Die automatische Erkennung von Satelliten- oder Luftbildern ist der vielversprechendste Weg, um Informationen über die Position verschiedener Objekte auf dem Boden zu erhalten. Die Ablehnung der manuellen Bildsegmentierung ist besonders wichtig, wenn große Bereiche der Erdoberfläche in kurzer Zeit bearbeitet werden sollen.
Vor kurzem hatte ich die Möglichkeit, theoretische Fähigkeiten anzuwenden und mich im Bereich des maschinellen Lernens in einem realen Bildsegmentierungsprojekt zu versuchen. Ziel des Projekts ist die Erkennung von Waldbeständen, nämlich Baumkronen in hochauflösenden Satellitenbildern. Unter dem Schnitt werde ich meine Erfahrungen und Ergebnisse teilen.
Wenn es um die Bildverarbeitung geht, kann die Segmentierung wie folgt definiert werden - dies ist das Vorhandensein charakteristischer Bereiche auf dem Bild, die in diesem Merkmalsraum gleichermaßen beschrieben werden.
Unterscheiden Sie zwischen Helligkeit, Kontur, Textur und semantischer Segmentierung.
Semantische (oder semantische) Bildsegmentierung dient zum Hervorheben von Bereichen auf dem Bild, von denen jeder einem bestimmten Attribut entspricht. Im Allgemeinen sind Probleme der semantischen Segmentierung schwer zu algorithmisieren, so dass Faltungs-Neuronale Netze, die gute Ergebnisse zeigen, derzeit häufig für die Bildsegmentierung verwendet werden.
Erklärung des Problems
Das Problem der binären Segmentierung wird gelöst - Farbbilder (hochauflösende Satellitenbilder) werden dem Eingang des neuronalen Netzwerks zugeführt, auf dem die Bereiche von Pixeln hervorgehoben werden müssen, die zu denselben Klassenbäumen gehören.
Ausgangsdaten
Zu meiner Verfügung gab es eine Reihe von Satellitenbildkacheln mit einem rechteckigen Bereich, in den das Polygon passt. Darin müssen Sie nach Bäumen suchen. Das Polygon oder Multipolygon wird als GeoJSON-Datei dargestellt. In meinem Fall hatten die Kacheln ein PNG-Format mit einer Größe von 256 x 256 Pixel in Echtfarbe. (leider ohne IR) Nummerierung der Kacheln in der Form /zoom/x/y.png.
Es ist garantiert, dass alle Kacheln im Set aus Satellitenbildern stammen, die ungefähr zur gleichen Jahreszeit (Spätfrühling - Frühherbst, abhängig vom Klima einer bestimmten Region) und an einem Tag in einem ähnlichen Winkel zur Oberfläche aufgenommen wurden, an dem eine leichte Wolkendecke zulässig war.
Datenaufbereitung
Da die Fläche des gewünschten Polygons kleiner sein kann als diese rechteckige Fläche, müssen zunächst die Kacheln ausgeschlossen werden, die über die Grenzen des Polygons hinausgehen. Zu diesem Zweck wurde ein einfaches Skript geschrieben, das die erforderlichen Kacheln aus dem GeoJSON-Dateipolygon auswählt. Es funktioniert wie folgt. Zunächst werden die Koordinaten aller Eckpunkte des Polygons in Kachelnummern
konvertiert und einem Array hinzugefügt. Es gibt auch einen Versatz relativ zum Ursprung. Zur visuellen Prüfung wird ein Bild erzeugt, bei dem ein Pixel einer Kachel entspricht. Das Polygon im Bild wird bereits unter Berücksichtigung des Versatzes mit PIL ausgefüllt. Danach wird das Bild in ein Array übertragen, aus dem die erforderlichen Kacheln ausgewählt werden, die in das Polygon fallen.
from PIL import Image, ImageDraw
 Visuelles Ergebnis der Konvertierung eines Polygons in eine Reihe von Kacheln
Visuelles Ergebnis der Konvertierung eines Polygons in eine Reihe von KachelnNetzwerkmodell
Um die Probleme der Bildsegmentierung zu lösen,
gibt es eine Reihe von Modellen für Faltungs-Neuronale Netze. Ich habe mich für
U-Net entschieden , das sich bei der Segmentierung von Binärbildern bewährt hat. Die U-Net-Architektur besteht aus den sogenannten Kontraktions- und Expansionspfaden, die durch Probros in den entsprechenden Größenstufen verbunden sind. Sie reduzieren zuerst die Auflösung des Bildes und erhöhen es dann, indem sie es zuvor mit den Bilddaten kombinieren und andere Ebenen durchlaufen Faltung. Somit wirkt das Netzwerk als eine Art Filter. Das Komprimieren und Dekomprimieren von Blöcken wird als Satz von Blöcken einer bestimmten Dimension dargestellt. Und jeder Block besteht aus grundlegenden Operationen: Faltung, ReLu und Max-Pooling. Es gibt Implementierungen des U-Net-Modells für Keras, Tensorflow, Caffe und PyTorch. Ich habe Keras benutzt.
