Hallo Habr! Heute möchte ich darüber sprechen, wie tiefes Lernen uns hilft, Kunst besser zu verstehen. Der Artikel ist entsprechend den von uns gelösten Aufgaben in Teile unterteilt:
- Suchen Sie nach einem Bild in der Datenbank anhand eines von einem Mobiltelefon aufgenommenen Fotos.
- Bestimmung des Stils und des Genres eines Bildes, das sich nicht in der Datenbank befindet.
All dies sollte Teil des Arthive-Datenbankdienstes und seiner mobilen Anwendungen werden.
Die Aufgabe bei der Identifizierung der Bilder bestand darin, das entsprechende Bild aus dem Bild der mobilen Anwendung in der Datenbank zu finden, wobei weniger als eine Sekunde dafür aufgewendet wurde. Die Verarbeitung vollständig auf dem mobilen Gerät wurde in der Phase vor der Entwurfsstudie ausgeschlossen. Darüber hinaus stellte sich heraus, dass es unmöglich ist , die Trennung des Bildes vom Hintergrund unter realen Aufnahmebedingungen auf einem mobilen Gerät garantiert durchzuführen. Aus diesem Grund haben wir beschlossen, dass unser Service das gesamte Foto vom Mobiltelefon als Eingabe akzeptiert, mit allen Verzerrungen, Rauschen und möglichen teilweisen Überlappungen.

Werden wir Dasha helfen, diese Bilder in einer Datenbank mit mehr als 200.000 Bildern zu finden?
Die Arthive Art Base umfasst fast 250.000 Bilder sowie verschiedene Metadaten. Die Basis wird ständig aktualisiert - von zehn bis Hunderten von Bildern pro Tag. Selbst mit einer begrenzten Auflösung (nicht mehr als 1400 Pixel auf den meisten Seiten) werden Bilder mit mehr als 80 Gigabyte ausgepumpt. Leider ist die Datenbank „schmutzig“: Es gibt defekte oder zu kleine Dateien, nicht ausgerichtete und unverarbeitete Bilder, doppelte Bilder. Insgesamt sind dies jedoch gute Daten.
Vergleich von Gemälden
Mal sehen, wie die Bilder in der Datenbank aussehen:
Grundsätzlich werden die Bilder in der Datenbank ausgerichtet, an den Rändern der Leinwand zugeschnitten, die Farben bleiben erhalten.
Und so könnten die Anfragen von Mobilgeräten aussehen:

Farben sind fast immer verzerrt - komplexe Beleuchtung wird gefunden, Blendung ist vorhanden, sogar Reflexionen anderer Gemälde im Glas werden gefunden. Die Bilder selbst sind perspektivisch verzerrt, können teilweise beschnitten werden oder im Gegenteil weniger als die Hälfte des Bildes einnehmen, können teilweise geschlossen werden, beispielsweise von Personen.
Um Bilder zu identifizieren, müssen Sie in der Lage sein, Bilder aus Abfragen mit Bildern in der Datenbank zu vergleichen.
Um Bilder zu vergleichen, die zu perspektivischen Verzerrungen und Farbverzerrungen neigen, verwenden wir die Schlüsselpunktanpassung. Dazu finden wir wichtige Punkte mit Deskriptoren auf den Bildern, finden deren Entsprechung und zeigen die entsprechenden Punkte mithilfe der RANSAC-Methode homografisch an. Dies erfolgt im Allgemeinen auf die gleiche Weise wie im OpenCV- Beispiel beschrieben. Wenn die Anzahl der von RANSAC gefundenen „Inlier“ -Punkte groß genug ist und die gefundene homografische Transformation plausibel erscheint (keine starke Skalierung oder Rotation aufweist), können wir davon ausgehen, dass es sich bei den gewünschten Bildern um ein und dasselbe Bild handelt, das perspektivischen Verzerrungen unterliegt .
Ein Beispiel für die Zuordnung von Schlüsselpunkten:

Negatives Übereinstimmungsbeispiel Vergleich von Gemälden aus dem obigen Beispiel Natürlich ist die Suche nach Schlüsselpunkten normalerweise ein ziemlich langsamer Prozess, aber um die Datenbank zu durchsuchen, können Sie die Schlüsselpunkte aller Bilder im Voraus finden und einige davon speichern. In unseren Experimenten kamen wir zu dem Schluss, dass weniger als 1000 Punkte für eine zuverlässige Suche nach Gemälden ausreichen. Bei Verwendung von 64 Bytes pro Punkt (Koordinaten + AKAZE-Deskriptor) zum Speichern von 1024 Punkten reichen 64 KByte pro Bild oder etwa 15 GB pro Basis aus.
