In einem
früheren Artikel habe ich versprochen, einige Details, die ich während der Untersuchung ausgelassen habe, detaillierter zu enthüllen [Google Mail hängt in Chrome unter Windows - ca. Per.], Einschließlich Seitentabellen, Sperren, WMI und des vmmap-Fehlers. Jetzt fülle ich diese Lücken zusammen mit aktualisierten Codebeispielen aus. Aber skizzieren Sie zunächst kurz die Essenz.
Der Punkt war, dass ein Prozess, der
Control Flow Guard (CFG) unterstützt, ausführbaren Speicher zuweist und gleichzeitig CFG-Speicher zuweist, den Windows niemals freigibt. Wenn Sie weiterhin ausführbaren Speicher
an verschiedenen Adressen zuweisen und freigeben, sammelt der Prozess daher eine beliebige Menge an CFG-Speicher. Der Chrome-Browser führt dies aus, was zu einem nahezu unbegrenzten Speicherverlust führt und auf einigen Computern einfriert.
Es ist zu beachten, dass Einfrierungen schwer zu vermeiden sind, wenn VirtualAlloc mehr als eine Million Mal langsamer als gewöhnlich ausgeführt wird.
Zusätzlich zu CFG gibt es einen weiteren verschwendeten Speicher, obwohl es nicht so viel ist, wie vmmap behauptet.
CFG und Seiten
Sowohl der Programmspeicher als auch der CFG-Speicher werden letztendlich mit 4-Kilobyte-Seiten belegt (dazu später mehr). Da 4 KB CFG-Speicher 256 KB Programmspeicher beschreiben können (dazu später mehr), bedeutet dies, dass Sie eine 4 KB CFG-Seite erhalten, wenn Sie einen 256 KB großen Speicherblock auswählen, der auf 256 KB ausgerichtet ist. Wenn Sie einen ausführbaren 4-KB-Block zuweisen, erhalten Sie weiterhin eine 4-KB-CFG-Seite, die jedoch größtenteils nicht verwendet wird.
Alles ist komplizierter, wenn der ausführbare Speicher freigegeben wird. Wenn Sie die VirtualFree-Funktion für einen Block ausführbaren Speichers verwenden, der kein Vielfaches von 256 KB ist oder nicht auf 256 KB ausgerichtet ist, sollte das Betriebssystem eine Analyse durchführen und sicherstellen, dass ein anderer ausführbarer Speicher keine CFG-Seite verwendet. Die Autoren von CFG haben beschlossen, sich nicht darum zu kümmern - und den zugewiesenen CFG-Speicher einfach für immer zu verlassen. Es ist sehr unglücklich. Dies bedeutet, dass wenn mein Testprogramm 1 Gigabyte ausgerichteten ausführbaren Speicher zuweist und dann freigibt, 16 MB CFG-Speicher übrig bleiben.
In der Praxis stellt sich heraus, dass, wenn die Chrome JavaScript-Engine 128 MB ausgerichteten ausführbaren Speicher zuweist und dann freigibt (nicht alles wurde verwendet, aber der gesamte Bereich zugewiesen und sofort freigegeben wurde), bis zu 2 MB CFG-Speicher zugewiesen bleiben, obwohl es trivial ist, ihn vollständig freizugeben . Da Chrome wiederholt Speicher an zufälligen Adressen zuweist und freigibt, führt dies zu dem oben beschriebenen Problem.
Zusätzlicher Speicherverlust
In jedem modernen Betriebssystem erhält jeder Prozess seinen eigenen Adressraum für den virtuellen Speicher, sodass das Betriebssystem Prozesse isoliert und den Speicher schützt. Dies erfolgt mithilfe
einer Speicherverwaltungseinheit (MMU) und
Seitentabellen . Der Speicher ist in 4 KB Seiten unterteilt. Dies ist die Mindestmenge an Speicher, die Ihnen das Betriebssystem zur Verfügung stellt. Jede Seite wird durch einen 8-Byte-Datensatz in der Seitentabelle angezeigt, und die Datensätze selbst werden auf 4-KB-Seiten gespeichert. Jede von ihnen verweist auf maximal 512 verschiedene Speicherseiten, daher benötigen wir eine Hierarchie von Seitentabellen. Für einen 48-Bit-Adressraum in einem 64-Bit-Betriebssystem lautet das System wie folgt:
- Eine Level 1-Tabelle umfasst 256 TB (48 Bit) und zeigt auf 512 verschiedene Tabellen der Level 2-Seite
- Jede Tabelle der Ebene 2 umfasst 512 GB und verweist auf 512 Tabellen der Ebene 3
- Jede Tabelle der Ebene 3 umfasst 1 GB und zeigt auf 512 Tabellen der Ebene 4
- Jede Tabelle der Ebene 4 umfasst 2 MB und verweist auf 512 physische Seiten
Die MMU indiziert die Tabelle der 1. Ebene in den ersten 9 (von 48) Bits der Adresse, die Tabellen der 2. Ebene in den nächsten 9 Bits und die verbleibenden Ebenen erhalten 9 Bits, dh nur 36 Bits. Die verbleibenden 12 Bits werden verwendet, um 4 Kilobyte-Seiten aus einer Tabelle der 4. Ebene zu indizieren. Gut, gut.
Wenn Sie sofort alle Ebenen der Tabellen ausfüllen, benötigen Sie mehr als 512 GB RAM, damit diese nach Bedarf ausgefüllt werden. Dies bedeutet, dass das Betriebssystem beim Zuweisen einer Speicherseite einige Seitentabellen auswählt - von null bis drei, je nachdem, ob sich die zugewiesenen Adressen in einem zuvor nicht verwendeten Bereich von 2 MB, einem zuvor nicht verwendeten Bereich von 1 GB oder einem zuvor nicht verwendeten Bereich von 512 GB befinden (Tabelle mit Seiten der Ebene 1) fällt immer auf).
Kurz gesagt, das Zuweisen zu zufälligen Adressen ist viel teurer als das Zuweisen zu Adressen in der Nähe, da im ersten Fall Seitentabellen nicht gemeinsam genutzt werden können. CFG-Lecks sind selten. Als
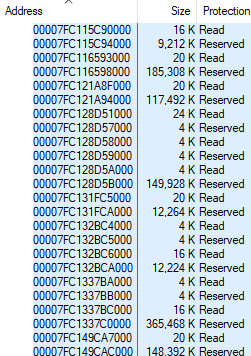
vmmap 412.480 KB verwendeter Seitentabellen in Chrome
anzeigte , ging ich davon aus, dass die Zahlen korrekt waren. Hier ist ein Screenshot von vmmap mit dem Speicherlayout chrome.exe aus dem vorherigen Artikel, jedoch mit der Zeile Seitentabelle:
Aber etwas schien nicht zu stimmen. Ich habe beschlossen, meinem
VirtualScan- Tool einen Seitentabellensimulator hinzuzufügen. Es wird berechnet, wie viele Seiten mit Seitentabellen während des Scanvorgangs für den gesamten zugewiesenen Speicher benötigt werden. Sie müssen nur den zugewiesenen Speicher scannen und dem Zähler jeweils ein Vielfaches von 2 MB, 1 GB oder 512 GB hinzufügen.
Es wurde schnell festgestellt, dass die Simulatorergebnisse vmmap für normale Prozesse entsprechen, jedoch nicht für Prozesse mit einer großen Menge an CFG-Speicher. Die Differenz entspricht ungefähr dem zugewiesenen CFG-Speicher. Für den obigen Prozess, bei dem vmmap über 402,8 MB (412.480 KB) Seitentabellen spricht, zeigt mein Tool 67,7 MB an.
Scan-Zeit, Festgeschrieben, Seitentabellen, Festgeschriebene Blöcke
Gesamt: 41,763 s, 1457,7 MiB, 67,7 MiB, 32112, 98 Codeblöcke
CFG: 41,759 s, 353,3 MiB, 59,2 MiB, 24866
Ich habe den vmmap-Fehler durch Ausführen von
VAllocStress sichergestellt , wodurch Windows in den Standardeinstellungen 2 Gigabyte CFG-Speicher
zuweist . vmmap gab an, 2 Gigabyte Seitentabellen zugewiesen zu haben:
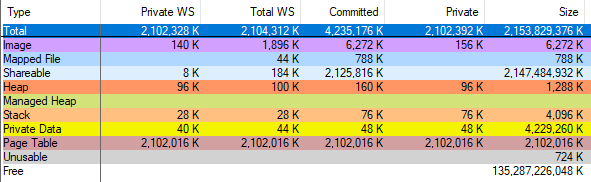
Und als ich den Vorgang über den Task-Manager abgeschlossen habe, hat vmmap gezeigt, dass die Menge des zugewiesenen Speichers nur um 2 Gigabyte abgenommen hat. Vmmap ist also falsch, meine Berechnungen mit Seitentabellen sind korrekt, und nach einer fruchtbaren
Diskussion auf Twitter habe ich einen Bericht über den vmmap-Fehler gesendet, der behoben werden sollte. Der CFG-Speicher belegt immer noch viele Seitentabelleneinträge (59,2 MB im obigen Beispiel), aber nicht so viel, wie vmmap sagt, und nach dem Korrigieren wird überhaupt nichts verbraucht.
Was ist CFG und CFG?
Ich möchte ein wenig zurücktreten und genauer erklären, was CFG ist.
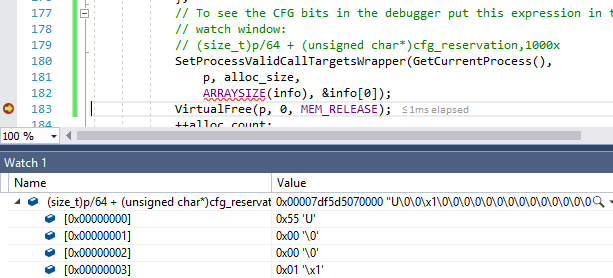
CFG steht für Control Flow Guard. Dies ist eine Methode zum Schutz vor Exploits durch Umschreiben von Funktionszeigern. Wenn CFG aktiviert ist, überprüfen der Compiler und das Betriebssystem gemeinsam die Gültigkeit des Verzweigungsziels. Zunächst wird das entsprechende CFG-Steuerbyte aus dem für 2 TB reservierten CFG-Bereich geladen. Der 64-Bit-Prozess in Windows verwaltet den 128-TB-Adressraum. Wenn Sie also die Adresse durch 64 teilen, können Sie das entsprechende CFG-Byte für dieses Objekt finden.
uint8_t cfg_byte = cfg_base[size_t(target_addr) / 64];Wir haben jetzt ein Byte, das beschreiben soll, welche Adressen im 64-Byte-Bereich gültige Verzweigungsziele sind. Zu diesem Zweck behandelt das CFG das Byte als vier Zwei-Bit-Werte, von denen jeder einem 16-Byte-Bereich entspricht. Diese Zwei-Bit-Zahl (deren Wert zwischen null und drei liegt) wird
wie folgt interpretiert :
- 0 - Alle Ziele in diesem 16-Byte-Block sind ungültige Ziele indirekter Zweige
- 1 - Die Startadresse in diesem 16-Byte-Block ist das gültige Ziel der indirekten Verzweigung
- 2 - verbunden mit "unterdrückten" CFG-Anrufen ; Adresse ist möglicherweise ungültig
- 3 - Nicht ausgerichtete Adressen in diesem 16-Byte-Block sind gültige Ziele einer indirekten Verzweigung, jedoch ist eine 16-Byte-ausgerichtete Adresse möglicherweise ungültig
Wenn das Ziel des indirekten Zweigs ungültig ist, wird der Prozess beendet und der Exploit verhindert. Hurra!
Daraus können wir schließen, dass für maximale Sicherheit die indirekten Ziele der Verzweigung auf 16 Bytes ausgerichtet sein sollten, und wir können verstehen, warum der CFG-Speicher für den Prozess ungefähr 1/64 des Programmspeichers beträgt.
Tatsächlich lädt CFG jeweils 32 Bit, dies sind jedoch Implementierungsdetails. Viele Quellen beschreiben den CFG-Speicher als 8-Byte-Einzelbit und nicht als 16-Byte-Doppelbit. Meine Erklärung ist besser.
Deshalb ist alles schlecht
Google Mail hängt aus zwei Gründen. Erstens ist das Scannen des CFG-Speichers unter Windows 10 16299 oder früher
schmerzhaft langsam. Ich habe gesehen, wie das Scannen des Adressraums eines Prozesses 40 Sekunden oder länger dauert, und buchstäblich 99,99% dieser Zeit wird der reservierte CFG-Speicher gescannt, obwohl er nur etwa 75% der festen Speicherblöcke ausmacht. Ich weiß nicht, warum das Scannen so langsam war, aber sie haben es in Windows 10 17134 behoben. Daher ist es nicht sinnvoll, das Problem genauer zu untersuchen.
Langsames Scannen verursachte eine Verlangsamung, da Google Mail eine CFG-Redundanz wünschte und WMI die Sperre für die Dauer des Scans hielt. Die Speicherreservierungssperre wurde jedoch während des gesamten Scans nicht gehalten. In meinem Beispiel gibt es ungefähr 49.000 Blöcke im CFG-Bereich, und die
NtQueryVirtualMemory- Funktion, die die Sperre empfängt und
aufhebt , wurde für jeden von ihnen einmal aufgerufen. Daher wurde die Sperre ~ 49.000 Mal erhalten und freigegeben und jedes Mal für weniger als 1 Millisekunde gehalten.
Obwohl die Sperre 49.000 Mal freigegeben wurde, konnte der Chrome-Prozess sie aus irgendeinem Grund nicht erhalten. Das ist nicht fair!
Das ist die Essenz des Problems. Wie ich letztes Mal schrieb:
Dies liegt daran, dass Windows-Sperren von Natur aus unfair sind. Wenn der Thread die Sperre aufhebt und sie dann sofort erneut anfordert, kann er sie für immer erhalten.
Faires Sperren bedeutet, dass zwei konkurrierende Threads es nacheinander erhalten. Dies bedeutet jedoch viele teure Kontextwechsel, sodass das Schloss lange Zeit nicht verwendet wird.

Unfaire Schlösser sind billiger und lassen Threads nicht in der Schlange stehen. Sie erfassen nur das Schloss, wie in
Joe Duffys Artikel erwähnt . Er schreibt auch:
Die Einführung unfairer Schlösser kann zweifellos zu Hunger führen. Statistisch gesehen ist die Zeit in parallelen Systemen jedoch tendenziell so variabel, dass jeder Thread aus probabilistischer Sicht letztendlich eine Umdrehung zur Ausführung erhält.
Wie kann ich die Aussage von Joe aus dem Jahr 2006 über die Seltenheit des Hungers mit meiner Erfahrung zu einem 100% wiederholbaren und lang anhaltenden Problem in Beziehung setzen? Ich denke, der Hauptgrund ist das, was 2006 passiert ist. Intel
hat Core Duo veröffentlicht , und Multi-Core-Computer sind allgegenwärtig.
Immerhin stellt sich heraus, dass dieses Hungerproblem nur bei einem Multi-Core-System auftritt! In einem solchen System hebt der WMI-Thread die Sperre auf, signalisiert dem Chrome-Thread, dass er aufwacht, und fährt fort. Da der WMI-Stream bereits ausgeführt wird, hat er ein "Handicap" vor dem Chrome-Stream, sodass er
NtQueryVirtualMemory problemlos erneut aufrufen und die Sperre erneut erhalten kann, bevor Chrome die Möglichkeit dazu hat.