Trainingsset erstellen
Um dieses Unet-Modell zu lernen, benötigen Sie Bilder. Das erste, was mir in den Sinn kam, war die Idee, OpenStreetMap-Daten zu nehmen und darauf basierend Masken für das Training zu generieren. Aber wie sich in meinem Fall herausstellte, lässt die Genauigkeit der Polygone, die ich benötige, zu wünschen übrig. Ich brauchte auch die Anwesenheit einzelner Bäume, die nicht immer kartiert sind. Deshalb musste ich ein solches Unternehmen aufgeben. Es ist jedoch erwähnenswert, dass dieser Ansatz für andere Objekte wie Straßen oder Gebäude
effektiv sein kann .

Da die Idee, automatisch ein Trainingsmuster basierend auf OSM-Daten zu generieren, aufgegeben werden musste, habe ich beschlossen, einen kleinen Bereich manuell zu markieren. Zu diesem Zweck habe ich den JOSM-Editor verwendet, in dem ich verfügbare Geländebilder als Substrat verwendet habe, das ich auf einem lokalen Server platziert habe. Dann tauchte ein anderes Problem auf - ich fand keine Gelegenheit, die Anzeige des Kachelrasters mit normalen JOSM-Werkzeugen einzuschalten. Aus diesem Grund haben einige einfache Zeilen in .htaccess auf demselben Server aus einem anderen Verzeichnis eine leere Kachel mit einem Pixelrand für jede Anforderung des Formulars grid_tile / z / x / y.png ausgegeben und JOSM eine solche spontane Ebene hinzugefügt. So ein Fahrrad.
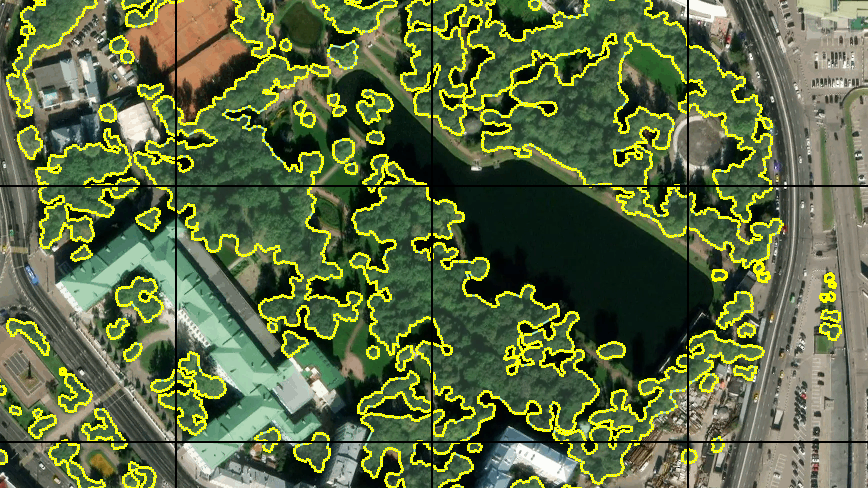
Zuerst habe ich ungefähr 30 Kacheln markiert. Mit einem Grafiktablett und dem „Schnellzeichnungsmodus“ in JOSM dauerte es nicht lange. Ich habe verstanden, dass eine solche Menge für ein vollwertiges Training nicht ausreicht, aber ich habe mich entschlossen, damit zu beginnen. Darüber hinaus wird das Training mit so vielen Daten schnell genug sein.
