
So endete der fünfte, letzte Tag von KDD. Ich konnte einige interessante Berichte von Facebook und Google AI hören, mich an Fußballtaktiken erinnern und einige Chemikalien erzeugen. Darüber und nicht nur - unter dem Schnitt. Wir sehen uns in einem Jahr in Anchorage, der Hauptstadt von Alaska!
Über Big Data-Lernen bei kleinen Datenproblemen
Der Morgenbericht des
chinesischen Professors war schwer. Der Sprecher, der während der Vorbereitung eindeutig frei geladen war, ging oft in die Irre, begann, Folien zu überspringen, und versuchte, das schläfrige Gehirn mit Mathematik zu beladen, anstatt lebenslang zu sprechen.
Der allgemeine Umriss der Geschichte drehte sich um die Idee, dass es bei weitem nicht immer viele Daten gibt. Es gibt zum Beispiel einen langen Schwanz, in dem es viele verschiedene Beispiele gibt. Es gibt Datensätze mit einer großen Anzahl von Klassen, die zwar an sich groß sind, aber nur wenige Datensätze für jede Klasse enthalten. Als Beispiel für einen solchen Datensatz zitierte er
Omniglot - handgeschriebene Zeichen aus durchschnittlich 50 Alphabeten, 1623 Klassen und 20 Bildern pro Klasse. In dieser Perspektive können Sie jedoch auch Datensätze von Empfehlungsaufgaben berücksichtigen, wenn wir viele Benutzer und nicht so viele Bewertungen für jeden einzelnen haben.
Was kann getan werden, um ML in einer solchen Situation das Leben zu erleichtern? Zuallererst. versuchen Sie, Wissen aus dem Themenbereich einzubringen. Dies kann in verschiedenen Formen erfolgen: Dies ist das Engineering von Funktionen sowie die spezifische Regularisierung und Verfeinerung der Netzwerkarchitektur. Eine andere gängige Lösung ist das Transferlernen. Ich denke, dass fast jeder, der mit Bildern gearbeitet hat, damit begonnen hat, ImageNet von seinen Daten zu aktualisieren. Im Fall von Omniglot ist
MNIST der natürliche Spender für die Übertragung.
Eine Form der Übertragung kann das
Lernen mehrerer
Aufgaben sein , über das KDD bereits mehrfach gesprochen wurde. Die Entwicklung von MTL kann als
Meta-Learning- Ansatz betrachtet werden. Indem wir den Algorithmus an Stichproben aus einer Vielzahl von Aufgaben trainieren, können wir nicht nur Parameter, sondern auch Hyperparameter
lernen (natürlich nur, wenn unser Verfahren differenzierbar ist).
Wenn wir das Thema Multitasking fortsetzen, können wir zum Konzept des lebenslangen kontinuierlichen Lernens kommen, das am deutlichsten am Beispiel der Robotik gezeigt werden kann. Der Roboter muss in der Lage sein, verschiedene Probleme zu lösen und beim Erlernen einer neuen Aufgabe frühere Erfahrungen zu nutzen. Sie können diesen Ansatz jedoch am Beispiel von Omniglot betrachten: Nachdem Sie einen der Charaktere gelernt haben, können Sie den nächsten anhand der gesammelten Erfahrung lernen. Auf diesem Weg erwartet uns zwar ein gefährliches Problem des
katastrophalen Vergessens , wenn der Algorithmus zu vergessen beginnt, was er zuvor gelernt hat (um dem entgegenzuwirken, empfiehlt er, den
EBR zu regulieren).
Darüber hinaus sprach der Redner über einige seiner Arbeiten in dieser Richtung.
Neuronale Prozesse (eine Analogie des Gaußschen Prozesses für neuronale Netze) und
Distil- und Transferlernen (Optimierung des Transferlernens für den Fall, dass wir kein zuvor trainiertes Modell als Grundlage verwenden, sondern unser Modell im Multitasking-Modus trainieren).
