Hallo Kollegen.
Wir haben gerade ein interessantes Buch von Brendan Burns übersetzt, in dem es um Entwurfsmuster für verteilte Systeme geht

Darüber hinaus ist die Übersetzung des Buches "
Mastering Kubernetes " (2. Auflage) bereits in vollem Gange und das Buch des Autors über Docker steht kurz vor der Veröffentlichung, das definitiv einen separaten Beitrag haben wird.
Wir glauben, dass die nächste Station auf diesem Weg ein Buch über Prometheus ist. Deshalb machen wir Sie heute auf eine Übersetzung eines kurzen Artikels von Björn Wenzel über die enge Interaktion von Prometheus und Kubernetes aufmerksam. Bitte denken Sie daran, an der Umfrage teilzunehmen.
Die Überwachung des Kubernetes-Clusters ist ein sehr wichtiges Geschäft. Der Cluster enthält eine Menge Informationen, mit denen Sie Fragen aus der Kategorie beantworten können: Wie viel Speicher und Speicherplatz sind jetzt verfügbar, wie aktiv wird die CPU verwendet? Welcher Container verbraucht wie viel Ressourcen? Dies umfasst auch Fragen zum Status von Anwendungen, die im Cluster ausgeführt werden.
Eines der Werkzeuge für solche Arbeiten heißt Prometheus. Es wird von der Cloud Native Computing Foundation unterstützt, ursprünglich wurde Prometheus von SoundCloud entwickelt. Konzeptionell ist Prometheus sehr einfach:
Architektur
Der Prometheus-Server kann beispielsweise in einem Kubernetes-Cluster arbeiten und die Konfiguration über eine spezielle Datei erhalten. Diese Konfiguration enthält insbesondere Informationen darüber, wo sich das Terminal befindet, von dem nach dem angegebenen Intervall Daten erfasst werden sollen. Anschließend fordert der Prometheus-Server Metriken von diesen Terminals in einem speziellen Format an (sie sind normalerweise unter
/metrics verfügbar) und speichert sie in einer Zeitreihendatenbank. Das Folgende ist ein kurzes Beispiel: Eine kleine Konfigurationsdatei, die Metriken von einem
node_exporter Modul
node_exporter , das als Agent auf jedem Knoten bereitgestellt wird:
scrape_configs: - job_name: "node_exporter" scrape_interval: "15s" target_groups: - targets: ['<ip>:9100']
Zuerst definieren wir den
job_name , später kann dieser Name verwendet werden, um Metriken in Prometheus anzufordern, dann das
scrape_interval und eine Gruppe von Servern, auf denen
node_exporter . Jetzt fragt Prometheus alle 15 Sekunden den Server nach dem
path /metrics zu den aktuellen Metriken. Es sieht ungefähr so aus:
Zuerst wird der Name der Metrik angegeben, dann die Signatur (Informationen in geschweiften Klammern) und schließlich der Wert der Metrik. Am interessantesten ist die Suchfunktion für diese Metriken. Prometheus hat zu diesem Zweck eine sehr mächtige
Abfragesprache .
Die oben bereits beschriebene Hauptidee von Prometheus lautet: Prometheus fragt in einem bestimmten Intervall den Port nach Metriken ab und speichert diese in einer Zeitreihendatenbank. Wenn Prometheus die Metriken selbst nicht entfernen kann, gibt es eine andere Funktion namens Pushgateway. Das Pushgateway-Gateway akzeptiert Metriken, die von externen Jobs gesendet wurden, und Prometheus sammelt in einem bestimmten Intervall Informationen von diesem Gateway.
Eine weitere optionale Komponente der Prometheus-Architektur ist der
alertmanager . Mit der
alertmanager Komponente können
alertmanager Grenzwerte festlegen und bei Überschreitung Benachrichtigungen per E-Mail, Slack oder Opsgenie senden.
Darüber hinaus enthält der Prometheus-Server viele
integrierte Funktionen . Beispielsweise kann er ec2-Instanzen über die Amazon-API anfordern oder Pods, Knoten und Dienste von Kubernetes anfordern. Es hat auch viele
Exporteure , zum Beispiel den oben genannten
node_exporter . Solche Exporteure können beispielsweise auf dem Knoten arbeiten, auf dem eine Anwendung wie MySQL installiert ist, und in einem bestimmten Intervall die Anwendung nach Metriken abfragen und diese auf dem Terminal / den Metriken bereitstellen, und der Prometheus-Server kann diese Metriken von dort erfassen.
Darüber hinaus ist es nicht schwierig, einen eigenen Exporter zu schreiben - beispielsweise für eine Anwendung, die Metriken wie JVM-Informationen bereitstellt. Es gibt zum Beispiel eine solche
Bibliothek, die von Prometheus entwickelt wurde, um solche Metriken zu exportieren. Diese Bibliothek kann in Verbindung mit Spring verwendet werden und ermöglicht es Ihnen, Ihre eigenen Metriken zu definieren. Hier ist ein Beispiel von der Seite
client_java :
@Controller public class MyController { @RequestMapping("/") @PrometheusTimeMethod(name = "my_controller_path_duration_seconds", help = "Some helpful info here") public Object handleMain() {
Dies ist eine Metrik, die die Dauer der Methode beschreibt. Andere Metriken können jetzt über das Terminal bereitgestellt oder über das Pushgateway übertragen werden.
Verwendung in Kubernetes Cluster
Wie bereits erwähnt, gibt es für die Verwendung von Prometheus im Kubernetes-Cluster integrierte Funktionen zum Entfernen von Informationen aus dem Herd, dem Knoten und dem Dienst. Am interessantesten ist, dass Kubernetes speziell für die Zusammenarbeit mit Prometheus entwickelt wurde. Beispielsweise bieten
kubelet und
kube-apiserver in Prometheus
kube-apiserver Metriken, sodass die Überwachung sehr einfach ist.
In diesem Beispiel verwende ich zunächst die offizielle Steuertabelle.
Für mich selbst habe ich die Konfiguration des Standard-Helmdiagramms ein wenig geändert. Erstens musste ich
rbac in der Prometheus-Installation aktivieren, sonst konnte Prometheus keine Informationen von
kube-apiserver sammeln. Aus diesem Grund habe ich meine eigene Datei values.yaml geschrieben, in der beschrieben wird, wie das Steuerdiagramm angezeigt werden soll.
Ich habe die einfachsten Änderungen vorgenommen:
alertmanager.enabled: false , alertmanager.enabled: false die Bereitstellung von alertmanager im Cluster wurde abgebrochen (ich wollte alertmanager nicht verwenden, ich denke, es ist einfacher, Warnungen mit Grafana zu konfigurieren).kubeStateMetrics.enabled: false Ich denke, diese Metriken geben nur einige Informationen über die maximale Anzahl von Herden zurück. Wenn Sie das System zum ersten Mal starten, sind diese Informationen für mich nicht wichtigserver.persistentVolume.enabled: false bis standardmäßig ein persistentes Volume konfiguriert ist- Ich habe die Konfiguration der Informationssammlung in Prometheus geändert, wie es in der Pull-Anfrage auf Github geschehen ist . Tatsache ist, dass in Kubernetes v1.7 cAdvisor-Metriken an einem anderen Port funktionieren.
