Jeden Tag führen Benutzer Millionen von Online-Aktivitäten durch. Das FACETz DMP-Projekt muss diese Daten strukturieren und segmentieren, um Benutzerpräferenzen zu identifizieren. In dem Artikel werden wir darüber sprechen, wie das Team ein Publikum von 600 Millionen Menschen segmentierte, täglich 5 Milliarden Ereignisse verarbeitete und mit Statistiken unter Verwendung von Kafka und HBase arbeitete.
Das Material basiert auf einer Abschrift eines
Berichts von Artyom Marinov , einem Big-Data-Spezialisten bei Directual, von der SmartData 2017-Konferenz.
Mein Name ist Artyom Marinov. Ich möchte darüber sprechen, wie wir die Architektur des FACETz DMP-Projekts neu gestaltet haben, als ich bei Data Centric Alliance gearbeitet habe. Warum wir es getan haben, wozu es geführt hat, welchen Weg wir gegangen sind und auf welche Probleme wir gestoßen sind.
DMP (Data Management Platform) ist eine Plattform zum Sammeln, Verarbeiten und Aggregieren von Benutzerdaten. Daten sind viele verschiedene Dinge. Die Plattform hat ungefähr 600 Millionen Benutzer. Dies sind Millionen von Cookies, die ins Internet gehen und verschiedene Ereignisse auslösen. Im Allgemeinen sieht ein Tag im Durchschnitt ungefähr so aus: Wir sehen ungefähr 5,5 Milliarden Ereignisse pro Tag, sie sind irgendwie nach Tag verteilt und erreichen auf dem Höhepunkt ungefähr 100.000 Ereignisse pro Sekunde.

Ereignisse sind verschiedene Benutzersignale. Zum Beispiel ein Besuch auf einer Site: Wir sehen, von welchem Browser der Benutzer geht, von welchem Useragent und von allem, was wir extrahieren können. Manchmal sehen wir, wie und für welche Suchanfragen er auf die Website kam. Es können auch verschiedene Daten aus der Offline-Welt sein, zum Beispiel was es mit Rabattgutscheinen bezahlt und so weiter.
Wir müssen diese Daten speichern und den Benutzer in die sogenannten Gruppen von Zielgruppensegmenten einordnen. Zum Beispiel können die Segmente eine "Frau" sein, die "Katzen liebt" und nach "Autoservice" sucht, sie "hat ein Auto, das älter als drei Jahre ist".
Warum einen Benutzer segmentieren? Hierfür gibt es viele Anwendungen, zum Beispiel Werbung. Verschiedene Werbenetzwerke können Algorithmen für die Anzeigenschaltung optimieren. Wenn Sie für Ihren Autoservice werben, können Sie eine Kampagne so einrichten, dass nur Personen mit einem alten Auto Informationen anzeigen, ausgenommen Besitzer neuer. Sie können den Inhalt der Website dynamisch ändern, Sie können die Daten für die Bewertung verwenden - es gibt viele Anwendungen.
Daten werden von vielen völlig unterschiedlichen Orten erhalten. Dies können direkte Pixeleinstellungen sein. Wenn der Kunde sein Publikum analysieren möchte, platziert er das Pixel auf der Website, ein unsichtbares Bild, das von unserem Server heruntergeladen wird. Unter dem Strich sehen wir den Besuch des Benutzers auf dieser Website: Sie können ihn speichern, mit der Analyse und dem Verständnis des Porträts des Benutzers beginnen. Alle diese Informationen stehen unserem Kunden zur Verfügung.

Daten können von verschiedenen Partnern abgerufen werden, die viele Daten sehen und diese auf verschiedene Weise monetarisieren möchten. Partner können Daten sowohl in Echtzeit bereitstellen als auch regelmäßig in Form von Dateien hochladen.
Hauptanforderungen:
- Horizontale Skalierbarkeit;
- Einschätzung des Publikumsvolumens;
- Bequemlichkeit der Überwachung und Entwicklung;
- Gute Reaktionsgeschwindigkeit auf Ereignisse.
Eine der Hauptanforderungen des Systems ist die horizontale Skalierbarkeit. Es gibt einen solchen Moment, in dem Sie bei der Entwicklung eines Portals oder Online-Shops die Anzahl Ihrer Benutzer schätzen können (wie es wachsen wird, wie es sich ändern wird) und ungefähr verstehen können, wie viel Ressourcen benötigt werden und wie das Geschäft im Laufe der Zeit leben und sich entwickeln wird.
Wenn Sie eine Plattform entwickeln, die DMP ähnlich ist, müssen Sie darauf vorbereitet sein, dass jede große Site - die bedingte Amazon - Ihre Pixel darin platzieren kann, und Sie müssen mit dem Verkehr dieser gesamten Site arbeiten, während Sie nicht fallen sollten, und den Indikatoren Systeme sollten sich davon irgendwie nicht ändern.
Es ist auch sehr wichtig, das Volumen eines bestimmten Publikums zu verstehen, damit ein potenzieller Werbetreibender oder eine andere Person einen Medienplan ausarbeiten kann. Zum Beispiel kommt eine Person zu Ihnen und fragt Sie, wie viele schwangere Frauen aus Nowosibirsk nach einer Hypothek suchen, um zu beurteilen, ob es sinnvoll ist, sie gezielt anzusprechen oder nicht.
Unter dem Gesichtspunkt der Entwicklung müssen Sie in der Lage sein, alles, was in Ihrem System geschieht, kühl zu überwachen, einen Teil des tatsächlichen Datenverkehrs zu debuggen und so weiter.
Eine der wichtigsten Systemanforderungen ist eine gute Reaktionsgeschwindigkeit auf Ereignisse. Je schneller die Systeme auf Ereignisse reagieren, desto besser ist dies offensichtlich. Wenn Sie nach Theaterkarten suchen, dann sehen Sie nach einem Tag, zwei Tagen oder sogar einer Stunde ein Rabattangebot - dies kann irrelevant sein, da Sie bereits Tickets kaufen oder zu einer Aufführung gehen könnten. Wenn Sie nach einem Bohrer suchen - Sie suchen danach, finden, kaufen, hängen ein Regal auf und nach ein paar Tagen beginnt das Bombardement: „Kaufen Sie einen Bohrer!“.
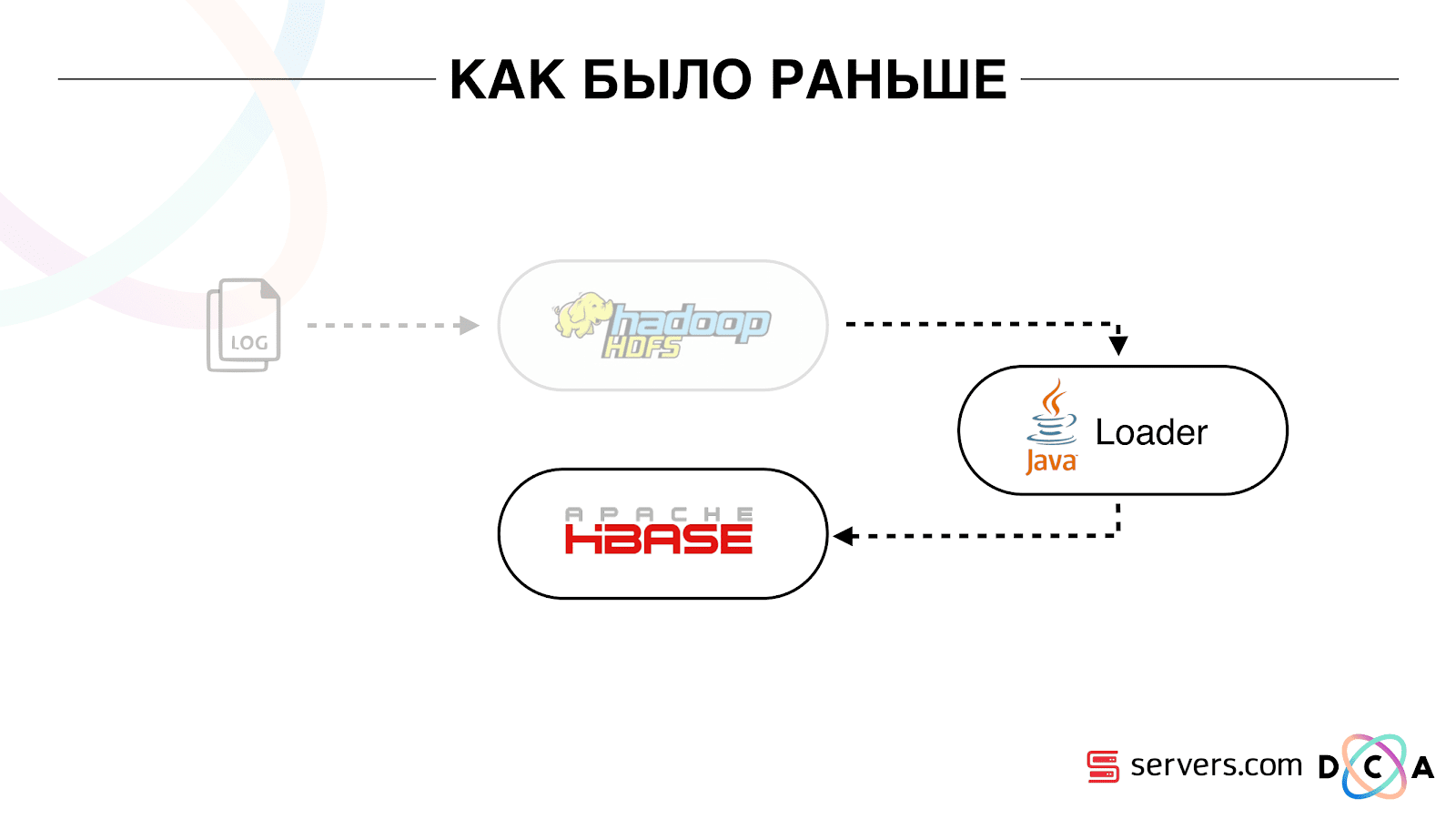
Wie zuvor
Der gesamte Artikel befasst sich mit dem Recycling von Architektur. Ich möchte Ihnen sagen, was unser Ausgangspunkt war, wie alles vor den Änderungen funktioniert hat.
Alle Daten, die wir hatten, ob es sich um einen direkten Datenstrom oder um Protokolle handelte, wurden in einem HDFS-verteilten Dateispeicher gespeichert. Dann gab es einen bestimmten Prozess, der regelmäßig gestartet wurde, alle unverarbeiteten Dateien aus HDFS nahm und sie in Datenanreicherungsanforderungen in HBase konvertierte („PUT-Anforderungen“).
Wie speichern wir Daten in HBase?
Dies ist eine spaltenweise Zeitreihendatenbank. Sie hat das Konzept eines Zeilenschlüssels - dies ist der Schlüssel, unter dem Sie Ihre Daten speichern. Wir verwenden die Benutzer-ID als Schlüssel, die Benutzer-ID, die wir generieren, wenn wir den Benutzer zum ersten Mal sehen. In jedem Schlüssel sind die Daten in Spaltenfamilien unterteilt - Entitäten, auf deren Ebene Sie die Metainformationen Ihrer Daten verwalten können. Sie können beispielsweise tausend Versionen von Datensätzen für „Daten“ der Spaltenfamilie speichern und diese zwei Monate lang speichern, und für die „Rohdaten“ der Spaltenfamilie - optional ein Jahr.