In einem Single-Core-System kann natürlich immer nur ein Thread gleichzeitig arbeiten. In der Regel erhöht Windows die Priorität eines neuen Threads. Wenn Sie die Priorität erhöhen, ist der neue Chrome-Thread bereit, wenn die Sperre aufgehoben wird, und wird
dem WMI-Thread sofort
voraus . Dies gibt dem Chrome-Thread viel Zeit, um aufzuwachen und eine Sperre zu erhalten, und es kommt nie zu Hunger.
Verstehst du In einem Multi-Core-System wirkt sich eine Prioritätserhöhung in den meisten Fällen nicht auf den WMI-Stream aus, da er auf einem anderen Kernel ausgeführt wird!
Dies bedeutet, dass ein System mit zusätzlichen Kernen
langsamer reagieren kann als ein System mit derselben Arbeitslast und weniger Kernen. Eine andere Schlussfolgerung ist merkwürdig: Wenn mein Computer stark ausgelastet wäre - Threads mit der entsprechenden Priorität, die auf allen Prozessorkernen arbeiten -, könnten Hänge vermieden werden (versuchen Sie nicht, dies zu Hause zu wiederholen).
Ungerechte Schlösser erhöhen somit die Produktivität, können jedoch zu Hunger führen. Ich vermute, dass die Lösung das sein kann, was ich "manchmal faire" Schlösser nenne. Sagen wir, 99% der Zeit werden sie unfair sein, aber in 1% geben Sie die Sperre für einen anderen Prozess. Dies wird die Vorteile der Produktivität mit mehr bewahren und das Problem des Hungers vermeiden. Bisher waren Sperren in Windows fair verteilt, und Sie können wahrscheinlich teilweise darauf zurückkommen, um das perfekte Gleichgewicht zu finden. Haftungsausschluss: Ich bin kein Experte für Sperren oder ein OS-Ingenieur, aber ich bin daran interessiert, Gedanken darüber zu hören, und zumindest bin ich
nicht der erste, der so etwas anbietet .
Linus Torvalds hat kürzlich die Bedeutung fairer Schlösser erkannt:
hier und
hier . Vielleicht ist es auch Zeit für eine Änderung unter Windows.
Zusammenfassend : Das Sperren für einige Sekunden ist nicht gut, es begrenzt die Parallelität. Auf Multi-Core-Systemen mit unfairen Sperren verhält sich das Entfernen und sofortige erneute Empfangen der Sperre
genau so - andere Threads können nicht funktionieren.
Fast ein Misserfolg mit ETW
Bei all diesen Nachforschungen habe ich mich auf die ETW-Ablaufverfolgung verlassen, daher hatte ich ein wenig Angst, als sich zu Beginn der Untersuchung herausstellte, dass Windows Performance Analyzer (WPA) keine Chrome-Zeichen laden konnte. Ich bin mir sicher, dass letzte Woche buchstäblich alles funktioniert hat. Was ist passiert ...
Es kam vor, dass Chrome M68 herauskam und mit lld-link anstelle des VC ++ - Linkers verknüpft wurde. Wenn Sie
dumpbin ausführen und die Debugging-Informationen
anzeigen , sehen Sie:
C:\b\c\b\win64_clang\src\out\Release_x64\./initialexe/chrome.exe.pdbNun, wahrscheinlich mag WPA diese Schrägstriche nicht. Aber es macht immer noch keinen Sinn, weil ich den Linker in lld-link geändert habe und ich erinnere mich, dass ich WPA zuvor getestet habe, also was ist passiert ...
Es stellte sich heraus, dass der Grund in der neuen WPA-Version 17134 lag. Ich habe das lld-Link-Layout getestet - und es hat in WPA 16229 gut funktioniert. Was für ein Zufall! Der neue Linker und der neue WPA waren nicht kompatibel.
