
Die Zeiten, in denen eine der dringendsten Aufgaben des Computer-Sehens die Fähigkeit war, Fotos von Hunden von Fotos von Katzen zu unterscheiden, liegen bereits in der Vergangenheit. Derzeit können neuronale Netze viel komplexere und interessantere Aufgaben für die Bildverarbeitung ausführen. Insbesondere können Sie im Netzwerk mit der Mask R-CNN-Architektur die Konturen („Masken“) verschiedener Objekte in Fotos auswählen, auch wenn mehrere solcher Objekte vorhanden sind, diese unterschiedlich groß sind und sich teilweise überlappen. Das Netzwerk ist auch in der Lage, die Posen von Personen im Bild zu erkennen.
Anfang dieses Jahres hatte ich die Gelegenheit, zu Bildungszwecken am Data Science Bowl 2018-Wettbewerb in Kaggle teilzunehmen. Zu Bildungszwecken habe ich eines dieser Modelle verwendet, die einige Teilnehmer in hohen Positionen großzügig angelegt haben. Es war ein neuronales Mask R-CNN-Netzwerk, das kürzlich von Facebook Research entwickelt wurde. (Es ist erwähnenswert, dass das Gewinnerteam immer noch eine andere Architektur verwendete - U-Net. Anscheinend war es besser für biomedizinische Aufgaben geeignet, einschließlich des Data Science Bowl 2018).
Da das Ziel darin bestand, uns mit den Aufgaben des Deep Learning vertraut zu machen und keinen hohen Platz einzunehmen, bestand nach dem Ende des Wettbewerbs ein starker Wunsch zu verstehen, wie das verwendete neuronale Netzwerk „unter der Haube“ funktioniert. Dieser Artikel ist eine Zusammenstellung von Informationen aus Originaldokumenten von arXiv.org und mehreren Artikeln auf Medium. Das Material ist rein theoretischer Natur (obwohl es am Ende Links zur praktischen Anwendung gibt) und enthält nicht mehr als in den angegebenen Quellen. Da es jedoch nur wenige Informationen zu diesem Thema auf Russisch gibt, ist der Artikel möglicherweise für jemanden nützlich.
Alle Abbildungen stammen aus Quellen anderer Personen und gehören deren rechtmäßigen Eigentümern.
Arten von Computer Vision-Aufgaben
In der Regel werden moderne Aufgaben des Computer-Sehens in vier Typen unterteilt (es war nicht erforderlich, Übersetzungen ihrer Namen auch in russischsprachigen Quellen, daher in Englisch, zu treffen, um keine Verwirrung zu stiften):
- Klassifizierung - Klassifizierung des Bildes nach dem darin enthaltenen Objekttyp;
- Semantische Segmentierung - Definition aller Pixel von Objekten einer bestimmten Klasse oder eines bestimmten Hintergrunds im Bild. Wenn sich mehrere Objekte derselben Klasse überlappen, können ihre Pixel nicht voneinander getrennt werden.
- Objekterkennung - Erkennung aller Objekte der angegebenen Klassen und Bestimmung des umschließenden Frameworks für jedes von ihnen;
- Instanzsegmentierung - Definition von Pixeln, die zu jedem Objekt jeder Klasse gehören, separat;
Am Beispiel eines Bildes mit Luftballons aus
[9] kann dies wie folgt dargestellt werden:
Evolutionäre Entwicklung der Maske R-CNN
Die Konzepte, die Mask R-CNN zugrunde liegen, wurden schrittweise durch die Architektur mehrerer neuronaler Zwischennetze entwickelt, die verschiedene Aufgaben aus der obigen Liste lösten. Der wahrscheinlich einfachste Weg, die Funktionsprinzipien dieses Netzwerks zu verstehen, besteht darin, alle diese Phasen nacheinander zu betrachten.
