In dem Film Mission Impossible 3 wurde der Prozess der Erstellung der berühmten Spionagemasken gezeigt, durch den einige Charaktere nicht mehr von anderen zu unterscheiden sind. Der Handlung zufolge musste zunächst die Person, in die sich der Held verwandeln wollte, aus verschiedenen Blickwinkeln fotografiert werden. Im Jahr 2018 wird ein einfaches 3D-Gesichtsmodell möglicherweise nicht einmal gedruckt, sondern zumindest in digitaler Form erstellt - und basiert auf nur einem Foto. Ein VisionLabs-Forscher beschrieb den Prozess auf der Yandex-Veranstaltung „
Welt mit den Augen von Robotern “ aus der Data & Science-Reihe ausführlich mit Einzelheiten zu bestimmten Methoden und Formeln.
- Guten Tag. Mein Name ist Nikolai, ich arbeite für VisionLabs, ein Computer Vision Unternehmen. Unser Hauptprofil ist die Gesichtserkennung, aber wir haben auch Technologien, die in der erweiterten und virtuellen Realität anwendbar sind. Insbesondere haben wir eine Technologie zum Erstellen eines 3D-Gesichts aus einem Foto, und heute werde ich darüber sprechen.

Beginnen wir mit einer Geschichte darüber, was es ist. Auf der Folie sehen Sie das Originalfoto von Jack Ma und ein 3D-Modell, das aus diesem Foto in zwei Variationen erstellt wurde: mit und ohne Textur, nur Geometrie. Dies ist die Aufgabe, die wir lösen.

Wir möchten auch in der Lage sein, dieses Modell zu animieren, die Blickrichtung, den Gesichtsausdruck zu ändern, Gesichtsausdrücke hinzuzufügen usw.
Die Anwendung ist in verschiedenen Bereichen. Am offensichtlichsten sind Spiele, einschließlich VR. Sie können auch virtuelle Umkleidekabinen einrichten - probieren Sie Brillen, Bärte und Frisuren an. Sie können 3D-Druck betreiben, da einige Leute an personalisierten Accessoires für ihr Gesicht interessiert sind. Und Sie können Gesichter für Roboter erstellen: Drucken und Anzeigen auf einem Display des Roboters.

Ich werde Ihnen zunächst erklären, wie Sie 3D-Gesichter im Allgemeinen generieren, und dann werden wir zur Aufgabe der 3D-Rekonstruktion als inverse Generierungsaufgabe übergehen. Danach konzentrieren wir uns auf die Animation und gehen auf die Herausforderungen ein, die sich in diesem Bereich ergeben.

Was ist die Aufgabe, Gesichter zu erzeugen? Wir möchten eine Möglichkeit haben, dreidimensionale Gesichter zu erzeugen, die sich in Form und Ausdruck unterscheiden. Hier sind zwei Zeilen mit Beispielen. Die erste Reihe zeigt Gesichter unterschiedlicher Form, die wie zu verschiedenen Personen gehören. Und unten ist das gleiche Gesicht mit einem anderen Ausdruck.

Eine Möglichkeit, das Generierungsproblem zu lösen, sind deformierbare Modelle. Die Fläche ganz links auf der Folie ist eine Art gemitteltes Modell, auf das wir durch Anpassen der Schieberegler Verformungen anwenden können. Hier sind drei Schieberegler. In der oberen Reihe befinden sich Flächen in Richtung der Erhöhung der Intensität des Schiebereglers, in der unteren Reihe in Richtung der Verringerung. Daher haben wir mehrere anpassbare Parameter. Durch die Installation können Sie Menschen verschiedene Formen geben.

Ein Beispiel für ein deformierbares Modell ist das berühmte Basler Gesichtsmodell, das aus Gesichts-Scans erstellt wurde. Um ein deformierbares Modell zu erstellen, müssen Sie zuerst einige Personen mitnehmen, sie in ein spezielles Labor bringen und ihre Gesichter mit spezieller Ausrüstung fotografieren und in 3D übersetzen. Auf dieser Grundlage können Sie dann neue Gesichter erstellen.

Wie ist es mathematisch angeordnet? Wir können uns ein dreidimensionales Modell eines Gesichts als Vektor im dreidimensionalen Raum vorstellen. Hier ist n die Anzahl der Eckpunkte im Modell, jeder Eckpunkt entspricht drei Koordinaten in 3D, und somit erhalten wir 3n Koordinaten.

Wenn wir einen Satz von Scans haben, wird jeder Scan durch einen solchen Vektor dargestellt, und wir haben einen Satz von n solchen Vektoren.
Außerdem können wir neue Flächen als lineare Kombinationen von Vektoren aus unserer Datenbank erstellen. Gleichzeitig möchten wir, dass die Koeffizienten aussagekräftig sind. Offensichtlich können sie nicht völlig willkürlich sein, und ich werde bald zeigen, warum. Eine der Einschränkungen kann so eingestellt werden, dass alle Koeffizienten im Bereich von 0 bis 1 liegen. Dies muss erfolgen, denn wenn die Koeffizienten völlig willkürlich sind, erweisen sich die Flächen als unplausibel.

Hier möchte ich den Parametern eine probabilistische Bedeutung geben. Das heißt, wir möchten eine Reihe von Parametern betrachten und verstehen, ob es wahrscheinlich ist, dass sich eine Person herausstellt oder nicht. Damit wollen wir, dass geringe Verzerrungen verzerrten Gesichtern entsprechen.

Hier erfahren Sie, wie es geht. Wir können die Hauptkomponentenmethode auf eine Reihe von Scans anwenden. Am Ausgang erhalten wir die durchschnittliche Fläche S0, erhalten die Matrix V, einen Satz von Hauptkomponenten, und erhalten auch Datenvariationen entlang der Hauptkomponenten. Dann können wir einen neuen Blick auf die Erzeugung von Gesichtern werfen. Wir werden die Gesichter als ein durchschnittliches Gesicht plus die Matrix der Hauptkomponenten, multipliziert mit dem Vektor der Parameter, darstellen.
Der Wert der Parameter ist die Intensität der Schieberegler, über die ich in einer der früheren Folien gesprochen habe. Außerdem können wir dem Parametervektor einen probabilistischen Wert zuweisen. Insbesondere können wir uns darauf einigen, dass dieser Vektor Gaußsch ist.

Auf diese Weise erhalten wir eine Methode, mit der Sie 3D-Gesichter generieren können. Diese Generierung wird durch die folgenden Parameter gesteuert. Wie auf der vorherigen Folie haben wir zwei Parametersätze, zwei Vektoren α id und α exp. Sie sind dieselben wie auf der vorherigen Folie, aber α id ist für die Form des Gesichts verantwortlich und α exp ist für die Emotion verantwortlich.
Ein neuer Vektor T erscheint ebenfalls - ein Texturvektor. Es hat dieselbe Dimension wie der Formvektor, und jeder Scheitelpunkt in diesem Vektor hat drei RGB-Werte. In ähnlicher Weise wird ein Texturvektor unter Verwendung des Parametervektors β erzeugt. Hier werden nicht die Parameter formalisiert, die für die Beleuchtung des Gesichts und für seine Position verantwortlich sind, sondern sie existieren auch.

Hier sind Beispiele für Flächen, die mit einem deformierten Modell erzeugt werden können. Bitte beachten Sie, dass sie sich in Form und Hautfarbe unterscheiden und auch bei unterschiedlichen Lichtverhältnissen gezeichnet werden.
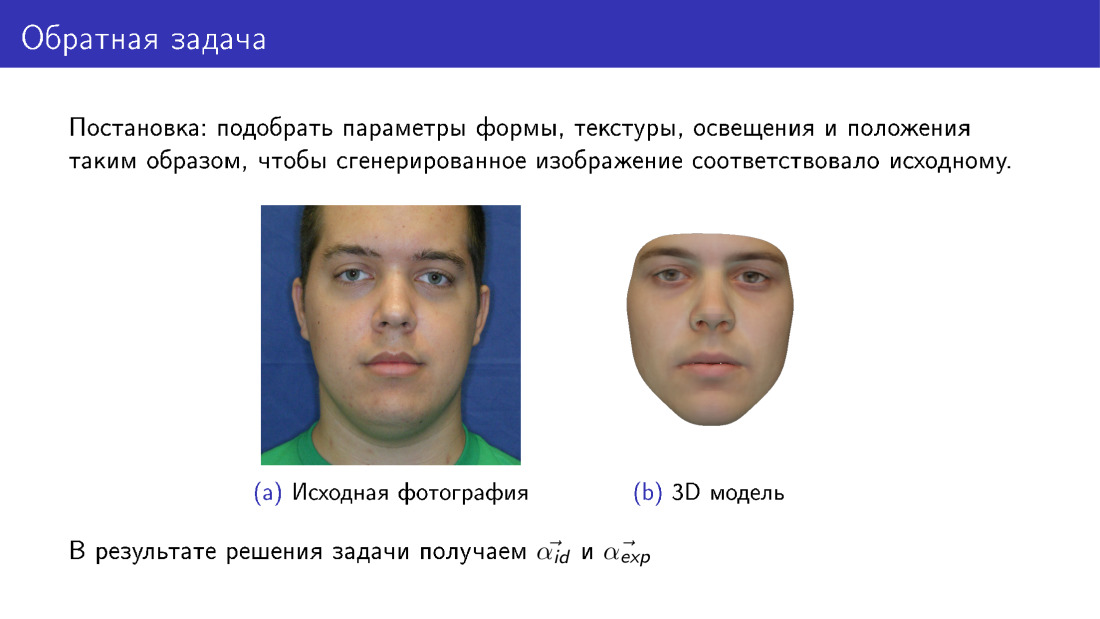
Jetzt können wir mit der 3D-Rekonstruktion fortfahren. Dies wird als inverses Problem bezeichnet, da wir solche Parameter für das verformbare Modell auswählen möchten, damit die Fläche, die wir daraus zeichnen, dem Original so ähnlich wie möglich ist. Diese Folie unterscheidet sich von der ersten darin, dass hier rechts das Gesicht vollständig synthetisch ist. Wenn auf der ersten Folie unsere Textur von einem Foto stammt, dann wurde hier die Textur von einem deformierbaren Modell übernommen.
Am Ausgang haben wir alle Parameter, auf der Folie werden α id und α exp dargestellt, und wir haben auch Beleuchtung, Texturparameter usw.