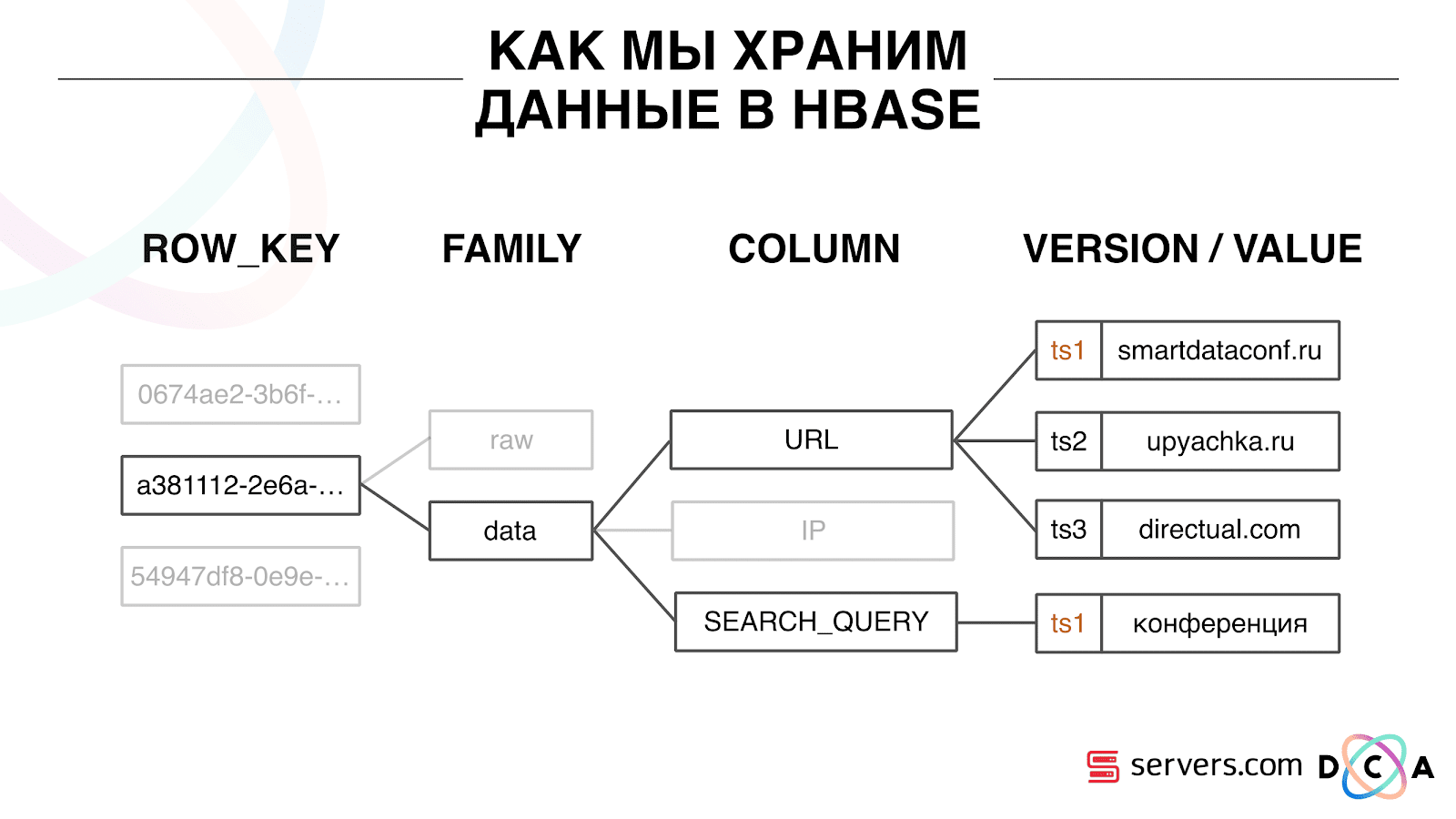
Innerhalb der Spaltenfamilie gibt es viele Spaltenqualifizierer (im Folgenden Spalte). Wir verwenden verschiedene Benutzerattribute als Spalte. Es könnte die URL sein, zu der er gegangen ist, IP-Adresse, Suchanfrage. Und am wichtigsten ist, dass in jeder Spalte viele Informationen gespeichert sind. Innerhalb der Spalten-URL kann angegeben werden, dass der Benutzer zu smartdataconf.ru und dann zu einigen anderen Websites gegangen ist. Als Version wird der Zeitstempel verwendet. Sie sehen einen geordneten Verlauf der Benutzerbesuche. In unserem Fall können wir feststellen, dass der Benutzer mit dem Schlüsselwort "Konferenz" auf die smartdataconf-Website gelangt ist, da er denselben Zeitstempel hat.
Arbeite mit HBase
Es gibt verschiedene Möglichkeiten, mit HBase zu arbeiten. Dies können PUT-Anforderungen (Anforderung zur Datenänderung), GET-Anforderung ("Geben Sie mir alle Daten zum Benutzer Vasya" usw.) sein. Sie können SCAN-Anforderungen ausführen - sequentielles Multithread-Scannen aller Daten in HBase. Wir haben dies früher zum Markieren in Zielgruppensegmenten verwendet.
Es gab eine Aufgabe namens Analytics Engine, die einmal am Tag ausgeführt und HBase in mehreren Threads gescannt wurde. Für jeden Benutzer hat sie die gesamte Geschichte aus HBase entfernt und eine Reihe von Analyseskripten durchlaufen.

Was ist ein Analyseskript? Dies ist eine Art Black Box (Java-Klasse), die alle Benutzerdaten als Eingabe empfängt und eine Reihe von Segmenten angibt, die sie als Ausgabe als geeignet erachtet. Wir geben alles an das Skript, das wir sehen - IP, Besuche, UserAgent usw., und in der Ausgabe geben die Skripte Folgendes aus: „Dies ist eine Frau, liebt Katzen, mag keine Hunde“.
Diese Daten wurden an Partner weitergegeben, Statistiken wurden berücksichtigt. Für uns war es wichtig zu verstehen, wie viele Frauen im Allgemeinen sind, wie viele Männer, wie viele Menschen Katzen lieben, wie viele ein Auto haben oder nicht und so weiter.
Wir haben Statistiken in MongoDB gespeichert und geschrieben, indem wir für jeden Tag einen bestimmten Segmentzähler erhöht haben. Wir hatten eine grafische Darstellung des Volumens jedes Segments für jeden Tag.
Dieses System war gut für seine Zeit. Es erlaubte, horizontal zu skalieren, zu wachsen, das Volumen des Publikums zu schätzen, aber es hatte eine Reihe von Nachteilen.
Es war nicht immer möglich zu verstehen, was im System vor sich ging, um die Protokolle zu betrachten. Während wir beim vorherigen Hoster waren, fiel die Aufgabe aus verschiedenen Gründen ziemlich oft. Es gab einen Hadoop-Cluster mit mehr als 20 Servern, einmal am Tag stürzte einer der Server stabil ab. Dies führte dazu, dass die Aufgabe teilweise fallen konnte und die Daten nicht berechnet wurden. Es war notwendig, Zeit zu haben, um es neu zu starten, und da es mehrere Stunden funktionierte, gab es eine Reihe bestimmter Nuancen.
Das Grundlegendste, was die vorhandene Architektur nicht erfüllte, war, dass die Reaktionszeit auf das Ereignis zu lang war. Es gibt sogar eine Geschichte zu diesem Thema. Es gab ein Unternehmen, das der Bevölkerung in den Regionen Mikrokredite gewährte, und wir haben mit ihnen zusammengearbeitet. Ihr Kunde kommt auf die Website, füllt einen Antrag auf Mikrokredit aus, das Unternehmen muss innerhalb von 15 Minuten eine Antwort geben: Sind sie bereit, einen Kredit zu vergeben oder nicht? Wenn Sie bereit sind, haben sie sofort Geld auf die Karte überwiesen.
Alles hat irgendwie gut funktioniert. Der Kunde entschied sich zu überprüfen, wie es im Allgemeinen passiert: Er nahm einen separaten Laptop, installierte ein sauberes System, besuchte viele Seiten im Internet und ging zu seiner Website. Sie sehen, dass es eine Anfrage gibt, und als Antwort sagen wir, dass es noch keine Daten gibt. Der Kunde fragt: "Warum gibt es keine Daten?"
Wir erklären: Es gibt eine gewisse Verzögerung, bevor der Benutzer eine Aktion ausführt. Daten werden an HBase gesendet, verarbeitet und erst dann erhält der Client das Ergebnis. Es scheint, dass nichts Schlimmes passieren wird, wenn der Benutzer die Werbung nicht gesehen hat - alles ist in Ordnung. In dieser Situation erhält der Benutzer aufgrund der Verzögerung möglicherweise kein Darlehen.
Dies ist kein Einzelfall, und es musste auf ein Echtzeitsystem umgestellt werden. Was wollen wir von ihr?

Wir möchten Daten in HBase schreiben, sobald wir sie sehen. Wir haben einen Besuch gesehen, alles, was wir wissen, bereichert und an Storage gesendet. Sobald sich die Daten im Speicher geändert haben, müssen Sie sofort alle vorhandenen Analyseskripts ausführen. Wir möchten die Bequemlichkeit der Überwachung und Entwicklung, die Fähigkeit, neue Skripte zu schreiben und sie in Teile des realen Datenverkehrs zu debuggen. Wir möchten verstehen, was das System gerade beschäftigt.
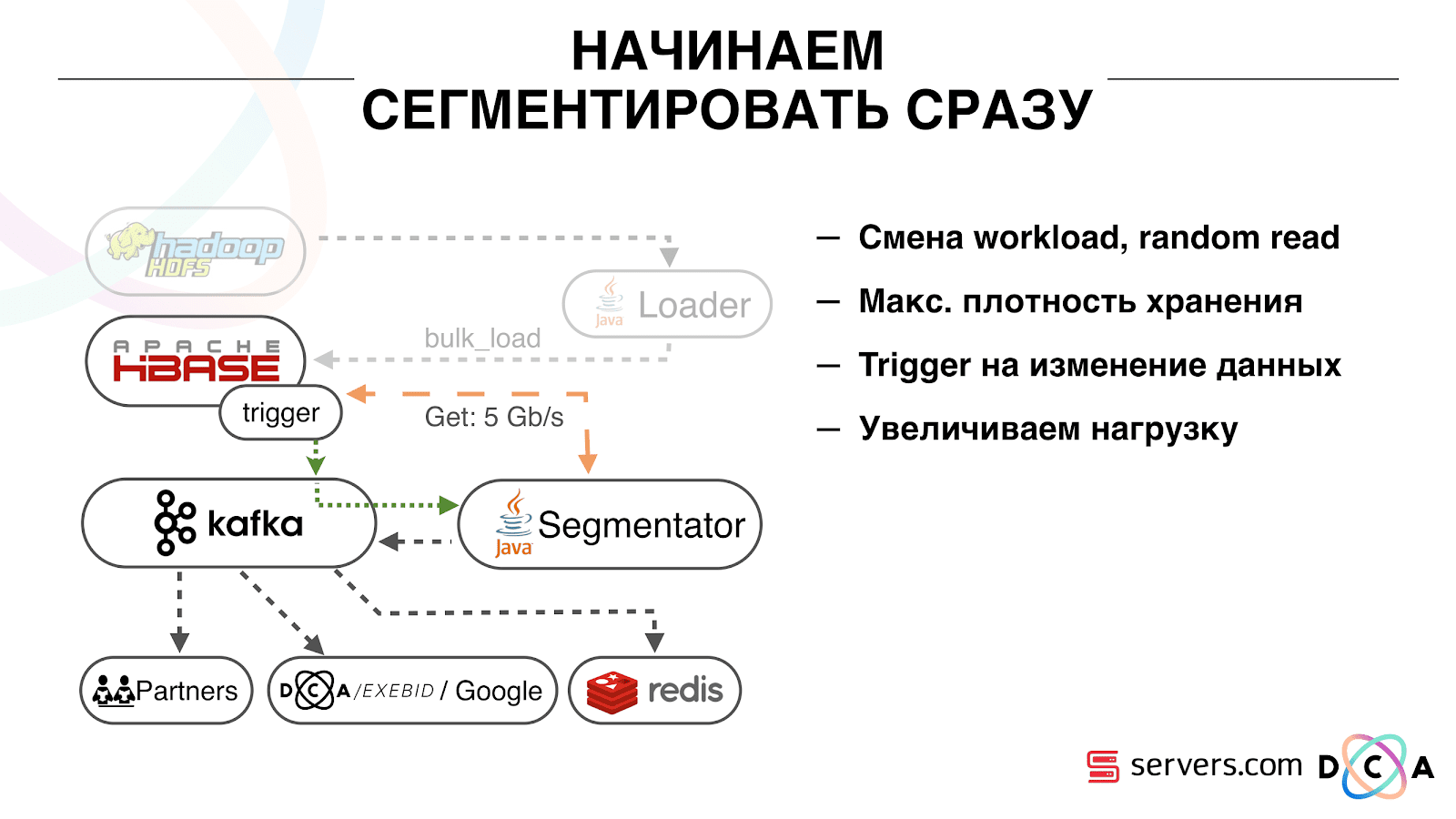
Das erste, mit dem wir begonnen haben, ist die Lösung des zweiten Problems: Segmentieren Sie den Benutzer unmittelbar nach dem Ändern der Daten über ihn in HBase. Anfänglich hatten wir Worker-Knoten (auf denen Kartenreduzierungsaufgaben gestartet wurden) am selben Ort wie HBase. In einigen Fällen war es sehr gut - die Berechnungen werden neben den Daten durchgeführt, Aufgaben funktionieren recht schnell, wenig Verkehr geht durch das Netzwerk. Es ist klar, dass die Aufgabe einige Ressourcen verbraucht, da sie komplexe Analyseskripte ausführt.