Ich habe die alte Version von WPA installiert, um die Untersuchung fortzusetzen (xcopy von einem Computer mit der alten Version) und einen
lld-link-Fehler gemeldet, den die Entwickler schnell behoben haben. Jetzt können Sie zu WPA 17134 zurückkehren, wenn der M69 mit einem festen Linker zusammengebaut ist.
Wmi
Der WMI-Freeze-Trigger ist ein
Windows Management Instrumentation-Snap-In , und ich bin nicht gut darin. Ich habe festgestellt, dass
2014 oder früher jemand auf das Problem einer signifikanten CPU-Auslastung in
WmiPrvSE.exe in
perfproc! GetProcessVaData gestoßen ist , aber er hat nicht genügend Informationen
bereitgestellt , um die Ursachen des Fehlers zu verstehen. Irgendwann habe ich einen Fehler gemacht und versucht herauszufinden, welche verrückte WMI-Anfrage Google Mail für ein paar Sekunden hängen lassen könnte. Ich habe
einige Experten mit der Untersuchung verbunden und viel Zeit damit verbracht, diese magische Abfrage zu finden. Ich habe
Microsoft-Windows-WMI- Aktivitätsaktivitäten in ETW-Traces aufgezeichnet, mit PowerShell experimentiert, um alle Win32_Perf-Abfragen zu finden, und mich auf ein paar weitere Umwege verlaufen, die zu langweilig sind, um sie zu diskutieren. Am Ende stellte ich fest, dass ein Google Mail-Hang diesen Zähler
Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly verursachte , der durch eine einzeilige PowerShell ausgelöst wurde:
measure-command {Get-WmiObject -Query “SELECT * FROM Win32_PerfFormattedData_PerfProc_ProcessAddressSpace_Costly”}
Ich wurde dann
noch verwirrter wegen des Namens des Zählers ("Liebes"? Wirklich?) Und weil dieser Zähler aufgrund von Faktoren erscheint und verschwindet, die ich nicht verstehe.
Aber die Details von WMI spielen keine Rolle. WMI hat nichts falsch gemacht - nicht wirklich - es hat nur den Speicher gescannt. Das Schreiben eines eigenen Scan-Codes erwies sich als viel nützlicher bei der Untersuchung des Problems.
Ärger für Microsoft
Chrome hat einen Patch veröffentlicht, der Rest ist für Microsoft.
Beschleunigen Sie das Scannen von CFG-Regionen - OK, fertig- Geben Sie CFG-Speicher frei, wenn ausführbarer Speicher freigegeben wird - zumindest bei einer Ausrichtung von 256 KB ist dies einfach
- Stellen Sie sich ein Flag vor, mit dem ausführbarer Speicher ohne CFG-Speicher zugewiesen werden kann, oder verwenden Sie zu diesem Zweck PAGE_TARGETS_INVALID. Beachten Sie, dass im Handbuch Windows Internals Part 1 7th Edition angegeben ist , dass Sie [CFG] -Seiten mit mindestens einem gesetzten Bit {1, X} auswählen sollten. Wenn Windows 10 dies implementiert, wird das Flag PAGE_TARGETS_INVALID (das derzeit von der Engine verwendet wird) verwendet v8 ) vermeidet die Speicherzuweisung
- Korrektur der Berechnung von Seitentabellen in vmmap für Prozesse mit einer großen Anzahl von CFG-Zuordnungen
Code-Updates
Ich habe die
Codebeispiele aktualisiert, insbesondere VAllocStress. Es sind 20 Zeilen enthalten, um zu demonstrieren, wie eine CFG-Reservierung für einen Prozess gefunden wird. Ich habe auch
Testcode hinzugefügt, der
SetProcessValidCallTargets verwendet , um den Wert der CFG-Bits zu überprüfen und die Tricks zu demonstrieren, die zum erfolgreichen Aufrufen erforderlich sind (Hinweis: Das Aufrufen über GetProcAddress verstößt wahrscheinlich gegen CFG!)