Wir wollten sicherstellen, dass das generierte Modell wie ein Foto aussieht. Diese Ähnlichkeit wird anhand der Energiefunktion ermittelt. Hier nehmen wir nur den pixelweisen Unterschied der Bilder in den Pixeln, in denen wir glauben, dass das Gesicht sichtbar ist. Wenn beispielsweise das Gesicht gedreht wird, tritt eine Überlappung auf. Zum Beispiel wird ein Teil des Wangenknochens von der Nase bedeckt. Und die Sichtbarkeitsmatrix M sollte eine solche Überlappung anzeigen.
Im Wesentlichen soll die 3D-Rekonstruktion diese Energiefunktion minimieren. Um dieses Minimierungsproblem zu lösen, wäre eine Initialisierung und Regularisierung wünschenswert. Eine Regularisierung ist aus einem offensichtlichen Grund erforderlich, da wir sagten, dass wir verzerrte Gesichter bekommen können, wenn wir die Parameter nicht regulieren und sie völlig willkürlich machen. Die Initialisierung ist erforderlich, da die Aufgabe insgesamt komplex ist, lokale Minima aufweist und Sie sich nicht mit ihnen befassen möchten.

Wie kann die Initialisierung erfolgen? Hierfür können Sie 68 Schlüsselpunkte des Gesichts verwenden. Seit 2013-2014 sind viele Algorithmen erschienen, mit denen 68 Punkte mit ziemlich guter Genauigkeit erkannt werden können, und jetzt nähern sie sich einer Sättigung ihrer Genauigkeit. Daher haben wir eine Möglichkeit, 68 Gesichtspunkte zuverlässig zu erkennen.
Wir können unserer Energiefunktion einen neuen Begriff hinzufügen, der besagt, dass die Projektionen derselben 68 Punkte des Modells mit den Schlüsselpunkten des Gesichts übereinstimmen sollen. Wir markieren diese Punkte auf dem Modell, verformen dann das Modell irgendwie, drehen es, projizieren die Punkte und stellen sicher, dass die Positionen der Punkte übereinstimmen. Auf dem linken Foto befinden sich zweifarbige Punkte, Violett und Gelb. Einige Punkte wurden vom Algorithmus erkannt, während andere aus dem Modell projiziert wurden. Markierungspunkte auf dem Modell rechts, aber für Punkte entlang der Gesichtskante wird nicht ein Punkt markiert, sondern eine ganze Linie. Dies geschieht, weil sich beim Drehen der Fläche die Markierungen dieser Punkte ändern müssen und der Punkt mit einer Linie ausgewählt wird.

Hier ist der Begriff, über den ich gesprochen habe. Es ist die koordinatenweise Differenz zweier Vektoren, die die Schlüsselpunkte des Gesichts und die vom Modell projizierten Schlüsselpunkte beschreiben.

Kehren wir zur Regularisierung zurück und betrachten das gesamte Problem aus der Perspektive der Bayes'schen Schlussfolgerung. Die Wahrscheinlichkeit, dass der Vektor α gleich etwas ist, das in einem bekannten Bild gegeben ist, ist proportional zum Produkt der Wahrscheinlichkeit, das Bild für ein gegebenes α zu beobachten, multipliziert mit der Wahrscheinlichkeit α. Wenn wir den negativen Logarithmus dieses Ausdrucks nehmen, den wir minimieren müssen, werden wir sehen, dass der für die Regularisierung verantwortliche Begriff hier eine konkrete Form hat. Dies ist insbesondere der zweite Begriff. Wenn wir uns daran erinnern, dass wir zuvor angenommen haben, dass der Vektor α Gaußsch ist, sehen wir, dass der für die Regularisierung verantwortliche Term die Summe der Quadrate der Parameter ist, die auf Variationen entlang der Hauptkomponenten reduziert sind.

