 Um die Überwachung nützlich zu machen, müssen wir verschiedene Szenarien wahrscheinlicher Probleme erarbeiten und Dashboards und Trigger so gestalten, dass sie die Ursache des Vorfalls sofort verstehen.
Um die Überwachung nützlich zu machen, müssen wir verschiedene Szenarien wahrscheinlicher Probleme erarbeiten und Dashboards und Trigger so gestalten, dass sie die Ursache des Vorfalls sofort verstehen.
In einigen Fällen wissen wir genau, wie diese oder jene Komponente der Infrastruktur funktioniert, und dann ist im Voraus bekannt, welche Metriken nützlich sind. Und manchmal entfernen wir fast alle möglichen Metriken mit maximaler Detailgenauigkeit und untersuchen dann, wie bestimmte Probleme auf ihnen sichtbar sind.
Heute werden wir uns ansehen, wie und warum WAL-Postgres (Write-Ahead Log) anschwellen können. Wie immer - Beispiele aus dem wirklichen Leben in Bildern.
Ein bisschen WAL-Theorie in postgresql
Jede Änderung in der Datenbank wird zuerst in der WAL aufgezeichnet, und erst danach werden die Daten auf der Seite im Puffercache geändert und als verschmutzt markiert - was auf der Festplatte gespeichert werden muss. Darüber hinaus wird regelmäßig der CHECKPOINT- Prozess gestartet, bei dem alle verschmutzten Seiten auf der Festplatte und die WAL-Segmentnummer gespeichert werden, bis zu der alle geänderten Seiten bereits auf die Festplatte geschrieben wurden.
Wenn postgresql aus irgendeinem Grund plötzlich abstürzt und erneut startet, werden alle WAL-Segmente vom letzten Prüfpunkt während des Wiederherstellungsprozesses abgespielt.
Die WAL-Segmente vor dem Prüfpunkt sind für die Datenbankwiederherstellung nach dem Absturz nicht mehr nützlich. In der Postgres-Datei ist WAL jedoch auch am Replikationsprozess beteiligt, und die Sicherung aller Segmente für die Wiederherstellung zu einem bestimmten Zeitpunkt - PITR kann ebenfalls konfiguriert werden.
Ein erfahrener Ingenieur hat wahrscheinlich schon alles verstanden, wie es im wirklichen Leben kaputt geht :)
Schauen wir uns die Charts an!
WAL Schwellung # 1
Unser Überwachungsagent für jede gefundene Instanz von postgres berechnet den Pfad auf der Festplatte zum Verzeichnis mit wal und entfernt sowohl die Gesamtgröße als auch die Anzahl der Dateien (Segmente):
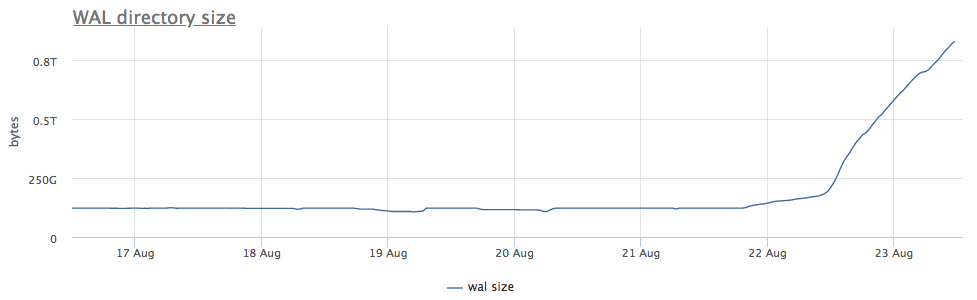
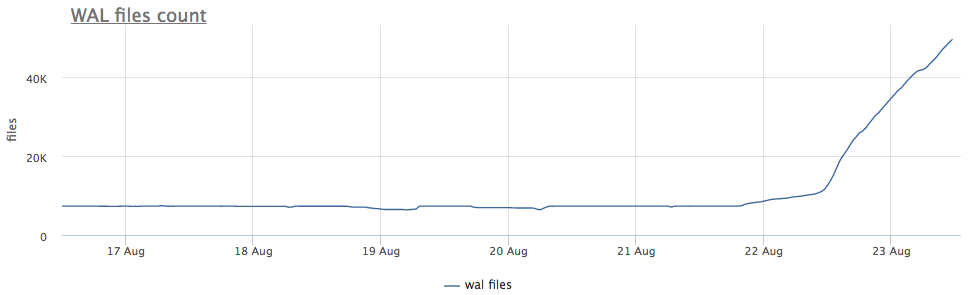
Zunächst schauen wir uns an, wie lange wir CHECKPOINT ausgeführt haben.