Ohne auf grundlegende Dinge wie die Rückausbreitung, die Funktion der nichtlinearen Aktivierung und die Funktionsweise eines mehrschichtigen neuronalen Netzwerks im Allgemeinen einzugehen, lohnt sich eine kurze Erklärung der Funktionsweise der Schichten von Convolution Neural Networks wahrscheinlich immer noch (R-CNN).
Faltung und MaxPooling
Mit einer Faltungsebene können Sie die Werte benachbarter Pixel kombinieren und allgemeinere Merkmale des Bildes hervorheben. Zu diesem Zweck wird das Bild nacheinander durch ein quadratisches Fenster kleiner Größe (3 x 3, 5 x 5, 7 x 7 Pixel usw.) verschoben, das als Kernel (Kernel) bezeichnet wird. Jedes Kernelement hat seinen eigenen Gewichtskoeffizienten multipliziert mit dem Wert des Pixels des Bildes, dem das Kernelement derzeit überlagert ist. Dann werden die für das gesamte Fenster erhaltenen Zahlen addiert, und diese gewichtete Summe gibt den Wert des nächsten Vorzeichens an.
Um eine Matrix ("Karte") von Attributen des gesamten Bildes zu erhalten, wird der Kern nacheinander horizontal und vertikal verschoben. In den folgenden Schichten wird die Faltungsoperation bereits auf die charakteristischen Karten angewendet, die aus den vorherigen Schichten erhalten wurden. Grafisch kann der Prozess wie folgt dargestellt werden:
Ein Bild oder eine Feature-Karte innerhalb einer Ebene kann nicht von einem, sondern von mehreren unabhängigen Filtern gescannt werden, wodurch nicht eine Karte, sondern mehrere (sie werden auch als „Kanäle“ bezeichnet) erhalten werden. Das Anpassen der Gewichte jedes Filters erfolgt mit demselben Backpropagation-Verfahren.
Wenn der Filterkern während des Scannens nicht über das Bild hinausgeht, ist die Abmessung der Feature-Map offensichtlich kleiner als die des Originalbilds. Wenn Sie die gleiche Größe beibehalten möchten, wenden Sie die sogenannten Auffüllungen an - Werte, die das Bild an den Rändern ergänzen und dann vom Filter zusammen mit den realen Pixeln des Bildes erfasst werden.
Zusätzlich zu den Auffüllungen werden Dimensionsänderungen auch durch Schritte beeinflusst - die Werte des Schritts, mit dem sich das Fenster um das Bild / die Karte bewegt.
Faltung ist nicht der einzige Weg, um eine verallgemeinerte Charakteristik einer Gruppe von Pixeln zu erhalten. Der einfachste Weg, dies zu tun, besteht darin, ein Pixel gemäß einer bestimmten Regel auszuwählen, beispielsweise das Maximum. Genau das macht die MaxPooling-Ebene.
Im Gegensatz zur Faltung wird Maxpooling normalerweise auf disjunkte Pixelgruppen angewendet.
R-CNN
Die R-CNN-Netzwerkarchitektur (Regions With CNNs) wurde von einem Team von UC Berkley entwickelt, um Convolution Neural Networks auf eine Objekterkennungsaufgabe anzuwenden. Die Ansätze zur Lösung solcher Probleme, die zu dieser Zeit existierten, näherten sich dem Maximum ihrer Fähigkeiten und ihre Leistung wurde nicht wesentlich verbessert.
CNN schnitt bei der Klassifizierung von Bildern gut ab, und in dem gegebenen Netzwerk wurden sie im Wesentlichen für dasselbe angewendet. Zu diesem Zweck wurde nicht das gesamte Bild dem CNN-Eingang zugeführt, sondern Regionen, die vorab auf eine andere Weise zugewiesen wurden, auf der sich einige Objekte befinden sollen. Zu dieser Zeit gab es mehrere solcher Ansätze, die Autoren entschieden sich für die
selektive Suche , obwohl sie darauf hinweisen, dass es keine besonderen Gründe für die Präferenz gibt.