Der Vergleich von Bildern nach Schlüsselpunkten dauerte in unserem Fall ungefähr 15 ms, dh für eine vollständige Aufzählung einer Datenbank mit 250.000 Bildern dauert es ungefähr 1 Stunde. Das ist viel.
Wenn wir dagegen lernen, schnell mehrere (z. B. 100) der wahrscheinlichsten Kandidaten aus der gesamten Datenbank auszuwählen, erreichen wir die Zielzeit von 1 Sekunde pro Anfrage.
Ähnlichkeitsrang
Deep Convolution-Netzwerke haben sich als eine gute Möglichkeit etabliert, nach ähnlichen Bildern zu suchen. Das Netzwerk wird verwendet, um Merkmale zu extrahieren und auf ihrer Basis einen Deskriptor zu berechnen, der die Eigenschaft hat, dass der Abstand (euklidisch, kosinus oder andere) zwischen den Deskriptoren ähnlicher Bilder geringer ist als für verschiedene Bilder.
Sie können das Netzwerk so trainieren, dass für das Bild des Bildes von der Basis und das verzerrte Bild vom Foto enge Deskriptoren und für verschiedene Bilder - weiter entfernte - erzeugt werden. Ferner wird ein solches Netzwerk verwendet, um Deskriptoren aller Bilder in der Datenbank und Fotodeskriptoren in Anfragen zu berechnen. Sie können schnell die nächstgelegenen Bilder auswählen und sie entsprechend dem Abstand zwischen den Deskriptoren anordnen.
Die grundlegende Methode zum Trainieren eines Netzwerks zur Berechnung eines Deskriptors ist die Verwendung eines siamesischen Netzwerks.
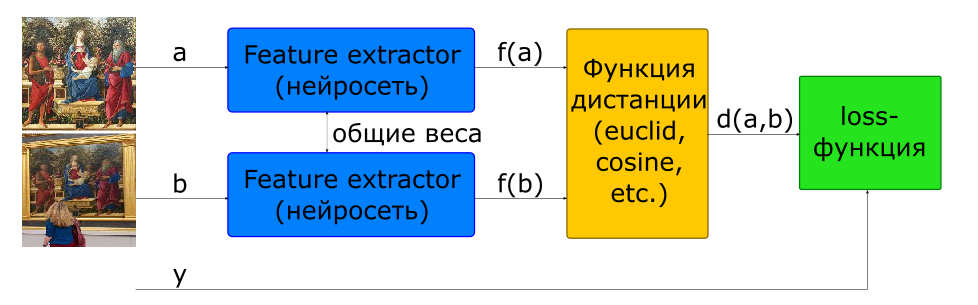
- Bilder eingeben
wenn und - eine Klasse wenn anders
- Bilddeskriptoren
- Abstand zwischen einem Paar von Merkmalsvektoren
- Zielfunktion
Um eine solche Architektur aufzubauen, wird im Modell zweimal ein Netzwerk verwendet, das einen Deskriptor (Feature Extractor) mit gemeinsamen Gewichten berechnet. Dem Netzwerkeingang werden einige Bilder zugeführt. Das Feature Extractor-Netzwerk berechnet die Bilddeskriptoren, dann berechnet das Netzwerk die Entfernung gemäß der angegebenen Metrik (normalerweise wird die euklidische oder Cosinus-Entfernung verwendet). Die Zielfunktion des Netzwerktrainings ist so aufgebaut, dass bei positiven Paaren (Bilder eines Bildes) der Abstand abnimmt und bei negativen (Bilder verschiedener Bilder) zunimmt. Um den Einfluss negativer Paare zu verringern, wird der Abstand zwischen ihnen durch den Randwert begrenzt.
Wir können also sagen, dass das Netzwerk während des Trainings versucht, Deskriptoren ähnlicher Bilder in einer Hypersphäre mit einem Randradius und Deskriptoren verschiedener Bilder zu berechnen, um die Grenzen dieser Sphäre zu verschieben.
Dies könnte beispielsweise so aussehen, als würde ein zweidimensionaler Deskriptor mithilfe des siamesischen Netzwerks im MNIST-Datensatz trainiert.