Wir nehmen Metriken von pg_stat_bgwriter:
- checkpoints_timed - Zähler für Checkpoint-Starts, die unter der Bedingung durchgeführt wurden, dass die Zeit vom letzten Checkpoint um mehr als pg_settings.checkpoint_timeout überschritten wurde
- checkpoints_req - Zähler für den Start des Prüfpunkts durch die Bedingung, dass die Wal-Größe vom letzten Prüfpunkt überschritten wird
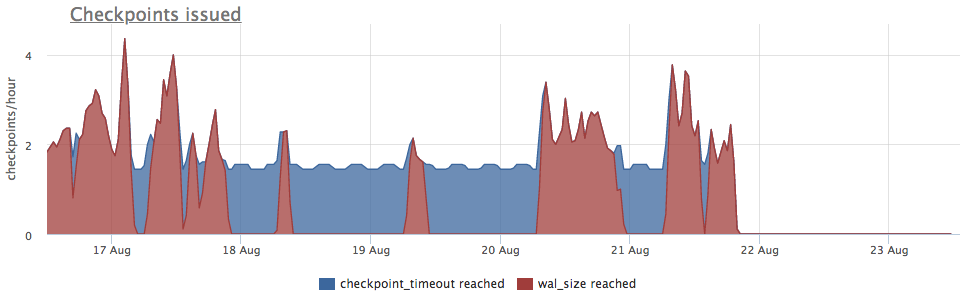
Wir sehen, dass der Checkpoint schon lange nicht mehr gestartet wurde. In diesem Fall ist es unmöglich, den Grund für das NICHT-Starten dieses Prozesses direkt zu verstehen (aber es wäre natürlich cool), aber wir wissen, dass in Postgres viele Probleme aufgrund langer Transaktionen auftreten!
Wir prüfen:

Weiterhin ist klar, was zu tun ist:
- eine Transaktion beenden
- beschäftigen sich mit den Gründen, warum es lang ist
- Warten Sie, aber prüfen Sie, ob genügend Platz vorhanden ist
Ein weiterer wichtiger Punkt: Bei Replikaten, die mit diesem Server verbunden sind, ist Wal ebenfalls geschwollen !
WAL-Archivierer
Ich erinnere Sie gelegentlich daran: Replikation ist kein Backup!
Ein gutes Backup sollte es Ihnen ermöglichen, jederzeit eine Wiederherstellung durchzuführen. Zum Beispiel, wenn jemand "versehentlich" auftrat
DELETE FROM very_important_tbl;
Dann sollten wir in der Lage sein, die Datenbank genau vor dieser Transaktion auf den Status zurückzusetzen. Dies wird als PITR (Point-in-Time Recovery) bezeichnet und in postgresql mit regelmäßigen vollständigen Sicherungen der Datenbank + Speichern aller WAL-Segmente nach dem Dump implementiert.
Die Einstellung archive_command ist für die Sicherung von wal verantwortlich. Postgres startet nur den von Ihnen angegebenen Befehl. Wenn der Vorgang fehlerfrei ausgeführt wird, gilt das Segment als erfolgreich kopiert. Wenn ein Fehler auftritt, wird versucht, bis zum Sieg das Segment auf der Festplatte zu liegen.
Nun, und zur Veranschaulichung - Grafiken der kaputten Archivierung wal:
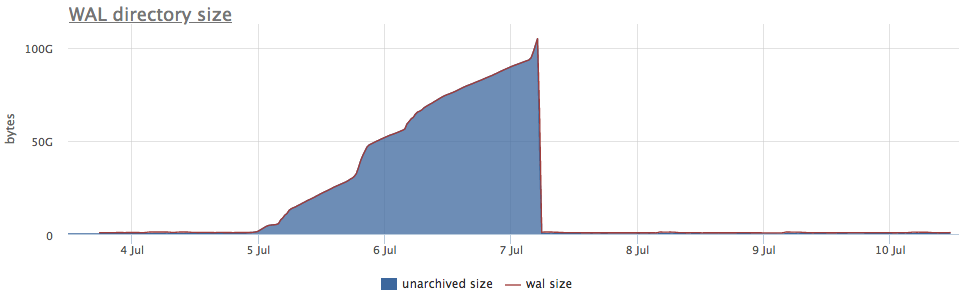
Hier gibt es zusätzlich zur Größe aller Wal-Segmente eine nicht archivierte Größe - dies ist die Größe von Segmenten, die noch nicht als erfolgreich gespeichert gelten.