Wir können also die volle Energiefunktion ausschreiben, die drei Begriffe enthält. Der erste Term ist verantwortlich für die Textur, für die Pixeldifferenz zwischen dem erzeugten Bild und dem Zielbild. Der zweite Begriff ist für wichtige Punkte verantwortlich, der dritte für die Regularisierung.
Die Koeffizienten der Terme im Minimierungsprozess werden nicht optimiert, sondern einfach eingestellt.
Hier wird die Energiefunktion als Funktion aller Parameter dargestellt. α id - Gesichtsformparameter, α exp - Ausdrucksparameter, β - Texturparameter, p - andere Parameter, über die wir gesprochen, aber nicht formalisiert haben, dies sind Positions- und Beleuchtungsparameter.
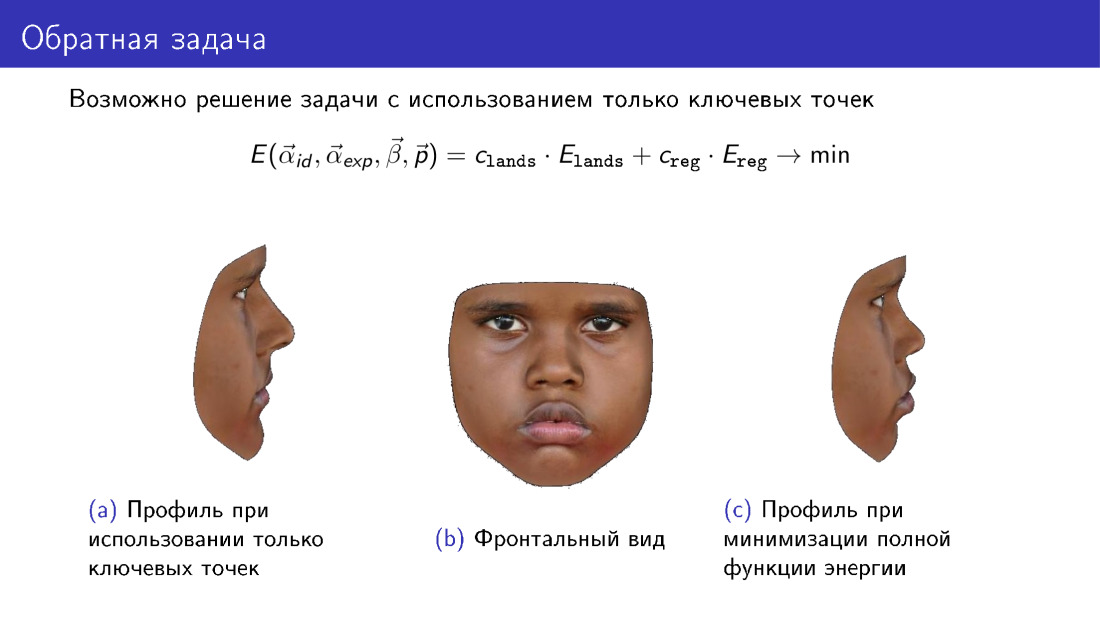
Lassen Sie uns auf diese Bemerkung eingehen. Diese Energiefunktion kann vereinfacht werden. Daraus können Sie den Begriff entfernen, der für die Textur verantwortlich ist, und nur die Informationen verwenden, die von 68 Punkten übertragen wurden. Auf diese Weise können Sie eine Art 3D-Modell erstellen. Beachten Sie jedoch das Modellprofil. Auf der linken Seite befindet sich ein Modell, das nur an wichtigen Punkten erstellt wurde. Auf der rechten Seite befindet sich ein Modell, das beim Erstellen eine Textur verwendet. Beachten Sie, dass das Profil rechts besser mit dem zentralen Foto übereinstimmt, das die Vorderansicht des Gesichts darstellt.

Die Animation mit dem vorhandenen Algorithmus zum Erstellen eines 3D-Modells des Gesichts funktioniert ganz einfach. Denken Sie daran, dass wir beim Erstellen eines 3D-Modells zwei Parametervektoren erhalten, von denen einer für die Form und der andere für den Ausdruck verantwortlich ist. Diese Vektoren von Parametern für den Benutzer und den Avatar haben immer ihre eigenen. Der Benutzer hat einen Vektor von Formularparametern, der Avatar hat einen anderen. Wir können jedoch die für den Ausdruck verantwortlichen Vektoren für sie gleich machen. Wir nehmen die Parameter, die für den Gesichtsausdruck des Benutzers verantwortlich sind, und ersetzen sie einfach durch das Avatar-Modell. So übertragen wir den Gesichtsausdruck des Benutzers auf den Avatar.
Lassen Sie uns über zwei Herausforderungen in diesem Bereich sprechen: die Arbeitsgeschwindigkeit und das begrenzte verformbare Modell.

Geschwindigkeit ist wirklich ein Problem. Das Minimieren der Gesamtenergiefunktion ist eine sehr rechenintensive Aufgabe. Insbesondere kann es 20 bis 40 dauern, durchschnittlich 30 Sekunden. Das ist lang genug. Wenn wir ein dreidimensionales Modell nur an Schlüsselpunkten erstellen, wird es viel schneller ausfallen, aber die Qualität wird darunter leiden.

Wie gehe ich mit diesem Problem um? Sie können mehr Ressourcen verwenden, einige Leute lösen dieses Problem auf der GPU. Es können nur wichtige Punkte verwendet werden, aber die Qualität wird darunter leiden. Und Sie können Methoden des maschinellen Lernens verwenden.

Mal sehen in der Reihenfolge. Hier ist die Arbeit von 2016, in der der Gesichtsausdruck des Benutzers auf ein bestimmtes Video übertragen wird. Sie können das Video mit Ihrem Gesicht steuern. Hier erfolgt die Erstellung des 3D-Modells in Echtzeit mit der GPU.

Hier sind die Methoden, die maschinelles Lernen verwenden. Die Idee ist, dass wir zuerst eine große Basis von Gesichtern für jedes Gesicht verwenden können, indem wir einen langen, aber genauen Algorithmus verwenden, um 3D-Modelle zu erstellen, jedes Modell als einen Satz von Parametern darzustellen und dann das Gitter zu trainieren, um diese Parameter vorherzusagen. Insbesondere wird in dieser Arbeit von 2016 ResNet verwendet, das ein Bild zur Eingabe nimmt und die Modellparameter zur Ausgabe gibt.

Das dreidimensionale Modell kann auf andere Weise dargestellt werden. In dieser Arbeit von 2017 wird das 3D-Modell nicht als eine Reihe von Parametern dargestellt, sondern als eine Reihe von Voxeln. Das Netzwerk sagt Voxel voraus und verwandelt das Bild in eine dreidimensionale Darstellung. Es ist erwähnenswert, dass Netzwerk-Trainingsoptionen möglich sind, für die 3D-Modelle überhaupt nicht erforderlich sind.

Dies funktioniert wie folgt. Hier ist der wichtigste Teil die Ebene, die die Parameter des verformbaren Modells als Eingabe verwenden und das Bild rendern kann. Es hat eine so wunderbare Eigenschaft, dass Sie dadurch die Rückausbreitung des Fehlers durchführen können. Das Netzwerk akzeptiert ein Bild als Eingabe, sagt die Parameter voraus, führt diese Parameter einer Ebene zu, die das Bild rendert, vergleicht dieses Bild mit der Eingabe, empfängt einen Fehler, gibt den Fehler zurück und lernt weiter. Somit lernt das Netzwerk, die Parameter des dreidimensionalen Modells vorherzusagen, wobei nur Bilder als Trainingsdaten verwendet werden. Und es ist sehr interessant.

Wir haben viel über Genauigkeit gesprochen - insbesondere darüber, dass es leidet, wenn wir einige Begriffe aus der Funktion der Energie herauswerfen. Lassen Sie uns formalisieren, was dies bedeutet und wie Sie die Genauigkeit der 3D-Gesichtsrekonstruktion bewerten können. Um dies zu erreichen, benötigen wir eine Basis von Wahrheits-Wahrheits-Scans, die mit speziellen Geräten durchgeführt werden und Methoden verwenden, für die es einige Garantien für die Genauigkeit gibt. Wenn eine solche Basis existiert, können wir unsere rekonstruierten Modelle mit der Grundwahrheit vergleichen. Dies geschieht einfach: Wir berechnen den durchschnittlichen Abstand von den Eckpunkten unseres Modells, das wir erstellt haben, zu den Eckpunkten in der Grundwahrheit und normalisieren auf die Größe des Scans. Dies muss erfolgen, weil die Gesichter unterschiedlich sind, einige größer, andere kleiner und der Fehler auf dem kleinen Gesicht kleiner wäre, einfach weil das Gesicht selbst kleiner ist. Daher ist eine Normalisierung erforderlich.

Ich möchte über unsere Arbeit sprechen, es wird in Workshops sein, es gibt ECCV. Wir machen ähnliche Dinge und bringen MobileNet bei, die Parameter eines deformierbaren Modells vorherzusagen. Als Trainingsdaten verwenden wir 3D-Modelle, die für Fotos aus dem 300-W-Datensatz erstellt wurden. Bewerten Sie die Genauigkeit anhand von BU4DFE-Scans.
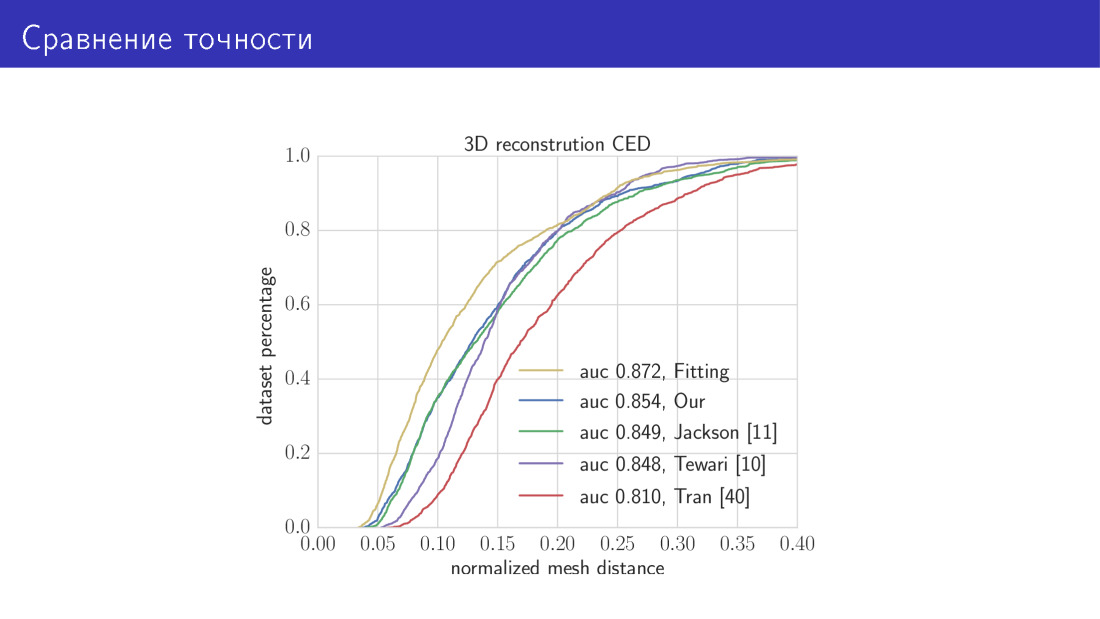
Hier ist das Ergebnis. Wir vergleichen unsere beiden Algorithmen mit dem Stand der Technik. Die gelbe Kurve in diesem Diagramm ist ein Algorithmus, der 30 Sekunden dauert und darin besteht, die Gesamtenergiefunktion zu minimieren. Hier entlang der X-Achse ist der Fehler, über den wir gerade gesprochen haben, der durchschnittliche Abstand zwischen den Eckpunkten. Die Y-Achse ist der Anteil der Bilder, bei denen dieser Fehler kleiner als der auf der X-Achse ist. In diesem Diagramm ist es umso besser, je höher die Kurve ist. Die nächste Kurve ist unser MobileNet-basiertes Netzwerk. Als nächstes die drei Werke, über die wir gesprochen haben. Parameter Predictive Network und Voxel Predictive Network.
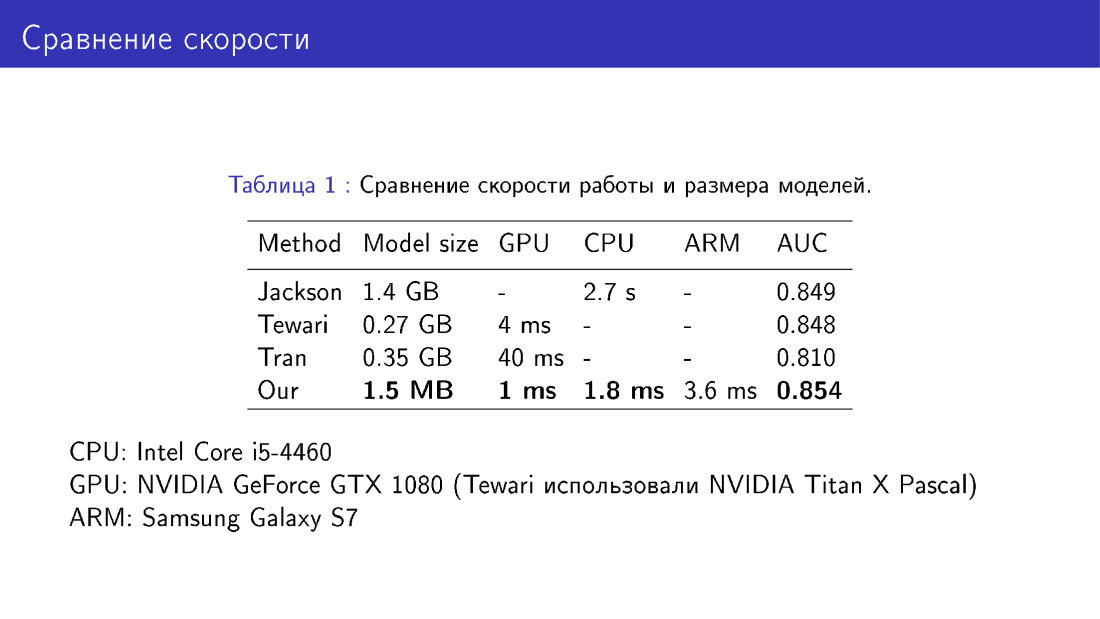
Wir haben unser Netzwerk auch hinsichtlich Modellgröße und Geschwindigkeit mit Kollegen verglichen. Dies ist ein Gewinn, da wir MobileNet verwenden, was recht einfach ist.
Die zweite Herausforderung ist die Begrenztheit des verformbaren Modells.