Danach können Sie Prometheus mit dem Helm starten:
helm install stable/prometheus --name prometheus-monitoring -f prometheus-values.yamlAlso installieren wir den Prometheus-Server und installieren ihn auf jedem Knoten unter node_exporter. Jetzt können Sie die Prometheus-Web-GUI aufrufen und einige Informationen anzeigen:
kubectl port-forward <prometheus-server-pod> 9090Der folgende Screenshot zeigt, zu welchen Zwecken Prometheus Informationen sammelt (Status / Ziele) und wann die Informationen im letzten Mal mehrmals aufgenommen wurden:
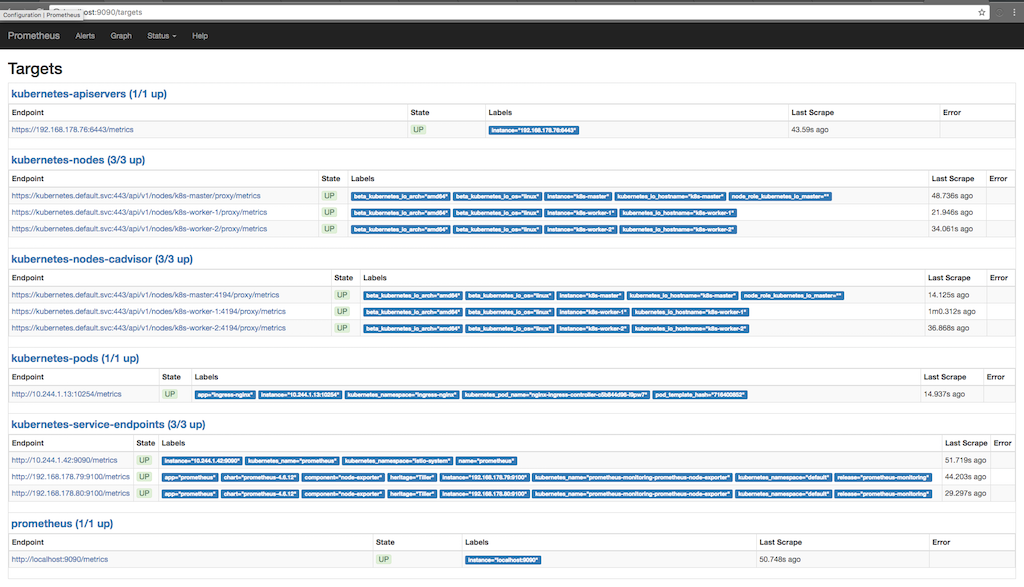
Hier können Sie sehen, wie Prometheus Metriken von Apiserver, Nodes, einem Cadvisor, der auf Knoten und Kubernetes-Service-Endpunkten ausgeführt wird, anfordert. Sie können die Metriken im Detail anzeigen, indem Sie zu Graph gehen und eine Abfrage schreiben, um die Informationen anzuzeigen, an denen wir interessiert sind:

Hier sehen wir zum Beispiel freien Speicherplatz am Einhängepunkt „/“. Am unteren Rand des Diagramms werden Signaturen hinzugefügt, die von Prometheus hinzugefügt wurden oder bereits bei node_exporter verfügbar sind. Wir verwenden diese Signaturen, um nur den Einhängepunkt "/" anzufordern.
Benutzerdefinierte Metriken mit Anmerkungen
Wie bereits im ersten Screenshot gezeigt, in dem die Ziele, für die Prometheus Metriken anfordert, abgeleitet werden, gibt es auch eine Metrik für den im Cluster arbeitenden Herd. Eine der schönen Eigenschaften von Prometheus ist die Fähigkeit, Informationen von ganzen Herden zu erhalten. Wenn der Container im Kamin Prometheus-Metriken bereitstellt, können wir diese Metriken mithilfe von Prometheus automatisch erfassen. Das einzige, worauf wir achten müssen, ist, die Installation mit zwei Anmerkungen zu versehen. in meinem Fall macht
nginx-ingress-controller dies sofort:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx annotations: prometheus.io/port: '10254' prometheus.io/scrape: 'true' ...
Hier sehen wir, dass die Bereitstellungsvorlage zwei Prometheus-Anmerkungen enthält. Der erste beschreibt den Port, über den Prometheus Metriken anfordern soll, und der zweite aktiviert die Datenerfassungsfunktion. Jetzt fordert Prometheus mit Anmerkungen versehene
Kubernetes Api-Server Pods zum Sammeln von Informationen an und versucht, Informationen vom Terminal / den Metriken zu sammeln.
Föderierte Arbeit
Wir haben ein Projekt, in dem Prometheus in einem Verbundmodus verwendet wird. Die Idee ist folgende: Wir sammeln nur die Informationen, auf die nur innerhalb des Clusters zugegriffen werden kann (oder es ist einfacher, diese Informationen innerhalb des Clusters zu sammeln), aktivieren den Verbundmodus und erhalten diese Informationen mit dem zweiten Prometheus, der außerhalb des Clusters installiert ist. Somit ist es möglich, Informationen von mehreren Kubernetes-Clustern gleichzeitig zu sammeln und auch andere Komponenten zu erfassen, auf die innerhalb dieses Clusters nicht zugegriffen werden kann oder die nicht mit diesem Cluster zusammenhängen. Außerdem ist es dann nicht erforderlich, die gesammelten Daten für längere Zeit im Cluster zu speichern. Wenn mit dem Cluster etwas schief geht, können wir einige Informationen, z. B. node_exporter, von außerhalb des Clusters sammeln.