Wenn wir in Echtzeit zur Arbeit gehen, ändert sich die Art der Belastung von HBase. Wir gehen zu zufälligen statt zu sequentiellen Messwerten über. Es ist wichtig, dass die Belastung von HBase erwartet wird. Wir können nicht zulassen, dass jemand die Aufgabe auf dem Hadoop-Cluster ausführt und die HBase-Leistung beeinträchtigt.
Als erstes haben wir HBase auf separate Server verschoben. Außerdem wurden BlockCache und BloomFilter optimiert. Dann haben wir gute Arbeit geleistet, um Daten in HBase zu speichern. Sie haben das System, über das ich am Anfang gesprochen habe, ziemlich überarbeitet und die Daten selbst geerntet.

Aus dem Offensichtlichen: Wir haben IP als Zeichenfolge gespeichert und sind in Zahlen lang geworden. Einige Daten wurden klassifiziert, Vokabeln ausgeführt und so weiter. Unter dem Strich konnten wir HBase deshalb etwa zweimal schütteln - von 10 TB auf 5 TB. HBase hat einen ähnlichen Mechanismus wie Trigger in einer regulären Datenbank. Dies ist ein Coprozessormechanismus. Wir haben einen Coprozessor geschrieben, der beim Wechsel eines Benutzers zu HBase die Benutzer-ID an Kafka sendet.
Die Benutzer-ID befindet sich in Kafka. Weiterhin gibt es einen bestimmten Service "Segmentator". Es liest den Strom von Benutzerkennungen und führt auf ihnen dieselben Skripte wie zuvor aus und fordert Daten von HBase an. Der Prozess wurde bei 10% des Datenverkehrs gestartet. Wir haben uns angesehen, wie er funktioniert. Alles war ziemlich gut.

Als nächstes begannen wir, die Last zu erhöhen und sahen eine Reihe von Problemen. Das erste, was wir sahen, war, dass der Service funktioniert, segmentiert und dann von Kafka abfällt, eine Verbindung herstellt und wieder funktioniert. Mehrere Dienste - sie helfen sich gegenseitig. Dann fällt der nächste ab, ein anderer und so weiter im Kreis. Gleichzeitig wird die Aufstellung der Benutzer für die Segmentierung fast nicht geharkt.
Dies lag an der Besonderheit des Herzschlagmechanismus in Kafka, damals war es noch Version 0.8. Herzschlag ist, wenn die Verbraucher dem Broker mitteilen, ob sie am Leben sind oder nicht, in unserem Fall berichtet der Segmentierer. Folgendes ist passiert: Wir haben ein ziemlich großes Datenpaket erhalten und zur Verarbeitung gesendet. Für eine Weile funktionierte es, während es funktionierte - es wurde kein Herzschlag gesendet. Makler glaubten, dass der Verbraucher tot war, und schalteten ihn aus.
Der Verbraucher arbeitete bis zum Ende, verschwendete wertvolle CPUs und versuchte zu sagen, dass das Datenpaket ausgearbeitet wurde und das nächste genommen werden konnte, aber er wurde abgelehnt, weil der andere wegnahm, womit er arbeitete. Wir haben es behoben, indem wir unseren Hintergrund-Heatbeat gemacht haben. Dann kam die Wahrheit zu einer neueren Version von Kafka, bei der wir dieses Problem behoben haben.
Dann stellte sich die Frage: Auf welcher Hardware sollten unsere Segmentatoren installiert werden? Die Segmentierung ist ein ressourcenintensiver Prozess (CPU-gebunden). Es ist wichtig, dass der Dienst nicht nur viel CPU verbraucht, sondern auch das Netzwerk lädt. Jetzt erreicht der Verkehr 5 Gbit / s. Die Frage war: Wo sollen die Dienste auf vielen kleinen oder kleinen Servern abgelegt werden?
Zu diesem Zeitpunkt sind wir bereits auf Bare Metal zu
servers.com gewechselt . Wir haben mit den Jungs von den Servern gesprochen, sie haben uns geholfen und es ermöglicht, die Arbeit unserer Lösung sowohl auf einer kleinen Anzahl teurer Server als auch auf vielen kostengünstigen Servern mit leistungsstarken CPUs zu testen. Wir haben die entsprechende Option ausgewählt und die Stückkosten für die Verarbeitung eines Ereignisses pro Sekunde berechnet. Übrigens fiel die Wahl auf ausreichend leistungsfähiges und gleichzeitig äußerst erschwingliches Dell R230, sie haben es auf den Markt gebracht - alles hat funktioniert.
Es ist wichtig, dass, nachdem der Segmentierer den Benutzer in Segmente markiert hat, das Ergebnis seiner Analyse in einem bestimmten Thema Segmentierungsergebnis auf Kafka zurückgreift.
Darüber hinaus können wir unabhängig voneinander verschiedene Verbraucher mit diesen Daten verbinden, die sich nicht gegenseitig stören. Auf diese Weise können wir jedem Partner unabhängig Daten geben, sei es einigen externen Partnern, internen DSP, Google oder Statistiken.
Bei Statistiken gibt es auch einen interessanten Punkt: Früher konnten wir den Wert von Zählern in MongoDB erhöhen, wie viele Benutzer sich an einem bestimmten Tag in einem bestimmten Segment befanden. Dies ist jetzt nicht möglich, da wir jetzt jeden Benutzer analysieren, nachdem er ein Ereignis abgeschlossen hat, d. H. mehrmals am Tag.
Daher mussten wir das Problem lösen, die eindeutige Anzahl von Benutzern im Stream zu zählen. Zu diesem Zweck haben wir die HyperLogLog-Datenstruktur und ihre Implementierung in Redis verwendet. Die Datenstruktur ist probabilistisch. Dies bedeutet, dass Sie dort Benutzerkennungen hinzufügen können. Die Kennungen selbst werden nicht gespeichert, sodass Sie Millionen von eindeutigen Kennungen in HyperLogLog äußerst kompakt speichern können. Dies dauert bis zu 12 Kilobyte pro Schlüssel.
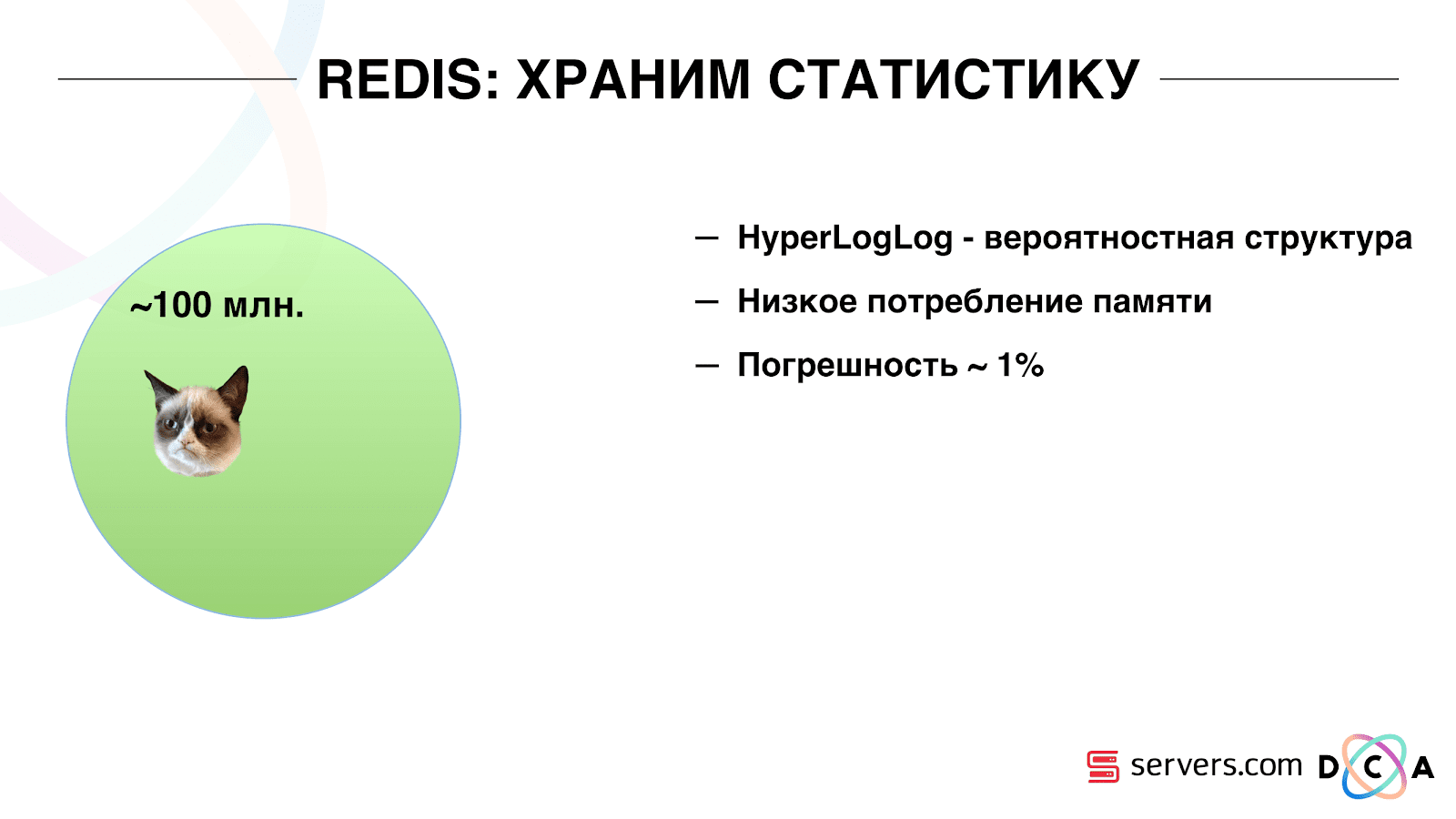
Sie können die Bezeichner nicht selbst erhalten, aber Sie können die Größe dieses Satzes herausfinden. Da die Datenstruktur probabilistisch ist, liegt ein Fehler vor. Wenn Sie beispielsweise ein Segment haben, das Katzen mag und für einen bestimmten Tag eine Anfrage nach der Größe dieses Segments stellt, erhalten Sie 99,2 Millionen und dies bedeutet etwa „von 99 Millionen auf 100 Millionen“.
