Zuvor haben wir über den leistungsstärksten japanischen Supercomputer für die Forschung in der Kernphysik gesprochen. Jetzt in Japan entwickeln sie einen Exaflops-Supercomputer Post-K - die Japaner werden einer der ersten sein, der eine Maschine mit einer solchen Rechenleistung auf den Markt bringt.
Die Inbetriebnahme ist für 2021 geplant.
Letzte Woche sprach Fujitsu über die technischen Eigenschaften des A64FX-Chips, der die Grundlage für die neue "Maschine" bilden wird. Wir werden Ihnen mehr über den Chip und seine Fähigkeiten erzählen.
 / Foto Toshihiro Matsui CC / Japanischer Supercomputer K Computer
/ Foto Toshihiro Matsui CC / Japanischer Supercomputer K ComputerTechnische Daten A64FX
Es wird erwartet, dass die Rechenkapazitäten von Post-K fast zehnmal
höher sein werden als die Leistung der leistungsstärksten der vorhandenen
IBM Summit- Supercomputer (
Stand Juni 2018 ).
Der Supercomputer hat eine ähnliche Leistung wie der A64FX Arm-basierte Chip. Dieser Chip
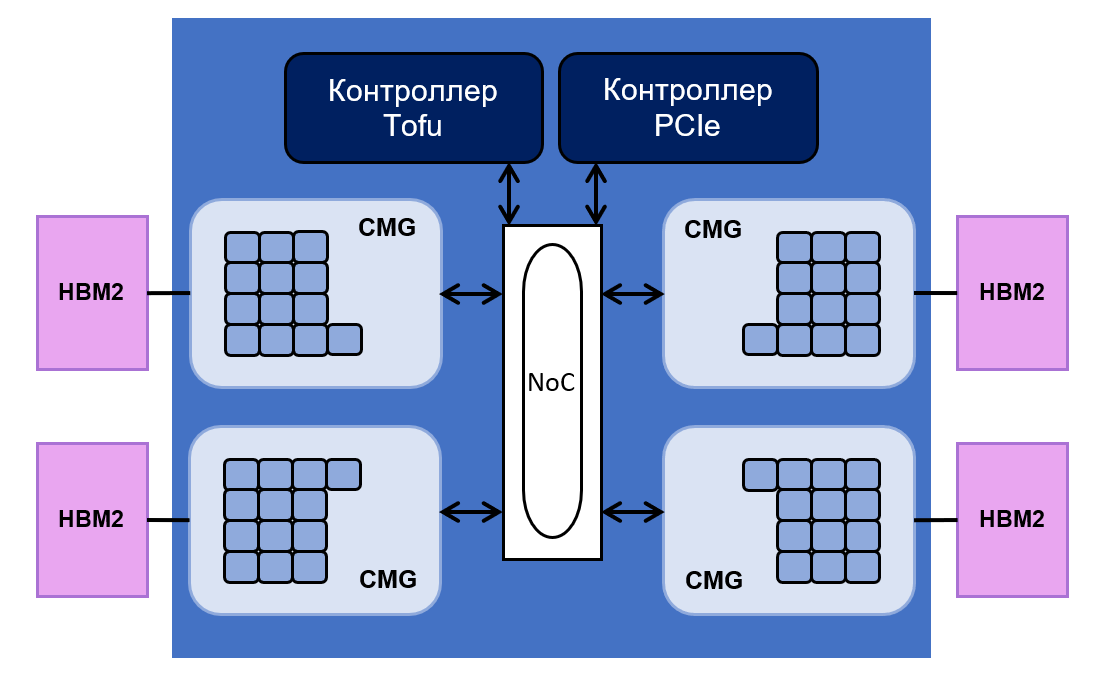
besteht aus 48 Kernen für Rechenvorgänge und vier Kernen für deren Steuerung. Alle von ihnen sind gleichmäßig in vier Gruppen unterteilt - Core Memory Groups (CMG).
Jede Gruppe verfügt über 8 MB L2-Cache. Es ist mit dem Speichercontroller und der NoC-Schnittstelle verbunden ("
Netzwerk auf einem Chip "). NoC verbindet verschiedene CMGs mit PCIe- und Tofu-Controllern. Letzterer ist für die Kommunikation zwischen dem Prozessor und dem Rest des Systems verantwortlich. Der Tofu-Controller verfügt über zehn Ports mit einem Durchsatz von 12,5 GB / s.
Das Chip-Layout ist wie folgt:
Der gesamte
HBM2- Speicher des Prozessors beträgt 32 Gigabyte und sein Durchsatz beträgt 1024 GB / s. Laut Fujitsu erreicht die Prozessorleistung bei Gleitkommaoperationen 2,7 Teraflops für 64-Bit-Operationen, 5,4 Teraflops für 32-Bit-Operationen und 10,8 Teraflops für 16-Bit-Operationen.
Die Erstellung von Post-K wird von den Top500-Ressourceneditoren überwacht, die eine Liste der leistungsstärksten Computersysteme erstellen. Demnach verwendet der Supercomputer mehr als 370.000 A64FX-Prozessoren, um die Leistung in einem Exaflop zu erreichen.
Das Gerät wird zunächst die Technologie der Vektorerweiterung namens Scalable Vector Extension (SVE) verwenden. Es unterscheidet sich von anderen
SIMD-Architekturen dadurch, dass es
die Länge von Vektorregistern nicht
begrenzt , sondern einen gültigen Bereich für sie festlegt. SVE unterstützt Vektoren mit einer Länge von 128 bis 2048 Bit. So kann jedes Programm auf anderen Prozessoren ausgeführt werden, die SVE unterstützen, ohne dass eine Neukompilierung erforderlich ist.