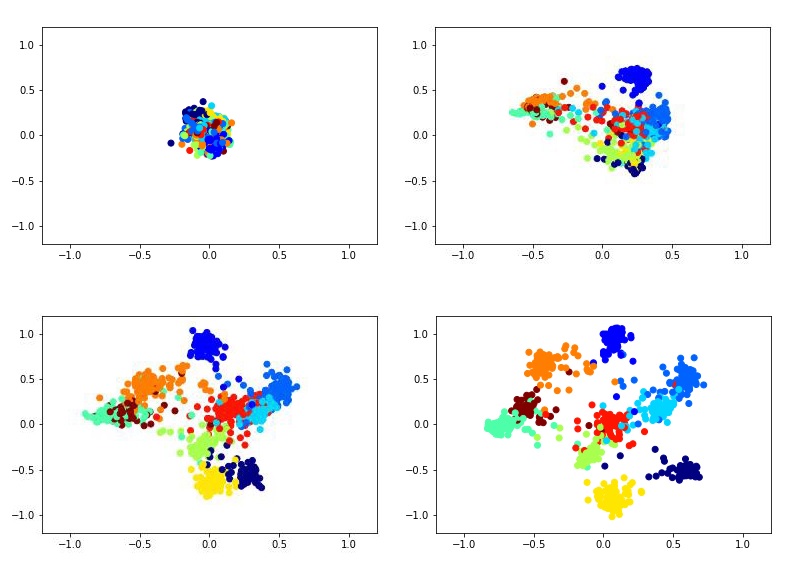
Um das siamesische Netzwerk zu trainieren, müssen Sie Bildpaare und eine Bezeichnung eingeben, die gleich 1 ist, wenn die Bilder derselben Klasse angehören, oder 0, wenn sie unterschiedlich sind. Es besteht das Problem, das Verhältnis von positiven und negativen Paaren zu wählen. Idealerweise wäre es natürlich notwendig, alle möglichen Kombinationen von Paaren aus dem Trainingssatz dem Netzwerktraining vorzulegen, aber dies ist technisch unmöglich. Und die Anzahl der negativen Paare übersteigt in diesem Fall die Anzahl der positiven Paare erheblich, was sich auch nicht sehr gut auf den Lernprozess auswirkt.
Ein Teil des Problems bei der Auswahl des Anteils der Paare für das Training wird mithilfe der Triplett-Architektur gelöst.
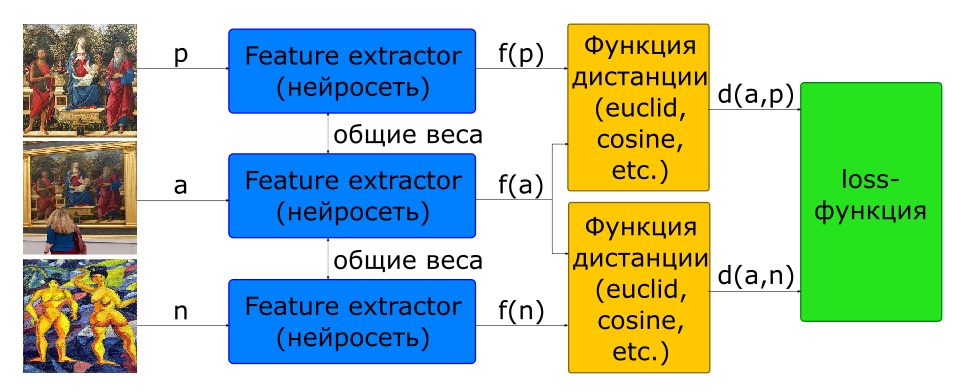
- Eingabebilder: - ein Bild, - ein anderer
- Zielfunktion
Am Eingang eines solchen Netzwerks werden sofort 3 Bilder gebildet, die ein positives und ein negatives Paar bilden.
Darüber hinaus sind sich fast alle Forscher einig, dass die Auswahl negativer Paare für das Lernen im Netzwerk von entscheidender Bedeutung ist. Die Zielfunktion für viele Stichproben (Paare für Siamesen, Tripel für Triplett) stellt sich als 0 heraus, wenn sie die Margin-Grenze nicht verletzen. Daher nehmen solche Stichproben nicht am Training des Netzwerks teil. Mit der Zeit verlangsamt sich der Lernprozess noch mehr, da es immer weniger Stichproben mit einem Wert ungleich Null der Zielfunktion gibt. Um dieses Problem zu lösen, werden negative Paare nicht zufällig ausgewählt, sondern indem nach Hard Cases Mining gesucht wird. In der Praxis werden hierfür mehrere Negativkandidaten ausgewählt, für die jeweils ein Deskriptor anhand der neuesten Version der Netzwerkgewichte (aus einer früheren Ära oder sogar aus der aktuellen) berechnet wird. Mit einem Deskriptor können Sie in jedem drei ein Negativ auswählen, das einen bekannten Verlust ungleich Null erzeugt.
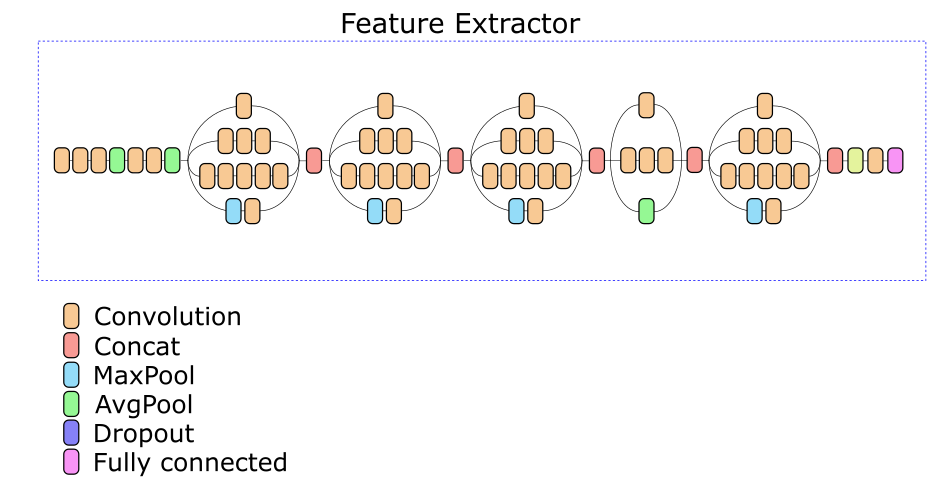
Um nach ähnlichen Bildern zu suchen, wird Feature Extractor vom Netzwerk getrennt und zur Berechnung von Deskriptoren verwendet. Für Bilder in der Datenbank werden Deskriptoren beim Hinzufügen im Voraus berechnet. Daher besteht die Aufgabe des Findens ähnlicher Bilder darin, den Bilddeskriptor in der Abfrage zu berechnen und nach den Deskriptoren zu suchen, die der gegebenen Metrik in der Datenbank am nächsten liegen.
Unser Network Feature Extractor basiert auf der Inception v3-Architektur. Eine der Zwischenschichten wurde experimentell ausgewählt, basierend auf deren Ausgabe ein Deskriptor von 512 reellen Zahlen berechnet wird.
Datenerweiterung
Es wäre schön, wenn wir jedes Bild in verschiedenen Rahmen an verschiedenen Wänden platzieren und jedes Mal Bilder aus einem anderen Blickwinkel auf verschiedenen Handys aufnehmen könnten. In der Praxis ist dies natürlich unmöglich. Daher ist es notwendig, Trainingsdaten zu generieren.
Um Daten zu generieren, wurden etwa 500 Fotografien verschiedener Gemälde mit unterschiedlichem Hintergrund unter verschiedenen Lichtbedingungen gesammelt. Für jedes Foto wurden 4 Punkte ausgewählt, die den Ecken der Leinwand des Bildes entsprechen. Für vier Punkte können wir jedes Bild beliebig in den Rahmen einpassen, wodurch das Bild ersetzt wird und eine fast zufällige perspektivische Verzerrung des Bildes aus der Datenbank erhalten wird. Ergänzend zu diesem Prozess mit zufälligen Zuschnitten, Rauschen und Farbverzerrungen erhalten wir die Möglichkeit, vollständig geeignete Bilder zu erstellen, die Fotografien von Gemälden imitieren.

Trennung eines Bildes von einem Hintergrund
Die Qualität der Arbeit und der Modelle zur Identifizierung von Gemälden sowie der Modelle zur Klassifizierung von Genres / Stilen hängt weitgehend davon ab, wie gut das Bild vom Hintergrund getrennt ist. Bevor Sie ein Bild in ein Modell einspeisen, müssen Sie im Idealfall die 4 Ecken der Leinwand finden und die Perspektive in einem Quadrat anzeigen. In der Praxis stellte sich heraus, dass es sehr schwierig war, einen Algorithmus zu implementieren, der dies garantiert. Einerseits gibt es eine Vielzahl von Hintergründen, Rahmen und Objekten, die in den Rahmen in der Nähe des Bildes fallen können. Auf der anderen Seite gibt es Gemälde, in denen sich recht rechteckige Umrisse (Fenster, Gebäudefassaden, Bild-in-Bild) bemerkbar machen. Infolgedessen ist es oft sehr schwierig zu sagen, wo das Bild endet und seine Umgebung beginnt.
Am Ende haben wir uns für eine einfache Implementierung entschieden, die auf klassischen Methoden des Computer-Sehens basiert (Grenzerkennung + morphologische Filterung + Analyse verbundener Komponenten), mit der Sie sicher monophone Hintergründe abschneiden können, ohne jedoch einen Teil des Bildes zu verlieren.
Arbeitsgeschwindigkeit
Der Abfrageverarbeitungsalgorithmus besteht aus den folgenden Hauptschritten:
- Vorbereitung - in der Tat ist ein einfacher Detektor des Bildes implementiert, der gut funktioniert, wenn das Bild einen einfachen Hintergrund enthält;
- Berechnen eines Bilddeskriptors unter Verwendung eines tiefen Netzwerks;
- Rangfolge der Bilder nach Entfernung zu Deskriptoren in der Datenbank;
- Suche nach wichtigen Punkten im Bild;
- Überprüfung der Kandidaten in der Rangfolge.
Wir haben die Netzwerkgeschwindigkeit bei 200 Anfragen getestet. Die folgende Verarbeitungszeit für jede der Stufen wurde erhalten (Zeit in Sekunden):
| Bühne | min | max | Durchschnitt |
|---|
| Vorbereitung (Bildsuche) | 0,008 | 0,011 | 0,016 |
| Deskriptorberechnung (GPU) | 0,082 | 0,092 | 0,088 |
| KNN (k <500, CPU, Brute Force) | 0,199 | 0,820 | 0,394 |
| Schlüsselpunktsuche | 0,031 | 0,432 | 0,156 |
| Überprüfen Sie die wichtigsten Punkte | 0,007 | 9.844 | 2,585 |
| Gesamtanforderungszeit | 0,358 | 10.386 | 3.239 |
Da die Überprüfung der Kandidaten sofort beendet wird, da das Bild mit ausreichender Sicherheit gefunden wird, können wir davon ausgehen, dass die minimale Verarbeitungszeit der Anforderungen den Bildern entspricht, die unter den ersten Kandidaten gefunden wurden. Die maximale Anforderungszeit wird für Gemälde erhalten, die überhaupt nicht gefunden wurden - die Prüfung endet nach 500 Kandidaten.
Es ist ersichtlich, dass die meiste Zeit für die Auswahl der Kandidaten und deren Überprüfung aufgewendet wird. Es ist anzumerken, dass die Umsetzung dieser Schritte sehr unoptimal gemacht wurde und ein großes Beschleunigungspotential aufweist.
Doppelte Suche
Nachdem wir den vollständigen Index der Basis von Gemälden erstellt hatten, suchten wir damit nach Duplikaten in der Datenbank. Nach ungefähr 3 Stunden Anzeigen der Datenbank wurde festgestellt, dass mindestens 13657 Bilder in der Datenbank zweimal (und ungefähr drei) wiederholt werden.
Darüber hinaus wurden sehr interessante Fälle gefunden, die keine Duplikate sind.
 Eins
Eins ,
zwei . Es scheint, dass dies zwei Phasen derselben Arbeit sind.
 Eins
Eins ,
zwei ,
drei . Achten Sie nicht auf den Namen - alle drei Bilder sind unterschiedlich.
Sowie ein Beispiel für eine falsch positive Identifizierung durch Schlüsselpunkte.
 Eins
Eins ,
zwei .
Anstelle einer Schlussfolgerung
Generell sind wir mit dem Ergebnis des Service zufrieden.
Bei Testsätzen wird eine Identifikationsgenauigkeit von über 80% erreicht. In der Praxis stellt sich häufig heraus, dass es ausreicht, das Bild aus einem anderen Blickwinkel zu fotografieren, wenn es nicht zum ersten Mal gefunden wird. Fehler, wenn das falsche Bild gefunden wird, treten fast nie auf.
Insgesamt wurde die Lösung in einen Docker-Container eingewickelt und dem Kunden übergeben. Jetzt ist die Identifizierung von Gemälden anhand von Fotos in Anwendungen möglich, die den Arthive-Dienst verwenden, z. B. das Puschkin-Museum, das auf dem Spielmarkt erhältlich ist (es löst das Gemälde jedoch vom Hintergrund und erfordert, dass der Hintergrund hell ist, was das Fotografieren manchmal schwierig macht).