Hallo allerseits!
Netracker entwickelt und liefert seit vielen Jahren Unternehmensanwendungen für den globalen Markt von Telekommunikationsbetreibern. Die Entwicklung solcher Lösungen ist ziemlich kompliziert: Hunderte von Menschen beteiligen sich an Projekten, und die Anzahl der aktiven Projekte liegt bei zehn.
Früher waren die Produkte monolithisch, aber jetzt bewegen wir uns zuversichtlich in Richtung Mikroservice-Anwendungen. DevOps stand vor einer ziemlich ehrgeizigen Aufgabe - diesen Technologiesprung zu schaffen.
Als Ergebnis haben wir ein erfolgreiches Montagekonzept erhalten, das wir als Best Practice teilen möchten. Die Beschreibung der Implementierung mit technischen Details wird sehr umfangreich sein, wir werden dies nicht im Rahmen dieses Artikels tun.
Im allgemeinen Fall ist Assemblierung die Umwandlung einiger Artefakte in andere.
Wer wird interessiert sein
Unternehmen, die fertige Software an eine vollständig Drittanbieterorganisation liefern und dafür bezahlt werden.
So könnte eine Entwicklung ohne externe Lieferung aussehen:
- Die IT-Abteilung des Werks entwickelt Software für ihr Unternehmen.
- Das Unternehmen ist im Outsourcing für einen ausländischen Kunden tätig. Der Kunde kompiliert und betreibt diesen Code unabhängig auf seinem eigenen Webserver.
- Das Unternehmen liefert Software an externe Kunden, jedoch unter einer Open Source-Lizenz. Der größte Teil der Verantwortung wird dadurch entlastet.
Wenn Sie nicht mit externer Versorgung konfrontiert sind, erscheint vieles, was unten geschrieben steht, überflüssig oder sogar paranoid.
In der Praxis muss alles in Übereinstimmung mit den internationalen Anforderungen für die verwendeten Lizenzen und Verschlüsselungen erfolgen, da sonst zumindest rechtliche Konsequenzen entstehen.
Ein Beispiel für einen Verstoß besteht darin, Code aus einer Bibliothek mit einer GPL3-Lizenz zu entnehmen und in eine kommerzielle Anwendung einzubetten.
Die Entstehung von Mikrodiensten erfordert Veränderungen
Wir haben umfangreiche Erfahrungen in der Montage und Lieferung von monolithischen Anwendungen gesammelt.
Mehrere Jenkins-Server, Tausende von CI-Jobs, mehrere vollautomatische Montagelinien basierend auf Jenkins, Dutzende engagierter Release-Ingenieure, eine eigene Expertengruppe für Konfigurationsmanagement.
In der Vergangenheit war der Ansatz im Unternehmen folgender: Entwickler schreiben den Quellcode, und DevOps erfindet und schreibt die Konfiguration des Assembly-Systems.
Als Ergebnis hatten wir zwei oder drei typische Baugruppenkonfigurationen, die für den Betrieb im Unternehmensökosystem ausgelegt waren. Schematisch sieht es so aus:
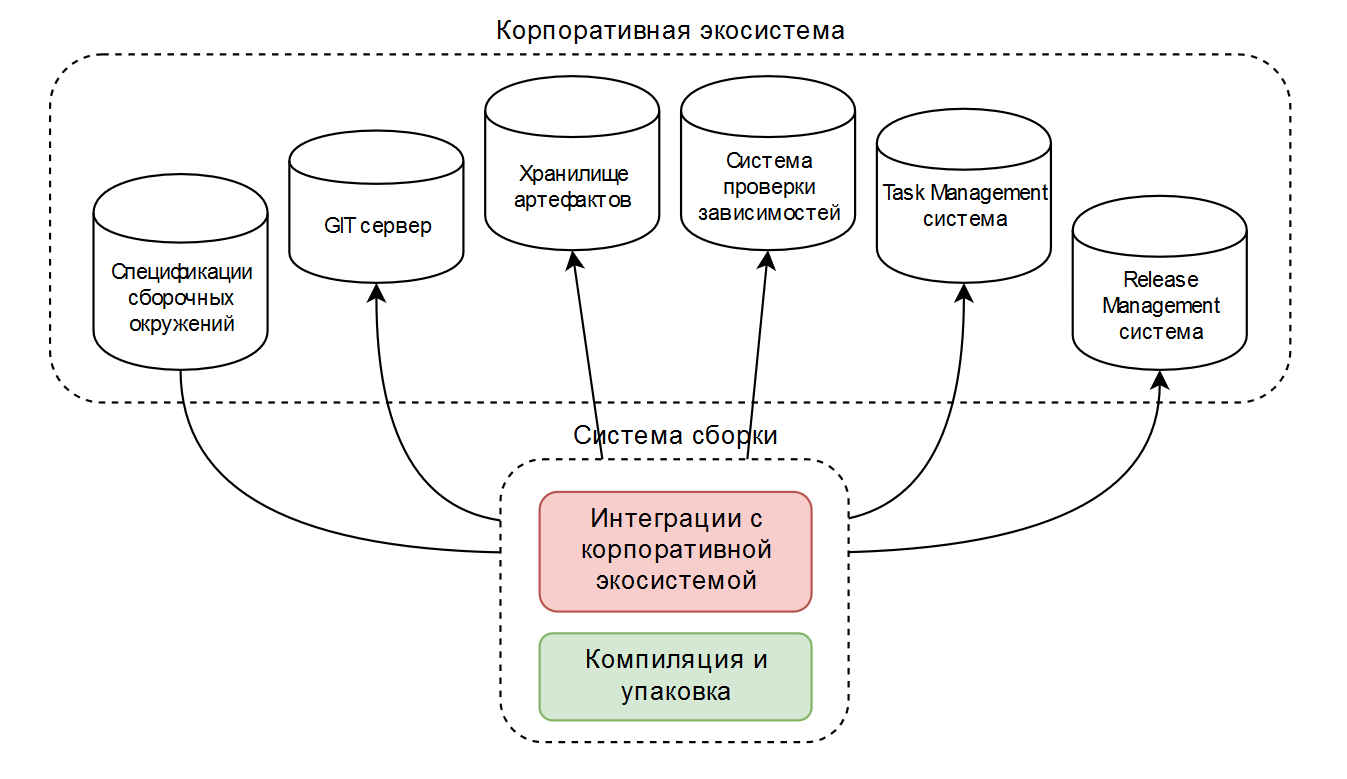
Das Build-Tool ist normalerweise Ant oder Maven, und etwas wird durch öffentlich verfügbare Plug-Ins implementiert, etwas wird selbst geschrieben. Dies funktioniert gut, wenn ein Unternehmen einen engen Satz von Technologien verwendet.
Microservices unterscheiden sich von monolithischen Anwendungen hauptsächlich durch die Vielfalt der Technologien.
Es stellt sich heraus, dass für jede Programmiersprache viele Assembly-Konfigurationen vorhanden sind. Eine zentrale Steuerung wird unmöglich.
Es ist erforderlich, Assembly-Skripte so weit wie möglich zu vereinfachen und Entwicklern die Möglichkeit zu geben, sie unabhängig voneinander zu bearbeiten.
Neben der einfachen Kompilierung und Verpackung (im Diagramm in Grün ) enthalten diese Skripte viel Code für die Integration in das Unternehmensökosystem (im Diagramm in Rot ).
Daher wurde beschlossen, die Baugruppe als "Black Box" zu betrachten, in der eine "intelligente" Baugruppenumgebung alle Probleme außer der Kompilierung und Verpackung selbst lösen kann.
Zu Beginn der Arbeit war nicht klar, wie man ein solches System bekommt. Architekturentscheidungen für DevOps-Aufgaben zu treffen, erfordert Erfahrung und Wissen. Wie bekomme ich sie? Mögliche Optionen sind unten:
- Suchen Sie im Internet nach Informationen.
- Eigene Erfahrung und Kenntnisse des DevOps-Teams. Um dies zu erreichen, ist es gut, dieses Team von Programmierern mit vielseitiger Erfahrung zu machen.
- Erfahrungen und Kenntnisse außerhalb des DevOps-Teams. Viele Entwickler im Unternehmen haben gute Ideen - Sie müssen sie hören. Kommunikation ist hilfreich.
- Wir erfinden und experimentieren!
Benötige ich Automatisierung?
Um diese Frage zu beantworten, müssen Sie verstehen, in welchem Entwicklungsstadium sich unsere Montageansätze befinden. Im Allgemeinen durchläuft eine Aufgabe die folgenden Ebenen.
- Unbewusste Ebene

Wir müssen eine Versammlung pro Woche veröffentlichen, unseren Jungs geht es gut. Das ist natürlich, warum darüber reden?
- Das Level des "Handwerkers", das sich schließlich in das Level des "Dodgers" verwandelt.

Es ist notwendig, zwei Baugruppen pro Tag stabil und fehlerfrei herzustellen. Wir haben Vasya, er macht es cool und niemand außer ihm verbringt diese Zeit.
- Manufakturebene

Die Dinge sind weit gegangen. Sie benötigen 20 Versammlungen pro Tag, Vasya kann das nicht bewältigen, und jetzt sitzt bereits ein Team von zehn Personen. Sie haben einen Chef, Pläne, Urlaub, Krankheitstage, Motivation, Teambildung, Schulungen, Traditionen und Regeln. Dies ist eine Spezialisierung, ihre Arbeit muss studiert werden.
Auf dieser Ebene wird die Aufgabe vom konkreten Executor getrennt und wird so zu einem Prozess.
Das Ergebnis ist eine klare, ausgearbeitete, eingeführte und hunderte Male korrigierte Beschreibung des Prozesses mit Text.
- Das Niveau der "automatisierten Produktion"

Die modernen Anforderungen an Baugruppen steigen: Alles sollte schnell und zuverlässig sein, 800 Baugruppen müssen pro Tag bereitgestellt werden. Dies ist von entscheidender Bedeutung, da das Unternehmen ohne solche Mengen Wettbewerbsvorteile verlieren wird.
Es findet eine kostspielige Automatisierung statt, und einige qualifizierte DevOps können den Prozess am Laufen halten. Eine weitere Skalierung ist kein Problem mehr.
Nicht jede Aufgabe sollte die letzte Stufe der Automatisierung erreichen.
Oft löst ein Handwerker mit einer Befehlszeile Probleme einfach und effektiv.
Die Automatisierung „friert“ den Prozess ein, senkt die Betriebskosten und erhöht die Änderungskosten.
Sie können direkt zur Fahrzeugbaugruppe gehen, aber das System ist unpraktisch, hält nicht mit den Anforderungen des Unternehmens Schritt und ist infolgedessen veraltet.
Was sind die Baugruppen und warum wird das Problem nicht durch vorgefertigte Montagesysteme gelöst?

Wir verwenden die folgende Klassifizierung, um die Aggregationsebenen von Baugruppen zu bestimmen.
L1. Ein kleiner unabhängiger Teil einer großen Anwendung. Dies kann eine Komponente, ein Mikroservice oder eine Hilfsbibliothek sein. Die L1-Assembly ist eine Lösung für lineare technische Probleme: Kompilieren, Packen, Arbeiten mit Abhängigkeiten. Maven, Gradle, Npm, Grunzen und andere Build-Systeme leisten hier hervorragende Arbeit. Es gibt Hunderte von ihnen.
Die L1-Montage muss mit vorgefertigten Werkzeugen von Drittanbietern erfolgen.
L2 +. Integrationseinheiten. L1-Entitäten werden zu größeren Formationen zusammengefasst, beispielsweise zu vollwertigen Microservice-Anwendungen. Mehrere dieser Anwendungen können als eine einzige Lösung gebündelt werden. Wir verwenden das Pluszeichen, da je nach Ebene der Baugruppenaggregation eine Ebene von L3 oder sogar L4 zugewiesen werden kann.
Ein Beispiel für solche Assemblys in der Welt von Drittanbietern ist die Vorbereitung von Linux-Distributionen. Metapakete dort.
Neben recht komplexen technischen Aufgaben (wie dieser: ru.wikipedia.org/wiki/Dependency_hell ). L2 + -Baugruppen sind häufig das Endprodukt und stellen daher viele Prozessanforderungen: ein System von Rechten, die Festlegung verantwortlicher Personen, das Fehlen von Rechtsfehlern, die Bereitstellung verschiedener Dokumentationen.
Bei L2 + werden Prozessanforderungen durch Automatisierung priorisiert.
Wenn die automatische Lösung nicht funktioniert, wie es für interessierte Personen bequem ist, wird sie nicht implementiert.
L2 + -Baugruppen werden höchstwahrscheinlich von einem proprietären Tool ausgeführt, das speziell auf die Prozesse des Unternehmens zugeschnitten ist. Denken Sie, Linux-Paketmanager haben sich das gerade ausgedacht?
Unsere Best Practices
Die Infrastruktur
Permanente Verfügbarkeit von Eisen
Die gesamte Assembly-Infrastruktur befindet sich auf geschlossenen Servern im Unternehmensnetzwerk. In einigen Fällen sind kommerzielle Cloud-Dienste möglich.
Autonomie
In allen CI-Prozessen ist das Internet nicht verfügbar. Alle erforderlichen Ressourcen werden intern gespiegelt und zwischengespeichert. Teilweise sogar github.com (danke, npm!) Die meisten dieser Probleme werden von Artifactory behoben.
Daher sind wir ruhig, wenn wir Artefakte aus Maven Central löschen oder beliebte Repositories schließen. Es gibt ein Beispiel: community.oracle.com/community/java/javanet-forge-sunset .
Durch das Spiegeln wird die Montagezeit erheblich verkürzt und der Unternehmens-Internetkanal freigegeben. Weniger kritische Netzwerkressourcen erhöhen die Build-Stabilität.
Drei Repositories für jeden Artefakttyp
- Dev ist ein Repository, in dem jeder Artefakte beliebigen Ursprungs veröffentlichen kann. Hier können Sie mit grundlegend neuen Ansätzen experimentieren, ohne sie vom ersten Tag an an Unternehmensstandards anzupassen.
- Staging ist ein Repository, das nur mit einer Assembly-Pipeline gefüllt ist.
- Release - Einzelbaugruppen, bereit zur externen Lieferung. Es ist mit einem speziellen Übertragungsvorgang mit manueller Bestätigung gefüllt.
30 Tage Regel
Aus Dev- und Staging-Repositorys löschen wir alles, was älter als 30 Tage ist. Dies trägt dazu bei, dass alle die gleichen Veröffentlichungsmöglichkeiten haben, indem eine begrenzte Menge an Server-Speicherplatz aufgewendet wird.
Die Freigabe wird für immer gespeichert, die Archivierung erfolgt bei Bedarf.
Montageumgebung reinigen
Oft verbleiben nach Baugruppen Hilfsdateien im System, was sich auf andere Baugruppenprozesse auswirken kann. Typische Beispiele:
- Das häufigste Problem ist ein Cache, der durch eine falsche Assembly beschädigt wurde (wie mit Caches umgegangen wird, siehe unten).
- Einige Dienstprogramme, wie z. B. npm, belassen Dienstdateien im Verzeichnis $ HOME, die sich auf alle nachfolgenden Starts dieser Dienstprogramme auswirken.
- Eine bestimmte Assembly kann den gesamten Speicherplatz in einer / tmp-Partition belegen, was zu einer allgemeinen Nichtverfügbarkeit der Umgebung führt.
Daher ist es besser, die einheitliche Umgebung zugunsten von Docker-Containern aufzugeben. Container sollten nur die erforderliche Software für eine bestimmte Baugruppe mit festen Versionen enthalten.
DevOps verwaltet eine Sammlung von Assembly Docker-Images, die ständig aktualisiert wird. Zuerst waren es ungefähr sechs, dann war es unter 30, dann haben wir die automatische Bilderzeugung aus der Softwareliste eingerichtet. Geben Sie jetzt einfach Anforderungen wie require ('maven 3.3.9', 'python') an - und die Umgebung ist bereit.
Selbstdiagnose
Es ist nicht nur notwendig, die Benutzerunterstützung für Anfragen zu organisieren, sondern wir müssen das Verhalten unseres eigenen Systems selbst analysieren. Wir sammeln ständig Protokolle und suchen in ihnen nach Stichwörtern, die Probleme anzeigen.
Auf einem "Live" -System reicht es aus, 20 bis 30 reguläre Ausdrücke zu schreiben, damit Sie für jede Assembly den Grund für den Rückgang auf der Ebene angeben können:
- Git Server Absturz
- Der Speicherplatz ist dort aufgebraucht.
- Build-Fehler aufgrund des Fehlers des Entwicklers;
- Bekannter Fehler in Docker.
Wenn etwas gefallen ist, aber kein einziges bekanntes Problem festgestellt wurde, ist dies eine Gelegenheit, die Sammlung von Masken aufzufüllen.
Dann gehen wir zum Benutzer und sagen, dass er einen Build hat und dies kann auf diese Weise behoben werden.
Sie werden überrascht sein, wie viele Probleme Benutzer nicht im Support melden. Es ist besser, sie im Voraus und zu einem geeigneten Zeitpunkt zu reparieren. Oft wird ein kleiner Veröffentlichungsfehler zwei Wochen lang ignoriert, und am Freitagabend stellt sich heraus, dass dies die externe Ausgabe blockiert.
Wir wählen sorgfältig aus, von welchen Systemen die Baugruppe abhängt
Idealerweise im Allgemeinen, um eine vollständige Autonomie der Baugruppe zu gewährleisten. Meistens ist dies jedoch unmöglich. Für Java-basierte Assemblys benötigen Sie mindestens Artifactory zum Spiegeln - siehe oben für Autonomie. Jedes integrierte System erhöht das Ausfallrisiko. Es ist wünschenswert, dass alle Systeme im anständigen HA-Modus arbeiten.
Fließbandschnittstelle
Einzelne Schnittstelle zum Aufrufen der Assembly
Wir machen jede Art von Montage mit einem System. Baugruppen aller Ebenen (L1, L2 +) werden durch Programmcode beschrieben und über einen Jenkins-Job aufgerufen.
Dieser Ansatz ist jedoch nicht ideal. Es ist besser, die automatischen Generierungsmechanismen für Jenkins-Jobs zu verwenden: Zum Beispiel 1 Job = 1 Git-Repository oder 1 Job = 1 Git-Zweig. Dadurch wird Folgendes erreicht:
- Protokolle von heterogenen Baugruppen werden in einer Story auf der Jenkins-Jobseite nicht verwechselt.
- Tatsächlich erhalten Sie bequem zugewiesene Jobs für ein Team oder einen Entwickler. Das Gefühl des Komforts kann durch Anpassen der Diagramme der Ergebnisse von Junit, Cobertura und Sonar verbessert werden.
Freiheit, Technologie zu wählen
Das Starten des Builds ist ein Aufruf des Bash-Skripts "./build.sh". Und dann - alle Montagesysteme, Programmiersprachen und alles andere, was zur Erfüllung einer Geschäftsaufgabe benötigt wird. Dies bietet einen Ansatz für die Montage als Black Box.
Smart Post
Das Fließband fängt Veröffentlichungen aus der Black Box ab und legt sie bereits im Unternehmensspeicher ab. Langweilige Probleme wie das Generieren von Docker-Image-Namen und die Auswahl des richtigen Repositorys für die Veröffentlichung werden automatisch behoben.
Staging- und Release-Repositorys haben immer Ordnung. Es ist erforderlich, die Besonderheiten von Veröffentlichungen verschiedener Typen zu unterstützen: maven, npm, file, docker.
Baugruppendeskriptor
Build.sh beschreibt das Kompilieren von Code, dies reicht jedoch für einen Assemblycontainer nicht aus.
Sie müssen auch wissen:
- welche Montageumgebung verwendet werden soll;
- Umgebungsvariablen in build.sh verfügbar;
- Welche Veröffentlichungen werden durchgeführt?
- andere spezifische Optionen.
Wir haben einen bequemen Weg gewählt, um diese Informationen in Form einer Yaml-Datei zu beschreiben, die .gitlab-ci.yaml ähnelt.
Baugruppenparametrierung
Der Benutzer kann beliebige Parameter angeben, ohne den Befehl git commit direkt zu Beginn der Assembly auszuführen.
Wir haben dies implementiert, indem wir Umgebungsvariablen direkt über die Jenkins-Jobschnittstelle definiert haben.
Zum Beispiel übertragen wir die Version der abhängigen Bibliothek in einen solchen Assembly-Parameter und definieren diese Version in einigen Fällen neu in eine experimentelle. Ohne einen solchen Mechanismus müsste der Benutzer jedes Mal den Befehl "git commit" ausführen.
Systemportabilität
Sie müssen in der Lage sein, den Assemblierungsprozess nicht nur auf dem Haupt-CI-Server, sondern auch auf dem Computer des Entwicklers zu reproduzieren. Dies hilft beim Debuggen komplexer Build-Skripte. Außerdem ist es manchmal bequemer, Gitlab CI anstelle von Jenkins zu verwenden. Daher muss das Build-System eine unabhängige Java-Anwendung sein. Wir haben es als Gradle-Plugin implementiert.
Ein Artefakt kann unter verschiedenen Namen veröffentlicht werden.
Es gibt zwei gegensätzliche Anforderungen für die Veröffentlichung, die gleichzeitig auftreten können.
Einerseits ist es für die langfristige Speicherung und Freigabeverwaltung erforderlich, die Eindeutigkeit der Namen veröffentlichter Artefakte sicherzustellen. Dies schützt zumindest Artefakte vor dem Überschreiben.
Andererseits ist es manchmal praktisch, ein tatsächliches Artefakt mit einem festen Namen wie dem neuesten zu haben. Beispielsweise muss der Entwickler nicht jedes Mal die genaue Version der Abhängigkeit kennen, sondern kann nur mit der neuesten Version arbeiten.
Das Artefakt wird in diesem Fall unter zwei oder mehr Namen veröffentlicht, da es für jeden geeignet ist.
Zum Beispiel:
- ein eindeutiger Name mit Zeitstempel oder UUID - für diejenigen, die Genauigkeit benötigen;
- der Name "neueste" - für ihre Entwickler, die immer den neuesten Code abholen;
- Der Name "<Hauptversion> .x-neueste" steht für ein benachbartes Team, das bereit ist, die neuesten Versionen aufzunehmen, jedoch nur im Rahmen eines bestimmten Hauptfachs.
Maven macht etwas Ähnliches in seiner Herangehensweise an SNAPSHOT.
Weniger Sicherheitsbeschränkungen
Jeder kann mit der Montage beginnen. Dies schadet niemandem, da die Baugruppe nur Artefakte erstellt.
Einhaltung gesetzlicher Bestimmungen
Kontrolle der externen Interaktionen des Montageprozesses
Die Baugruppe kann während ihrer Arbeit nichts Verbotenes verwenden.
Zu diesem Zweck wird die Aufzeichnung des Netzwerkverkehrs und der Zugriff auf Datei-Caches implementiert. Wir erhalten das Protokoll der Netzwerkaktivität der Assembly in Form einer URL-Liste mit sha256-Hashes der empfangenen Daten. Außerdem wird jede URL validiert:
- statische Whitelist;
- dynamische Datenbank zulässiger Artefakte (z. B. für Maven-, RPM-, Npm-Abhängigkeiten). Jede Sucht wird individuell betrachtet. Eine automatische Genehmigung oder ein Nutzungsverbot kann funktionieren, und es kann auch eine lange Diskussion mit Anwälten beginnen.
Transparenter Inhalt veröffentlichter Artefakte
Manchmal besteht die Aufgabe darin, eine Liste von Software von Drittanbietern in jeder Baugruppe bereitzustellen. Zu diesem Zweck haben sie einen einfachen Kompositionsanalysator erstellt, der alle Dateien und Archive in der Baugruppe analysiert, den Drittanbieter anhand von Hashes erkennt und einen Bericht erstellt.
Der ausgegebene Quellcode kann nicht aus GIT entfernt werden
Manchmal müssen Sie den Quellcode finden, indem Sie sich das vor zwei Jahren kompilierte binäre Artefakt ansehen. Dazu ist es notwendig, Tags in Git automatisch mit externer Ausgabe zuzuweisen und deren Entfernung zu verbieten.
Logistik und Buchhaltung
Alle Baugruppen werden in der Datenbank gespeichert.