Auch in HyperLogLog können Sie die Größe der Vereinigung mehrerer Sätze ermitteln. Angenommen, Sie haben zwei Segmente: "liebt Robben" und "liebt Hunde". Sagen wir die ersten 100 Millionen, die zweiten 1 Million. Man kann fragen: "Wie viele Tiere mögen sie?" und erhalten Sie die Antwort "ungefähr 101 Millionen" mit einem Fehler von 1%. Es wäre interessant zu berechnen, wie sehr Katzen und Hunde gleichzeitig geliebt werden, aber dies zu tun ist ziemlich schwierig.

Einerseits können Sie die Größe jedes Satzes ermitteln, die Größe der Vereinigung ermitteln, addieren, voneinander subtrahieren und den Schnittpunkt ermitteln. Aufgrund der Tatsache, dass die Größe des Fehlers größer sein kann als die Größe des endgültigen Schnittpunkts, kann das Endergebnis die Form "von -50 bis 50.000" haben.

Wir haben viel daran gearbeitet, die Leistung beim Schreiben von Daten in Redis zu steigern. Anfangs erreichten wir 200.000 Operationen pro Sekunde. Wenn jedoch jeder Benutzer mehr als 50 Segmente hat - Informationen über jeden Benutzer aufzeichnen - 50 Vorgänge. Es stellt sich heraus, dass wir nur eine begrenzte Bandbreite haben und in diesem Beispiel keine Informationen über mehr als 4.000 Benutzer pro Sekunde schreiben können. Dies ist um ein Vielfaches weniger als erforderlich.
Wir haben über Lua eine separate „gespeicherte Prozedur“ in Redis erstellt, dort geladen und eine Zeichenfolge mit der gesamten Liste der Segmente eines Benutzers übergeben. Die darin enthaltene Prozedur schneidet die übergebene Zeichenfolge in die erforderlichen HyperLogLog-Updates und speichert die Daten, sodass wir ungefähr 1 Million Updates pro Sekunde erreicht haben.
Ein bisschen Hardcore: Redis ist Single-Threaded, Sie können es an einen Prozessorkern und eine Netzwerkkarte an einen anderen anheften und eine weitere Leistung von 15% erzielen, wodurch Kontextwechsel eingespart werden. Darüber hinaus ist der wichtige Punkt, dass Sie die Datenstruktur nicht einfach gruppieren können, da die Operationen zum Erhalten der Leistung der Gruppenvereinigungen nicht gruppiert werden
Kafka ist ein großartiges Werkzeug
Sie sehen, dass Kafka unser Haupttransportinstrument im System ist.
Es hat die Essenz von "Thema". Hier schreiben Sie die Daten, aber im Wesentlichen die Warteschlange. In unserem Fall gibt es mehrere Warteschlangen. Eine davon sind Kennungen von Benutzern, die segmentiert werden müssen. Das zweite sind Segmentierungsergebnisse.
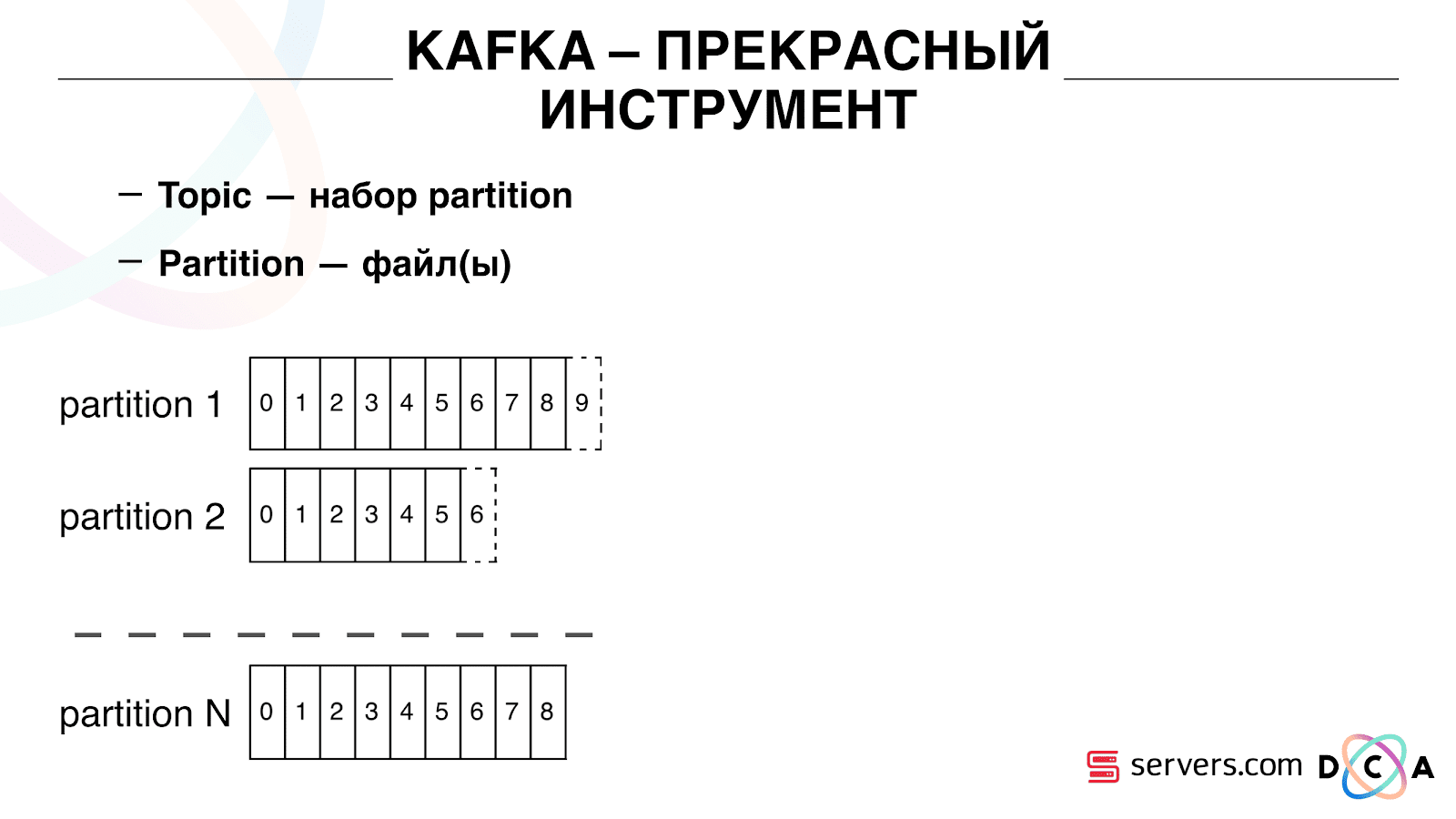
Ein Thema ist eine Reihe von Partitionen. Es ist in einige Teile unterteilt. Jede Partition ist eine Datei auf der Festplatte. Wenn Ihre Produzenten Daten schreiben, schreiben sie Textstücke an das Ende der Partition. Wenn Ihre Kunden die Daten lesen, lesen sie einfach von diesen Partitionen.
Wichtig ist, dass Sie mehrere Verbrauchergruppen unabhängig voneinander verbinden können. Diese verbrauchen Daten, ohne sich gegenseitig zu stören. Dies wird durch den Namen der Verbrauchergruppe bestimmt und wie folgt erreicht.
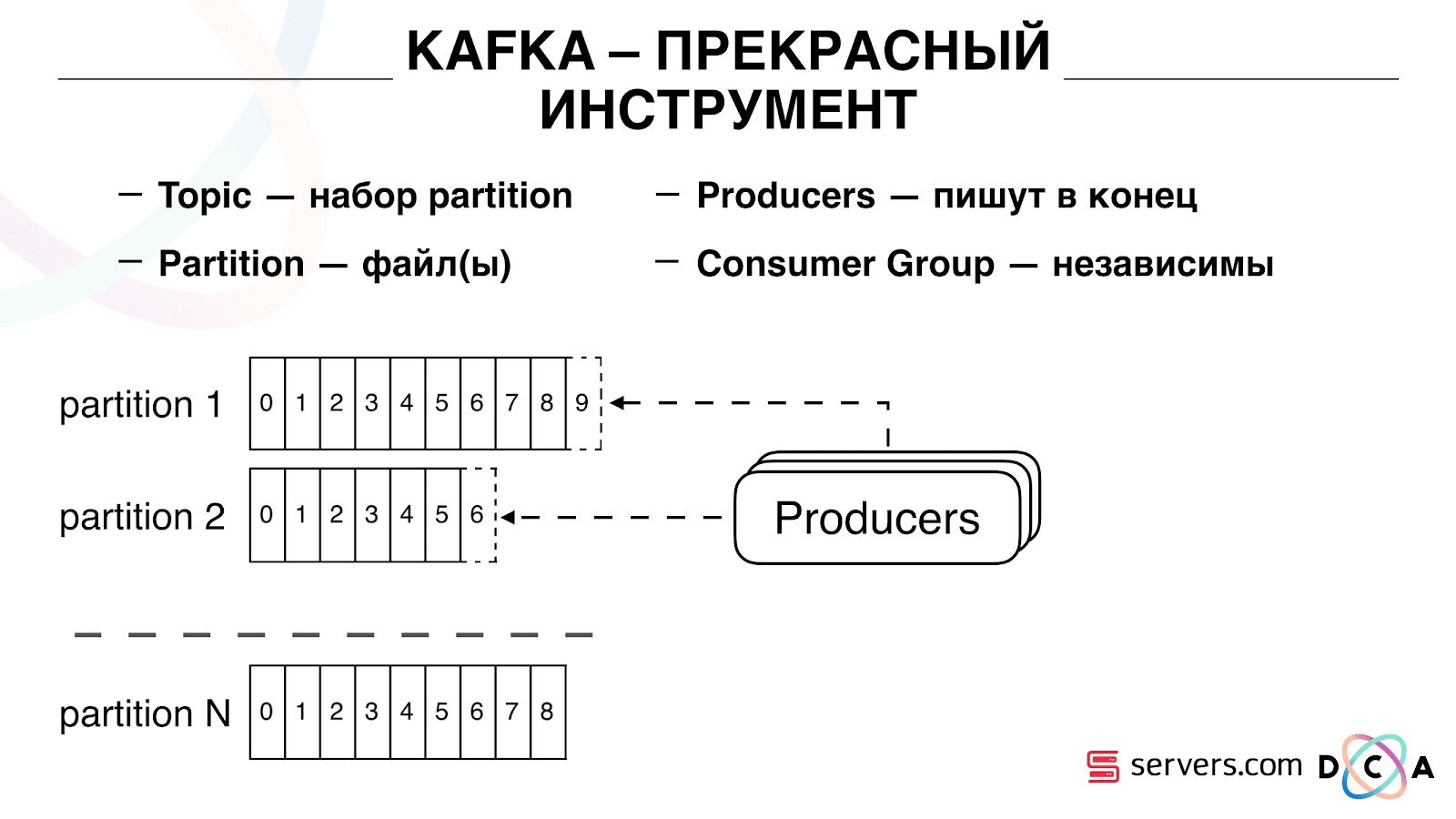
Es gibt so etwas wie einen Versatz, die Position, an der sich die Verbrauchergruppe jetzt auf jeder Partition befindet. Beispielsweise verwendet Gruppe A die siebte Nachricht von Partition1 und die fünfte von Partition2. Gruppe B, unabhängig von A, hat einen anderen Versatz.