Mit SVE (da es sich um eine SIMD-Funktion handelt) kann der Prozessor gleichzeitig Berechnungen mit mehreren Datenfeldern durchführen. Hier ist ein Beispiel für eine dieser Anweisungen für die NEON-Funktion, die für die Vektorberechnung in anderen Arm-Prozessorarchitekturen verwendet wurde:
vadd.i32 q1, q2, q3
Es addiert vier 32-Bit-Ganzzahlen aus dem 128-Bit-Register q2 mit den entsprechenden Zahlen im 128-Bit-Register q3 und schreibt das resultierende Array in q1. Das Äquivalent dieser Operation in C sieht folgendermaßen aus:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];
Darüber hinaus unterstützt SVE die automatische Vektorisierung. Ein automatischer Vektorisierer analysiert die Zyklen im Code und verwendet, wenn möglich, Vektorregister, um sie auszuführen. Dies verbessert die Codeleistung.
Zum Beispiel eine Funktion in C:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c) { unsigned int i; for(i = 0; i < SIZE; i++) { a[i] = b[i] + c[i]; } }
Es wird wie folgt kompiliert (für einen 32-Bit-Arm-Prozessor):
104cc: ldr.w r3, [r4, #4]! 104d0: ldr.w r1, [r2, #4]! 104d4: cmp r4, r5 104d6: add r3, r1 104d8: str.w r3, [r0, #4]! 104dc: bne.n 104cc <vectorize_this+0xc>
Wenn Sie die automatische Vektorisierung verwenden, sieht dies folgendermaßen aus:
10780: vld1.64 {d18-d19}, [r5 :64] 10784: adds r6, #1 10786: cmp r6, r7 10788: add.w r5, r5, #16 1078c: vld1.32 {d16-d17}, [r4] 10790: vadd.i32 q8, q8, q9 10794: add.w r4, r4, #16 10798: vst1.32 {d16-d17}, [r3] 1079c: add.w r3, r3, #16 107a0: bcc.n 10780 <vectorize_this+0x70>
Hier werden die SIMD-Register q8 und q9 mit Daten von Arrays geladen, auf die r5 und r4 zeigen. Danach fügt der vadd-Befehl vier 32-Bit-Ganzzahlwerte gleichzeitig hinzu. Dies erhöht die Codemenge, aber auf diese Weise werden für jede Iteration der Schleife viel mehr Daten verarbeitet.
Wer schafft sonst Exaflops Supercomputer
Exaflops-Supercomputer werden nicht nur in Japan hergestellt. Beispielsweise wird auch in China und den USA gearbeitet.
Erstellen Sie in China Tianhe-3 (Tianhe-3). Der Prototyp wird bereits im National Supercomputing Center in Tianjin
getestet . Die endgültige Version des Computers soll 2020 fertiggestellt werden.
 / Foto O01326 CC / Tianhe-2 Supercomputer - Vorgänger von Tianhe-3
/ Foto O01326 CC / Tianhe-2 Supercomputer - Vorgänger von Tianhe-3Das Herzstück von Tianhe-3
sind chinesische Phytium-Prozessoren. Das Gerät enthält 64 Kerne,
hat eine Leistung von 512 Gigaflops und eine Speicherbandbreite von 204,8 GB / s.
Ein funktionierender Prototyp wurde auch für eine Maschine aus der
Sunway- Serie erstellt. Es wird im National Supercomputer Center in Jinan getestet. Laut den Entwicklern arbeiten derzeit etwa 35 Anwendungen auf dem Computer - dies sind biomedizinische Simulatoren, Anwendungen zur Verarbeitung von Big Data und Programme zur Untersuchung des Klimawandels. Es wird erwartet, dass die Arbeiten am Computer in der ersten Hälfte des Jahres 2021 abgeschlossen sein werden.
Für die Vereinigten Staaten
planen die Amerikaner
, ihren Exaflops-Computer bis 2021
zu erstellen . Das Projekt heißt Aurora A21 und das
Argonne National Laboratory des US-Energieministeriums sowie Intel und Cray arbeiten daran.
In diesem Jahr haben Forscher bereits zehn Projekte für das Aurora Early Science Program ausgewählt, deren Teilnehmer als erste das neue Hochleistungssystem einsetzen werden. Darunter befanden sich Programme zur Erstellung einer
Karte von Gehirnneuronen, zur Untersuchung der Dunklen Materie und zur Entwicklung eines Teilchenbeschleunigersimulators.
Exaflops-Computer werden es ermöglichen, komplexe Modelle für die Forschung zu erstellen, so dass viele wissenschaftliche Projekte auf die Entwicklung solcher Maschinen warten. Eines der ehrgeizigsten ist das Human Brain Project (HBP), dessen Ziel es ist, ein vollständiges Modell des menschlichen Gehirns zu erstellen und neuromorphe Berechnungen zu untersuchen. Laut Wissenschaftlern von HBP kann der Einsatz neuer Exaflopsysteme bereits in den ersten Tagen ihres Bestehens festgestellt werden.
Was wir in IT-GRAD tun: • IaaS • PCI-DSS-Hosting • Cloud -152
Inhalt aus unserem IaaS-Unternehmensblog: