Vor einiger Zeit habe ich eine kostenlose Testversion unter Google für die Cloud aktiviert. Ich habe mein Problem nicht gelöst. Es stellte sich heraus, dass Google 12 Monate lang 300 US-Dollar im Rahmen der Testversion zur Verfügung stellt. Entgegen meinen Erwartungen werden neben dem Budgetlimit auch andere Limits festgelegt. Zum Beispiel habe ich die Verwendung von virtuellen Maschinen mit mehr als 8 VCPU in einer Region nicht zugelassen. Nach einem halben Jahr entschied ich mich, das Testbudget zu verwenden, um mich mit dataproc, einem vorinstallierten Hadup-Cluster von Google, vertraut zu machen. Die Aufgabe besteht darin, zu bewerten, wie einfach es für mich wäre, ein Projekt über den Zugriff von Google zu starten, ob es sinnvoll ist oder ob es besser ist, sich sofort auf meine Hardware zu konzentrieren und über die Verwaltung nachzudenken. Ich habe das vage Gefühl, dass sich der moderne Hardware- und BigData-Stack leicht an kleine Datenbanken mit zehn oder Hunderten von GB anpassen sollte, wobei brutal, wenn nicht der gesamte Datensatz, die überwiegende Mehrheit in den Arbeitsspeicher des Clusters geladen wird. Einige separate Unterdaten für Data Marts sind möglicherweise nicht mehr erforderlich.
Kurz gesagt, dataproc war beeindruckt von der Leichtigkeit des Starts und der Einstellungen im Vergleich zu Oracle und Cloudera. In der ersten Phase habe ich mit einem Knotencluster auf 8 vCpu gespielt, von denen das Maximum eine völlig kostenlose Testversion ermöglicht. Wenn Sie sich die Einfachheit ansehen, dann ermöglichen ihre Technologien einem Hindu bereits, einen Cluster in 15 Minuten zu starten, Beispieldaten zu laden und Berichte mit einem regulären BI-Tool ohne Zwischenunterfenster zu erstellen. Ein tiefes Wissen über Hadoup ist überhaupt nicht mehr erforderlich.
Im Prinzip habe ich gesehen, dass die Sache für einen schnellen Start wunderbar ist und für ein vernünftiges Geld können Sie einen Prototyp ausführen und bewerten, welche Art von Hardware Sie für eine Aufgabe benötigen. Ein größerer Cluster in Dutzenden von Knoten frisst jedoch offensichtlich viel mehr als eine Miete + ein paar Administratoren, die sich den Cluster ansehen. Weit entfernt von der Tatsache, dass die Cloud wirtschaftlich rentabel aussehen wird. Im ersten Schritt habe ich versucht, eine vollständige Mikrooption mit einem Knotencluster 8 vCpu und 0,5 TB Rohdaten zu evaluieren. Grundsätzlich sind die Spark + Hadoop-Tests für größere Cluster im Internet bereits voll, aber ich plane, die Option später etwas größer zu testen.
In nur einer Stunde habe ich Skripte gegoogelt, um ein Cluster-Backup zu erstellen, die Firewall zu konfigurieren und den Thrift-Server zu konfigurieren, mit dem jdbc von Windows aus eine Verbindung zu Spark SQL herstellen konnte. Ich verbrachte weitere zwei oder drei Stunden damit, die Standard-Funkeneinstellungen zu optimieren und ein paar kleine Tabellen mit einer Größe von etwa 10 GB (die Größe der Datendateien in Oracle) zu laden. Ich habe die gesamten Tabellen in den Speicher verschoben (Tabellencache ändern;) und es war möglich, mit ihnen von meinem Windows-Computer aus Dbeaver und Tableau (über den Spark-SQL-Connector) zu arbeiten.
Standardmäßig verwendete spark nur 1 Executor auf 4 vCpu, ich bearbeitete spark-defaults.conf, installierte 3 Executer, jeweils 2 vCpu und konnte lange Zeit nicht verstehen, warum ich wirklich nur 1 Executor in meiner Arbeit habe. Es stellte sich heraus, dass ich den Speicher nicht bearbeitet habe, die anderen beiden Garne konnten einfach keinen Speicher zuweisen. Ich stellte 6,5 GB auf dem Executer ein, wonach alle drei wie erwartet zu steigen begannen.
Als nächstes entschied ich mich, mit einer etwas ernsteren Lautstärke und einer Aufgabe zu spielen, die DWH aus TPC-DS-Tests näher kam. Für den Anfang habe ich offiziell Tabellen mit einem Skalierungsfaktor von 500 des offiziellen Tools erstellt. Ich habe ungefähr 480 GB Rohdaten (abgegrenzter Text) erhalten. Der TPC-DS-Test ist ein typischer DWH mit Fakten und Dimensionen. Ich habe nicht verstanden, wie man Daten direkt im Google-Speicher generiert. Ich musste virtuelle Maschinen auf der Festplatte generieren und sie dann in den Google-Speicher kopieren. Nach meinem Verständnis ist Google der Ansicht, dass die Haube perfekt mit Google Storage zusammenarbeitet und die Geschwindigkeit dort etwas besser ist, als wenn sich die Daten innerhalb des Clusters auf HDFS befinden würden. In diesem Fall geht ein Teil der Last von HDFS in den Google-Speicher.