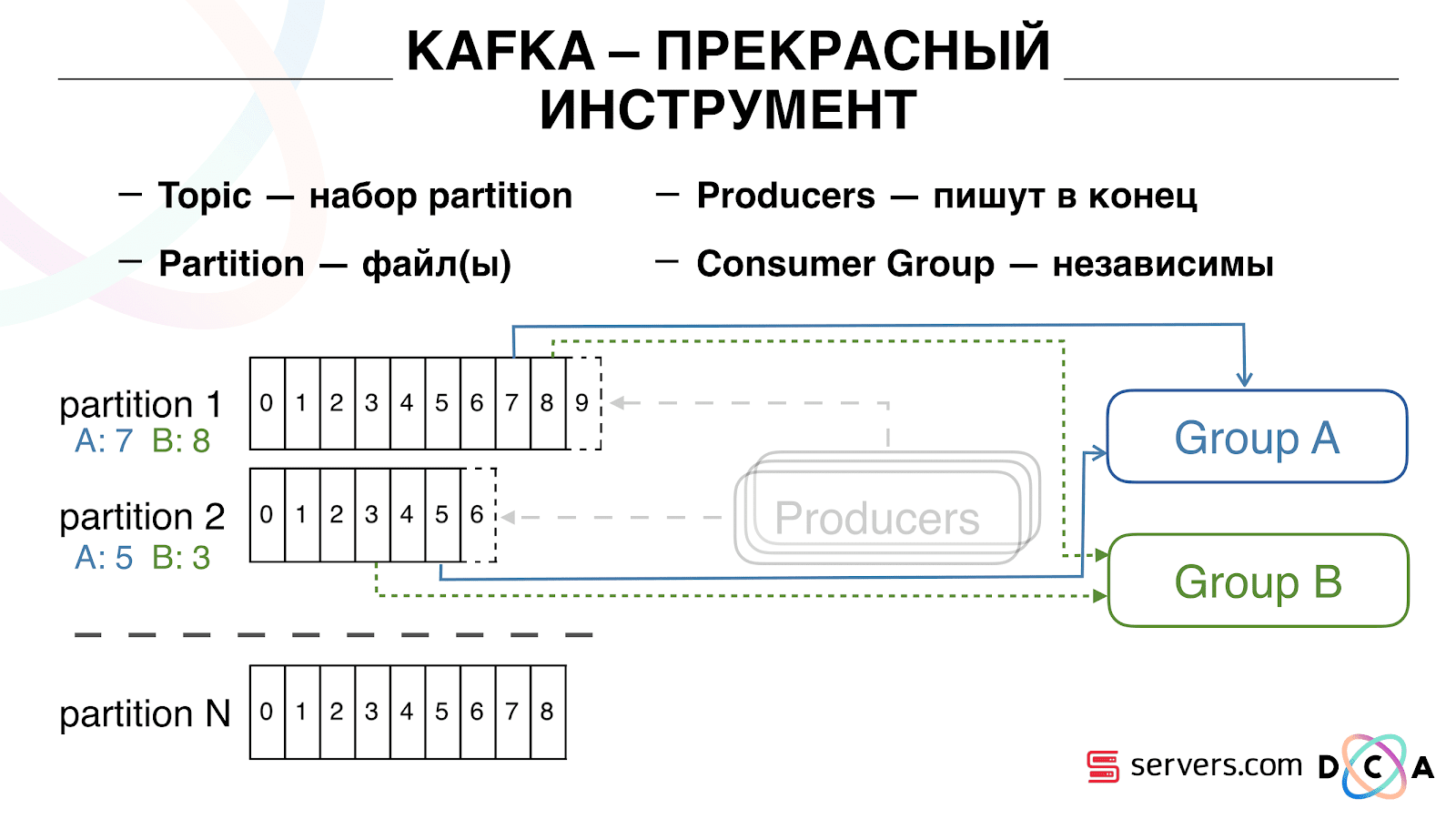 Sie können Ihre Verbrauchergruppe horizontal skalieren, einen weiteren Prozess oder Server hinzufügen. Dies geschieht durch eine Neuzuweisung von Partitionen (Kafka Broker weist jedem Verbraucher eine Liste von Partitionen für den Verbrauch zu). Dies bedeutet, dass die erste Verbrauchergruppe nur Partition 1 und die zweite nur Partition 2 verbraucht. Wenn einige der Verbraucher sterben (z. B. kommt kein Hearthbeat), erfolgt eine neue Neuzuweisung Jeder Verbraucher erhält eine aktuelle Partitionsliste zur Verarbeitung.
Sie können Ihre Verbrauchergruppe horizontal skalieren, einen weiteren Prozess oder Server hinzufügen. Dies geschieht durch eine Neuzuweisung von Partitionen (Kafka Broker weist jedem Verbraucher eine Liste von Partitionen für den Verbrauch zu). Dies bedeutet, dass die erste Verbrauchergruppe nur Partition 1 und die zweite nur Partition 2 verbraucht. Wenn einige der Verbraucher sterben (z. B. kommt kein Hearthbeat), erfolgt eine neue Neuzuweisung Jeder Verbraucher erhält eine aktuelle Partitionsliste zur Verarbeitung. Es ist sehr praktisch. Zunächst können Sie den Offset für jede Verbrauchergruppe bearbeiten. Stellen Sie sich vor, es gibt einen Partner, an den Sie Daten aus diesem Thema mit den Ergebnissen der Segmentierung übertragen. Er schreibt, dass er versehentlich den letzten Tag der Daten infolge eines Fehlers verloren hat. Und Sie, für die Verbrauchergruppe dieses Kunden, rollen einfach einen Tag zurück und gießen den gesamten Datentag darauf. Wir können auch eine eigene Verbrauchergruppe haben, eine Verbindung zum Produktionsverkehr herstellen, beobachten, was passiert, und reale Daten debuggen.Wir haben also erreicht, dass wir begonnen haben, Benutzer beim Wechsel zu segmentieren, neue Verbraucher unabhängig voneinander zu verbinden, Statistiken zu schreiben und sie zu beobachten. Jetzt müssen Sie die Daten sofort nach Eingang bei uns in HBase schreiben lassen.
Es ist sehr praktisch. Zunächst können Sie den Offset für jede Verbrauchergruppe bearbeiten. Stellen Sie sich vor, es gibt einen Partner, an den Sie Daten aus diesem Thema mit den Ergebnissen der Segmentierung übertragen. Er schreibt, dass er versehentlich den letzten Tag der Daten infolge eines Fehlers verloren hat. Und Sie, für die Verbrauchergruppe dieses Kunden, rollen einfach einen Tag zurück und gießen den gesamten Datentag darauf. Wir können auch eine eigene Verbrauchergruppe haben, eine Verbindung zum Produktionsverkehr herstellen, beobachten, was passiert, und reale Daten debuggen.Wir haben also erreicht, dass wir begonnen haben, Benutzer beim Wechsel zu segmentieren, neue Verbraucher unabhängig voneinander zu verbinden, Statistiken zu schreiben und sie zu beobachten. Jetzt müssen Sie die Daten sofort nach Eingang bei uns in HBase schreiben lassen.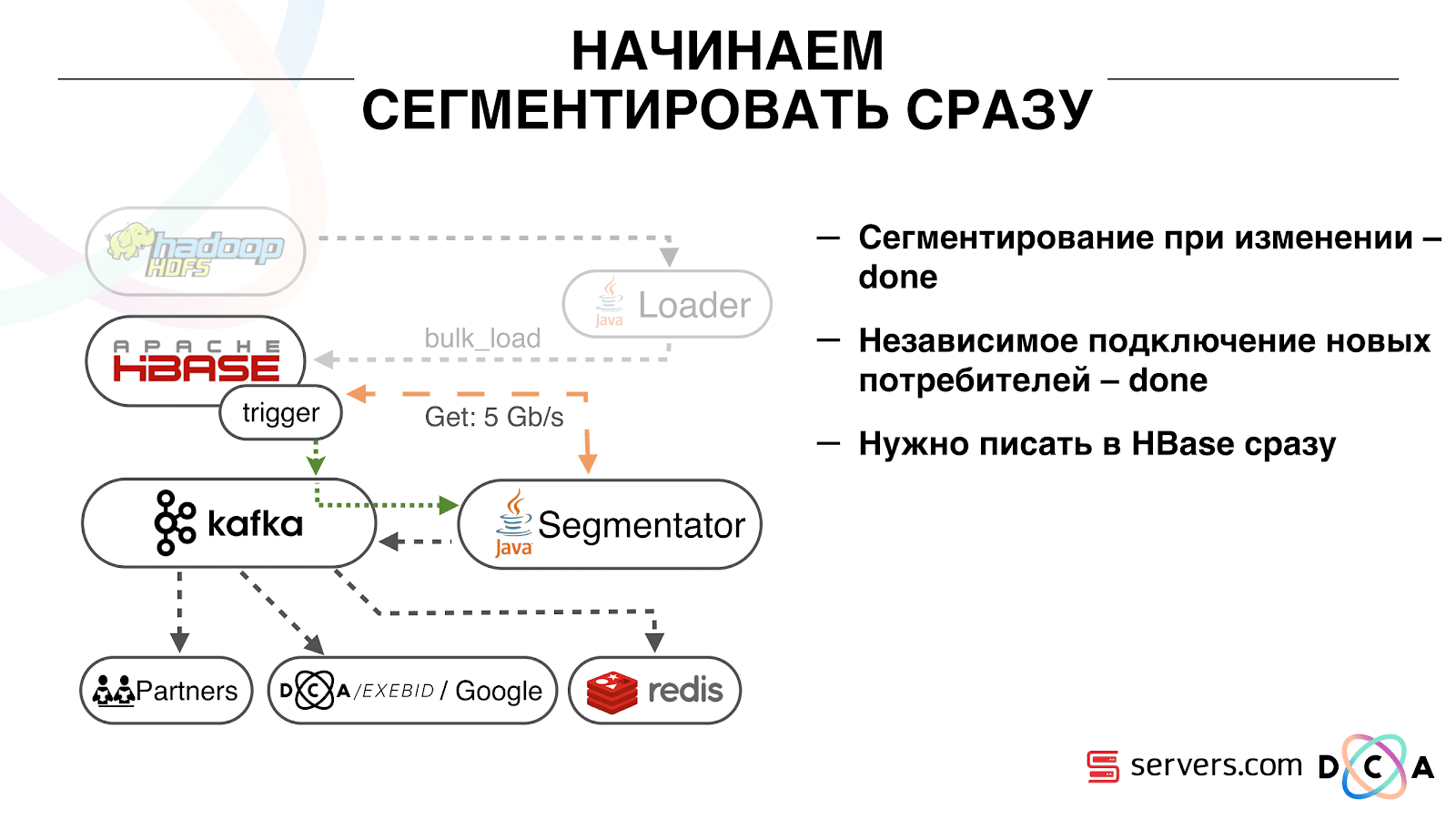 Wie wir es gemacht haben. Früher wurden Batch-Daten geladen. Es gab einen Batch Loader, der Benutzeraktivitätsprotokolldateien verarbeitete: Wenn ein Benutzer 10 Besuche machte, kam der Batch für 10 Ereignisse und wurde in einem Vorgang in HBase aufgezeichnet. Es gab nur ein Ereignis pro Segmentierung. Jetzt wollen wir jedes einzelne Ereignis in den Speicher schreiben. Wir werden den Schreib- und den Lesestream stark erhöhen. Die Anzahl der Ereignisse pro Segmentierung wird ebenfalls erhöht.
Wie wir es gemacht haben. Früher wurden Batch-Daten geladen. Es gab einen Batch Loader, der Benutzeraktivitätsprotokolldateien verarbeitete: Wenn ein Benutzer 10 Besuche machte, kam der Batch für 10 Ereignisse und wurde in einem Vorgang in HBase aufgezeichnet. Es gab nur ein Ereignis pro Segmentierung. Jetzt wollen wir jedes einzelne Ereignis in den Speicher schreiben. Wir werden den Schreib- und den Lesestream stark erhöhen. Die Anzahl der Ereignisse pro Segmentierung wird ebenfalls erhöht. Als erstes haben wir HBase auf die SSD portiert. Standardmäßig wird dies nicht besonders durchgeführt. Dies wurde mit HDFS durchgeführt. Sie können sagen, dass sich ein bestimmtes Verzeichnis in HDFS auf einer solchen Gruppe von Festplatten befinden muss. Es gab ein cooles Problem mit der Tatsache, dass, als wir HBase zur SSD brachten und sie stoppten, alle Schnappschüsse dort ankamen und unsere SSDs ziemlich schnell endeten.Dies ist auch gelöst. Wir haben begonnen, regelmäßig Snapshots in eine Datei zu exportieren, in ein anderes HDFS-Verzeichnis zu schreiben und alle Metainformationen zu Snapshots zu löschen. Wenn Sie wiederherstellen müssen - nehmen Sie die gespeicherte Datei, importieren und wiederherstellen. Diese Operation ist zum Glück sehr selten.Auch auf der SSD haben sie Write Ahead Log, Twisted MemStore, herausgenommen und den Cache-Block beim Schreiben aktiviert. Sie können sie beim Aufzeichnen von Daten sofort in den Blockcache stellen. Das ist sehr praktisch, weil In unserem Fall ist es sehr wahrscheinlich, dass die Daten sofort gelesen werden, wenn wir sie aufgezeichnet haben. Dies gab auch einige Vorteile.Als nächstes haben wir alle unsere Datenquellen auf das Schreiben von Daten in Kafka umgestellt. Bereits von Kafka aus haben wir Daten in HDFS aufgezeichnet, um die Abwärtskompatibilität aufrechtzuerhalten, einschließlich der Möglichkeit, dass unsere Analysten mit Daten arbeiten, MapReduce-Aufgaben ausführen und deren Ergebnisse analysieren können.Wir haben eine separate Verbrauchergruppe verbunden, die Daten in HBase schreibt. Dies ist in der Tat ein Wrapper, der aus Kafka liest und die PUTs in HBase bildet.
Als erstes haben wir HBase auf die SSD portiert. Standardmäßig wird dies nicht besonders durchgeführt. Dies wurde mit HDFS durchgeführt. Sie können sagen, dass sich ein bestimmtes Verzeichnis in HDFS auf einer solchen Gruppe von Festplatten befinden muss. Es gab ein cooles Problem mit der Tatsache, dass, als wir HBase zur SSD brachten und sie stoppten, alle Schnappschüsse dort ankamen und unsere SSDs ziemlich schnell endeten.Dies ist auch gelöst. Wir haben begonnen, regelmäßig Snapshots in eine Datei zu exportieren, in ein anderes HDFS-Verzeichnis zu schreiben und alle Metainformationen zu Snapshots zu löschen. Wenn Sie wiederherstellen müssen - nehmen Sie die gespeicherte Datei, importieren und wiederherstellen. Diese Operation ist zum Glück sehr selten.Auch auf der SSD haben sie Write Ahead Log, Twisted MemStore, herausgenommen und den Cache-Block beim Schreiben aktiviert. Sie können sie beim Aufzeichnen von Daten sofort in den Blockcache stellen. Das ist sehr praktisch, weil In unserem Fall ist es sehr wahrscheinlich, dass die Daten sofort gelesen werden, wenn wir sie aufgezeichnet haben. Dies gab auch einige Vorteile.Als nächstes haben wir alle unsere Datenquellen auf das Schreiben von Daten in Kafka umgestellt. Bereits von Kafka aus haben wir Daten in HDFS aufgezeichnet, um die Abwärtskompatibilität aufrechtzuerhalten, einschließlich der Möglichkeit, dass unsere Analysten mit Daten arbeiten, MapReduce-Aufgaben ausführen und deren Ergebnisse analysieren können.Wir haben eine separate Verbrauchergruppe verbunden, die Daten in HBase schreibt. Dies ist in der Tat ein Wrapper, der aus Kafka liest und die PUTs in HBase bildet.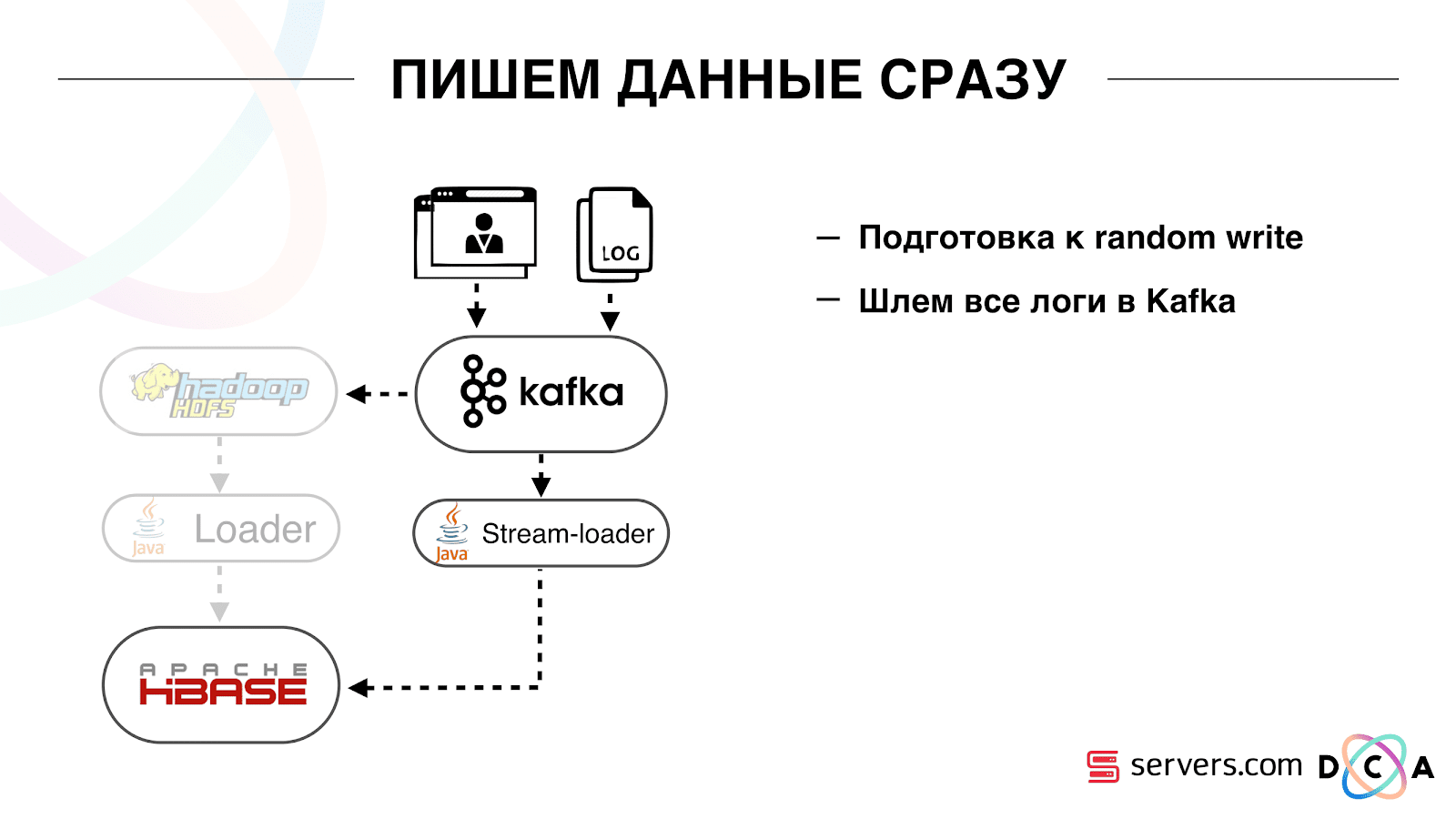 Wir haben zwei Schaltkreise parallel gestartet, um die Abwärtskompatibilität nicht zu beeinträchtigen und die Systemleistung nicht zu beeinträchtigen. Ein neues System wurde nur bei einem bestimmten Prozentsatz des Verkehrs eingeführt. Mit 10% war alles ziemlich cool. Bei größerer Belastung konnten die Segmentierer den Segmentierungsfluss jedoch nicht bewältigen.
Wir haben zwei Schaltkreise parallel gestartet, um die Abwärtskompatibilität nicht zu beeinträchtigen und die Systemleistung nicht zu beeinträchtigen. Ein neues System wurde nur bei einem bestimmten Prozentsatz des Verkehrs eingeführt. Mit 10% war alles ziemlich cool. Bei größerer Belastung konnten die Segmentierer den Segmentierungsfluss jedoch nicht bewältigen. Wir sammeln die Metrik "Wie viele Nachrichten lagen in Kafka, bevor sie von dort gelesen wurden?". Dies ist eine gute Metrik. Anfangs haben wir die Metrik "Wie viele Rohnachrichten sind jetzt" gesammelt, aber sie sagt nichts Besonderes aus. Sie sehen aus: "Ich habe eine Million Rohnachrichten", na und? Um diese Million zu interpretieren, müssen Sie wissen, wie schnell der Segmentator (Verbraucher) arbeitet, was nicht immer klar ist.Mit dieser Metrik sehen Sie sofort, dass die Daten in die Warteschlange geschrieben und daraus entnommen werden, und Sie sehen, wie viel sie voraussichtlich verarbeiten werden. Wir haben festgestellt, dass wir keine Zeit zum Segmentieren hatten und die Nachricht einige Stunden vor dem Lesen in der Warteschlange stand.Sie könnten einfach Kapazität hinzufügen, aber es wäre einfach zu
Wir sammeln die Metrik "Wie viele Nachrichten lagen in Kafka, bevor sie von dort gelesen wurden?". Dies ist eine gute Metrik. Anfangs haben wir die Metrik "Wie viele Rohnachrichten sind jetzt" gesammelt, aber sie sagt nichts Besonderes aus. Sie sehen aus: "Ich habe eine Million Rohnachrichten", na und? Um diese Million zu interpretieren, müssen Sie wissen, wie schnell der Segmentator (Verbraucher) arbeitet, was nicht immer klar ist.Mit dieser Metrik sehen Sie sofort, dass die Daten in die Warteschlange geschrieben und daraus entnommen werden, und Sie sehen, wie viel sie voraussichtlich verarbeiten werden. Wir haben festgestellt, dass wir keine Zeit zum Segmentieren hatten und die Nachricht einige Stunden vor dem Lesen in der Warteschlange stand.Sie könnten einfach Kapazität hinzufügen, aber es wäre einfach zu teuer . Deshalb haben wir versucht zu optimieren.Selbstskalierung
Wir haben HBase. Der Benutzer ändert sich, seine Kennung fliegt in Kafka. Das Thema ist in Partitionen unterteilt, die Zielpartition wird anhand der Benutzer-ID ausgewählt. Dies bedeutet, dass wenn Sie den Benutzer "Vasya" sehen - er geht zu Partition 1. Wenn Sie "Petya" sehen - zu Partition 2. Dies ist praktisch - Sie können erreichen, dass Sie einen Verbraucher auf einer Instanz Ihres Dienstes sehen, und den zweiten - auf der anderen Seite.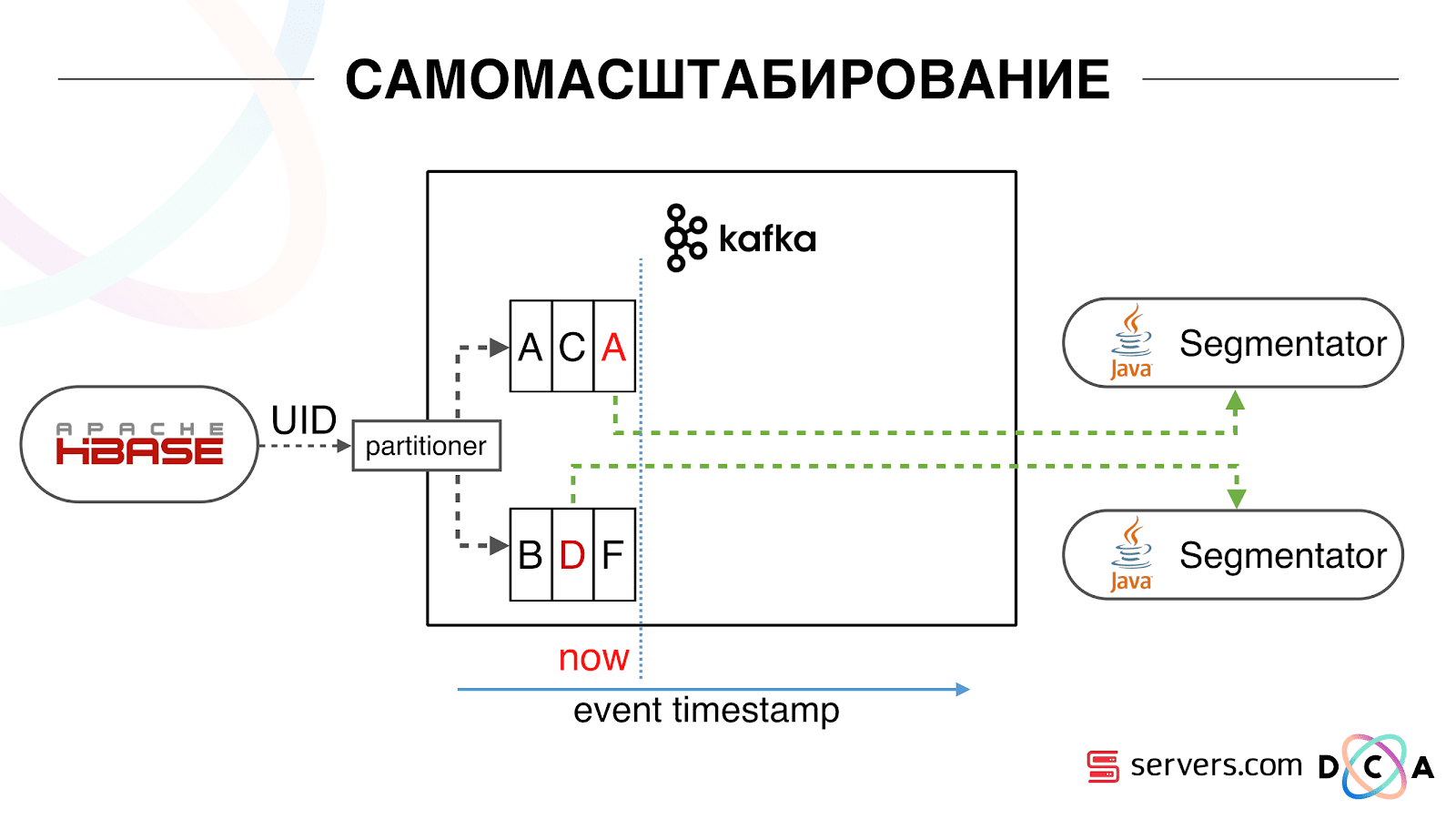 Wir begannen zu beobachten, was los war. Ein typisches Benutzerverhalten im Internet besteht darin, auf eine Website zu gehen und mehrere Hintergrundregisterkarten zu öffnen. Die zweite Möglichkeit besteht darin, zur Website zu gehen und mit wenigen Klicks zur Zielseite zu gelangen.Wir sehen uns die Segmentierungswarteschlange an und sehen Folgendes: Benutzer A hat die Seite besucht. 5 weitere Ereignisse kommen von diesem Benutzer - jedes bedeutet ein Öffnen der Seite. Wir verarbeiten jedes Ereignis vom Benutzer. Tatsächlich enthalten die Daten in HBase jedoch alle 5 Besuche. Wir verarbeiten alle 5 Besuche zum ersten Mal, zum zweiten Mal usw. - wir verschwenden CPU-Ressourcen.
Wir begannen zu beobachten, was los war. Ein typisches Benutzerverhalten im Internet besteht darin, auf eine Website zu gehen und mehrere Hintergrundregisterkarten zu öffnen. Die zweite Möglichkeit besteht darin, zur Website zu gehen und mit wenigen Klicks zur Zielseite zu gelangen.Wir sehen uns die Segmentierungswarteschlange an und sehen Folgendes: Benutzer A hat die Seite besucht. 5 weitere Ereignisse kommen von diesem Benutzer - jedes bedeutet ein Öffnen der Seite. Wir verarbeiten jedes Ereignis vom Benutzer. Tatsächlich enthalten die Daten in HBase jedoch alle 5 Besuche. Wir verarbeiten alle 5 Besuche zum ersten Mal, zum zweiten Mal usw. - wir verschwenden CPU-Ressourcen.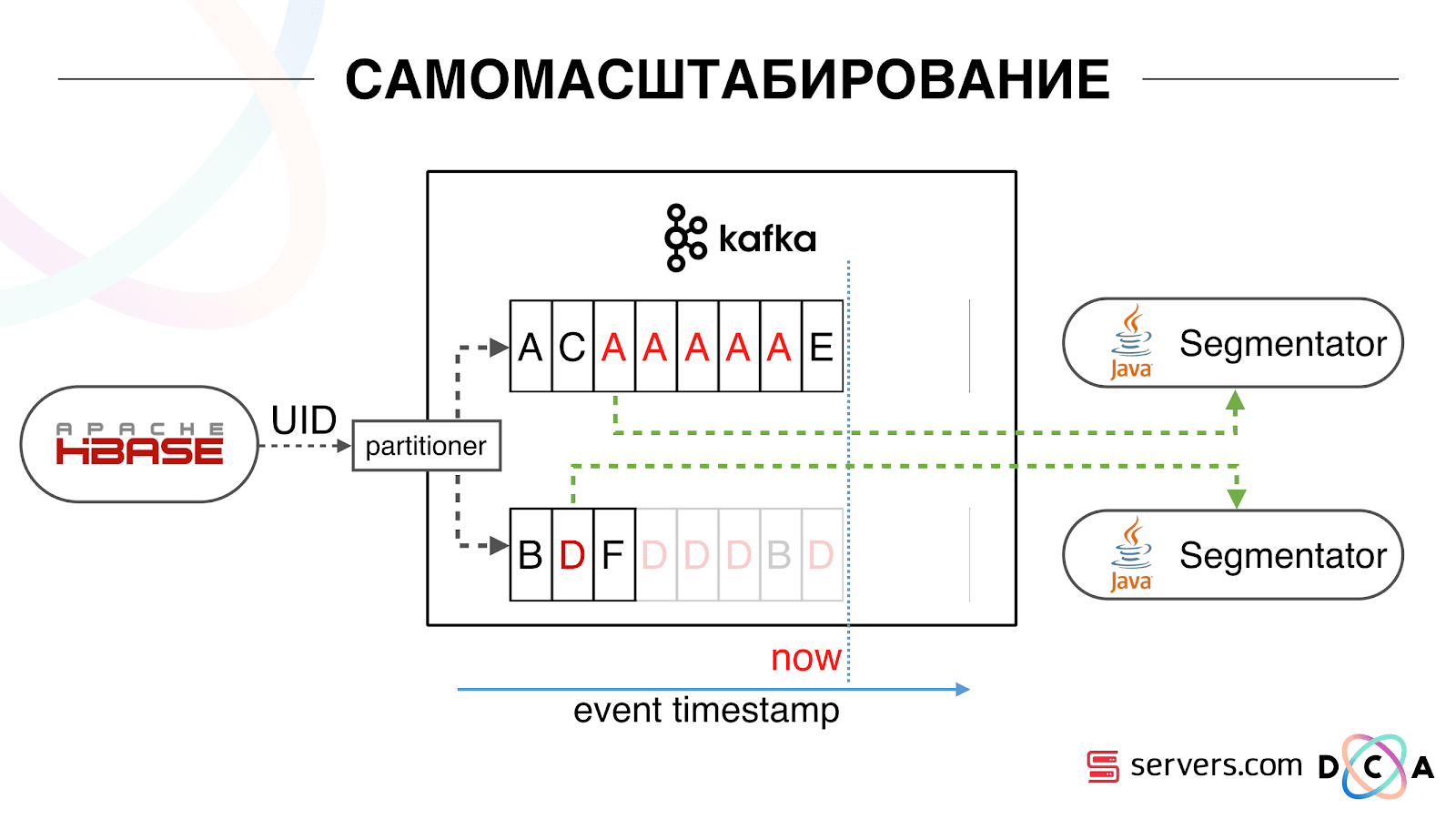 Aus diesem Grund haben wir begonnen, auf jedem Segmentierer einen bestimmten lokalen Cache mit dem Datum zu speichern, an dem wir diesen Benutzer zuletzt analysiert haben. Das heißt, wir haben es verarbeitet, seine Benutzer-ID und seinen Zeitstempel in den Cache geschrieben. Jede Kafka-Nachricht hat auch einen Zeitstempel - wir vergleichen ihn einfach: Wenn der Zeitstempel in der Warteschlange kleiner als das Datum der letzten Segmentierung ist - haben wir den Benutzer bereits auf diese Daten analysiert, und Sie können dieses Ereignis einfach überspringen.Benutzerereignisse (rotes A) können unterschiedlich sein und sind nicht in Ordnung. Der Benutzer kann mehrere Hintergrundregisterkarten öffnen, mehrere Links hintereinander öffnen. Möglicherweise hat die Site mehrere unserer Partner gleichzeitig, von denen jeder diese Daten sendet.Unser Pixel kann den Besuch des Benutzers und dann eine andere Aktion sehen - wir werden seinen Helm an uns selbst senden. Wenn fünf Ereignisse eintreffen, verarbeiten wir das erste rote A. Wenn das Ereignis eingetroffen ist, befindet es sich bereits in HBase. Wir sehen Ereignisse, durchlaufen eine Reihe von Skripten. Wir sehen das folgende Ereignis und dort alle die gleichen Ereignisse, weil sie bereits aufgezeichnet sind. Wir führen es erneut aus, speichern den Cache mit dem Datum und vergleichen ihn mit dem Zeitstempel des Ereignisses.
Aus diesem Grund haben wir begonnen, auf jedem Segmentierer einen bestimmten lokalen Cache mit dem Datum zu speichern, an dem wir diesen Benutzer zuletzt analysiert haben. Das heißt, wir haben es verarbeitet, seine Benutzer-ID und seinen Zeitstempel in den Cache geschrieben. Jede Kafka-Nachricht hat auch einen Zeitstempel - wir vergleichen ihn einfach: Wenn der Zeitstempel in der Warteschlange kleiner als das Datum der letzten Segmentierung ist - haben wir den Benutzer bereits auf diese Daten analysiert, und Sie können dieses Ereignis einfach überspringen.Benutzerereignisse (rotes A) können unterschiedlich sein und sind nicht in Ordnung. Der Benutzer kann mehrere Hintergrundregisterkarten öffnen, mehrere Links hintereinander öffnen. Möglicherweise hat die Site mehrere unserer Partner gleichzeitig, von denen jeder diese Daten sendet.Unser Pixel kann den Besuch des Benutzers und dann eine andere Aktion sehen - wir werden seinen Helm an uns selbst senden. Wenn fünf Ereignisse eintreffen, verarbeiten wir das erste rote A. Wenn das Ereignis eingetroffen ist, befindet es sich bereits in HBase. Wir sehen Ereignisse, durchlaufen eine Reihe von Skripten. Wir sehen das folgende Ereignis und dort alle die gleichen Ereignisse, weil sie bereits aufgezeichnet sind. Wir führen es erneut aus, speichern den Cache mit dem Datum und vergleichen ihn mit dem Zeitstempel des Ereignisses. Dank dessen erhielt das System die Eigenschaft der Selbstskalierbarkeit. Die y-Achse ist der Prozentsatz dessen, was wir mit Benutzer-IDs tun, wenn sie zu uns kommen. Grün - die Arbeit, die wir ausgeführt haben, hat das Segmentierungsskript gestartet. Gelb - das haben wir nicht gemacht, weil Bereits genau diese Daten segmentiert.