Eine vorgefertigte Architektur wurde auch als CNN-Netzwerk verwendet -
CaffeNet (AlexNet). Solche neuronalen Netze werden wie andere für den ImageNet-Bildsatz in 1000 Klassen klassifiziert. R-CNN wurde entwickelt, um Objekte mit einer geringeren Anzahl von Klassen (N = 20 oder 200) zu erkennen. Daher wurde die letzte Klassifizierungsschicht von CaffeNet durch eine Schicht mit N + 1-Ausgängen (mit einer zusätzlichen Klasse für den Hintergrund) ersetzt.
Die selektive Suche gab ungefähr 2.000 Regionen mit unterschiedlichen Größen und Seitenverhältnissen zurück, aber CaffeNet akzeptiert Bilder mit einer festen Größe von 227 x 227 Pixel als Eingabe, sodass Sie sie ändern mussten, bevor Sie Regionen an die Netzwerkeingabe senden. Zu diesem Zweck wurde das Bild aus der Region in das kleinste überspannende Quadrat eingeschlossen. Entlang der (kleineren) Seite, entlang der die Felder gebildet wurden, wurden mehrere "kontextbezogene" (die Region umgebende) Pixel des Bildes hinzugefügt, der Rest des Feldes war mit nichts gefüllt. Das resultierende Quadrat wurde auf eine Größe von 227 x 227 skaliert und dem Eingang von CaffeNet zugeführt.

Trotz der Tatsache, dass CNN trainierte, um N + 1-Klassen zu erkennen, wurde es am Ende nur verwendet, um einen festen 4096-dimensionalen Merkmalsvektor zu extrahieren. N lineare SVMs waren an der direkten Bestimmung des Objekts im Bild beteiligt, von denen jede eine binäre Klassifizierung nach ihrem Objekttyp durchführte, um zu bestimmen, ob es so etwas in der übertragenen Region gab oder nicht. Im Originaldokument wird der gesamte Vorgang durch das folgende Schema veranschaulicht:
Die Autoren argumentieren, dass der Klassifizierungsprozess in SVM sehr produktiv ist und im Wesentlichen nur Matrixoperationen sind. Die von CNN erhaltenen Merkmalsvektoren werden über alle Regionen zu einer 2000 × 4096-Matrix kombiniert, die dann mit einer 4096 × N-Matrix mit SVM-Gewichten multipliziert wird.
Es ist zu beachten, dass die mit der selektiven Suche erhaltenen Regionen nur einige Objekte enthalten können und nicht die Tatsache, dass sie diese vollständig enthalten. Ob eine Region, die ein Objekt enthält, berücksichtigt werden soll oder nicht, wurde durch die
IoU-Metrik (Intersection over Union) bestimmt . Diese Metrik ist das Verhältnis der Schnittfläche eines rechteckigen Kandidatenbereichs mit einem Rechteck, das das Objekt tatsächlich umfasst, zur Vereinigungsfläche dieser Rechtecke. Wenn das Verhältnis einen vorbestimmten Schwellenwert überschreitet, wird angenommen, dass der Kandidatenbereich das gewünschte Objekt enthält.
IoU wurde auch verwendet, um eine übermäßige Anzahl von Regionen herauszufiltern, die ein bestimmtes Objekt enthalten (nicht maximale Unterdrückung). Wenn die IoU einer Region mit einer Region, die das maximale Ergebnis für dasselbe Objekt erhalten hat, über einem Schwellenwert lag, wurde die erste Region einfach verworfen.
Während des Fehleranalyseverfahrens entwickelten die Autoren auch eine Methode, mit der der Fehler bei der Auswahl des umschließenden Rahmens des Objekts verringert werden kann - Bounding-Box-Regression. Nach der Klassifizierung des Inhalts der Kandidatenregion wurden vier Parameter unter Verwendung einer linearen Regression basierend auf Attributen von CNN - (dx, dy, dw, dh) bestimmt. Sie beschrieben, wie stark die Mitte des Rahmens der Region um x und y verschoben werden sollte und wie stark die Breite und Höhe geändert werden muss, um das erkannte Objekt genauer abzudecken.