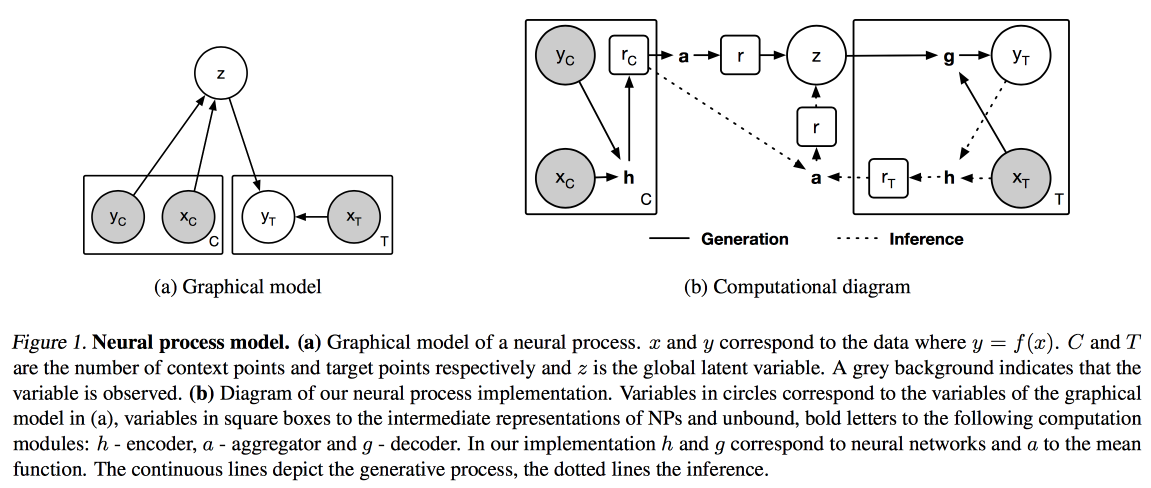
Bilder und Texte
Heute habe ich mich entschlossen, morgens auf angewandten Berichten über die Arbeit mit Texten, Bildern und Videos zu gehen.
Korpusumwandlungsservice
Die Häufigkeit von Veröffentlichungen nimmt sehr schnell zu. Es ist schwierig, damit zu arbeiten, insbesondere angesichts der Tatsache, dass fast die gesamte Suche im Text durchgeführt wird. IBM
bietet seine Services zum Markieren von Gehäusen mit wissenschaftlichem Wissen 3.0 an. Der Hauptworkflow sieht folgendermaßen aus:
- Parsim PDF, erkennen Sie Text in Bildern.
- Wir prüfen, ob es ein Modell für diese Textform gibt, wenn ja, machen wir daraus einen semantischen Auszug.
- Wenn es kein Modell gibt, senden wir eine Anmerkung und trainieren.
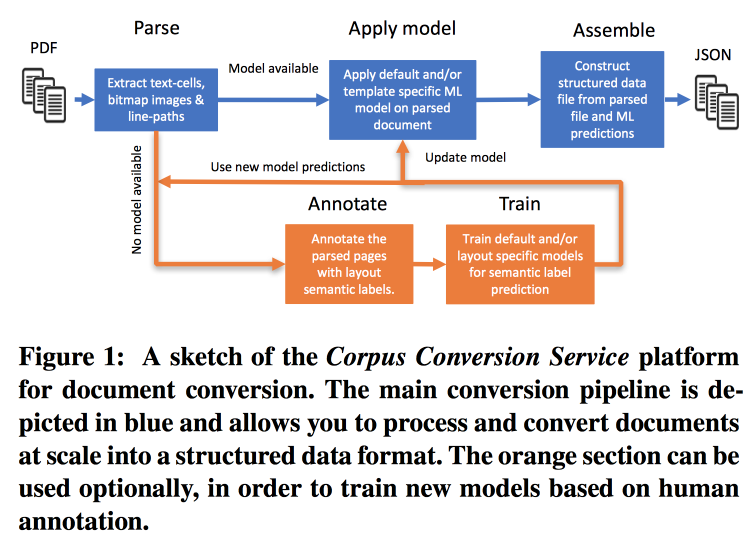
Um Modelle zu trainieren, beginnen wir mit der Clusterbildung nach Struktur. Innerhalb eines Clusters mit Crowdsourcing gestalten wir mehrere Seiten. Es stellt sich heraus, dass beim Training zur Kennzeichnung von 200-300 Dokumenten eine Genauigkeit von> 98% erreicht wird. Das Markup weist ein starkes Klassenungleichgewicht auf (fast alles ist als Text markiert). Sie müssen daher die Genauigkeit aller Klassen und die Verwirrungsmatrix überprüfen.
Modelle haben eine hierarchische Struktur. Beispielsweise erkennt ein Modell eine Tabelle und das andere schneidet in Zeilen / Spalten / Überschriften (und ja, eine Tabelle kann in einer Tabelle verschachtelt sein). Als Modell wird ein Faltungsnetzwerk verwendet.
Für all dies haben sie mit Kubernetes einen Förderer auf Docker zusammengestellt und sind bereit, Ihren Textkorpus gegen eine angemessene Gebühr herunterzuladen. Sie können nicht nur mit PDF-Text arbeiten, sondern auch mit Scans. Sie unterstützen orientalische Sprachen. Sie ziehen nicht nur den Text heraus, sondern arbeiten auch daran, das Wissensdiagramm zu extrahieren. Sie versprechen, die Details zum nächsten KDD mitzuteilen.
Seltene Abfrageerweiterung durch generative gegnerische Netzwerke in der Suchmaschinenwerbung
Suchmaschinen verdienen das meiste Geld mit Werbung, und Werbung wird angezeigt, je nachdem, wonach der Benutzer sucht. Der Vergleich ist jedoch nicht immer offensichtlich. Auf Anfrage von Flugtickets ist es beispielsweise nicht sehr korrekt, Anzeigen für billige Bustickets anzuzeigen, aber expedia funktioniert gut, aber Sie können dies nicht anhand von Schlüsselwörtern verstehen. Modelle für maschinelles Lernen können helfen, funktionieren jedoch bei seltenen Abfragen nicht gut.
Um dieses Problem zu lösen und die Suchabfrage zu erweitern,
trainieren wir die bedingte GAN gemäß dem Sequenz-zu-Sequenz-Modell. Wir verwenden wiederkehrende Netzwerke (2-Layer-GRU) als Architektur. Wir ändern min-max von GAN und versuchen, Keywords hinzuzufügen, für die es Klicks auf Anzeigen gab.
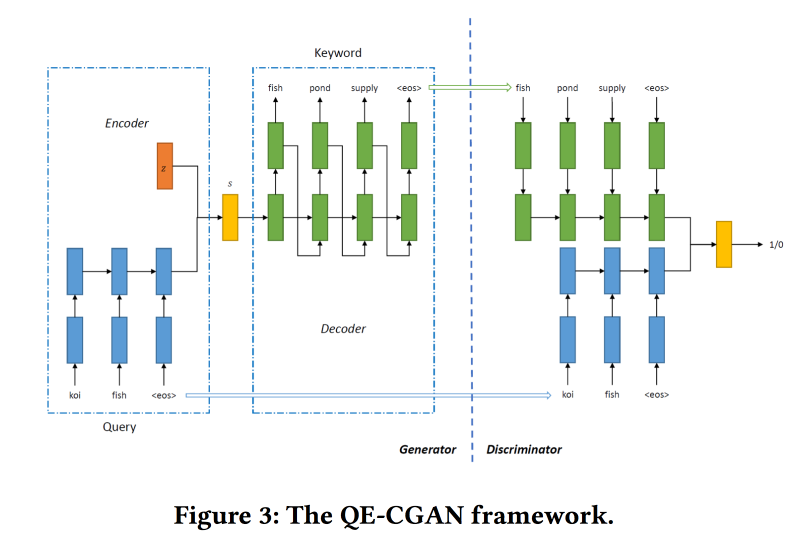
Datensatz für Schulungen zu 14 Millionen Anfragen und 4 Millionen Werbeschlüsselwörtern. Das vorgeschlagene Modell funktioniert besser am langen Ende der Anfrage, für die es durchgeführt wurde. Aber im Kopf ist die Leistung nicht höher.
Kollaboratives Deep Metric Learning für das Videoverständnis
Die Arbeit wird von den Jungs von Google AI präsentiert. Sie möchten gute Videoeinbettungen erstellen und diese dann in ähnlichen Videos, Empfehlungen, automatischen Anmerkungen usw. verwenden. Es funktioniert wie folgt:
- Aus dem Video probieren wir Frames - ein Bild und einen Teil der Audiospur.
- Wir extrahieren Funktionen aus den Bildern, die Inception zuvor gelernt hat.
- Wir machen dasselbe mit dem Audiofragment (die spezifische Netzwerkarchitektur wurde nicht gezeigt). An den erhaltenen Schildern hängen wir vollständig verbundene Maschen mit dem Ziehen an Rahmen. Wir normalisieren durch L2.