Dank dessen erhielt das System die Eigenschaft der Selbstskalierbarkeit. Die y-Achse ist der Prozentsatz dessen, was wir mit Benutzer-IDs tun, wenn sie zu uns kommen. Grün - die Arbeit, die wir ausgeführt haben, hat das Segmentierungsskript gestartet. Gelb - das haben wir nicht gemacht, weil Bereits genau diese Daten segmentiert.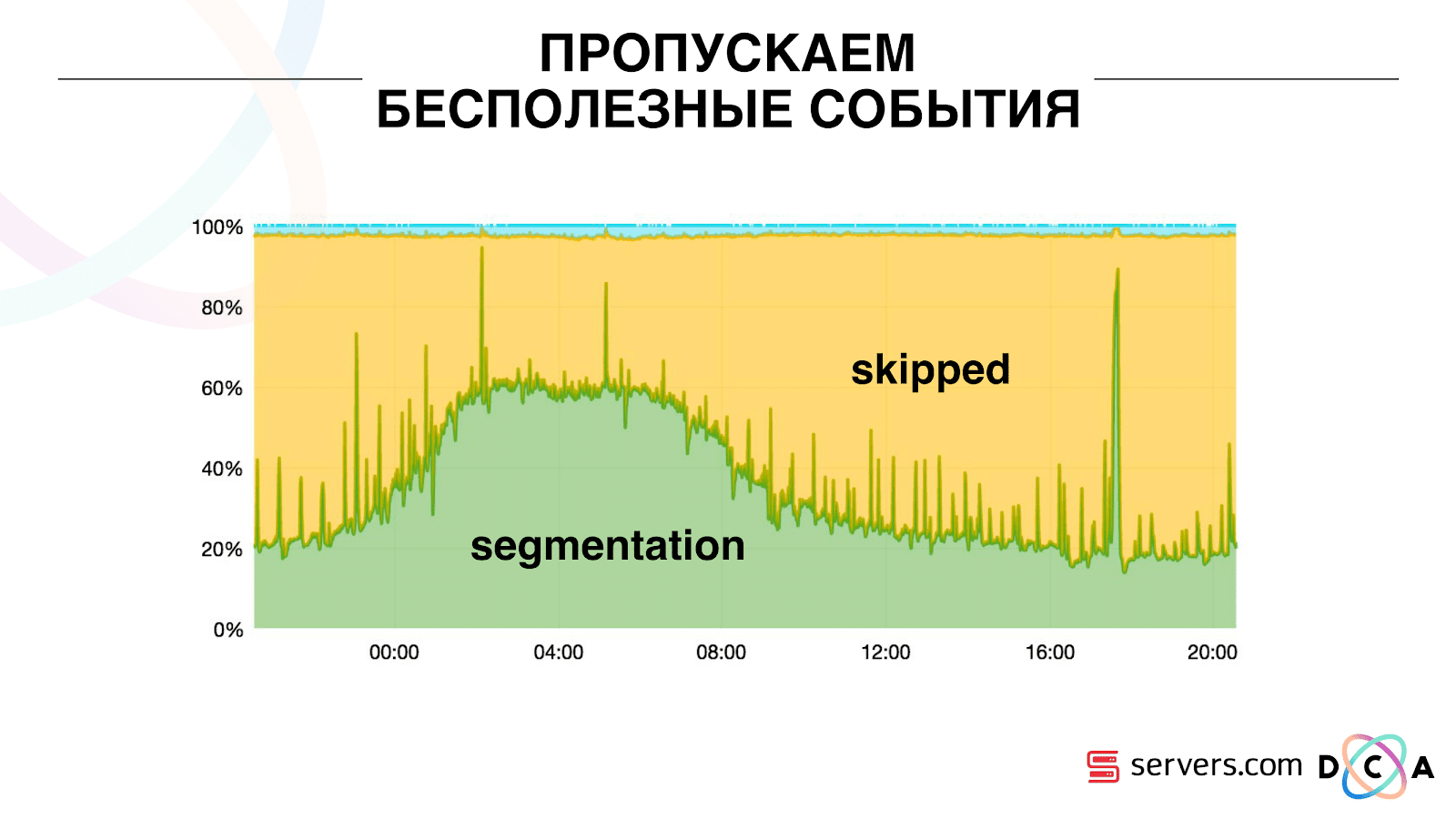 Es ist ersichtlich, dass nachts Ressourcen vorhanden sind, weniger Daten fließen und Sie jedes zweite Ereignis segmentieren können. Ein kleinerer Ressourcentag, und wir segmentieren nur 20% der Ereignisse. Ein Sprung am Ende des Tages - der Partner hat Datendateien hochgeladen, die wir zuvor noch nicht gesehen hatten, und sie mussten „ehrlich“ segmentiert werden.Das System selbst passt sich dem Lastwachstum an. Wenn wir einen sehr großen Partner haben, verarbeiten wir dieselben Daten, jedoch etwas seltener. In diesem Fall verschlechtern sich die Eigenschaften des Systems am Abend, die Segmentierung wird nicht um 2-3 Sekunden, sondern um eine Minute verzögert. Fügen Sie am Morgen die Server hinzu und kehren Sie zu den gewünschten Ergebnissen zurück.So haben wir ca. 5 mal auf den Servern gespart. Jetzt arbeiten wir auf 10 Servern, und so würde es 50-60 dauern.Das kleine blaue Ding oben sind die Bots. Dies ist der schwierigste Teil der Segmentierung. Sie haben eine große Anzahl von Besuchen, sie erzeugen eine sehr große Last auf dem Eisen. Wir sehen jeden Bot auf einem separaten Server. Wir können darauf einen lokalen Cache mit einer schwarzen Liste von Bots sammeln. Einführung eines einfachen Betrugs: Wenn ein Benutzer für eine bestimmte Zeit zu viele Besuche macht, stimmt etwas nicht mit ihm, wir fügen ihn für eine Weile der schwarzen Liste hinzu. Dies ist ein kleiner blauer Streifen, ungefähr 5%. Sie gaben uns weitere 30% Einsparungen bei der CPU.Damit haben wir in jeder Phase das erreicht, was wir für die gesamte Pipeline der Datenverarbeitung sehen. Wir sehen Metriken, wie viel die Nachricht in Kafka war. Abends trübte sich irgendwo etwas, die Bearbeitungszeit erhöhte sich auf eine Minute, dann wurde es freigegeben und wieder normalisiert.
Es ist ersichtlich, dass nachts Ressourcen vorhanden sind, weniger Daten fließen und Sie jedes zweite Ereignis segmentieren können. Ein kleinerer Ressourcentag, und wir segmentieren nur 20% der Ereignisse. Ein Sprung am Ende des Tages - der Partner hat Datendateien hochgeladen, die wir zuvor noch nicht gesehen hatten, und sie mussten „ehrlich“ segmentiert werden.Das System selbst passt sich dem Lastwachstum an. Wenn wir einen sehr großen Partner haben, verarbeiten wir dieselben Daten, jedoch etwas seltener. In diesem Fall verschlechtern sich die Eigenschaften des Systems am Abend, die Segmentierung wird nicht um 2-3 Sekunden, sondern um eine Minute verzögert. Fügen Sie am Morgen die Server hinzu und kehren Sie zu den gewünschten Ergebnissen zurück.So haben wir ca. 5 mal auf den Servern gespart. Jetzt arbeiten wir auf 10 Servern, und so würde es 50-60 dauern.Das kleine blaue Ding oben sind die Bots. Dies ist der schwierigste Teil der Segmentierung. Sie haben eine große Anzahl von Besuchen, sie erzeugen eine sehr große Last auf dem Eisen. Wir sehen jeden Bot auf einem separaten Server. Wir können darauf einen lokalen Cache mit einer schwarzen Liste von Bots sammeln. Einführung eines einfachen Betrugs: Wenn ein Benutzer für eine bestimmte Zeit zu viele Besuche macht, stimmt etwas nicht mit ihm, wir fügen ihn für eine Weile der schwarzen Liste hinzu. Dies ist ein kleiner blauer Streifen, ungefähr 5%. Sie gaben uns weitere 30% Einsparungen bei der CPU.Damit haben wir in jeder Phase das erreicht, was wir für die gesamte Pipeline der Datenverarbeitung sehen. Wir sehen Metriken, wie viel die Nachricht in Kafka war. Abends trübte sich irgendwo etwas, die Bearbeitungszeit erhöhte sich auf eine Minute, dann wurde es freigegeben und wieder normalisiert. Wir können überwachen, wie sich unsere Aktionen mit dem System auf den Durchsatz auswirken. Wir können sehen, wie viel das Skript ausgeführt wird, wo es optimiert werden muss und wie viel gespeichert werden kann. Wir können die Größe der Segmente sehen, die Dynamik der Größe der Segmente, ihre Assoziation und Schnittmenge bewerten. Dies kann für mehr oder weniger gleiche Segmentgrößen erfolgen.
Wir können überwachen, wie sich unsere Aktionen mit dem System auf den Durchsatz auswirken. Wir können sehen, wie viel das Skript ausgeführt wird, wo es optimiert werden muss und wie viel gespeichert werden kann. Wir können die Größe der Segmente sehen, die Dynamik der Größe der Segmente, ihre Assoziation und Schnittmenge bewerten. Dies kann für mehr oder weniger gleiche Segmentgrößen erfolgen.Was möchten Sie verfeinern?
Wir haben einen Hadoop-Cluster mit einigen Computerressourcen. Er ist beschäftigt - Analysten arbeiten tagsüber daran, aber nachts ist er praktisch frei. Im Allgemeinen können wir den Segmentierer als separaten Prozess in unserem Cluster containerisieren und ausführen. Wir möchten Statistiken genauer speichern, um das Volumen der Kreuzung genauer berechnen zu können. Wir brauchen auch eine Optimierung der CPU. Dies wirkt sich direkt auf die Kosten der Entscheidung aus.Zusammenfassend: Kafka ist gut, aber wie bei jeder anderen Technologie müssen Sie verstehen, wie es im Inneren funktioniert und was damit passiert. Beispielsweise funktioniert die Garantie für die Nachrichtenpriorität nur innerhalb der Partition. Wenn Sie eine Nachricht senden, die an verschiedene Partitionen gesendet wird, ist nicht klar, in welcher Reihenfolge diese verarbeitet werden.Reale Daten sind sehr wichtig. Wenn wir nicht auf echten Datenverkehr getestet hätten, hätten wir höchstwahrscheinlich keine Probleme mit Bots und Benutzersitzungen gesehen. Würde etwas im luftleeren Raum entwickeln, rennen und sich hinlegen. Es ist wichtig zu überwachen, was Sie für notwendig halten, um zu überwachen, und nicht zu überwachen, was Sie nicht denken.Minute der Werbung. Wenn Ihnen dieser Bericht von der SmartData-Konferenz gefallen hat, beachten Sie bitte, dass SmartData 2018 am 15. Oktober in St. Petersburg stattfindet, einer Konferenz für diejenigen, die in die Welt des maschinellen Lernens, der Analyse und der Datenverarbeitung eintauchen. Das Programm wird viele interessante Dinge enthalten, die Seite hat bereits ihre ersten Redner und Berichte.