Training und erstes Ergebnis
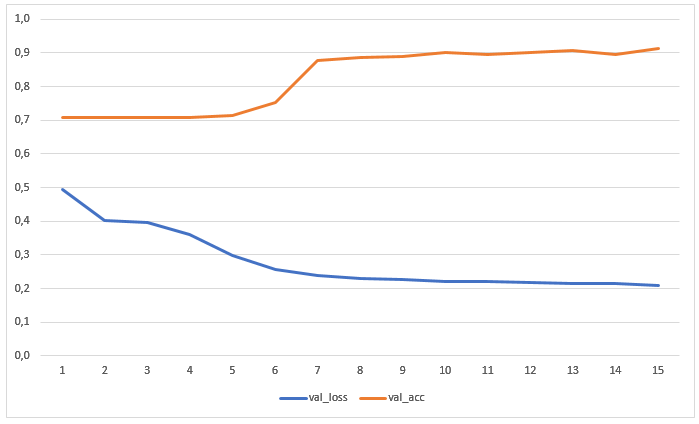
Das Netzwerk wurde für 15 Epochen ohne vorherige Datenerweiterung trainiert. Die Grafik zeigt die Werte für Verluste und Genauigkeit der Testprobe:
Das Ergebnis der Erkennung von Bildern, die sich weder im Training noch in der Testprobe befanden, erwies sich als recht vernünftig:

Nach einer gründlicheren Untersuchung der Ergebnisse wurden einige Probleme deutlich. Viele Fehler befanden sich in den Schattenbereichen der Bilder - das Netzwerk fand entweder Bäume im Schatten, wo sie nicht waren, oder genau das Gegenteil. Dies wurde erwartet, da das Trainingsset nur wenige solcher Beispiele enthielt. Ich hatte aber nicht erwartet, dass einige Teile der Wasseroberfläche und dunkle Dächer des Metallprofils (vermutlich) als Bäume erkannt würden. Es gab auch Ungenauigkeiten bei Rasenflächen. Es wurde beschlossen, die Stichprobe zu verbessern, indem eine größere Anzahl von Bildern mit kontroversen Abschnitten hinzugefügt wurde, sodass die Trainingsstichprobe fast verdoppelt wurde.
Datenerweiterung
Um die Datenmenge weiter zu erhöhen, habe ich beschlossen, das Bild in einem beliebigen Winkel zu drehen. Zunächst habe ich das Standardmodul keras.preprocessing.image.ImageDataGenerator ausprobiert. Wenn Sie unter Beibehaltung des Maßstabs drehen, verbleiben leere Bereiche an den Bildrändern, deren Füllung durch den Parameter
fill_mode festgelegt wird. Sie können diese Bereiche einfach mit Farbe füllen, indem Sie sie in
cval angeben . Ich wollte jedoch eine vollständige Drehung, in der Hoffnung, dass die Auswahl vollständiger ist, und habe den Generator selbst implementiert. Dadurch konnte die Größe um mehr als das Zehnfache erhöht werden.
 fill_mode = am nächsten
fill_mode = am nächstenMein Datengenerator klebt vier benachbarte Kacheln in eine einzige Quellkachel mit einer Größe von 512 x 512 Pixel. Der Drehwinkel wird zufällig ausgewählt, wobei berücksichtigt wird, dass die zulässigen Intervalle von x und y für die Mitte der resultierenden Kachel berechnet werden, in der er nicht über die ursprüngliche Kachel hinausgeht. Die Koordinaten des Zentrums werden unter Berücksichtigung der zulässigen Intervalle zufällig ausgewählt. Natürlich gelten alle diese Transformationen für das Kachelmaskenpaar. All dies wird für verschiedene Gruppen benachbarter Kacheln wiederholt. Aus einer Gruppe können Sie mehr als ein Dutzend Kacheln mit verschiedenen Abschnitten des Geländes erhalten, die in verschiedenen Winkeln gedreht werden.
 Ein Beispiel für das Ergebnis des Generators
Ein Beispiel für das Ergebnis des GeneratorsLernen mit mehr Daten
Infolgedessen betrug die Größe des Trainingsmusters 1881 Bilder, und ich erhöhte auch die Anzahl der Epochen auf 30:
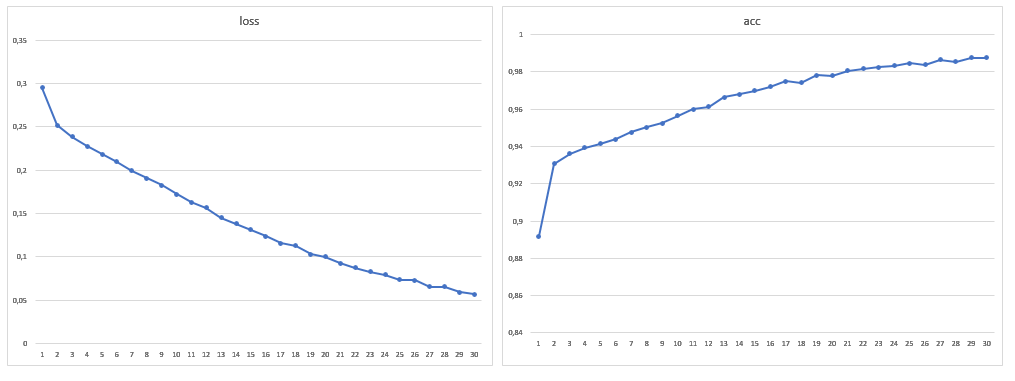
Nach dem Training des Modells mit einem neuen Datenvolumen wurden keine Probleme mit der fehlerhaften Segmentierung von Dächern und Wasser mehr festgestellt. Es war überhaupt nicht möglich, Fehler im Schatten loszuwerden, aber sie wurden im Auge weniger, ebenso wie Fehler bei Rasenflächen. Es ist zu beachten, dass die überwiegende Mehrheit der Fehler darin besteht, dass das Netzwerk Bäume dort sieht, wo sie nicht sind, und nicht umgekehrt. Die erreichte Genauigkeit kann verbessert werden, indem Satellitenbilder mit einer großen Anzahl von Kanälen verwendet und die Netzwerkarchitektur für eine bestimmte Aufgabe geändert werden.

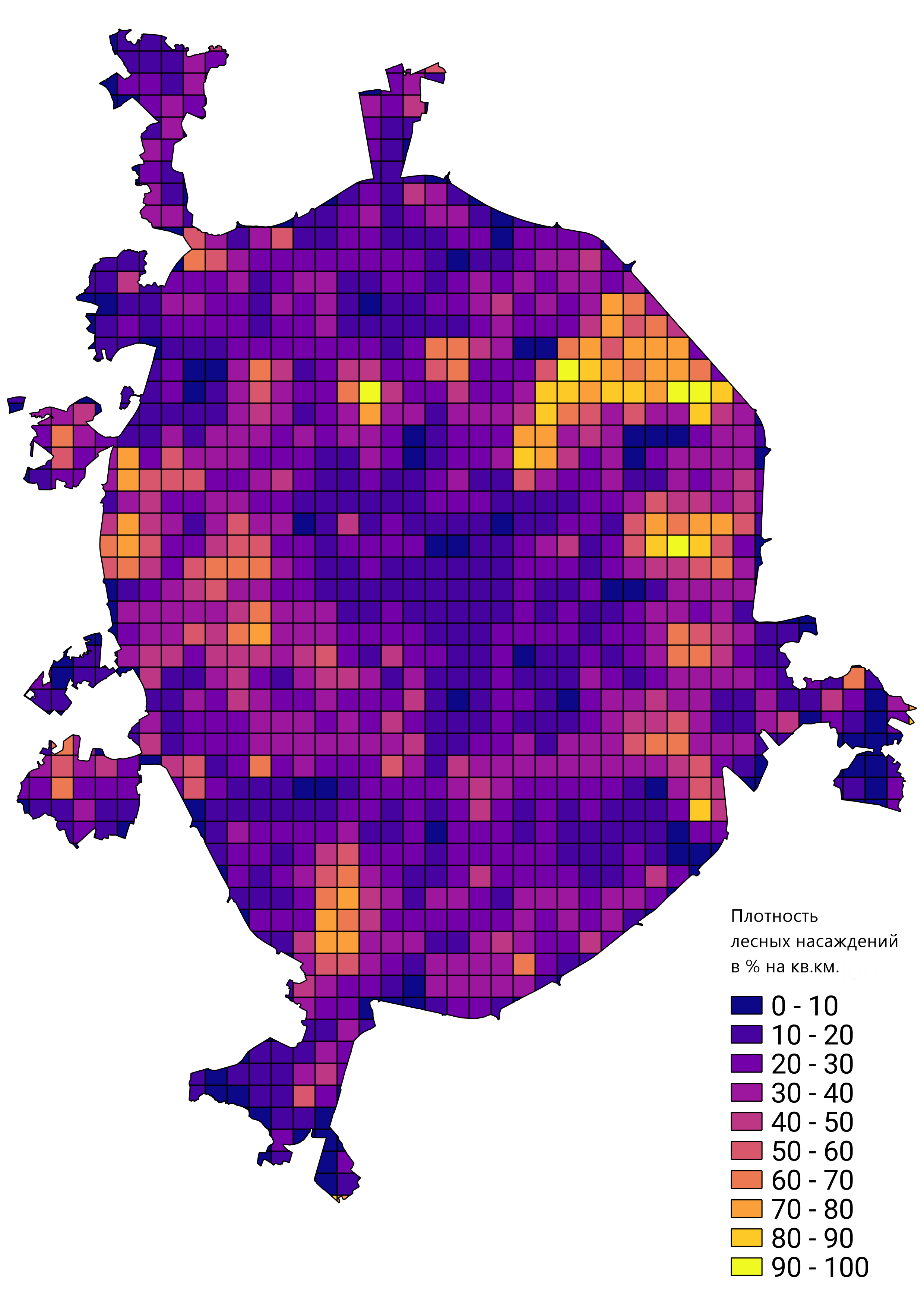
Im Allgemeinen war ich mit dem Ergebnis der geleisteten Arbeit zufrieden, und der geschulte Netzwerkprototyp wurde angewendet, um echte Probleme zu lösen. Zum Beispiel die Berechnung der Dichte von Waldbeständen in Moskau: