, sind die gleichen, als ob wir dorthin gegangen wären sofort. Dieses Schema wurde jedoch „in der Produktion“ implementiert. Die Ergebnisse des A / B-Tests wurden nicht berichtet.
Ein weiteres Beispiel ist die Nierentransplantation. Im Gegensatz zu vielen anderen Organen können Sie mit einer Niere leben, sodass häufig die Situation auftritt, dass jemand bereit ist, einer anderen Person eine Niere zu geben, jedoch keine abstrakte, sondern eine bestimmte (aufgrund persönlicher Beziehungen). Die Wahrscheinlichkeit, dass Spender und Empfänger kompatibel sind, ist jedoch sehr gering, und Sie müssen auf ein anderes Organ warten. Es gibt eine Alternative - den Nierenaustausch. Wenn zwei Paare ein Spender und ein Empfänger sind und innen nicht kompatibel sind, aber zwischen den Paaren kompatibel sind, können Sie Folgendes austauschen: 4 gleichzeitige Extraktions- / Implantationsvorgänge. Das System funktioniert bereits dafür. Und wenn es ein „freies“ Organ gibt, das nicht an ein bestimmtes Paar gebunden ist, kann dies zu einer ganzen Austauschkette führen (in der Praxis gab es Ketten mit bis zu 30 Transplantationen).
Mittlerweile gibt es viele ähnliche Matching-Märkte: von Uber bis zum Online-Werbemarkt, und aufgrund der Computerisierung ändert sich alles sehr schnell. Unter anderem ändert sich die „Privatsphäre“ stark: Als Beispiel zitierte der Redner eine Studie eines Studenten, die zeigte, dass in den USA nach den Wahlen die Anzahl der Reisen zu Thanksgiving aufgrund von Reisen zwischen Staaten mit unterschiedlichen politischen Ansichten zurückging. Die Studie wurde an einem anonymen Datensatz von Telefonkoordinaten durchgeführt, aber der Autor identifizierte recht leicht das „Zuhause“ des Telefonbesitzers deanonymisierter Datensatz.
Unabhängig davon ging der Redner auf technologische Arbeitslosigkeit ein. Ja, unbemannte Autos werden viele von ihnen berauben (6% der Arbeitsplätze in den USA sind gefährdet), aber sie werden neue Arbeitsplätze schaffen (für Automechaniker). Natürlich kann der ältere Fahrer nicht mehr umschulten und für ihn ist es ein schwerer Schlag. In solchen Momenten müssen Sie sich nicht darauf konzentrieren, wie Sie Änderungen verhindern können (es wird nicht funktionieren), sondern darauf, wie Sie den Menschen helfen können, so schmerzlos wie möglich durchzukommen. In der Mitte des letzten Jahrhunderts, während der Mechanisierung der Landwirtschaft, haben viele Menschen ihren Arbeitsplatz verloren, aber wir sind froh, dass jetzt die Hälfte der Bevölkerung nicht mehr auf dem Feld arbeiten muss? Leider handelt es sich hier nur um implementierte Minderungsoptionen für diejenigen, die mit technologischer Arbeitslosigkeit konfrontiert sind. Der Redner schlug nicht vor ...
Und ja, noch einmal über Fairness. Es ist unmöglich, die Verteilung des Prognosemodells in allen Gruppen gleich zu machen, da das Modell seine Bedeutung verliert. Was kann theoretisch getan werden, damit die Verteilung der FEHLER der ersten und zweiten Art für alle Gruppen gleich ist? Es sieht schon viel vernünftiger aus, aber wie dies in der Praxis erreicht werden kann, ist nicht klar. Er gab einen Link zu einem interessanten Artikel über die Rechtspraxis - in den USA entscheidet ein Richter
auf der Grundlage der ML-Prognose , ob er gegen Kaution freigelassen werden soll.
Empfehlungen I.
Ich war im Zeitplan verwirrt und kam zu der falschen Rede, aber immer noch zum Thema - dem ersten Block über Empfehlungssysteme.