- Als nächstes ein interessanter Punkt - wir versuchen sicherzustellen, dass ähnliche Videos in Bezug auf kollaborative Ähnlichkeit nahe beieinander liegen. Dazu verwenden wir im Training den Triplettverlust (wir nehmen ein Objekt, probieren es ähnlich und unähnlich aus, stellen sicher, dass die Einbettungen des Unähnlichen weiter vom Original entfernt sind als das Ähnliche). Vergessen Sie nicht, dass Sie Negative Mining verwenden müssen.

Sie werden für einen Kaltstart in ähnlichen Videos verwendet, es gibt jedoch einige Probleme: Aufgrund der visuellen Ähnlichkeit können sie Videos in einer anderen Sprache oder Videos zu einem anderen Thema finden (insbesondere relevant für das Videoformat „Board and Lecturer“). Wir empfehlen Ihnen, zusätzliche Metainformationen zum Video zu verwenden.
Es gibt ein Problem mit den Empfehlungen: Sie müssen den Browserverlauf und 5 Milliarden Videos von Youtube abgleichen. Um die Arbeit zu beschleunigen, berechnen wir für den Benutzer den Vektor der durchschnittlichen Einbettung der angesehenen Videos. Auf
Movielens überprüft, Trailer von Youtube zur Analyse abgepumpt. Sie zeigten, dass es für Benutzer mit einer kleinen Anzahl von Bewertungen besser funktioniert.
Beim Problem mit Videoanmerkungen wird
der Ansatz
der Expertenmischung verwendet: Sie trainieren auf logreg für die Einbettung für jede mögliche Annotation. Auf
Youtube-8 überprüft und ein sehr gutes Ergebnis gezeigt.
Namensdisambiguierung in AMiner: Clustering, Wartung und Human in the Loop
AMiner - eine Grafik für die Akademie, die verschiedene Dienstleistungen für die Arbeit mit Literatur bietet. Eines der Probleme: Kollisionen von Namen von Autoren und Entitäten. Zur Lösung wird ein automatischer Algorithmus mit irgendeiner Form von aktivem Lernen
angeboten .
Der Prozess besteht aus drei Schritten: Mithilfe einer Textsuche sammeln wir Kandidaten (Dokumente mit ähnlichen Namen von Autoren), Cluster (mit automatischer Bestimmung der Anzahl von Clustern) und erstellen Profile.

Um die Ähnlichkeit beim Clustering zu berücksichtigen, benötigen Sie eine Art Präsentation (Emeding). Es kann unter Verwendung des globalen Modells (im gesamten Diagramm) oder lokal (für die Kandidaten, die eine Stichprobe erstellt haben) erhalten werden. Globale Fangmuster, die auf neue Dokumente übertragen werden können, und lokale Fangmuster helfen dabei, individuelle Merkmale zu berücksichtigen - wir werden sie kombinieren. Um globale Einbettungen zu erhalten, verwenden sie auch das siamesische Netzwerk, das in Triplettverlust geschult ist, und für lokale Netzwerke - einen Grafik-Auto-Encoder (ich habe die Bilder im Artikel aus Platzgründen belassen).
Die schmerzhafteste Frage ist, wie viele Cluster ich habe. Der
X-Mittel- Ansatz skaliert nicht auf eine große Anzahl von Clustern, RNN wird verwendet, um deren Anzahl vorherzusagen: K Cluster werden aus einer markierten Menge abgetastet, dann N Beispiele aus diesen Clustern. Sie trainieren das Netzwerk, um die anfängliche Anzahl von Clustern zu ermitteln.

Daten kommen schnell genug an, 500.000 pro Monat, aber es dauert Wochen, bis das gesamte Modell ausgeführt wird. Für eine schnelle Initialisierung verwenden sie die Auswahl von Kandidaten für die Textsuche und IPN für globale Einbettungen. Ein wichtiger Punkt: Personen, die festlegen, was im Cluster enthalten sein soll und was nicht, werden in den Lernprozess einbezogen. Anhand dieser Daten wird das Modell umgeschult.
Rosetta: Großsystem zur Texterkennung und -erkennung in Bildern
Die Jungs von FB
werden ihre Lösung zum Extrahieren von Texten aus Bildern
vorstellen . Das Modell arbeitet in zwei Schritten: Das erste Netzwerk bestimmt den Text, das zweite erkennt ihn.