Nachdem ich über Dbeaver eine Verbindung hergestellt hatte, konvertierte ich die Textdateien mithilfe von SQL-Befehlen in Parkett-basierte Tablets mit bissiger Verpackung. 480 GB Textdaten in 187 GB Parkettdateien. Der Vorgang dauerte ungefähr zwei Stunden, die größte Tabelle im Text belegte 188 GB, 3 Funkenausführer verwandelten sie in 74 Minuten in Parkett, die Größe des SUV betrug 66,8 GB. Auf meinem Desktop mit ungefähr der gleichen 8 vCpu (i7-3770k) würde das Einfügen in eine Tabellenauswahl * ... in eine Oracle-Tabelle mit einem 8k-Block einen Tag dauern, und wie viel die Datendatei dauern würde, ist sogar beängstigend.
Als nächstes überprüfte ich die Leistung von BI-Tools in einer solchen Konfiguration und erstellte einen einfachen Bericht in Tableua
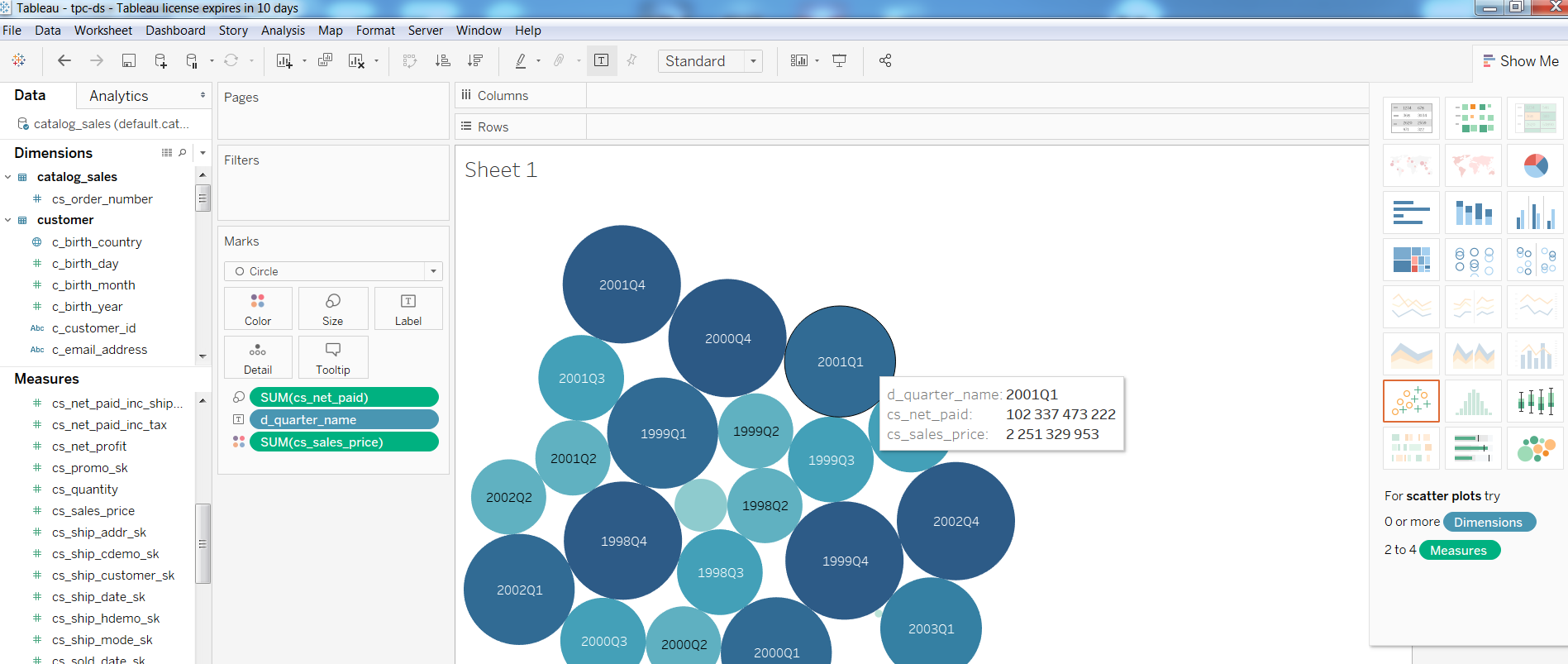
Bei Abfragen Query1 aus dem TPC-DS-Test
Abfrage1WITH customer_total_return AS (SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, Sum(sr_return_amt) AS ctr_total_return FROM store_returns, date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2001 GROUP BY sr_customer_sk, sr_store_sk) SELECT c_customer_id FROM customer_total_return ctr1, store, customer WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100;
Abgeschlossen in 1:08, Abfrage2 unter Beteiligung der größten Tabellen (catalog_sales, web_sales)
Abfrage2 WITH wscs AS (SELECT sold_date_sk, sales_price FROM (SELECT ws_sold_date_sk sold_date_sk, ws_ext_sales_price sales_price FROM web_sales) UNION ALL (SELECT cs_sold_date_sk sold_date_sk, cs_ext_sales_price sales_price FROM catalog_sales)), wswscs AS (SELECT d_week_seq, Sum(CASE WHEN ( d_day_name = 'Sunday' ) THEN sales_price ELSE NULL END) sun_sales, Sum(CASE WHEN ( d_day_name = 'Monday' ) THEN sales_price ELSE NULL END) mon_sales, Sum(CASE WHEN ( d_day_name = 'Tuesday' ) THEN sales_price ELSE NULL END) tue_sales, Sum(CASE WHEN ( d_day_name = 'Wednesday' ) THEN sales_price ELSE NULL END) wed_sales, Sum(CASE WHEN ( d_day_name = 'Thursday' ) THEN sales_price ELSE NULL END) thu_sales, Sum(CASE WHEN ( d_day_name = 'Friday' ) THEN sales_price ELSE NULL END) fri_sales, Sum(CASE WHEN ( d_day_name = 'Saturday' ) THEN sales_price ELSE NULL END) sat_sales FROM wscs, date_dim WHERE d_date_sk = sold_date_sk GROUP BY d_week_seq) SELECT d_week_seq1, Round(sun_sales1 / sun_sales2, 2), Round(mon_sales1 / mon_sales2, 2), Round(tue_sales1 / tue_sales2, 2), Round(wed_sales1 / wed_sales2, 2), Round(thu_sales1 / thu_sales2, 2), Round(fri_sales1 / fri_sales2, 2), Round(sat_sales1 / sat_sales2, 2) FROM (SELECT wswscs.d_week_seq d_week_seq1, sun_sales sun_sales1, mon_sales mon_sales1, tue_sales tue_sales1, wed_sales wed_sales1, thu_sales thu_sales1, fri_sales fri_sales1, sat_sales sat_sales1 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998) y, (SELECT wswscs.d_week_seq d_week_seq2, sun_sales sun_sales2, mon_sales mon_sales2, tue_sales tue_sales2, wed_sales wed_sales2, thu_sales thu_sales2, fri_sales fri_sales2, sat_sales sat_sales2 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998 + 1) z WHERE d_week_seq1 = d_week_seq2 - 53 ORDER BY d_week_seq1;
abgeschlossen in 4:33 Minuten, Abfrage3 in 3.6, Abfrage4 in 32 Minuten.
Wenn jemand an den Einstellungen interessiert ist, unter dem Schnitt meine Notizen zum Erstellen eines Clusters. Im Prinzip gibt es nur ein paar gcloud-Befehle und die Einstellung HIVE_SERVER2_THRIFT_PORT.
AnmerkungenOption für einen Knotencluster:
gcloud dataproc --region europa-north1 cluster erstellen test1 \
--subnet default \
--bucket tape1 \
--zone europe-north1-a \
--single-node \
--master-machine-type n1-highmem-8 \
--master-boot-disk-size 500 \
--image-version 1.3 \
--Initialisierungsaktionen gs: //dataproc-initialization-actions/hue/hue.sh \
--Initialisierungsaktionen gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--Initialisierungsaktionen gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--projekt 123
Option für 3 Knoten:
gcloud dataproc --region europe-north1 cluster \
Erstelle Cluster-Test1 --bucket tape1 \
--subnet default --zone europe-north1-a \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 --num-worker 2 \
--worker-machine-type n1-standard-1 --worker-boot-disk-size 10 \
--Initialisierungsaktionen gs: //dataproc-initialization-actions/hue/hue.sh \
--Initialisierungsaktionen gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--Initialisierungsaktionen gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--projekt 123
gcloud compute --project = 123 \
Firewall-Regeln erstellen allow-dataproc \
--direction = INGRESS --priority = 1000 --network = default \
--action = ALLOW --rules = tcp: 8088, tcp: 50070, tcp: 8080, tcp: 10010, tcp: 10000 \
--source-range = xxx.xxx.xxx.xxx / 32 --target-tags = dataproc
am Hauptknoten:
sudo su - vi /usr/lib/spark/conf/spark-env.sh
Änderung: Exportieren Sie HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark /usr/lib/spark/sbin/start-thriftserver.sh
Fortsetzung folgt ...