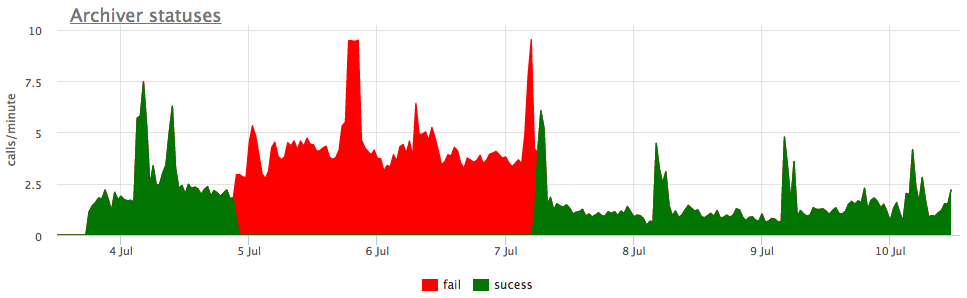
Wir betrachten die Status gemäß den Zählern von pg_stat_archiver. Für die Anzahl der Dateien haben wir einen automatischen Trigger für alle Clients erstellt, da dieser häufig ausfällt, insbesondere wenn ein Cloud-Speicher als Ziel verwendet wird (z. B. S3).
Replikationsverzögerung
Die laufende Streaming-Replikation funktioniert durch Übertragen und Spielen von Wal auf Replikaten. Wenn das Replikat aus irgendeinem Grund hinterherhinkt und eine bestimmte Anzahl von Segmenten nicht verliert, speichert der Assistent pg_settings.wal_keep_segments- Segmente dafür. Wenn das Replikat auf einer größeren Anzahl von Segmenten zurückfällt, kann es keine Verbindung mehr zum Master herstellen (es muss neu gegossen werden).
Um die Beibehaltung einer beliebigen Anzahl von Segmenten zu gewährleisten, wurde die Funktionalität der Replikationssteckplätze in 9.4 beschrieben, auf die später eingegangen wird.
Replikationssteckplätze
Wenn die Replikation mithilfe des Replikationssteckplatzes konfiguriert wurde und mindestens eine erfolgreiche Replikatverbindung zum Steckplatz bestand, speichert das Postgres alle neuen Wal-Segmente, bis der Platz leer ist, falls das Replikat verschwindet.
Das heißt, ein vergessener Replikationssteckplatz kann zu Wal-Schwellungen führen. Glücklicherweise können wir den Status von Slots über pg_replication_slots überwachen.
So sieht es in einem Live-Beispiel aus:
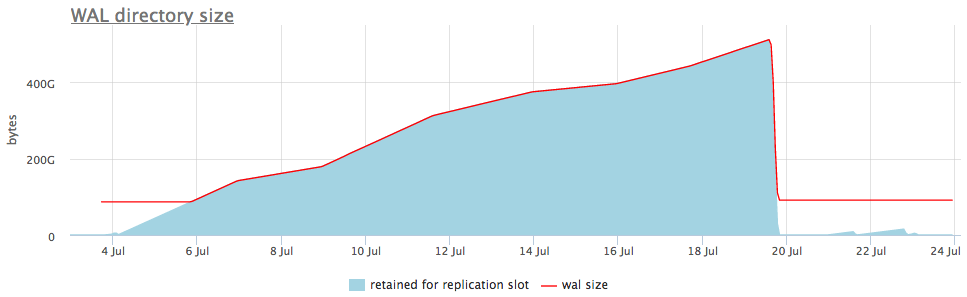

In der oberen Grafik wird neben der Wal-Größe immer entweder ein Slot mit der maximalen Anzahl akkumulierter Segmente angezeigt, aber es gibt auch eine detaillierte Grafik, die zeigt, welcher Slot geschwollen ist.
Sobald wir verstanden haben, welche Art von Slot Daten sammelt, können wir entweder die damit verbundenen Replikate reparieren oder einfach löschen.
Ich habe die häufigsten Fälle von Walschwellungen angeführt, aber ich bin mir sicher, dass es auch andere Fälle gibt (manchmal werden auch Fehler in Postgres gefunden). Daher ist es wichtig, die Größe des Wal zu überwachen und auf Probleme zu reagieren, bevor der Speicherplatz knapp wird und die Datenbank keine Anforderungen mehr bearbeitet.
Unser Überwachungsservice weiß bereits, wie man all dies sammelt, richtig visualisiert und alarmiert. Außerdem haben wir eine lokale Lieferoption für diejenigen, für die die Cloud nicht geeignet ist.