Faster-RCNN wurde als Detektor verwendet, wobei ResNet durch
SuffleNet ersetzt wurde , um die Arbeit zu beschleunigen. Zur Erkennung verwendeten sie ResNet18 und trainierten mit
CTC-Verlust .
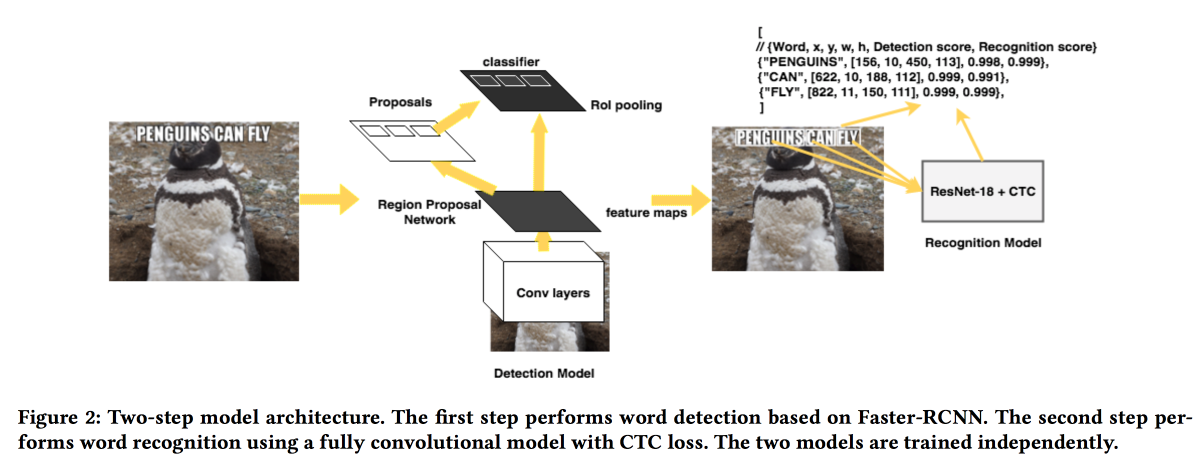
Um die Konvergenz zu verbessern, haben wir verschiedene Tricks angewendet:
- Während des Trainings wurde ein kleines Geräusch in das Ergebnis des Detektors eingeführt.
- Die Texte wurden horizontal um 20% gestreckt.
- Verwendetes Curriculum-Lernen - nach und nach komplizierte Beispiele (nach Anzahl der Zeichen).
Naturwissenschaft
Der letzte inhaltliche Teil der Konferenz war den „Naturwissenschaften“ gewidmet. Ein bisschen Chemie, Fußball und mehr.
Kontrollierte heterogene Behandlungseffekterkennung mit falscher Entdeckungsrate für online kontrolliertes Experiment
Sehr interessante Arbeit zur Analyse von A / B-Tests. Das Problem bei den meisten Analysesystemen besteht darin, dass sie den durchschnittlichen Effekt betrachten, während in der Realität einige Benutzer meistens positiv und andere negativ auf die Änderung reagieren und mehr erreicht werden kann, wenn Sie verstehen, für wen die Funktion bestimmt ist und für wen Nein.

Sie können Benutzer im Voraus in Kohorten einteilen und deren Auswirkungen bewerten. Mit zunehmender Anzahl von Kohorten steigt jedoch die Anzahl der falsch positiven
Ergebnisse (Sie können versuchen, sie mithilfe der
Bonferoni- Methode zu reduzieren, dies ist jedoch zu konservativ). Darüber hinaus müssen Sie die Kohorten im Voraus kennen. Die Jungs schlagen vor, eine Kombination mehrerer Ansätze zu verwenden: Kombinieren Sie den Mechanismus zur Erkennung heterogener Effekte (HTE) mit falsch positiven Filtermethoden.
Um einen heterogenen Effekt zu erkennen, wird eine Matrix mit
x=0/1 0/1 (in der Gruppe oder nicht) und der Effekt in eine Matrix umgewandelt, in der anstelle von
0/1 die Zahl
(x — p)/p(1-p) , wobei
p die Wahrscheinlichkeit der Aufnahme in ist der Test. Als nächstes wird ein Modell zur Vorhersage des Effekts von
x (lineare oder Lasso-Regression) vermittelt. Diejenigen Benutzer, bei denen sich das Ergebnis erheblich von der Prognose unterscheidet, sind Kandidaten für die Trennung in einen „heterogenen“ Effekt.