Achten Sie auf das linke Gesicht, schauen Sie auf die Flügel der Nase. Es gibt Schatten auf den Flügeln der Nase. Die Ränder der Schatten stimmen nicht mit den Rändern der Nase auf dem Foto überein, so dass ein Defekt erhalten wird. Der Grund dafür kann sein, dass das verformbare Modell im Prinzip nicht in der Lage ist, die Nase mit der erforderlichen Form aufzubauen, da dieses verformbare Modell aus Scans von nur 200 Flächen erhalten wurde. Wir möchten, dass die Nase korrekt ist, wie auf dem rechten Foto. Wir müssen also irgendwie über den Rahmen des deformierbaren Modells hinausgehen.

Dies kann unter Verwendung einer nichtparametrischen Verformung des Netzes erfolgen. Hier sind drei Aufgaben, die wir lösen möchten: Ändern Sie den lokalen Teil des Gesichts, z. B. die Nase, und binden Sie ihn dann in das ursprüngliche Modell des Gesichts ein, damit alles andere unverändert bleibt.

Dies kann wie folgt erfolgen. Kehren wir zur Bezeichnung des Netzes als Vektor im dreidimensionalen Raum zurück und betrachten den Mittelungsoperator. Dies ist ein Operator, der in S mit einem Header jeden Scheitelpunkt durch den Durchschnitt seiner Nachbarn ersetzt. Die Nachbarn des Gipfels sind diejenigen, die durch eine Kante mit ihm verbunden sind.
Wir werden eine bestimmte Energiefunktion definieren, die die Position des Scheitelpunkts relativ zu seinen Nachbarn beschreibt. Wir wollen, dass die Position des Peaks relativ zu seinen Nachbarn unverändert bleibt oder sich zumindest nicht wesentlich ändert. Gleichzeitig werden wir S irgendwie modifizieren. Diese Energiefunktion wird als intern bezeichnet, da es auch einen externen Begriff geben wird, der besagt, dass beispielsweise die Nase eine bestimmte Form annehmen sollte.
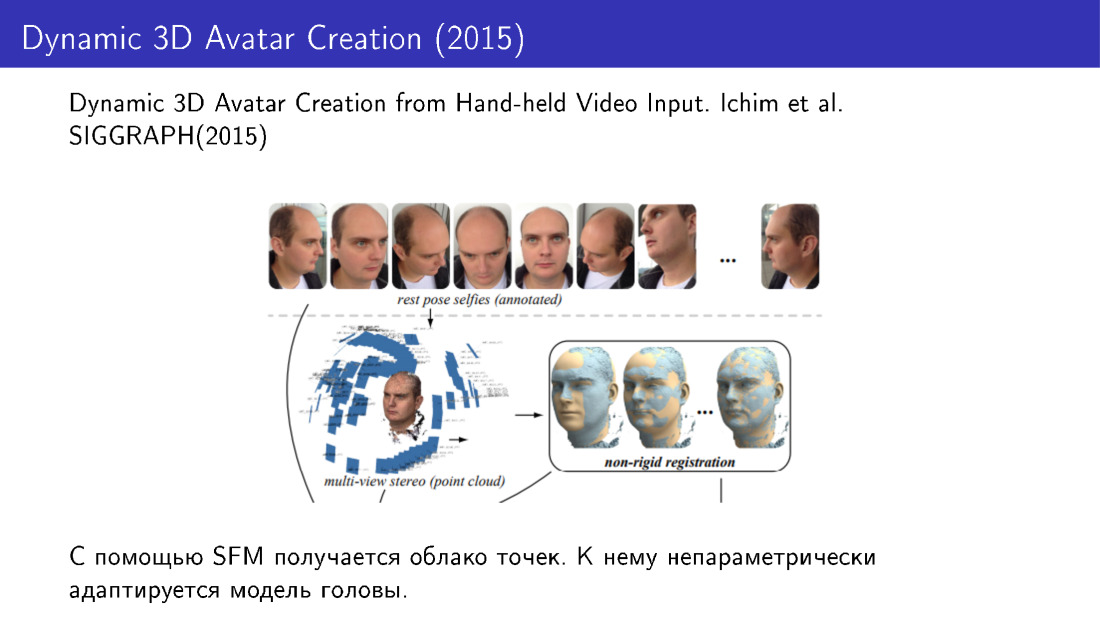
Solche Techniken wurden beispielsweise in der Arbeit von 2015 verwendet. Sie haben aus mehreren Fotos eine 3D-Gesichtsrekonstruktion durchgeführt. Wir haben mehrere Fotos vom Telefon aufgenommen, eine Punktwolke erhalten und dann das Gesichtsmodell mit nicht parametrischen Änderungen an diese Wolke angepasst.
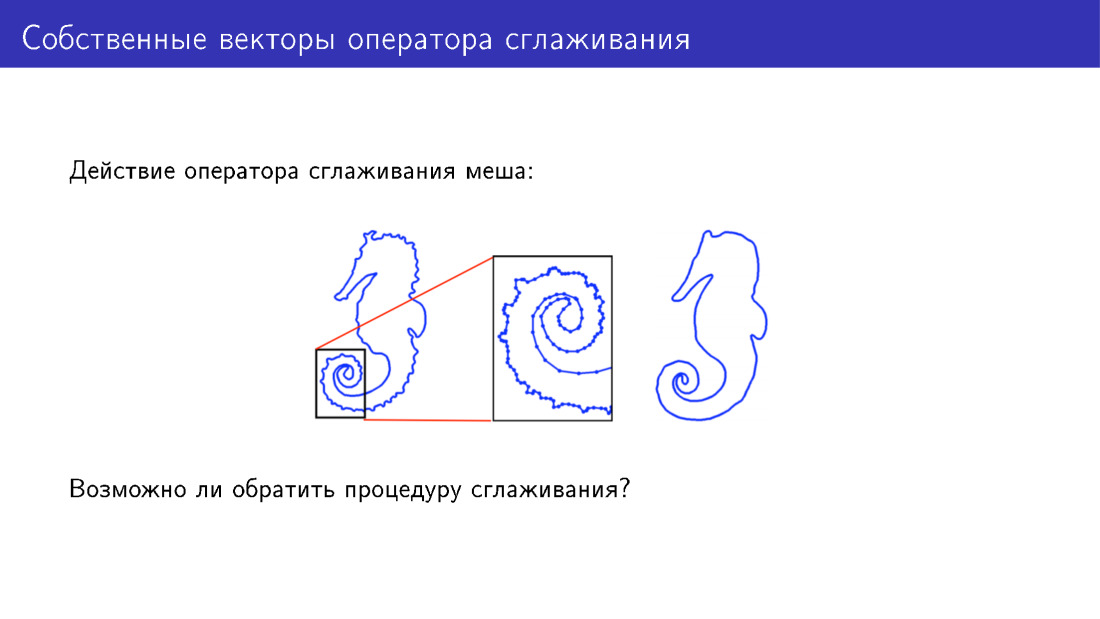
Sie können auf andere Weise über das verformbare Modell hinausgehen. Lassen Sie uns auf die Aktion des Glättungsoperators eingehen. Hier wird der Einfachheit halber ein zweidimensionales Netz dargestellt, auf das dieser Operator angewendet wurde. Es gibt viele Details zum Modell auf der linken Seite, beim Modell auf der rechten Seite wurden diese Details geglättet. Aber können wir etwas tun, um Details hinzuzufügen, anstatt sie zu entfernen?

. .
? -: - . . , 2016 . , .