Für diese Zwecke verwenden wir das Datei-Repository in Artifactory. Es enthält alle unterstützenden Informationen: Wer hat es gestartet, was waren die Ergebnisse der Überprüfungen, welche Artefakte wurden veröffentlicht, welcher Git-Hash wurde verwendet usw.
Wir wissen, wie wir die Baugruppe so genau wie möglich reproduzieren können
Nach den Ergebnissen der Montage speichern wir folgende Informationen:
- den genauen Status des gesammelten Codes;
- Mit welchen Parametern wurde der Start durchgeführt?
- welche Befehle wurden genannt;
- Welcher Zugriff auf externe Ressourcen erfolgte?
- gebrauchte Montageumgebung.
Bei Bedarf können wir die Frage, wie es zusammengebaut wurde, genau beantworten.
Zweiwege-Kommunikation der Versammlung mit dem JIRA-Ticket
Stellen Sie sicher, dass Sie die folgenden Probleme lösen können:
- Erstellen Sie für die Montage eine Liste der darin enthaltenen JIRA-Tickets.
- Schreiben Sie in das JIRA-Ticket, in welchen Baugruppen es enthalten ist.
Eine enge bidirektionale Kommunikation zwischen der Assembly und dem Git-Commit wird bereitgestellt. Und dann können Sie aus dem Text der Kommentare bereits alle Links zu JIRA herausfinden.
Geschwindigkeit
Caches des Assembly-Systems
Das Fehlen eines Maven-Cache kann die Erstellungszeit um eine Stunde verlängern.
Der Cache verletzt die Isolation der Assembly-Umgebung und die Sauberkeit der Assembly. Dieses Problem kann gelöst werden, indem der Ursprung für jedes zwischengespeicherte Artefakt bestimmt wird. Wir haben jede Cache-Datei mit einem https-Link verknüpft, von dem sie einmal heruntergeladen wurde. Weiterhin verarbeiten wir das Lesen eines Caches als Netzwerkadresse.
Netzwerkressourcen-Caches
Das geografische Wachstum des Unternehmens führt dazu, dass Dateien mit einer Größe von 300 MB zwischen Kontinenten übertragen werden müssen. Es wird viel Zeit aufgewendet, insbesondere wenn Sie dies häufig tun müssen.
Git-Repositorys, Docker-Images von Assembly-Umgebungen, Dateispeicher - alles muss sorgfältig zwischengespeichert werden. Na ja, natürlich regelmäßig sauber.
Montage - so schnell wie möglich, alles andere - dann
Die erste Phase: Wir machen die Montage und geben sofort, ohne unnötige Gesten, das Ergebnis.
Die zweite Stufe: Validierung, Analyse, Buchhaltung und andere Bürokratie. Dies kann bereits in einem separaten Jenkins-Job und ohne strenge Fristen erfolgen.
Was ist das Ergebnis?
- Die Hauptsache ist, dass die Baugruppe den Entwicklern klar geworden ist , sie können sie selbst entwickeln und optimieren.
- Die Grundlage für die Erstellung von Geschäftsprozessen wurde geschaffen, die von der Baugruppe abhängen: Installation, Issue-Management, Test, Release-Management usw.
- Das DevOps-Team schreibt keine Assembly-Skripte mehr: Entwickler tun es.
- Aus komplexen Unternehmensanforderungen wurde ein transparenter Bericht mit einer endgültigen Liste von Prüfungen.
- Jeder kann ein beliebiges Repository erstellen, indem er build.sh über eine einzige Schnittstelle aufruft. Es reicht ihm, einfach die Git-Koordinaten des Quellcodes anzugeben. Diese Person kann ein Teammanager, ein QA / IT-Ingenieur usw. sein.
Und ein paar Zahlen
- Zeitkosten. Vom Aufrufen des Jenkins-Jobs bis zur sofortigen Arbeit von build.sh sind weitere 15 Sekunden erforderlich. 15 docker-, , . . .
- . . 2200 . — on-commit-.
- 300 git-, .
- 30 , (25 ) — docker.
- , :
- glide, golang, promu;
- maven, gradle;
- python & pip;
- ruby;
- nodejs & npm;
- docker;
- rpm build tools & gcc;
- Android ADT;
- ;
- legacy-;
- .