Als nächstes haben wir zwei Methoden für den falsch positiven Filter ausprobiert:
Benjamini-Hochberg und
Knockoffs . Die erste ist viel einfacher zu implementieren, die zweite ist flexibler und zeigt interessantere Ergebnisse.
Fluch des Gewinners: Bias-Schätzung für die Gesamtwirkung von Merkmalen in online kontrollierten Experimenten
Die Jungs von AirBnB haben ein bisschen darüber gesprochen, wie sie das Experimentanalysesystem verbessert haben. Das Hauptproblem besteht darin, dass wir beim Experimentieren mit vielen Verzerrungen in dieser Arbeit Selektionsverzerrungen berücksichtigt haben - wir wählen Experimente mit dem besten
beobachteten Ergebnis aus. Dies bedeutet jedoch, dass wir häufiger Experimente auswählen, bei denen das beobachtete Ergebnis im Vergleich zum tatsächlichen Ergebnis zu hoch ist.
Infolgedessen ist beim Kombinieren von Experimenten der endgültige Effekt geringer als die Summe der Effekte von Experimenten. Wenn Sie diese Verzerrung kennen, können Sie versuchen, sie mithilfe des statistischen Geräts zu bewerten und zu subtrahieren (vorausgesetzt, der Unterschied zwischen den tatsächlichen und den beobachteten Effekten ist normal verteilt). Kurz gesagt, so etwas:

Wenn Sie
Bootstrap hinzufügen, können Sie sogar Konfidenzintervalle für eine unvoreingenommene Schätzung des Effekts erstellen.
Automatische Erkennung von Taktiken in räumlich-zeitlichen Fußballspieldaten
Interessante Arbeit zur Offenlegung der Taktik von Fußballmannschaften. Spieldaten sind in Form von Aktionssequenzen (Pass / Touch / Hit usw.) verfügbar, etwa 2000 Aktionen pro Spiel. Kombinieren Sie kontinuierliche (Koordinaten / Zeit) und diskrete (Spieler) Attribute. Es ist wichtig, die Daten anhand der Kenntnisse des Themenbereichs zu erweitern (z. B. die Rolle des Spielers und die Art des Passes hinzufügen), aber es funktioniert nicht immer. Darüber hinaus interessieren sich verschiedene Arten von Benutzern für verschiedene Arten von Mustern: Trainer - erfolgreich, Stürmer - defensiv, Journalist - einzigartig.
Das vorgeschlagene Verfahren ist wie folgt:
- Teilen Sie den Fluss in Phasen für den Übergang des Balls zwischen den Teams.
- Clusterphasen mit dynamischer Zeitverzerrung als Entfernung. Wie man die Anzahl der Cluster bestimmt, wird nicht mitgeteilt.
- Wir ordnen Cluster nach Zweck (für die wir nach Taktiken suchen).
- Minimieren Sie die Muster innerhalb des Clusters (sequentielles Pattern Mining CM-SPADE ), und verlassen Sie die Koordinaten entsprechend den Feldsegmenten (linke / rechte Flanke, Mitte, Strafe).
- Ordnen Sie die Muster erneut.