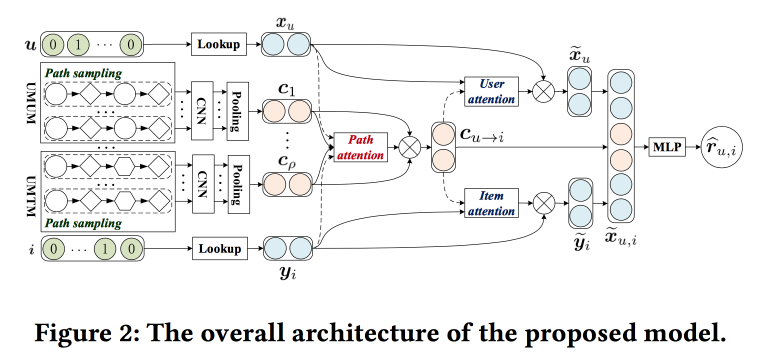
Nutzung des Meta-Pfad-basierten Kontexts für die Top-N-Empfehlung mit Co-Attention-Mechanismus
Die Jungs versuchen, die Empfehlungen
zu verbessern , indem sie die Pfade in der Grafik analysieren. Die Idee ist ganz einfach. Es gibt einen „klassischen“ Empfehlungsgeber für neuronale Netze mit Einbettungen für Objekte und Benutzer und einem vollständig verbundenen Teil darüber. Das Diagramm enthält Empfehlungen, einschließlich solcher mit Markups für neuronale Netze. Versuchen wir, all dies in einem Mechanismus zu kombinieren. Beginnen wir mit der Erstellung eines „Meta-Graphen“, der Benutzer, Filme und Attribute (Schauspieler / Regisseur / Genre usw.) vereint. Auf dem Zufalls-Walk-Om-Graphen werden eine Reihe von Pfaden abgetastet, dem Faltungsnetzwerk zugeführt, Benutzereinbettungen an der Seite und hinzugefügt Objekt, und darüber setzen wir Aufmerksamkeit (hier ein wenig knifflig, mit seinen eigenen Eigenschaften für verschiedene Zweige). Um die endgültige Antwort zu erhalten, legen Sie ein Perzeptron mit zwei versteckten Schichten darauf.
Consumer-Internetanwendungen
In der Pause zwischen den Berichten gehe ich zu der Präsentation über, in der ich ursprünglich wollte: Gastredner von LinkedIn, Pinterest und Amazon sprechen hier. Alle Mädchen und alle Leiter der DS-Abteilungen.
Neraline Contextual Recommentations für aktive Communities LinkedIn
Das Endergebnis ist , die Entwicklung und Aktivierung der Community auf LinkedIn zu fördern. Ich habe die Hälfte der Entwicklung verpasst, die letzte Empfehlung: lokale Muster auszunutzen. In Indien beispielsweise versuchen Studenten nach dem Abschluss häufig, Absolventen derselben Universität aus früheren Kursen mit einer etablierten Karriere zu kontaktieren. LinkedIn berücksichtigt dies beim Erstellen und bei der Abgabe von Empfehlungen.
Es reicht jedoch nicht aus, nur eine Community zu erstellen. Es ist eine Aktivität erforderlich: Benutzer veröffentlichen Inhalte, erhalten und geben Feedback. Zeigen Sie die Korrelation des erhaltenen Feedbacks mit der Anzahl der zukünftigen Veröffentlichungen. Zeigen Sie, wie die Informationen im gesamten Diagramm kaskadiert werden. Was aber, wenn ein Knoten nicht an der Kaskade beteiligt ist? Benachrichtigung senden!
Dann gab es viele Gespräche mit der gestrigen Geschichte über die Arbeit mit Benachrichtigungen und dem Band. Hier verwenden sie auch den Mehrzweckoptimierungsansatz "Maximieren einer der Metriken, während die anderen innerhalb bestimmter Grenzen gehalten werden". Um die Last zu kontrollieren, haben wir unser Air Trafic Control-System eingeführt, das die Last der Benachrichtigungen pro Benutzer begrenzt (sie konnten Abmeldungen und Beschwerden um 20% reduzieren, ohne das Engagement zu verlieren). ATC entscheidet, ob ein Push an den Benutzer gesendet werden kann oder nicht, und dieser Push wird von einem anderen System namens Concourse vorbereitet, das im Streaming-Modus arbeitet (wie bei uns auf
Samza !). Es war über sie, dass gestern viel erzählt wurde. Concourse hat auch einen Offline-Partner namens Beehive, der jedoch nach und nach zunehmend gestreamt wird.
Noch ein paar Punkte:
- Die Dedupilierung ist wichtig und von hoher Qualität, da viele Kanäle und Inhalte vorhanden sind.
- Es ist wichtig, eine Plattform zu haben. Und sie haben ein engagiertes Plattformteam, und Programmierer arbeiten dort.
Pinterest Ansatz zum maschinellen Lernen
Ein Pinterest-
Sprecher spricht und spricht jetzt über zwei große Aufgaben, die ML verwenden - Feed (Homefeed) und Suche. Der Redner sagt sofort, dass das Endprodukt das Ergebnis der Arbeit nicht nur von Datenwissenschaftlern, sondern auch von ML-Ingenieuren und Programmierern ist - allen wurden Menschen zugewiesen.
Das Band (die Situation, in der keine Benutzerabsicht besteht) wird gemäß dem folgenden Modell erstellt:
- Wir verstehen den Benutzer - wir verwenden Informationen aus dem Profil, dem Diagramm, der Interaktion mit den Pins (die ich gesehen habe, die ich getreten habe), wir erstellen Einbettungen nach Verhalten und Attributen.
- Wir verstehen den Inhalt - wir betrachten ihn in allen Aspekten: visuell, textuell, wer ist der Autor, welche Boards engagieren sich, wer reagiert. Es ist sehr wichtig, sich daran zu erinnern, dass Menschen auf einem Bild oft unterschiedliche Dinge sehen: Jemand hat einen blauen Akzent im Design, jemand hat einen Kamin und jemand hat eine Küche.