Somit kann das Verfahren zum Erkennen von Objekten durch das R-CNN-Netzwerk in die folgenden Schritte unterteilt werden:
- Markieren Sie Kandidatenregionen mithilfe der selektiven Suche.
- Konvertieren einer Region in die von CNN CaffeNet akzeptierte Größe.
- Erhalten unter Verwendung eines CNN 4096-dimensionalen Vektors von Merkmalen.
- Durchführen von N binären Klassifikationen jedes Merkmalsvektors unter Verwendung von N linearen SVMs.
- Lineare Regression von Regionsrahmenparametern für eine genauere Objektabdeckung
Die Autoren stellten fest, dass die von ihnen entwickelte Architektur auch beim Problem der semantischen Segmentierung eine gute Leistung erbrachte.
Schnelle r-cnn
Trotz der guten Ergebnisse war die Leistung von R-CNN immer noch gering, insbesondere für tiefere als CaffeNet-Netzwerke (wie VGG16). Darüber hinaus erforderte das Training für den Bounding-Box-Regressor und SVM das Speichern einer großen Anzahl von Attributen auf der Festplatte, sodass die Speichergröße teuer war.
Die Autoren von Fast R-CNN schlugen vor, den Prozess aufgrund einiger Änderungen zu beschleunigen:
- Durch CNN nicht jede der 2000 Kandidatenregionen einzeln passieren, sondern das gesamte Bild. Die vorgeschlagenen Regionen werden dann der resultierenden Karte mit gemeinsamen Merkmalen überlagert.
- Anstelle des unabhängigen Trainings von drei Modellen (CNN, SVM, bbox regressor) kombinieren Sie alle Trainingsverfahren in einem.
Die Umwandlung von Zeichen, die in verschiedene Regionen fielen, in eine feste Größe wurde unter Verwendung des
RoIPooling- Verfahrens durchgeführt. Ein Bereichsfenster mit der Breite w und der Höhe h wurde in ein Gitter mit H × W-Zellen der Größe h / H × w / W unterteilt. (Die Autoren des Dokuments verwendeten W = H = 7). Für jede solche Zelle wurde Max Pooling durchgeführt, um nur einen Wert auszuwählen, wodurch die resultierende H × W-Merkmalsmatrix erhalten wurde.
Binäre SVMs wurden nicht verwendet, stattdessen wurden die ausgewählten Features auf eine vollständig verbundene Schicht und dann auf zwei parallele Schichten übertragen: Softmax mit K + 1-Ausgängen (einer für jede Klasse + 1 für den Hintergrund) und Bounding-Box-Regressor.
Die allgemeine Netzwerkarchitektur sieht folgendermaßen aus:
Für das gemeinsame Training des Softmax-Klassifikators und des Bbox-Regressors wurde die kombinierte Verlustfunktion verwendet:
L(p,u,tu,v)=Lcls(p,u)+ lambda[u ge1]Lloc(tu,v)
Hier:
u - die Klasse des tatsächlich in der Kandidatenregion dargestellten Objekts;
Lcls(p,u)=− log(pu) - Protokollverlust für Klasse u;
v=(vx,vy,vw,vh) - echte Änderungen im Rahmen der Region für eine genauere Abdeckung des Objekts;
tu=(tux,tuy,tuw,tuh) - prognostizierte Änderungen im Rahmen der Region;
Lloc - Verlustfunktion zwischen vorhergesagten und realen Rahmenänderungen;
[u ge1] - Anzeigefunktion gleich 1 wenn
u ge1 und 0, wenn umgekehrt. Klasse
u=0 Der Hintergrund wird angezeigt (d. h. das Fehlen von Objekten in der Region).
lambda - Koeffizient, der den Beitrag beider Verlustfunktionen zum Gesamtergebnis ausgleichen soll. In allen Experimenten der Autoren des Dokuments war es jedoch gleich 1.
Die Autoren erwähnen auch, dass sie die abgeschnittene SVD-Zerlegung der Gewichtsmatrix verwendeten, um die Berechnungen in einer vollständig verbundenen Schicht zu beschleunigen.
Schneller r-cnn
Nach den Verbesserungen bei Fast R-CNN stellte sich heraus, dass der Engpass im neuronalen Netzwerk der Mechanismus zur Erzeugung von Kandidatenregionen ist. Im Jahr 2015 konnte ein Team von Microsoft Research diesen Schritt deutlich beschleunigen. Sie schlugen vor, Regionen nicht aus dem Originalbild zu berechnen, sondern wiederum aus einer Karte von Merkmalen, die von CNN erhalten wurden. Zu diesem Zweck wurde ein Modul namens Region Proposal Network (RPN) hinzugefügt. Die gesamte Architektur ist wie folgt:
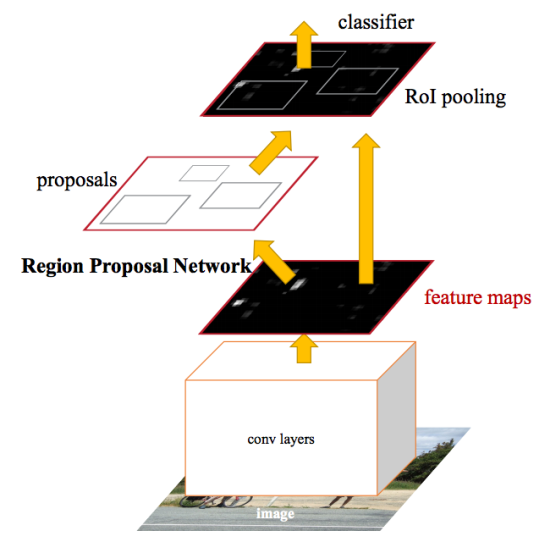
Im Rahmen des RPN gleiten sie laut extrahiertem CNN in ein „mini-neuronales Netzwerk“ mit einem kleinen (3x3) Fenster. Die mit seiner Hilfe erhaltenen Werte werden auf zwei parallele, vollständig verbundene Schichten übertragen: die Box-Regressionsschicht (reg) und die Box-Klassifizierungsschicht (cls). Die Ausgaben dieser Schichten basieren auf den sogenannten Ankern: k Rahmen für jede Position des Schiebefensters, die unterschiedliche Größen und Seitenverhältnisse haben. Die Reg-Schicht für jeden solchen Anker erzeugt 4 Koordinaten, wodurch die Position des umschließenden Rahmens korrigiert wird. Die cls-Schicht erzeugt jeweils zwei Zahlen - die Wahrscheinlichkeit, dass der Frame mindestens ein Objekt enthält oder nicht. In dem Dokument wird dies durch das folgende Schema veranschaulicht:
Der Lernprozess reg und cls Ebenen kombiniert; Sie haben eine gemeinsame Verlustfunktion, die die Summe der Verlustfunktionen jedes einzelnen von ihnen mit einem Ausgleichskoeffizienten ist.
Beide RPN-Schichten bieten nur Angebote für Kandidatenregionen. Diejenigen, die höchstwahrscheinlich ein Objekt enthalten, werden an das Objekterkennungs- und -verfeinerungsmodul weitergeleitet, das weiterhin als Fast R-CNN implementiert ist.
Um die in CNN erhaltenen Merkmale zwischen dem RPN und dem Erkennungsmodul zu teilen, wird der Trainingsprozess des gesamten Netzwerks iterativ in mehreren Schritten aufgebaut:
- Der RPN-Teil wird initialisiert und trainiert, um Kandidatenregionen zu identifizieren.
- Unter Verwendung der vorgeschlagenen RPN-Regionen wird der schnelle R-CNN-Teil neu trainiert.
- Ein trainiertes Erkennungsnetzwerk wird verwendet, um Gewichte für RPNs zu initialisieren. Allgemeine Faltungsschichten sind jedoch fest und nur die für RPN spezifischen Schichten werden neu abgestimmt.
- Mit festen Faltungsschichten wird Fast R-CNN endlich abgestimmt.
Das vorgeschlagene Schema ist nicht das einzige, und selbst in seiner gegenwärtigen Form kann es durch weitere iterative Schritte fortgesetzt werden, aber die Autoren der ursprünglichen Studie führten Experimente genau nach einem solchen Training durch.
Maske r-cnn
Die Maske R-CNN entwickelt die schnellere R-CNN-Architektur durch Hinzufügen eines weiteren Zweigs, der die Position der Maske vorhersagt, die das gefundene Objekt abdeckt, und somit das Problem der Instanzsegmentierung löst. Die Maske ist nur eine rechteckige Matrix, in der 1 an einer Position bedeutet, dass das entsprechende Pixel zu einem Objekt einer bestimmten Klasse gehört, 0 - dass das Pixel nicht zum Objekt gehört.

Die Visualisierung mehrfarbiger Masken auf den Quellbildern kann zu farbenfrohen Bildern führen:

Die Autoren des Dokuments unterteilen die entwickelte Architektur bedingt in ein CNN-Netzwerk zur Berechnung von Bildmerkmalen, das so genannte Backbone und Head - die Vereinigung der Teile, die für die Vorhersage des Hüllrahmens, die Klassifizierung des Objekts und die Bestimmung seiner Maske verantwortlich sind. Die Verlustfunktion ist für sie gleich und umfasst drei Komponenten:
L=Lcls+Lbox+Lmask
Die Maskenextraktion erfolgt in einem klassenunabhängigen Stil: Masken werden für jede Klasse separat vorhergesagt, ohne vorher zu wissen, was in der Region dargestellt wird, und dann wird einfach die Maske der Klasse ausgewählt, die den unabhängigen Klassifikator gewonnen hat. Es wird argumentiert, dass ein solcher Ansatz effektiver ist, als sich auf a priori Kenntnisse der Klasse zu stützen.
Eine der Hauptmodifikationen, die sich aus der Notwendigkeit ergeben, die Maske vorherzusagen, ist eine Änderung der
RoIPool- Prozedur (die die Merkmalsmatrix für die Kandidatenregion berechnet) zum sogenannten
RoIAlign . Tatsache ist, dass die von CNN erhaltene Merkmalskarte eine kleinere Größe als das Originalbild hat und der Bereich, der die ganzzahlige Anzahl von Pixeln im Bild abdeckt, nicht in einem proportionalen Bereich der Karte mit der ganzzahligen Anzahl von Merkmalen angezeigt werden kann:
In RoIPool wurde das Problem einfach durch Abrunden der Bruchwerte auf ganze Zahlen gelöst. Dieser Ansatz funktioniert gut bei der Auswahl des umschließenden Rahmens, aber die auf der Grundlage dieser Daten berechnete Maske ist zu ungenau.
Im Gegensatz dazu verwendet RoIAlign keine Rundung, alle Zahlen bleiben gültig und die bilineare Interpolation über die vier nächsten ganzzahligen Punkte wird zur Berechnung der Attributwerte verwendet.
Im Originaldokument wird der Unterschied wie folgt erklärt:
Hier bezeichnet die schraffierte Karte eine Merkmalskarte und fortlaufend - die Anzeige auf der Merkmalskarte der Kandidatenregion aus dem Originalfoto. In dieser Region sollten 4 Gruppen für maximales Pooling mit 4 Attributen vorhanden sein, die in der Abbildung durch Punkte angegeben sind. Im Gegensatz zum RoIPool-Verfahren, bei dem der Bereich aufgrund von Rundungen einfach an ganzzahligen Koordinaten ausgerichtet wird, belässt RoIAlign die Punkte an ihren aktuellen Positionen, berechnet jedoch die Werte für jeden von ihnen mithilfe der bilinearen Interpolation anhand der vier nächsten Vorzeichen.
Bilineare InterpolationDie bilineare Interpolation der Funktion zweier Variablen erfolgt durch lineare Interpolation, zuerst in Richtung einer der Koordinaten, dann in der anderen.
Es sei notwendig, den Wert der Funktion zu interpolieren
f ( x , y ) am Punkt P mit bekannten Werten der Funktion an den umgebenden Punkten
Q11=(x1,y1),Q12=(x1,y2),Q21=(x2,y1),Q22=(x2,y2) (siehe Bild unten). Dazu werden zunächst die Werte der Hilfspunkte R1 und R2 interpoliert und anschließend der Wert am Punkt P darauf basierend interpoliert.
R1=(x,y1)
R2=(x,y2)
f(R1)≈ frac(x2−x)(x2−x1)f(Q11)+ frac(x−x1)(x2−x1)f(Q21)
f(R2)≈ frac(x2−x)(x2−x1)f(Q12)+ frac(x−x1)(x2−x1)f(Q22)
f(P)≈(y2−y)(y2−y1)f(R1)+(y−y1)(y2−y1)f(R2)
( — ,
)
Zusätzlich zu den hohen Ergebnissen bei den Aufgaben der Instanzsegmentierung und Objekterkennung erwies sich die Maske R-CNN als geeignet, die Pose von Personen in der Fotografie zu bestimmen (Schätzung der menschlichen Pose). Der Schlüsselpunkt hierbei ist die Auswahl von Schlüsselpunkten (Schlüsselpunkten) wie der linken Schulter, dem rechten Ellbogen, dem rechten Knie usw., anhand derer Sie einen Rahmen der Position einer Person zeichnen können: Um die Referenzpunkte zu bestimmen, wird das neuronale Netzwerk so trainiert, dass Masken ausgegeben werden Davon hatte nur ein Pixel (derselbe Punkt) den Wert 1 und der Rest - 0 (One-Hot-Mask). Gleichzeitig trainiert das Netzwerk, K solche Einzelpixelmasken auszugeben, eine für jeden Referenzpunkttyp.
Um die Referenzpunkte zu bestimmen, wird das neuronale Netzwerk so trainiert, dass Masken ausgegeben werden Davon hatte nur ein Pixel (derselbe Punkt) den Wert 1 und der Rest - 0 (One-Hot-Mask). Gleichzeitig trainiert das Netzwerk, K solche Einzelpixelmasken auszugeben, eine für jeden Referenzpunkttyp.Feature Pyramid Networks
In Experimenten mit der Maske R-CNN wurden neben dem üblichen CNN ResNet-50/101 als Rückgrat auch Studien zur Machbarkeit der Verwendung des Feature Pyramid Network (FPN) durchgeführt. Sie zeigten, dass die Verwendung von FPN im Backbone Mask R-CNN eine Steigerung sowohl der Genauigkeit als auch der Leistung verleiht. Dies macht es nützlich, die Verbesserung auf die gleiche Weise zu beschreiben, obwohl ihr ein separates Dokument gewidmet ist und wenig mit der betrachteten Artikelserie zu tun hat.Der Zweck von Feature-Pyramiden besteht wie bei Bildpyramiden darin, die Erkennungsqualität von Objekten unter Berücksichtigung eines breiten Bereichs ihrer möglichen Größen zu verbessern.In Feature Pyramid Network werden Feature-Maps, die von aufeinanderfolgenden CNN-Layern mit abnehmenden Dimensionen extrahiert wurden, als eine Art hierarchische "Pyramide" betrachtet, die als Bottom-Up-Pfad bezeichnet wird. Darüber hinaus haben die Zeichenkarten sowohl der unteren als auch der oberen Ebene der Pyramide ihre Vor- und Nachteile: Die ersteren haben eine hohe Auflösung, aber eine geringe semantische Generalisierungsfähigkeit; der zweite - im Gegenteil:Mit der FPN-Architektur können Sie die Vorteile der oberen und unteren Schicht kombinieren, indem Sie einen Top-Down-Pfad und seitliche Verbindungen hinzufügen. Dazu wird die Karte jeder darüber liegenden Ebene auf die Größe der darunter liegenden Ebene vergrößert und deren Inhalt Element für Element hinzugefügt. In den endgültigen Vorhersagen werden die resultierenden Karten aller Ebenen verwendet.Schematisch kann dies wie folgt dargestellt werden:Das Erhöhen der Größe der Karte der obersten Ebene (Upsampling) erfolgt nach der einfachsten Methode - dem nächsten Nachbarn, d. H. Ungefähr so:Nützliche Links
Ursprüngliche Forschungsarbeiten auf arXiv.org:1. R-CNN: https://arxiv.org/abs/1311.25242. Schnelles R-CNN: https://arxiv.org/abs/1504.080833. Schnelleres R-CNN : https://arxiv.org/abs/1506.014974. Maske R-CNN: https://arxiv.org/abs/1703.068705. Feature Pyramid Network: https://arxiv.org/abs/1612.03144Auf Medium. com zum Thema Maske R-CNN gibt es viele Artikel, sie sind leicht zu finden. Als Referenz bringe ich nur diejenigen mit, die ich gelesen habe:6. Einfaches Verständnis der Maske RCNN - eine kurze Zusammenfassung der Prinzipien der resultierenden Architektur.7. Eine kurze Geschichte der CNNs in der Bildsegmentierung: Von R-CNN zur Maske R-CNN- Die Geschichte der Entwicklung des Netzwerks in der gleichen chronologischen Reihenfolge wie in diesem Artikel.8. Von R-CNN zu Maske R-CNN ist eine weitere Betrachtung der Entwicklungsstadien.9. Farbtupfer: Instanzsegmentierung mit Maske R-CNN und TensorFlow - Implementierung eines neuronalen Netzwerks in der Opensource-Bibliothek von Matterport.Der letzte Artikel beschreibt nicht nur die Prinzipien von Mask R-CNN, sondern bietet auch die Möglichkeit, das Netzwerk in der Praxis auszuprobieren: zum Färben von Luftballons in verschiedenen Farben auf Schwarzweißbildern.Darüber hinaus können Sie mit dem neuronalen Netzwerk an dem Modell üben, das ich im Kaggle-Wettbewerb Data Science Bowl 2018 verwendet habe (aber natürlich nicht nur mit diesem Modell; in den Abschnitten Kernel und Diskussionen finden Sie viele interessante Dinge):10. Maske R- CNN in PyTorch von Heng CherKeng. Die Implementierung umfasst eine Reihe von Bereitstellungsschritten. Der Autor gibt Anweisungen. Das Modell erfordert PyTorch 0.4.0, Unterstützung für GPU-Computing, NVIDIA CUDA. Wenn mein eigenes System die Anforderungen nicht erfüllt, kann ich Deep Learning AMI- Images für virtuelle Amazon-Maschinen empfehlen (Instanzen werden mit stündlicher Abrechnung bezahlt, die Mindestgröße ist anscheinend p2.xlarge).Ich bin auch hier auf dem Hub auf einen Artikel über die Verwendung des Netzwerks von Matterport bei der Bildverarbeitung mit Geschirr gestoßen (wenn auch ohne Quelle). Ich hoffe, der Autor wird nur mit der zusätzlichen Erwähnung zufrieden sein :11. ConvNets. Prototyp eines Projekts mit Mask R-CNN