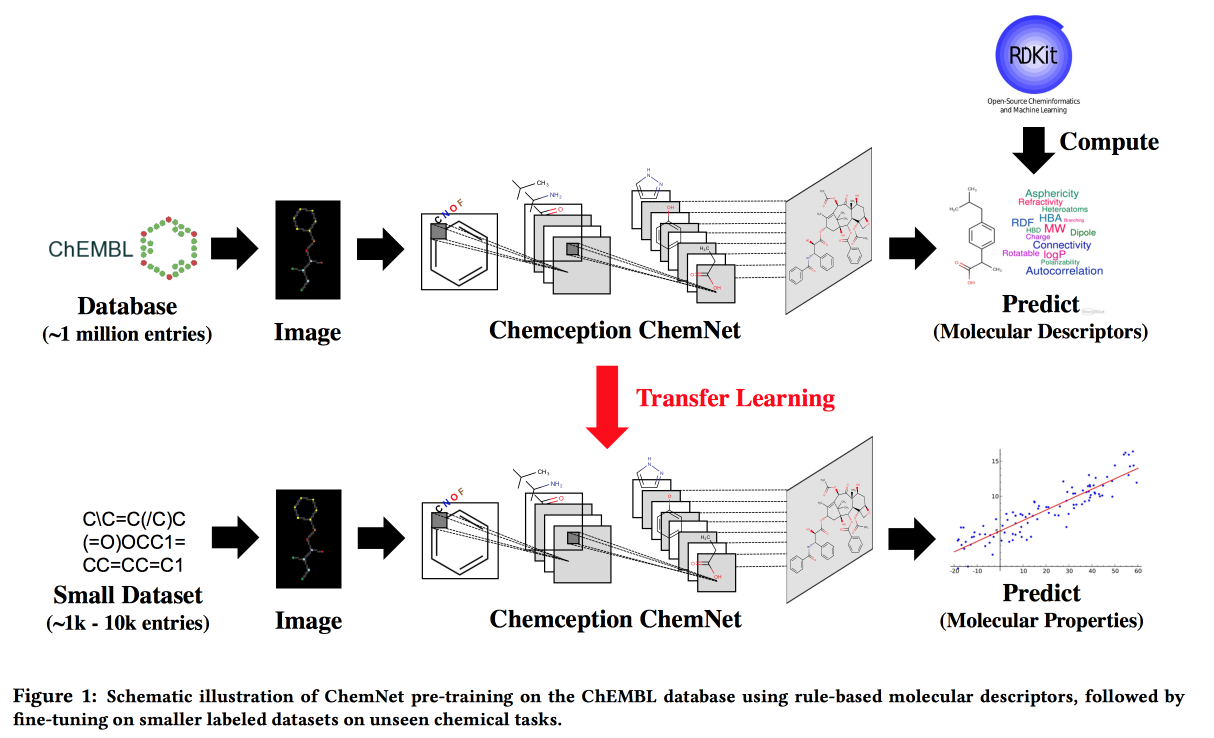
Verwenden regelbasierter Labels für schwach überwachtes Lernen: Ein ChemNet für übertragbare chemische Eigenschaften P.
Arbeiten Sie für Situationen, in denen es keine großen Datenmengen gibt, aber theoretische Modelle mit hierarchischen Regeln. Mit Hilfe der Theorie bauen wir ein „Experten“ -Neuronales Netzwerk auf. Anwendbar für die Entwicklung chemischer Verbindungen mit gewünschten Eigenschaften.
In Analogie zu Bildern möchte ich ein Netzwerk erhalten, in dem Schichten verschiedenen Abstraktionsebenen entsprechen: Atome / funktionelle Gruppen / Fragmente / Moleküle. In der Vergangenheit gab es Ansätze für große, beschriftete Datensätze, z. B. SMILE2Vect: Verwenden Sie
SMILE , um eine Formel in Text zu übersetzen, und wenden Sie dann Techniken zum Erstellen von Einbettungen für Texte an.
Was aber, wenn es keinen großen markierten Datensatz gibt? Wir unterrichten ChemNet mithilfe von
RDKit für die Ziele, die es vorhersagen kann, und übertragen dann das Lernen, um das Problem zu lösen. Wir zeigen, dass wir mit Modellen konkurrieren können, die auf gekennzeichneten Daten trainiert sind. Sie können in Ebenen lernen, was bedeutet, das Ziel zu erreichen - die Ebenen nach Abstraktionsebene aufzuteilen.
PrePeP - Ein Tool zur Identifizierung und Charakterisierung von Pan-Assay-Interferenzverbindungen
Wir entwickeln Medikamente , verwenden Data Science, um Kandidaten auszuwählen. Es gibt Moleküle, die mit vielen Substanzen reagieren. Sie können nicht als Arzneimittel verwendet werden, sondern treten häufig in der Anfangsphase des Tests auf. Dies sind die
PAINS- Moleküle
, die wir filtern werden.
Es gibt Schwierigkeiten: Die Daten sind entladen und arrogant (107 Tausend), die Klassen sind unausgeglichen (positiv 0,5%) und Chemiker möchten ein interpretiertes Modell erhalten. Kombinieren Sie die Daten aus der
Graphstruktur (
gSpan ) des Moleküls und den chemischen Fingerabdrücken. Sie kämpften mit dem Gleichgewicht, indem sie negative Unterabtastungen einsackten, Bäume lehrten und Prognosen mit Stimmenmehrheit aggregierten.