- Alles zusammen - ein dreistufiges Verfahren: Wir generieren Kandidaten (Empfehlungen + Abonnements), personalisieren sie (mithilfe des Ranking-Modells) und mischen sie gemäß Richtlinien und Geschäftsregeln.
Für Empfehlungen verwenden sie einen zufälligen Spaziergang unter dem User-Board-Pin-Diagramm. Sie führen PinSage ein, über das sie
gestern gesprochen haben . Die Personalisierung hat sich von der Zeitsortierung über ein lineares Modell und GBDT zu einem neuronalen Netzwerk entwickelt (seit 2017). Beim Sammeln der endgültigen Liste ist es wichtig, die Geschäftsregeln nicht zu vergessen: Frische, Vielfalt, zusätzliche Filter. Wir haben mit Heuristiken begonnen und bewegen uns nun in Richtung des gesamten Kontextoptimierungsmodells in Bezug auf Ziele.
In einer Suchsituation (wenn es eine Absicht gibt) bewegen sie sich etwas anders: Sie versuchen, die Absicht besser zu verstehen. Verwenden Sie dazu das Abfrageverständnis und die Abfrageerweiterungstechniken. Die Erweiterung erfolgt nicht nur durch automatische Vervollständigung, sondern auch durch eine schöne visuelle Navigation. Sie verwenden verschiedene Techniken für die Arbeit mit Bildern und Texten. Wir haben 2014 ohne tiefes Lernen begonnen, 2015 die visuelle Suche mit tiefem Lernen gestartet, 2016 die Objekterkennung mit semantischer Analyse und Suche hinzugefügt und kürzlich den Objektivdienst gestartet - Sie richten die Kamera des Smartphones auf das Motiv und erhalten Stecknadeln. Beim Deep Learning verwenden sie aktiv Multi-Task: Es gibt einen gemeinsamen Block, der die Bildeinbettung erstellt. und andere Netzwerke an der Spitze, um verschiedene Probleme zu lösen.
Zusätzlich zu diesen Aufgaben wird ML viel häufiger verwendet, wenn: Benachrichtigungen / Werbung / Spam / Prognosen usw.
Ein wenig über die gewonnenen Erkenntnisse:
- Wir müssen uns an Vorurteile erinnern, eine der gefährlichsten „Reichen werden reicher“ (die Tendenz des maschinellen Lernens, Verkehr auf bereits beliebte Objekte zu übertragen).
- Es ist obligatorisch zu testen und zu überwachen: Bei der Implementierung des Rasters wurden zunächst alle Indikatoren stark reduziert, dann stellte sich heraus, dass die Verteilung der Funktionen aufgrund der Fehlerverteilung lange Zeit verschoben war und Lücken online erschienen.
- Infrastruktur und Plattform sind sehr wichtig, mit besonderem Schwerpunkt auf der Bequemlichkeit und Parallelisierung von Experimenten. Sie müssen jedoch in der Lage sein, Experimente offline abzuschneiden.
- Metriken und Verständnis: Offline garantiert nicht online, aber für die Interpretation von Modellen stellen wir Werkzeuge her.
- Aufbau eines nachhaltigen Ökosystems: In Bezug auf den Müllfilter und den Clickbait sollten Sie der Benutzeroberfläche und dem Modell ein negatives Feedback hinzufügen.
- Denken Sie daran, eine Ebene zum Einbetten von Geschäftsregeln zu haben.
Breites Wissensdiagramm von Amazon
Jetzt spielt ein
Mädchen von Amazon.
Es gibt Wissensdiagramme - Entitätsknoten, Attributkanten usw. -, die beispielsweise in Wikipedia automatisch erstellt werden. Sie helfen, viele Probleme zu lösen. Wir möchten etwas Ähnliches für Produkte erhalten, aber es gibt viele Probleme damit: Es gibt keine strukturierten Eingabedaten, Produkte sind dynamisch, es gibt viele Aspekte, die nicht in das Wissensgraphmodell passen (es ist meiner Meinung nach umstritten, eher „nicht ohne ernsthafte Komplikation der Struktur lügen "), Viele vertikale und" unbenannte Entitäten ". Als das Konzept an das Management "verkauft" wurde und die Genehmigung erhielt, sagten die Entwickler, es sei ein "Projekt für hundert Jahre", und als Ergebnis schafften sie es in 15 Mannmonaten.
Wir haben zunächst Entitäten aus dem Amazon-Verzeichnis extrahiert: Hier gibt es eine Art Struktur, obwohl sie Crowdsourcing und schmutzig ist. Als nächstes verbanden sie OpenTag (gestern ausführlicher beschrieben) für die Textverarbeitung. Und die dritte Komponente war Ceres - ein Tool zum Parsen aus dem Web unter Berücksichtigung des DOM-Baums. Die Idee ist, dass Sie durch Kommentieren einer der Seiten der Site den Rest leicht analysieren können - schließlich werden alle von einer Vorlage generiert (aber es gibt viele Nuancen). Zu diesem Zweck haben wir das Vertex-Markup-System verwendet (das 2011 von Amazon gekauft wurde). Es erstellt ein Markup-System, auf dessen Grundlage eine Reihe von xpath erstellt wird, um Attribute zu isolieren, und die logistische Regression bestimmt, welche auf einer bestimmten Seite anwendbar sind. Verwenden Sie eine zufällige Gesamtstruktur, um Informationen von verschiedenen Standorten zusammenzuführen. Sie verwenden auch aktives Training, komplexe Seiten werden zur manuellen Neukennzeichnung gesendet. Am Ende überwachen sie die Wissensreinigung - ein einfacher Klassifikator, zum Beispiel eine Marke / keine Marke.
Als nächstes ein wenig fürs Leben. Sie unterscheiden zwei Arten von Zielen. Roofshots sind die kurzfristigen Ziele, die wir durch die Bewegung des Produkts erreichen, und Moonshots sind die Ziele, mit denen wir die Grenzen und die globale Führung überschreiten.
Einbettungen und Vertreter
Nach dem Mittagessen ging ich zu dem Abschnitt über das Erstellen von Einbettungen, hauptsächlich für Diagramme.
Ähnliche Übungen mit einer einheitlichen semantischen Darstellung finden
Die Jungs
lösen das Problem, ähnliche Aufgaben in einem chinesischen Online-Lernsystem zu finden. Zuweisungen werden durch Text, Bilder und eine Reihe verwandter Kontsetov beschrieben. Der Beitrag der Entwickler besteht darin, Informationen aus diesen Quellen zusammenzuführen. Faltungen werden für Bilder gemacht, Einbettungen werden für Konzepte trainiert, ebenso für Wörter. Worteinbettungen werden zusammen mit Informationen zu Konzepten und Bildern an das auf Aufmerksamkeit basierende LSTM übergeben. Holen Sie sich eine Darstellung des Jobs.

Der oben beschriebene Block wird in ein siamesisches Netzwerk umgewandelt, in dem auch Aufmerksamkeit hinzugefügt wird und am Ausgang eine Ähnlichkeitsbewertung.
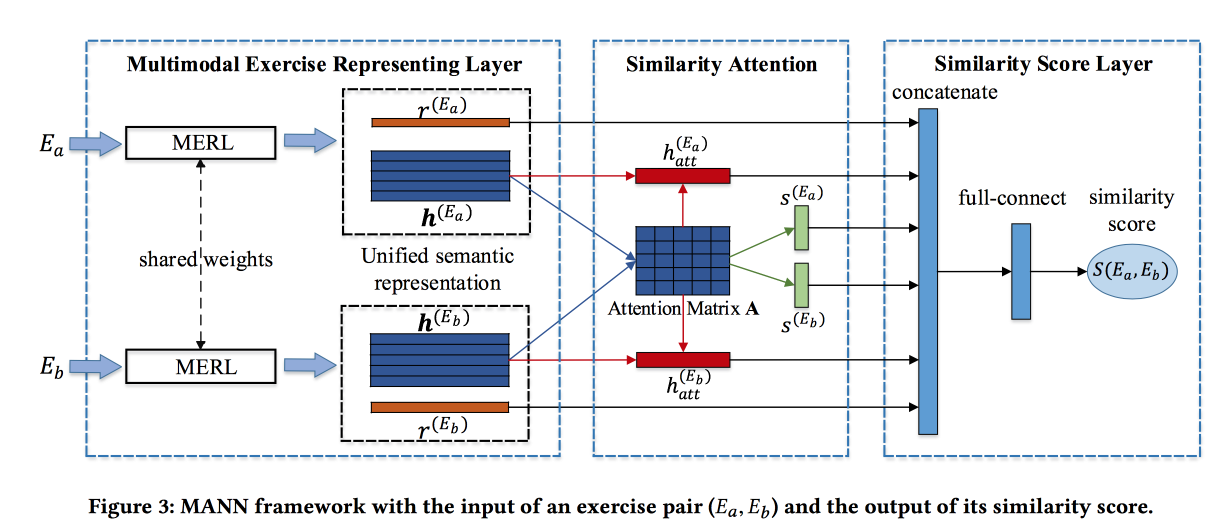
Sie unterrichten an einem markierten Datensatz von 100.000 Übungen und 400.000 Paaren (insgesamt 1,5 Millionen Übungen). Fügen Sie hartes Negativ hinzu, indem Sie Übungen mit denselben Konzepten abtasten. Aufmerksamkeitsmatrizen können dann verwendet werden, um Ähnlichkeit zu interpretieren.
Proximity Preservity Network Embedding beliebiger Ordnung
Die Jungs
bauen eine sehr interessante Variante von Einbettungen für Grafiken. Erstens werden Methoden, die auf Spaziergängen und auf der Basis von Nachbarn basieren, dafür kritisiert, dass sie sich auf die „Nähe“ eines bestimmten Niveaus konzentrieren (entsprechend der Länge des Spaziergangs). Sie bieten eine Methode, die die Nähe der gewünschten Reihenfolge und mit kontrollierten Gewichten berücksichtigt.
Die Idee ist sehr einfach. Nehmen wir eine Polynomfunktion und wenden sie auf die Adjazenzmatrix des Graphen an, und wir faktorisieren das Ergebnis durch SVD. In diesem Fall ist der Grad eines bestimmten Elements des Polynoms der Grad der Nähe, und das Gewicht dieses Elements ist der Einfluss dieses Niveaus auf das Ergebnis. Natürlich ist diese wilde Idee nicht realisierbar: Nachdem die Adjazenzmatrix auf eine Potenz angehoben wurde, wird sie dichter, passt nicht in das Gedächtnis und Sie faktorisieren eine solche Figur.
Ohne Mathematik ist es Müll, denn wenn Sie die Polynomfunktion NACH der Erweiterung auf das Ergebnis anwenden, erhalten wir genau das Gleiche, als ob die Erweiterung auf eine große Matrix angewendet würde. Eigentlich nicht wirklich. Wir betrachten SVD ungefähr und lassen nur die obersten Eigenwerte, aber nach dem Anwenden des Polynoms kann sich die Reihenfolge der Eigenwerte ändern, sodass Sie Zahlen mit einem Rand nehmen müssen.

Der Algorithmus besticht durch seine Einfachheit und zeigt beeindruckende Ergebnisse bei der Verbindungsvorhersage.

NetWalk: Ein flexibler Deep Embedding-Ansatz zur Erkennung von Anomalien in dynamischen Netzwerken
Wie der Name schon sagt, werden
wir die grafischen Einbettungen basierend auf Spaziergängen
erstellen . Aber nicht nur, sondern im Streaming-Modus, da wir das Problem der Suche nach Anomalien in dynamischen Netzwerken lösen (gestern wurde an diesem Thema gearbeitet). Um die Einbettungen schnell zu lesen und zu aktualisieren, verwenden sie das Konzept eines „
Reservoirs “, in dem ein Beispiel des Diagramms liegt und das stochastisch aktualisiert wird, wenn Änderungen eingehen.
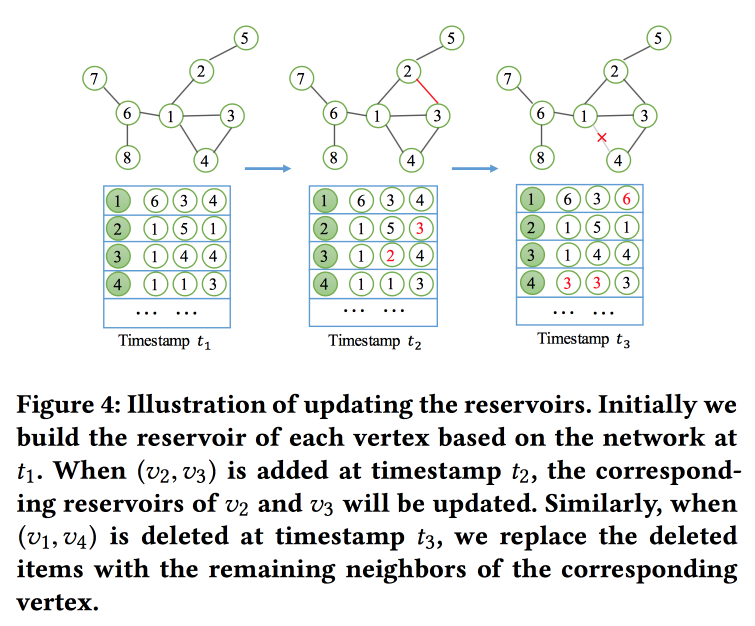
Für das Training formulieren sie eine ziemlich komplizierte Aufgabe mit mehreren Zielen. Die wichtigsten sind die Nähe der Einbettungen für Knoten in einem Pfad und die minimalen Fehler beim Wiederherstellen des Netzwerks mit einem Auto-Encoder.
Hierarchische taxonomiebewusste Netzwerkeinbettung
Eine weitere
Option zum Erstellen von Einbettungen für ein Diagramm, diesmal basierend auf einem probabilistischen Generierungsmodell. Die Qualität von Einbettungen wird durch die Verwendung von Informationen aus einer hierarchischen Taxonomie verbessert (z. B. eine Wissensdomäne für Zitierungsnetzwerke oder eine Produktkategorie für Produkte in E-Tail). Der Generierungsprozess basiert auf einigen "Themen", von denen einige an Knoten in einer Taxonomie und einige an einen bestimmten Knoten gebunden sind.
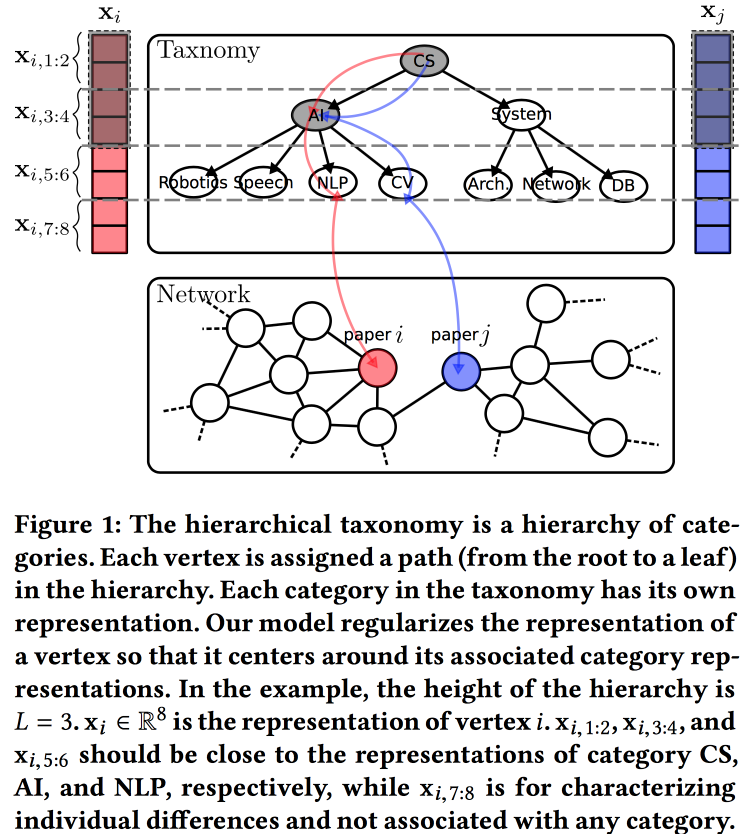
Wir assoziieren die a priori Normalverteilung mit einem Nullmittelwert mit den Parametern der Taxonomie, den Parametern eines bestimmten Scheitelpunkts in der Taxonomie - die Normalverteilung mit dem Durchschnitt gleich dem Taxonomieparameter und die Normalverteilung mit dem Nullmittelwert und der unendlichen Streuung für die freien Parameter des Scheitelpunkts. Wir erzeugen die Umgebung des Scheitelpunkts mithilfe der Bernoulli-Verteilung, wobei die Erfolgswahrscheinlichkeit proportional zur Nähe der Parameter der Knoten ist. Wir optimieren diesen gesamten Koloss mit dem
EM-Algorithmus .
Deep Recursive Network Embedding mit regelmäßiger Äquivalenz
Gängige Einbettungstechniken funktionieren nicht für alle Aufgaben. Betrachten Sie beispielsweise die Rolle einer Knotenaufgabe. Um die Rolle zu bestimmen, sind nicht bestimmte Nachbarn (die normalerweise betrachtet werden) wichtig, sondern die Diagrammstruktur in der Nähe des Scheitelpunkts und einige Muster darin. Gleichzeitig ist es sehr schwierig, diese Muster (reguläre Äquivalenz) direkt algorithmisch zu suchen, aber für große Graphen ist dies unrealistisch.
Deshalb werden wir den
anderen Weg gehen . Für jeden Knoten berechnen wir die mit seinem Diagramm verknüpften Parameter: Grad, Dichte, verschiedene Zentralitäten usw. Einbettungen können nicht allein darauf aufgebaut werden, aber Rekursion kann verwendet werden, da das Vorhandensein desselben Musters impliziert, dass die Attribute der Nachbarn von zwei Knoten mit derselben Rolle ähnlich sein sollten. Das heißt, Sie können mehr Ebenen stapeln.
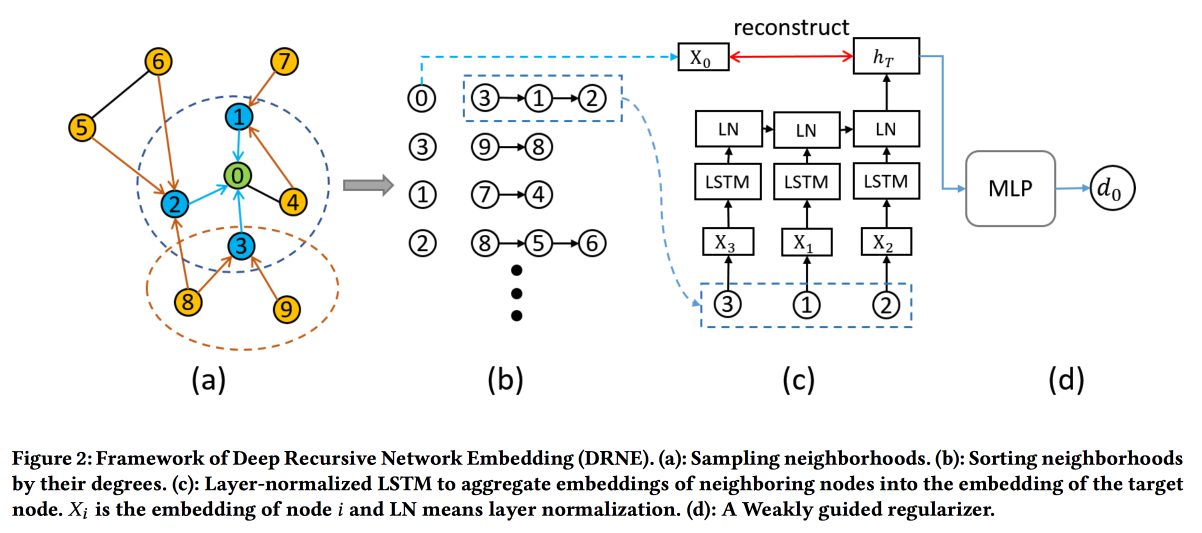
Validierungen zeigen, dass sie bei vielen Aufgaben die Standardbasislinien von DeepWalk und node2wek umgehen.
Einbettung des zeitlichen Netzwerks über die Nachbarschaftsbildung
Die neueste Arbeit zum Einbetten von Graphen für heute. Dieses Mal werden wir uns die Dynamik ansehen: Wir werden sowohl den Moment der Verbindung als auch alle Fakten der Interaktion in der Zeit bewerten. Nehmen Sie als Beispiel das Zitierungsnetzwerk, in dem Interaktion eine gemeinsame Veröffentlichung ist.
Wir verwenden den Hawkes-Prozess, um zu modellieren, wie sich vergangene Scheitelpunktinteraktionen auf ihre zukünftigen Interaktionen auswirken. HP . attention . log likelihood . .
Safety
. , . , ML , , .
Using Machine Learning to Assess the Risk of and Prevent Water Main Breaks
: , , — . , . , ( - , ), 1-2 % . ,
.
data miner-
Data Science for Social Good . , , :

, . : , GBDT. -1 % .
base line-: « » , , « , » . ML, , .
27 32- , , , ( , — ). , $1,2 .
, , , 1940-, , ( ) .
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
NASA
( ). — . , . , .
ML . LSTM , . ( , ). , , . , . , .
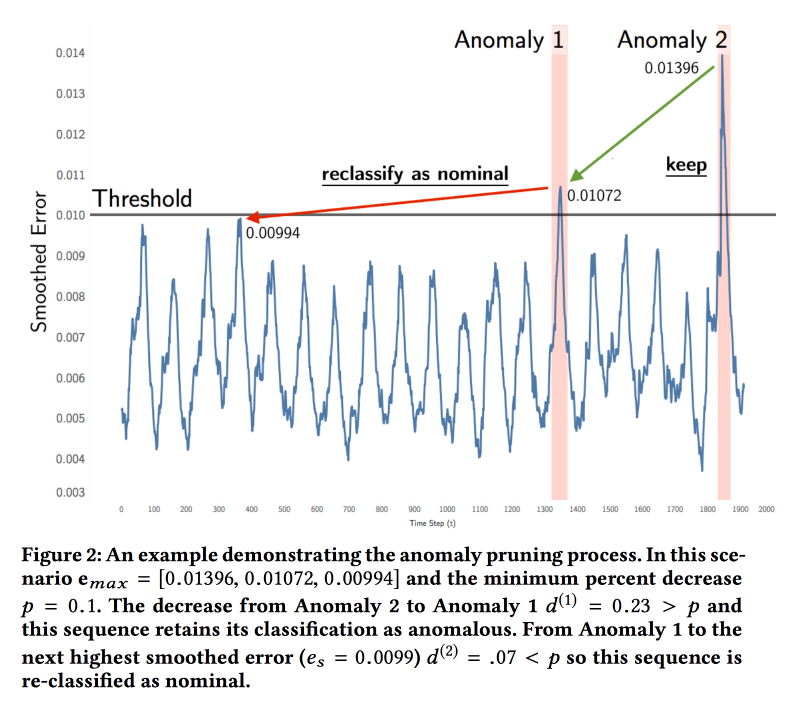
:
soil moisture active passive Curiosity c Mars Science Laboratory. 122 , 80 %. , , . , , .
Explaining Aviation Safety Incidents Using Deep Temporal Multiple Instance Learning
, , . Safety Incidents, , . , . .
, - , . «», .. , . , , . , , .
GRU ,
Multiple Instances Learning . , «» — , . « , , — » ( = ). max pooling .

cross entropy loss . base line
MI-SVM ADOPT.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
, ,
.
. 120 . , 2013 , : . , 2014-. 2015- — . , . , …
— , . , . .
. «», . : , , , . , , — , …
6 . , 20 %. data scientist-.
, 19 , , , . , « ». , , XGBoost - . ( 7 % , ).
Die Behörden wagten es nicht, Modelle gemäß der Prognose zu graben, aber sie gaben den Jungs eine Schmutzpumpe, die mit relativ geringem Schaden an die Rohre gelangen konnte, um zu überprüfen, ob Kupfer oder Blei vorhanden waren. Mit dieser Maschine begannen die Jungs "aktives Lernen" zu üben und waren von der Effektivität des Modells überzeugt. Nach einer nachträglichen Analyse der Daten haben wir festgestellt, dass die Verwendung des Modells in einem aktiven Lernformat die Kostenüberschreitung von 16% auf 3% reduzieren würde. Darüber hinaus stellten sie fest, dass die Behörden im Umgang mit Wissenschaftlern ihre Einstellung zu den Daten erheblich verbessert haben - anstelle von Flugblättern und verstreuten Tabletten wurde in Excel ein normales Portal angezeigt, um den Prozess des Austauschs des Wasserversorgungssystems zu überwachen.
Nach einer nachträglichen Analyse der Daten haben wir festgestellt, dass die Verwendung des Modells in einem aktiven Lernformat die Kostenüberschreitung von 16% auf 3% reduzieren würde. Darüber hinaus stellten sie fest, dass die Behörden im Umgang mit Wissenschaftlern ihre Einstellung zu den Daten erheblich verbessert haben - anstelle von Flugblättern und verstreuten Tabletten wurde in Excel ein normales Portal angezeigt, um den Prozess des Austauschs des Wasserversorgungssystems zu überwachen.Eine dynamische Pipeline zur räumlich-zeitlichen Vorhersage des Brandrisikos
Zusammenfassend ist ein weiterer wunder Punkt die Brandinspektion. Was passiert, wenn sie nicht durchgeführt werden, haben wir im März 2018 erfahren. Auch in den USA sind solche Fälle nicht selten. Gleichzeitig sind die Ressourcen für die Inspektion von Feuerwehrleuten begrenzt, sie müssen an die Orte mit dem größten Risiko geleitet werden.
Es gibt offene Modelle zur Bewertung des Brandrisikos, die jedoch für Waldbrände ausgelegt und für die Stadt nicht geeignet sind. Es gibt eine Art System in New York, aber es ist geschlossen. Sie müssen also versuchen
, Ihre eigenen zu erstellen .
In Zusammenarbeit mit den Feuerwehrleuten von Pittsburgh sammelten die Jungs über mehrere Jahre hinweg Daten zu Bränden, fügten Informationen zu Demografie, Einkommen, Unternehmensformen usw. sowie andere Anrufe bei der Feuerwehr hinzu, die nicht mit Bränden zusammenhängen. Und sie versuchten, anhand dieser Daten die Brandgefahr zu bewerten.
Es werden zwei verschiedene XGBoost-Modelle unterrichtet: für Haushalte und gewerbliche Immobilien. Die Qualität der Arbeit wurde laut
Kappa zunächst im Hinblick auf das starke Ungleichgewicht der Klassen bewertet.
Durch Hinzufügen dynamischer Faktoren (Anrufe bei der Feuerwehr, Auslösen von Meldern / Alarmen) zum Modell wurde die Qualität erheblich verbessert. Um diese zu verwenden, musste das Modell jedoch jede Woche neu berechnet werden. Basierend auf der Prognose stellten die Modelle eine angenehme Netzmündung für Brandinspektoren her, die zeigte, wo sich die Objekte mit dem größten Risiko befinden.
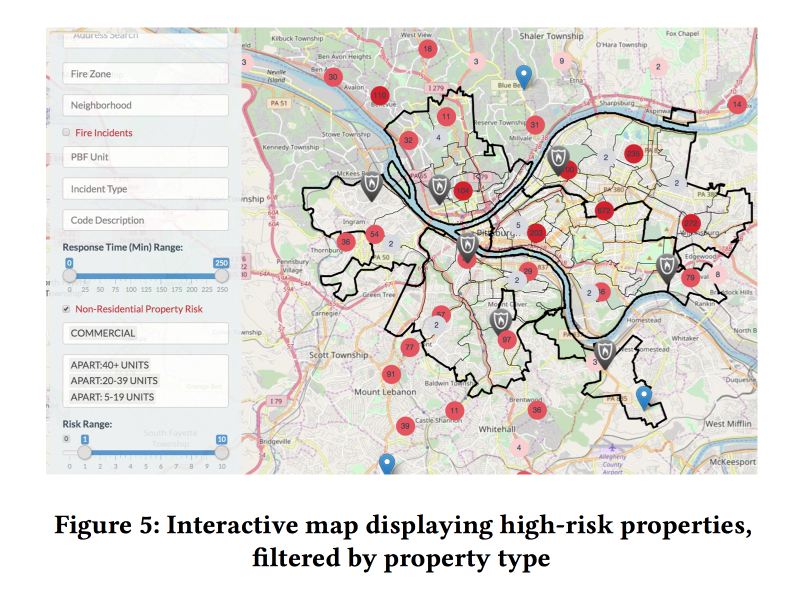
Die Bedeutung der Symptome wurde analysiert. Zu den wichtigen Merkmalen für den Handel gehörten Fehlalarme (anscheinend geht das Herunterfahren weiter). Aber für Haushalte - die Höhe der gezahlten Steuern (Hallo Fairness, Brandinspektionen in armen Gegenden werden häufiger durchgeführt).